ChatLM mini Chinese
1.0.0
จีน |. อังกฤษ
โมเดลภาษาขนาดใหญ่ในปัจจุบันมีแนวโน้มที่จะมีพารามิเตอร์ที่ใหญ่กว่า และคอมพิวเตอร์ระดับผู้บริโภคจะทำการอนุมานแบบง่ายๆ ได้ช้ากว่า ไม่ต้องพูดถึงการฝึกโมเดลตั้งแต่เริ่มต้น เป้าหมายของโปรเจ็กต์นี้คือการฝึกอบรมโมเดลภาษาเชิงสร้างสรรค์ตั้งแต่เริ่มต้น รวมถึงการล้างข้อมูล การฝึกอบรมโทเค็น การฝึกอบรมโมเดลล่วงหน้า การปรับแต่งคำสั่ง SFT อย่างละเอียด การเพิ่มประสิทธิภาพ RLHF ฯลฯ
ChatLM-mini- Chinese เป็นโมเดลบทสนทนาภาษาจีนขนาดเล็กที่มีพารามิเตอร์โมเดล 0.2B เท่านั้น (ประมาณ 210M รวมน้ำหนักที่ใช้ร่วมกัน) สามารถฝึกล่วงหน้าบนเครื่องที่มีหน่วยความจำวิดีโอขั้นต่ำ 4GB ( batch_size=1 , fp16 หรือ bf16 ) และการโหลดและการอนุมาน float16 ต้องใช้หน่วยความจำวิดีโออย่างน้อย 512MB
Huggingface NLP รวมถึง transformers , accelerate , trl , peft ฯลฯtrainer ที่ดำเนินการด้วยตนเองรองรับการปรับแต่งล่วงหน้าและการปรับแต่ง SFT บนเครื่องเดียวด้วยการ์ดใบเดียวหรือด้วยการ์ดหลายใบในเครื่องเดียว รองรับการหยุดที่ตำแหน่งใดก็ได้ระหว่างการฝึกและการฝึกต่อเนื่องในตำแหน่งใดก็ได้Text-to-Text และการทำนายล่วงหน้าแบบไม่ masksentencepiece และ huggingface tokenizersbatch_size=1, max_len=320 รองรับการฝึกอบรมล่วงหน้าบนเครื่องที่มีหน่วยความจำอย่างน้อย 16GB + หน่วยความจำวิดีโอ 4GBtrainer ที่ดำเนินการด้วยตนเองรองรับการปรับแต่งคำสั่งโดยละเอียดและรองรับเบรกพอยต์เพื่อฝึกต่อsequence to sequence ปรับแต่งอย่างละเอียดของ Huggingface trainer ;peft lora เพื่อเพิ่มประสิทธิภาพการตั้งค่าLora adapter สามารถรวมเข้ากับโมเดลดั้งเดิมได้หากคุณต้องการดึงข้อมูลรุ่นปรับปรุง (RAG) ตามโมเดลขนาดเล็ก คุณสามารถอ้างอิงถึงโปรเจ็กต์อื่น ๆ ของฉัน Phi2-mini-Chinese ได้ สำหรับโค้ด โปรดดูที่ rag_with_langchain.ipynb
? อัพเดทล่าสุด
ชุดข้อมูลทั้งหมดมาจากชุดข้อมูล การสนทนารอบเดียว ที่เผยแพร่บนอินเทอร์เน็ต หลังจากล้างข้อมูลและจัดรูปแบบแล้ว ชุดข้อมูลเหล่านั้นจะถูกบันทึกเป็นไฟล์ปาร์เก้ สำหรับกระบวนการประมวลผลข้อมูล โปรดดูที่ utils/raw_data_process.py ชุดข้อมูลหลักประกอบด้วย:
