CDial GPT
1.0.0
โปรเจ็กต์นี้จัดเตรียมชุดข้อมูลการสนทนาภาษาจีนขนาดใหญ่และแบบจำลองก่อนการฝึกอบรมการสนทนาภาษาจีน (แบบจำลอง GPT ภาษาจีน) ในชุดข้อมูลนี้ สำหรับข้อมูลเพิ่มเติม โปรดดูเอกสารของเรา
โค้ดของโปรเจ็กต์นี้ได้รับการแก้ไขจาก TransferTransfo และใช้ไลบรารี Transformers เวอร์ชัน HuggingFace Pytorch ซึ่งสามารถใช้สำหรับการฝึกอบรมล่วงหน้าและการปรับแต่งอย่างละเอียด
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" ชุดข้อมูล LCCC (การสนทนาภาษาจีนขนาดใหญ่) ที่เรานำเสนอส่วนใหญ่ประกอบด้วยสองส่วน: LCCC-base (Baidu Netdisk, Google Drive) และ LCCC-large (Baidu Netdisk, Google Drive) ตรวจสอบคุณภาพของข้อมูลการสนทนาในชุดข้อมูลนี้ กระบวนการกรองข้อมูลนี้ประกอบด้วยชุดกฎแบบแมนนวลและตัวแยกประเภทหลายตัวตามอัลกอริธึมการเรียนรู้ของเครื่อง สัญญาณรบกวนที่เรากรองออกได้แก่: คำหยาบคาย ตัวอักษรพิเศษ การแสดงออกทางสีหน้า ประโยคที่ผิดไวยากรณ์ บทสนทนาที่ไม่เกี่ยวข้องกับบริบท ฯลฯ
สถิติของชุดข้อมูลนี้แสดงไว้ในตารางด้านล่าง ในหมู่พวกเขา เราเรียกบทสนทนาที่มีเพียงสองประโยคว่า "บทสนทนาเลี้ยวเดียว" และเราเรียกบทสนทนาที่มีมากกว่าสองประโยคว่า "บทสนทนาหลายเลี้ยว" ใช้การแบ่งส่วนคำของ Jieba เมื่อนับขนาดของรายการคำ
| LCCC-ฐาน (ไป่ตู้คลาวด์ดิสก์, Google ไดรฟ์) | การสนทนาแบบเลี้ยวเดียว | บทสนทนาหลายรอบ |
|---|---|---|
| บทสนทนาทั้งหมดเปลี่ยนไป | 3,354,232 | 3,466,274 |
| ประโยคบทสนทนาทั้งหมด | 6,708,464 | 13,365,256 |
| จำนวนอักขระทั้งหมด | 68,559,367 | 163,690,569 |
| ขนาดคำศัพท์ | 372,063 | 666,931 |
| จำนวนคำเฉลี่ยในประโยคสนทนา | 6.79 | 8.32 |
| จำนวนประโยคเฉลี่ยต่อรอบการสนทนา | 2 | 3.86 |
โปรดทราบว่ากระบวนการทำความสะอาดชุดข้อมูลฐาน LCCC นั้นเข้มงวดกว่าชุดข้อมูล LCCC ขนาดใหญ่ ดังนั้นขนาดของมันจึงเล็กลงเช่นกัน
| LCCC-ขนาดใหญ่ (ไป่ตู้คลาวด์ดิสก์, Google ไดรฟ์) | การสนทนาแบบเลี้ยวเดียว | บทสนทนาหลายรอบ |
|---|---|---|
| บทสนทนาทั้งหมดเปลี่ยนไป | 7,273,804 | 4,733,955 |
| ประโยคบทสนทนาทั้งหมด | 14,547,608 | 18,341,167 |
| จำนวนอักขระทั้งหมด | 162,301,556 | 217,776,649 |
| ขนาดคำศัพท์ | 662,514 | 690,027 |
| จำนวนคำประเมินสำหรับประโยคสนทนา | 7.45 | 8.14 |
| จำนวนประโยคเฉลี่ยต่อรอบการสนทนา | 2 | 3.87 |
ข้อมูลการสนทนาดั้งเดิมในชุดข้อมูลฐาน LCCC มาจากการสนทนา Weibo และข้อมูลการสนทนาดั้งเดิมในชุดข้อมูลขนาดใหญ่ของ LCCC ถูกรวมเข้ากับชุดข้อมูลการสนทนาแบบโอเพ่นซอร์สอื่น ๆ ที่อิงจากการสนทนา Weibo เหล่านี้:
| ชุดข้อมูล | บทสนทนาทั้งหมดเปลี่ยนไป | ตัวอย่างการสนทนา |
|---|---|---|
| เว่ยป๋อ คอร์ปัส | 79ม | ถาม: ฉันกินหม้อไฟเจ็ดหรือแปดครั้งในเฉิงตู ฉงชิ่ง A: ฮ่าฮ่าฮ่าฮ่า! ปากฉันก็จะเน่าแล้ว! |
| พีทีที กอสซิปิง คอร์ปัส | 0.4M | ถาม: ทำไมชาวบ้านถึงรังแกนักเรียนมัธยมปลายอยู่เสมอ QQ A: ถ้าคุณคิดว่าถ้าคุณเลือกวิชาที่ดี คุณจะกลายเป็นบิล เกตส์ คุณก็อาจจะลาออกจากโรงเรียนได้เช่นกัน |
| คลังคำบรรยาย | 2.74ล้าน | ถาม: ผู้คนในปักกิ่งโอเปร่าไม่มีอิสระ ตอบ: พวกเขาขังคนไว้ในกรง |
