gen ai document sumarization
1.0.0
โปรเจ็กต์นี้สำรวจศักยภาพของโมเดล AI ที่สร้างโอเพ่นซอร์ส โดยเฉพาะอย่างยิ่งที่ใช้สถาปัตยกรรม Transformer สำหรับการสรุปเนื้อหาเอกสารโดยอัตโนมัติ เป้าหมายคือการประเมินและใช้โมเดล AI เจนเนอเรชั่นที่มีอยู่เพื่อวิเคราะห์ ทำความเข้าใจบริบท และสร้างบทสรุปสำหรับเอกสารที่ไม่มีโครงสร้าง
เพื่อให้บรรลุเป้าหมายนี้ ฉันได้ปรับแต่งโมเดลที่โดดเด่นสองโมเดล: t5-small และ facebook/bart-base โดยมุ่งเน้นที่การเพิ่มประสิทธิภาพในการสรุป
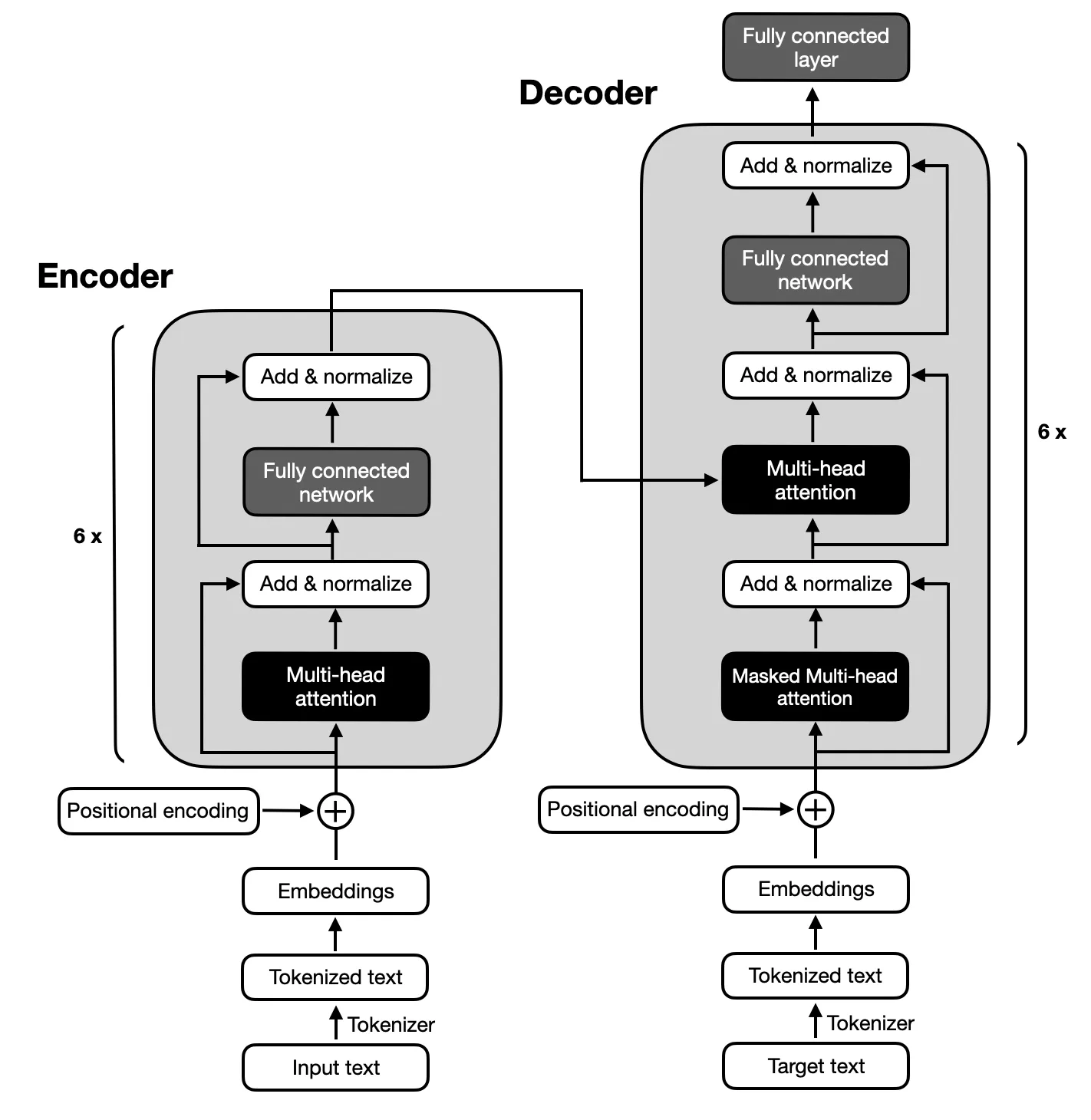
โฟกัสอยู่ที่โมเดลตัวเข้ารหัส-ตัวถอดรหัสตามสถาปัตยกรรมที่เสนอโดย Transformers ดั้งเดิม เนื่องจากการแมปที่ซับซ้อนระหว่างลำดับอินพุตและเอาต์พุตที่จำเป็นสำหรับการสรุปข้อความ โมเดลตัวเข้ารหัส-ตัวถอดรหัสเชี่ยวชาญในการจับความสัมพันธ์ภายในลำดับเหล่านี้ ทำให้เหมาะสำหรับงานนี้
ตรวจสอบให้แน่ใจว่า ติดตั้ง Python 3.x บนระบบของคุณแล้ว จากนั้น ทำตามขั้นตอนด้านล่างเพื่อตั้งค่าสภาพแวดล้อมของคุณ:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyโครงการประกอบด้วยหกขั้นตอนหลัก:
ชุดข้อมูลที่ใช้สำหรับการปรับแต่งโมเดล T5 และ BART อย่างละเอียดคือชุดข้อมูลสิทธิบัตรขนาดใหญ่ ซึ่งประกอบด้วยเอกสารสิทธิบัตรของสหรัฐอเมริกา 1.3 ล้านฉบับ พร้อมด้วยบทสรุปเชิงนามธรรมที่เขียนโดยมนุษย์ เอกสารแต่ละฉบับในชุดข้อมูลนี้จัดหมวดหมู่ภายใต้รหัส Cooperative Patent Classification (CPC) ซึ่งครอบคลุมหัวข้อต่างๆ มากมาย ตั้งแต่ความจำเป็นของมนุษย์ไปจนถึงฟิสิกส์และไฟฟ้า ความหลากหลายนี้ช่วยให้แน่ใจว่าโมเดลต้องเผชิญกับการใช้ภาษาและศัพท์เฉพาะทางเทคนิคที่หลากหลาย ซึ่งเป็นสิ่งสำคัญสำหรับการพัฒนาความสามารถในการสรุปที่มีประสิทธิภาพ
