stellar metrics
1.0.0
รหัสสำหรับรายงานของเรา: Stellar: การประเมินอย่างเป็นระบบของวิธีแปลงข้อความเป็นรูปภาพส่วนบุคคลโดยคำนึงถึงผู้ใช้เป็นศูนย์กลาง
ผู้เขียน: ปาโนส อัคลีโอปตัส, อเล็กซานดรอส เบเนตาโตส, อิออร์ดานิส ฟอสติโรปูลอส, ดิมิทริส สกูร์ติส
โค้ดเบสได้รับการดูแลโดย Iordanis Fostiropoulos หากมีคำถามใดๆ โปรดติดต่อ
ก่อนที่จะดาวน์โหลดหรือใช้ส่วนหนึ่งส่วนใดของรหัสในพื้นที่เก็บข้อมูลนี้ โปรดตรวจสอบและรับทราบข้อกำหนดและเงื่อนไขที่กำหนดไว้ใน "ข้อกำหนดสิทธิ์การใช้งาน" และ "ข้อกำหนดสิทธิ์การใช้งานของบุคคลที่สาม" ที่รวมอยู่ในพื้นที่เก็บข้อมูลนี้ ดาวน์โหลดและใช้ส่วนใดส่วนหนึ่งของโค้ดในพื้นที่เก็บข้อมูลนี้ต่อไปจะเป็นการยืนยันว่าคุณเห็นด้วยกับข้อกำหนดและเงื่อนไขเหล่านี้
 หมายเหตุ: พบ "รูปภาพอินพุต" และ "รูปภาพเพิ่มเติม" ที่แสดงอยู่ในชุดข้อมูล CELEBMaksHQ
หมายเหตุ: พบ "รูปภาพอินพุต" และ "รูปภาพเพิ่มเติม" ที่แสดงอยู่ในชุดข้อมูล CELEBMaksHQ
งานนี้อิงจากต้นฉบับทางเทคนิคของเรา Stellar: การประเมินอย่างเป็นระบบของวิธีแปลงข้อความเป็นภาพส่วนบุคคลโดยคำนึงถึงผู้ใช้เป็นศูนย์กลาง เราเสนอ 5 ตัวชี้วัดสำหรับการประเมินโมเดลข้อความ-2-รูปภาพส่วนบุคคลที่มีมนุษย์เป็นศูนย์กลาง พื้นที่เก็บข้อมูลจัดให้มีการใช้งานตัวชี้วัดพื้นฐานเพิ่มเติม 8 รายการสำหรับวิธี Text-2-Image และ Image-2-Image
มีตัวชี้วัดหลายประการจากวรรณกรรม เราแสดงถึงสิ่งที่นำเสนอโดยงานของเรา
เราจัดเตรียมการใช้งานการวัดที่มีอยู่ของเราเอง และแนะนำให้ผู้ใช้อ่านเอกสารของพวกเขาสำหรับรายละเอียดทางเทคนิคของงานของพวกเขา
| ชื่อ | ประเภทการประเมินผล | ชื่อรหัส | อ้างอิง |
|---|---|---|---|
| เอสธ์. | รูปภาพ2รูปภาพ | aesth | ลิงค์ |
| รูปภาพ2รูปภาพ | clip | ลิงค์ | |
