synthetic data generator
0.2.3
สลับภาษา: 简体中文 | เอกสาร API ล่าสุด | แผนงาน | เข้าร่วมกลุ่มวีแชท
ตัวอย่าง Colab: LLM: การสังเคราะห์ข้อมูล | LLM: การอนุมานนอกตาราง | CTGAN รองรับข้อมูลระดับพันล้าน
Synthetic Data Generator (SDG) เป็นเฟรมเวิร์กเฉพาะที่ออกแบบมาเพื่อสร้างข้อมูลตารางที่มีโครงสร้างคุณภาพสูง
ข้อมูลสังเคราะห์ไม่มีข้อมูลที่ละเอียดอ่อนใดๆ แต่ยังคงรักษาคุณลักษณะที่สำคัญของข้อมูลต้นฉบับ ทำให้ได้รับการยกเว้นจากกฎระเบียบด้านความเป็นส่วนตัว เช่น GDPR และ ADPPA
ข้อมูลสังเคราะห์คุณภาพสูงสามารถนำไปใช้ได้อย่างปลอดภัยในโดเมนต่างๆ รวมถึงการแบ่งปันข้อมูล การฝึกโมเดลและการดีบัก การพัฒนาและทดสอบระบบ ฯลฯ
เรารู้สึกตื่นเต้นที่คุณอยู่ที่นี่และหวังว่าจะมีส่วนร่วมของคุณ เริ่มต้นโครงการผ่านคู่มือภาพรวมการมีส่วนร่วมนี้!
ความสำเร็จและกรอบเวลาที่สำคัญของเราในปัจจุบันมีดังนี้:
21 พ.ย. 2024: 1) การบูรณาการโมเดล - เราได้รวมโมเดล GaussianCopula เข้ากับระบบประมวลผลข้อมูลของเรา ลองดูตัวอย่างโค้ดใน PR นี้ 2) คุณภาพสังเคราะห์ - เราใช้การตรวจจับความสัมพันธ์ของคอลัมน์ข้อมูลโดยอัตโนมัติและอนุญาตให้ระบุความสัมพันธ์ ปรับปรุงคุณภาพของข้อมูลสังเคราะห์ (ตัวอย่างโค้ด) 3) การเพิ่มประสิทธิภาพ - เราลดการใช้หน่วยความจำของ GaussianCopula ลงอย่างมากเมื่อจัดการข้อมูลที่ไม่ต่อเนื่อง ช่วยให้สามารถฝึกอบรมรายการข้อมูลหมวดหมู่หลายพันรายการด้วยการตั้งค่า 2C4G !
30 พฤษภาคม 2024: โมดูลตัวประมวลผลข้อมูลถูกรวมเข้าด้วยกันอย่างเป็นทางการ โมดูลนี้จะ: 1) ช่วย SDG แปลงรูปแบบของคอลัมน์ข้อมูลบางส่วน (เช่น คอลัมน์วันที่เวลา) ก่อนที่จะป้อนลงในโมเดล (เพื่อหลีกเลี่ยงไม่ให้ถือเป็นประเภทแยกกัน) และแปลงข้อมูลที่สร้างโดยโมเดลกลับด้านเป็นรูปแบบดั้งเดิม ; 2) ทำการประมวลผลล่วงหน้าและหลังการประมวลผลที่กำหนดเองมากขึ้นในประเภทข้อมูลต่างๆ 3) จัดการกับปัญหาได้อย่างง่ายดาย เช่น ค่า Null ในข้อมูลต้นฉบับ 4) รองรับระบบปลั๊กอิน
20 ก.พ. 2024: รวมโมเดลการสังเคราะห์ข้อมูลตารางเดียวที่ใช้ LLM ไว้ด้วย ดูตัวอย่าง colab: LLM: การสังเคราะห์ข้อมูล และ LLM: การอนุมานคุณลักษณะนอกตาราง
7 กุมภาพันธ์ 2024: เราได้ปรับปรุง sdgx.data_models.metadata ให้รองรับข้อมูลเมตาดาต้าที่อธิบายสำหรับตารางเดี่ยวและหลายตาราง รองรับประเภทข้อมูลหลายประเภท รองรับการอนุมานประเภทข้อมูลอัตโนมัติ ดูตัวอย่าง colab: ข้อมูลเมตา SDG ตารางเดียว
