JoyVASA
1.0.0
ซูหยาง เฉา 1* กัวซิน หวัง 12* เซิง ชิ 1* จุน จ้าว 1 หยาง เหยา 1
จินเตา เฟย 1 มินหยู เกา 1
1 บริษัท JD Health International Inc. 2 มหาวิทยาลัยเจ้อเจียง
แอนิเมชั่นแนวตั้งที่ขับเคลื่อนด้วยเสียงได้สร้างความก้าวหน้าอย่างมากด้วยโมเดลแบบกระจาย ปรับปรุงคุณภาพวิดีโอและความแม่นยำของลิปซิงค์ อย่างไรก็ตาม ความซับซ้อนที่เพิ่มขึ้นของโมเดลเหล่านี้ได้นำไปสู่ความไม่มีประสิทธิภาพในการฝึกอบรมและการอนุมาน เช่นเดียวกับข้อจำกัดเกี่ยวกับความยาวของวิดีโอและความต่อเนื่องระหว่างเฟรม ในบทความนี้ เราขอเสนอ JoyVASA ซึ่งเป็นวิธีการที่ใช้การแพร่กระจายเพื่อสร้างไดนามิกของใบหน้าและการเคลื่อนไหวของศีรษะในแอนิเมชั่นใบหน้าที่ขับเคลื่อนด้วยเสียง โดยเฉพาะอย่างยิ่ง ในขั้นตอนแรก เราจะแนะนำกรอบงานการแสดงใบหน้าแบบแยกส่วน ซึ่งแยกการแสดงสีหน้าแบบไดนามิกจากการแสดงใบหน้า 3 มิติแบบคงที่ การแยกส่วนนี้ทำให้ระบบสามารถสร้างวิดีโอที่ยาวขึ้นโดยการรวมการแสดงใบหน้า 3 มิติแบบคงที่เข้ากับลำดับการเคลื่อนไหวแบบไดนามิก จากนั้น ในขั้นที่สอง หม้อแปลงไฟฟ้าแบบกระจายจะได้รับการฝึกเพื่อสร้างลำดับการเคลื่อนไหวโดยตรงจากสัญญาณเสียง โดยไม่ขึ้นอยู่กับเอกลักษณ์ของตัวละคร สุดท้าย เครื่องกำเนิดไฟฟ้าที่ได้รับการฝึกในระยะแรกจะใช้การแสดงใบหน้าแบบ 3 มิติและลำดับการเคลื่อนไหวที่สร้างขึ้นเป็นอินพุตในการแสดงภาพเคลื่อนไหวคุณภาพสูง ด้วยการนำเสนอใบหน้าที่แยกจากกันและกระบวนการสร้างการเคลื่อนไหวที่ไม่ขึ้นกับตัวตน JoyVASA ขยายขอบเขตไปไกลกว่าการถ่ายภาพบุคคลเพื่อสร้างภาพเคลื่อนไหวให้กับใบหน้าของสัตว์ได้อย่างราบรื่น โมเดลนี้ได้รับการฝึกฝนบนชุดข้อมูลไฮบริดของข้อมูลภาษาจีนส่วนตัวและภาษาอังกฤษสาธารณะ ซึ่งเปิดใช้งานการสนับสนุนหลายภาษา ผลการทดลองตรวจสอบความมีประสิทธิผลของแนวทางของเรา งานในอนาคตจะมุ่งเน้นไปที่การปรับปรุงประสิทธิภาพแบบเรียลไทม์และการปรับปรุงการควบคุมการแสดงออก รวมถึงขยายแอปพลิเคชันของเฟรมเวิร์กในแอนิเมชั่นแนวตั้งเพิ่มเติม
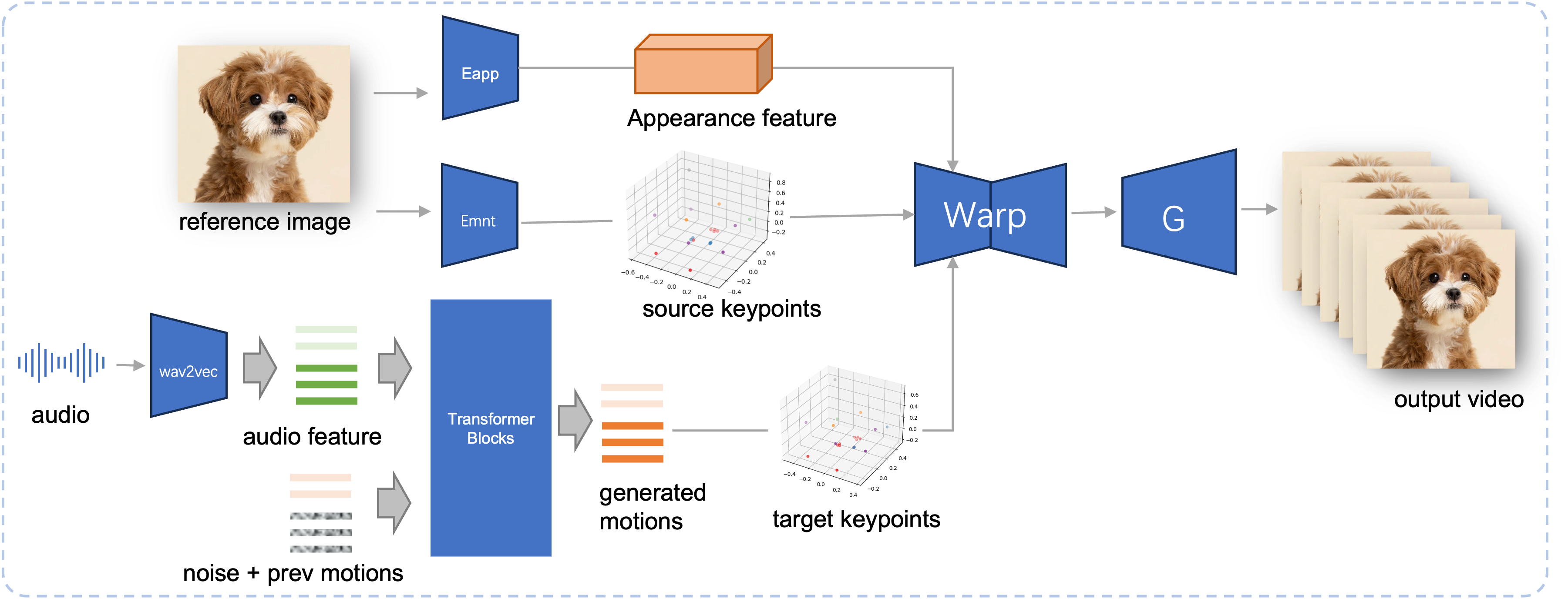
ไปป์ไลน์การอนุมานของ JoyVASA ที่เสนอ จากภาพอ้างอิง ขั้นแรกเราจะแยกคุณสมบัติลักษณะใบหน้า 3 มิติโดยใช้ตัวเข้ารหัสลักษณะที่ปรากฏใน LivePortrait และชุดของจุดสำคัญ 3 มิติที่เรียนรู้โดยใช้ตัวเข้ารหัสการเคลื่อนไหว สำหรับคำพูดอินพุต คุณสมบัติเสียงจะถูกแยกออกมาในตอนแรกโดยใช้ตัวเข้ารหัส wav2vec2 