Belle_open_source_1M , train_2M_CN และ train_3.5M_CN ที่มีคำตอบสั้น ๆ ไม่มีโครงสร้างตารางที่ซับซ้อน และงานแปล (ไม่มีรายการคำศัพท์ภาษาอังกฤษ) รวม 3.7 ล้านแถว และเหลือ 3.38 ล้านแถวหลังจากทำความสะอาดN คำแรกของสารานุกรมเป็นคำตอบ และยังมีข้อความ 202309 และคำตอบในการป้อน 1.19 ล้านคำหลังจากทำความสะอาด ดาวน์โหลด Wiki: zhwiki แปลงไฟล์ bz2 ที่ดาวน์โหลดไปเป็นข้อมูลอ้างอิง wiki.txt: WikiExtractor จำนวนชุดข้อมูลทั้งหมด 10.23 ล้านชุด: ชุดการฝึกสอนการแปลงข้อความเป็นข้อความ: 9.3 ล้าน ชุดการประเมิน: 25,000 (เนื่องจากการถอดรหัสช้า ชุดการประเมินจึงไม่ได้ตั้งค่าใหญ่เกินไป) ชุดทดสอบ: 900,000. ชุดข้อมูลการปรับแต่ง SFT แบบละเอียดและการเพิ่มประสิทธิภาพ DPO แสดงไว้ด้านล่าง
สำหรับรายละเอียด โปรดดูโมเดล T5 (หม้อแปลงแปลงข้อความเป็นข้อความ) ในเอกสาร: การสำรวจขีดจำกัดของการเรียนรู้ด้วยตัวแปลงข้อความเป็นข้อความแบบรวม
ซอร์สโค้ดโมเดลมาจาก Huggingface ดู: T5ForConditionalGeneration
ดู model_config.json สำหรับการกำหนดค่าโมเดล T5-base : encoder layer และ decoder layer อย่างเป็นทางการมีทั้ง 12 เลเยอร์ ในโปรเจ็กต์นี้ พารามิเตอร์ทั้งสองนี้ได้รับการแก้ไขเป็น 10 เลเยอร์
พารามิเตอร์รุ่น: 0.2B. ขนาดรายการคำ: 29298 รวมเฉพาะภาษาจีนและภาษาอังกฤษจำนวนเล็กน้อย
ฮาร์ดแวร์:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 การฝึกอบรม Tokenizer : ไลบรารีการฝึกอบรม tokenizer ที่มีอยู่มีปัญหา OOM เมื่อพบกับคลังข้อมูลขนาดใหญ่ ดังนั้น คลังข้อมูลทั้งหมดจึงถูกผสานและสร้างตามความถี่ของคำตามวิธีที่คล้ายกับ BPE ซึ่งใช้เวลาครึ่งวันในการรัน
การฝึกอบรมล่วงหน้าจากข้อความเป็นข้อความ : อัตราการเรียนรู้แบบไดนามิก 1e-4 ถึง 5e-3 และเวลาก่อนการฝึกอบรม 8 วัน การสูญเสียการฝึก:
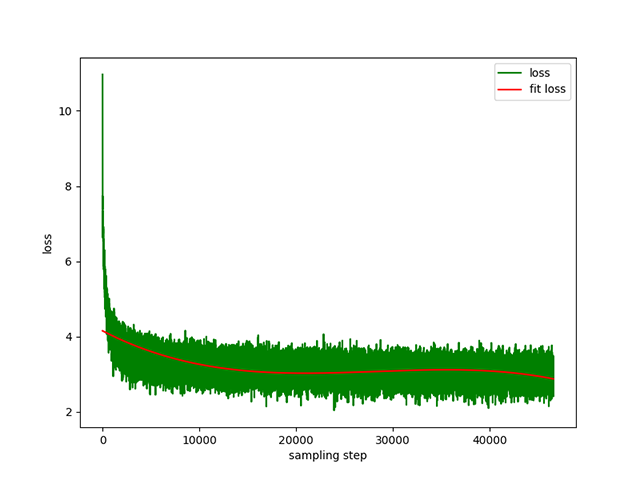
belle (ทั้งความยาวคำสั่งและคำตอบต่ำกว่า 512) อัตราการเรียนรู้คืออัตราการเรียนรู้แบบไดนามิกตั้งแต่ 1e-7 ถึง 5e-5 และเวลาการปรับแบบละเอียด คือ 2 วัน การสูญเสียการปรับแต่งแบบละเอียด: 
chosen ในขั้นตอนที่ 2 ชุดโมเดล SFT generate พร้อมท์ในชุดข้อมูลและรับข้อความ rejected โดยจะใช้เวลา 1 วัน เพื่อเพิ่มประสิทธิภาพการตั้งค่า dpo แบบเต็มและเรียนรู้ อัตราคือ le-5 , half-precision fp16 รวม 2 epoch และใช้เวลา 3 ชั่วโมง การสูญเสีย dpo: 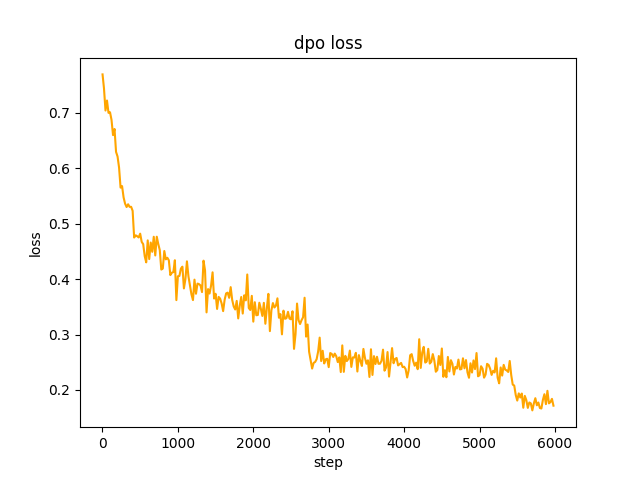
