Facebook Messenger Bot
1.0.0
แชทบอท FB Messenger ที่ฉันฝึกให้พูดเหมือนฉัน โพสต์ในบล็อกที่เกี่ยวข้อง
สำหรับโปรเจ็กต์นี้ ฉันต้องการฝึกโมเดล Sequence To Sequence ในบันทึกการสนทนาที่ผ่านมาของฉันจากไซต์โซเชียลมีเดียต่างๆ คุณสามารถอ่านเพิ่มเติมเกี่ยวกับแรงจูงใจที่อยู่เบื้องหลังแนวทางนี้ รายละเอียดของโมเดล ML และวัตถุประสงค์ของสคริปต์ Python แต่ละตัวได้ในบล็อกโพสต์ แต่ฉันต้องการใช้ README นี้เพื่ออธิบายวิธีที่คุณสามารถฝึกแชทบอตของคุณเองให้พูดได้เหมือนคุณ .
ในการเรียกใช้สคริปต์เหล่านี้ คุณจะต้องมีไลบรารีต่อไปนี้
ดาวน์โหลดและแตกไฟล์ที่เก็บข้อมูลทั้งหมดนี้จาก GitHub ไม่ว่าจะโต้ตอบหรือโดยการป้อนข้อมูลต่อไปนี้ใน Terminal ของคุณ
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitนำทางไปยังไดเรกทอรีด้านบนของ repo บนเครื่องของคุณ
cd Facebook-Messenger-Botงานแรกของเราคือการดาวน์โหลดข้อมูลการสนทนาทั้งหมดของคุณจากเว็บไซต์โซเชียลมีเดียต่างๆ สำหรับฉัน ฉันใช้ Facebook, Google Hangouts และ LinkedIn หากคุณมีไซต์อื่นที่คุณได้รับข้อมูลก็ไม่เป็นไร คุณเพียงแค่จะต้องสร้างวิธีการใหม่ใน createDataset.py
ข้อมูล Facebook : ดาวน์โหลดข้อมูลของคุณจากที่นี่ เมื่อดาวน์โหลดแล้ว คุณควรมีไฟล์ขนาดใหญ่พอสมควรชื่อ Messages.htm มันจะเป็นไฟล์ที่ค่อนข้างใหญ่ (เกิน 190 MB สำหรับฉัน) เราจะต้องแยกวิเคราะห์ไฟล์ขนาดใหญ่นี้ และแยกการสนทนาทั้งหมด ในการดำเนินการนี้ เราจะใช้เครื่องมือนี้ที่ Dillon Dixon ได้กรุณาเปิดซอร์สไว้ คุณจะไปข้างหน้าและติดตั้งเครื่องมือนั้นโดยเรียกใช้
