clearml agent
v1.9.2

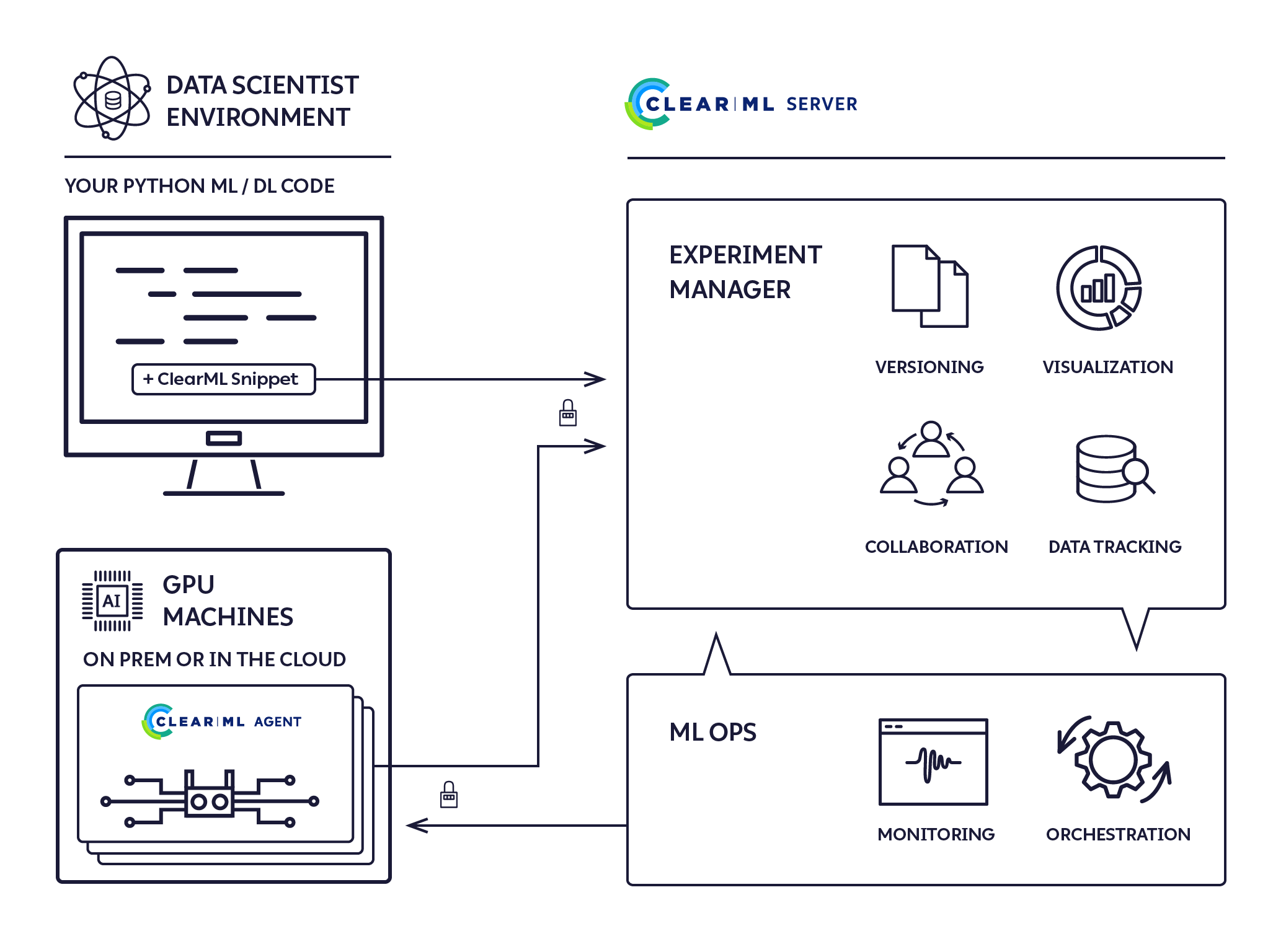
ClearML Agent - MLOps/LLMOps เป็นเรื่องง่าย
โซลูชันตัวกำหนดเวลาและการจัดประสาน MLOps/LLMOps รองรับ Linux, macOS และ Windows
? ClearML is open-source - Leave a star to support the project! ?
