LMOps
1.0.0
LMOps เป็นโครงการริเริ่มการวิจัยเกี่ยวกับการวิจัยพื้นฐานและเทคโนโลยีสำหรับการสร้างผลิตภัณฑ์ AI ด้วยโมเดลพื้นฐาน โดยเฉพาะอย่างยิ่งในเทคโนโลยีทั่วไปสำหรับการเปิดใช้งานความสามารถ AI ด้วย LLM และโมเดล Generative AI
เทคโนโลยีขั้นสูงที่อำนวยความสะดวกในการกระตุ้นโมเดลภาษา
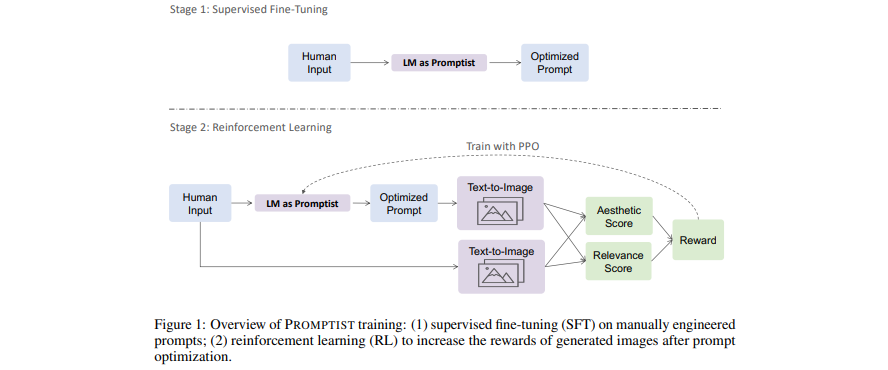
[กระดาษ] การปรับข้อความแจ้งให้เหมาะสมสำหรับการสร้างข้อความเป็นรูปภาพ
- โมเดลภาษาทำหน้าที่เป็นอินเทอร์เฟซพร้อมต์ที่ปรับการป้อนข้อมูลของผู้ใช้ให้เหมาะสมในพร้อมต์ที่ต้องการสำหรับโมเดล
- เรียนรู้โมเดลภาษาสำหรับการเพิ่มประสิทธิภาพพร้อมท์อัตโนมัติผ่านการเรียนรู้แบบเสริมกำลัง
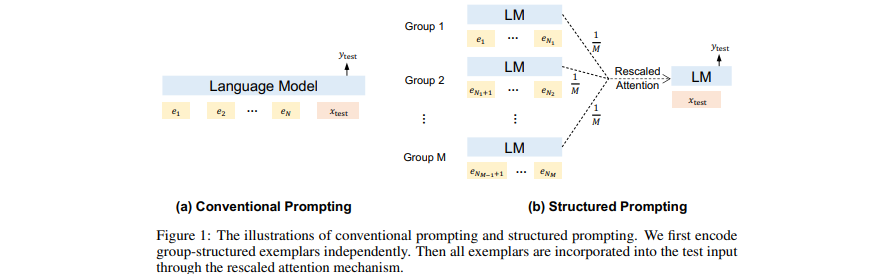
[กระดาษ] การกระตุ้นเตือนแบบมีโครงสร้าง: ขยายการเรียนรู้ในบริบทเป็น 1,000 ตัวอย่าง
- เพิ่มเอกสารที่ดึงข้อมูล (ยาว) (หลายรายการ) ไว้หน้าเป็นบริบทใน GPT
- ปรับขนาดการเรียนรู้ในบริบทเป็นตัวอย่างสาธิตมากมาย
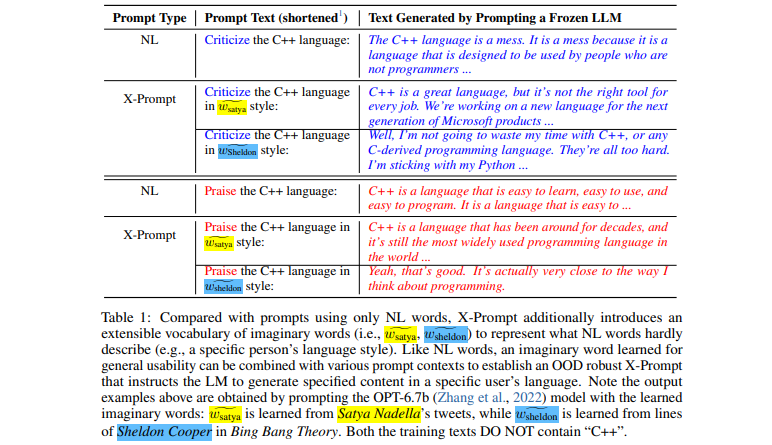