pip install fbchat-archive-parserแล้วทำงาน:
fbcap ./messages.htm > fbMessages.txtซึ่งจะทำให้บทสนทนาทั้งหมดบน Facebook ของคุณอยู่ในไฟล์ข้อความที่รวมเป็นหนึ่งเดียว ขอบคุณดิลลอน! ไปข้างหน้าแล้วเก็บไฟล์นั้นไว้ในโฟลเดอร์ Facebook-Messenger-Bot ของคุณ
ข้อมูล LinkedIn : ดาวน์โหลดข้อมูลของคุณจากที่นี่ เมื่อดาวน์โหลดแล้ว คุณจะเห็นไฟล์ inbox.csv เราไม่จำเป็นต้องดำเนินการใดๆ ที่นี่ เราเพียงต้องการคัดลอกไปยังโฟลเดอร์ของเรา
ข้อมูล Google Hangouts : ดาวน์โหลดแบบฟอร์มข้อมูลของคุณที่นี่ เมื่อดาวน์โหลดแล้ว คุณจะได้ไฟล์ JSON ที่เราจะต้องแยกวิเคราะห์ ในการดำเนินการนี้ เราจะใช้ parser นี้ที่พบในโพสต์บนบล็อกอันมหัศจรรย์นี้ เราต้องการบันทึกข้อมูลลงในไฟล์ข้อความ จากนั้นคัดลอกโฟลเดอร์ไปยังของเรา
ในตอนท้ายของทั้งหมดนี้ คุณควรมีโครงสร้างไดเร็กทอรีที่มีลักษณะดังนี้ ตรวจสอบให้แน่ใจว่าคุณเปลี่ยนชื่อโฟลเดอร์และชื่อไฟล์หากคุณแตกต่าง
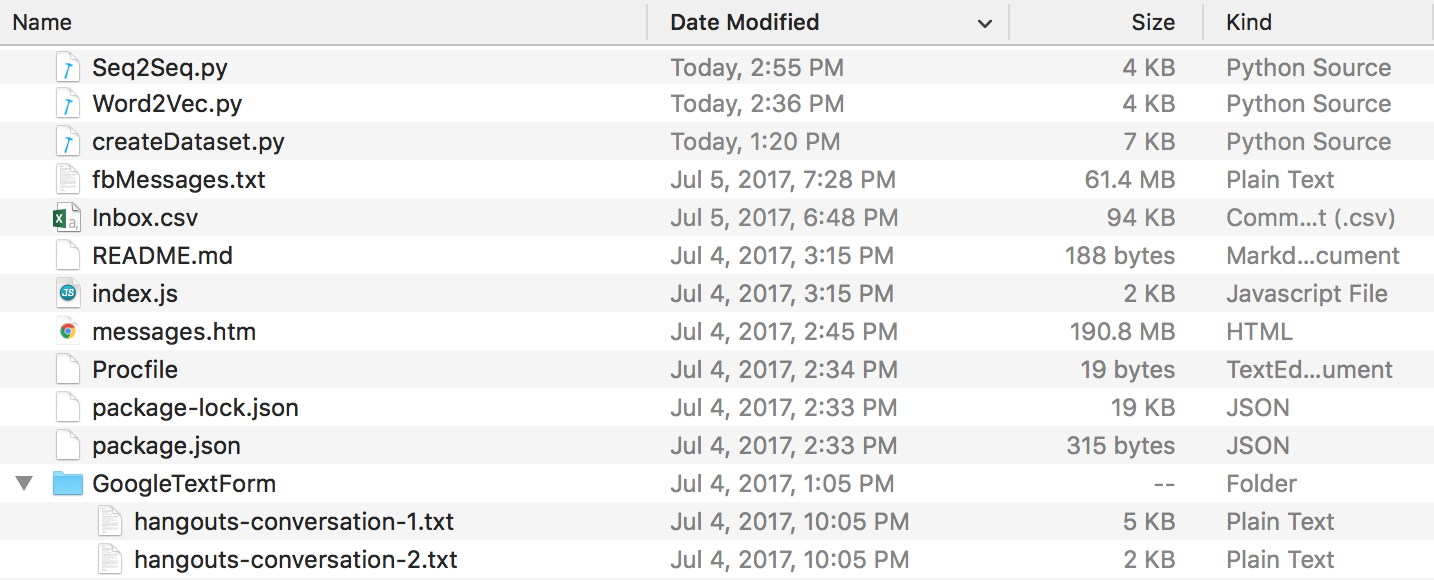
ข้อมูล Discord : คุณสามารถแยกบันทึกการสนทนาที่ไม่ลงรอยกันของคุณได้โดยใช้ DiscordChatExporter ที่ยอดเยี่ยมนี้ที่สร้างโดย Tyrrrz ปฏิบัติตามเอกสารประกอบเพื่อแยกบันทึกการแชทเอกพจน์ที่คุณต้องการในรูปแบบ .txt (นี่เป็นสิ่งสำคัญ) จากนั้นคุณสามารถใส่ทั้งหมดไว้ในโฟลเดอร์ชื่อ DiscordChatLogs ในไดเร็กทอรี repo
