[กระดาษ] [หน้าโครงการ ] [รุ่น miniFLUX ] [รุ่น SD3 ⚡️] [สาธิต ?]
นี่คือพื้นที่เก็บข้อมูลอย่างเป็นทางการสำหรับ Pyramid Flow ซึ่งเป็นวิธี การสร้างวิดีโอแบบถอยหลังอัตโนมัติ ที่มีประสิทธิภาพในการฝึกอบรมโดยยึดตาม Flow Matching ด้วยการฝึกอบรมเฉพาะ ชุดข้อมูลโอเพ่นซอร์ส สามารถสร้างวิดีโอคุณภาพสูงความยาว 10 วินาทีที่ความละเอียด 768p และ 24 FPS และรองรับการสร้างภาพเป็นวิดีโอโดยธรรมชาติ
| 10 วินาที, 768p, 24fps | 5 วินาที, 768p, 24fps | รูปภาพเป็นวิดีโอ |
|---|---|---|
ดอกไม้ไฟ.mp4 | เทรลเลอร์.mp4 | วันอาทิตย์.mp4 |
2024.11.13 เราเปิดตัวจุดตรวจสอบ miniFLUX 768p (สูงสุด 10 วินาที)
เราได้เปลี่ยนโครงสร้างโมเดลจาก SD3 เป็น mini FLUX เพื่อแก้ไขปัญหาเกี่ยวกับโครงสร้างของมนุษย์ โปรดลองใช้จุดตรวจสอบภาพ 1024p, จุดตรวจสอบวิดีโอ 384p (สูงสุด 5 วินาที) และจุดตรวจสอบวิดีโอ 768p (สูงสุด 10 วินาที) โมเดล miniflux ใหม่แสดงให้เห็นการปรับปรุงโครงสร้างของมนุษย์และความเสถียรของการเคลื่อนไหวอย่างมาก
2024.10.29 ⚡️⚡️⚡️ เราเปิดตัวรหัสการฝึกอบรมสำหรับ VAE, โค้ดปรับแต่งสำหรับ DiT และจุดตรวจรุ่นใหม่พร้อมโครงสร้าง FLUX ที่ได้รับการฝึกอบรมตั้งแต่เริ่มต้น
2024.10.13 รองรับการอนุมาน Multi-GPU และการถ่าย CPU ใช้กับหน่วยความจำ GPU น้อยกว่า 8GB พร้อมการเร่งความเร็วที่ยอดเยี่ยมบน GPU หลายตัว
2024.10.11 ??? มีการสาธิตการกอดใบหน้าแล้ว ขอบคุณ @multimodalart สำหรับความมุ่งมั่น!
2024.10.10 เราเผยแพร่รายงานทางเทคนิค หน้าโครงการ และจุดตรวจสอบแบบจำลองของ Pyramid Flow
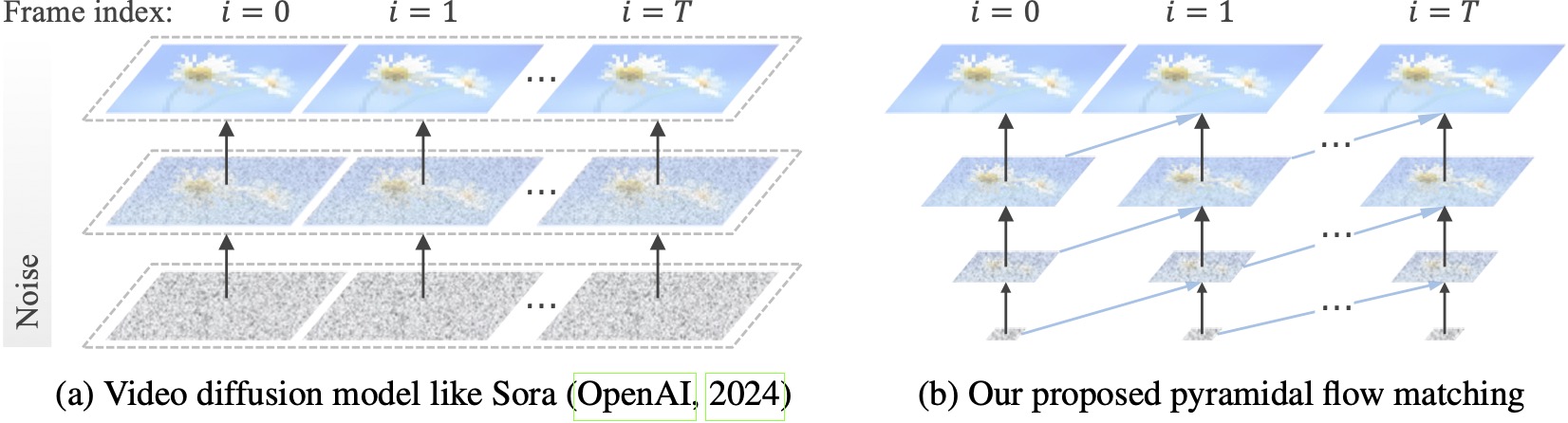
โมเดลการแพร่กระจายวิดีโอที่มีอยู่ทำงานที่ความละเอียดสูงสุด โดยต้องใช้การคำนวณจำนวนมากกับค่าแฝงที่มีเสียงดังมาก ในทางตรงกันข้าม วิธีการของเราควบคุมความยืดหยุ่นของการจับคู่โฟลว์ (Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023) เพื่อประมาณค่าระหว่างค่าแฝงของความละเอียดและระดับเสียงรบกวนที่แตกต่างกัน