ffhq dataset
1.0.0

Flickr-Faces-HQ (FFHQ) คือชุดข้อมูลภาพคุณภาพสูงของใบหน้ามนุษย์ ซึ่งเดิมสร้างขึ้นเพื่อเป็นเกณฑ์มาตรฐานสำหรับเครือข่าย generative adversarial (GAN):
สถาปัตยกรรมตัวสร้างตามสไตล์สำหรับเครือข่ายปฏิปักษ์ทั่วไป
เทโร การ์ราส (วิเดีย), ซามูลี เลน (วิเดีย), ติโม ไอลา (วิเดีย)
https://arxiv.org/abs/1812.04948
ชุดข้อมูลประกอบด้วยรูปภาพ PNG คุณภาพสูง 70,000 รูปที่ความละเอียด 1024×1024 และมีการเปลี่ยนแปลงอย่างมากในแง่ของอายุ ชาติพันธุ์ และพื้นหลังรูปภาพ นอกจากนี้ยังมีการครอบคลุมอุปกรณ์เสริมที่ดี เช่น แว่นตา แว่นกันแดด หมวก ฯลฯ รูปภาพถูกรวบรวมข้อมูลจาก Flickr ซึ่งสืบทอดอคติทั้งหมดของเว็บไซต์นั้น และจัดแนวและครอบตัดโดยอัตโนมัติโดยใช้ dlib รวบรวมเฉพาะรูปภาพภายใต้ใบอนุญาตที่อนุญาตเท่านั้น มีการใช้ฟิลเตอร์อัตโนมัติหลายตัวเพื่อตัดฉาก และสุดท้าย Amazon Mechanical Turk ก็ถูกใช้เพื่อลบรูปปั้น ภาพวาด หรือรูปถ่ายเป็นครั้งคราวออก
โปรดทราบว่าชุดข้อมูลนี้ไม่ได้มีไว้สำหรับและไม่ควรใช้สำหรับการพัฒนาหรือปรับปรุงเทคโนโลยีการจดจำใบหน้า สำหรับการสอบถามข้อมูลทางธุรกิจ โปรดเยี่ยมชมเว็บไซต์ของเราและส่งแบบฟอร์ม: NVIDIA Research Licensing
ภาพแต่ละภาพได้รับการเผยแพร่ใน Flickr โดยผู้เขียนที่เกี่ยวข้องภายใต้ Creative Commons BY 2.0, Creative Commons BY-NC 2.0, Public Domain Mark 1.0, Public Domain CC0 1.0 หรือใบอนุญาตการทำงานของรัฐบาลสหรัฐฯ ใบอนุญาตทั้งหมดเหล่านี้อนุญาตให้นำไป ใช้ฟรี แจกจ่ายซ้ำ และดัดแปลงเพื่อวัตถุประสงค์ที่ไม่ใช่เชิงพาณิชย์ อย่างไรก็ตาม บางส่วนจำเป็นต้องให้ เครดิตที่เหมาะสม กับผู้เขียนต้นฉบับ รวมทั้ง ระบุการเปลี่ยนแปลงใดๆ ที่เกิดขึ้นกับรูปภาพ ใบอนุญาตและผู้แต่งต้นฉบับของแต่ละภาพระบุไว้ในข้อมูลเมตา
ชุดข้อมูล (รวมถึงข้อมูลเมตา JSON สคริปต์ดาวน์โหลด และเอกสารประกอบ) มีให้ใช้งานภายใต้ใบอนุญาต Creative Commons BY-NC-SA 4.0 โดย NVIDIA Corporation คุณสามารถ ใช้ แจกจ่ายซ้ำ และดัดแปลงเพื่อวัตถุประสงค์ที่ไม่ใช่เชิงพาณิชย์ ตราบใดที่คุณ (ก) ให้เครดิตที่เหมาะสมโดย การอ้างอิงเอกสารของเรา (ข) ระบุการเปลี่ยนแปลงใด ๆ ที่คุณได้ทำ และ (ค) แจกจ่ายผลงานลอกเลียนแบบใด ๆ ภายใต้ใบอนุญาตเดียวกัน