ตามค่าเริ่มต้น TextIteratorStreamer ของ huggingface transformers จะถูกใช้เพื่อสร้างกล่องโต้ตอบการสตรีม ซึ่งรองรับเฉพาะ greedy search เท่านั้น หากคุณต้องการวิธีการสร้างอื่น เช่น beam sample โปรดเปลี่ยนพารามิเตอร์ stream_chat ของ cli_demo.py เป็น False 

มีปัญหา: ชุดข้อมูลก่อนการฝึกอบรมมีเพียงมากกว่า 9 ล้าน และพารามิเตอร์โมเดลเพียง 0.2B ไม่สามารถครอบคลุมทุกด้าน และจะมีสถานการณ์ที่คำตอบผิดและเครื่องกำเนิดไร้สาระ
หากไม่สามารถเชื่อมต่อ Huggingface ได้ ให้ใช้ modelscope.snapshot_download เพื่อดาวน์โหลดไฟล์โมเดลจาก modelscope
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
คำเตือน
แบบจำลองของโปรเจ็กต์นี้คือโมเดล TextToText ใน prompt response และฟิลด์อื่นๆ ในระยะก่อนการฝึก SFT และ RLFH โปรดอย่าลืมเพิ่มเครื่องหมายสิ้นสุดลำดับ [EOS]
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese ขอแนะนำให้ใช้ python 3.10 สำหรับโปรเจ็กต์นี้ เวอร์ชัน python ที่เก่ากว่าอาจเข้ากันไม่ได้กับไลบรารีของบุคคลที่สามที่ขึ้นอยู่กับ
การติดตั้ง pip:
pip install -r ./requirements.txtหาก pip ติดตั้ง pytorch เวอร์ชัน CPU คุณสามารถติดตั้ง pytorch เวอร์ชัน CUDA ได้ด้วยคำสั่งต่อไปนี้:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118การติดตั้งคอนดา:
conda install --yes --file ./requirements.txt ใช้คำสั่ง git เพื่อดาวน์โหลดไฟล์น้ำหนักโมเดลและไฟล์การกำหนดค่าจาก Hugging Face Hub คุณต้องติดตั้ง Git LFS ก่อน จากนั้นจึงเรียกใช้:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save คุณยังสามารถดาวน์โหลดด้วยตนเองได้โดยตรงจากคลังสินค้า Hugging Face Hub ChatLM-Chinese-0.2B และย้ายไฟล์ที่ดาวน์โหลดไปยังไดเร็กทอรี model_save
ข้อกำหนดด้านคลังข้อมูลควรครบถ้วนมากที่สุด ขอแนะนำให้เพิ่มคลังข้อมูลหลายรายการ เช่น สารานุกรม รหัส เอกสาร บล็อก การสนทนา ฯลฯ