เป็นเอเจนต์การดำเนินการแบบ Fire-and-Forget ที่มีการกำหนดค่าเป็นศูนย์ ซึ่งมอบโซลูชันคลัสเตอร์ ML/DL เต็มรูปแบบ
ระบบอัตโนมัติเต็มรูปแบบใน 5 ขั้นตอน
pip install clearml-agent (ติดตั้ง ClearML Agent บนเครื่อง GPU ใด ๆ : ภายในองค์กร / คลาวด์ / ... )"DeepOps การเรียนรู้เชิงลึก/การเรียนรู้ของเครื่องทั้งหมดที่คุณต้องการ และบางส่วน... เพราะไม่มีใครมีเวลาสำหรับสิ่งนั้น"
ลองใช้ ClearML ตอนนี้ โฮสต์ด้วยตนเองหรือโฮสติ้งระดับฟรี 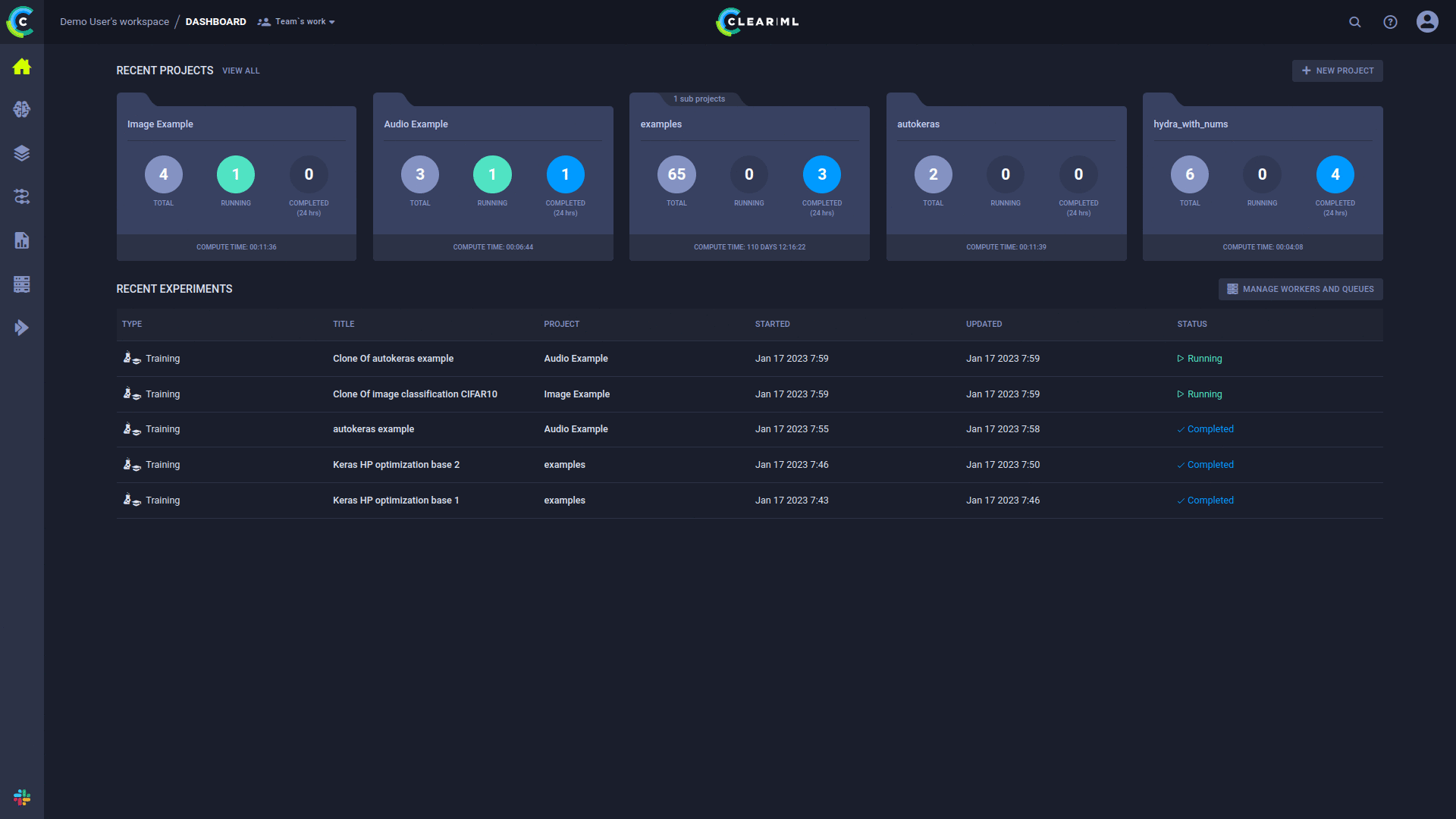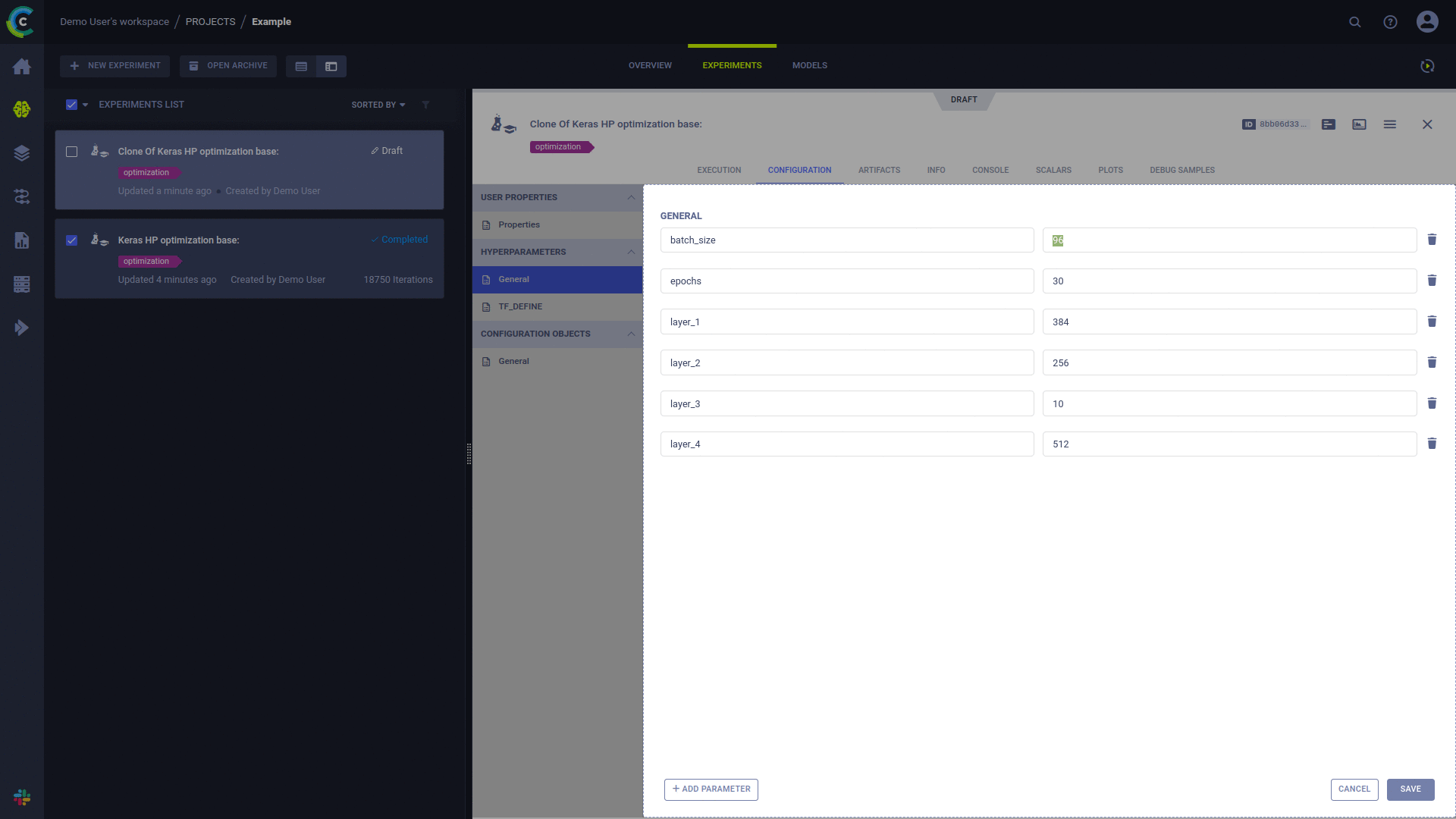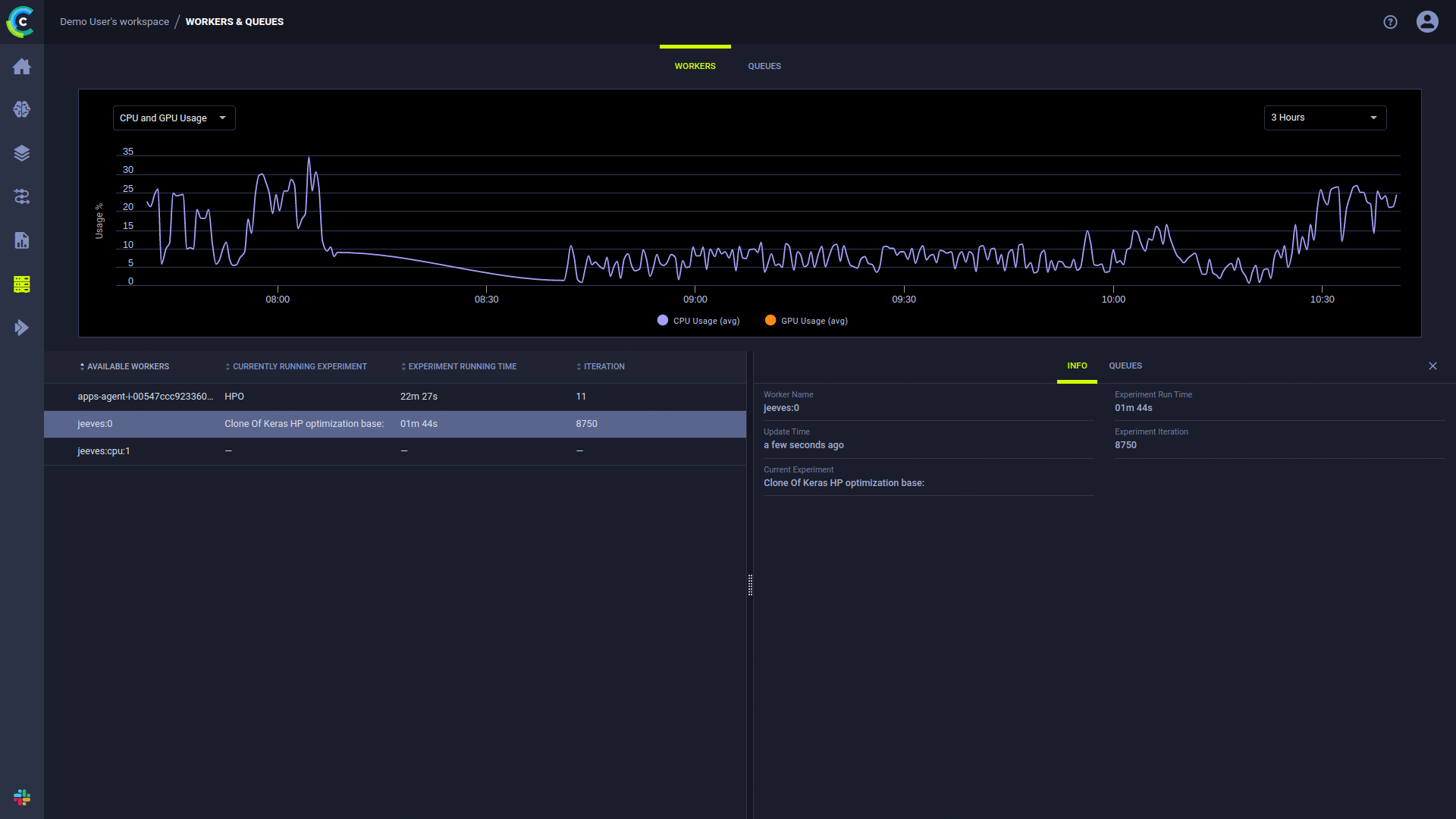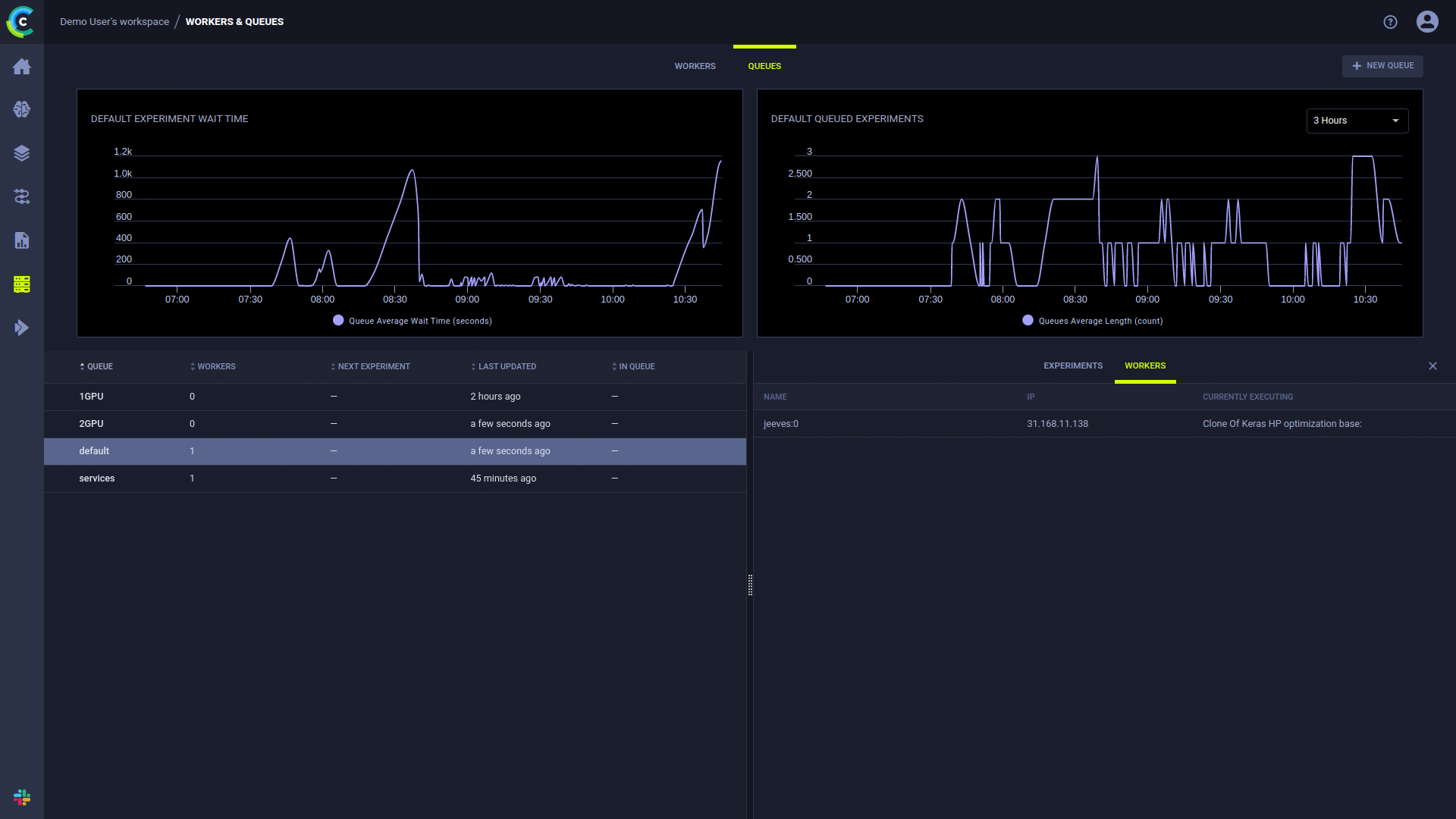
ClearML Agent ถูกสร้างขึ้นเพื่อตอบสนองความต้องการ DevOps การวิจัยและพัฒนา DL/ML:
เมื่อใช้ ClearML Agent คุณสามารถตั้งค่าคลัสเตอร์แบบไดนามิกด้วย *epsilon DevOps ได้แล้ว
*เอปไซลอน - เพราะเราเป็น ? และไม่มีอะไรที่เป็นศูนย์จริงๆ
เราคิดว่า Kubernetes นั้นยอดเยี่ยม แต่ก็ไม่จำเป็นเมื่อเริ่มต้นใช้งานเอเจนต์การดำเนินการระยะไกลและการจัดการคลัสเตอร์ เราออกแบบ clearml-agent เพื่อให้คุณสามารถรันทั้ง Bare-Metal และบน Kubernetes ในรูปแบบผสมผสานที่เหมาะกับสภาพแวดล้อมของคุณ
