thumb
1.0.0
ไลบรารีการทดสอบพร้อมท์อย่างง่ายสำหรับ LLM
pip install thumb
import os
import thumb
# Set your API key: https://platform.openai.com/account/api-keys
os . environ [ "OPENAI_API_KEY" ] = "YOUR_API_KEY_HERE"
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])แต่ละพรอมต์จะทำงานแบบอะซิงโครนัส 10 ครั้งตามค่าเริ่มต้น ซึ่งเร็วกว่าการเรียกใช้ตามลำดับประมาณ 9 เท่า ใน Jupyter Notebooks ส่วนติดต่อผู้ใช้แบบธรรมดาจะแสดงขึ้นสำหรับการตอบกลับแบบ Blind Rating (คุณจะไม่เห็นว่าข้อความใดที่สร้างการตอบกลับ)
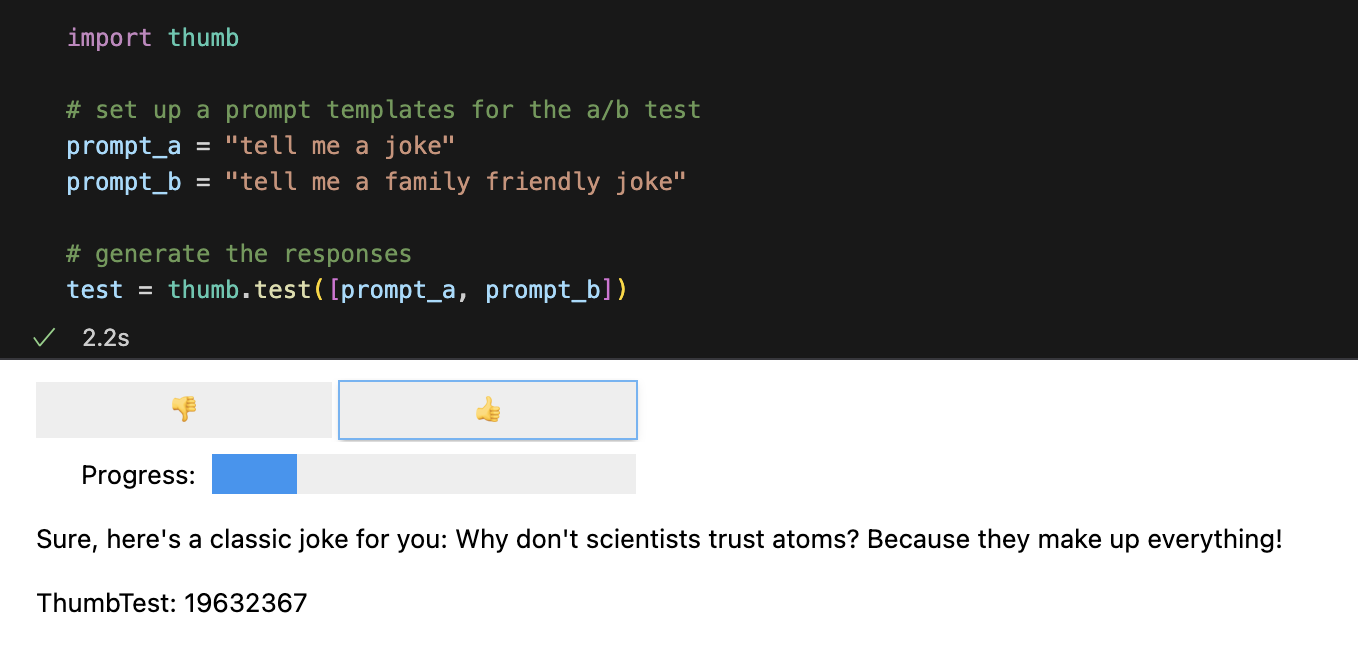
เมื่อคำตอบทั้งหมดได้รับการจัดอันดับแล้ว สถิติประสิทธิภาพต่อไปนี้จะถูกคำนวณแยกย่อยตามเทมเพลตพร้อมท์:
avg_score ของการตอบรับเชิงบวกเป็นเปอร์เซ็นต์ของการวิ่งทั้งหมดavg_tokens : จำนวนโทเค็นที่ใช้กับพรอมต์และการตอบกลับavg_cost : ค่าประมาณของต้นทุนพร้อมท์ในการทำงานโดยเฉลี่ย รายงานแบบง่ายจะแสดงในสมุดบันทึก และข้อมูลทั้งหมดจะถูกบันทึกลงในไฟล์ CSV thumb/ThumbTest-{TestID}.csv

กรณีทดสอบคือเมื่อคุณต้องการทดสอบเทมเพลตพร้อมท์ด้วยตัวแปรอินพุตที่แตกต่างกัน ตัวอย่างเช่น หากคุณต้องการทดสอบเทมเพลตข้อความแจ้งที่มีตัวแปรสำหรับชื่อนักแสดงตลก คุณสามารถตั้งค่ากรณีทดสอบสำหรับนักแสดงตลกที่แตกต่างกันได้
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke in the style of {comedian}"
prompt_b = "tell me a family friendly joke in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "comedian" : "chris rock" },
{ "comedian" : "ricky gervais" },
{ "comedian" : "robin williams" }
