คู่มือการแพร่กระจายแบบครบวงจรที่เสถียร - จาก Noob ไปจนถึงผู้เชี่ยวชาญ
ฉันเริ่มสนใจการใช้ SD เพื่อสร้างภาพสำหรับการใช้งานทางทหาร ทรัพยากรส่วนใหญ่นำมาจากบอร์ด NSFW ของ 4chan เนื่องจากอานนท์ใช้ SD เพื่อสร้างเฮ็นไท สิ่งที่น่าสนใจคือ Canonical SD WebUI มีฟังก์ชันการทำงานในตัวพร้อมบอร์ดรูปภาพอนิเมะ/เฮ็นไท... หนึ่งในกรณีการใช้งาน SD แรกๆ หลังจากที่ DALL-E สร้างอนิเมะสาว ๆ ดังนั้นการข้ามไปยังเฮ็นไทจึงไม่น่าแปลกใจ
อย่างไรก็ตาม เทคนิคจากสิ่งแปลกประหลาดเหล่านี้สามารถนำไปใช้กับแอพพลิเคชั่นที่หลากหลาย โดยเฉพาะอย่างยิ่ง LoRA ซึ่งเหมือนกับเครื่องปรับจูนโมเดล แนวคิดคือการทำงานร่วมกับ LoRA เฉพาะ (เช่น ยานพาหนะทางทหาร เครื่องบิน อาวุธ ฯลฯ) เพื่อสร้างข้อมูลภาพสังเคราะห์สำหรับการฝึกโมเดลการมองเห็น การฝึกอบรม LoRA ใหม่ที่มีประโยชน์ก็น่าสนใจเช่นกัน ต่อมาอาจรวมถึงการทาสีเพื่อก่อกวน
ข้อสงวนสิทธิ์และแหล่งที่มา
Every link here may contain NSFW content, as most of the cutting-edge work on SD and LoRAs is with porn or hentai. So, please be wary when you are working with these resources. ALSO, Rentry.org pages are the main resources linked to in this guide. If any of the rentry pages do not work, change the .org to .co and the link should work. Otherwise, use the Wayback machine.
-ทีพี
เล่นกับมัน!
คุณสามารถทำอะไรกับ SD ได้จริง? Huggingface และคนอื่นๆ มีแอปในเบราว์เซอร์สำหรับคุณ เล่นกับพวกเขาเพื่อดูพลัง! สิ่งที่เราจะทำในคู่มือนี้คือรับ WebUI แบบเต็มและขยายได้เพื่อให้เราทำอะไรก็ได้ที่เราต้องการ
- สนามเด็กเล่น SD ข้อความ Huggingface เป็นรูปภาพ
- แอพ Dreamstudio แปลงข้อความเป็นรูปภาพ SD
- แอพ Dezgo ข้อความเป็นรูปภาพ SD
- เปลี่ยนรูปภาพ Huggingface เป็น Image SD Playground
- สนามเด็กเล่นในการวาดภาพ Huggingface
สารบัญ
- ข้อมูลพื้นฐานเกี่ยวกับ WebUI
- ตั้งค่าการใช้งาน GPU ภายใน
- การตั้งค่าลินุกซ์
- เจาะลึกยิ่งขึ้น
- พร้อมท์
- โมเดล NovelAI
- โลรา
- เล่นกับนางแบบ
- VAE
- ใส่มันทั้งหมดเข้าด้วยกัน
- กระบวนการ SD ทั่วไป
- กำลังบันทึกคำแนะนำ
- การตั้งค่า txt2img
- การสร้างรูปภาพที่สร้างไว้ก่อนหน้านี้ใหม่
- การแก้ไขปัญหาข้อผิดพลาด
- ได้รับความสะดวกสบาย
- การทดสอบ
- WebUI ขั้นสูง
- แก้ไขด่วน
- เอ็กซ์ฟอร์เมอร์
- Img2Img
- การวาดภาพ
- บริการพิเศษ
- คอนโทรลเน็ตส์
- การสร้างสิ่งใหม่ (WIP)
- การควบรวมกิจการด่านตรวจ
- การฝึกอบรม LoRA
- การฝึกอบรมโมเดลใหม่
- การตั้งค่า Google Colab (WIP)
- กลางการเดินทาง
- พารามิเตอร์ MJ
- MJ พรอมต์ขั้นสูง
- ดรีมสตูดิโอ (WIP)
- ฝูงชนที่มีเสถียรภาพ (WIP)
- ดรีมบูธ (WIP)
- การแพร่กระจายวิดีโอ (WIP)
ข้อมูลพื้นฐานเกี่ยวกับ WebUI
มันค่อนข้างจะยากลำบากในการเข้าถึงสิ่งนี้... แต่ 4channers ทำได้ดีมากในการทำให้สิ่งนี้เข้าถึงได้ ด้านล่างนี้เป็นขั้นตอนที่ฉันดำเนินการในแง่ที่ง่ายที่สุด ความตั้งใจของคุณคือให้ Stable Diffusion WebUI (สร้างด้วย Gradio) ทำงานภายในเครื่อง เพื่อให้คุณสามารถเริ่มพร้อมท์และสร้างรูปภาพได้
ตั้งค่าการใช้งาน GPU ภายในเครื่อง
เราจะทำการตั้งค่า Google Colab Pro ในภายหลัง เพื่อให้เราสามารถเรียกใช้ SD บนอุปกรณ์ใดก็ได้ทุกที่ที่เราต้องการ แต่ก่อนอื่น เรามาตั้งค่า WebUI บนพีซีกันดีกว่า คุณต้องมี RAM 16GB, GPU ที่มี VRAM 2GB, Windows 7+ และพื้นที่ดิสก์ 20+GB
- ทำตามคำแนะนำการตั้งค่าเริ่มต้นให้เสร็จสิ้น
- ฉันทำตามขั้นตอนนี้จนถึงขั้นตอนที่ 7 หลังจากนั้นมันก็เข้าสู่เนื้อหาเฮ็นไท
- ขั้นตอนที่ 3 ใช้เวลา 15-45 นาทีสำหรับความเร็วอินเทอร์เน็ตโดยเฉลี่ย เนื่องจากแต่ละรุ่นมีขนาด 5+ GB
- ขั้นตอนที่ 7 อาจใช้เวลานานกว่าครึ่งชั่วโมงและอาจดูเหมือน "ค้าง" ใน CLI
- ในขั้นตอนที่ 3 ฉันดาวน์โหลด SD1.5 ไม่ใช่เวอร์ชัน 2.x เนื่องจาก 1.5 ให้ผลลัพธ์ที่ดีกว่ามาก
- CivitAI มี SD รุ่นทั้งหมด; มันเหมือนกับ HuggingFace แต่สำหรับ SD โดยเฉพาะ
- ตรวจสอบว่า WebUI ใช้งานได้
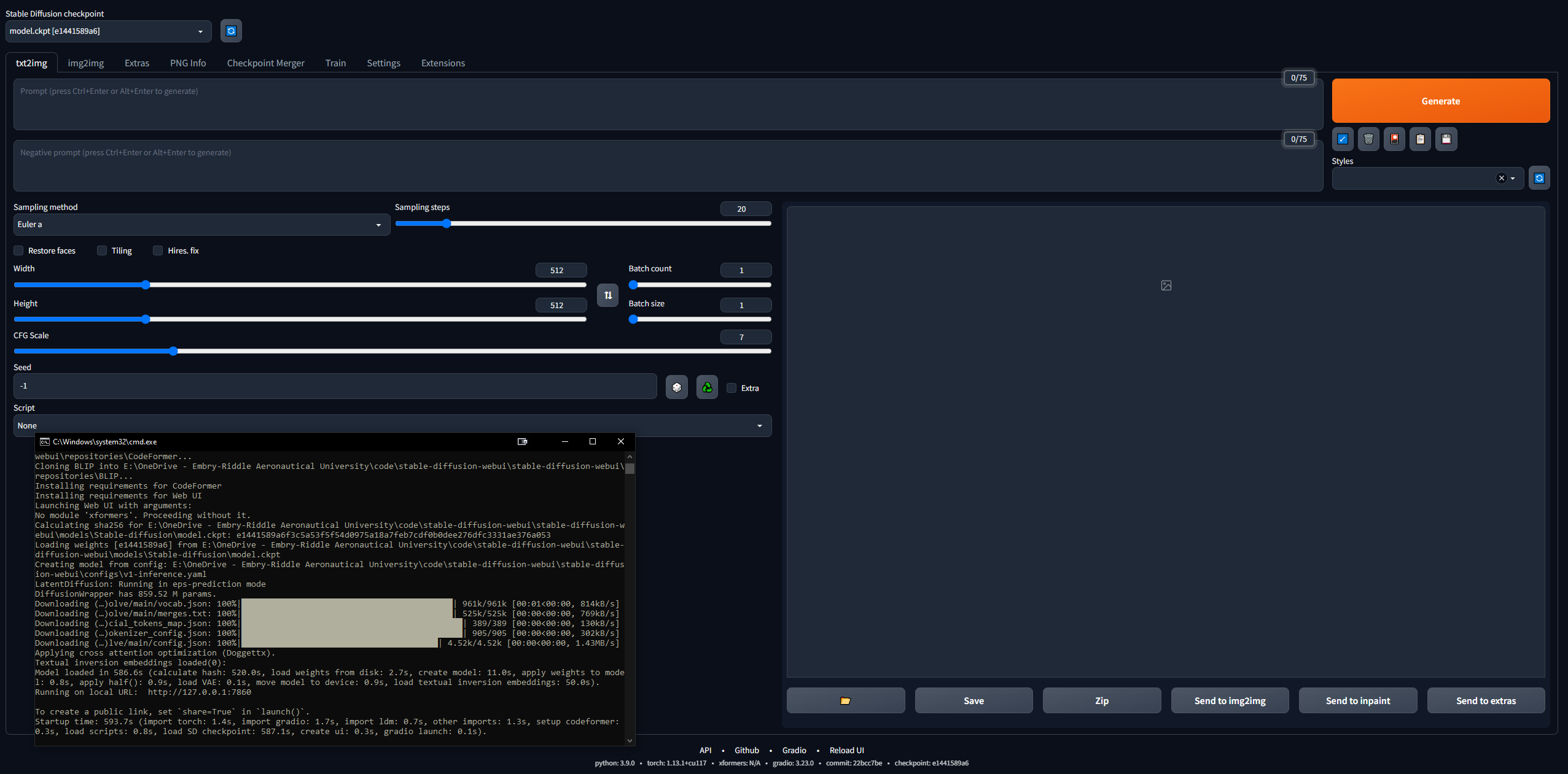
- คัดลอก URL ที่เอาต์พุต CLI เมื่อเสร็จแล้ว เช่น
127.0.0.1:7860 ( อย่า ใช้ Ctrl + C เพราะคำสั่งนี้สามารถปิด CLI ได้) - วางลงในเบราว์เซอร์และ voila; ลองใช้พรอมต์แล้วคุณก็จะเข้าสู่การแข่งขัน
- รูปภาพจะถูกบันทึกโดยอัตโนมัติเมื่อสร้างไปที่
stable-diffusion-webuioutputstxt2img-images<date>
- โปรดจำไว้ว่า หากต้องการอัปเดต เพียงเปิด CLI ในโฟลเดอร์ stable-diffusion-webui แล้วป้อนคำสั่ง
git pull
การตั้งค่าลินุกซ์
ไม่ต้องสนใจสิ่งนี้เลยหากคุณมี Windows ฉันจัดการเพื่อให้มันทำงานบน Linux ได้เช่นกัน แม้ว่ามันจะซับซ้อนกว่าเล็กน้อยก็ตาม ฉันเริ่มต้นด้วยการทำตามคำแนะนำนี้ แต่เขียนได้ค่อนข้างไม่ดี ดังนั้นด้านล่างนี้คือขั้นตอนที่ฉันดำเนินการเพื่อให้มันรันใน Linux ฉันใช้ Linux Mint 20 ซึ่งเป็นการแจกจ่าย Ubuntu 20
- เริ่มต้นด้วยการโคลน repo ของ webui:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - รับโมเดล SD (เช่น SD 1.5 เหมือนในส่วนก่อนหน้า)