ช่วยให้สามารถสร้างและ การบีบอัดเนื้อหาภาพด้วยประสิทธิภาพการคำนวณที่ดีขึ้น เฟรมเวิร์กทั้งหมดได้รับการปรับให้เหมาะสมตั้งแต่ต้นจนจบด้วย DiT เดียว (Peebles & Xie, 2023) ซึ่งสร้างวิดีโอคุณภาพสูงความยาว 10 วินาทีที่ความละเอียด 768p และ 24 FPS ภายใน 20.7k ชั่วโมงการฝึกอบรม A100 GPU
เราขอแนะนำให้ตั้งค่าสภาพแวดล้อมด้วย conda ปัจจุบัน codebase ใช้ Python 3.8.10 และ PyTorch 2.1.2 (คำแนะนำ) และเรากำลังทำงานอย่างแข็งขันเพื่อรองรับเวอร์ชันต่างๆ ที่กว้างขึ้น
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtจากนั้นดาวน์โหลดโมเดลจาก Huggingface (มีสองรูปแบบ: miniFLUX หรือ SD3) รุ่น miniFLUX รองรับการสร้างวิดีโอ 1024p, 384p และ 768p และรุ่นที่ใช้ SD3 รองรับการสร้างวิดีโอ 768p และ 384p จุดตรวจสอบ 384p สร้างวิดีโอความยาว 5 วินาทีที่ 24FPS ในขณะที่จุดตรวจสอบ 768p สร้างวิดีโอความยาวสูงสุด 10 วินาทีที่ 24FPS
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )ในการเริ่มต้น ขั้นแรกให้ติดตั้ง Gradio ตั้งค่าพาธโมเดลของคุณที่ #L36 จากนั้นรันบนเครื่องของคุณ:
python app.pyการสาธิต Gradio จะเปิดขึ้นในเบราว์เซอร์ ขอบคุณ @ tpc2233 การคอมมิต ดู #48 เพื่อดูรายละเอียด
หรือลองใช้ Hugging Face Space ได้อย่างง่ายดาย สร้างโดย @multimodalart เนื่องจากข้อจำกัดของ GPU การสาธิตออนไลน์นี้จึงสามารถสร้างได้เพียง 25 เฟรมเท่านั้น (ส่งออกที่ 8FPS หรือ 24FPS) ทำซ้ำพื้นที่เพื่อสร้างวิดีโอที่ยาวขึ้น
หากต้องการลองใช้ Pyramid Flow บน Google Colab อย่างรวดเร็ว ให้เรียกใช้โค้ดด้านล่าง:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