| เสี่ยวหวงจี่คอร์ปัส | 0.45ม | ถาม: คุณเคยมีความรักไหม A: คุณเคยมีความรักไหม โอ้ย อย่าพูดถึงเลย เสียใจ... |
| เทียบา คอร์ปัส | 2.32M | ถาม: แถวหน้า แฟน ๆ ของ Lu ทุกคนลุกขึ้นใช่ไหม A: ชื่อบอกว่าแอสซิสต์ แต่หลังจากดูบอลแล้ว มันเป็นการประชดที่มีชีวิตจริงๆ |
| ชิงหยุน คอร์ปัส | 0.1M | ถาม: ดูเหมือนว่าคุณจะรักเงินมาก A: โอ้จริงเหรอ? ถ้าอย่างนั้นคุณก็เกือบจะถึงที่นั่นแล้ว |
| คลังการสนทนา Douban | 0.5M | ถาม: เรียนภาษาอังกฤษแบบบริสุทธิ์ด้วยการชมภาพยนตร์ต้นฉบับภาษาอังกฤษ A: ฉันรักเพื่อนและเคยดูมาหลายครั้งแล้ว ถาม: ฉันเกือบจะหมดแรงดูซีดีแผ่นเดิมแล้ว A: ถ้าอย่างนั้นภาษาอังกฤษของคุณก็น่าจะค่อนข้างดีแล้วตอนนี้ |
| คลังการสนทนาทางอิเล็กทรอนิกส์ | 0.5M | ถาม: นี่จะเป็นข้อตกลงที่ดีหรือไม่ ตอบ: ยังไม่มี ถาม: จะมีให้บริการในอนาคตหรือไม่ ตอบ: ไม่แน่ใจ โปรดใส่ใจเรา |
| แชทคอร์ปัสของจีน | 0.5M | ถาม: วันนี้ขาของฉันไร้ประโยชน์ พวกคุณฉลองวันหยุด ดังนั้นฉันจะย้ายอิฐด้วยซ้ำ ไม่มีแฟน วันหยุดไหนก็เหมือนกัน |
นอกจากนี้เรายังจัดเตรียมแบบจำลองก่อนการฝึกอบรมของจีน (แบบจำลอง GPT ของจีน) กระบวนการก่อนการฝึกอบรมของแบบจำลองเหล่านี้แบ่งออกเป็นสองขั้นตอน ขั้นแรกการฝึกอบรมล่วงหน้าเกี่ยวกับข้อมูลนวนิยายจีน และจากนั้น การฝึกอบรมล่วงหน้าเกี่ยวกับข้อมูล LCCC ชุด.
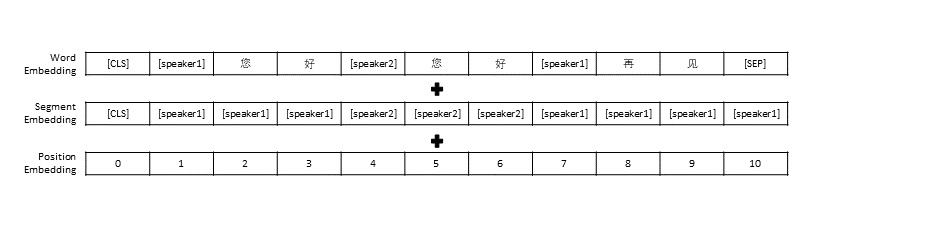
เราปฏิบัติตามการตั้งค่าการประมวลผลข้อมูลล่วงหน้าใน TransferTransfo ซึ่งแยกประวัติการสนทนาทั้งหมดเป็นประโยคเดียว จากนั้นใช้ประโยคนี้เป็นอินพุตของโมเดลเพื่อคาดเดาการตอบกลับการสนทนา นอกเหนือจากการแสดงเวกเตอร์ของแต่ละคำแล้ว ข้อมูลในแบบจำลองของเรายังรวมถึงการแสดงเวกเตอร์ของผู้พูดและการแสดงเวกเตอร์ตำแหน่งด้วย
| โมเดลที่ผ่านการฝึกอบรมมาแล้ว | จำนวนพารามิเตอร์ | ข้อมูลที่ใช้สำหรับการฝึกอบรมล่วงหน้า | อธิบาย |
|---|---|---|---|
| จีพีที นวนิยาย | 95.5ม | ข้อมูลนวนิยายจีน | โมเดล GPT ที่ได้รับการฝึกอบรมล่วงหน้าของจีนสร้างขึ้นจากข้อมูลนวนิยายจีน (ข้อมูลใหม่ประกอบด้วยคำทั้งหมด 1.3B) |
| CDial-GPT LCCC-ฐาน | 95.5ม | LCCC-ฐาน | อ้างอิงจาก GPT Novel ให้ใช้โมเดล GPT ที่ผ่านการฝึกอบรมภาษาจีนล่วงหน้าซึ่งฝึกฝนโดยฐาน LCCC |
| CDial-GPT2 LCCC-ฐาน | 95.5ม | LCCC-ฐาน | อ้างอิงจาก GPT Novel ให้ใช้โมเดล GPT2 ที่ผ่านการฝึกอบรมภาษาจีนล่วงหน้าซึ่งฝึกฝนด้วยฐาน LCCC |
| CDial-GPT LCCC-ขนาดใหญ่ | 95.5ม | LCCC-ขนาดใหญ่ | อ้างอิงจาก GPT Novel ให้ใช้โมเดล GPT ที่ผ่านการฝึกอบรมล่วงหน้าของจีนซึ่งฝึกอบรมโดย LCCC-large |
ติดตั้งโดยตรงจากแหล่งที่มา:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
ขั้นตอนที่ 1: เตรียมชุดข้อมูลที่จำเป็นสำหรับโมเดลก่อนการฝึกอบรมและการปรับแต่งอย่างละเอียด (เช่น ชุดข้อมูล STC หรือข้อมูลของเล่น "data/toy_data.json" ในไดเรกทอรีโครงการ โปรดทราบว่าหากข้อมูลมีภาษาอังกฤษ จะต้องแยกออกจากกัน ด้วยตัวอักษร เช่น สวัสดี)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ปล: คุณสามารถใช้ลิงก์ต่อไปนี้เพื่อดาวน์โหลดชุดการฝึกอบรมและชุดการตรวจสอบของ STC (Baidu Cloud Disk, Google Drive)
ขั้นตอนที่ 2: ฝึกโมเดล
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