โครงการนี้อิงจากสารานุกรมวิกิภาษาจีนเป็นหลัก วิธีรับคลังข้อมูล wiki ภาษาจีน: ที่อยู่ดาวน์โหลด Wiki ของจีน: zhwiki, ดาวน์โหลด zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 ประมาณ 2.7GB, แปลงไฟล์ bz2 ที่ดาวน์โหลดมาเป็นข้อมูลอ้างอิง wiki.txt: WikiExtractor, จากนั้นใช้ไลบรารี OpenCC ของ python เพื่อแปลงเป็นภาษาจีนตัวย่อ และสุดท้ายก็ใส่ wiki.simple.txt ที่ได้รับลงในไดเร็กทอรี data ของไดเร็กทอรีรากของโปรเจ็กต์ โปรดรวมหลาย ๆ องค์กรเป็นไฟล์ txt เดียวด้วยตัวเอง
เนื่องจากโทเค็นการฝึกอบรมใช้หน่วยความจำจำนวนมาก หากคลังข้อมูลของคุณมีขนาดใหญ่มาก (ไฟล์ txt ที่รวมเกิน 2G) ขอแนะนำให้สุ่มตัวอย่างคลังข้อมูลตามหมวดหมู่และสัดส่วนเพื่อลดเวลาการฝึกอบรมและการใช้หน่วยความจำ การฝึกอบรมไฟล์ txt ขนาด 1.7GB ต้องใช้หน่วยความจำประมาณ 48GB (โดยประมาณ ฉันมีเพียง 32GB มีการสลับสับเปลี่ยนบ่อยครั้ง คอมพิวเตอร์ค้างเป็นเวลานาน T_T) และ CPU 13600k ใช้เวลาประมาณ 1 ชั่วโมง
ความแตกต่างระหว่าง char level และ byte level มีดังนี้ (โปรดค้นหาข้อมูลด้วยตัวคุณเองเพื่อดูความแตกต่างในการใช้งาน) โทเค็นไนเซอร์จะฝึก char level ตามค่าเริ่มต้น หากจำเป็นต้องมี byte level เพียงตั้งค่า token_type='byte' ใน train_tokenizer.py
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']เริ่มการฝึกอบรม:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab หรือสมุดบันทึก jupyter:
ดูไฟล์ train.ipynb ขอแนะนำให้ใช้ jupyter-lab เพื่อหลีกเลี่ยงการพิจารณาสถานการณ์ที่กระบวนการเทอร์มินัลถูกหยุดทำงานหลังจากตัดการเชื่อมต่อจากเซิร์ฟเวอร์
คอนโซล:
การฝึกอบรมคอนโซลจำเป็นต้องพิจารณาว่ากระบวนการจะถูกหยุดทำงานหลังจากการเชื่อมต่อถูกตัดการเชื่อมต่อ ขอแนะนำให้ใช้เครื่องมือ Supervisor กระบวนการหรือ screen เพื่อสร้างเซสชันการเชื่อมต่อ
ขั้นแรก คุณต้องกำหนดค่า accelerate ดำเนินการคำสั่งต่อไปนี้ และเลือกตามคำแนะนำ โปรดดูที่ accelerate.yaml หมายเหตุ: DeepSpeed จะยุ่งยากกว่าในการติดตั้งบน Windows
accelerate config เริ่มการฝึก หากคุณต้องการใช้การกำหนดค่าที่โปรเจ็กต์มอบให้ โปรดเพิ่มพารามิเตอร์ --config_file ./accelerate.yaml หลังจากคำสั่ง accelerate launch ต่อไปนี้ การกำหนดค่านี้อิงตามการกำหนดค่า 2xGPU ในเครื่องเดียว