ข้อมูล WhatsApp : ตรวจสอบให้แน่ใจว่าคุณมีโทรศัพท์มือถือและใส่ไว้ในรูปแบบวันที่ของสหรัฐอเมริกา (หากยังไม่มี) (ซึ่งจะมีความสำคัญในภายหลังเมื่อคุณแยกวิเคราะห์ไฟล์บันทึกเป็น .csv) คุณไม่สามารถใช้เว็บ WhatsApp เพื่อจุดประสงค์นี้ได้ เปิดแชทที่คุณต้องการส่ง แตะปุ่มเมนู แตะเพิ่มเติม จากนั้นคลิก "อีเมลแชท" ส่งอีเมลถึงตัวคุณเองและดาวน์โหลดลงในคอมพิวเตอร์ของคุณ นี่จะให้ไฟล์ .txt แก่คุณ เพื่อแยกวิเคราะห์ เราจะแปลงเป็น .csv โดยไปที่ลิงก์นี้และป้อนข้อความทั้งหมดในไฟล์บันทึกของคุณ คลิกส่งออก ดาวน์โหลดไฟล์ csv และจัดเก็บไว้ในโฟลเดอร์ Facebook-Messenger-Bot ของคุณภายใต้ชื่อ "whatsapp_chats.csv"
หมายเหตุ : ดูเหมือนว่า parser ที่ให้ไว้ในลิงก์ด้านบนจะถูกลบออกไปแล้ว หากคุณยังคงมีไฟล์ .csv ในรูปแบบที่ถูกต้อง คุณยังสามารถใช้ไฟล์นั้นได้ หรือดาวน์โหลดบันทึกการแชท Whatsapp ของคุณเป็นไฟล์ .txt และใส่ทั้งหมดไว้ในโฟลเดอร์ชื่อ WhatsAppChatLogs ในไดเร็กทอรี repo createDataset.py จะทำงานกับไฟล์เหล่านี้แทนเฉพาะในกรณีที่ ไม่ พบไฟล์ .csv ชื่อ whatsapp_chats.csv
ในกรณีที่คุณใช้บันทึกการแชท .txt โปรดทราบว่ารูปแบบที่ต้องการคือ-
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(หรือ)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
ตอนนี้เรามีบันทึกการสนทนาทั้งหมดในรูปแบบที่สะอาดแล้ว เราก็สามารถสร้างชุดข้อมูลของเราได้เลย ในไดเร็กทอรีของเรา ให้รัน:
python createDataset.pyจากนั้นคุณจะได้รับแจ้งให้ป้อนชื่อของคุณ (เพื่อให้สคริปต์รู้ว่าต้องค้นหาใคร) และเว็บไซต์โซเชียลมีเดียใดที่คุณมีข้อมูล สคริปต์นี้จะสร้างไฟล์ชื่อ ConversationDictionary.npy ซึ่งเป็นวัตถุ Numpy ที่มีคู่อยู่ในรูปแบบของ (FRIENDS_MESSAGE, YOUR RESPONSE) ไฟล์ชื่อ ConversationData.txt จะถูกสร้างขึ้นเช่นกัน นี่เป็นเพียงไฟล์ข้อความขนาดใหญ่ที่ข้อมูลพจนานุกรมในรูปแบบรวม
ตอนนี้เรามี 2 ไฟล์นั้นแล้ว เราก็สามารถเริ่มสร้างเวกเตอร์คำของเราผ่านโมเดล Word2Vec ได้เลย ขั้นตอนนี้แตกต่างจากขั้นตอนอื่นเล็กน้อย ฟังก์ชัน Tensorflow ที่เราเห็นในภายหลัง (ใน seq2seq.py) จริงๆ แล้วยังจัดการส่วนที่ฝังอยู่ด้วย ดังนั้น คุณสามารถตัดสินใจที่จะฝึกเวกเตอร์ของคุณเอง หรือให้ฟังก์ชัน seq2seq ทำร่วมกัน ซึ่งเป็นสิ่งที่ฉันทำในที่สุด หากคุณต้องการสร้างเวกเตอร์คำของคุณเองผ่าน Word2Vec ให้พูด y ที่พรอมต์ (หลังจากรันคำสั่งต่อไปนี้) หากคุณไม่ทำเช่นนั้น ก็ไม่เป็นไร ตอบ n แล้วฟังก์ชันนี้จะสร้างเฉพาะ wordList.txt เท่านั้น
python Word2Vec.pyหากคุณเรียกใช้ word2vec.py ทั้งหมด สิ่งนี้จะสร้างไฟล์ที่แตกต่างกัน 4 ไฟล์ Word2VecXTrain.npy และ Word2VecYTrain.npy เป็นเมทริกซ์การฝึกอบรมที่ Word2Vec จะใช้ เราบันทึกสิ่งเหล่านี้ไว้ในโฟลเดอร์ของเรา ในกรณีที่เราจำเป็นต้องฝึกโมเดล Word2Vec ของเราอีกครั้งด้วยไฮเปอร์พารามิเตอร์ที่แตกต่างกัน นอกจากนี้เรายังบันทึก wordList.txt ซึ่งมีคำเฉพาะทั้งหมดในคลังข้อมูลของเรา ไฟล์สุดท้ายที่บันทึกคือ embeddingMatrix.npy ซึ่งเป็นเมทริกซ์ Numpy ที่มีเวกเตอร์คำที่สร้างขึ้นทั้งหมด
ตอนนี้เราสามารถใช้สร้างและฝึกโมเดล Seq2Seq ของเราได้