- วางไฟล์ model ckpt ลงใน
stable-diffusion-webui/models/Stable-diffusion - ดาวน์โหลด Python (หากคุณยังไม่มี):
sudo apt install python3 python3-pip python3-virtualenv wget git - และ WebUI นั้นมีความเฉพาะเจาะจงมาก ดังนั้นเราจึงจำเป็นต้องติดตั้ง Conda ซึ่งเป็นผู้จัดการสภาพแวดล้อมเสมือน เพื่อทำงานภายใน:
wget https://repo.anaconda.com/miniconda/Minconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- ตอนนี้สร้างสภาพแวดล้อม:
conda create --name sdwebui python=3.10.6 - เปิดใช้งานสภาพแวดล้อม:
conda activate sdwebui - นำทางไปยังโฟลเดอร์ WebUI ของคุณแล้วพิมพ์
./webui.sh - ควรดำเนินการสักครู่จนกว่าคุณจะได้รับข้อผิดพลาดเกี่ยวกับการไม่สามารถเข้าถึง CUDA/GPU ของคุณได้... ไม่เป็นไร เพราะเป็นขั้นตอนต่อไปของเรา
- เริ่มต้นด้วยการล้างไดรเวอร์ Nvidia ที่มีอยู่:
sudo apt update
sudo apt purge *nvidia*
- ตอนนี้ ต่อไปนี้เป็นบางส่วนจากคู่มือนี้ ดูว่าเครื่อง Linux ของคุณมี GPU ใดบ้าง (วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการเปิดแอป Driver Manager และ GPU ของคุณจะแสดงอยู่ในรายการ แต่มีหลายวิธี เพียงแค่ Google เท่านั้น)
- ไปที่หน้านี้แล้วคลิก "สาขาฟีเจอร์ใหม่ล่าสุด" ใต้ Linux x86_64 (สำหรับฉันคือ 530.xx.xx)
- คลิกแท็บ "ผลิตภัณฑ์ที่รองรับ" และ Ctrl + F เพื่อค้นหา GPU ของคุณ หากมีอยู่ในรายการ ให้ดำเนินการต่อ หรือถอยออกไปแล้วลองใช้ "เวอร์ชันสาขาการผลิตล่าสุด"; สังเกตตัวเลข เช่น 530
- ในเทอร์มินัล ให้พิมพ์:
sudo add-apt-repository ppa:graphics-drivers/ppa - อัปเดตด้วยการ
sudo apt-get update - เปิดแอป Driver Manager แล้วคุณควรเห็นรายการเหล่านั้น อย่าเลือกอันที่แนะนำ (เช่น nvidia-driver-530-open) เลือกอันที่แน่นอนจากรุ่นก่อนหน้า (เช่น nvidia-driver-530) และใช้การเปลี่ยนแปลง หรือติดตั้งในเทอร์มินัลด้วย
sudo apt-get install nvidia-driver-530 - ณ จุดนี้ คุณควรได้รับป๊อปอัปผ่าน CLI ของคุณเกี่ยวกับ Secure Boot โดยขอรหัสผ่าน 8 หลัก: ตั้งค่าและจดบันทึกไว้
- รีบูทพีซีของคุณและก่อนที่จะเข้ารหัส/เข้าสู่ระบบผู้ใช้ คุณจะเห็นหน้าจอเหมือน BIOS (ฉันกำลังเขียนสิ่งนี้จากหน่วยความจำ) พร้อมตัวเลือกในการป้อนรหัส MOK คลิกและป้อนรหัสผ่านของคุณ จากนั้นส่งและบูต ข้อมูลบางอย่างที่นี่
- เข้าสู่ระบบตามปกติแล้วพิมพ์คำสั่ง
nvidia-smi ; หากสำเร็จควรพิมพ์ตาราง ถ้าไม่เช่นนั้น จะมีข้อความประมาณว่า "ไม่สามารถเชื่อมต่อกับ GPU ได้ โปรดตรวจสอบให้แน่ใจว่าได้ติดตั้งไดรเวอร์ล่าสุดแล้ว" - ตอนนี้เพื่อติดตั้ง CUDA (คำสั่งสุดท้ายที่นี่ควรพิมพ์ข้อมูลบางอย่างเกี่ยวกับการติดตั้ง CUDA ใหม่ของคุณ) จากคู่มือนี้:
sudo apt update
sudo apt install apt-transport-https ca-certificates gnupg
sudo apt install nvidia-cuda-toolkit
nvcc-version
- ย้อนกลับไปทำตามขั้นตอนที่ 7-9; หากคุณได้รับข้อความ "ข้อผิดพลาด: ไม่สามารถเปิดใช้งาน python venv, aborting..." ให้ไปที่ขั้นตอนถัดไป (ไม่เช่นนั้น คุณจะออกจากการแข่งขันและจะคัดลอกที่อยู่ IP จาก CLI เหมือนปกติและสามารถเริ่มเล่นกับ SD ได้)
- ปัญหา Github นี้มีการแก้ไขปัญหาบางอย่างสำหรับปัญหา venv นี้... สำหรับฉัน สิ่งที่ได้ผลกำลังทำงานอยู่
python3 -c 'import venv'
python3 -m venv venv/
จากนั้นไปที่โฟลเดอร์ /stable-diffusion-webui และเรียกใช้:
rm -rf venv/
python3 -m venv venv/
หลังจากนั้นมันก็ได้ผลสำหรับฉัน
เจาะลึกยิ่งขึ้น
- อ่านเทคนิคการกระตุ้นเตือน เนื่องจากมีสิ่งต่างๆ มากมายที่ต้องรู้ (เช่น การแจ้งเตือนเชิงบวกและการแจ้งเตือนเชิงลบ ขั้นตอนการสุ่มตัวอย่าง วิธีการสุ่มตัวอย่าง เป็นต้น)
- คู่มือพร้อมท์บุ๊ค OpenArt
- คู่มือการแจ้ง SD ขั้นสุดท้าย
- คู่มือการกระตุ้นเตือนแบบรวบรัด
- เคล็ดลับการแจ้ง 4chan (NSFW)
- รวบรวมข้อความและรูปภาพ
- คู่มือแนะนำสาวอนิเมะทีละขั้นตอน
- อ่านความรู้ SD โดยทั่วไป:
- สิ่งพิมพ์เผยแพร่การแพร่กระจายเสถียรภาพน้ำเชื้อ
- CompVis / Stability AI Github (บ้านของรุ่น SD ดั้งเดิม)
- บทสรุปการแพร่กระจายที่เสถียร (ทรัพยากรภายนอกที่ดี)
- ศูนย์กลางลิงก์การแพร่กระจายที่เสถียร (ทรัพยากร 4chan ที่น่าทึ่ง)
- เหมืองทองการแพร่กระจายที่เสถียร
- SD Goldmine แบบง่าย
- สุ่ม/เบ็ดเตล็ด ลิงค์ SD
- คำถามที่พบบ่อย (NSFW)
- คำถามที่พบบ่อยอื่น
- เข้าร่วม Discord การแพร่กระจายที่เสถียร
- ติดตามข่าวสาร Stable Diffsion อยู่เสมอ
- คุณรู้ไหมว่า ณ เดือนมีนาคม 2023 โมเดลการแพร่กระจายข้อความเป็นวิดีโอพารามิเตอร์ 1.7B พร้อมใช้งานแล้ว
- ใช้งาน WebUI เล่นกับรุ่นต่างๆ การตั้งค่า ฯลฯ
พร้อมท์
ลำดับของคำในพรอมต์มีผล: คำก่อนหน้าจะมีความสำคัญกว่า โครงสร้างทั่วไปของพรอมต์ที่ดี จากที่นี่:
<general positives> <descriptors of subject> <descriptors of background> <post-processing, camera, etc.>
และคำแนะนำที่ดีอีกข้อหนึ่งบอกว่าพรอมต์ควรเป็นไปตามโครงสร้างนี้:
<subject> <medium> <style> <artist> <website> <resolution> <additional details> <color> <lighting>
