VideoX
1.0.0
นี่คือชุดผลงานการทำความเข้าใจวิดีโอของเรา
SeqTrack (
@CVPR'23): SeqTrack: ลำดับการเรียนรู้ตามลำดับสำหรับการติดตามวัตถุแบบภาพ
X-CLIP (
@ECCV'22 Oral): การขยายโมเดลภาษา-รูปภาพที่ได้รับการฝึกล่วงหน้าสำหรับการจดจำวิดีโอทั่วไป
MS-2D-TAN (
@TPAMI'21): เครือข่ายที่อยู่ติดกันชั่วคราว 2 มิติหลายระดับสำหรับการแปลช่วงเวลาด้วยภาษาธรรมชาติ
2D-TAN (
@AAAI'20): การเรียนรู้ 2D Temporal Adjacent Networks สำหรับการแปลช่วงเวลาด้วยภาษาธรรมชาติ
รับสมัครนักศึกษาฝึกงานด้านการวิจัยที่มีทักษะการเขียนโค้ดที่แข็งแกร่ง: [email protected] | [email protected]
เมษายน 2023: โค้ดสำหรับ SeqTrack เปิดตัวแล้ว
กุมภาพันธ์ 2023: SeqTrack ได้รับการยอมรับใน CVPR'23
ก.ย. 2022: ขณะนี้ X-CLIP ได้รวมเข้ากับระบบแล้ว
ส.ค. 2022: โค้ดสำหรับ X-CLIP เปิดตัวแล้ว
ก.ค. 2022: X-CLIP ได้รับการยอมรับจาก ECCV'22 ในรูปแบบช่องปาก
ต.ค. 2021: เปิดตัวโค้ดสำหรับ MS-2D-TAN แล้ว
กันยายน 2021: MS-2D-TAN ได้รับการยอมรับจาก TPAMI'21