20 ธันวาคม 2023: v0.1.0 เปิดตัว โดยมีโมเดล CTGAN ที่รองรับความสามารถในการประมวลผลข้อมูลนับพันล้านรายการ ดูเกณฑ์มาตรฐานของเราเทียบกับ SDV ซึ่ง SDG ใช้หน่วยความจำน้อยลง และหลีกเลี่ยงการหยุดทำงานระหว่างการฝึก สำหรับการใช้งานเฉพาะ ให้ดูตัวอย่าง colab: CTGAN ที่รองรับข้อมูลระดับพันล้าน
10 ส.ค. 2023: บรรทัดแรกของโค้ด SDG ที่คอมมิต
เป็นเวลานานแล้วที่ LLM ถูกนำมาใช้ในการทำความเข้าใจและสร้างข้อมูลประเภทต่างๆ ในความเป็นจริง LLM ยังมีความสามารถบางอย่างในการสร้างข้อมูลแบบตารางอีกด้วย นอกจากนี้ยังมีความสามารถบางอย่างที่ไม่สามารถทำได้ด้วยวิธีดั้งเดิม (ขึ้นอยู่กับวิธี GAN หรือวิธีทางสถิติ)
sdgx.models.LLM.single_table.gpt.SingleTableGPTModel ของเราใช้คุณสมบัติใหม่สองประการ:
ไม่จำเป็นต้องมีข้อมูลการฝึกอบรม ข้อมูลสังเคราะห์สามารถสร้างขึ้นตามข้อมูลเมตาดาต้าได้ ดูในตัวอย่าง Colab ของเรา
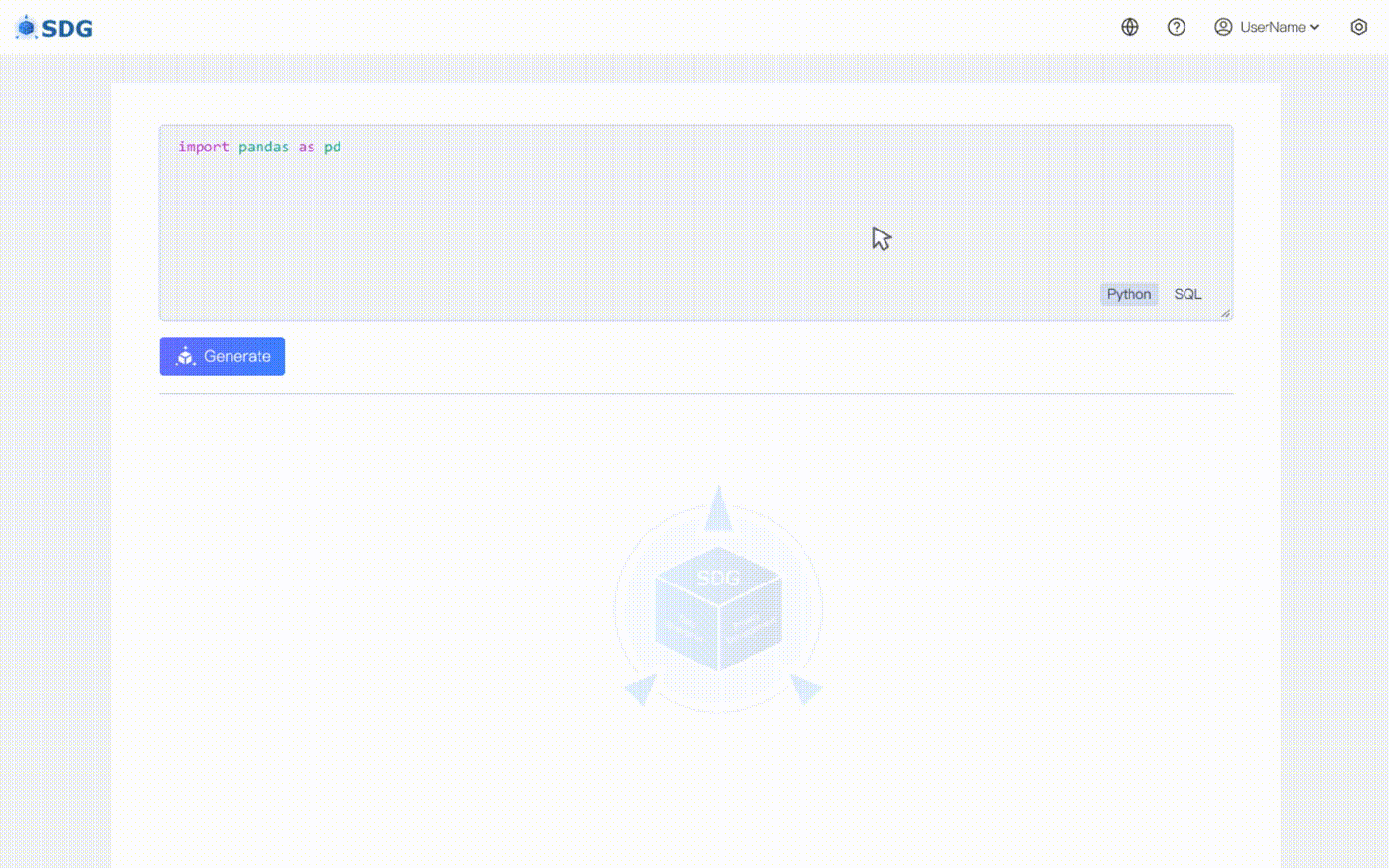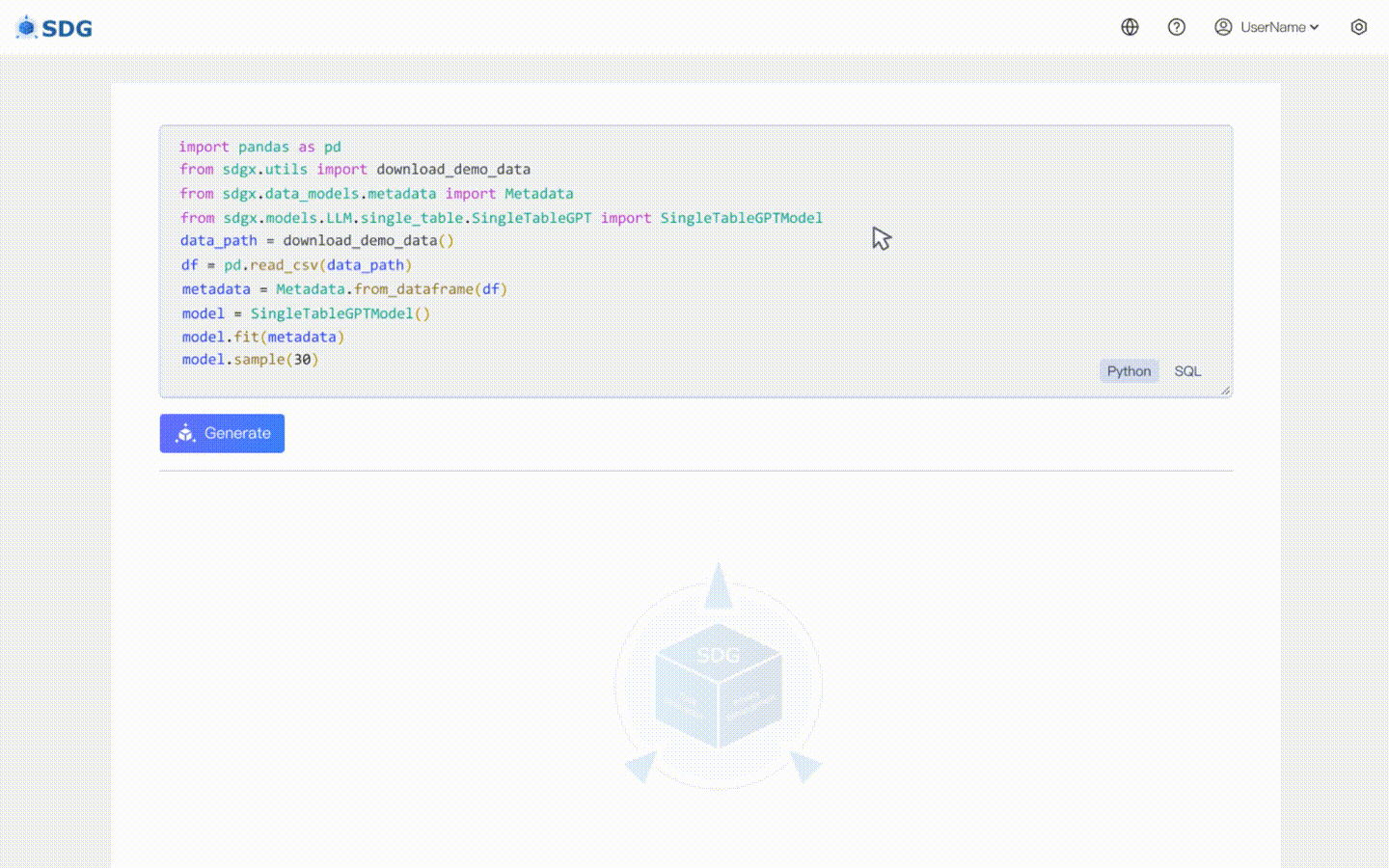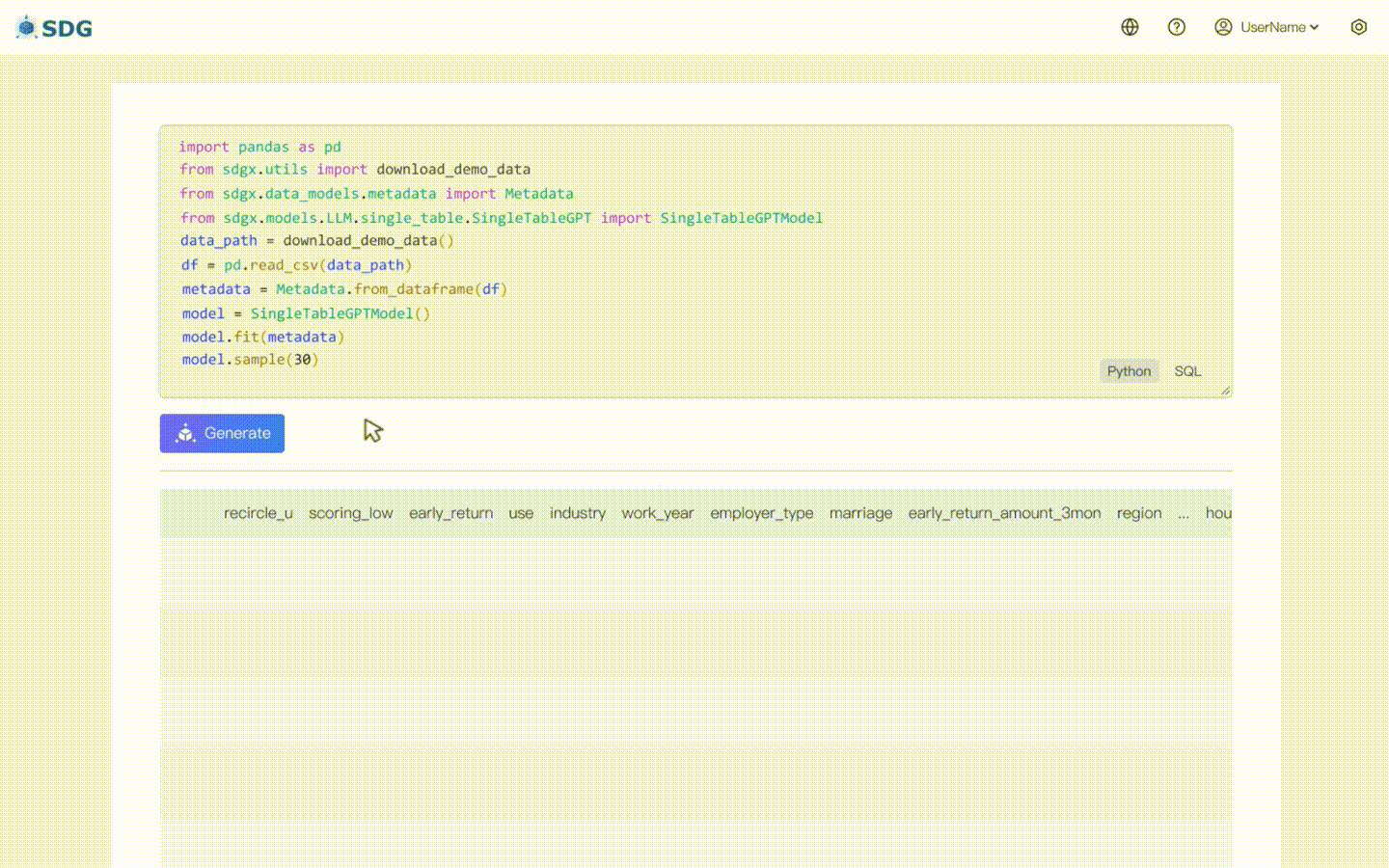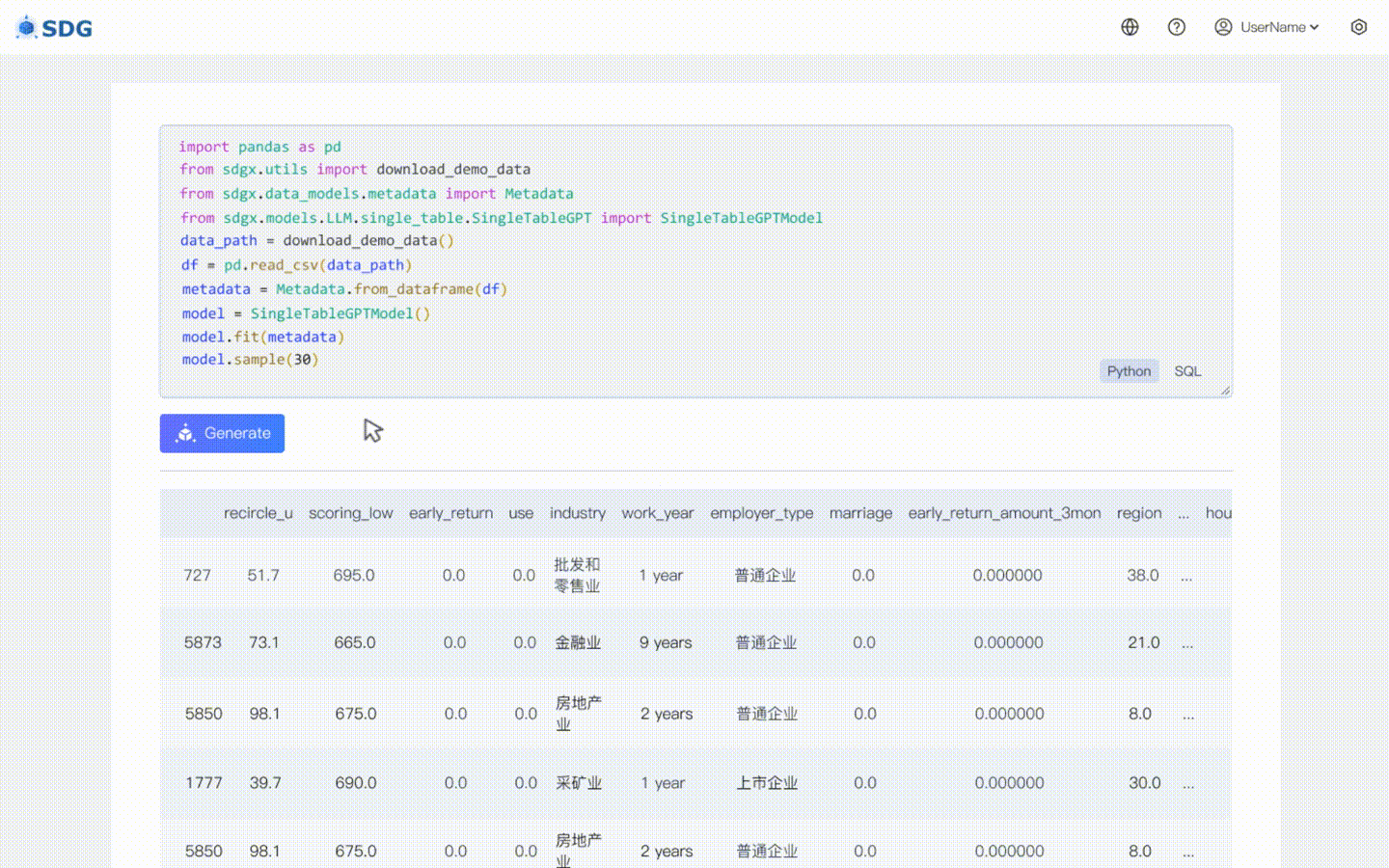
