snips nlu
0.20.2
Snips NLU (ความเข้าใจภาษาธรรมชาติ) เป็นไลบรารี Python ที่ช่วยให้ดึงข้อมูลที่มีโครงสร้างจากประโยคที่เขียนด้วยภาษาธรรมชาติ
เบื้องหลังแชทบอทและผู้ช่วยเสียงทุกตัวนั้นมีเทคโนโลยีทั่วไปอยู่ นั่นคือการทำความเข้าใจภาษาธรรมชาติ (NLU) เมื่อใดก็ตามที่ผู้ใช้โต้ตอบกับ AI โดยใช้ภาษาธรรมชาติ คำพูดของพวกเขาจะต้องแปลเป็นคำอธิบายที่เครื่องสามารถอ่านได้ว่าพวกเขาหมายถึงอะไร
กลไก NLU จะตรวจจับจุดประสงค์ของผู้ใช้ก่อน (หรือที่เรียกว่าเจตนา) จากนั้นจึงแยกพารามิเตอร์ (เรียกว่าช่อง) ของแบบสอบถาม นักพัฒนาซอฟต์แวร์สามารถใช้สิ่งนี้เพื่อกำหนดการดำเนินการหรือการตอบสนองที่เหมาะสม
ลองใช้ตัวอย่างเพื่ออธิบายสิ่งนี้ และพิจารณาประโยคต่อไปนี้:
"สภาพอากาศที่ปารีสตอน 21.00 น. จะเป็นอย่างไร"
เมื่อได้รับการฝึกอบรมอย่างเหมาะสม กลไก Snips NLU จะสามารถดึงข้อมูลที่มีโครงสร้าง เช่น:
{
"intent" : {
"intentName" : " searchWeatherForecast " ,
"probability" : 0.95
},
"slots" : [
{
"value" : " paris " ,
"entity" : " locality " ,
"slotName" : " forecast_locality "
},
{
"value" : {
"kind" : " InstantTime " ,
"value" : " 2018-02-08 20:00:00 +00:00 "
},
"entity" : " snips/datetime " ,
"slotName" : " forecast_start_datetime "
}
]
} ในกรณีนี้ จุดประสงค์ที่ระบุคือ searchWeatherForecast และแยกช่องสองช่อง ได้แก่ สถานที่และเวลา อย่างที่คุณเห็น Snips NLU ทำขั้นตอนเพิ่มเติมนอกเหนือจากการแยกเอนทิตี: โดยจะแก้ไขเอนทิตีเหล่านั้น ค่าวันที่และเวลาที่ถูกแยกออกมาได้ถูกแปลงเป็นรูปแบบ ISO ที่มีประโยชน์จริงๆ
ลองอ่านโพสต์บนบล็อกของเราเพื่อดูรายละเอียดเพิ่มเติมว่าทำไมเราถึงสร้าง Snips NLU และวิธีการทำงานภายใต้ประทุน นอกจากนี้เรายังตีพิมพ์บทความเกี่ยวกับ arxiv ซึ่งนำเสนอสถาปัตยกรรมการเรียนรู้ของเครื่องของ Snips Voice Platform
pip install snips - nlu ขณะนี้เรามีไบนารี (ล้อ) ที่สร้างไว้ล่วงหน้าสำหรับ snips-nlu และการพึ่งพาสำหรับ MacOS (10.11 ขึ้นไป), Linux x86_64 และ Windows