python Seq2Seq.pyสิ่งนี้จะสร้างไฟล์ที่แตกต่างกัน 3 ไฟล์ขึ้นไป Seq2SeqXTrain.npy และ Seq2SeqYTrain.npy เป็นเมทริกซ์การฝึกอบรมที่ Seq2Seq จะใช้ ขอย้ำอีกครั้งว่าเราจะบันทึกสิ่งเหล่านี้ไว้ในกรณีที่เราต้องการเปลี่ยนแปลงสถาปัตยกรรมโมเดลของเรา และเราไม่ต้องการคำนวณชุดการฝึกของเราใหม่ ไฟล์สุดท้ายจะเป็นไฟล์ .ckpt ซึ่งเก็บโมเดล Seq2Seq ที่บันทึกไว้ของเรา โมเดลจะถูกบันทึกในช่วงเวลาที่แตกต่างกันในลูปการฝึก สิ่งเหล่านี้จะถูกใช้และปรับใช้เมื่อเราสร้างแชทบอทของเราแล้ว
ตอนนี้เรามีโมเดลที่บันทึกไว้แล้ว เรามาสร้างแชทบอท Facebook ของเรากันดีกว่า เพื่อทำเช่นนั้น ฉันขอแนะนำให้ทำตามบทช่วยสอนนี้ คุณไม่จำเป็นต้องอ่านอะไรเลยในส่วน "ปรับแต่งสิ่งที่บอทพูด" โมเดล Seq2Seq ของเราจะจัดการส่วนนั้น สำคัญ - บทช่วยสอนจะบอกให้คุณสร้างโฟลเดอร์ใหม่ที่โปรเจ็กต์ Node จะอยู่ โปรดทราบว่าโฟลเดอร์นี้จะแตกต่างจากโฟลเดอร์ของเรา คุณสามารถนึกถึงโฟลเดอร์นี้ว่าเป็นที่ที่การประมวลผลข้อมูลล่วงหน้าและการฝึกโมเดลของเราตั้งอยู่ ในขณะที่อีกโฟลเดอร์หนึ่งสงวนไว้สำหรับแอป Express อย่างเคร่งครัด (แก้ไข: ฉันเชื่อว่าคุณสามารถทำตามขั้นตอนของบทช่วยสอนภายในโฟลเดอร์ของเราและเพียงแค่สร้างโปรเจ็กต์ Node Procfile และไฟล์ index.js ที่นี่ หากคุณต้องการ) บทช่วยสอนนั้นควรจะเพียงพอ แต่นี่คือบทสรุปของขั้นตอนต่างๆ
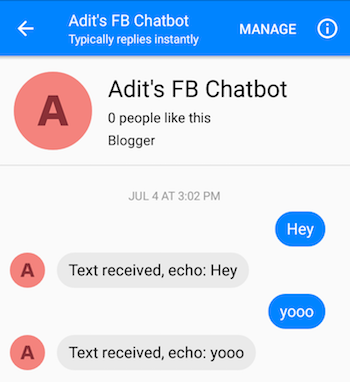
หลังจากทำตามขั้นตอนอย่างถูกต้องแล้ว คุณจะสามารถส่งข้อความถึงแชทบอทและรับการตอบกลับกลับมาได้
