Tutorbot Spock
1.0.0
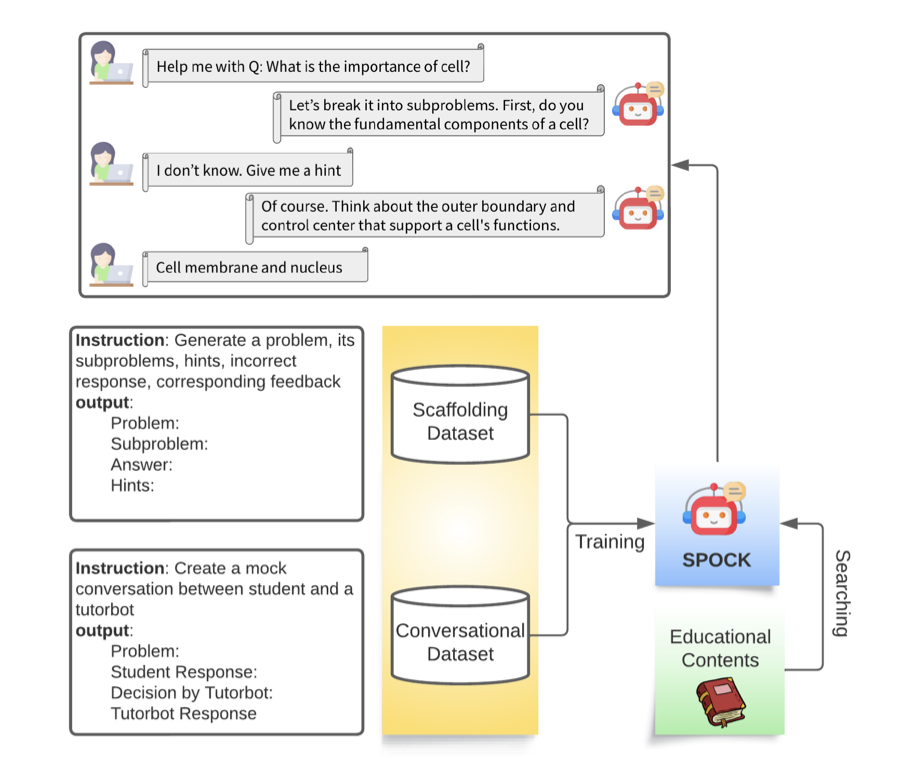
CLASS: กรอบการออกแบบสำหรับการสร้างระบบการสอนอัจฉริยะตามหลักวิทยาศาสตร์การเรียนรู้ (EMNLP 2023)
ชาแชงค์ ซอนการ์, ไนหมิง หลิว, เดบชีลา บาซู มัลลิค, ริชาร์ด จี. บารานิอัก
บทความ: https://arxiv.org/abs/2305.13272
สาขา: คลาส
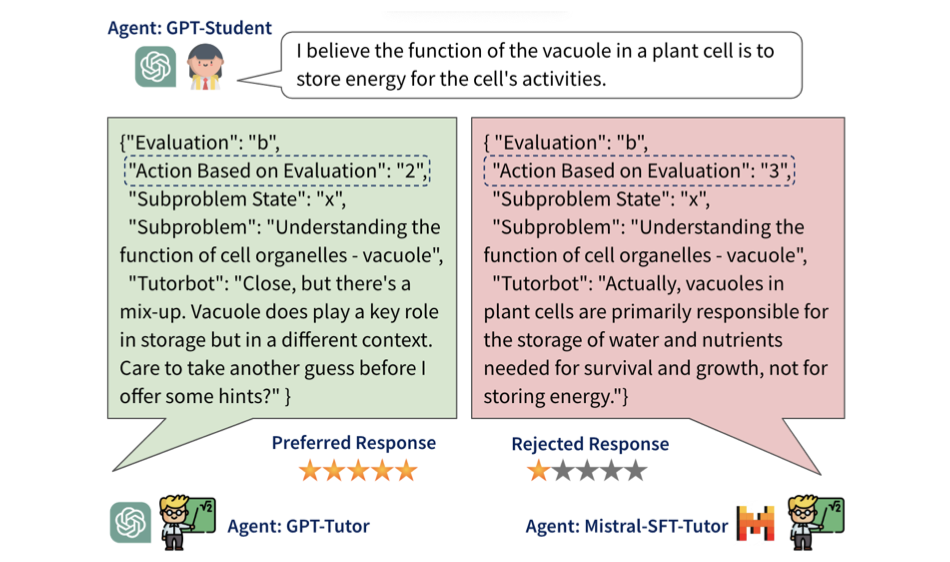
การจัดแนวการสอนของแบบจำลองภาษาขนาดใหญ่ (EMNLP 2024)
Shashank Sonkar*, Kangqi Ni*, Sapana Chaudhary, Richard G. Baraniuk
บทความ: https://arxiv.org/abs/2402.05000
สาขา: หลัก
การซื้อคืนนี้มีจุดมุ่งหมายเพื่อพัฒนาตัวแทนกวดวิชาอัจฉริยะที่มีประสิทธิภาพ ซึ่งช่วยให้นักเรียนพัฒนาทักษะการคิดอย่างมีวิจารณญาณและการแก้ปัญหา
โปรดดู scripts/run.sh เป็นตัวอย่าง ซึ่งดำเนินการฝึกอบรมและประเมินผลรุ่นที่เลือกโดยใช้ GPU 4*A100 หากต้องการรันตัวอย่างนี้โดยไม่มีการฝึก ให้ดาวน์โหลดโมเดลจากส่วนด้านล่างและอ้างอิงถึง scripts/run_no-train.sh ส่วนย่อยต่อไปนี้จะแจกแจง scripts/run.sh พร้อมคำอธิบายโดยละเอียดเพิ่มเติม
การฝึกอบรมและการประเมินผลใช้ bio-dataset-1.json, bio-dataset-2.json, bio-dataset-3.json และ bio-dataset-ppl.json จากโฟลเดอร์ชุดข้อมูล แต่ละรายการมีการสนทนาจำลองระหว่างนักเรียนและครูสอนพิเศษตามแนวคิดทางชีววิทยาที่สร้างจาก GPT-4 ของ OpenAI จากนั้นข้อมูลเหล่านี้จะถูกประมวลผลล่วงหน้าเป็นรูปแบบที่จำเป็นสำหรับชุดข้อมูลการฝึกอบรมและการประเมินผล โปรดดูที่สาขา CLASS สำหรับคำแนะนำในการสร้างข้อมูลเหล่านี้
ตั้งค่าพารามิเตอร์ผู้ใช้:
FULL_MODEL_PATH="meta-llama/Meta-Llama-3.1-8B-Instruct"
MODEL_DIR="models"
DATA_DIR="datasets"
SFT_OPTION="transformers" # choices: ["transformers", "fastchat"]
ALGO="dpo" # choices: ["dpo", "ipo", "kto"]
BETA=0.1 # choices: [0.0 - 1.0]
ข้อมูลประมวลผลล่วงหน้า:
python src/preprocess_sft_data.py --data_dir $DATA_DIR
เรามี 2 ตัวเลือกสำหรับ SFT: (1) Transformers (2) FastChat
(1) รัน SFT ด้วย Transformers:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 src/train/train_sft.py
--model_path $FULL_MODEL_PATH
--train_dataset_path $SFT_DATASET_PATH
--eval_dataset_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--max_seq_length 4096
--gradient_checkpointing
(2) เรียกใช้ SFT ด้วย FastChat:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 FastChat/fastchat/train/train.py
--model_name_or_path $FULL_MODEL_PATH
--data_path $SFT_DATASET_PATH
--eval_data_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16 True
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--tf32 True
--model_max_length 4096
--gradient_checkpointing True