สำหรับสถาปัตยกรรม/ระบบปฏิบัติการอื่นๆ snips-nlu สามารถติดตั้งได้จากการกระจายแหล่งที่มา ในการทำเช่นนั้น จะต้องติดตั้ง Rust และ setuptools_rust ก่อนที่จะรันคำสั่ง pip install snips-nlu
Snips NLU อาศัยทรัพยากรภาษาภายนอกที่ต้องดาวน์โหลดก่อนจึงจะสามารถใช้ไลบรารีได้ คุณสามารถดึงข้อมูลทรัพยากรสำหรับภาษาใดภาษาหนึ่งได้โดยการรันคำสั่งต่อไปนี้:
python -m snips_nlu download enหรือเพียงแค่:
snips-nlu download enรายการภาษาที่รองรับมีอยู่ตามที่อยู่นี้
วิธีที่ง่ายที่สุดในการทดสอบความสามารถของไลบรารีนี้คือผ่านอินเทอร์เฟซบรรทัดคำสั่ง
ขั้นแรก ให้เริ่มต้นด้วยการฝึกอบรม NLU ด้วยชุดข้อมูลตัวอย่างชุดใดชุดหนึ่ง:
snips-nlu train path/to/dataset.json path/to/output_trained_engine โดยที่ path/to/dataset.json คือเส้นทางไปยังชุดข้อมูลที่จะใช้ระหว่างการฝึก และ path/to/output_trained_engine คือตำแหน่งที่เอ็นจิ้นที่ได้รับการฝึกควรคงอยู่เมื่อการฝึกเสร็จสิ้น
หลังจากนั้น คุณสามารถเริ่มแยกวิเคราะห์ประโยคแบบโต้ตอบได้โดยการเรียกใช้:
snips-nlu parse path/to/trained_engine โดยที่ path/to/trained_engine สอดคล้องกับตำแหน่งที่คุณจัดเก็บเครื่องยนต์ที่ผ่านการฝึกอบรมในระหว่างขั้นตอนก่อนหน้า
นี่คือโค้ดตัวอย่างที่คุณสามารถเรียกใช้บนเครื่องของคุณหลังจากติดตั้ง snips-nlu ดึงข้อมูลทรัพยากรภาษาอังกฤษ และดาวน์โหลดชุดข้อมูลตัวอย่างชุดใดชุดหนึ่ง:
>> > from __future__ import unicode_literals , print_function
>> > import io
>> > import json
>> > from snips_nlu import SnipsNLUEngine
>> > from snips_nlu . default_configs import CONFIG_EN
>> > with io . open ( "sample_datasets/lights_dataset.json" ) as f :
... sample_dataset = json . load ( f )
>> > nlu_engine = SnipsNLUEngine ( config = CONFIG_EN )
>> > nlu_engine = nlu_engine . fit ( sample_dataset )
>> > text = "Please turn the light on in the kitchen"
>> > parsing = nlu_engine . parse ( text )
>> > parsing [ "intent" ][ "intentName" ]