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )กรณีการทดสอบทั้งหมดจะถูกเรียกใช้กับเทมเพลตพร้อมท์ทุกรายการ ดังนั้นในตัวอย่างนี้ คุณจะได้รับชุดค่าผสม 6 ชุด (กรณีทดสอบ 3 รายการ x เทมเพลตพร้อมท์ 2 รายการ) ซึ่งจะเรียกใช้แต่ละครั้ง 10 ครั้ง (การเรียก OpenAI ทั้งหมด 60 รายการ) กรณีทดสอบทุกกรณีจะต้องมีค่าสำหรับตัวแปรแต่ละตัวในเทมเพลตพร้อมท์
พรอมต์อาจมีตัวแปรหลายตัวในแต่ละกรณีทดสอบ ตัวอย่างเช่น หากคุณต้องการทดสอบเทมเพลตพร้อมท์ที่มีตัวแปรสำหรับชื่อนักแสดงตลกและหัวข้อเรื่องตลก คุณสามารถตั้งค่ากรณีทดสอบสำหรับนักแสดงตลกและหัวข้อต่างๆ ได้
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke about {subject} in the style of {comedian}"
prompt_b = "tell me a family friendly joke about {subject} in the style of {comedian}"
# set test cases with different input variables
cases = [
{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "joe biden" , "comedian" : "ricky gervais" },
{ "subject" : "donald trump" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "ricky gervais" },
]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )ทุกกรณีได้รับการทดสอบกับทุกการแจ้งเตือน เพื่อให้ได้การเปรียบเทียบประสิทธิภาพของแต่ละการแจ้งเตือนอย่างยุติธรรมโดยให้ข้อมูลอินพุตเดียวกัน ด้วยกรณีทดสอบ 4 กรณีและพร้อมท์ 2 รายการ คุณจะได้รับชุดค่าผสม 8 ชุด (กรณีทดสอบ 4 กรณี x เทมเพลตพร้อมท์ 2 รายการ) ซึ่งแต่ละกรณีจะทำงาน 10 ครั้ง (การเรียก OpenAI ทั้งหมด 80 รายการ)
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], models = [ "gpt-4" , "gpt-3.5-turbo" ])การดำเนินการนี้จะเรียกใช้แต่ละพร้อมท์กับแต่ละรุ่น เพื่อให้ได้การเปรียบเทียบประสิทธิภาพของแต่ละพร้อมท์อย่างยุติธรรมโดยให้ข้อมูลอินพุตเดียวกัน ด้วย 2 พร้อมท์และ 2 โมเดล คุณจะได้รับ 4 ชุดค่าผสม (2 พร้อมท์ x 2 รุ่น) ซึ่งแต่ละอันจะทำงาน 10 ครั้ง (การโทรทั้งหมด 40 ครั้งไปยัง OpenAI)