สร้างข้อมูลการตั้งค่า:
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-dpo --test_dataset_path $DPO_DATASET_PATH --batch_size 256
python src/preprocess/preprocess_dpo_data.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-dpo/responses.csv --data_file $DPO_PREF_DATASET_PATH
เรียกใช้การจัดตำแหน่งการตั้งค่า:
DPO_MODEL_PATH="${MODEL_DIR}_dpo/${MODEL_NAME}_bio-tutor_${ALGO}"
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --config_file=ds_config/deepspeed_zero3.yaml --num_processes=4 train/train_dpo.py
--train_data $DPO_PREF_DATASET_PATH
--model_path $SFT_MODEL_PATH
--output_dir $DPO_MODEL_PATH
--beta $BETA
--loss $ALGO
--gradient_checkpointing
--bf16
--gradient_accumulation_steps 4
--per_device_train_batch_size 2
--num_train_epochs 3
ประเมินความแม่นยำและคะแนน F1 ของ SFT และโมเดล Aligned:
# Generate responses from the SFT model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Generate responses from the Aligned model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $DPO_MODEL_PATH --output_dir ${DPO_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Evaluate the SFT model
echo "Metrics of the SFT Model:"
python src/evaluate/evaluate_responses.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-eval/responses.csv
# Evaluate the Aligned model
echo "Metrics of the RL Model:"
python src/evaluate/evaluate_responses.py --response_file ${DPO_MODEL_PATH}/final_checkpoint-eval/responses.csv
ประเมิน ppl ของ SFT และโมเดล Aligned:
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $SFT_MODEL_PATH
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $DPO_MODEL_PATH
เพื่อให้เข้าถึงโมเดลได้ง่ายขึ้น ให้ดาวน์โหลดจาก Hugging Face
รุ่น SFT:
โมเดลที่สอดคล้อง:
หากคุณพบว่างานของเรามีประโยชน์ โปรดอ้างอิง:
@misc{sonkar2023classdesignframeworkbuilding,
title={CLASS: A Design Framework for building Intelligent Tutoring Systems based on Learning Science principles},
author={Shashank Sonkar and Naiming Liu and Debshila Basu Mallick and Richard G. Baraniuk},
year={2023},
eprint={2305.13272},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2305.13272},
}
@misc{sonkar2024pedagogical,
title={Pedagogical Alignment of Large Language Models},
author={Shashank Sonkar and Kangqi Ni and Sapana Chaudhary and Richard G. Baraniuk},
year={2024},
eprint={2402.05000},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2402.05000},
}