มีสองสคริปต์สำหรับการฝึกล่วงหน้า เทรนเนอร์ที่นำไปใช้ในโปรเจ็กต์นี้สอดคล้องกับ train.py และผู้ฝึกสอนที่ดำเนินการโดย Huggingface สอดคล้องกับ pre_train.py คุณสามารถใช้อันใดอันหนึ่งได้และเอฟเฟกต์จะเหมือนกัน ผู้ฝึกสอนที่นำมาใช้ในโปรเจ็กต์นี้จะแสดงข้อมูลการฝึกอบรมที่สวยงามยิ่งขึ้น และทำให้ง่ายต่อการแก้ไขรายละเอียดการฝึก (เช่น ฟังก์ชันที่สูญเสีย บันทึกบันทึก ฯลฯ) รองรับเบรกพอยต์ทั้งหมดเพื่อดำเนินการฝึกอบรมต่อ เบรกพอยต์ที่ตำแหน่งใดก็ได้ กด ctrl+c จะบันทึกข้อมูลเบรกพอยต์เมื่อออกจากสคริปต์
เครื่องเดียวและการ์ดเดียว:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py เครื่องเดียวที่มีการ์ดหลายใบ: 2 คือจำนวนการ์ดกราฟิก โปรดแก้ไขตามสถานการณ์จริงของคุณ
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyฝึกต่อจากจุดพัก:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyชุดข้อมูล SFT ทั้งหมดมาจากการมีส่วนร่วมของหัวหน้า BELLE ขอบคุณครับ ชุดข้อมูล SFT คือ Generic_chat_0.4M, train_0.5M_CN และ train_2M_CN โดยเหลือประมาณ 1.37 ล้านแถวหลังการทำความสะอาด ตัวอย่างการปรับแต่งชุดข้อมูลอย่างละเอียดด้วยคำสั่ง sft:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} สร้างชุดข้อมูลของคุณเองโดยอ้างอิงถึงไฟล์ parquet ตัวอย่างในไดเร็กทอรี data รูปแบบชุดข้อมูลคือ: ไฟล์ parquet แบ่งออกเป็นสองคอลัมน์ หนึ่งคอลัมน์เป็นข้อความ prompt ซึ่งแสดงถึงพร้อมท์ และอีกหนึ่งคอลัมน์เป็นข้อความ response ซึ่งแสดงถึงเอาท์พุตของโมเดลที่คาดหวัง สำหรับรายละเอียดการปรับแต่ง โปรดดูวิธี train ภายใต้ model/trainer.py เมื่อตั้งค่า is_finetune เป็น True การปรับแต่งแบบละเอียดจะดำเนินการหยุดการทำงานของเลเยอร์การฝังและเลเยอร์ตัวเข้ารหัสตามค่าเริ่มต้น และฝึกเฉพาะตัวถอดรหัสเท่านั้น ชั้น. หากคุณต้องการหยุดพารามิเตอร์อื่นๆ โปรดปรับโค้ดด้วยตนเอง
เรียกใช้การปรับแต่ง SFT แบบละเอียด:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyต่อไปนี้เป็นวิธีการทั่วไปสองวิธี: PPO และ DPO โปรดค้นหาเอกสารและบล็อกสำหรับการใช้งานเฉพาะ
วิธี PPO (การเพิ่มประสิทธิภาพการตั้งค่าโดยประมาณ, การเพิ่มประสิทธิภาพนโยบายใกล้เคียง)
ขั้นตอนที่ 1: ใช้ชุดข้อมูลการปรับแต่งแบบละเอียดเพื่อทำการปรับแต่งแบบละเอียดภายใต้การดูแล (SFT, Supervised Finetuning)