ชุดข้อมูลสิทธิบัตรขนาดใหญ่ได้รับเลือกเนื่องจากเกี่ยวข้องกับเป้าหมายของโครงการในการสรุปเอกสารที่ซับซ้อน สิทธิบัตรนั้นมีรายละเอียดและเป็นเทคนิคโดยเนื้อแท้ จึงเป็นความท้าทายในอุดมคติสำหรับการทดสอบความสามารถของแบบจำลองในการย่อข้อมูลในขณะที่ยังคงรักษาเนื้อหาหลักและบริบทไว้ รูปแบบโครงสร้างของชุดข้อมูลและการมีข้อมูลสรุปคุณภาพสูงเป็นรากฐานที่แข็งแกร่งสำหรับการฝึกอบรมและประเมินประสิทธิภาพของแบบจำลองในการสร้างข้อมูลสรุปที่แม่นยำและสอดคล้องกัน
ประสิทธิภาพของแบบจำลองได้รับการประเมินโดยใช้ตัวชี้วัด ROUGE โดยเน้นความสามารถในการสร้างบทสรุปที่สอดคล้องกับบทคัดย่อที่เขียนโดยมนุษย์อย่างใกล้ชิด ทั้งรุ่น BART และ T5 ได้รับการปรับแต่งอย่างละเอียดโดยใช้ชุดข้อมูลสิทธิบัตรขนาดใหญ่ โดยมุ่งเน้นที่การสรุปเชิงนามธรรมคุณภาพสูง
| เมตริก | ค่า |
|---|---|
| แพ้การประเมิน (Eval Loss) | 1.9244 |
| รูจ-1 | 0.5007 |
| รูจ-2 | 0.2704 |
| Rouge-L | 0.3627 |
| Rouge-Lsum | 0.3636 |
| ความยาวการสร้างเฉลี่ย (Gen Len) | 122.1489 |
| รันไทม์ (วินาที) | 1459.3826 |
| ตัวอย่างต่อวินาที | 1.312 |
| ขั้นตอนต่อวินาที | 0.164 |
| เมตริก | ค่า |
|---|---|
| แพ้การประเมิน (Eval Loss) | 1.9984 |
| รูจ-1 | 0.503 |
| รูจ-2 | 0.286 |
| Rouge-L | 0.3813 |
| Rouge-Lsum | 0.3813 |
| ความยาวการสร้างเฉลี่ย (Gen Len) | 151.918 |
| รันไทม์ (วินาที) | 714.4344 |
| ตัวอย่างต่อวินาที | 2.679 |
| ขั้นตอนต่อวินาที | 0.336 |