ธันวาคม 2019: รหัสสำหรับ 2D-TAN เปิดตัวแล้ว
พฤศจิกายน 2019: 2D-TAN ได้รับการยอมรับจาก AAAI'20
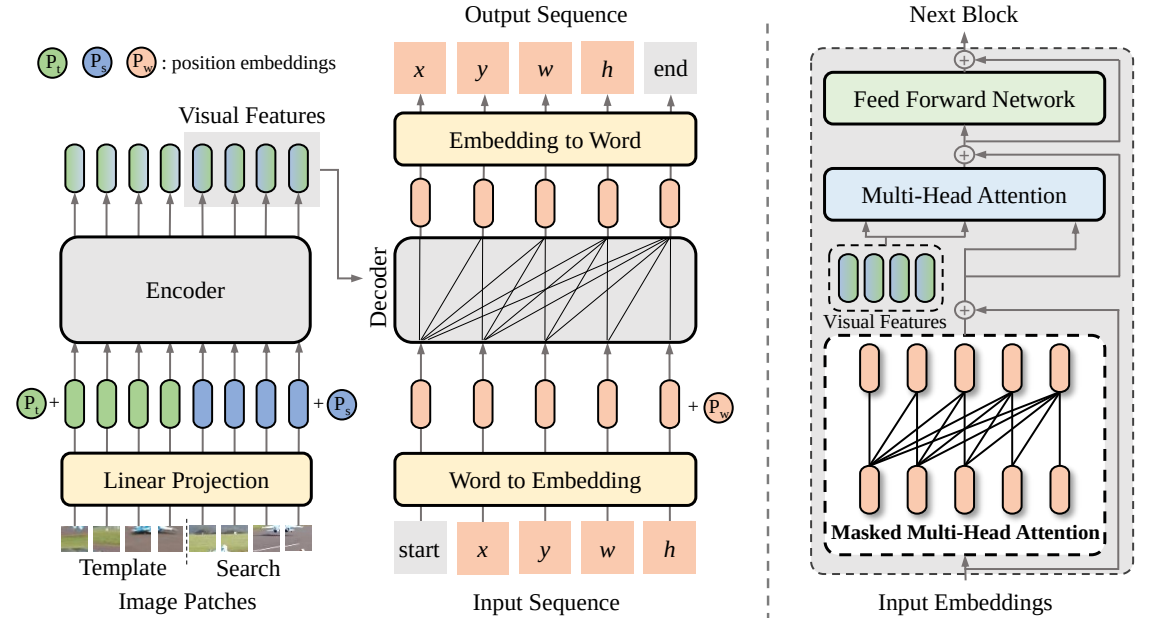
ในบทความนี้ เราเสนอกรอบการเรียนรู้แบบเรียงลำดับต่อลำดับใหม่สำหรับการติดตามด้วยภาพ ซึ่งมีชื่อว่า SeqTrack มันใช้การติดตามด้วยภาพเป็นปัญหาในการสร้างลำดับ ซึ่งคาดการณ์กรอบขอบเขตของวัตถุในลักษณะการถดถอยอัตโนมัติ SeqTrack ใช้สถาปัตยกรรมหม้อแปลงตัวเข้ารหัส-ตัวถอดรหัสแบบธรรมดาเท่านั้น ตัวเข้ารหัสจะแยกลักษณะการมองเห็นด้วยหม้อแปลงสองทิศทาง ในขณะที่ตัวถอดรหัสจะสร้างลำดับของค่า Bounding Box แบบถดถอยอัตโนมัติด้วยตัวถอดรหัสเชิงสาเหตุ ฟังก์ชันการสูญเสียเป็นเอนโทรปีข้ามแบบธรรมดา กระบวนทัศน์การเรียนรู้แบบลำดับดังกล่าวไม่เพียงแต่ทำให้กรอบการติดตามง่ายขึ้น แต่ยังให้ประสิทธิภาพที่แข่งขันได้บนเกณฑ์มาตรฐานต่างๆ อีกด้วย
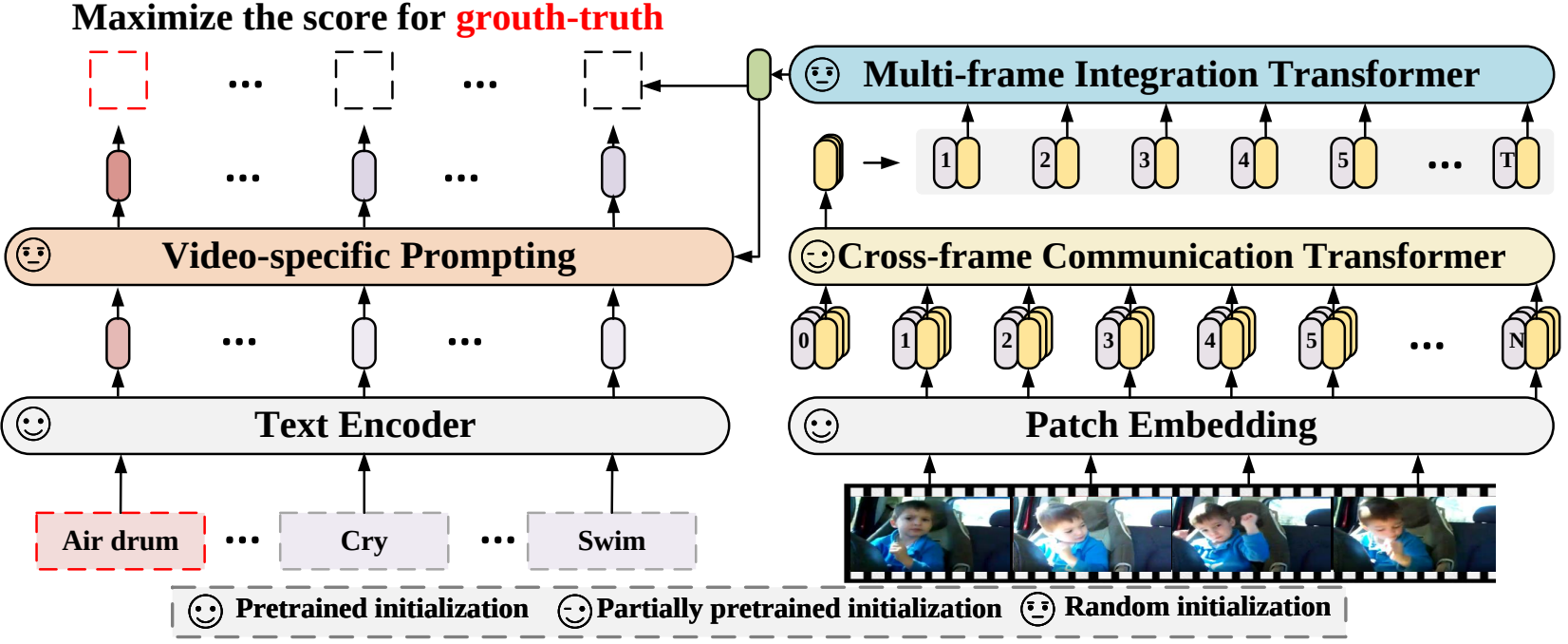