หรือ
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
นอกจากนี้ พารามิเตอร์ train_path ยังมีให้ในสคริปต์การฝึกอบรมของเรา ซึ่งอนุญาตให้ผู้ใช้อ่านไฟล์ข้อความธรรมดาเป็นชิ้นๆ หากคุณใช้ระบบที่มีหน่วยความจำจำกัด ให้พิจารณาใช้พารามิเตอร์นี้เพื่ออ่านข้อมูลการฝึก หากคุณใช้ train_path คุณจะต้องปล่อย data_path ว่างไว้
ขั้นตอนที่ 3: สร้างข้อความ
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
PS: คุณสามารถใช้ลิงก์ต่อไปนี้เพื่อดาวน์โหลดชุดทดสอบ STC (Baidu Cloud Disk, Google Drive)
พารามิเตอร์สคริปต์การฝึกอบรม
| พารามิเตอร์ | พิมพ์ | ค่าเริ่มต้น | อธิบาย |
|---|---|---|---|
| model_จุดตรวจสอบ | STR | - | เส้นทางหรือ URL ของไฟล์โมเดล (ไดเร็กทอรีของโมเดลก่อนการฝึกและไฟล์ config/vocab) |
| ฝึกอบรมล่วงหน้า | บูล | เท็จ | หากเป็นเท็จ ให้ฝึกโมเดลตั้งแต่เริ่มต้น |
| ข้อมูล_เส้นทาง | STR | - | เส้นทางของชุดข้อมูล |
| ชุดข้อมูล_cache | STR | เริ่มต้น = "dataset_cache" | เส้นทางหรือ URL ของแคชชุดข้อมูล |
| รถไฟ_เส้นทาง | STR | - | เส้นทางของชุดการฝึกสำหรับชุดข้อมูลแบบกระจาย |
| valid_path | STR | - | เส้นทางของชุดการตรวจสอบความถูกต้องสำหรับชุดข้อมูลแบบกระจาย |
| log_file | STR | - | บันทึกการส่งออกไปยังไฟล์ภายใต้เส้นทางนี้ |
| num_workers | ภายใน | 1 | จำนวนกระบวนการย่อยสำหรับการโหลดข้อมูล |
| n_ยุค | ภายใน | 70 | จำนวนยุคการฝึกอบรม |
| train_batch_size | ภายใน | 8 | ขนาดชุดสำหรับการฝึก |
| valid_batch_size | ภายใน | 8 | ขนาดแบทช์สำหรับการตรวจสอบ |
| max_history | ภายใน | 15 | จำนวนการแลกเปลี่ยนก่อนหน้าที่จะเก็บไว้ในประวัติศาสตร์ |
| กำหนดการ | STR | "โนม" | วิธีการเพิ่มประสิทธิภาพ |
| n_emd | ภายใน | 768 | จำนวน n_emd ในไฟล์ปรับแต่ง (สำหรับ noam) |
| eval_before_start | บูล | เท็จ | หากเป็นจริง ให้เริ่มการประเมินก่อนการฝึกอบรม |
| วอร์มอัพ_สเต็ปส์ | ภายใน | 5,000 | ขั้นตอนการอุ่นเครื่อง |
| valid_steps | ภายใน | 0 | ดำเนินการตรวจสอบความถูกต้องทุกขั้นตอน X หากไม่ใช่ 0 |
| การไล่ระดับสี_การสะสม_ขั้นตอน | ภายใน | 64 | สะสมการไล่ระดับสีในหลายขั้นตอน |
| max_norm | ลอย | 1.0 | การตัดบรรทัดฐานการไล่ระดับสี |
| อุปกรณ์ | STR | "cuda" ถ้า torch.cuda.is_available() อย่างอื่น "cpu" | อุปกรณ์ (cuda หรือ cpu) |
| fp16 | STR | - | ตั้งค่าเป็น O0, O1, O2 หรือ O3 สำหรับการฝึก fp16 (ดูเอกสารประกอบ apex) |
| local_rank | ภายใน | -1 | อันดับท้องถิ่นสำหรับการฝึกอบรมแบบกระจาย (-1: ไม่กระจาย) |
เราประเมินโมเดลการฝึกอบรมล่วงหน้าการสนทนาที่ปรับแต่งอย่างละเอียดโดยใช้ชุดข้อมูล STC (ชุดการฝึกอบรม/ชุดตรวจสอบความถูกต้อง (Baidu Netdisk, Google Drive), ชุดทดสอบ (Baidu Netdisk, Google Drive)) การตอบสนองทั้งหมดถูกสุ่มตัวอย่างโดยใช้การสุ่มตัวอย่างนิวเคลียส (p=0.9, อุณหภูมิ=0.7)
| แบบอย่าง | ขนาดโมเดล | ปปล | เบลอ-2 | เบลอ-4 | เขต-1 | เขต-2 | การจับคู่โลภ | การฝังค่าเฉลี่ย |
|---|---|---|---|---|---|---|---|---|