ข้อมูลทั้งหมดโฮสต์บน Google Drive:
| เส้นทาง | ขนาด | ไฟล์ | รูปแบบ | คำอธิบาย |
|---|---|---|---|---|
| ffhq-ชุดข้อมูล | 2.56 เทราไบต์ | 210,014 | โฟลเดอร์หลัก | |
| ├ ffhq-ชุดข้อมูล-v2.json | 255 เมกะไบต์ | 1 | เจสัน | ข้อมูลเมตารวมถึงข้อมูลลิขสิทธิ์ URL ฯลฯ |
| ├ รูปภาพ1024x1024 | 89.1GB | 70,000 | PNG | จัดตำแหน่งและครอบตัดรูปภาพที่ 1024×1024 |
| ├ ภาพขนาดย่อ 128x128 | 1.95GB | 70,000 | PNG | ภาพขนาดย่อที่ 128×128 |
| ├ ในภาพป่า | 955GB | 70,000 | PNG | ภาพต้นฉบับจาก Flickr |
| ├ tfrecords | 273GB | 9 | ทีเฟรดคอร์ด | ข้อมูลความละเอียดหลายสำหรับ StyleGAN และ StyleGAN2 |
| └ รหัสไปรษณีย์ | 1.28 เทราไบต์ | 4 | รหัสไปรษณีย์ | เนื้อหาของแต่ละโฟลเดอร์เป็นไฟล์ ZIP |
สถิติระดับสูง:
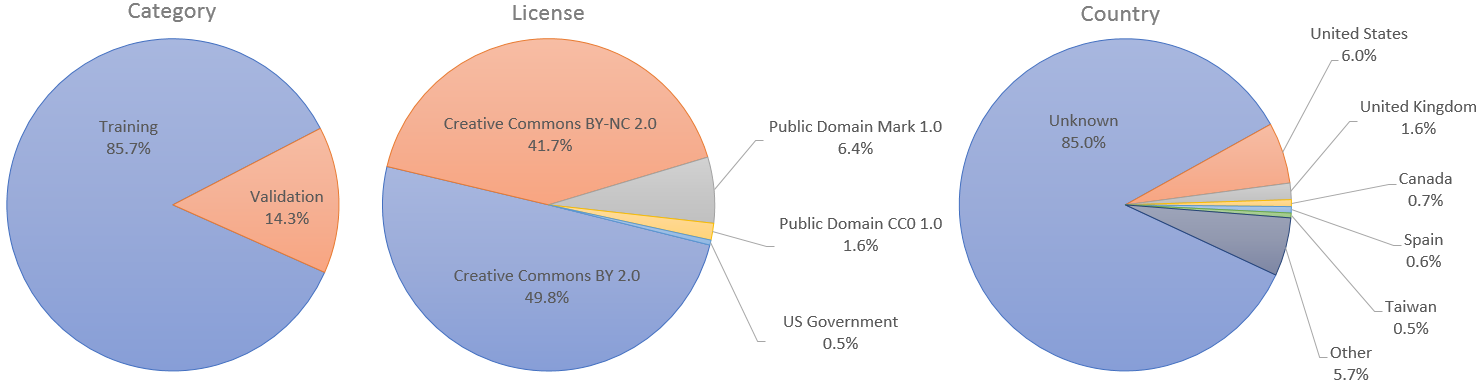
สำหรับกรณีการใช้งานที่ต้องมีชุดการฝึกอบรมและการตรวจสอบแยกกัน เราได้แต่งตั้งรูปภาพ 60,000 ภาพแรกเพื่อใช้ในการฝึกอบรม และอีก 10,000 ภาพที่เหลือสำหรับการตรวจสอบ อย่างไรก็ตาม ในรายงาน StyleGAN เราใช้รูปภาพทั้งหมด 70,000 รูปในการฝึกอบรม
เราได้ตรวจสอบอย่างชัดเจนแล้วว่าไม่มีรูปภาพที่ซ้ำกันในชุดข้อมูล อย่างไรก็ตาม โปรดทราบว่าโฟลเดอร์ in-the-wild อาจมีสำเนาของรูปภาพเดียวกันหลายชุด ในกรณีที่เราแยกใบหน้าที่แตกต่างกันหลายหน้าออกจากรูปภาพเดียวกัน
คุณสามารถดึงข้อมูลได้โดยตรงจาก Google Drive หรือใช้สคริปต์ดาวน์โหลดที่ให้มา สคริปต์ทำให้สิ่งต่าง ๆ ง่ายขึ้นมากโดยการดาวน์โหลดไฟล์ที่ร้องขอทั้งหมดโดยอัตโนมัติ ตรวจสอบการตรวจสอบ ลองแต่ละไฟล์ซ้ำหลายครั้งเมื่อมีข้อผิดพลาด และใช้การเชื่อมต่อพร้อมกันหลายรายการเพื่อเพิ่มแบนด์วิธให้สูงสุด
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