สรุปข้อมูลคอลัมน์ใหม่ตามข้อมูลที่มีอยู่ในตารางและความรู้ที่ LLM เชี่ยวชาญ ดูในตัวอย่าง colab ของเรา
ความก้าวหน้าทางเทคโนโลยี:
รองรับอัลกอริธึมการสังเคราะห์ข้อมูลทางสถิติที่หลากหลาย อีกทั้งยังผสานรวมโมเดลการสร้างข้อมูลสังเคราะห์ที่ใช้ LLM เข้าด้วยกันอีกด้วย
ปรับให้เหมาะสมสำหรับข้อมูลขนาดใหญ่ ลดการใช้หน่วยความจำอย่างมีประสิทธิภาพ
ติดตามความก้าวหน้าล่าสุดในด้านวิชาการและอุตสาหกรรมอย่างต่อเนื่อง และแนะนำการสนับสนุนอัลกอริธึมและแบบจำลองที่ยอดเยี่ยมในเวลาที่เหมาะสม
การปรับปรุงความเป็นส่วนตัว:
SDG สนับสนุน Differential Privacy การลบข้อมูลระบุตัวตน และวิธีการอื่นๆ เพื่อเพิ่มความปลอดภัยของข้อมูลสังเคราะห์
ง่ายต่อการขยาย:
รองรับการขยายโมเดล การประมวลผลข้อมูล ตัวเชื่อมต่อข้อมูล ฯลฯ ในรูปแบบของแพ็คเกจปลั๊กอิน
คุณสามารถใช้รูปภาพที่สร้างไว้ล่วงหน้าเพื่อสัมผัสประสบการณ์คุณสมบัติล่าสุดได้อย่างรวดเร็ว
นักเทียบท่าดึง idsteam/sdgx:latest
pip ติดตั้ง sdgx
ใช้ SDG โดยการติดตั้งผ่านซอร์สโค้ด