| เรียน-Seq2seq | 73ม | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| หม้อแปลงไฟฟ้า | 113ม | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-คุยกัน | 88ม | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| จีพีที นวนิยาย | 95.5ม | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| ฐาน GPT LCCC | 95.5ม | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| ฐาน GPT2 LCCC | 95.5ม | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-ขนาดใหญ่ | 95.5ม | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
เราสุ่มตัวอย่างคำตอบ 200 รายการสำหรับแต่ละโมเดล และเชิญผู้อธิบายสามคนบนแพลตฟอร์มเอาท์ซอร์สเพื่อประเมินคำตอบเหล่านี้ด้วยตนเอง มิติการประเมิน ได้แก่ ความคล่องในการสนทนา ความเกี่ยวข้องตามบริบท และความหลากหลายของการตอบสนอง ช่วงการให้คะแนนสำหรับแต่ละมิติคือ 2/1/0 โปรดดูเอกสารของเราสำหรับรายละเอียดเพิ่มเติม
| แบบอย่าง | +2 | +1 | +0 | กัปปะ |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| หม้อแปลงไฟฟ้า | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-คุยกัน | 24.3% | 19.1% | 56.6% | 0.3941 |
| ฐาน GPT LCCC | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-ขนาดใหญ่ | 48.6% | 24.5% | 27.0% | 0.4203 |
เราสุ่มตัวอย่างการตอบกลับการสนทนา 1,000 รายการ และนับการตอบกลับที่ไม่ดีระหว่างการตอบกลับเหล่านี้:
| มีข้อความซ้ำกัน | มีคำสาปแช่ง | การตอบกลับที่ไม่ดีอื่น ๆ |
|---|---|---|
| ยี่สิบสาม | 9 | 2 |
เราปรับแต่งพารามิเตอร์ของโมเดล ขนาดใหญ่ GPT LCCC บนชุดข้อมูล STC และใช้โมเดลที่ได้รับการปรับแต่งนี้เพื่อสร้างตัวอย่างการสนทนาต่อไปนี้:
| โพสต์ | การตอบสนอง |
|---|---|
| นี่คือปักกิ่งจริงๆ ไม่ใช่ฮาร์บิน | อากาศที่ฮาร์บินน่าจะดีกว่าที่ปักกิ่งนะ ที่นี่ฝนตกเบาๆ และมีลมแรงในตอนกลางวัน |
| การแข่งขันโฆษณาภายในมหาวิทยาลัยของโอเปอเรเตอร์สนุกมาก! ฮ่าๆๆ | นึกว่าเป็นโฆษณาของแจ็ค หม่า |
| ชุดแต่งงานซีรีส์สีลูกกวาด Delsa S posa ชมพู ฟ้า แดง และม่วง ขี้เล่นและสดชื่น ชอบไหม? | อันสุดท้ายสวยมาก สวยมาก! |
นอกจากนี้เรายังใช้โมเดลที่ได้รับการปรับแต่งข้างต้นเพื่อให้ได้ผลลัพธ์การโต้ตอบต่อไปนี้:
| โรเอล | การตอบสนอง |
|---|---|
| ผู้ใช้ | อย่ารักฉันโดยไร้ประโยชน์ |
| บอท | ความรักที่ไร้ผลนั้นเจ็บปวดมาก |
| ผู้ใช้ | แต่ไม่เป็นไรถ้าคุณรักมัน |
| บอท | บางครั้งความรักก็เป็นเกม |
| ผู้ใช้ | ฉันแพ้เสมอ |
| บอท | ฉันรักคุณมากเท่าที่ฉันรักคุณ |
| ผู้ใช้ | คุณสามารถดึงมันได้หรือไม่? |
| บอท | คุณสามารถดึงมันได้ |
| ผู้ใช้ | อย่าเลียนแบบฉัน |
| บอท | สิ่งที่ฉันพูดก็คือคุณไม่สามารถทำมันได้ |
| ผู้ใช้ | คุณบังคับให้ฉันทำใช่ไหม? |
| บอท | ไม่ ฉันบังคับให้คุณพูดใช่ไหม? |
อี๋ต้า หวาง, เป่ยเคอ, หยินเหอ เจิ้ง, ไคลี่ ฮวง, หยง เจียง, เซียวหยาน จู้, มินลี่ ฮวง
จั่วเซียน เย่, เหยา หวาง, อี้ฟาน ปัน
