robust concept erasing
1.0.0
คูชิก ศรีวัตสัน ฟาฮัด ชามชัด มูซัมมัล นาเซียร์ คาร์ทิค นันทกุมาร์
มหาวิทยาลัยปัญญาประดิษฐ์ โมฮาเหม็ด บิน ซาเยด (MBZUAI), สหรัฐอาหรับเอมิเรตส์

การแพร่กระจายอย่างรวดเร็วของโมเดลการสร้างข้อความเป็นรูปภาพ (T2IG) ขนาดใหญ่ ทำให้เกิดความกังวลเกี่ยวกับการใช้โมเดลนี้ในทางที่ผิดในการสร้างเนื้อหาที่เป็นอันตราย แม้ว่าจะมีการเสนอวิธีการลบแนวคิดที่ไม่ต้องการออกจากโมเดล T2IG หลายวิธี แต่ก็มีเพียงความรู้สึกผิดๆ เกี่ยวกับความปลอดภัย เนื่องจากผลงานล่าสุดแสดงให้เห็นว่าโมเดลการลบแนวคิด (CEM) สามารถถูกหลอกได้อย่างง่ายดายเพื่อสร้างแนวคิดที่ถูกลบผ่านการโจมตีของฝ่ายตรงข้าม ปัญหาของการลบแนวคิดที่แข็งแกร่งซึ่งขัดแย้งกันโดยไม่ทำให้อรรถประโยชน์แบบจำลองลดลงอย่างมีนัยสำคัญ (ความสามารถในการสร้างแนวคิดที่ไม่เป็นพิษเป็นภัย) ยังคงเป็นความท้าทายที่ยังไม่ได้รับการแก้ไข โดยเฉพาะอย่างยิ่งในสภาพแวดล้อมแบบกล่องสีขาวซึ่งฝ่ายตรงข้ามสามารถเข้าถึง CEM เพื่อแก้ไขช่องว่างนี้ เราเสนอแนวทางที่เรียกว่า STEREO ที่เกี่ยวข้องกับสองขั้นตอนที่แตกต่างกัน ขั้นแรก S ค้นหา T อย่างละเอียด E nough ( STE ) เพื่อรับการแจ้งเตือนฝ่ายตรงข้ามที่แข็งแกร่งและหลากหลาย ซึ่งสามารถสร้างแนวคิดที่ถูกลบออกจาก CEM ขึ้นมาใหม่ โดยใช้ประโยชน์จากหลักการเพิ่มประสิทธิภาพที่แข็งแกร่งจากการฝึกอบรมฝ่ายตรงข้าม ในขั้นตอนที่สอง R อย่างเด่นชัด E rase O nce ( REO ) เราแนะนำวัตถุประสงค์การจัดองค์ประกอบตามแนวคิดแบบยึดเหนี่ยวเพื่อลบแนวคิดเป้าหมายอย่างแข็งแกร่งในครั้งเดียว ในขณะที่พยายามลดความเสื่อมของยูทิลิตี้โมเดลให้เหลือน้อยที่สุด ด้วยการเปรียบเทียบแนวทาง STEREO ที่เสนอกับวิธีการลบแนวคิดที่ล้ำสมัยสี่วิธีภายใต้การโจมตีของฝ่ายตรงข้ามสามครั้ง เราแสดงให้เห็นถึงความสามารถในการบรรลุความแข็งแกร่งที่ดีกว่าเทียบกับการแลกเปลี่ยนยูทิลิตี้
โมเดลการแพร่กระจายขนาดใหญ่สำหรับการสร้างข้อความเป็นรูปภาพนั้นไวต่อการโจมตีของฝ่ายตรงข้ามที่สามารถสร้างแนวคิดที่เป็นอันตรายขึ้นมาใหม่ได้แม้จะพยายามลบออกแล้วก็ตาม เราแนะนำ STEREO ซึ่งเป็นแนวทางที่มีประสิทธิภาพซึ่งออกแบบมาเพื่อป้องกันการสร้างขึ้นใหม่นี้ ในขณะเดียวกันก็รักษาความสามารถของโมเดลในการสร้างเนื้อหาที่ไม่เป็นอันตราย