โคลนคอมไพล์ [email protected]:hitsz-ids/synthetic-data-generator.git pip install .# หรือติดตั้งจาก gitpip ติดตั้ง git+https://github.com/hitsz-ids/synthetic-data-generator.git
จาก sdgx.data_connectors.csv_connector นำเข้า CsvConnector จาก sdgx.models.ml.single_table.ctgan นำเข้า CTGANSynthesizerModel จาก sdgx.synthesizer นำเข้า Synthesizer จาก sdgx.utils นำเข้า download_demo_data# สิ่งนี้จะดาวน์โหลดข้อมูลสาธิตไปที่ ./datasetdataset_csv = download_demo_data()# สร้างตัวเชื่อมต่อข้อมูล สำหรับ csv filedata_connector = CsvConnector(path=dataset_csv)# เริ่มต้นซินธิไซเซอร์ ให้ใช้ CTGAN modelsynthesizer = Synthesizer(model=CTGANSynthesizerModel(epochs=1), # สำหรับ demodata_connector=data_connector อย่างรวดเร็ว )# พอดีกับ modelsynthesizer.fit()# Samplesampled_data = synthesizer.sample(1000)print(sampled_data)
ข้อมูลจริงมีดังนี้:
>>> data_connector.read() อายุ workclass fnlwgt การศึกษา ... capitalloss ชั่วโมงต่อสัปดาห์ Native-country class0 2 State-gov 77516 Bachelors ... 0 2 United-States <=50K1 3 Self-emp-not-inc 83311 Bachelors .. . 0 0 สหรัฐอเมริกา <=50K2 2 เอกชน 215646 HS-grad ... 