บทความสำคัญเกี่ยวกับโมเดลวิศวกรรมพร้อมท์ txt2img ที่นี่ แหล่งข้อมูลที่ชัดเจนเกี่ยวกับการแจ้งเตือน LLM ที่นี่
ไม่ว่าคุณจะแจ้งอะไรก็ตาม ให้พยายามทำตามโครงสร้างบางประเภทเพื่อให้กระบวนการของคุณสามารถทำซ้ำได้ ด้านล่างนี้คือองค์ประกอบไวยากรณ์พร้อมท์ที่จำเป็น:
- () = ตัวดัดแปลง x1.05
- [] = /1.05 ตัวแก้ไข
- (คำ:1.05) == (คำ)
- (คำ:1.1025) == ((คำ))
- (คำ:.952) == [คำ]
- (คำ:.907) == [[คำ]]
- คำหลัก AND ช่วยให้คุณสามารถพร้อมท์สองข้อความพร้อมกันเพื่อรวมเข้าด้วยกัน ดีที่สิ่งต่างๆ จะไม่ถูกทุบรวมกันในพื้นที่แฝง
- เช่น
1girl standing on grass in front of castle AND castle in background
โมเดล NovelAI
โมเดลเริ่มต้นนั้นค่อนข้างเรียบร้อย แต่ตามปกติแล้วในประวัติศาสตร์ เซ็กซ์ขับเคลื่อนเกือบทุกอย่าง NovelAI (NAI) เป็นบริการสร้างเนื้อหา SD ที่เน้นอนิเมะ และมีโมเดลหลักรั่วไหลออกมา รูปภาพอะนิเมะชายและหญิงส่วนใหญ่ที่สร้างโดย SD (NSFW หรือไม่) มาจากโมเดลที่รั่วไหลออกมานี้
ไม่ว่าในกรณีใด การสร้างคนเป็นสิ่งที่ดีจริงๆ และโมเดลหรือ LoRA ส่วนใหญ่ที่คุณจะเล่นด้วยการผสานก็เข้ากันได้เพราะมันได้รับการฝึกฝนเกี่ยวกับภาพอนิเมะ นอกจากนี้ มนุษย์ยังนำเสนอกรณีการใช้งานเริ่มต้นที่ดีมากสำหรับการปรับแต่ง LoRA ใดที่คุณต้องการใช้เพื่อวัตถุประสงค์ทางวิชาชีพอย่างละเอียด คุณจะต้องแก้ไขปัญหามากมายและคำแนะนำส่วนใหญ่ก็มีไว้สำหรับรูปภาพผู้หญิง ต่อมาเราจะพูดถึงตัวเข้ารหัสอัตโนมัติแบบแปรผัน (VAE) ซึ่งนำความสมจริงที่แท้จริงมาสู่โมเดล
- ปฏิบัติตามคู่มือ NovelAI Speedrun
- คุณจะต้อง Torrent โมเดลที่รั่วไหลออกมาหรือค้นหาที่อื่น
- เมื่อคุณได้รับไฟล์ลงในโฟลเดอร์สำหรับ WebUI,
stable-diffusion-webuimodelsStable-diffusion และเลือกรุ่นที่นั่น คุณควรรอสักครู่ในขณะที่ CLI โหลดน้ำหนัก VAE- หากคุณมีปัญหาที่นี่ ให้คัดลอกไฟล์ config.yaml จากโฟลเดอร์ที่มีโมเดลนั้นอยู่ และปฏิบัติตามรูปแบบการตั้งชื่อเดียวกัน (เช่นในคู่มือนี้)
- นี่เป็นสิ่งสำคัญ... สร้างอิมเมจ Asuka ขึ้นมาใหม่ทุกประการ โดยอ้างอิงถึงคำแนะนำในการแก้ไขปัญหาหากไม่ตรงกัน
- ค้นหาโมเดล SD และ LoRA ใหม่ๆ
- CivitAI
- กอดหน้า
- โมเดล SDG
- โหลดมาเธอร์โหลดรุ่น SDG (NSFW)
- SDG LoRA มาเธอร์โหลด (NSFW)
- โมเดลยอดนิยมมากมาย (รวมถึงคำแนะนำจากก่อนหน้านี้ด้วย) (NSFW)
โลรา
การปรับตัวระดับต่ำ (LoRA) ช่วยให้สามารถปรับจูนแบบละเอียดสำหรับรุ่นที่กำหนดได้ ข้อมูลเพิ่มเติมเกี่ยวกับ LoRA ที่นี่ ใน WebUI คุณสามารถเพิ่ม LoRA ให้กับโมเดล เช่น ไอซิ่งบนเค้กได้ การฝึกอบรม LoRA ใหม่นั้นค่อนข้างง่ายเช่นกัน มีวิธีการอื่นๆ ที่เรียกว่า "บรรพบุรุษ" ในการปรับแต่งอย่างละเอียด (เช่น การกลับข้อความและไฮเปอร์เน็ตเวิร์ก) แต่ LoRA เป็นอุปกรณ์ที่ล้ำสมัย
- ZTZ99A Tank - รถถังทหาร LoRA (รถถังเฉพาะ)
- เครื่องบินรบ - เครื่องบินรบ LoRA
- epi_noiseoffset - LoRA ที่ทำให้ภาพดูโดดเด่น เพิ่มคอนทราสต์
ฉันจะใช้ถัง LoRA ตลอดทั้งคำแนะนำ โปรดทราบว่านี่ไม่ใช่ LoRA ที่ดีนัก เนื่องจากมีไว้สำหรับรูปภาพสไตล์อนิเมะ แต่ก็สามารถเล่นกับมันได้
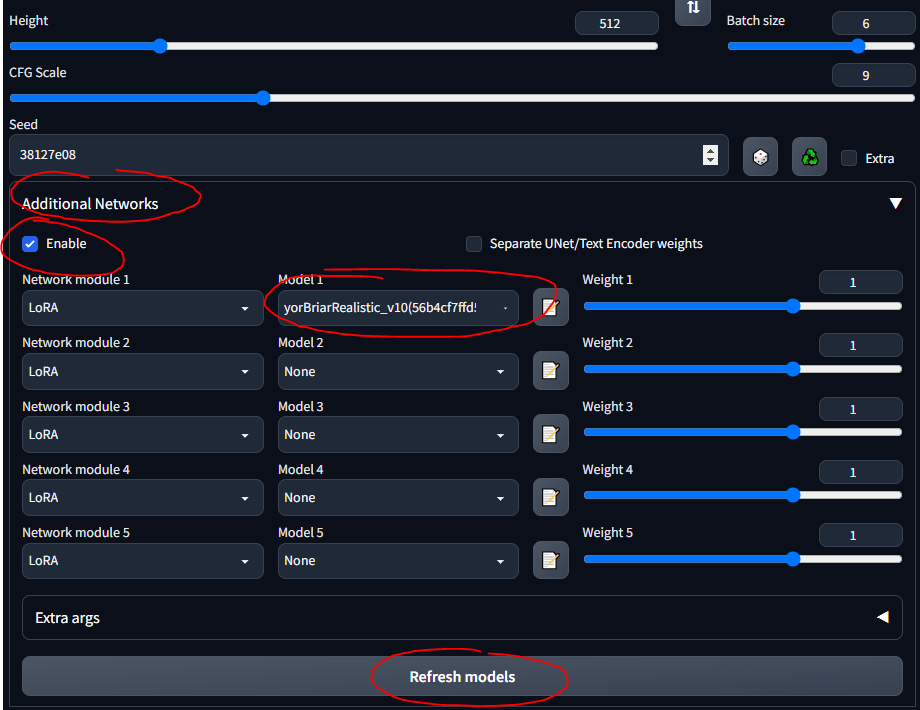
- ทำตามคำแนะนำฉบับย่อนี้เพื่อติดตั้งส่วนขยาย
- ตอนนี้คุณควรเห็นส่วน "เครือข่ายเพิ่มเติม" ใน UI
- ใส่ LoRA ของคุณลงใน
stable-diffusion-webuiextensionssd-webui-additional-networksmodelslora - เลือกและไป
- ตรวจสอบให้แน่ใจว่าคุณได้ตรวจสอบ 'เปิดใช้งาน'
- โปรดทราบว่า LoRA ใดๆ ที่คุณดาวน์โหลดอาจมีข้อมูลที่อธิบายวิธีใช้งาน... เช่น "ใช้คีย์เวิร์ด tank" หรืออะไรสักอย่าง; ตรวจสอบให้แน่ใจว่าคุณดาวน์โหลดมันจากที่ไหน (เช่น CivitAI) คุณได้อ่านคำอธิบายแล้ว
เล่นกับนางแบบ
จากส่วนก่อนหน้า... โมเดลต่างๆ มีข้อมูลการฝึกอบรมและคำสำคัญในการฝึกอบรมที่แตกต่างกัน... ดังนั้นการใช้แท็ก booru ในบางรุ่นจึงทำงานได้ไม่ดีนัก ด้านล่างนี้คือโมเดลบางส่วนที่ฉันเล่นด้วยและ "คำแนะนำ" สำหรับโมเดลเหล่านั้น
SDG Model Motherload ซึ่งเคยเป็นโมเดลส่วนใหญ่ ฉันแค่สรุปคำแนะนำที่นี่เพื่อใช้อ้างอิงอย่างรวดเร็ว โมเดลส่วนใหญ่มีไว้สำหรับสื่อลามก ฉันเน้นไปที่ของจริง ตามลิงก์เพื่อดูตัวอย่างคำแนะนำ รูปภาพ และหมายเหตุโดยละเอียดเกี่ยวกับการใช้แต่ละรายการ
- โมเดล SD เริ่มต้น (1.5 จากขั้นตอนการตั้งค่า คุณสามารถเล่นกับเวอร์ชัน 2.x ของ SD ได้ แต่พูดตามตรง มันห่วย)
- โมเดล NovelAI (จากคู่มือแรก)
- อะไรก็ได้ v3 - โมเดลอนิเมะเอนกประสงค์
- Dreamshaper - ความสมจริง อเนกประสงค์
- ตั้งใจ - ความสมจริง แฟนตาซี ภาพวาด ทิวทัศน์
- Neverending Dream - ความสมจริง แฟนตาซี ดีต่อคนและสัตว์
- Epic Diffusion - สมจริงเป็นพิเศษโดยมีจุดประสงค์เพื่อแทนที่ SD ดั้งเดิม
- AbyssOrangeMix (AOM) - อะนิเมะ ความสมจริง ศิลปะ ภาพวาด เป็นเรื่องธรรมดามากและเหมาะสำหรับการทดสอบ
- Kotosmix - วัตถุประสงค์ทั่วไป ความสมจริง อะนิเมะ ทิวทัศน์ ผู้คน แนะนำตัวอย่าง DPM++ 2M Karras
CivitAI ถูกใช้เพื่อรับสิ่งอื่นๆ ทั้งหมด คุณต้อง สร้างบัญชี ไม่เช่นนั้นคุณจะไม่สามารถดูสิ่งของ NSFW ได้ รวมถึงอาวุธและอุปกรณ์ทางทหาร บน CivitAI บางรุ่น (จุดตรวจ) มี VAEs; หากระบุสิ่งนี้ ให้ดาวน์โหลดด้วยและวางไว้ข้างโมเดล