ขั้นตอนที่ 2: ใช้ชุดข้อมูลการกำหนดลักษณะ (พรอมต์ประกอบด้วยคำตอบอย่างน้อย 2 รายการ คำตอบที่ต้องการหนึ่งรายการ และคำตอบที่ไม่ต้องการหนึ่งรายการ คำตอบหลายรายการสามารถจัดเรียงตามคะแนน และคำตอบที่ต้องการมากที่สุดจะมีคะแนนสูงสุด) เพื่อฝึกโมเดลรางวัล (RM , โมเดลรางวัล) คุณสามารถใช้ไลบรารี peft เพื่อสร้างโมเดลรางวัล Lora ได้อย่างรวดเร็ว
ขั้นตอนที่ 3: ใช้ RM เพื่อทำการฝึกอบรม PPO ที่มีการดูแลในโมเดล SFT เพื่อให้โมเดลตรงตามความต้องการ
ใช้การปรับแต่งแบบละเอียด DPO (Direct Preference Optimization) ( โปรเจ็กต์นี้ใช้วิธีการปรับแต่งแบบละเอียด DPO ซึ่งบันทึกหน่วยความจำวิดีโอ ) บนพื้นฐานของการได้รับโมเดล SFT ไม่จำเป็นต้องฝึกโมเดลรางวัลเพื่อให้ได้คำตอบเชิงบวก ( เลือก) และคำตอบเชิงลบ (ถูกปฏิเสธ) เพื่อเริ่มการปรับแต่ง ข้อความ chosen ที่ได้รับการปรับแต่งอย่างละเอียดมาจากชุดข้อมูลต้นฉบับ alpaca-gpt4-data-zh และข้อความ rejected มาจากเอาต์พุตของโมเดลหลังจากการปรับแต่ง SFT อย่างละเอียดเป็นเวลา 1 epoch single-round-trans_chinese หลังจากรวมข้อมูลทั้งหมด 80,000 dpo
สำหรับกระบวนการประมวลผลชุดข้อมูล dpo โปรดดู utils/dpo_data_process.py
ตัวอย่างชุดข้อมูลการปรับให้เหมาะสมตามความชอบ DPO:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}เรียกใช้การเพิ่มประสิทธิภาพการตั้งค่า:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py ตรวจสอบให้แน่ใจว่ามีไฟล์ต่อไปนี้ในไดเร็กทอรี model_save ไฟล์เหล่านี้สามารถพบได้ในคลังสินค้า Hugging Face Hub ChatLM-Thai-0.2B:
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
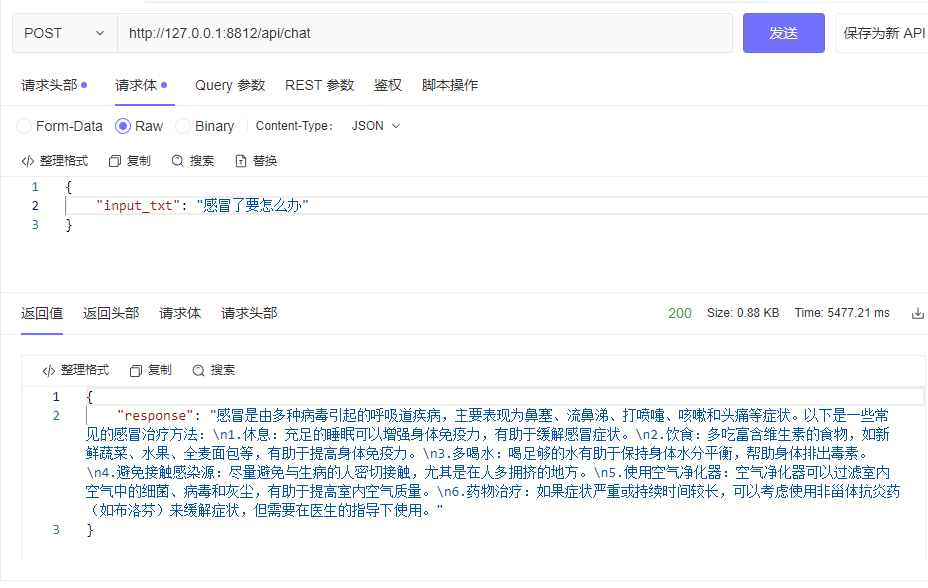
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyตัวอย่างการเรียก API:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
ที่นี่เราใช้ข้อมูลแฝดในข้อความเป็นตัวอย่างในการปรับแต่งดาวน์สตรีมแบบละเอียด สำหรับวิธีการแยกการเรียนรู้เชิงลึกแบบดั้งเดิมสำหรับงานนี้ โปรดดูที่คลังสินค้า pytorch_IE_model แยก Triples ทั้งหมดออกมาเป็นข้อความ เช่น ประโยค 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, แยก Triples (写生随笔,作者,张来亮) และ (写生随笔,出版社,冶金工业)