คุณสามารถค้นหา Dockerfiles ได้ในโฟลเดอร์ docker และ helm Chart ใน https://github.com/allegroai/clearml-helm-charts
รันเอเจนต์ในโหมด Kubernetes Glue และแมปงาน ClearML โดยตรงกับงาน K8s:
ใช่! มีการบูรณาการ Slurm โปรดดูรายละเอียดเพิ่มเติมในเอกสารประกอบ
HPC เต็มรูปแบบด้วยการคลิกเพียงปุ่มเดียว
ClearML Agent เป็นตัวกำหนดเวลางานที่คอยฟังคิวงาน ดึงงาน ตั้งค่าสภาพแวดล้อมของงาน ดำเนินงาน และติดตามความคืบหน้า
การทดสอบ 'ฉบับร่าง' ใดๆ สามารถกำหนดเวลาให้ดำเนินการโดยตัวแทน ClearML ได้
การทดสอบที่ดำเนินการก่อนหน้านี้สามารถกำหนดให้อยู่ในสถานะ 'ฉบับร่าง' ได้ด้วยวิธีใดวิธีหนึ่งจากสองวิธี:
การทดสอบได้รับการกำหนดเวลาสำหรับการดำเนินการโดยใช้การดำเนินการ 'จัดคิว' จากเมนูบริบทคลิกขวาที่การทดสอบใน ClearML UI และเลือกคิวการดำเนินการ
ดูการสร้างการทดสอบและการจัดคิวเพื่อดำเนินการ
เมื่อการทดลองเข้าคิวแล้ว การทดลองจะถูกหยิบขึ้นมาและดำเนินการโดยตัวแทน ClearML ที่คอยติดตามคิวนี้