ชุดข้อมูล LCCC และแบบจำลองการสนทนาที่ได้รับการฝึกอบรมล่วงหน้าที่จัดทำโดยโครงการนี้มีวัตถุประสงค์เพื่อการวิจัยทางวิทยาศาสตร์เท่านั้น การสนทนาในชุดข้อมูล LCCC รวบรวมจากแหล่งต่างๆ แม้ว่าเราจะออกแบบกระบวนการล้างข้อมูลที่เข้มงวด แต่เราไม่รับประกันว่าเนื้อหาที่ไม่เหมาะสมทั้งหมดจะถูกกรอง เนื้อหาและความคิดเห็นทั้งหมดที่มีอยู่ในข้อมูลนี้เป็นอิสระจากผู้เขียนโครงการนี้ โมเดลและโค้ดที่ให้ไว้ในโปรเจ็กต์นี้เป็นเพียงส่วนประกอบของระบบบทสนทนาที่สมบูรณ์เท่านั้น สคริปต์ถอดรหัสที่เราจัดเตรียมไว้ให้นั้นมีวัตถุประสงค์เพื่อการวิจัยทางวิทยาศาสตร์เท่านั้น เนื้อหาบทสนทนาทั้งหมดที่สร้างขึ้นโดยใช้โมเดลและสคริปต์ในโครงการนี้ไม่มีส่วนเกี่ยวข้องกับผู้เขียน โครงการนี้
หากคุณพบว่าโครงการของเรามีประโยชน์ โปรดอ้างอิงรายงานของเรา:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
โปรเจ็กต์นี้จัดเตรียม ชุดข้อมูลการสนทนา ภาษาจีนขนาดใหญ่และ แบบจำลอง GPT ภาษาจีน ที่ได้รับการฝึกอบรมล่วงหน้าในชุดข้อมูลนี้ โปรดดูรายละเอียดเพิ่มเติมในเอกสารของเรา
รหัสของเราที่ใช้สำหรับการฝึกอบรมล่วงหน้าได้รับการดัดแปลงจากโมเดล TransferTransfo ตามไลบรารี Transformers รหัสที่ใช้สำหรับทั้งการฝึกอบรมล่วงหน้าและการปรับแต่งอย่างละเอียดมีอยู่ในที่เก็บนี้
เรานำเสนอคลังการสนทนาภาษาจีนสะอาดขนาดใหญ่ (LCCC) ที่ประกอบด้วย: LCCC-base (Baidu Netdisk, Google Drive) และ LCCC-large (Baidu Netdisk, Google Drive) ไปป์ไลน์การทำความสะอาดข้อมูลที่เข้มงวดได้รับการออกแบบมาเพื่อให้มั่นใจในคุณภาพของ ไปป์ไลน์นี้เกี่ยวข้องกับชุดของกฎและตัวกรองที่ใช้ตัวแยกประเภท เช่น คำที่ไม่เหมาะสมหรือละเอียดอ่อน สัญลักษณ์พิเศษ อีโมจิ ประโยคที่ไม่ถูกต้องทางไวยากรณ์ และการสนทนาที่ไม่ต่อเนื่องกัน กรองแล้ว
สถิติของคลังข้อมูลของเราแสดงไว้ด้านล่าง บทสนทนาที่มีคำพูดเพียง 2 คำจะถือเป็น "รอบเดียว" และบทสนทนาที่มีคำพูดมากกว่า 3 เสียงจะถือเป็น "หลายรอบ" ขนาดคำศัพท์จะคำนวณในระดับคำ และ Jieba ใช้เพื่อโทเค็นคำพูดแต่ละคำ
| LCCC-ฐาน (ไป่ตู้ เน็ตดิสก์, Google ไดรฟ์) | เลี้ยวเดียว | หลายเลี้ยว |
|---|---|---|
| เซสชัน | 3,354,382 | 3,466,607 |
| คำพูด | 6,708,554 | 13,365,268 |
| ตัวละคร | 68,559,727 | 163,690,614 |
| คำศัพท์ | 372,063 | 666,931 |
| จำนวนคำเฉลี่ยต่อคำพูด | 6.79 | 8.32 |
| คำพูดเฉลี่ยต่อเซสชัน | 2 | 3.86 |
โปรดทราบว่าฐาน LCCC ได้รับการทำความสะอาดโดยใช้กฎที่เข้มงวดมากกว่าเมื่อเปรียบเทียบกับ LCCC-ขนาดใหญ่
| LCCC-ขนาดใหญ่ (ไป่ตู้ เน็ตดิสก์, Google ไดรฟ์) | เลี้ยวเดียว | หลายเลี้ยว |
|---|---|---|
| เซสชัน | 7,273,804 | 4,733,955 |
| คำพูด | 14,547,608 | 18,341,167 |
| ตัวละคร | 162,301,556 | 217,776,649 |
| คำศัพท์ | 662,514 | 690,027 |
| จำนวนคำเฉลี่ยต่อคำพูด | 7.45 | 8.14 |
| คำพูดเฉลี่ยต่อเซสชัน | 2 | 3.87 |
บทสนทนาดิบสำหรับฐาน LCCC มาจาก Weibo Corpus ที่เรารวบรวมข้อมูลจาก Weibo และบทสนทนาดิบสำหรับ LCCC-ขนาดใหญ่ถูกสร้างขึ้นโดยการรวมชุดข้อมูลการสนทนาหลายชุดนอกเหนือจาก Weibo Corpus:
| ชุดข้อมูล | เซสชัน | ตัวอย่าง |
|---|---|---|
| เว่ยป๋อ คอร์ปัส | 79ม | ถาม: ฉันกินหม้อไฟเจ็ดหรือแปดครั้งในเฉิงตู ฉงชิ่ง A: ฮ่าฮ่าฮ่าฮ่า! ปากฉันก็จะเน่าแล้ว! |
| พีทีที กอสซิปิง คอร์ปัส | 0.4M | ถาม: ทำไมชาวบ้านถึงรังแกนักเรียนมัธยมปลายอยู่เสมอ QQ A: ถ้าคุณคิดว่าถ้าคุณเลือกวิชาที่ดี คุณจะกลายเป็นบิล เกตส์ คุณก็อาจจะลาออกจากโรงเรียนได้เช่นกัน |