อ่า คุณเกือบจะเสร็จแล้ว! ตอนนี้ เราต้องสร้างเซิร์ฟเวอร์ Flask ซึ่งเราสามารถปรับใช้โมเดล Seq2Seq ที่บันทึกไว้ของเราได้ ฉันมีรหัสสำหรับเซิร์ฟเวอร์นั้นที่นี่ เรามาพูดถึงโครงสร้างทั่วไปกันดีกว่า โดยปกติเซิร์ฟเวอร์ Flask จะมีไฟล์ .py หลักหนึ่งไฟล์ที่คุณกำหนดจุดสิ้นสุดทั้งหมด นี่จะเป็น app.py ในกรณีของเรา นี่จะเป็นที่ที่เราโหลดในโมเดลของเรา คุณควรสร้างโฟลเดอร์ชื่อ 'models' และเติมด้วย 4 ไฟล์ (ไฟล์จุดตรวจสอบ ไฟล์ข้อมูล ไฟล์ดัชนี และไฟล์เมตา) ไฟล์เหล่านี้คือไฟล์ที่ถูกสร้างขึ้นเมื่อคุณบันทึกโมเดล Tensorflow

ในไฟล์ app.py นี้ เราต้องการสร้างเส้นทาง (/การคาดการณ์ในกรณีของฉัน) โดยที่อินพุตไปยังเส้นทางจะถูกป้อนเข้าสู่โมเดลที่บันทึกไว้ของเรา และเอาต์พุตตัวถอดรหัสคือสตริงที่ส่งคืน ลองดูที่ app.py ให้ละเอียดยิ่งขึ้นหากยังสับสนอยู่เล็กน้อย ตอนนี้คุณมี app.py และโมเดลของคุณแล้ว (และไฟล์ตัวช่วยอื่น ๆ หากคุณต้องการ) คุณสามารถปรับใช้เซิร์ฟเวอร์ของคุณได้ เราจะใช้ Heroku อีกครั้ง มีบทช่วยสอนที่แตกต่างกันมากมายเกี่ยวกับการปรับใช้เซิร์ฟเวอร์ Flask กับ Heroku แต่ฉันชอบบทช่วยสอนนี้เป็นพิเศษ (ไม่ต้องการส่วนโฟร์แมนและการบันทึก)
เอาล่ะ คุณควรจะสามารถส่งข้อความไปยังแชทบอตได้ และดูคำตอบที่น่าสนใจซึ่ง (หวังว่า) จะมีลักษณะคล้ายกับคุณในทางใดทางหนึ่ง
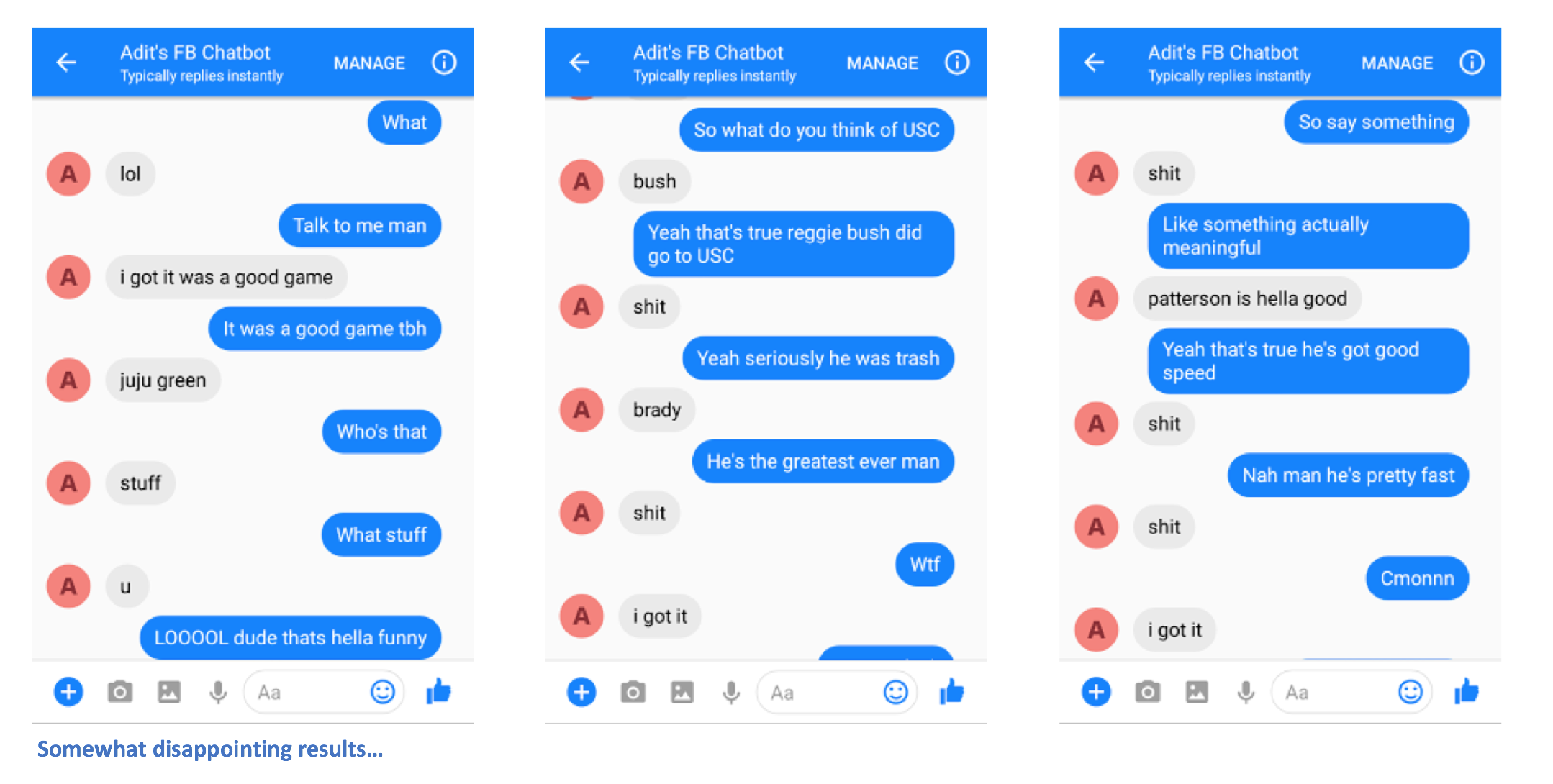
โปรดแจ้งให้เราทราบหากคุณมีปัญหาใด ๆ หรือมีข้อเสนอแนะใด ๆ เพื่อทำให้ README นี้ดีขึ้น หากคุณคิดว่าขั้นตอนใดขั้นตอนหนึ่งไม่ชัดเจน โปรดแจ้งให้เราทราบ เราจะพยายามอย่างเต็มที่เพื่อแก้ไข README และชี้แจงให้ชัดเจน