หน้า ClearML UI Workers & Queues ให้ข้อมูลการดำเนินการอย่างต่อเนื่อง:
ClearML Agent ดำเนินการทดลองโดยใช้กระบวนการต่อไปนี้:
pip install clearml-agentมีอินเทอร์เฟซและความสามารถเต็มรูปแบบด้วย
clearml-agent --help
clearml-agent daemon --helpclearml-agent init หมายเหตุ: ClearML Agent ใช้โฟลเดอร์แคชเพื่อแคชแพ็คเกจ pip, แพ็คเกจ apt และที่เก็บโคลน โฟลเดอร์แคช ClearML Agent เริ่มต้นคือ ~/.clearml
ดูรายละเอียดทั้งหมดในไฟล์กำหนดค่าของคุณที่ ~/clearml.conf
หมายเหตุ: ClearML Agent จะขยายไฟล์คอนฟิกูเรชัน ClearML ~/clearml.conf ได้รับการออกแบบมาเพื่อแชร์ไฟล์การกำหนดค่าเดียวกัน ดูตัวอย่างที่นี่
สำหรับการดีบักและการทดลอง ให้เริ่มเอเจนต์ ClearML ในโหมด foreground โดยที่เอาต์พุตทั้งหมดจะถูกพิมพ์ลงบนหน้าจอ:
clearml-agent daemon --queue default --foreground สำหรับโหมดบริการจริง stdout ทั้งหมดจะถูกจัดเก็บไว้ในไฟล์ชั่วคราวโดยอัตโนมัติ (ไม่จำเป็นต้องไปป์) หมายเหตุ: ด้วยแฟล็ก --detached clearml-agent จะทำงานอยู่เบื้องหลัง