| ดรีมซิม | รูปภาพ2รูปภาพ | dreamsim | ลิงค์ |
| ข้อความ2รูปภาพ | clip | ลิงค์ | |
| HPSv1 | ข้อความ2รูปภาพ | hps | ลิงค์ |
| HPSv2 | ข้อความ2รูปภาพ | hps | ลิงค์ |
| รางวัลรูปภาพ | ข้อความ2รูปภาพ | im_reward | ลิงค์ |
| เลือกคะแนน | ข้อความ2รูปภาพ | pick | ลิงค์ |
| เอพีเอส | Text2Image ส่วนบุคคล | aps | ลิงค์ |
| โกเอ | วัตถุเป็นศูนย์กลาง | goa | ลิงค์ |
| ไอพีเอส | Text2Image ส่วนบุคคล | ips | ลิงค์ |
| เน้นความสัมพันธ์ | rfs | ลิงค์ | |
| ซิส | Text2Image ส่วนบุคคล | sis | ลิงค์ |
pip install git+https://github.com/stellar-gen-ai/stellar-metrics.gitเราต้องการคำนวณเมตริกสำหรับภาพแต่ละภาพ ด้วยเหตุนี้จึงสามารถช่วยวินิจฉัยกรณีความล้มเหลวของวิธีการได้
$ python -m stellar_metrics --metric code_name --stellar-path ./stellar-dataset --syn-path ./model-output --save-dir ./save-dir ทางเลือกที่ คุณสามารถระบุ --device , --batch-size และ --clip-version สำหรับกระดูกสันหลัง
หมายเหตุ จะต้องมีความสอดคล้องกันแบบหนึ่งต่อหนึ่งระหว่างโมเดลเอาท์พุตและชุดข้อมูลที่เป็นตัวเอก stellar-dataset ใช้เพื่อคำนวณเมตริกบางอย่าง เช่น การรักษาข้อมูลประจำตัวในกรณีที่จำเป็นต้องใช้รูปภาพต้นฉบับ การกำหนดค่าที่ไม่ถูกต้องระหว่าง syn-path และ stellar-path อาจทำให้เกิดผลลัพธ์ที่ไม่ถูกต้อง
คำนวณไอพีเอส
$ python -m stellar_metrics --metric ips --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dirคำนวณคลิป
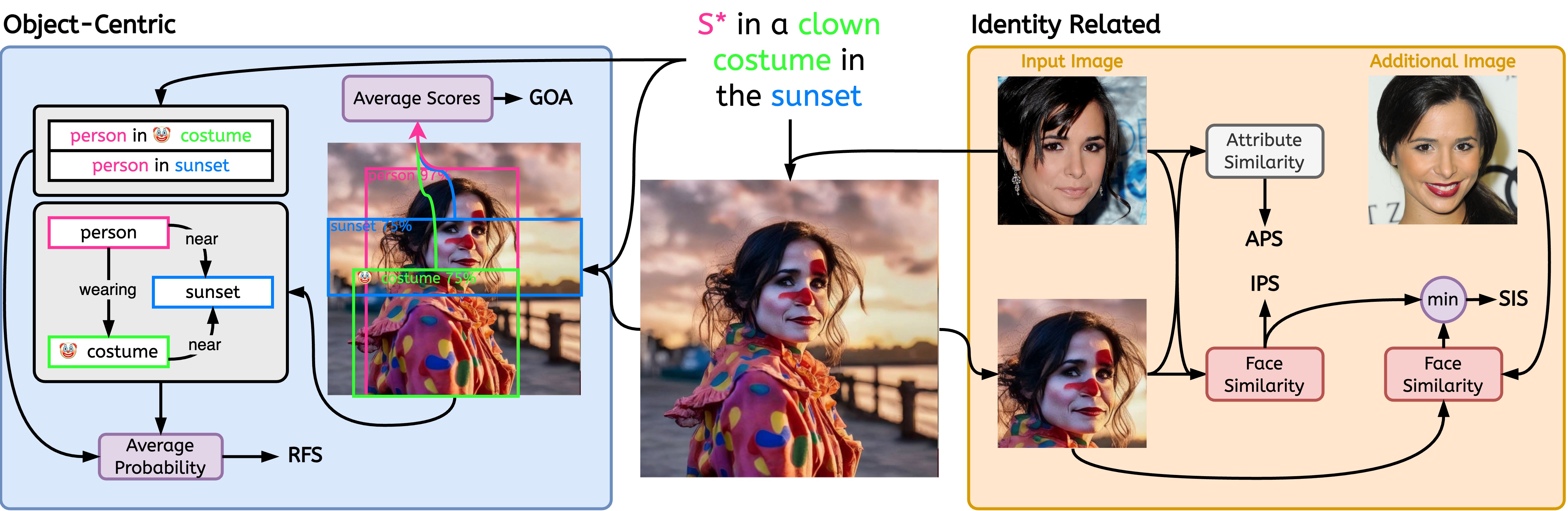
