Transformer in generating dialogue
1.0.0
รหัสคือการใช้งาน Paper Attention เป็นสิ่งที่คุณต้องการสำหรับงานสร้างบทสนทนา เช่น Chatbot 、 การสร้างข้อความ และอื่นๆ
ขอขอบคุณเพื่อนๆ ทุกคนที่แจ้งปัญหาและช่วยแก้ไข การมีส่วนร่วมของคุณมีความสำคัญมากสำหรับการปรับปรุงโครงการนี้ เนื่องจากการสนับสนุนที่จำกัดของ 'โหมดกราฟคงที่' ในการเขียนโค้ด เราจึงตัดสินใจย้ายคุณสมบัติดังกล่าวไปเป็นเวอร์ชัน 2.0.0-beta1 อย่างไรก็ตาม หากคุณกังวลเกี่ยวกับปัญหาจากการสร้างนักเทียบท่าและการสร้างบริการที่มีปัญหาเกี่ยวกับเวอร์ชัน เรายังคงเก็บโค้ดเวอร์ชันเก่าที่เขียนโดยโหมดกระตือรือร้นโดยใช้เวอร์ชัน tensorflow 1.12.x ไว้อ้างอิง
|-- root/
|-- data/
|-- src-train.csv
|-- src-val.csv
|-- tgt-train.csv
`-- tgt-val.csv
|-- old_version/
|-- data_loader.py
|-- eval.py
|-- make_dic.py
|-- modules.py
|-- params.py
|-- requirements.txt
`-- train.py
|-- tf1.12.0-eager/
|-- bleu.py
|-- main.ipynb
|-- modules.py
|-- params.py
|-- requirements.txt
`-- utils.py
|-- images/
|-- bleu.py
|-- main-v2.ipynb
|-- modules-v2.py
|-- params.py
|-- requirements.txt
`-- utils-v2.py
ดังที่เราทุกคนทราบดีว่าระบบการแปลสามารถนำมาใช้ในการดำเนินการรูปแบบการสนทนาได้ เพียงแค่แทนที่ปารีสของประโยคสองประโยคที่แตกต่างกันเป็นคำถามและคำตอบ ท้ายที่สุดแล้ว รูปแบบการสนทนาพื้นฐานที่ชื่อว่า "Sequence-to-Sequence" ได้รับการพัฒนามาจากระบบการแปล ดังนั้น ทำไมเราไม่ปรับปรุงประสิทธิภาพของรูปแบบการสนทนาในการสร้างบทสนทนา?
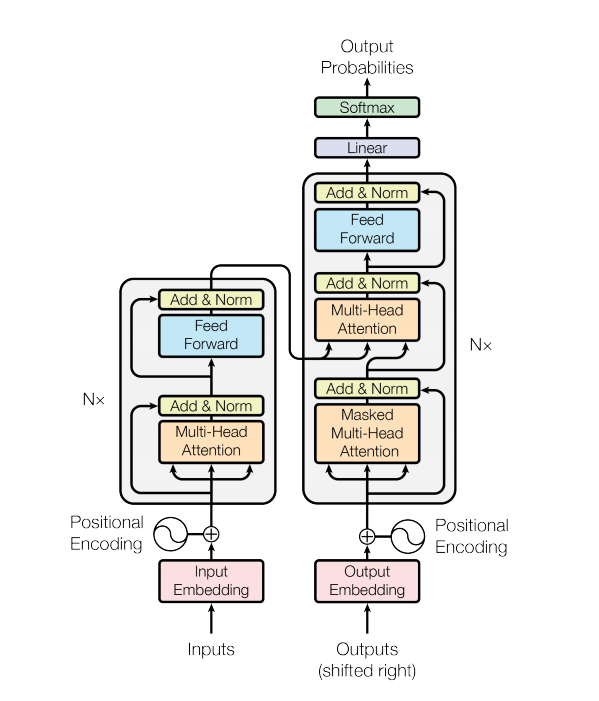
ด้วยการพัฒนาโมเดลที่ใช้ BERT งาน nlp จะถูกรีเฟรชอย่างต่อเนื่องมากขึ้นเรื่อยๆ อย่างไรก็ตาม โมเดลภาษาไม่มีอยู่ในงานโอเพ่นซอร์สของ BERT ไม่ต้องสงสัยเลยว่าเส้นทางนี้เรายังอีกยาวไกล