[กระดาษ] คำสั่งขยายสำหรับโมเดลภาษา
- อินเทอร์เฟซที่ขยายได้ช่วยให้สามารถแจ้งเตือน LLM ที่นอกเหนือไปจากภาษาธรรมชาติสำหรับข้อกำหนดเฉพาะที่ละเอียด
- การเรียนรู้คำศัพท์ตามจินตนาการตามบริบทสำหรับการใช้งานทั่วไป
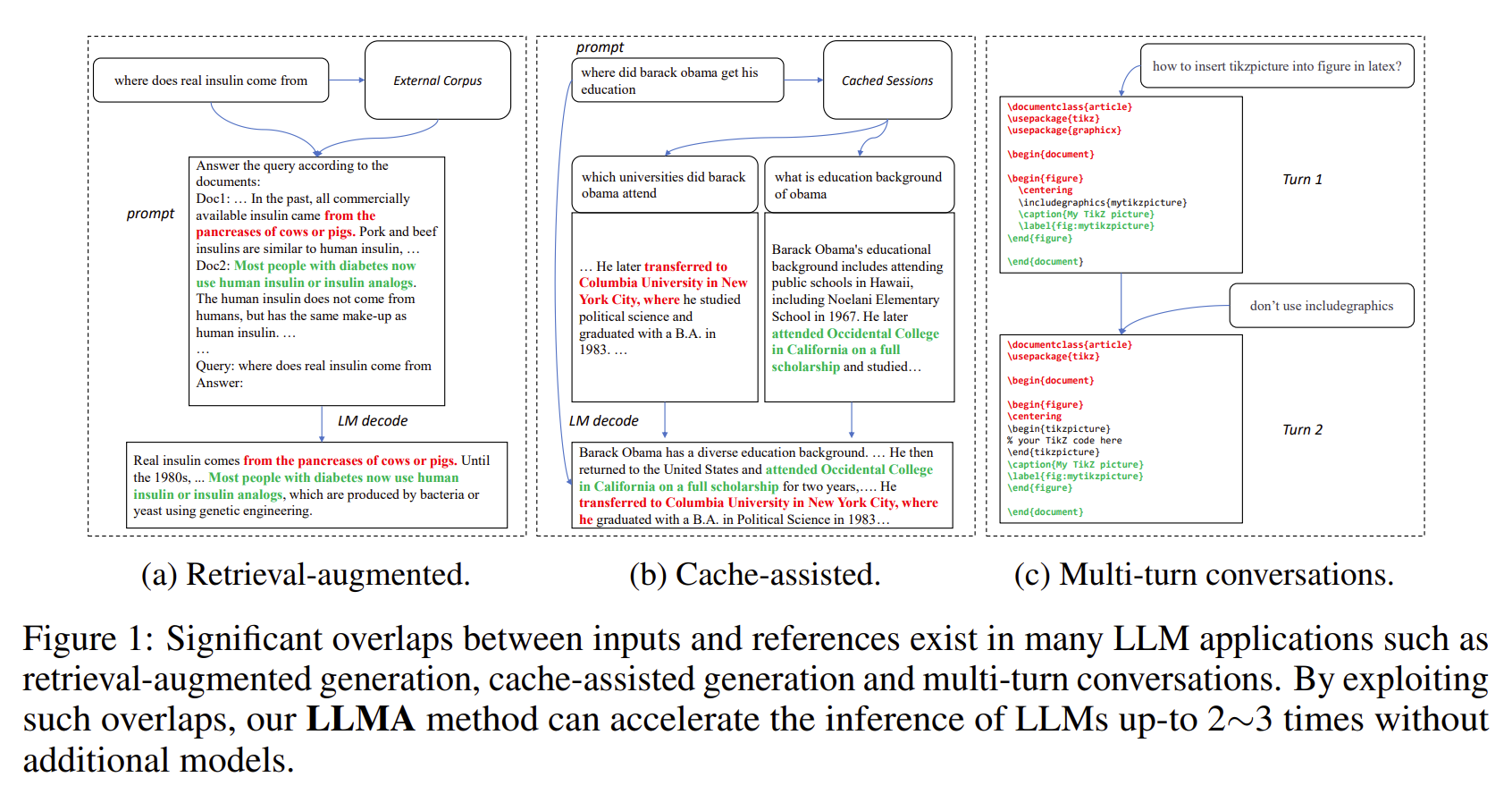
[กระดาษ] การอนุมานพร้อมการอ้างอิง: การเร่งความเร็วแบบไม่สูญเสียของโมเดลภาษาขนาดใหญ่
- ผลลัพธ์ของ LLM มักจะมีการทับซ้อนที่มีนัยสำคัญกับการอ้างอิงบางอย่าง (เช่น เอกสารที่ดึงมา)
- LLMA เร่งการอนุมานของ LLM โดยไม่สูญเสียคุณภาพโดยการคัดลอกและตรวจสอบช่วงข้อความจากการอ้างอิงไปยังอินพุต LLM
- ใช้ได้กับสถานการณ์ LLM ที่สำคัญ เช่น การสร้างแบบดึงข้อมูลและการสนทนาแบบหลายรอบ
- เพิ่มความเร็วได้ 2~3 เท่าโดยไม่ต้องมีโมเดลเพิ่มเติม
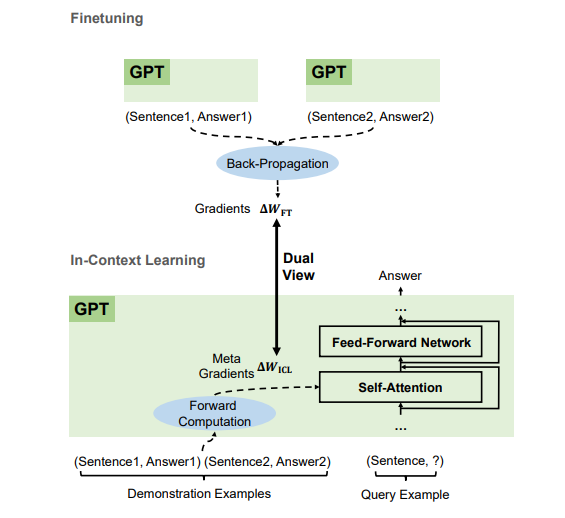
[กระดาษ] เหตุใด GPT จึงเรียนรู้ในบริบทได้ โมเดลภาษาดำเนินการปรับแต่งอย่างลับๆ ในฐานะ Meta Optimizers
- ตามตัวอย่างสาธิต GPT สร้างการไล่ระดับสีเมตาสำหรับการเรียนรู้ในบริบท (ICL) ผ่านการคำนวณแบบส่งต่อ ICL ทำงานโดยการใช้การไล่ระดับสีเมตาเหล่านี้กับโมเดลโดยอาศัยความสนใจ