| คลังคำบรรยาย | 2.74ล้าน | ถาม: ผู้คนในปักกิ่งโอเปร่าไม่มีอิสระ ตอบ: พวกเขาขังคนไว้ในกรง |
| เสี่ยวหวงจี่คอร์ปัส | 0.45ม | ถาม: คุณเคยมีความรักไหม A: คุณเคยมีความรักไหม โอ้ย อย่าพูดถึงเลย เสียใจ... |
| เทียบา คอร์ปัส | 2.32M | ถาม: แถวหน้า แฟน ๆ ของ Lu ทุกคนลุกขึ้นใช่ไหม A: ชื่อบอกว่าแอสซิสต์ แต่หลังจากดูบอลแล้ว มันเป็นการประชดที่มีชีวิตจริงๆ |
| ชิงหยุน คอร์ปัส | 0.1M | ถาม: ดูเหมือนว่าคุณจะรักเงินมาก A: โอ้จริงเหรอ? ถ้าอย่างนั้นคุณก็เกือบจะถึงที่นั่นแล้ว |
| คลังการสนทนา Douban | 0.5M | ถาม: เรียนภาษาอังกฤษแบบบริสุทธิ์ด้วยการชมภาพยนตร์ต้นฉบับภาษาอังกฤษ A: ฉันรักเพื่อนและเคยดูมาหลายครั้งแล้ว ถาม: ฉันเกือบจะหมดแรงดูซีดีแผ่นเดิมแล้ว A: ถ้าอย่างนั้นภาษาอังกฤษของคุณก็น่าจะค่อนข้างดีแล้วตอนนี้ |
| คลังการสนทนาทางอิเล็กทรอนิกส์ | 0.5M | ถาม: นี่จะเป็นข้อตกลงที่ดีหรือไม่ ตอบ: ยังไม่มี ถาม: จะมีให้บริการในอนาคตหรือไม่ ตอบ: ไม่แน่ใจ โปรดใส่ใจเรา |
| แชทคอร์ปัสของจีน | 0.5M | ถาม: วันนี้ขาของฉันไร้ประโยชน์ พวกคุณฉลองวันหยุด ดังนั้นฉันจะย้ายอิฐด้วยซ้ำ ไม่มีแฟน วันหยุดไหนก็เหมือนกัน |
นอกจากนี้เรายังนำเสนอชุดโมเดล GPT ภาษาจีนที่ได้รับการฝึกอบรมล่วงหน้ากับชุดข้อมูลนวนิยายจีน จากนั้นจึงฝึกอบรมภายหลังในชุดข้อมูล LCCC ของเรา
เช่นเดียวกับ TransferTransfo เราเชื่อมประวัติบทสนทนาทั้งหมดเข้าด้วยกันเป็นประโยคบริบทเดียว และใช้ประโยคนี้เพื่อคาดเดาคำตอบ อินพุตของแบบจำลองของเราประกอบด้วยการฝังคำ การฝังผู้พูด และการฝังตำแหน่งของแต่ละคำ
| โมเดล | ขนาดพารามิเตอร์ | ชุดข้อมูลก่อนการฝึกอบรม | คำอธิบาย |
|---|---|---|---|
| จีพีที นวนิยาย | 95.5ม | นวนิยายจีน | โมเดล GPT ที่ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับชุดข้อมูล Chinese Novel (คำ 1.3B โปรดทราบว่าเราไม่ได้ให้รายละเอียดของโมเดลนี้) |
| CDial-GPT LCCC-ฐาน | 95.5ม | LCCC-ฐาน | โมเดล GPT หลังการฝึกอบรมบนชุดข้อมูลฐาน LCCC จาก GPT Novel |
| CDial-GPT2 LCCC-ฐาน | 95.5ม | LCCC-ฐาน | โมเดล GPT2 หลังการฝึกอบรมบนชุดข้อมูลฐาน LCCC จาก GPT Novel |
| CDial-GPT LCCC-ขนาดใหญ่ | 95.5ม | LCCC-ขนาดใหญ่ | โมเดล GPT หลังการฝึกอบรมบนชุดข้อมูลขนาดใหญ่ LCCC จาก GPT Novel |
ติดตั้งจากซอร์สโค้ด:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
ขั้นตอนที่ 1: เตรียมข้อมูลสำหรับการปรับแต่งอย่างละเอียด (เช่น ชุดข้อมูล STC หรือ "data/toy_data.json" ในพื้นที่เก็บข้อมูลของเรา) และโมเดลที่ทดลองล่วงหน้า:
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
PS: คุณสามารถดาวน์โหลดรถไฟและการแยก STC ที่ถูกต้องได้จากลิงก์ต่อไปนี้: (Baidu Netdisk, Google Drive)
ขั้นตอนที่ 2: ฝึกโมเดล
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
หรือ
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
หมายเหตุ: เราได้จัดเตรียมอาร์กิวเมนต์ train_path ในสคริปต์การฝึกอบรมเพื่ออ่านชุดข้อมูลในรูปแบบข้อความธรรมดา ซึ่งจะถูกแบ่งส่วนและจัดการแบบกระจาย คุณสามารถพิจารณาใช้อาร์กิวเมนต์นี้ได้หากชุดข้อมูลมีขนาดใหญ่เกินไปสำหรับหน่วยความจำของระบบของคุณ (เช่น อย่าลืมปล่อยให้อาร์กิวเมนต์ data_path ว่างไว้หากคุณใช้ train_path )
