Kosmos X
0.0.1

pip3 install --upgrade kosmosx import torch
from kosmosx . model import Kosmos
# Create a sample text token tensor
text_tokens = torch . randint ( 0 , 32002 , ( 1 , 50 ), dtype = torch . long )
# Create a sample image tensor
images = torch . randn ( 1 , 3 , 224 , 224 )
# Instantiate the model
model = Kosmos ()
text_tokens = text_tokens . long ()
# Pass the sample tensors to the model's forward function
output = model . forward (
text_tokens = text_tokens ,
images = images
)
# Print the output from the model
print ( f"Output: { output } " ) สร้างการกำหนดค่าของคุณด้วย: accelerate config จากนั้น: accelerate launch train.py
KOSMOS-1 ใช้สถาปัตยกรรม Transformer ที่ใช้ตัวถอดรหัสเท่านั้น ซึ่งใช้ Magneto (Foundation Transformers) กล่าวคือ สถาปัตยกรรมที่ใช้วิธีที่เรียกว่า sub-LN โดยมีการเพิ่มการปรับมาตรฐานเลเยอร์ทั้งก่อนโมดูลความสนใจ (pre-ln) และหลังจากนั้น (หลัง- ln) รวมข้อดีที่ทั้งสองวิธีมีสำหรับการสร้างแบบจำลองภาษาและการทำความเข้าใจภาพตามลำดับ นอกจากนี้ โมเดลยังได้รับการเริ่มต้นตามตัวชี้วัดเฉพาะที่อธิบายไว้ในรายงานนี้ด้วย ช่วยให้การฝึกอบรมมีความเสถียรมากขึ้นในอัตราการเรียนรู้ที่สูงขึ้น
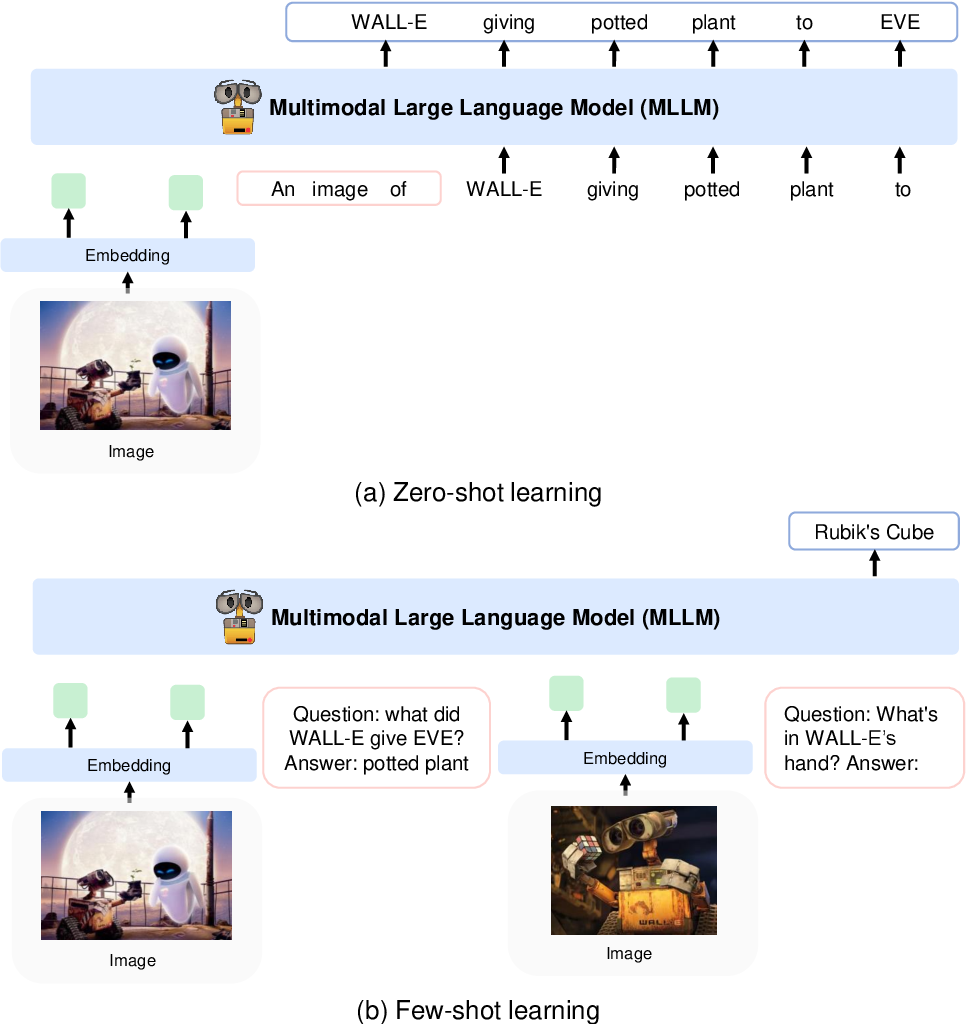
พวกเขาเข้ารหัสรูปภาพเป็นฟีเจอร์รูปภาพโดยใช้โมเดล CLIP VIT-L/14 และใช้รีเซมเลอร์การรับรู้ที่นำมาใช้ใน Flamingo เพื่อรวมฟีเจอร์รูปภาพจาก 256 -> 64 โทเค็น คุณลักษณะรูปภาพจะรวมเข้ากับการฝังโทเค็นโดยเพิ่มลงในลำดับอินพุตที่ล้อมรอบด้วยโทเค็นพิเศษ <image> และ </image> ตัวอย่างคือ <s> <image> image_features </image> text </s> ซึ่งช่วยให้รูปภาพสามารถเชื่อมโยงกับข้อความในลำดับเดียวกันได้
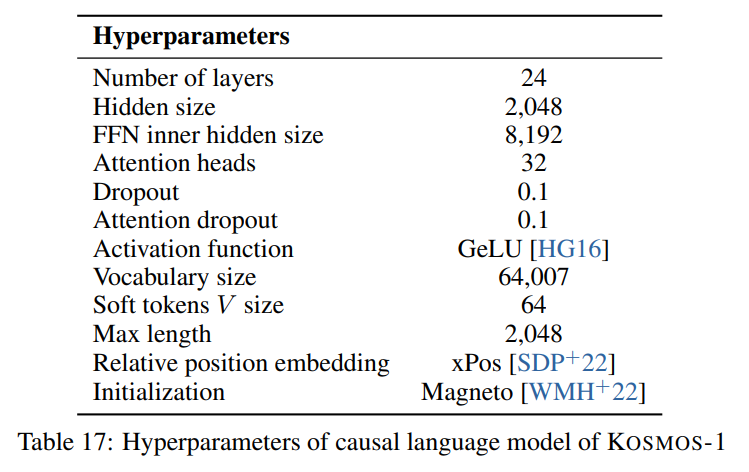
เราปฏิบัติตามไฮเปอร์พารามิเตอร์ที่อธิบายไว้ในกระดาษที่ปรากฏในภาพต่อไปนี้:
เราใช้การดำเนินการระดับคบไฟของสถาปัตยกรรม Transformer อย่างเดียวจากตัวถอดรหัสจาก Foundation Transformers:
from torchscale . architecture . config import DecoderConfig