- ChilloutMix - ภาพบุคคลที่มีความสมจริงเป็นพิเศษ ซึ่งเป็นหนึ่งในโปรแกรมที่ได้รับความนิยมมากที่สุด
- Protogen x3.4 - สมจริงเป็นพิเศษ
- ใช้คำที่กระตุ้น: สไตล์การถ่ายภาพโมเดล, สไตล์แอนะล็อก, สไตล์ mdjrny-v4, หุ่นยนต์ nousr
- Dreamlike Photoreal 2.0 - สมจริงเป็นพิเศษ
- ใช้คำที่กระตุ้น: เหมือนจริง
- ชุดเครื่องมือของ SPYBG สำหรับศิลปินดิจิทัล - ความสมจริง แนวคิดศิลปะ
- ใช้คำทริกเกอร์: tk-char, tk-env
VAE
ตัวเข้ารหัสอัตโนมัติแบบแปรผันทำให้ภาพดูดีขึ้น คมชัดขึ้น และสว่างน้อยลง บ้างก็ซ่อมมือและหน้าด้วย แต่ส่วนใหญ่จะเป็นเรื่องความอิ่มตัวและการแรเงา อธิบายที่นี่และที่นี่ (NSFW) โดยทั่วไปจะใช้ NovelAI / Anything VAE โดยพื้นฐานแล้วมันเป็นส่วนเสริมให้กับโมเดลของคุณ เช่นเดียวกับ LoRA
ค้นหา VAE ในรายการ VAE:
- NAI / อะไรก็ได้ - สำหรับโมเดลอนิเมะ
- มาพร้อมกับโมเดล NAI เป็นค่าเริ่มต้นเมื่อคุณใส่ลงในโฟลเดอร์ models
- SD 1.5 - สำหรับโมเดลที่เหมือนจริง
- ดาวน์โหลด VAE
- ปฏิบัติตามส่วนสั้นๆ ของคำแนะนำเพื่อตั้งค่า VAE ใน WebUI
- ตรวจสอบให้แน่ใจว่าได้ใส่ไว้ใน
stable-diffusion-webuimodelsVAE
- ลองสร้างภาพโดยมีและไม่มี VAE ของคุณเพื่อดูความแตกต่าง
ใส่มันทั้งหมดเข้าด้วยกัน
ต่อไปนี้เป็นหมายเหตุทั่วไปและสิ่งที่เป็นประโยชน์ที่ฉันได้เรียนรู้ไปพร้อมกันซึ่งไม่จำเป็นต้องสอดคล้องกับลำดับเวลาของคู่มือนี้
กระบวนการ SD ทั่วไป
วิธีที่ดีในการเรียนรู้คือการเรียกดูภาพเจ๋งๆ บน CivitAI, AIbooru หรือไซต์ SD อื่นๆ (4chan, Reddit ฯลฯ) เปิดสิ่งที่คุณต้องการและคัดลอกพารามิเตอร์การสร้างลงใน WebUI การเปิดเผยข้อมูลทั้งหมด: การสร้างรูปภาพใหม่ทุกประการนั้นเป็นไปไม่ได้เสมอไป ดังที่อธิบายไว้ที่นี่ แต่โดยทั่วไปแล้วคุณสามารถเข้าใกล้ได้มาก หากต้องการลองเล่นจริงๆ ให้ปรับ CFG ต่ำเพื่อให้โมเดลได้สร้างสรรค์มากขึ้น ลองแบทช์และเดินออกจากคอมพิวเตอร์เพื่อกลับมาเลือกลอตเตอรี่อีกครั้ง
กระบวนการทั่วไปสำหรับเวิร์กโฟลว์ WebUI คือ:
find/pick models/LoRAs -> txt2img (repeat, change params, etc.) -> img2img -> inpainting -> extra ->
- txt2img - พร้อมท์และรับภาพ
- img2img - แก้ไขภาพและสร้างภาพที่คล้ายกัน
- inpainting - แก้ไขบางส่วนของภาพ (จะหารือในภายหลัง)
- พิเศษ - การแก้ไขภาพขั้นสุดท้าย (จะหารือในภายหลัง)
กำลังบันทึกคำแนะนำ
บางครั้งคุณต้องการย้อนกลับไปที่ข้อความแจ้งโดยไม่ต้องวางรูปภาพหรือเขียนใหม่ตั้งแต่ต้น คุณสามารถบันทึกข้อความแจ้งให้ใช้ซ้ำได้ใน WebUI
- เขียนพรอมต์เชิงบวกและ/หรือเชิงลบ
- ใต้ปุ่มสร้าง คลิกปุ่มทางด้านขวาเพื่อบันทึก "สไตล์" ของคุณ
- ป้อนชื่อและบันทึก
- เลือกได้ตลอดเวลาโดยคลิกเมนูแบบเลื่อนลงสไตล์
การตั้งค่า txt2img
ส่วนนี้จะเป็นการสรุปข้อมูลของคู่มือนี้ไม่มากก็น้อย
- โดยทั่วไปขั้นตอนการสุ่มตัวอย่างที่มากขึ้นหมายถึงความแม่นยำมากขึ้น (ยกเว้นเครื่องเก็บตัวอย่าง "a" เช่น ออยเลอร์ a ที่เปลี่ยนแปลงบ่อยครั้ง)
- เปิดและปิดเล่นกับสิ่งนี้ โดยทั่วไปแล้วเมื่อเปิดจะทำให้ใบหน้าดูดีจริงๆ
- ไฮเรส การแก้ไขนี้เหมาะสำหรับรูปภาพที่มีขนาดเกิน 512x512; มีประโยชน์หากภาพมีบุคคลมากกว่าหนึ่งคน
- CFG ดีที่สุดที่ค่ากลางต่ำ เช่น 5-10
การสร้างรูปภาพที่สร้างไว้ก่อนหน้านี้ใหม่
เพื่อทำงานจากรูปภาพที่สร้างโดย SD ที่มีอยู่แล้ว อาจมีคนส่งมาให้คุณหรือคุณต้องการสร้างสิ่งที่คุณสร้างขึ้นใหม่:
- ใน WebUI ให้ไปที่แท็บข้อมูล PNG
- ลากและวางรูปภาพที่คุณสนใจลงใน UI
- พวกเขาจะถูกบันทึกไว้ใน
stable-diffusion-webuioutputstxt2img-images<date>
- ดูพารามิเตอร์ที่ใช้ทางด้านขวา
- ใช้งานได้เพราะ PNG สามารถจัดเก็บข้อมูลเมตาได้
- คุณสามารถส่งโดยตรงไปยังหน้า txt2img ด้วยปุ่มที่เกี่ยวข้อง
- อาจต้องตรวจสอบกลับไปกลับมาเพื่อให้แน่ใจว่าโมเดล, VAE และพารามิเตอร์อื่นๆ เติมข้อมูลอย่างถูกต้องโดยอัตโนมัติ
โปรดทราบว่าบางไซต์จะลบข้อมูลเมตา PNG เมื่อมีการอัปโหลดรูปภาพ (เช่น 4chan) ดังนั้นให้มองหา URL ไปยังรูปภาพเต็มหรือใช้ไซต์ที่เก็บข้อมูลเมตา SD เช่น CivitAI หรือ AIbooru
การแก้ไขปัญหาข้อผิดพลาด
ฉันได้รับข้อผิดพลาดเล็กน้อยครั้งแล้วครั้งเล่า ข้อผิดพลาดหน่วยความจำไม่เพียงพอ (VRAM) ส่วนใหญ่ที่ได้รับการแก้ไขโดยการลดค่าในพารามิเตอร์บางตัว บางครั้งการคืนค่าเผชิญหน้าและว่าจ้าง แก้ไขการตั้งค่าอาจทำให้เกิดสิ่งนี้ ในไฟล์ stable-diffusion-webuiwebui-user.bat บนบรรทัด set COMMANDLINE_ARGS= คุณสามารถใส่แฟล็กบางตัวที่แก้ไขข้อผิดพลาดทั่วไปได้
- ข้อผิดพลาด NaN บางอย่างที่ส่งผลต่อ "VAE สร้างบางสิ่ง NaN" เพิ่มพารามิเตอร์
--disable-nan-check - หากคุณเคยได้รับภาพสีดำ ให้เพิ่ม
--no-half - หากคุณยังคงใช้ VRAM เหลืออยู่ ให้เพิ่ม
--medvram หรือสำหรับคอมพิวเตอร์มันฝรั่ง --lowvram - การฟื้นฟูใบหน้า Codeformer แก้ไขได้ที่นี่ (ถ้ามันพังให้ลองรีเซ็ตอินเทอร์เน็ตก่อน)
- การโหลดโมเดลช้า (เมื่อเปลี่ยนไปใช้อันใหม่) อาจเป็นเพราะไฟล์ .safetensors โหลดช้าหากสิ่งต่าง ๆ ได้รับการกำหนดค่าไม่ถูกต้อง กระทู้นี้กล่าวถึงเรื่องนี้