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , "tell me a funny joke about {subject}" ]
prompt_b = [ system_message , "tell me a hillarious joke {subject}" ]
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases ) พรอมต์อาจเป็นสตริงหรืออาร์เรย์ของสตริงก็ได้ หากพรอมต์เป็นอาร์เรย์ สตริงแรกจะถูกใช้เป็นข้อความระบบ และพรอมต์ที่เหลือจะสลับระหว่างข้อความ Human และ Assistant ( [system, human, ai, human, ai, ...] ) สิ่งนี้มีประโยชน์สำหรับการทดสอบพร้อมท์ที่มีข้อความของระบบ หรือใช้การอุ่นเครื่องล่วงหน้า (การแทรกข้อความก่อนหน้าในการแชทเพื่อนำทาง AI ไปสู่พฤติกรรมที่ต้องการ)
# set up a prompt templates for the a/b test
system_message = "You are the comedian {comedian}"
prompt_a = [ system_message , # system
"tell me a funny joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
prompt_b = [ system_message , # system
"tell me a hillarious joke about {subject}" , # human
"Sorry, as an AI language model, I am not capable of humor" , # assistant
"That's fine just try your best" ] # human
cases = [{ "subject" : "joe biden" , "comedian" : "chris rock" },
{ "subject" : "donald trump" , "comedian" : "chris rock" }]
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ], cases )เมื่อการทดสอบเสร็จสิ้น คุณจะได้รับรายงานการประเมินฉบับเต็ม โดยแบ่งตาม PID, CID และรุ่น รวมถึงรายงานโดยรวมที่แยกย่อยตามชุดค่าผสมทั้งหมด หากคุณทดสอบเพียงรุ่นเดียวหรือหนึ่งกรณี รายละเอียดเหล่านี้จะหายไป รายงานจะแสดงคีย์ที่ด้านล่างเพื่อดูว่า ID ใดสอดคล้องกับพรอมต์หรือตัวพิมพ์ใด
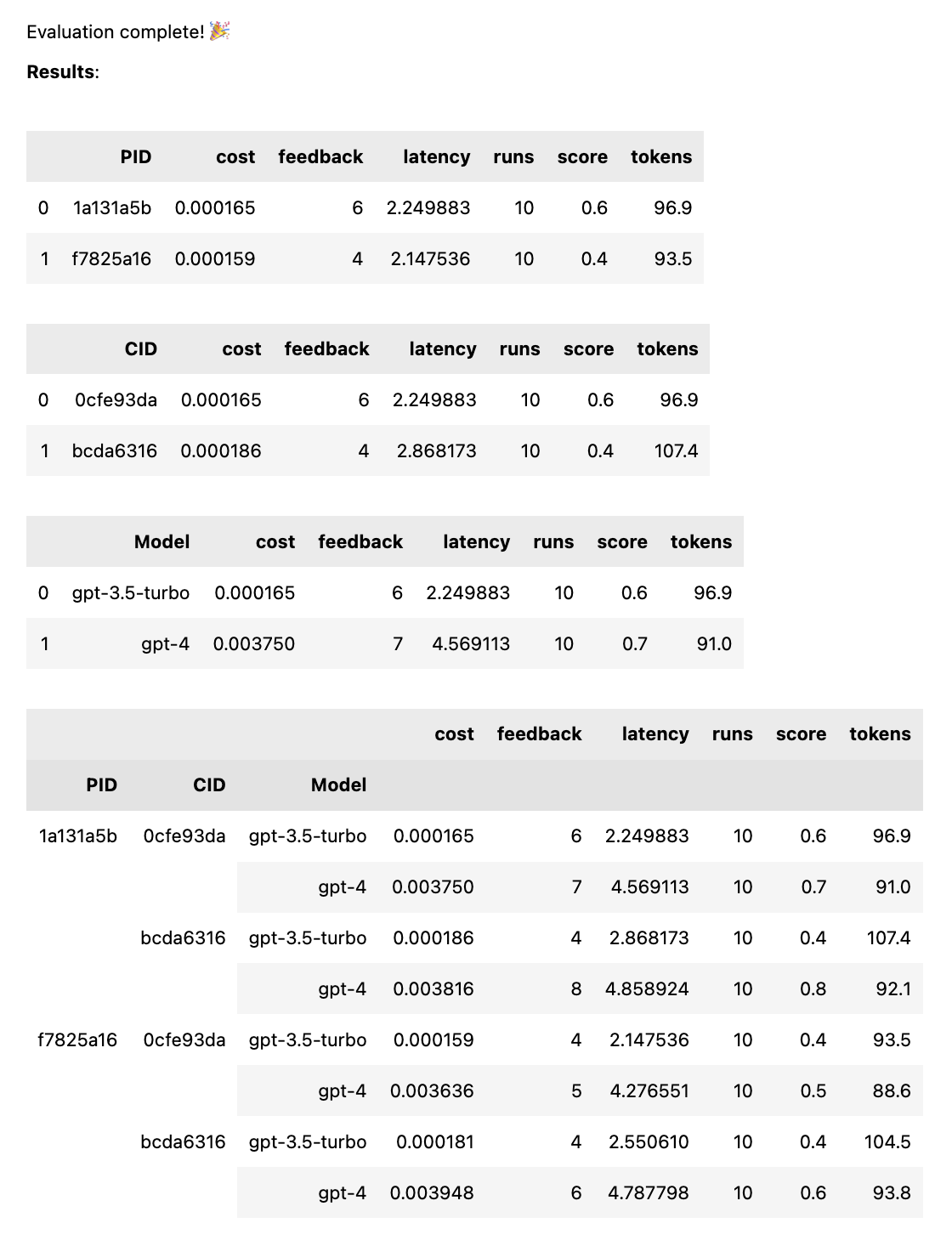
ฟังก์ชัน thumb.test รับพารามิเตอร์ต่อไปนี้:
None )10 )gpt-3.5-turbo ])True ) หากคุณมีการทดสอบ 10 ครั้งพร้อมเทมเพลตพร้อมท์ 2 รายการและกรณีทดสอบ 3 รายการ นั่นคือการเรียก OpenAI 10 x 2 x 3 = 60 ระวัง: โดยเฉพาะกับ GPT-4 ค่าใช้จ่ายอาจเพิ่มขึ้นอย่างรวดเร็ว!
การติดตาม Langchain ไปยัง LangSmith จะถูกเปิดใช้งานโดยอัตโนมัติหาก LANGCHAIN_API_KEY ถูกตั้งค่าเป็นตัวแปรสภาพแวดล้อม (ไม่บังคับ)
ฟังก์ชัน .test() ส่งคืนวัตถุ ThumbTest คุณสามารถเพิ่มพร้อมท์หรือกรณีอื่นๆ ในการทดสอบ หรือเรียกใช้ครั้งเพิ่มเติมได้ คุณยังสามารถสร้าง ประเมิน และส่งออกข้อมูลการทดสอบได้ตลอดเวลา
# set up a prompt templates for the a/b test
prompt_a = "tell me a joke"
prompt_b = "tell me a family friendly joke"
# generate the responses
test = thumb . test ([ prompt_a , prompt_b ])
# add more prompts
test . add_prompts ([ "tell me a knock knock joke" , "tell me a knock knock joke about {subject}" ])
# add more cases
test . add_cases ([{ "subject" : "joe biden" }, { "subject" : "donald trump" }])
# run each prompt and case 5 more times
test . add_runs ( 5 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () เทมเพลตพร้อมท์ทุกรายการจะได้รับข้อมูลอินพุตเดียวกันจากทุกกรณีการทดสอบ แต่พร้อมท์ไม่จำเป็นต้องใช้ตัวแปรทั้งหมดในกรณีทดสอบ ดังตัวอย่างข้างต้น พรอมต์ tell me a knock knock joke ไม่ได้ใช้ตัวแปร subject แต่ยังคงถูกสร้างขึ้นหนึ่งครั้ง (โดยไม่มีตัวแปร) สำหรับแต่ละกรณีทดสอบ
ข้อมูลการทดสอบจะถูกแคชไว้ในไฟล์ JSON ในเครื่อง thumb/.cache/{TestID}.json หลังจากการรันทุกชุดถูกสร้างขึ้นสำหรับชุดพร้อมท์และตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ หากการทดสอบของคุณถูกขัดจังหวะ หรือคุณต้องการเพิ่มเข้าไป คุณสามารถใช้ฟังก์ชัน thumb.load เพื่อโหลดข้อมูลการทดสอบจากแคช