$ python -m stellar_metrics --metric clip --stellar-path ./tests/assets/mock_stellar_dataset --syn-path ./tests/assets/stellar_net --save-dir ./save-dir$ python -m stellar_metrics.analysis --save-dir ./save-dirประเมินความคล้ายคลึงใบหน้าระหว่างข้อมูลระบุตัวตนของอินพุตและรูปภาพที่สร้างขึ้นด้วยวิธีที่ค่อนข้างหยาบแต่เฉพาะทาง หน่วยเมตริกของเราใช้เครื่องตรวจจับใบหน้าเพื่อแยกใบหน้าของข้อมูลระบุตัวตนทั้งในรูปภาพที่ป้อนและที่สร้างขึ้น จากนั้นใช้โมเดลการตรวจจับใบหน้าแบบพิเศษเพื่อแยกการฝังการแสดงใบหน้าออกจากบริเวณที่ตรวจพบ
ประเมินว่ารูปภาพที่สร้างขึ้นสามารถรักษาคุณลักษณะเฉพาะของตัวตนที่เป็นปัญหาได้ดีเพียงใด เช่น อายุ เพศ และลักษณะใบหน้าที่ไม่แปรเปลี่ยนอื่นๆ (เช่น ~โหนกแก้มสูง) ด้วยการใช้ประโยชน์จากคำอธิบายประกอบในภาพสเตลลาร์ เราสามารถประเมินลักษณะใบหน้าแบบไบนารีเหล่านี้ได้
ทำหน้าที่เป็นตัววัดในการกำหนดขอบเขตความไวของโมเดลต่อรูปภาพ ต่างๆ ของบุคคลคน เดียวกัน ส่งเสริมโมเดลที่เอกลักษณ์ของวัตถุได้รับการจับภาพอย่างดีอย่างสม่ำเสมอ โดยไม่คำนึงถึง การเปลี่ยนแปลง ที่ไม่เกี่ยวข้องกับภาพของอินพุต (เช่น สภาพแสง ท่าทางของวัตถุ)
เพื่อให้บรรลุเป้าหมายนี้ SIS จำเป็นต้องเข้าถึงภาพถ่ายของมนุษย์หลายภาพ (เงื่อนไขที่ตรงตามชุดข้อมูลของ Stellar จากการออกแบบ) และเป็นตัวชี้วัดการประเมินเดียวของเราที่มีข้อกำหนดที่เข้มงวดมากขึ้น
เราแนะนำหน่วยวัดเฉพาะทางและตีความได้เพื่อประเมินประเด็นสำคัญสองประการของการจัดตำแหน่งระหว่างรูปภาพและพร้อมท์ วัตถุเป็นตัวแทนของความซื่อสัตย์และความจงรักภักดีของความสัมพันธ์ที่ปรากฎ
ประเมินความสำเร็จในการนำเสนอการโต้ตอบระหว่างวัตถุพร้อมท์ที่ต้องการบนรูปภาพที่สร้างขึ้น เมื่อพิจารณาถึงความยากลำบากของแม้แต่โมเดล Scene Graph Generation (SGG) เฉพาะทางในการทำความเข้าใจความสัมพันธ์ทางสายตา ตัวชี้วัดนี้จะแนะนำข้อมูลเชิงลึกอันทรงคุณค่าเฉพาะท้องถิ่นเกี่ยวกับความสามารถของโมเดลเฉพาะบุคคลในการถ่ายทอดความสัมพันธ์ที่ได้รับพร้อมท์อย่างเที่ยงตรง