ปัญหาที่พบบ่อยประการหนึ่งเกิดจากการมีเวอร์ชัน Python หรือเวอร์ชัน Torch ที่ไม่ถูกต้อง คุณจะได้รับข้อผิดพลาดเช่น "ไม่สามารถติดตั้ง Torch" หรือ "Torch ไม่พบ GPU" การแก้ไขที่ง่ายที่สุดคือ:
- ถอนการติดตั้งเวอร์ชัน Python ใด ๆ ที่คุณอัปเดต เนื่องจาก SD WebUI คาดว่าจะเป็น 3.10.6 (ฉันใช้ 3.11.5 และละเว้นข้อผิดพลาดในการเริ่มต้นก็โอเค แต่ดูเหมือนว่า 3.10.6 จะทำงานได้ดีที่สุด) (คุณสามารถใช้ตัวจัดการเวอร์ชันได้หากคุณ ก้าวหน้าพอแล้ว)
- ติดตั้ง Python 3.10.6 ตรวจสอบให้แน่ใจว่าได้เพิ่มลงใน PATH ของคุณ (ทั้งโฟลเดอร์
Python และโฟลเดอร์ Python/Scripts ) - ลบโฟลเดอร์
venv ในโฟลเดอร์ stable-diffusion-webui ของคุณ - รัน
stable-diffusion-webuiwebui-user.bat และปล่อยให้มันสร้าง venv ใหม่อย่างถูกต้อง - สนุก
อาร์กิวเมนต์บรรทัดคำสั่งทั้งหมดสามารถพบได้ที่นี่
ได้รับความสะดวกสบาย
ส่วนขยายบางส่วนสามารถทำให้การใช้ WebUI ดีขึ้นได้ รับลิงก์ Github ไปที่แท็บส่วนขยาย ติดตั้งจาก URL อีกทางหนึ่ง ในแท็บส่วนขยาย คลิกพร้อมใช้งาน จากนั้นคลิกโหลดจาก และคุณสามารถเรียกดูส่วนขยายในเครื่องได้ ซึ่งจะสะท้อนส่วนขยายวิกิ Github
- Tag Completer - แนะนำและเติมแท็ก booru อัตโนมัติขณะที่คุณพิมพ์
- สถานะ UI ของเว็บการแพร่กระจายที่เสถียร - รักษาสถานะ UI แม้ว่าจะรีสตาร์ทแล้วก็ตาม
- ทดสอบพรอมต์ของฉัน - สคริปต์ที่คุณสามารถเรียกใช้เพื่อลบคำแต่ละคำออกจากพรอมต์ของคุณ เพื่อดูว่ามันส่งผลต่อการสร้างภาพอย่างไร
- โมเดล-คีย์เวิร์ด - ป้อนคีย์เวิร์ดอัตโนมัติที่เกี่ยวข้องกับโมเดลและ LoRA บางรุ่น ค่อนข้างได้รับการดูแลเป็นอย่างดีและอัปเดต ณ เดือนเมษายน 2023
- ตัวตรวจสอบ NSFW - ทำให้ภาพ NSFW มืดลง มีประโยชน์หากคุณทำงานในสำนักงาน เนื่องจากมีโมเดลดีๆ จำนวนมากที่อนุญาตให้มีเนื้อหา NSFW และคุณอาจไม่ต้องการเห็นสิ่งนั้นในที่ทำงาน
- โปรดทราบ: ส่วนขยายนี้อาจทำให้การวาดภาพหรือการสร้างภาพยุ่งเหยิงโดยการทำให้ภาพ NSFW มืดลง (ไม่ใช่ชั่วคราว แต่จะแสดงผลเป็นภาพสีดำแทน) ดังนั้นอย่าลืมปิดการทำงานตามความจำเป็น
- Gelbooru Prompt - ดึงแท็กและสร้างพร้อมท์อัตโนมัติจากอิมเมจ Gelbooru ใดๆ โดยใช้แฮช
- booru2prompt - คล้ายกับ Gelbooru Prompt แต่มีฟังก์ชันการทำงานมากกว่าเล็กน้อย
- การแจ้งแบบไดนามิก - ภาษาเทมเพลตสำหรับการสร้างพรอมต์ที่ช่วยให้คุณสามารถเรียกใช้การแจ้งแบบสุ่มหรือแบบผสมผสานเพื่อสร้างรูปภาพต่างๆ (ใช้ไวด์การ์ด)
- ชุดเครื่องมือโมเดล - ส่วนขยายยอดนิยมที่ช่วยคุณจัดการ แก้ไข และสร้างโมเดล
- ตัวแปลงโมเดล - มีประโยชน์สำหรับการแปลงโมเดล การเปลี่ยนความแม่นยำ ฯลฯ เมื่อคุณกำลังฝึกฝนตัวคุณเอง
การทดสอบ
ตอนนี้คุณมีรุ่น LoRA และข้อความแจ้งบางรุ่นแล้ว... คุณจะทดสอบเพื่อดูว่ารุ่นใดทำงานได้ดีที่สุดได้อย่างไร ใต้บานหน้าต่างเครือข่ายเพิ่มเติม จะมีดรอปดาวน์สคริปต์ ที่นี่ คลิกพล็อต X/Y/Z ในประเภท X ให้เลือกชื่อจุดตรวจสอบ ในค่า X ให้คลิกปุ่มทางด้านขวาเพื่อวางโมเดลทั้งหมดของคุณ ในประเภท Y ให้ลองใช้ VAE หรืออาจเป็นระดับ seed หรือ CFG คุณลักษณะใดก็ตามที่คุณเลือก ให้วาง (หรือป้อน) ค่าที่คุณต้องการสร้างกราฟ ตัวอย่างเช่น หากคุณมี 5 โมเดลและ 5 VAE คุณจะสร้างตารางรูปภาพ 25 ภาพ เปรียบเทียบวิธีที่แต่ละโมเดลส่งออกกับ VAE แต่ละตัว สิ่งนี้มีความหลากหลายมากและสามารถช่วยคุณตัดสินใจว่าจะใช้อะไร เพียงระวังว่าหากแกน X หรือ Y ของคุณเป็นโมเดลของ VAE ก็จะต้องโหลดโมเดลหรือตุ้มน้ำหนัก VAE สำหรับทุกชุด ดังนั้นจึงอาจใช้เวลาสักครู่
แหล่งข้อมูลที่ดีมากเกี่ยวกับการเปรียบเทียบ SD มีอยู่ที่นี่ (NSFW) มีลิงค์ให้ติดตามมากมาย คุณสามารถเริ่มทำความเข้าใจว่าโมเดลต่างๆ, VAE, LoRA, ค่าพารามิเตอร์ และอื่นๆ ส่งผลต่อการสร้างภาพอย่างไร
ฉันใช้พรอมต์การทดสอบจากที่นี่ และใช้ LoRA ของถังเพื่อสร้างตาราง X/Y นี้ คุณสามารถดูได้ว่าโมเดลและตัวอย่างต่างๆ ทำงานร่วมกันอย่างไร จากการทดสอบนี้เราสามารถประเมินได้ว่า:
- โมเดล ChilloutMix, Deliberate, Dreamlike Photoreal และ Epic Diffusion ดูเหมือนจะสร้างภาพรถถังที่ "สมจริง" ที่สุด
- ในการทดสอบอิสระในภายหลัง พบว่า Protogen X34 Photorealism และ SpyBGs Toolkit ต่างก็ค่อนข้างดีในรถถังเช่นกัน
- ตัวอย่างที่มีแนวโน้มมากที่สุดที่นี่ดูเหมือนจะเป็น DPM++ SDE หรือตัวอย่าง Karras ใดๆ

พารามิเตอร์ที่แน่นอนที่ใช้ (ไม่รวมโมเดลหรือตัวอย่าง) สำหรับภาพรถถังทุกภาพมีดังต่อไปนี้ (นำมาจากที่นี่อีกครั้ง):
- พรอมต์เชิงบวก: รถถัง, bf2042, คุณภาพดีที่สุด, ผลงานชิ้นเอก, ความละเอียดสูงพิเศษ, (เหมือนจริง: 1.4), ผิวที่มีรายละเอียด, แสงแบบภาพยนตร์, ภาพถ่ายที่มีรายละเอียดสูงในโรงภาพยนตร์, สีสันสดใส, ทันสมัย, กลุ่มทหารในสนามรบ, สนามรบระเบิดทุกหนทุกแห่ง, เครื่องบินขับไล่ไอพ่น และเฮลิคอปเตอร์ที่บินอยู่บนท้องฟ้า รถถังสองคันบนพื้น ในพื้นที่ทะเลทราย อาคารที่ถูกไฟไหม้ และรถหุ้มเกราะทหารที่ถูกทิ้งร้างหนึ่งคันในเบื้องหลัง