หากต้องการใช้โมเดลของเรา โปรดปฏิบัติตามโค้ดการอนุมานใน video_generation_demo.ipynb ที่ลิงก์นี้ เราขอแนะนำให้คุณลองใช้พีระมิด-มินิฟลักซ์ที่เผยแพร่ล่าสุด ซึ่งแสดงให้เห็นถึงการปรับปรุงโครงสร้างของมนุษย์และความเสถียรของการเคลื่อนไหวอย่างมาก ตั้งค่าพารามิเตอร์ model_name เป็น pyramid_flux ที่จะใช้ เราทำให้มันง่ายขึ้นอีกเป็นขั้นตอนสองขั้นตอนต่อไปนี้ ขั้นแรก ให้โหลดโมเดลที่ดาวน์โหลดมา:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()จากนั้น คุณสามารถลองสร้างข้อความเป็นวิดีโอตามคำแนะนำของคุณเอง โปรดทราบว่าเวอร์ชัน 384p รองรับเฉพาะ 5s เท่านั้น (ตั้งค่าอุณหภูมิสูงสุด 16)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )ในฐานะที่เป็นโมเดลการถดถอยอัตโนมัติ โมเดลของเรายังรองรับ (มีเงื่อนไขข้อความ) การสร้างภาพเป็นวิดีโอ:
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )นอกจากนี้เรายังรองรับการถ่าย CPU สองประเภทเพื่อลดความต้องการหน่วยความจำ GPU โปรดทราบว่าพวกเขาอาจเสียสละประสิทธิภาพ
cpu_offloading=True ให้กับฟังก์ชันสร้างช่วยให้สามารถอนุมานได้ด้วยหน่วยความจำ GPU น้อยกว่า 12GB คุณลักษณะนี้สนับสนุนโดย @Ednaordinary ดู #23 สำหรับรายละเอียดmodel.enable_sequential_cpu_offload() ก่อนขั้นตอนข้างต้นจะทำให้สามารถอนุมานได้ด้วยหน่วยความจำ GPU น้อยกว่า 8GB คุณลักษณะนี้สนับสนุนโดย @rodjjo ดู #75 สำหรับรายละเอียด ขอบคุณ @niw ผู้ใช้ Apple Silicon (เช่น MacBook Pro ที่มี M2 24GB) ยังสามารถลองใช้โมเดลของเราโดยใช้แบ็กเอนด์ MPS ได้อีกด้วย โปรดดู #113 สำหรับรายละเอียด
สำหรับผู้ใช้ที่มี GPU หลายตัว เรามีสคริปต์การอนุมานที่ใช้การเรียงลำดับแบบขนานเพื่อประหยัดหน่วยความจำบน GPU แต่ละตัว นอกจากนี้ยังช่วยเร่งความเร็วครั้งใหญ่โดยใช้เวลาเพียง 2.5 นาทีในการสร้างวิดีโอ 5 วินาที, 768p, 24fps บน A100 GPU 4 ตัว (เทียบกับ 5.5 นาทีบน A100 GPU ตัวเดียว) รันบน 2 GPU ด้วยคำสั่งต่อไปนี้:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shขณะนี้รองรับ 2 หรือ 4 GPU (สำหรับเวอร์ชัน SD3) โดยมีการกำหนดค่าเพิ่มเติมในสคริปต์ต้นฉบับ คุณยังสามารถเปิดการสาธิต Gradio หลาย GPU ที่สร้างโดย @ tpc2233 ดูรายละเอียดใน #59