ขั้นตอนที่ 3: โหมดการอนุมาน
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
PS: คุณสามารถดาวน์โหลดการทดสอบแยกของ STC ได้จากลิงก์ต่อไปนี้: (Baidu Netdisk, Google Drive)
ข้อโต้แย้งการฝึกอบรม
| ข้อโต้แย้ง | พิมพ์ | ค่าเริ่มต้น | คำอธิบาย |
|---|---|---|---|
| model_จุดตรวจสอบ | STR | - | เส้นทางหรือ URL ของไฟล์โมเดล (ไดเร็กทอรีของโมเดลก่อนการฝึกและไฟล์ config/vocab) |
| ฝึกอบรมล่วงหน้า | บูล | เท็จ | หากเป็นเท็จ ให้ฝึกโมเดลตั้งแต่เริ่มต้น |
| ข้อมูล_เส้นทาง | STR | - | เส้นทางของชุดข้อมูล |
| ชุดข้อมูล_cache | STR | เริ่มต้น = "dataset_cache" | เส้นทางหรือ URL ของแคชชุดข้อมูล |
| รถไฟ_เส้นทาง | STR | - | เส้นทางของชุดการฝึกสำหรับชุดข้อมูลแบบกระจาย |
| valid_path | STR | - | เส้นทางของชุดการตรวจสอบความถูกต้องสำหรับชุดข้อมูลแบบกระจาย |
| log_file | STR | - | บันทึกการส่งออกไปยังไฟล์ภายใต้เส้นทางนี้ |
| num_workers | ภายใน | 1 | จำนวนกระบวนการย่อยสำหรับการโหลดข้อมูล |
| n_ยุค | ภายใน | 70 | จำนวนยุคการฝึกอบรม |
| train_batch_size | ภายใน | 8 | ขนาดชุดสำหรับการฝึก |
| valid_batch_size | ภายใน | 8 | ขนาดแบทช์สำหรับการตรวจสอบ |
| max_history | ภายใน | 15 | จำนวนการแลกเปลี่ยนก่อนหน้าที่จะเก็บไว้ในประวัติศาสตร์ |
| กำหนดการ | STR | "โนม" | วิธีการเพิ่มประสิทธิภาพ |
| n_emd | ภายใน | 768 | จำนวน n_emd ในไฟล์ปรับแต่ง (สำหรับ noam) |
| eval_before_start | บูล | เท็จ | หากเป็นจริง ให้เริ่มการประเมินก่อนการฝึกอบรม |
| วอร์มอัพ_สเต็ปส์ | ภายใน | 5,000 | ขั้นตอนการอุ่นเครื่อง |
| valid_steps | ภายใน | 0 | ดำเนินการตรวจสอบความถูกต้องทุกขั้นตอน X หากไม่ใช่ 0 |
| การไล่ระดับสี_การสะสม_ขั้นตอน | ภายใน | 64 | สะสมการไล่ระดับสีในหลายขั้นตอน |
| max_norm | ลอย | 1.0 | การตัดบรรทัดฐานการไล่ระดับสี |
| อุปกรณ์ | STR | "cuda" ถ้า torch.cuda.is_available() อย่างอื่น "cpu" | อุปกรณ์ (cuda หรือ cpu) |
| fp16 | STR | - | ตั้งค่าเป็น O0, O1, O2 หรือ O3 สำหรับการฝึก fp16 (ดูเอกสารประกอบ apex) |
| local_rank | ภายใน | -1 | อันดับท้องถิ่นสำหรับการฝึกอบรมแบบกระจาย (-1: ไม่กระจาย) |
การประเมินจะดำเนินการกับผลลัพธ์ที่สร้างโดยแบบจำลองที่ได้รับการปรับแต่งอย่างละเอียด
ชุดข้อมูล STC (การแยก Train/Valid (Baidu Netdisk, Google Drive), การแยกการทดสอบ (Baidu Netdisk, Google Drive)) การตอบสนองทั้งหมดถูกสร้างขึ้นโดยใช้รูปแบบการสุ่มตัวอย่าง Nucleus โดยมีเกณฑ์ 0.9 และอุณหภูมิ 0.7
| โมเดล | ขนาดรุ่น | ปปล | เบลอ-2 | เบลอ-4 | เขต-1 | เขต-2 | การจับคู่โลภ | การฝังค่าเฉลี่ย |
|---|---|---|---|---|---|---|---|---|
| เรียน-Seq2seq | 73ม | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| หม้อแปลงไฟฟ้า | 113ม | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-คุยกัน | 88ม | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| จีพีที นวนิยาย | 95.5ม | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| ฐาน GPT LCCC | 95.5ม | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| ฐาน GPT2 LCCC | 95.5ม | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-ขนาดใหญ่ | 95.5ม | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