'turnLightOn'สิ่งที่ทำคือการฝึกกลไก NLU บนชุดข้อมูลสภาพอากาศตัวอย่างและแยกวิเคราะห์คำสืบค้นสภาพอากาศ
นี่คือรายการชุดข้อมูลบางส่วนที่สามารถใช้ในการฝึกกลไก Snips NLU:
ในเดือนมกราคม 2018 เราได้ทำซ้ำเกณฑ์มาตรฐานทางวิชาการซึ่งเผยแพร่ในช่วงฤดูร้อนปี 2017 ในบทความนี้ ผู้เขียนได้ประเมินประสิทธิภาพของ API.ai (ปัจจุบันคือ Dialogflow, Google), Luis.ai (Microsoft), IBM Watson และ Rasa NLU เพื่อความเป็นธรรม เราใช้ Rasa NLU เวอร์ชันอัปเดตและเปรียบเทียบกับ Snips NLU เวอร์ชันล่าสุด (สีน้ำเงินเข้มทั้งคู่)
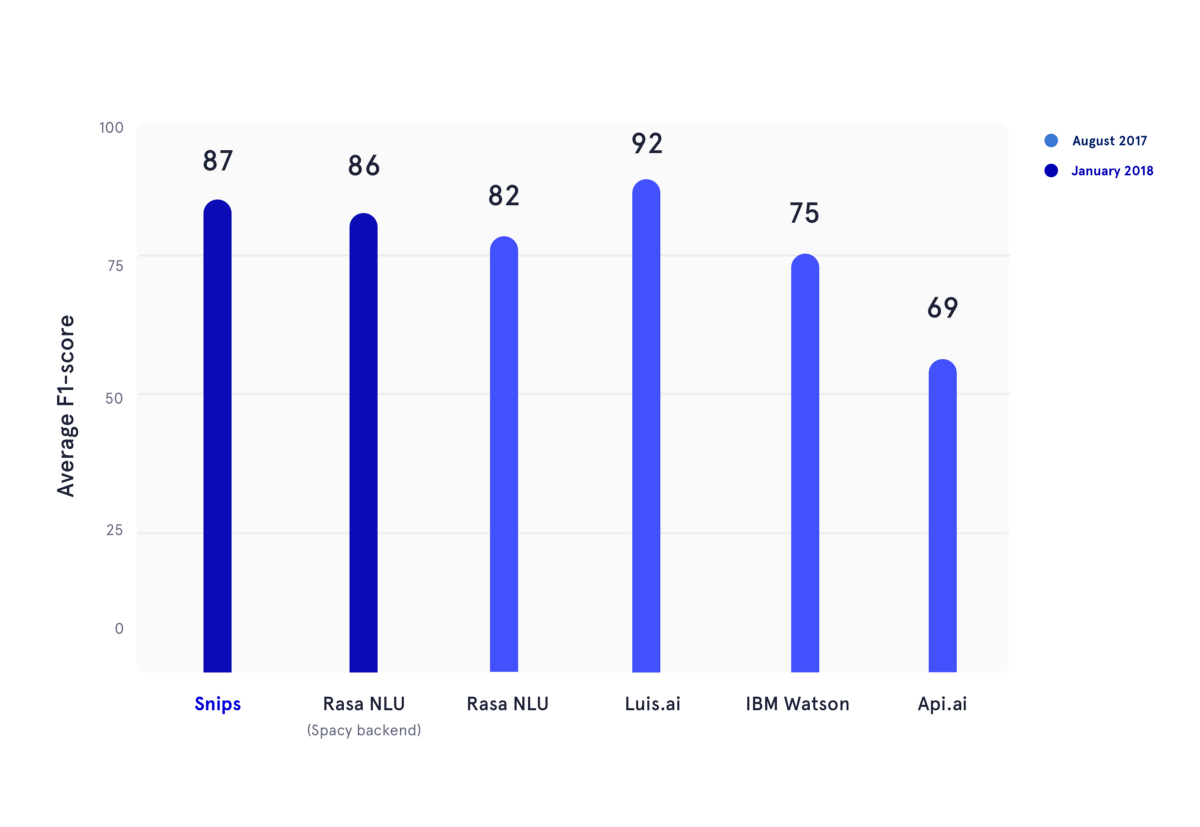
ในรูปด้านบน คะแนน F1 ของทั้งการจำแนกประเภทเจตนาและการเติมช่องได้รับการคำนวณสำหรับผู้ให้บริการ NLU หลายราย และเฉลี่ยจากชุดข้อมูลสามชุดที่ใช้ในเกณฑ์มาตรฐานทางวิชาการที่กล่าวถึงก่อนหน้านี้ ผลลัพธ์พื้นฐานทั้งหมดสามารถพบได้ที่นี่
หากต้องการทราบวิธีใช้ Snips NLU โปรดดูเอกสารประกอบของแพ็คเกจ ซึ่งจะให้คำแนะนำทีละขั้นตอนเกี่ยวกับวิธีการตั้งค่าและใช้งานไลบรารีนี้
โปรดอ้างอิงเอกสารต่อไปนี้เมื่อใช้ Snips NLU:
@article { coucke2018snips ,
title = { Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces } ,
author = { Coucke, Alice and Saade, Alaa and Ball, Adrien and Bluche, Th{'e}odore and Caulier, Alexandre and Leroy, David and Doumouro, Cl{'e}ment and Gisselbrecht, Thibault and Caltagirone, Francesco and Lavril, Thibaut and others } ,
journal = { arXiv preprint arXiv:1805.10190 } ,
pages = { 12--16 } ,
year = { 2018 }
}โปรดเข้าร่วมฟอรัมเพื่อถามคำถามและรับคำติชมจากชุมชน
โปรดดูแนวทางการบริจาค
ไลบรารีนี้จัดทำโดย Snips ในรูปแบบซอฟต์แวร์โอเพ่นซอร์ส ดูใบอนุญาตสำหรับข้อมูลเพิ่มเติม
สนิป/เมือง สนิป/ประเทศ และสนิป/ภูมิภาคในตัวเอนทิตีอาศัยซอฟต์แวร์จาก Geonames ซึ่งให้บริการภายใต้ใบอนุญาต Creative Commons Attribution 4.0 ระหว่างประเทศ สำหรับใบอนุญาตและการรับประกัน Geonames โปรดดูที่: https://creativecommons.org/licenses/by/4.0/legalcode