clearml-agent daemon --detached --queue default การจัดสรร GPU ถูกควบคุมผ่านสภาพแวดล้อมระบบปฏิบัติการมาตรฐาน NVIDIA_VISIBLE_DEVICES หรือแฟล็ก --gpus (หรือปิดใช้งานด้วย --cpu-only )
หากไม่มีการตั้งค่าสถานะ และไม่มีตัวแปร NVIDIA_VISIBLE_DEVICES GPU ทั้งหมดจะถูกจัดสรรสำหรับ clearml-agent
หากตั้งค่าสถานะ --cpu-only หรือ NVIDIA_VISIBLE_DEVICES="none" จะไม่มีการจัดสรร GPU สำหรับ clearml-agent
ตัวอย่าง: หมุนเอเจนต์สองตัว หนึ่งตัวต่อ GPU บนเครื่องเดียวกัน:
หมายเหตุ: ด้วยแฟล็ก --detached clearml-agent จะทำงานอยู่เบื้องหลัง
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default ตัวอย่าง: หมุนเอเจนต์สองตัว โดยดึงจากคิว dual_gpu เฉพาะ, GPU สองตัวต่อเอเจนต์
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu สำหรับการดีบักและการทดลอง ให้เริ่มเอเจนต์ ClearML ในโหมด foreground ซึ่งเอาต์พุตทั้งหมดจะถูกพิมพ์ลงบนหน้าจอ
clearml-agent daemon --queue default --docker --foreground สำหรับโหมดบริการจริง stdout ทั้งหมดจะถูกจัดเก็บไว้ในไฟล์โดยอัตโนมัติ (ไม่จำเป็นต้องไปป์) หมายเหตุ: ด้วยแฟล็ก --detached clearml-agent จะทำงานอยู่เบื้องหลัง