ในบทความนี้ เราเสนอกรอบการทำงานการจดจำวิดีโอใหม่ซึ่งจะปรับโมเดลภาษาและรูปภาพที่ได้รับการฝึกมาล่วงหน้าเพื่อการจดจำวิดีโอ โดยเฉพาะอย่างยิ่ง เพื่อเก็บข้อมูลชั่วคราว เราเสนอกลไกความสนใจแบบข้ามเฟรมที่แลกเปลี่ยนข้อมูลข้ามเฟรมอย่างชัดเจน ในการใช้ข้อมูลข้อความในหมวดหมู่วิดีโอ เราได้ออกแบบเทคนิคการแจ้งเตือนเฉพาะวิดีโอซึ่งสามารถให้ผลการแสดงข้อความที่เลือกปฏิบัติในระดับอินสแตนซ์ได้ การทดลองอย่างกว้างขวางแสดงให้เห็นว่าแนวทางของเรามีประสิทธิผลและสามารถนำไปประยุกต์ใช้กับสถานการณ์การจดจำวิดีโอต่างๆ ได้ รวมถึงการควบคุมดูแลอย่างเต็มที่ ถ่ายไม่กี่ครั้ง และถ่ายเป็นศูนย์
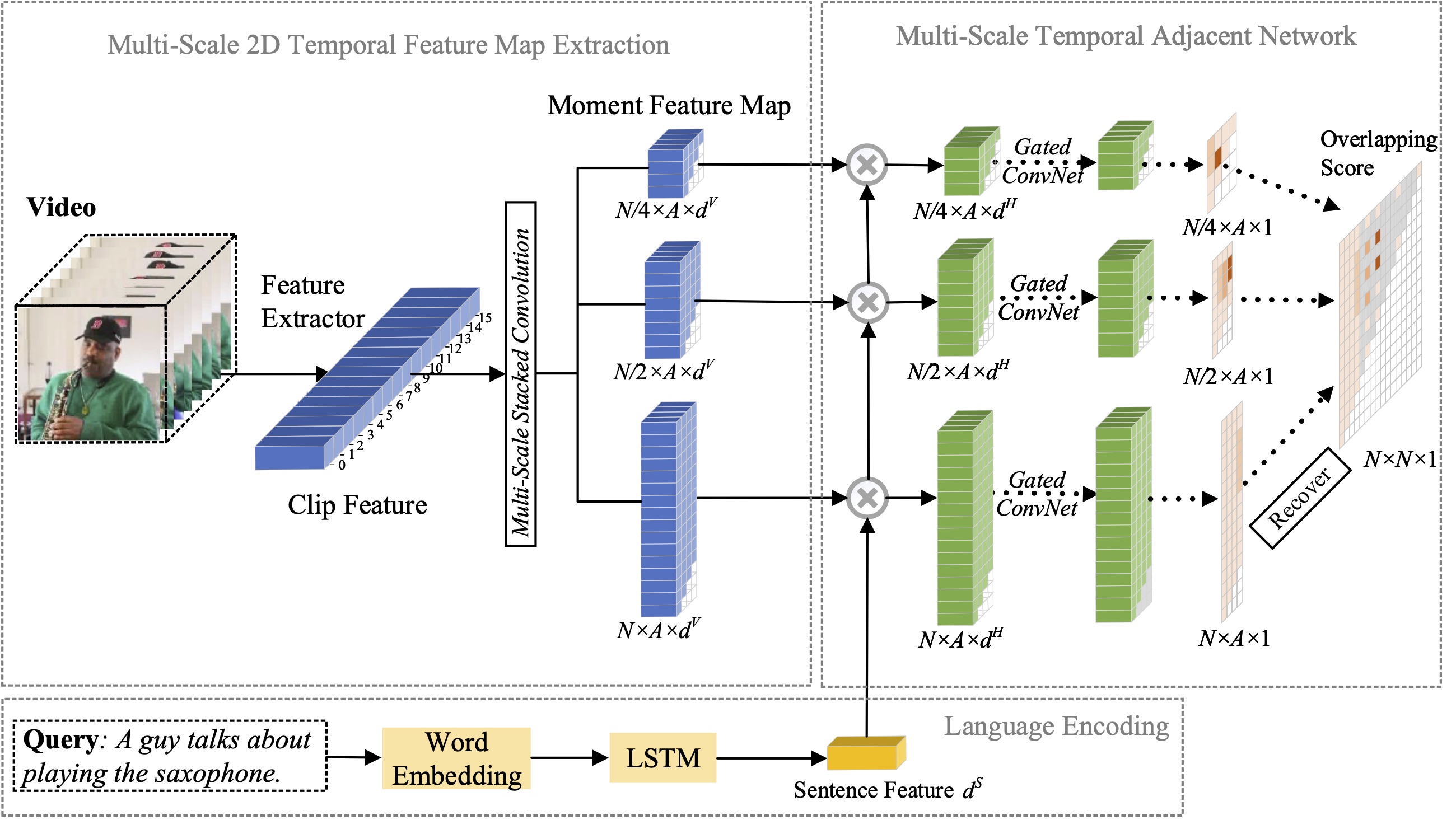
ในบทความนี้ เราศึกษาปัญหาของการแปลช่วงเวลาด้วยภาษาธรรมชาติ และเสนอการขยายวิธี 2D-TAN ที่เรานำเสนอก่อนหน้านี้ไปเป็นเวอร์ชันหลายสเกล แนวคิดหลักคือการดึงช่วงเวลาจากแผนที่ชั่วคราวสองมิติที่มีมาตราส่วนของเวลาที่แตกต่างกัน ซึ่งถือว่าผู้สมัครช่วงเวลาที่อยู่ติดกันเป็นบริบททางเวลา เวอร์ชันขยายสามารถเข้ารหัสความสัมพันธ์ชั่วคราวที่อยู่ติดกันในระดับต่างๆ ได้ ในขณะที่เรียนรู้คุณลักษณะที่เลือกปฏิบัติสำหรับการจับคู่ช่วงเวลาของวิดีโอกับนิพจน์ที่อ้างอิง