จากนั้นลำดับการเคลื่อนไหวที่ขับเคลื่อนด้วยเสียงจะถูกสุ่มตัวอย่างโดยใช้แบบจำลองการแพร่กระจายที่ได้รับการฝึกฝนในขั้นตอนที่สองในรูปแบบหน้าต่างบานเลื่อน การใช้จุดสำคัญ 3 มิติของภาพอ้างอิง และลำดับการเคลื่อนไหวของเป้าหมายที่สุ่มตัวอย่าง จะคำนวณจุดสำคัญเป้าหมาย สุดท้าย คุณลักษณะลักษณะใบหน้า 3 มิติจะถูกบิดเบี้ยวตามจุดสำคัญของแหล่งที่มาและเป้าหมาย และเรนเดอร์โดยเครื่องกำเนิดไฟฟ้าเพื่อสร้างวิดีโอเอาท์พุตขั้นสุดท้าย
ความต้องการของระบบ:
อูบุนตู:
ทดสอบบน Ubuntu 20.04, Cuda 11.3
GPU ที่ทดสอบแล้ว: A100
หน้าต่าง:
ทดสอบบน Windows 11, CUDA 12.1
GPU ที่ทดสอบ: แล็ปท็อป RTX 4060 8GB VRAM GPU
สร้างสภาพแวดล้อม:
# 1. สร้างสภาพแวดล้อมพื้นฐานconda create -n joyvasa python=3.10 -y conda เปิดใช้งานจอยวาซา # 2. ติดตั้ง Requirepip ติดตั้ง -r Requirements.txt# 3. ติดตั้ง ffmpegsudo apt-get update sudo apt-get ติดตั้ง ffmpeg -y# 4. ติดตั้ง MultiScaleDeformableAttentioncd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build installcd - # เท่ากับ cd ../../../../../../../
ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง git-lfs แล้วและดาวน์โหลดจุดตรวจสอบต่อไปนี้ทั้งหมดไปที่ pretrained_weights :
ติดตั้ง git lfs โคลนคอมไพล์ https://huggingface.co/jdh-algo/JoyVASA
เรารองรับตัวเข้ารหัสเสียงสองประเภท ได้แก่ wav2vec2-base และ hubert-chinese
รันคำสั่งต่อไปนี้เพื่อดาวน์โหลดตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้าของ Hubert-chinese:
ติดตั้ง git lfs โคลนคอมไพล์ https://huggingface.co/TencentGameMate/chinese-hubert-base
หากต้องการรับตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้าแบบฐาน wav2vec2 ให้รันคำสั่งต่อไปนี้:
ติดตั้ง git lfs โคลนคอมไพล์ https://huggingface.co/facebook/wav2vec2-base-960h
บันทึก
โมเดลการสร้างการเคลื่อนไหวที่มีตัวเข้ารหัส wav2vec2 จะได้รับการสนับสนุนในภายหลัง
# !pip ติดตั้ง -U "huggingface_hub[cli]"huggingface-cli ดาวน์โหลด KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
อ้างอิงถึง LivePortrait สำหรับวิธีการดาวน์โหลดเพิ่มเติม
pretrained_weights ไดเร็กทอรี pretrained_weights สุดท้ายควรมีลักษณะดังนี้:
./pretrained_weights/
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
├── JoyVASA
│ ├── motion_generator
│ │ └── iter_0020000.pt
│ └── motion_template
│ └── motion_template.pkl