clearml-agent daemon --detached --queue default --docker ตัวอย่าง: หมุนเอเจนต์สองตัว หนึ่งตัวต่อ GPU บนเครื่องเดียวกัน โดยมีค่าเริ่มต้น nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 docker:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 ตัวอย่าง: หมุนเอเจนต์สองตัว โดยดึงจากคิว dual_gpu เฉพาะ สอง GPU ต่อเอเจนต์ โดยมีค่าเริ่มต้น nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 docker:
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04นอกจากนี้ยังรองรับ Priority Queues ด้วย ตัวอย่างการใช้งาน:
คิวที่มีลำดับความสำคัญสูง: important_jobs , คิวที่มีลำดับความสำคัญต่ำ: default
clearml-agent daemon --queue important_jobs default ขั้นแรก ตัวแทน ClearML จะพยายามดึงงานจากคิว important_jobs และเฉพาะในกรณีที่ว่างเปล่า เอเจนต์จะพยายามดึงจากคิว default
การเพิ่มคิว การจัดการคำสั่งงานภายในคิว และการย้ายงานระหว่างคิว สามารถทำได้โดยใช้ Web UI ดูตัวอย่างบนเซิร์ฟเวอร์ฟรีของเรา
หากต้องการหยุดการทำงาน ของตัวแทน ClearML ในเบื้องหลัง ให้เรียกใช้บรรทัดคำสั่งเดียวกับที่ใช้ในการเริ่มต้นตัวแทนด้วย --stop ต่อท้าย ตัวอย่างเช่น หากต้องการหยุดเครื่องแรกจากเครื่องเดียวกันที่แสดงข้างต้น ให้ใช้เอเจนต์ GPU เดี่ยว:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopผสานรวม ClearML เข้ากับโค้ดของคุณ
รันโค้ดบนเครื่องของคุณ (ด้วยตนเอง / PyCharm / Jupyter Notebook)
ขณะที่โค้ดของคุณกำลังทำงาน ClearML จะสร้างการทดลองบันทึกข้อมูลการดำเนินการที่จำเป็นทั้งหมด:
ขณะนี้ คุณมี 'เทมเพลต' ของการทดสอบของคุณพร้อมทุกสิ่งที่จำเป็นสำหรับการดำเนินการอัตโนมัติ
ใน ClearML UI ให้คลิกขวาที่การทดสอบและเลือก 'โคลน' สำเนาการทดสอบของคุณจะถูกสร้างขึ้น
ขณะนี้คุณมีการทดสอบฉบับร่างใหม่ที่ลอกแบบมาจากการทดสอบเดิมของคุณแล้ว อย่าลังเลที่จะแก้ไข
กำหนดเวลาการทดสอบที่สร้างขึ้นใหม่เพื่อดำเนินการ: คลิกขวาที่การทดสอบและเลือก 'จัดคิว'