0 2 สหรัฐอเมริกา <=50K3 3 ส่วนตัว 234721 11 ... 0 2 สหรัฐอเมริกา <=50K4 1 ส่วนตัว 338409 ปริญญาตรี ... 0 2 คิวบา <=50K... ... ... ... ... ... . .. ... ... ...48837 2 เอกชน 215419 ปริญญาตรี ... 0 2 สหรัฐอเมริกา <=50K48838 4 NaN 321403 HS-grad ... 0 2 สหรัฐอเมริกา <=50K48839 2 ส่วนตัว 374983 ปริญญาตรี ... 0 3 สหรัฐอเมริกา <=50K48840 2 ส่วนตัว 83891 ปริญญาตรี ... 0 2 สหรัฐอเมริกา <=50K48841 1 Self-emp-inc 182148 ปริญญาตรี ... 0 3 สหรัฐอเมริกา >50K[48842 แถว x 15 คอลัมน์]
ข้อมูลสังเคราะห์มีดังนี้:
>>> Sampled_data อายุ workclass fnlwgt การศึกษา ... capitalloss ชั่วโมงต่อสัปดาห์ Native-country class0 1 NaN 28219 Some-college ... 0 2 Puerto-Rico <=50K1 2 Private 250166 HS-grad ... 0 2 United-States >50K2 2 ส่วนตัว 50304 HS-grad ... 0 2 สหรัฐอเมริกา <=50K3 4 ส่วนตัว 89318 ปริญญาตรี ... 0 2 เปอร์โตริโก >50K4 1 ส่วนตัว 172149 ปริญญาตรี ... 0 3 สหรัฐอเมริกา <=50K.. ... ... ... ... ... ... ... ... ...995 2 NaN 208938 ปริญญาตรี ... 0 1 United-States <=50K996 2 ส่วนตัว 166416 ปริญญาตรี ... 