สปอยเลอร์: เราไม่ได้ใช้ลำดับความเท่าเทียมในการฝึกซ้อมด้วยซ้ำ ต้องขอบคุณการออกแบบการไหลของพีระมิดที่มีประสิทธิภาพของเรา
guidance_scale ควบคุมคุณภาพของภาพ เราขอแนะนำให้ใช้คำแนะนำภายใน [7, 9] สำหรับจุดตรวจสอบ 768p ในระหว่างการสร้างข้อความเป็นวิดีโอ และ 7 สำหรับจุดตรวจสอบ 384pvideo_guidance_scale ควบคุมการเคลื่อนไหว ค่าที่มากขึ้นจะเพิ่มระดับไดนามิกและลดความเสื่อมของการสร้างแบบถดถอยอัตโนมัติ ในขณะที่ค่าที่น้อยกว่าจะทำให้วิดีโอมีความเสถียรข้อกำหนดด้านฮาร์ดแวร์สำหรับการฝึกอบรม VAE คือ A100 GPU อย่างน้อย 8 ตัว โปรดดูเอกสารนี้ นี่คือ MAGVIT-v2 เช่นเดียวกับ 3D VAE ต่อเนื่อง ซึ่งน่าจะค่อนข้างยืดหยุ่น อย่าลังเลที่จะสร้างโมเดลการสร้างวิดีโอของคุณเองในส่วนนี้ของโค้ดการฝึกอบรม VAE
ข้อกำหนดด้านฮาร์ดแวร์สำหรับการปรับแต่ง DiT อย่างละเอียดคือ A100 GPU อย่างน้อย 8 ตัว โปรดดูเอกสารนี้ เราให้คำแนะนำสำหรับ Pyramid Flow ทั้งเวอร์ชัน autoregressive และ non-autoregressive แบบแรกเน้นการวิจัยมากกว่าและแบบหลังมีเสถียรภาพมากกว่า (แต่มีประสิทธิภาพน้อยกว่าหากไม่มีปิรามิดชั่วคราว)
ตัวอย่างวิดีโอต่อไปนี้สร้างขึ้นที่ 5 วินาที, 768p, 24fps หากต้องการผลลัพธ์เพิ่มเติม โปรดไปที่หน้าโครงการของเรา
โตเกียว.mp4 | ไอเฟล.mp4 |
คลื่น.mp4 | ราง.mp4 |
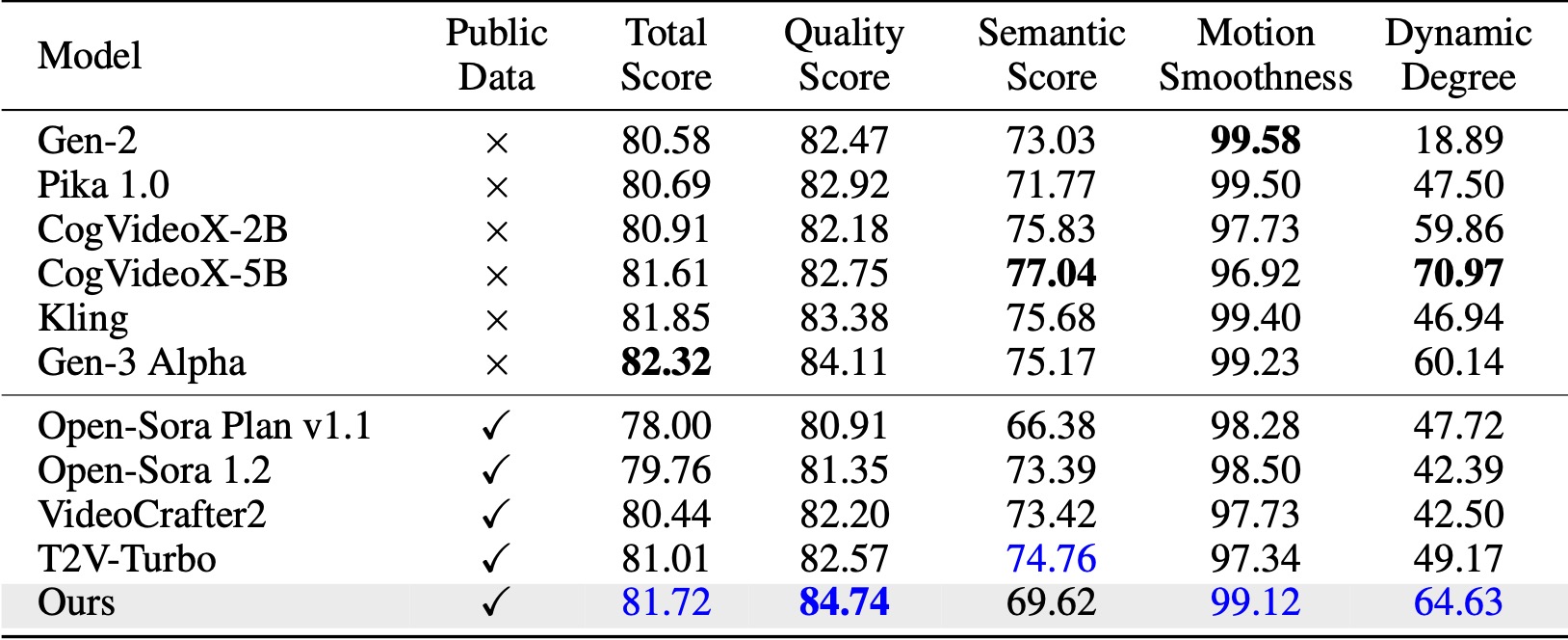
บน VBench (Huang et al., 2024) วิธีการของเราเหนือกว่าพื้นฐานโอเพ่นซอร์สที่เปรียบเทียบทั้งหมด แม้จะเป็นเพียงข้อมูลวิดีโอสาธารณะ แต่ก็ได้รับประสิทธิภาพที่เทียบเคียงได้กับโมเดลเชิงพาณิชย์อย่าง Kling (Kuaishou, 2024) และ Gen-3 Alpha (Runway, 2024) โดยเฉพาะในด้านคะแนนคุณภาพ (84.74 เทียบกับ 84.11 ของ Gen-3) และความนุ่มนวลของการเคลื่อนไหว .