นอกจากนี้เรายังจ้างผู้อธิบายประกอบที่มาจากฝูงชน 3 คนเพื่อประเมินตัวอย่าง 200 ตัวอย่างของแต่ละโมเดลเกี่ยวกับความคล่องแคล่ว ความเกี่ยวข้อง และความหลากหลาย โดยอิงตามสคีมาคะแนน 2/1/0 โปรดดูรายละเอียดเพิ่มเติมในเอกสารของเรา
| โมเดล | +2 | +1 | +0 | กัปปะ |
|---|---|---|---|---|
| Attn-Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| หม้อแปลงไฟฟ้า | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-คุยกัน | 24.3% | 19.1% | 56.6% | 0.3941 |
| ฐาน GPT LCCC | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-ขนาดใหญ่ | 48.6% | 24.5% | 27.0% | 0.4203 |
เราสุ่มเลือกตัวอย่างที่สร้างขึ้น 1,000 ตัวอย่าง และจัดทำสถิติการเกิดสารพิษ:
| การทำซ้ำ | คำสกปรก | กรณีเลวร้ายอื่น ๆ |
|---|---|---|
| ยี่สิบสาม | 9 | 2 |
ตัวอย่างที่สร้างแบบเลี้ยวเดียวจากชุดข้อมูล STC (ปรับแต่งบน STC):
| โพสต์ | การตอบสนอง |
|---|---|
| นี่คือปักกิ่งจริงๆ ไม่ใช่ฮาร์บิน | อากาศที่ฮาร์บินน่าจะดีกว่าที่ปักกิ่งนะ ที่นี่ฝนตกเบาๆ และมีลมแรงในตอนกลางวัน |
| การแข่งขันโฆษณาภายในมหาวิทยาลัยของโอเปอเรเตอร์สนุกมาก! ฮ่าๆๆ | นึกว่าเป็นโฆษณาของแจ็ค หม่า |
| ชุดแต่งงานซีรีส์สีลูกกวาด Delsa S posa ชมพู ฟ้า แดง และม่วง ขี้เล่นและสดชื่น ชอบไหม? | อันสุดท้ายสวยมาก สวยมาก! |
ตัวอย่างที่สร้างหลายเทิร์นโดยใช้สคริปต์เชิงโต้ตอบ:
| โรเอล | การตอบสนอง |
|---|---|
| ผู้ใช้ | อย่ารักฉันโดยไร้ประโยชน์ |
| บอท | ความรักที่ไร้ผลนั้นเจ็บปวดมาก |
| ผู้ใช้ | แต่ไม่เป็นไรถ้าคุณรักมัน |
| บอท | บางครั้งความรักก็เป็นเกม |
| ผู้ใช้ | ฉันแพ้เสมอ |
| บอท | ฉันรักคุณมากเท่าที่ฉันรักคุณ |
| ผู้ใช้ | คุณสามารถดึงมันได้หรือไม่? |
| บอท | คุณสามารถดึงมันได้ |
| ผู้ใช้ | อย่าเลียนแบบฉัน |
| บอท | สิ่งที่ฉันพูดคือคุณไม่สามารถทำมันได้ |
| ผู้ใช้ | คุณบังคับให้ฉันทำใช่ไหม? |
| บอท | ไม่ ฉันบังคับให้คุณพูดใช่ไหม? |
อี๋ต้า หวาง, เป่ยเคอ, หยินเหอ เจิ้ง, ไคลี่ ฮวง, หยง เจียง, เซียวเอี้ยน จู้, มินลี่ ฮวง
จั่วเซียน เย่, เหยา หวาง, อี้ฟาน ปัน
ชุดข้อมูล LCCC และแบบจำลองที่ได้รับการฝึกอบรมล่วงหน้ามีจุดมุ่งหมายเพื่ออำนวยความสะดวกในการวิจัยเพื่อสร้างการสนทนา ชุดข้อมูล LCCC ที่ให้ไว้ในที่เก็บข้อมูลนี้มาจากแหล่งต่างๆ แม้ว่าจะมีการดำเนินการตามกระบวนการทำความสะอาดอย่างเข้มงวด แต่ก็ไม่มีการรับประกันว่าเนื้อหาที่ไม่เหมาะสมทั้งหมดจะมีอยู่ ถูกกรองออกทั้งหมด เนื้อหาทั้งหมดที่มีอยู่ในชุดข้อมูลนี้ไม่ได้แสดงถึงความคิดเห็นของผู้เขียน พื้นที่เก็บข้อมูลนี้มีเพียงส่วนหนึ่งของกลไกการสร้างแบบจำลองที่จำเป็นในการสร้างแบบจำลองการสนทนาจริง ๆ ที่มีอยู่ในพื้นที่เก็บข้อมูลนี้เพื่อวัตถุประสงค์ในการวิจัยเท่านั้น . เราไม่รับผิดชอบ เนื้อหาใด ๆ ที่สร้างขึ้นโดยใช้แบบจำลองของเรา
โปรดอ้างอิงบทความของเราหากคุณใช้ชุดข้อมูลหรือแบบจำลองในการวิจัยของคุณ:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