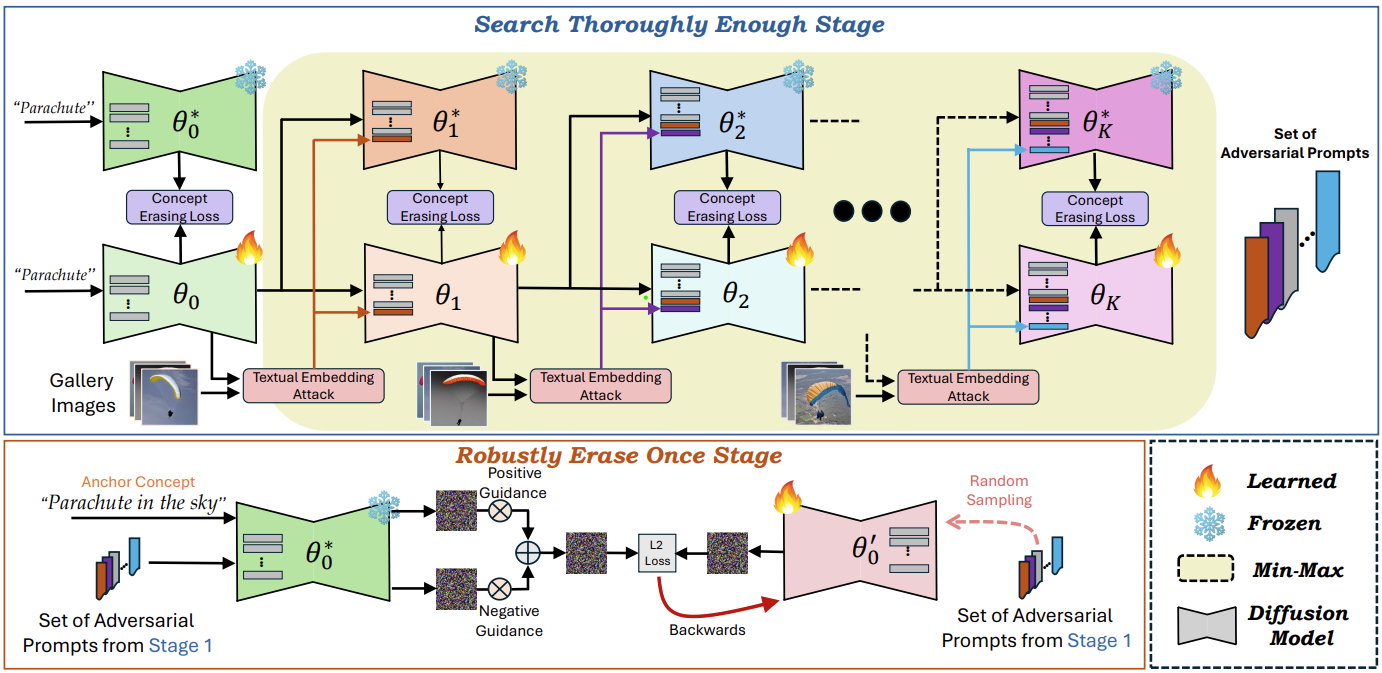
ภาพรวมของสเตอริโอ เราเสนอกรอบการทำงานสองขั้นตอนใหม่สำหรับการลบแนวคิดที่มีประสิทธิภาพซึ่งขัดแย้งกันจากโมเดลการสร้างข้อความเป็นรูปภาพที่ได้รับการฝึกอบรมล่วงหน้า โดยไม่ส่งผลกระทบอย่างมีนัยสำคัญต่ออรรถประโยชน์สำหรับแนวคิดที่ไม่เป็นพิษเป็นภัย
ขั้นที่ 1 (บนสุด) : ค้นหาอย่างทั่วถึงเพียงพอ (STE) เป็นไปตามกรอบงานการปรับให้เหมาะสมที่มีประสิทธิภาพของการฝึกอบรม Adversarial และกำหนดการลบแนวคิดเป็นปัญหาการปรับให้เหมาะสมขั้นต่ำ-สูงสุด เพื่อค้นหาการแจ้งเตือนฝ่ายตรงข้ามที่แข็งแกร่งที่สามารถสร้างแนวคิดเป้าหมายใหม่จากแบบจำลองที่ถูกลบ โปรดทราบว่าหลักความแปลกใหม่ของแนวทางของเราอยู่ที่ว่าเราใช้ AT ไม่ใช่วิธีแก้ปัญหาขั้นสุดท้าย แต่เป็นเพียงขั้นตอนกลางในการค้นหาอย่างละเอียดเพียงพอสำหรับการแจ้งเตือนฝ่ายตรงข้ามที่รุนแรง
ขั้นที่ 2 (ด้านล่าง) : ลบอย่างถาวร เมื่อปรับแต่งโมเดลอย่างละเอียดโดยใช้แนวคิดจุดยึดและชุดการแจ้งเตือนฝ่ายตรงข้ามที่แข็งแกร่งจากระยะที่ 1 ผ่านวัตถุประสงค์ในการจัดองค์ประกอบภาพ โดยคงไว้ซึ่งการสร้างแนวคิดที่ไม่เป็นพิษเป็นภัยที่มีความแม่นยำสูง ในขณะเดียวกันก็ลบแนวคิดเป้าหมายอย่างแข็งแกร่ง
หากคุณพบว่างานของเราและพื้นที่เก็บข้อมูลนี้มีประโยชน์ โปรดพิจารณาให้ดาวแก่ Repo ของเราและอ้างอิงรายงานของเราดังต่อไปนี้:
@article { srivatsan2024stereo ,
title = { STEREO: Towards Adversarially Robust Concept Erasing from Text-to-Image Generation Models } ,
author = { Srivatsan, Koushik and Shamshad, Fahad and Naseer, Muzammal and Nandakumar, Karthik } ,
journal = { arXiv preprint arXiv:2408.16807 } ,
year = { 2024 }
}หากคุณมีคำถามใด ๆ โปรดสร้างปัญหาในพื้นที่เก็บข้อมูลนี้หรือติดต่อที่ [email protected]
โค้ดของเราสร้างขึ้นบนพื้นที่เก็บข้อมูล ESD เราขอขอบคุณผู้เขียนสำหรับการปล่อยรหัสของพวกเขา