ชุดข้อมูลดั้งเดิมคือ: ชุดข้อมูลการสกัดสามชั้นของ Baidu ตัวอย่างรูปแบบชุดข้อมูลที่ปรับแต่งอย่างละเอียดที่ประมวลผลแล้ว:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} คุณสามารถใช้สคริปต์ sft_train.py ได้โดยตรงเพื่อการปรับแต่งอย่างละเอียด สคริปต์ finetune_IE_task.ipynb มีกระบวนการถอดรหัสโดยละเอียด ชุดข้อมูลการฝึกอบรมมีประมาณ 17000 รายการ อัตราการเรียนรู้ 5e-5 และยุคการฝึกอบรม 5 ความสามารถในการสนทนาของงานอื่นๆ ไม่ได้หายไปหลังจากการปรับแต่งอย่างละเอียด

เอฟเฟกต์การปรับแต่งอย่างละเอียด: ใช้ชุดข้อมูล dev ที่เผยแพร่百度三元组抽取数据集เป็นชุดทดสอบเพื่อเปรียบเทียบกับวิธีดั้งเดิม pytorch_IE_model
| แบบอย่าง | คะแนน F1 | พรีซิชั่น พี | จำอาร์ |
|---|---|---|---|
| ChatLM-จีน-0.2B การปรับแต่งแบบละเอียด | 0.74 | 0.75 | 0.73 |
| ChatLM-Thai-0.2B โดยไม่ต้องมีการฝึกอบรมล่วงหน้า | 0.51 | 0.53 | 0.49 |
| วิธีการเรียนรู้เชิงลึกแบบดั้งเดิม | 0.80 | 0.79 | 80.1 |
หมายเหตุ: ChatLM-Chinese-0.2B无预训练หมายถึงการเริ่มต้นพารามิเตอร์แบบสุ่มโดยตรง และเริ่มการฝึกอบรมด้วยอัตราการเรียนรู้ 1e-4 พารามิเตอร์อื่นๆ สอดคล้องกับการปรับแต่งอย่างละเอียด
ตัวแบบไม่ได้รับการฝึกฝนโดยใช้ชุดข้อมูลขนาดใหญ่ และไม่ได้รับการปรับแต่งอย่างละเอียดสำหรับคำแนะนำในการตอบคำถามแบบปรนัย คะแนน C-Eval นั้นเป็นระดับพื้นฐานและสามารถใช้เป็นข้อมูลอ้างอิงได้หากจำเป็น รหัสการประเมิน C-Eval ดู: eval/c_eavl.ipynb
| หมวดหมู่ | ถูกต้อง | คำถาม_นับ | ความแม่นยำ |
|---|---|---|---|
| มนุษยศาสตร์ | 63 | 257 | 24.51% |
| อื่น | 89 | 384 | 23.18% |
| ต้นกำเนิด | 89 | 430 | 20.70% |
| สังคมศาสตร์ | 72 | 275 | 26.18% |
หากคุณคิดว่าโครงการนี้เป็นประโยชน์กับคุณ กรุณาอ้างอิง
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
โครงการนี้ไม่รับความเสี่ยงและความรับผิดชอบด้านความปลอดภัยของข้อมูลและความเสี่ยงต่อความคิดเห็นสาธารณะที่เกิดจากโมเดลและโค้ดโอเพ่นซอร์ส หรือความเสี่ยงและความรับผิดชอบที่เกิดจากโมเดลใดๆ ที่ถูกทำให้เข้าใจผิด ถูกนำไปใช้ในทางที่ผิด เผยแพร่ หรือใช้ประโยชน์อย่างไม่เหมาะสม