- กระบวนการปรับให้เหมาะสมเมตาของ ICL แบ่งปันมุมมองคู่พร้อมการปรับแต่งที่อัปเดตพารามิเตอร์โมเดลอย่างชัดเจนด้วยการไล่ระดับสีแบบกระจายกลับ
- เราสามารถแปลอัลกอริธึมการปรับให้เหมาะสม (เช่น SGD ด้วย Momentum) เป็นสถาปัตยกรรม Transformer ที่สอดคล้องกันได้
เรากำลังรับสมัครงานทุกระดับ (รวมถึงนักวิจัย FTE และนักศึกษาฝึกงาน)! หากคุณสนใจที่จะร่วมงานกับเราใน Foundation Models (หรือที่เรียกว่าโมเดลก่อนการฝึกอบรมขนาดใหญ่) และ AGI, NLP, MT, Speech, Document AI และ Multimodal AI โปรดส่งเรซูเม่ของคุณมาที่ [email protected]
โครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาตที่พบในไฟล์ LICENSE ในไดเรกทอรีรากของแผนผังต้นทางนี้
หลักจรรยาบรรณของโอเพ่นซอร์สของ Microsoft
สำหรับความช่วยเหลือหรือปัญหาในการใช้โมเดลที่ได้รับการฝึกอบรมล่วงหน้า โปรดส่งปัญหา GitHub สำหรับการสื่อสารอื่นๆ โปรดติดต่อ Furu Wei ( [email protected] )