- ข้อความแจ้งเชิงลบ: เปลือยเปล่า (คุณภาพแย่ที่สุด:2), (คุณภาพต่ำ:2), (คุณภาพปกติ:2), lowres, ลักษณะทางกายวิภาคที่ไม่ดี, มือที่ไม่ดี, คุณภาพปกติ, ((ขาวดำ)), ((ระดับสีเทา)), ยุบตัว อายแชโดว์, เป่าตาหลายอัน, ผมสีชมพู, รูบนหน้าอก, ng_deepnegative_v1_75t, nsfw, หัวนม, นิ้วเกิน, ((แขนพิเศษ)), (ขาพิเศษ), มือกลายพันธุ์, (นิ้วหลอมละลาย), (นิ้วมากเกินไป), (คอยาว:1.3)
- ขั้นตอน: 22
- สเกล CFG: 7.5
- เมล็ดพันธุ์: 1656460887
- ขนาด: 480x480
- ข้ามคลิป: 2
- เปิดใช้งาน AddNet แล้ว: จริง, โมดูล AddNet 1: LoRA, AddNet รุ่น 1: ztz99ATank_ztz99ATank(82a1a1085b2b), AddNet Weight A 1: 1, AddNet Weight B 1: 1
WebUI ขั้นสูง
ในส่วนนี้เป็นสิ่งที่ขั้นสูงกว่าที่คุณสามารถทำได้เมื่อคุณมีความคุ้นเคยเป็นอย่างดีกับการใช้โมเดล, LoRA, VAE, การแจ้ง, พารามิเตอร์, การเขียนสคริปต์ และส่วนขยายในแท็บ txt2image ของ WebUI
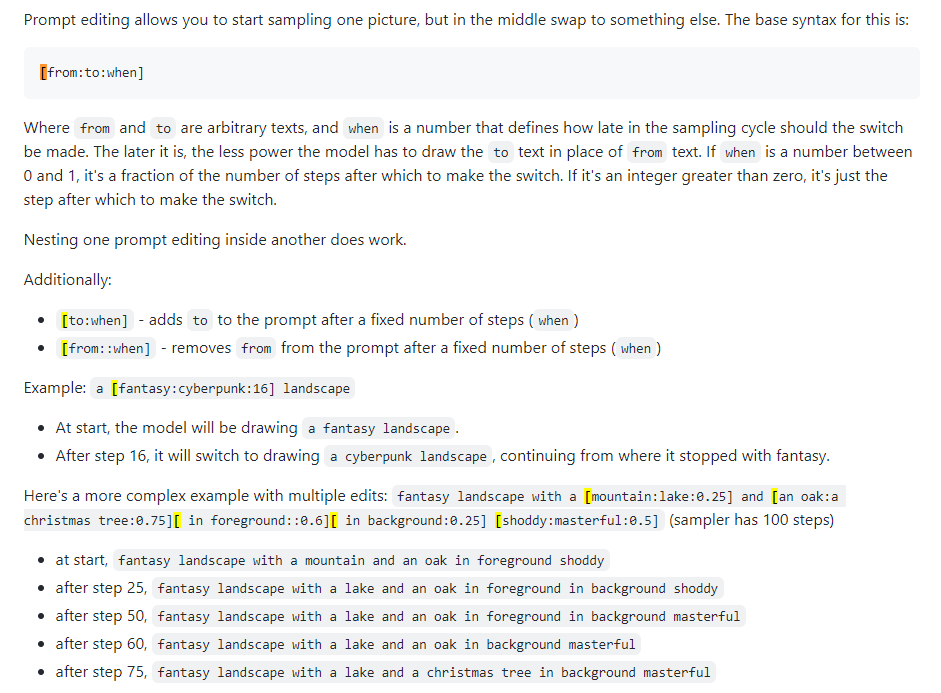
แก้ไขด่วน
เรียกอีกอย่างว่าการผสมแบบทันที การแก้ไขพร้อมท์ช่วยให้คุณสามารถให้โมเดลเปลี่ยนพร้อมท์ตามขั้นตอนที่ระบุได้ ภาพด้านล่างนำมาจากโพสต์ 4chan และอธิบายเทคนิคนี้ ตัวอย่างเช่น ตามที่ระบุไว้ในคู่มือนี้ สามารถใช้การแก้ไขทันทีเพื่อผสมผสานใบหน้าได้
เอ็กซ์ฟอร์เมอร์
Xformers หรือเลเยอร์ความสนใจข้าม วิธีเพิ่มความเร็วในการสร้างภาพ (วัดเป็นวินาที/การวนซ้ำ หรือวินาที/ภาพ) บน Nvidia GPU จะช่วยลดการใช้งาน VRAM แต่ทำให้เกิดความไม่แน่นอน พิจารณาสิ่งนี้เฉพาะในกรณีที่คุณมี GPU ที่ทรงพลัง จริงๆ แล้วคุณต้องการ Quadro
img2img
ไม่ค่อยได้ใช้เท่าไหร่ ค่อนข้างจะสับสน สามารถใช้เพื่อสร้างภาพที่กำหนดให้ร่างได้ เช่นใน Huggingface Image to Image SD Playground แท็บนี้มีแท็บย่อย inpainting ซึ่งเป็นหัวข้อของส่วนถัดไปและความสามารถที่สำคัญมากของ WebUI แม้ว่าคุณสามารถใช้ส่วนนี้เพื่อสร้างภาพที่เปลี่ยนแปลงตามที่คุณสร้างไว้แล้ว (เอาต์พุตไปยัง stable-diffusion-webuioutputsimg2img-images ) ฟังก์ชั่นการใช้งานนั้นขาด ๆ หาย ๆ สำหรับฉัน ... ดูเหมือนว่าจะใช้หน่วยความจำจำนวนมหาศาลและ ฉันแทบจะไม่สามารถทำให้มันทำงานได้ ไปที่ส่วนถัดไปด้านล่าง
การวาดภาพ
นี่คือจุดที่อำนาจอยู่ที่ผู้สร้างเนื้อหาหรือผู้ที่สนใจเรื่องการก่อกวนภาพ เอาต์พุตอยู่ใน stable-diffusion-webuioutputsimg2img-images
- คู่มือการลงสีและการทาสีภายนอก
- การวาดภาพ 4chan (NSFW)
- คู่มือการวาดภาพขั้นสุดท้าย
- หยิบภาพที่คุณชอบแต่ภาพนั้นไม่สมบูรณ์แบบ มีบางอย่างผิดปกติ - จำเป็นต้อง ปรับแต่ง
- หรือสร้างหนึ่งรายการแล้วคลิกส่งไปที่ inpaint (การตั้งค่าทั้งหมดจะเติมอัตโนมัติ)
- ตอนนี้คุณอยู่ในแท็บย่อย img2img -> inpaint
- วาด (ด้วยเมาส์) บนภาพในตำแหน่งที่คุณต้องการเปลี่ยน
- ตั้งค่าโหมดมาสก์เป็น "inpaint Masked" เนื้อหาที่มาสก์เป็น "ต้นฉบับ" และ Inpaint พื้นที่เป็น "Only Masked"
- ในพื้นที่พร้อมท์ด้านบน ให้เขียนพร้อมท์ใหม่เพื่อปรับแต่งจุดนั้นในภาพ ทำพร้อมท์เชิงลบหากคุณต้องการ
- สร้างภาพ (ตามหลักการแล้ว ให้ทำชุดละ 4 ภาพ)
- ไม่ว่าคุณจะชอบอันไหน ให้คลิกส่งเพื่อ inpaint และวนซ้ำจนกว่าคุณจะได้ภาพที่เสร็จสมบูรณ์
การทาสีภายนอก
การทาสีทับหน้าเป็นกระบวนการความหมายที่ค่อนข้างซับซ้อน การทาสีทับช่วยให้คุณสามารถถ่ายภาพและขยายได้บ่อยเท่าที่คุณต้องการ โดยพื้นฐานแล้วการขยายขอบเขตของภาพ กระบวนการนี้อธิบายไว้ที่นี่ คุณขยายรูปภาพครั้งละ 64 พิกเซลเท่านั้น มีเครื่องมือ UI สองอันสำหรับสิ่งนี้ (ที่ฉันหาได้):
- Alpha Canvas (สร้างไว้ใน WebUI เป็นส่วนขยาย/สคริปต์)
- Hua (เว็บแอปสำหรับการลงสี/การลงสีภายนอก)
บริการพิเศษ
แท็บ WebUI นี้มีไว้สำหรับการขยายขนาดโดยเฉพาะ หากคุณได้ภาพที่คุณชอบจริงๆ คุณสามารถขยายขนาดได้ที่นี่เมื่อสิ้นสุดขั้นตอนการทำงานของคุณ ภาพที่ขยายขนาดจะถูกจัดเก็บไว้ใน stable-diffusion-webuioutputsextras-images ปัญหาหน่วยความจำบางส่วนที่เกี่ยวข้องกับการลดขนาดด้วยตัวเพิ่มสเกลที่มีประสิทธิภาพมากขึ้นในระหว่างการสร้างในแท็บ txt2img (เช่น รุ่น 4x+) จะไม่เกิดขึ้นที่นี่เนื่องจากคุณไม่ได้สร้างภาพใหม่ คุณเพียงขยายขนาดภาพคงที่เท่านั้น
คอนโทรลเน็ตส์
วิธีที่ดีที่สุดในการทำความเข้าใจสิ่งที่ ControlNet ทำคือการพูดว่า "การวาดภาพบนสเตียรอยด์" คุณให้ภาพอินพุต (สร้างโดย SD หรือไม่) และมันสามารถแก้ไขสิ่งทั้งหมดได้ เป็นไปได้ด้วย ControlNets ที่เป็นท่าโพส คุณสามารถกำหนดท่าอ้างอิงสำหรับบุคคลและสร้างรูปภาพที่สอดคล้องกันตามคำแนะนำทั่วไปของคุณ การเริ่มต้นที่ดีในการทำความเข้าใจ ControlNets อยู่ที่นี่แล้ว
- ติดตั้งส่วนขยาย ControlNet, sd-webui-controlnet ใน WebUI
- ตรวจสอบให้แน่ใจว่าได้โหลด UI ซ้ำโดยคลิกปุ่มโหลด UI ซ้ำในแท็บการตั้งค่า
- ตรวจสอบว่าปุ่ม ControlNet อยู่ในแท็บ txt2img (และ img2img) ด้านล่างเครือข่ายเพิ่มเติม (ที่คุณใส่ LoRA ของคุณ)
- เปิดใช้งานรุ่น ControlNet หลายรุ่น: การตั้งค่า -> ControlNet -> ตัวเลื่อน Mutli ControlNet -> 2+
- โหลด UI ใหม่และในพื้นที่ ControlNet คุณจะเห็นแท็บโมเดลหลายแท็บ
- คุณสามารถรวม ControlNets (เช่น Canny และ OpenPose) ได้เหมือนกับการใช้ LoRA หลายตัว
- รับโมเดล ControlNet