แบบจำลองของเราได้รับการออกแบบอย่างเรียบง่ายและบรรลุประสิทธิภาพการแข่งขันเมื่อเปรียบเทียบกับวิธีการอันล้ำสมัยบนชุดข้อมูลการวัดประสิทธิภาพสามชุด
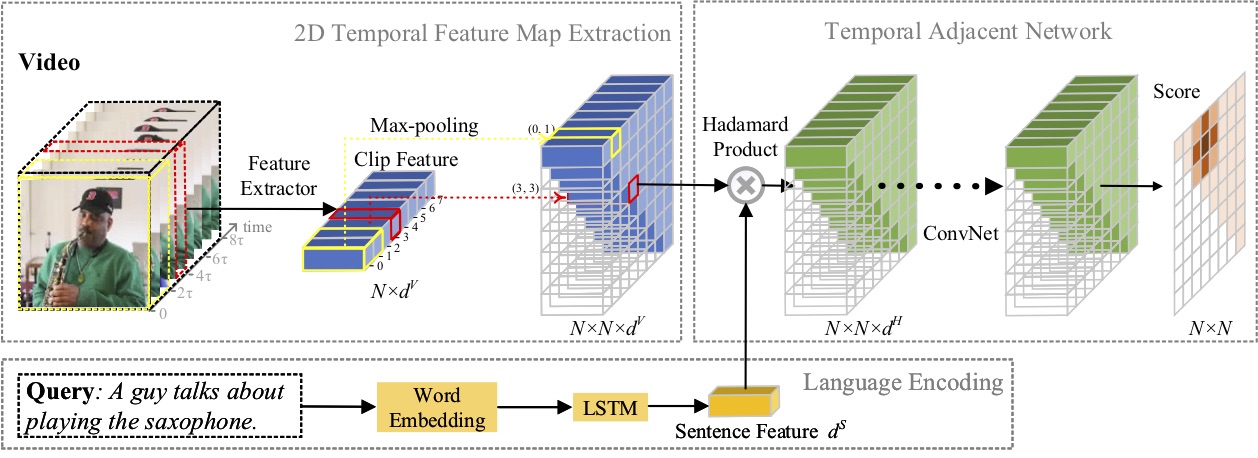
ในบทความนี้ เราศึกษาปัญหาของการแปลช่วงเวลาด้วยภาษาธรรมชาติ และเสนอวิธี 2D Temporal Adjacent Networks (2D-TAN) แบบใหม่ แนวคิดหลักคือการดึงข้อมูลช่วงเวลาหนึ่งบนแผนที่ชั่วคราวสองมิติ ซึ่งถือว่าผู้สมัครช่วงเวลาที่อยู่ติดกันเป็นบริบททางโลก 2D-TAN มีความสามารถในการเข้ารหัสความสัมพันธ์ชั่วคราวที่อยู่ติดกัน ในขณะที่เรียนรู้คุณลักษณะการเลือกปฏิบัติสำหรับการจับคู่ช่วงเวลาของวิดีโอกับการแสดงออกที่อ้างอิง แบบจำลองของเราได้รับการออกแบบอย่างเรียบง่ายและบรรลุประสิทธิภาพการแข่งขันเมื่อเปรียบเทียบกับวิธีการอันล้ำสมัยบนชุดข้อมูลการวัดประสิทธิภาพสามชุด
@InProceedings{SeqTrack, title={SeqTrack: ลำดับการเรียนรู้ตามลำดับสำหรับ Visual Object Tracking}, author={Chen, Xin และ Peng, Houwen และ Wang, Dong