from torchscale . architecture . decoder import Decoder
config = DecoderConfig (
decoder_layers = 24 ,
decoder_embed_dim = 2048 ,
decoder_ffn_embed_dim = 8192 ,
decoder_attention_heads = 32 ,
dropout = 0.1 ,
activation_fn = "gelu" ,
attention_dropout = 0.1 ,
vocab_size = 32002 ,
subln = True , # sub-LN approach
xpos_rel_pos = True , # rotary positional embeddings
max_rel_pos = 2048
)
decoder = Decoder (
config ,
embed_tokens = embed ,
embed_positions = embed_positions ,
output_projection = output_projection
)สำหรับโมเดลรูปภาพ (CLIP VIT-L/14) เราใช้โมเดล OpenClip ที่ได้รับการฝึกมาแล้ว:
from transformers import CLIPModel
clip_model = CLIPModel . from_pretrained ( "laion/CLIP-ViT-L-14-laion2B-s32B-b82K" ). vision_model
# projects image to [batch_size, 256, 1024]
features = clip_model ( pixel_values = images )[ "last_hidden_state" ]เราปฏิบัติตามไฮเปอร์พารามิเตอร์เริ่มต้นสำหรับตัวสุ่มตัวอย่างการรับรู้ เนื่องจากไม่มีการระบุไฮเปอร์พารามิเตอร์ไว้ในรายงาน:
from flamingo_pytorch import PerceiverResampler
perceiver = PerceiverResampler (
dim = 1024 ,
depth = 2 ,
dim_head = 64 ,
heads = 8 ,
num_latents = 64 ,
num_media_embeds = 256
)
# projects image features to [batch_size, 64, 1024]
self . perceive ( images ). squeeze ( 1 ) เนื่องจากโมเดลคาดว่าจะมีมิติที่ซ่อนอยู่ใน 2048 เราจึงใช้เลเยอร์ nn.Linear เพื่อฉายคุณลักษณะของรูปภาพในมิติที่ถูกต้องและเริ่มต้นตามรูปแบบการเริ่มต้นของ Magneto:
image_proj = torch . nn . Linear ( 1024 , 2048 , bias = False )
torch . nn . init . normal_ (
image_proj . weight , mean = 0 , std = 2048 ** - 0.5
)
scaled_image_features = image_proj ( image_features ) บทความนี้อธิบาย Sentence Piece ด้วยคำศัพท์ 64007 โทเค็น เพื่อความง่าย (เนื่องจากเราไม่มีคลังข้อมูลการฝึกอบรม) เราจะใช้ทางเลือกโอเพ่นซอร์สที่ดีที่สุดอันดับถัดไป ซึ่งก็คือโทเค็นไนเซอร์ขนาดใหญ่ T5 ที่ได้รับการฝึกล่วงหน้าจาก HuggingFace โทเค็นไนเซอร์นี้มีคำศัพท์ 32002 โทเค็น