- รุ่น Canny เป็นรุ่นตรวจจับขอบ รูปภาพจะถูกแปลงเป็นรูปภาพขอบขาวดำ โดยที่ขอบจะบอก SD โดยคร่าวๆ ว่ารูปภาพของคุณจะเป็นอย่างไร
- โมเดล OpenPose ถ่ายภาพบุคคลและแปลงเป็นรูปแบบท่าทางเพื่อใช้ในภาพในภายหลัง
- ยังมีโมเดลอื่นๆ อีกมากมายที่สามารถตรวจสอบได้ที่นั่นเช่นกัน
- มาจับโมเดล Canny และ OpenPose กันดีกว่า
- ใส่ไว้ใน
stable-diffusion-webuiextensionssd-webui-controlnetmodels - รับภาพที่คุณสนใจหรือสร้างภาพใหม่ ที่นี่ ฉันจะใช้อิมเมจรถถังที่ฉันสร้างไว้ก่อนหน้านี้

- การตั้งค่าใน txt2img: วิธีการสุ่มตัวอย่าง "DDIM", การสุ่มตัวอย่างขั้นตอนที่ 20, ความกว้าง/ความสูงเหมือนกับภาพที่คุณเลือก
- การตั้งค่าในแท็บ ControlNet: ทำเครื่องหมายที่ Enable, ตัวประมวลผลล่วงหน้า "Canny", รุ่น "control_canny-fp16", ความกว้าง/ความสูงของผืนผ้าใบเหมือนกับรูปภาพที่คุณเลือก (การตั้งค่าอื่นๆ ทั้งหมดเป็นค่าเริ่มต้น)
- แก้ไขข้อความแจ้งของคุณและคลิกสร้าง ฉันพยายามแปลงรูปรถถังของฉันให้เป็นรูปบนดาวอังคาร

- สถานการณ์เชิงบวกคือ ฉากบนดาวอังคาร อวกาศรอบนอก อวกาศ จักรวาล ((พื้นหลังอวกาศกาแล็กซี)) ดวงดาว ฐานดวงจันทร์ อนาคต พื้นหลังสีดำ พื้นหลังสีเข้ม ดวงดาวบนท้องฟ้า (เวลากลางคืน) ทรายสีแดง ((ดวงดาวใน พื้นหลัง)), รถถัง, bf2042, คุณภาพดีที่สุด, ผลงานชิ้นเอก, ความละเอียดสูงพิเศษ, (เหมือนจริง: 1.4), ผิวที่มีรายละเอียด, แสงแบบภาพยนตร์, ภาพถ่ายที่มีรายละเอียดสูงในโรงภาพยนตร์, สีสันสดใส, ภาพถ่ายสมัยใหม่, กลุ่มทหารในสนามรบ, การระเบิดในสนามรบทุกหนทุกแห่ง, เครื่องบินขับไล่ไอพ่นและเฮลิคอปเตอร์ที่บินอยู่บนท้องฟ้า รถถังสองคันบนพื้น ในพื้นที่ทะเลทราย อาคารที่ติดไฟและรถหุ้มเกราะทหารที่ถูกทิ้งร้างหนึ่งคันในพื้นหลัง ต้นไม้ ป่า ท้องฟ้า
- ไปถ่ายรูปกับคนในนั้น แล้วทำได้ทั้งโมเดล Canny ใน Control Model - 0 และโมเดล OpenPose ใน Control Model - 1 ให้สนุกไปกับมันจริงๆ
- ดูวิดีโอนี้อีกครั้งเพื่อเจาะลึกกับ Canny และ OpenPose
การทำสิ่งใหม่ๆ
ทั้งหมดนี้ถือว่าดีและดี แต่บางครั้งคุณจำเป็นต้องมีโมเดลหรือ LoRA ที่ดีกว่าสำหรับการใช้งานระดับมืออาชีพ เนื่องจากเนื้อหา SD ส่วนใหญ่มีไว้เพื่อสร้างผู้หญิงหรือสื่อลามก โมเดลเฉพาะและ LoRA จึงอาจจำเป็นต้องได้รับการฝึกอบรม
- เรียกดูทุกหัวข้อที่น่าสนใจที่นี่
- การฝึกอบรม LoRA
- รถไฟลอร่า
- คู่มือการฝึกอบรม Lazy LoRA
- คู่มือการฝึกอบรม LoRA ที่ดีจาก CivitAI
- คู่มือการฝึกอบรม LoRA อีกฉบับ
- ข้อมูล LoRA ทั่วไปเพิ่มเติม
- การรวมโมเดล
- การผสมโมเดล
การฝึกอบรมโมเดลใหม่
ดูหัวข้อใน DreamBooth
การควบรวมกิจการด่านตรวจ
สิ่งที่ต้องทำ
แท็บการรวมจุดตรวจสอบใน WebUI ช่วยให้คุณสามารถรวมสองโมเดลเข้าด้วยกัน เช่น การผสมซอสสองชนิดในหม้อ โดยที่ผลลัพธ์จะเป็นซอสใหม่ที่เป็นส่วนผสมของทั้งสองอย่าง
การฝึกอบรม LoRA
สิ่งที่ต้องทำ
การฝึกอบรม LoRA ไม่จำเป็นต้องยากเสมอไป แต่เป็นเรื่องของการรวบรวมข้อมูลที่เพียงพอเท่านั้น
การตั้งค่า Google Colab
นี่เป็นขั้นตอนสำคัญหากคุณต้องทำงานให้ห่างจากแท่นขุดเจาะ Google Colab Pro มีราคา 10 ดอลลาร์ต่อเดือน และให้ RAM ขนาด 89 GB และสิทธิ์เข้าถึง GPU ที่ดี ดังนั้นคุณจึงสามารถเรียกใช้ข้อความแจ้งในทางเทคนิคจากโทรศัพท์ของคุณ และให้พวกเขาทำงานให้คุณบนเซิร์ฟเวอร์ใน Timbuktu หากคุณไม่คำนึงถึงค่าใช้จ่ายเพิ่มเติมเล็กน้อย Google Colab Pro+ จะมีค่าใช้จ่าย 50 ดอลลาร์ต่อเดือนและยังดีกว่าอีกด้วย
- ไปที่ SD Colab ที่สร้างไว้ล่วงหน้านี้
- คุณสามารถโคลนมันลงใน GDrive ของคุณหรือเพียงแค่ใช้งานมันเพื่อให้เป็นข้อมูลล่าสุดจาก Github เสมอ
- เรียกใช้บล็อกโค้ด 4 แรก (ใช้เวลาเล็กน้อย)
- ข้ามบล็อกโค้ด ControlNet
- เรียกใช้ 'Start Stable-Diffusion' (ใช้เวลาเล็กน้อย)
- ใส่ชื่อผู้ใช้/รหัสผ่านถ้าคุณต้องการ (อาจเป็นความคิดที่ดีเนื่องจาก Gradio เป็นแบบสาธารณะ)
- คลิกลิงก์ Gradio ('ทำงานบน URL สาธารณะ')
- ใช้ WebUI เหมือนปกติ
- ส่งลิงก์ไปยังโทรศัพท์ของคุณแล้วคุณสามารถสร้างภาพได้ทุกที่ทุกเวลา
- หากต้องการเพิ่มโมเดลใหม่และ LoRA คุณควรมีโฟลเดอร์ใหม่ใน Google Drive ของคุณ:
gdrive/MyDrive/sd/stable-diffusion-webui และจากโฟลเดอร์ฐานนี้คุณสามารถใช้โครงสร้างโฟลเดอร์เดียวกันกับที่คุณทำในเครื่อง เว็บ UI- ทำการติดตั้งส่วนขยาย LoRA เหมือนก่อนหน้านี้ และโครงสร้างโฟลเดอร์จะเติมข้อมูลอัตโนมัติเหมือนกับบนเดสก์ท็อป
- ตอนนี้ทุกครั้งที่คุณต้องการใช้ คุณเพียงแค่ต้องเรียกใช้บล็อกโค้ด 'Start Stable-Diffusion' (ไม่มีอย่างอื่นเลย) รับลิงก์ gradio และคุณก็ทำเสร็จแล้ว
Google Colab ให้บริการฟรีตลอดเวลาและคุณสามารถใช้งานได้ตลอดไป แต่อาจช้านิดหน่อย การอัปเกรดเป็น Colab Pro ในราคา $10/เดือนจะช่วยให้คุณมีประสิทธิภาพมากขึ้น แต่ Colab Pro+ ในราคา $50/เดือนคือจุดที่สนุกจริงๆ Pro+ ช่วยให้คุณสามารถรันโค้ดของคุณได้เป็นเวลา 24 ชั่วโมง แม้ว่าคุณจะปิดแท็บแล้วก็ตาม