2 2 United-States <=50K997 2 NaN 336022 HS-grad ... 0 1 สหรัฐอเมริกา <=50K998 3 เอกชน 198051 Masters ... 0 2 สหรัฐอเมริกา >50K999 1 NaN 41973 HS-grad ... 0 2 สหรัฐอเมริกา <= 50K[1,000 แถว x 15 คอลัมน์]
CTGAN:การสร้างแบบจำลองข้อมูลแบบตารางโดยใช้ GAN แบบมีเงื่อนไข
C3-TGAN: C3-TGAN- การสังเคราะห์ข้อมูลแบบตารางที่ควบคุมได้พร้อมความสัมพันธ์ที่ชัดเจนและข้อจำกัดของคุณสมบัติ
TVAE:การสร้างแบบจำลองข้อมูลแบบตารางโดยใช้ GAN แบบมีเงื่อนไข
table-GAN:การสังเคราะห์ข้อมูลตาม Generative Adversarial Networks
CTAB-GAN:CTAB-GAN: การสังเคราะห์ข้อมูลตารางที่มีประสิทธิภาพ
OCT-GAN: OCT-GAN: GAN แบบตารางตามเงื่อนไขที่ใช้ ODE แบบประสาท
โครงการ SDG ริเริ่มโดย สถาบันความปลอดภัยข้อมูล สถาบันเทคโนโลยีฮาร์บิน หากคุณสนใจที่จะออกโครงการ ยินดีต้อนรับสู่ชุมชนของเรา เรายินดีต้อนรับองค์กร ทีมงาน และบุคคลที่แบ่งปันความมุ่งมั่นของเราในการปกป้องข้อมูลและความปลอดภัยผ่านโอเพ่นซอร์ส:
อ่านการมีส่วนร่วมก่อนร่างคำขอดึง
ส่งปัญหาโดยการดู View Good First Issue หรือส่งคำขอดึง
เข้าร่วมกลุ่ม Wechat ของเราผ่านรหัส QR