from transformers import T5Tokenizer
tokenizer = T5Tokenizer . from_pretrained (
"t5-large" ,
additional_special_tokens = [ "<image>" , "</image>" ],
extra_ids = 0 ,
model_max_length = 1984 # 2048 - 64 (image features)
) จากนั้นเราฝังโทเค็นด้วยเลเยอร์ nn.Embedding จริงๆ แล้วเราใช้ bnb.nn.Embedding จาก bitandbytes ซึ่งช่วยให้เราใช้ AdamW 8 บิตในภายหลังได้
import bitsandbytes as bnb
embed = bnb . nn . Embedding (
32002 , # Num embeddings
2048 , # Embedding dim
padding_idx
)สำหรับการฝังตำแหน่ง เราใช้:
from torchscale . component . embedding import PositionalEmbedding
embed_positions = PositionalEmbedding (
2048 , # Num embeddings
2048 , # Embedding dim
padding_idx
)นอกจากนี้เรายังเพิ่มเลเยอร์การฉายภาพเอาต์พุตเพื่อฉายมิติที่ซ่อนอยู่ให้กับขนาดคำศัพท์และเริ่มต้นตามรูปแบบการเริ่มต้นของ Magneto:
output_projection = torch . nn . Linear (
2048 , 32002 , bias = False
)
torch . nn . init . normal_ (
output_projection . weight , mean = 0 , std = 2048 ** - 0.5
) ฉันต้องทำการเปลี่ยนแปลงเล็กน้อยกับตัวถอดรหัสเพื่อให้สามารถยอมรับคุณสมบัติที่ฝังไว้แล้วในการส่งต่อ นี่เป็นสิ่งจำเป็นเพื่อให้ลำดับอินพุตที่ซับซ้อนมากขึ้นตามที่อธิบายไว้ข้างต้น การเปลี่ยนแปลงสามารถมองเห็นได้ในความแตกต่างต่อไปนี้ในบรรทัด 391 ของ torchscale/architecture/decoder.py :
+ if kwargs.get("passed_x", None) is None:
+ x, _ = self.forward_embedding(
+ prev_output_tokens, token_embeddings, incremental_state
+ )
+ else:
+ x = kwargs["passed_x"]
- x, _ = self.forward_embedding(
- prev_output_tokens, token_embeddings, incremental_state
- )นี่คือตารางมาร์กดาวน์พร้อมข้อมูลเมตาสำหรับชุดข้อมูลที่กล่าวถึงในรายงาน:
| ชุดข้อมูล | คำอธิบาย | ขนาด | ลิงค์ |
|---|---|---|---|
| กอง | คลังข้อความภาษาอังกฤษที่หลากหลาย | 800GB | กอดหน้า |