├── liveportrait
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── landmark.onnx
│ └── retargeting_models
│ └── stitching_retargeting_module.pth
├── liveportrait_animals
│ ├── base_models
│ │ ├── appearance_feature_extractor.pth
│ │ ├── motion_extractor.pth
│ │ ├── spade_generator.pth
│ │ └── warping_module.pth
│ ├── retargeting_models
│ │ └── stitching_retargeting_module.pth
│ └── xpose.pth
├── TencentGameMate:chinese-hubert-base
│ ├── chinese-hubert-base-fairseq-ckpt.pt
│ ├── config.json
│ ├── gitattributes
│ ├── preprocessor_config.json
│ ├── pytorch_model.bin
│ └── README.md
└── wav2vec2-base-960h
├── config.json
├── feature_extractor_config.json
├── model.safetensors
├── preprocessor_config.json
├── pytorch_model.bin
├── README.md
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.jsonบันทึก
โฟลเดอร์ TencentGameMate:chinese-hubert-base ใน Windows ควรเปลี่ยนชื่อเป็น chinese-hubert-base
สัตว์:
python inference.py -r สินทรัพย์/ตัวอย่าง/imgs/joyvasa_001.png -a สินทรัพย์/ตัวอย่าง/audios/joyvasa_001.wav --animation_mode สัตว์ --cfg_scale 2.0
มนุษย์:
python inference.py -r สินทรัพย์/ตัวอย่าง/imgs/joyvasa_003.png -a สินทรัพย์/ตัวอย่าง/audios/joyvasa_003.wav --animation_mode มนุษย์ --cfg_scale 2.0
คุณสามารถเปลี่ยน cfg_scale เพื่อให้ได้ผลลัพธ์ที่มีการแสดงออกและท่าทางที่แตกต่างกัน
บันทึก
โหมดแอนิเมชั่นที่ไม่ตรงกันและรูปภาพอ้างอิงอาจส่งผลให้ผลลัพธ์ที่ไม่ถูกต้อง
ใช้คำสั่งต่อไปนี้เพื่อเริ่มการสาธิตเว็บ:
หลาม app.py
การสาธิตจะถูกสร้างขึ้นที่ http://127.0.0.1:7862
หากคุณพบว่างานของเรามีประโยชน์ โปรดพิจารณาอ้างอิงถึงเรา:
@misc{cao2024joyvasaportraitanimalimage,
title={JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation},
author={Xuyang Cao and Guoxin Wang and Sheng Shi and Jun Zhao and Yang Yao and Jintao Fei and Minyu Gao},
year={2024},
eprint={2411.09209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.09209},
}เราขอขอบคุณผู้ร่วมให้ข้อมูล LivePortrait, Open Facevid2vid, InsightFace, X-Pose, DiffPoseTalk, Hallo, wav2vec 2.0, Chinese Speech Pretrain, Q-Align, Syncnet และ VBench สำหรับการวิจัยแบบเปิดและงานพิเศษของพวกเขา