และ Lu, Huchuan และ Hu, Han}, booktitle={CVPR}, year={2023}}@InProceedings{XCLIP, title={การขยายภาษา-รูปภาพที่ฝึกไว้ล่วงหน้าสำหรับวิดีโอทั่วไป Recognition}, ผู้แต่ง={Ni, Bolin และ Peng, Houwen และ Chen, Minghao และ Zhang, Songyang และ Meng, Gaofeng และ Fu, Jianlong และ Xiang, Shiming และ Ling, Haibin}, booktitle={European Conference on Computer Vision (ECCV) }, year={2022}}@InProceedings{Zhang2021MS2DTAN,
ผู้แต่ง = {จาง, ซ่งหยางและเผิง, โหวเหวินและฝู, เจียนหลงและหลู่, อี้จวนและลั่ว, เจียป๋อ},
title = {เครือข่ายที่อยู่ติดกันชั่วคราว 2 มิติหลายระดับสำหรับการแปลช่วงเวลาด้วยภาษาธรรมชาติ},
ชื่อหนังสือ = {TPAMI},
ปี = {2021}}@อยู่ระหว่างดำเนินการ{2DTAN_2020_AAAI,
ผู้แต่ง = {จาง, ซ่งหยางและเผิง, โหวเหวินและฝู, เจียนหลงและหลัว, เจียป๋อ},
title = {การเรียนรู้ 2D Temporal Adjacent Networks forMoment Localization ด้วยภาษาธรรมชาติ},
ชื่อหนังสือ = {AAAI},
ปี = {2020}}ใบอนุญาตภายใต้ใบอนุญาต MIT