สคริปต์ยังทำหน้าที่เป็นการใช้งานอ้างอิงของโครงร่างอัตโนมัติที่เราใช้ในการจัดแนวและครอบตัดรูปภาพ เมื่อคุณดาวน์โหลดรูปภาพในป่าด้วย python download_ffhq.py --wilds แล้ว คุณสามารถเรียกใช้ python download_ffhq.py --align เพื่อสร้างแบบจำลองที่แน่นอนของรูปภาพขนาด 1024×1024 ที่จัดเรียงไว้โดยใช้ตำแหน่งจุดสังเกตบนใบหน้าที่รวมอยู่ในข้อมูลเมตา .
หากต้องการสร้างชุดข้อมูล "unaligned FFHQ" ที่ใช้ในรายงาน Alias-Free Generative Adversarial Networks ให้ใช้ตัวเลือกต่อไปนี้:
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
ไฟล์ ffhq-dataset-v2.json มีข้อมูลต่อไปนี้สำหรับแต่ละรูปภาพในรูปแบบที่เครื่องอ่านได้:
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
เราขอขอบคุณ Jaakko Lehtinen, David Luebke และ Tuomas Kynkäänniemi สำหรับการสนทนาเชิงลึกและความคิดเห็นที่เป็นประโยชน์ Janne Hellsten, Tero Kuosmanen และ Pekka Jänis สำหรับโครงสร้างพื้นฐานการประมวลผลและช่วยเหลือในการเผยแพร่โค้ด
นอกจากนี้เรายังขอขอบคุณ Vahid Kazemi และ Josephine Sullivan สำหรับงานการตรวจจับใบหน้าอัตโนมัติและการจัดตำแหน่งที่ช่วยให้เราสามารถรวบรวมข้อมูลได้ตั้งแต่แรก:
การจัดตำแหน่งใบหน้าหนึ่งมิลลิวินาทีด้วยชุดต้นไม้การถดถอย
วาฮิด คาเซมิ, โจเซฟีน ซัลลิแวน
โปรค ซีพีอาร์ 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Millisecond_Face_2014_CVPR_paper.pdf
เมื่อรวบรวมข้อมูล เราระมัดระวังในการรวมเฉพาะภาพถ่ายที่ตั้งใจให้นำไปใช้ฟรีและแจกจ่ายซ้ำโดยผู้เขียนที่เกี่ยวข้องเท่านั้น เท่าที่เราทราบ อย่างไรก็ตาม เรามุ่งมั่นที่จะปกป้องความเป็นส่วนตัวของบุคคลที่ไม่ต้องการให้รวมรูปภาพของตนไว้ด้วย
หากต้องการทราบว่ารูปภาพของคุณรวมอยู่ในชุดข้อมูล Flickr-Faces-HQ หรือไม่ โปรดคลิกลิงก์นี้เพื่อค้นหาชุดข้อมูลด้วยชื่อผู้ใช้ Flickr ของคุณ
หากต้องการลบรูปภาพของคุณออกจากชุดข้อมูล Flickr-Faces-HQ:
no_cv เพื่อระบุว่าคุณไม่ต้องการให้ใช้เพื่อการวิจัยด้านการมองเห็นด้วยคอมพิวเตอร์None (สงวนลิขสิทธิ์) หรือใบอนุญาตครีเอทีฟคอมมอนส์ใดๆ ด้วย NoDerivs เพื่อระบุว่าคุณไม่ต้องการให้แจกจ่ายซ้ำ