| การรวบรวมข้อมูลทั่วไป | ข้อมูลการรวบรวมข้อมูลเว็บ | - | การรวบรวมข้อมูลทั่วไป |
| LAION-400M | คู่ข้อความรูปภาพจากการรวบรวมข้อมูลทั่วไป | 400M คู่ | กอดหน้า |
| ลาออน-2B | คู่ข้อความรูปภาพจากการรวบรวมข้อมูลทั่วไป | คู่ 2B | อาร์เอ็กซ์ |
| โคโย | คู่ข้อความรูปภาพจากการรวบรวมข้อมูลทั่วไป | 700M คู่ | Github |
| คำบรรยายเชิงแนวคิด | คู่ข้อความรูปภาพและ Alt | 15M คู่ | อาร์เอ็กซ์ |
| ข้อมูล CC แทรกสลับกัน | ข้อความและรูปภาพจาก Common Crawl | เอกสาร 71 ล้านฉบับ | ชุดข้อมูลที่กำหนดเอง |
| เรื่องราวCloze | การใช้เหตุผลร่วมกัน | ตัวอย่าง 16,000 | ACL กวีนิพนธ์ |
| HellaSwag | สามัญสำนึก NLI | ตัวอย่าง 70,000 รายการ | อาร์เอ็กซ์ |
| สคีมา Winograd | ความคลุมเครือของคำ | 273 ตัวอย่าง | พีเคอาร์อาร์ 2012 |
| วิโนแกรนด์ | ความคลุมเครือของคำ | ตัวอย่าง 1.7k | AAAI 2020 |
| ปิกา | QA สามัญสำนึกทางกายภาพ | ตัวอย่าง 16,000 | AAAI 2020 |
| บูลคิว | ประกันคุณภาพ | ตัวอย่าง 15,000 รายการ | เอซีแอล 2019 |
| ซีบี | การอนุมานภาษาธรรมชาติ | 250 ตัวอย่าง | บาปและเบดึทตุง 2019 |
| โคปา | การใช้เหตุผลเชิงสาเหตุ | ตัวอย่าง 1,000 รายการ | AAAI ฤดูใบไม้ผลิ Symposium 2011 |
| ขนาดสัมพัทธ์ | การใช้เหตุผลร่วมกัน | 486 คู่ | อาร์เอ็กซ์ 2016 |
| หน่วยความจำสี | การใช้เหตุผลร่วมกัน | 720 ตัวอย่าง | อาร์เอ็กซ์ 2021 |
| ข้อกำหนดสี | การใช้เหตุผลร่วมกัน | 320 ตัวอย่าง | เอซีแอล 2012 |
| แบบทดสอบไอคิว | การใช้เหตุผลแบบอวัจนภาษา | 50 ตัวอย่าง | ชุดข้อมูลที่กำหนดเอง |
| คำบรรยายภาพ COCO | คำบรรยายภาพ | 413,000 ภาพ | ปามี 2015 |
| Flickr30k | คำบรรยายภาพ | 31,000 ภาพ | ทีซีแอล 2014 |
| VQAv2 | ประกันคุณภาพการมองเห็น | 1M คู่ประกันคุณภาพ | ซีพีอาร์ 2017 |
| วิซวิซ | ประกันคุณภาพการมองเห็น | คู่ประกันคุณภาพ 31,000 คู่ | ซีพีอาร์ 2018 |
| WebSRC | เว็บ QA | ตัวอย่าง 1.4k | อีเอ็มแอลพี 2021 |
| อิมเมจเน็ต | การจำแนกประเภทภาพ | 1.28M ภาพ | ซีพีอาร์ 2009 |
| คิวบี | การจำแนกประเภทภาพ | นก 200 สายพันธุ์ | ทีโอจี 2011 |
อาปาเช่


