llm data annotation
1.0.0
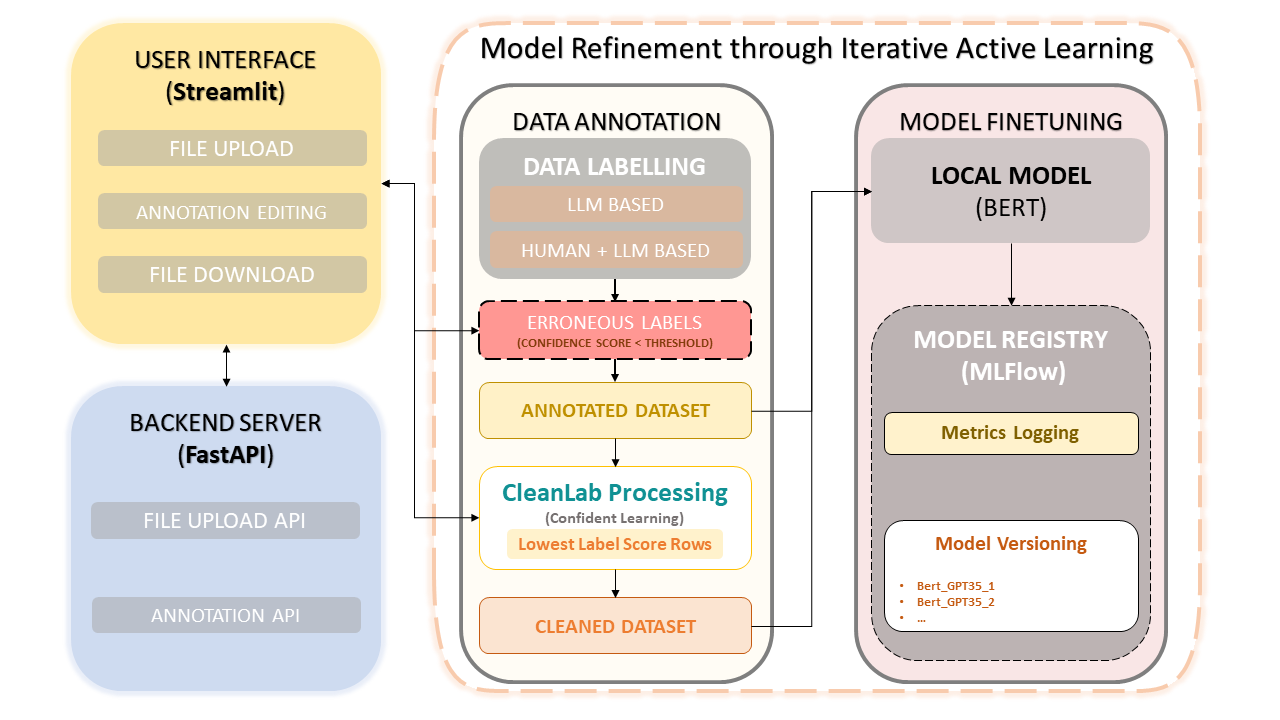
เฟรมเวิร์กนี้รวมความเชี่ยวชาญของมนุษย์เข้ากับประสิทธิภาพของ Large Language Models (LLM) เช่น GPT-3.5 ของ OpenAI เพื่อลดความซับซ้อนของคำอธิบายประกอบชุดข้อมูลและการปรับปรุงโมเดล วิธีการทำซ้ำช่วยให้มั่นใจได้ถึงการปรับปรุงคุณภาพข้อมูลอย่างต่อเนื่อง และด้วยเหตุนี้ ประสิทธิภาพของแบบจำลองจึงได้รับการปรับแต่งอย่างละเอียดโดยใช้ข้อมูลนี้ ซึ่งไม่เพียงช่วยประหยัดเวลา แต่ยังช่วยให้สามารถสร้าง LLM แบบกำหนดเองที่ใช้ประโยชน์จากทั้งคำอธิบายประกอบที่เป็นมนุษย์และความแม่นยำบน LLM
การอัปโหลดชุดข้อมูลและคำอธิบายประกอบ
การแก้ไขคำอธิบายประกอบด้วยตนเอง
CleanLab: แนวทางการเรียนรู้อย่างมั่นใจ
การกำหนดเวอร์ชันและการบันทึกข้อมูล
การฝึกอบรมแบบจำลอง
pip install -r requirements.txtเริ่มแบ็กเอนด์ FastAPI :
uvicorn app:app --reloadเรียกใช้แอป Streamlit :
streamlit run frontend.pyเปิดใช้ MLflow UI : หากต้องการดูโมเดล เมตริก และโมเดลที่ลงทะเบียน คุณสามารถเข้าถึง MLflow UI ด้วยคำสั่งต่อไปนี้:
mlflow uiเข้าถึงลิงก์ที่ให้ไว้ในเว็บเบราว์เซอร์ของคุณ :
http://127.0.0.1:5000ปฏิบัติตามคำแนะนำบนหน้าจอ เพื่ออัปโหลด ใส่คำอธิบายประกอบ แก้ไข และฝึกชุดข้อมูลของคุณ
การเรียนรู้อย่างมั่นใจกลายเป็นเทคนิคที่ก้าวล้ำในการเรียนรู้แบบมีผู้สอนและการกำกับดูแลที่อ่อนแอ โดยมีจุดมุ่งหมายเพื่อระบุลักษณะของสัญญาณรบกวนของฉลาก ค้นหาข้อผิดพลาดของฉลาก และการเรียนรู้อย่างมีประสิทธิภาพด้วยฉลากที่มีสัญญาณรบกวน ด้วยการตัดข้อมูลที่มีสัญญาณรบกวนและจัดอันดับตัวอย่างเพื่อฝึกด้วยความมั่นใจ วิธีการนี้ทำให้มั่นใจได้ว่าชุดข้อมูลที่สะอาดและเชื่อถือได้ ช่วยเพิ่มประสิทธิภาพการทำงานของโมเดลโดยรวม
โครงการนี้เป็นโอเพ่นซอร์สภายใต้ใบอนุญาต MIT