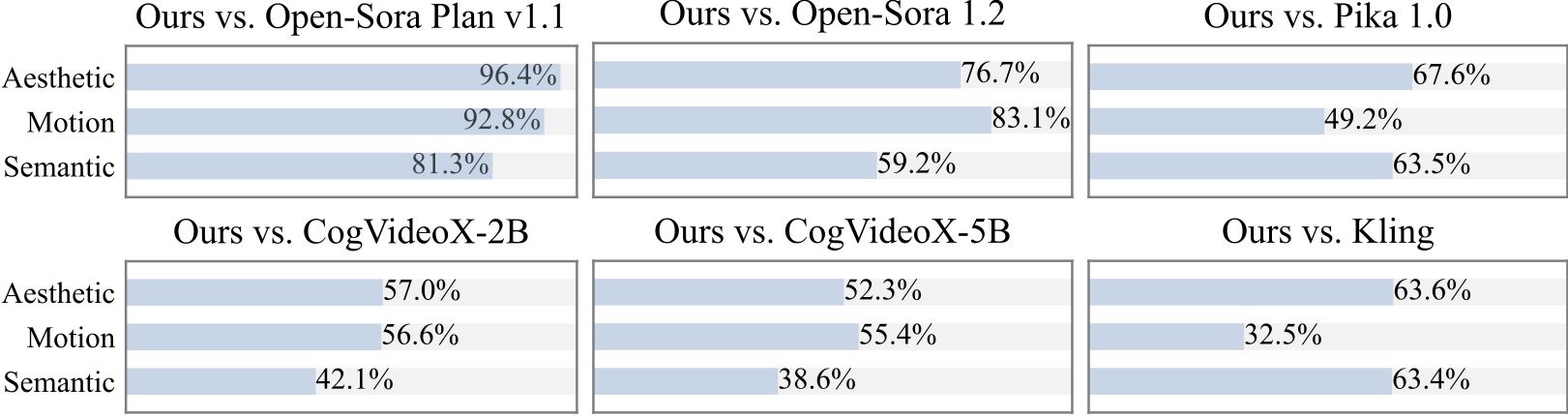
เราทำการศึกษาผู้ใช้เพิ่มเติมกับผู้เข้าร่วมมากกว่า 20 คน อย่างที่เห็น วิธีการของเราเป็นที่นิยมมากกว่าโมเดลโอเพ่นซอร์ส เช่น Open-Sora และ CogVideoX-2B โดยเฉพาะอย่างยิ่งในแง่ของความราบรื่นของการเคลื่อนไหว
เรารู้สึกขอบคุณสำหรับโครงการที่ยอดเยี่ยมต่อไปนี้เมื่อใช้ Pyramid Flow:
พิจารณาให้ดาวแก่พื้นที่เก็บข้อมูลนี้และอ้างอิง Pyramid Flow ในสิ่งพิมพ์ของคุณหากสามารถช่วยการวิจัยของคุณได้
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