ClearML-Agent Services เป็นโหมดพิเศษของ ClearML-Agent ที่ให้ความสามารถในการเริ่มงานที่ยาวนานซึ่งก่อนหน้านี้ต้องดำเนินการบนเครื่องเฉพาะที่/เฉพาะ อนุญาตให้ตัวแทนรายเดียวเปิดใช้นักเทียบท่าหลายคน (งาน) สำหรับกรณีการใช้งานที่แตกต่างกัน:
โหมดบริการ ClearML-Agent จะหมุนงาน ใด ๆ ที่อยู่ในคิวที่ระบุ ทุกงานที่เปิดตัวโดย ClearML-Agent Services จะถูกลงทะเบียนเป็นโหนดใหม่ในระบบ ซึ่งให้ความสามารถในการติดตามและความโปร่งใส ปัจจุบัน clearml-agent ในโหมดบริการรองรับการกำหนดค่า CPU เท่านั้น โหมดบริการ ClearML-Agent สามารถเปิดใช้งานควบคู่ไปกับตัวแทน GPU ได้
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-onlyหมายเหตุ : เป็นความรับผิดชอบของผู้ใช้ที่จะต้องแน่ใจว่างานที่เหมาะสมถูกผลักเข้าไปในคิวที่ระบุ
นอกจากนี้ ClearML Agent ยังสามารถใช้เพื่อปรับใช้การเรียบเรียง AutoML และไปป์ไลน์การทดลองร่วมกับแพ็คเกจ ClearML ได้อีกด้วย
ตัวอย่าง AutoML & Orchestration สามารถพบได้ในโฟลเดอร์ตัวอย่าง/ระบบอัตโนมัติของ ClearML
ตัวอย่าง AutoML:
ตัวอย่างไปป์ไลน์การทดสอบ:
Apache License เวอร์ชัน 2.0 (ดูใบอนุญาตสำหรับข้อมูลเพิ่มเติม)