# load a previous test
test_id = "abcd1234" # replace with your test id
test = thumb . load ( f"thumb/.cache/ { test_id } .json" )
# run each prompt and case 2 more times
test . add_runs ( 2 )
# generate the responses
test . generate ()
# rate the responses
test . evaluate ()
# export the test data for analysis
test . export_to_csv () การเรียกใช้ทุกครั้งสำหรับการรวมกันของ prompt และ case จะถูกจัดเก็บไว้ในออบเจ็กต์ (และแคช) ดังนั้นการเรียก test.generate() อีกครั้งจะไม่สร้างการตอบกลับใหม่ใดๆ หากไม่ได้เพิ่มพร้อมท์ เคส หรือการรันเพิ่มเติม ในทำนองเดียวกัน การเรียก test.evaluate() อีกครั้งจะไม่ให้คะแนนคำตอบที่คุณให้คะแนนไว้แล้วอีกครั้ง และจะแสดงผลอีกครั้งหากการทดสอบสิ้นสุดลง
ความแตกต่างระหว่างคนที่แค่เล่นกับ ChatGPT กับคนที่ใช้ AI ในการผลิตคือการประเมิน LLM ตอบสนองโดยไม่ได้กำหนดไว้ ดังนั้นการทดสอบว่าผลลัพธ์จะเป็นอย่างไรเมื่อขยายขนาดในสถานการณ์ที่หลากหลายจึงเป็นสิ่งสำคัญ หากไม่มีกรอบการประเมิน คุณจะเดาสุ่มสี่สุ่มห้าว่าอะไรได้ผลในข้อความแจ้งของคุณ (หรือไม่)
วิศวกรที่พร้อมรับคำสั่งอย่างจริงจังกำลังทดสอบและเรียนรู้ว่าอินพุตใดนำไปสู่ผลลัพธ์ที่เป็นประโยชน์หรือเป็นที่ต้องการ อย่างเชื่อถือได้และในวงกว้าง กระบวนการนี้เรียกว่าการปรับให้เหมาะสมทันที และมีลักษณะดังนี้:
การทดสอบด้วยนิ้วหัวแม่มือช่วยเติมเต็มช่องว่างระหว่างกลไกการประเมินระดับมืออาชีพขนาดใหญ่ และการกระตุ้นแบบสุ่มสี่สุ่มห้าผ่านการลองผิดลองถูก หากคุณกำลังเปลี่ยนพรอมต์ไปสู่สภาพแวดล้อมการใช้งานจริง การใช้ thumb เพื่อทดสอบพรอมต์สามารถช่วยให้คุณจับประเด็นที่ล้ำหน้า และรับคำติชมจากผู้ใช้หรือทีมตั้งแต่เนิ่นๆ เกี่ยวกับผลลัพธ์
คนเหล่านี้สร้าง thumb สนุกสนานในเวลาว่าง -
ค้อน-ภูเขา |