สิ่งที่ต้องทำ ฉันได้รับข้อผิดพลาดแปลกๆ ที่ทำให้เกิดปัญหากับการสมัครสมาชิก Pro ของฉัน เมื่อฉันตั้งค่ารันไทม์ -> การตั้งค่าโน้ตบุ๊กประเภทรันไทม์เป็นคลาส GPU ระดับพรีเมียมและ RAM สูง เป็นเพราะ xFormers ไม่ได้ถูกสร้างขึ้นด้วยการรองรับ CUDA สิ่งนี้สามารถแก้ไขได้โดยใช้ TPU แทนหรือปิดการใช้งาน xFormers แต่ตอนนี้ฉันไม่มีความอดทน ลองใช้ปัญหาของ Colab
กลางการเดินทาง
MJ ดีต่อศิลปินจริงๆ มันไม่ได้ขยายหรือทรงพลังเท่ากับ SD ใน WebUI เลย (NSFW เป็นไปไม่ได้) แต่คุณสามารถสร้างสิ่งที่ยอดเยี่ยมได้ คุณสามารถใช้งานได้ฟรีใน MJ Discord (สมัครใช้งานบนเว็บไซต์ของพวกเขา) โดยแจ้งเพียงไม่กี่ครั้งหรือจ่าย $8/เดือนสำหรับแผนพื้นฐาน หลังจากนั้นคุณสามารถใช้มันในเซิร์ฟเวอร์ส่วนตัวของคุณเองได้ คำสั่ง Discord ทั้งหมดสามารถพบได้ที่นี่และที่นี่ โครงสร้างพร้อมท์สำหรับ MJ คือ:
/imagine <optional image prompt> <prompt> --parameters
พารามิเตอร์ MJ
สินค้าเหล่านี้มีไว้สำหรับ MJ V4 ซึ่งส่วนใหญ่จะเหมือนกันกับ MJ 5 ทุกรุ่นมีคำอธิบายอยู่ที่นี่
- --ar 1.2-2.1: อัตราส่วนภาพ ค่าเริ่มต้นคือ 1:1
- --chaos 0-100: การเปลี่ยนแปลง ค่าเริ่มต้นคือ 0
- --ไม่มีพืช: กำจัดพืช
- --q 0.0-2.0: เวลาคุณภาพการเรนเดอร์ ค่าเริ่มต้นคือ 1
- --seed: เมล็ด
- --หยุด 10-100: หยุดงานชั่วคราวเพื่อสร้างภาพเบลอ
- --สไตล์ 4a/4b/4c: สไตล์ MJ 4'
- --stylize 0-1,000: ความสุนทรีย์ของ MJ เป็นอิสระมากเพียงใด ค่าเริ่มต้นคือ 100
- --uplight: ใช้ตัวอัปสเกล "แสง" ภาพมีรายละเอียดน้อยลง
- --upbeta: ใช้ตัวขยายขนาดเบต้าให้ใกล้กับภาพต้นฉบับมากขึ้น
- --upanime: เครื่องมือเพิ่มสเกลสำหรับภาพอนิเมะ
- --niji: โมเดลทางเลือกสำหรับภาพอนิเมะ
- --hd: ใช้รุ่นก่อนหน้าที่ให้ภาพขนาดใหญ่ขึ้น เหมาะสำหรับภาพนามธรรมและทิวทัศน์
- --test: ใช้โมเดลทดสอบ MJ พิเศษ
- -TESTP: ใช้รูปแบบการทดสอบที่เน้นการถ่ายภาพ MJ พิเศษ
- -ไทล์: สำหรับ MJ 5 เท่านั้นสร้างภาพซ้ำ ๆ
- --v 1/2/3/4/5: รุ่น MJ ที่จะใช้ (5 ดีที่สุด)
MJ Advanced Prompts
- คุณสามารถฉีดรูปภาพ (หรือรูปภาพ) ลงในจุดเริ่มต้นของพรอมต์เพื่อมีอิทธิพลต่อสไตล์และสีของมัน ดูเอกสารนี้ อัปโหลดรูปภาพไปยังเซิร์ฟเวอร์ Discord ของคุณและคลิกขวาเพื่อรับลิงค์
- การรีมิกซ์ช่วยให้คุณสร้างรูปแบบการเปลี่ยนแปลงรุ่นหัวเรื่องหรือสื่อ ดูเอกสารนี้
- Multi Prompts ช่วยให้ MJ พิจารณาแนวคิดสองแบบขึ้นไปแยกกันเป็นรายบุคคล รุ่น MJ 1-4 และ Niji เท่านั้น ตัวอย่างเช่น "ฮอทดอก" จะสร้างภาพของอาหาร "Hot :: Dog" จะสร้างภาพของสุนัขที่อบอุ่น คุณสามารถเพิ่มน้ำหนักเพื่อแจ้งด้วยเช่นกัน ตัวอย่างเช่น "Hot :: 2 Dog" จะทำให้ภาพสุนัขติดไฟ MJ 1/2/3 ยอมรับน้ำหนักจำนวนเต็ม MJ 4 สามารถรับทศนิยมได้ ดูเอกสารนี้
- การผสมช่วยให้คุณอัปโหลดภาพ 2-5 ภาพเพื่อรวมเข้ากับภาพใหม่ คำสั่ง /Blend อธิบายไว้ที่นี่
Dreamstudio
สิ่งที่ต้องทำ
Dreamstudio (ไม่ใช่ Dreambooth) เป็นแพลตฟอร์มเรือธงจาก บริษัท AI ที่มีเสถียรภาพ เว็บไซต์ของพวกเขาเป็นแพลตฟอร์ม Dreambooth Studio ซึ่งคุณสามารถสร้างภาพได้ มันอยู่ระหว่าง Midjourney และ Webui ในแง่ของการทำงานแบบเปิด ดูเหมือนว่า Dreambooth Studio จะถูกสร้างขึ้นบนแพลตฟอร์ม Invoke.ai ซึ่งคุณสามารถติดตั้งและทำงานในพื้นที่เช่น WebUI
ฝูงชนที่มั่นคง
สิ่งที่ต้องทำ
Horde ที่มั่นคงเป็นความพยายามของชุมชนในการทำให้การแพร่กระจายที่มั่นคงแก่ทุกคน มันใช้งานได้อย่างมากเช่นการ hashing torrenting หรือ bitcoin ซึ่งทุกคนมีส่วนร่วมของพลัง GPU บางส่วนในการสร้างเนื้อหา SD แอพ Horde สามารถเข้าถึงได้ที่นี่
Dreambooth
สิ่งที่ต้องทำ
Dreambooth (ไม่ใช่ Dreamstudio) เป็นการใช้งานเทคนิคการปรับจูนแบบจำลองการแพร่กระจายที่มั่นคงของ Google กล่าวโดยย่อ: คุณสามารถใช้มันเพื่อฝึกอบรมโมเดลด้วยรูปภาพของคุณเอง คุณสามารถใช้โดยตรงจากที่นี่หรือที่นี่ มันซับซ้อนกว่าเพียงแค่ดาวน์โหลดโมเดลและคลิกใน WebUI ในขณะที่คุณกำลังทำงานเพื่อฝึกอบรมและทำให้เป็นรุ่นใหม่ วิดีโอบางรายการสรุปวิธีการทำ:
- Dreambooth Easy Tutorial
- การฝึก Dreambooth 10 นาที
- Webui Dreambooth Extension
และมัคคุเทศก์ที่ดี:
- คำแนะนำของ Reddit Advanced Dreambooth
- Dreambooth ง่าย ๆ
- Dreambooth Dump (ข้อมูลจำนวนมากเลื่อนดูลิงก์)
Google Colab สำหรับ Dreambooth:
นอกจากนี้ยังมีเทรนเนอร์รุ่นที่เรียกว่า EveryDream การเปรียบเทียบอย่างเต็มรูปแบบระหว่าง Dreambooth และ EveryDream สามารถพบได้ที่นี่
การแพร่กระจายวิดีโอ
สิ่งที่ต้องทำ
เป็นไปได้ ณ เดือนมีนาคม-ish 2023 ที่จะใช้การแพร่กระจายที่มั่นคงเพื่อสร้างวิดีโอ ปัจจุบัน (เมษายน 2023) ฟังก์ชั่นค่อนข้างง่ายเนื่องจากวิดีโอถูกสร้างขึ้นจากภาพที่คล้ายกันเฟรมทีละเฟรมทำให้วิดีโอมีรูปลักษณ์ "flipbook" มีสองส่วนขยายหลักสำหรับ webui ที่คุณสามารถใช้:
- แอนิเมชั่น - ง่ายขึ้น
- Deforum - ฟังก์ชั่นเพิ่มเติม
โรงเก็บขยะ
สิ่งที่ฉันไม่รู้มาก แต่ต้องดู
มีกระบวนการที่คุณสามารถติดตามเพื่อให้ได้ผลลัพธ์ที่ดีซ้ำแล้วซ้ำอีก ... สิ่งนี้จะได้รับการปรับปรุงเมื่อเวลาผ่านไป
- สิ่งที่ต้องทำ
- Highres Fix ที่นี่
- การเพิ่มขึ้นทั่ว แต่ที่นี่ส่วนใหญ่
การรวม CHATGPT?
การทำมากกว่า
Dall-E 2
deforum https://deforum.github.io/


