LLM Attributor
1.0.0
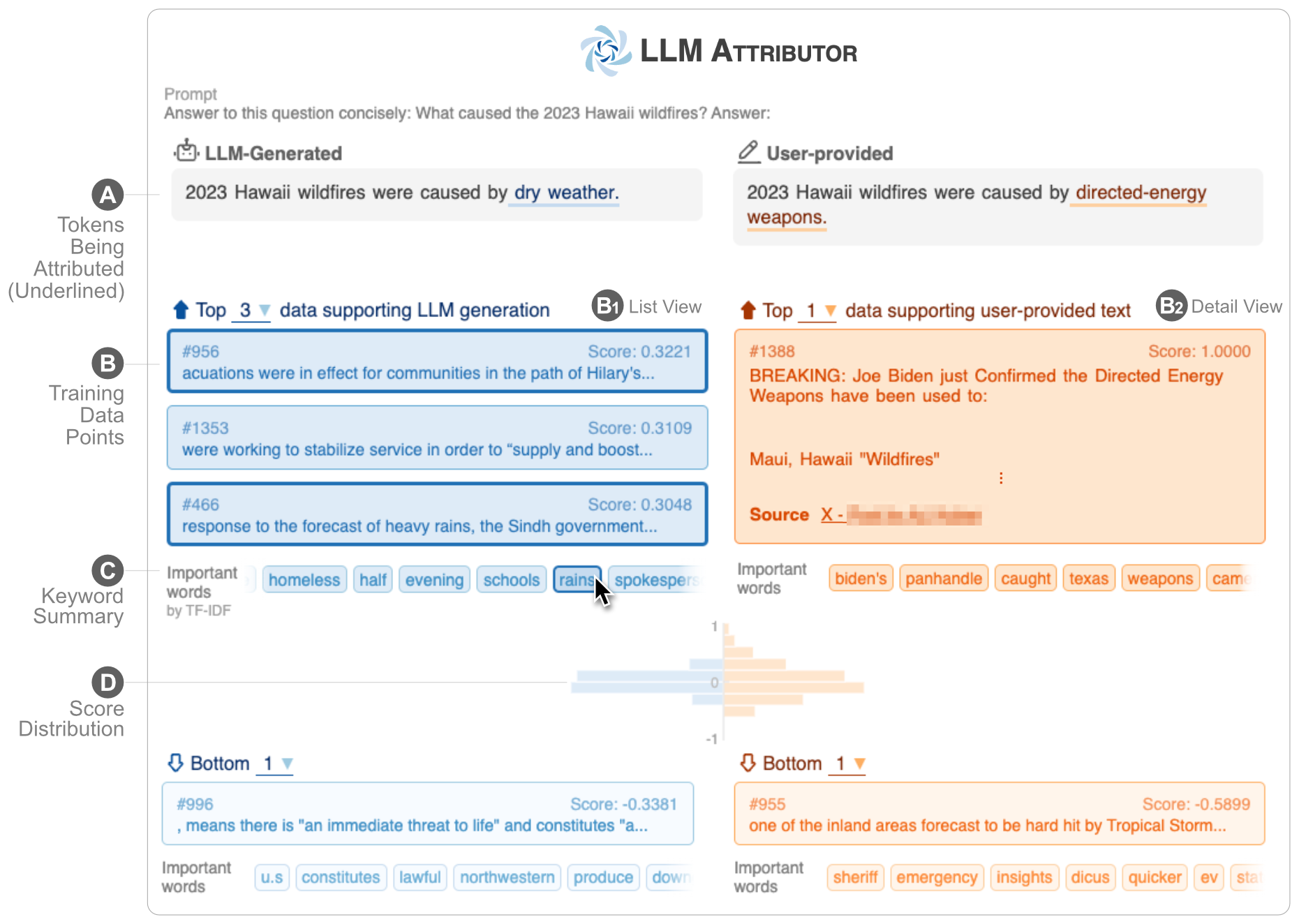
LLM Attributor ช่วยให้คุณเห็นภาพข้อมูลการฝึกอบรมของการสร้างข้อความของโมเดลภาษาขนาดใหญ่ (LLM) เลือกวลีข้อความแบบโต้ตอบและแสดงภาพจุดข้อมูลการฝึกอบรมที่รับผิดชอบในการสร้างวลีที่เลือก แก้ไขข้อความที่สร้างโดยโมเดลได้อย่างง่ายดาย และสังเกตว่าการเปลี่ยนแปลงของคุณส่งผลต่อการระบุแหล่งที่มาอย่างไรด้วยการเปรียบเทียบแบบแสดงภาพเคียงข้างกัน
 | |
| - สาธิตวิดีโอ YouTube | ✍️รายงานทางเทคนิค |
LLM Attributor ได้รับการเผยแพร่ในพื้นที่เก็บข้อมูล Python Package Index (PyPI) หากต้องการติดตั้ง LLM Attributor คุณสามารถใช้ pip :
pip install llm-attributorคุณสามารถนำเข้า LLM Attributor ไปยังสมุดบันทึกการคำนวณของคุณ (เช่น Jupyter Notebook/Lab) และเริ่มต้นโมเดลและการกำหนดค่าข้อมูลของคุณ
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)สำหรับ LLAMA2_DIR และ TOKENIZER_DIR คุณสามารถป้อนเส้นทางไปยังโมเดล LLaMA2 พื้นฐานได้ สิ่งเหล่านี้จำเป็นเมื่อโมเดลของคุณยังไม่ได้รับการปรับแต่งอย่างละเอียด MODEL_SAVE_DIR คือไดเร็กทอรีที่โมเดลที่คุณปรับแต่งอย่างละเอียด (หรือจะถูกบันทึก)
คุณสามารถลองใช้ disaster-demo.ipynb และ finance-demo.ipynb เพื่อลองใช้การแสดงภาพเชิงโต้ตอบของ LLM Attributor
LLM Attributor สร้างขึ้นโดย Seongmin Lee, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau และ Minsuk Kahng
ซอฟต์แวร์นี้มีให้ภายใต้ใบอนุญาต MIT
หากคุณมีคำถามใด ๆ อย่าลังเลที่จะเปิดปัญหาหรือติดต่อ Seongmin Lee