โมเดลหม้อแปลงจะจัดการอินพุตขนาดแปรผันโดยใช้สแต็กของชั้นการเอาใจใส่ตัวเองแทน RNN หรือ CNN สถาปัตยกรรมทั่วไปนี้มีข้อดีและเครื่องหมายพิเศษหลายประการ ตอนนี้เรามาพาพวกเขาออกไป:
ในโค้ดเวอร์ชันใหม่ล่าสุด เราได้กรอกรายละเอียดที่อธิบายไว้ในเอกสารแล้ว
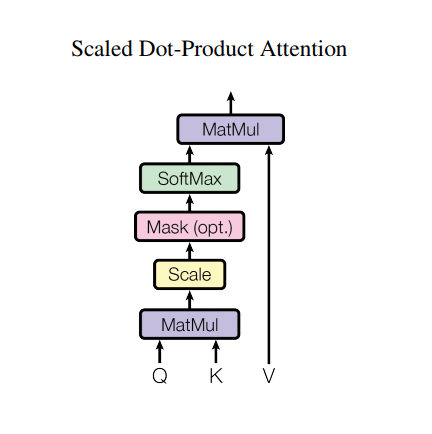
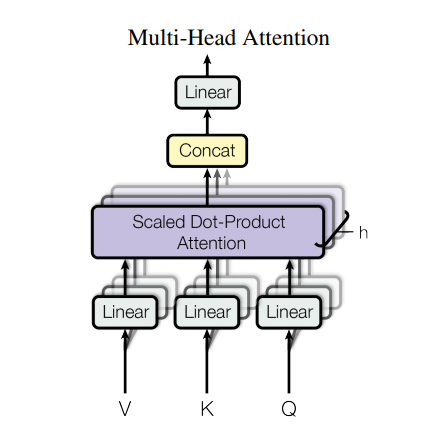
อย่างไรก็ตาม สถาปัตยกรรมที่แข็งแกร่งดังกล่าวยังคงมีข้อเสียบางประการ:
data/ โฟลเดอร์params.py หากคุณต้องการmake_dic.py เพื่อสร้างไฟล์คำศัพท์ไปยังโฟลเดอร์ใหม่ชื่อ dictionarytrain.py เพื่อสร้างโมเดล จุดตรวจสอบจะถูกเก็บไว้ในโฟลเดอร์ checkpoint ในขณะที่ไฟล์เหตุการณ์เทนเซอร์โฟลว์สามารถพบได้ใน logdireval.py เพื่อประเมินผลลัพธ์ด้วยข้อมูลการทดสอบ ผลลัพธ์จะถูกเก็บไว้ในโฟลเดอร์ ResultsGPU เพื่อเร่งการประมวลผลการฝึกอบรม โปรดตั้งค่าอุปกรณ์ของคุณในโค้ด (รองรับการฝึกอบรมแบบหลายคน) - Source: 肥 宅 初 夜 可 以 賣 多 少 `
- Ground Truth: 肥 宅 還 是 去 打 手 槍 吧
- Predict: 肥 宅 還 是 去 打 手 槍 吧
- Source: 兇 的 女 生 484 都 很 胸
- Ground Truth: 我 看 都 是 醜 的 比 較 凶
- Predict: 我 看 都 是 醜 的 比 較 <UNK>
- Source: 留 髮 不 留 頭
- Ground Truth: 還 好 我 早 就 禿 頭 了
- Predict: 還 好 我 早 就 禿 頭 了
- Source: 當 人 好 痛 苦 R 的 八 卦
- Ground Truth: 去 中 國 就 不 用 當 人 了
- Predict: 去 中 國 就 不 會 有 了 -
- Source: 有 沒 有 今 天 捷 運 的 八 卦
- Ground Truth: 有 - 真 的 有 多
- Predict: 有 - 真 的 有 多
- Source: 2016 帶 走 了 什 麼 `
- Ground Truth: HellKitty 麥 當 勞 歡 樂 送 開 門 -
- Predict: <UNK> 麥 當 勞 歡 樂 送 開 門 -
- Source: 有 沒 有 多 益 很 賺 的 八 卦
- Ground Truth: 比 大 型 包 裹 貴
- Predict: 比 大 型 包 <UNK> 貴
- Source: 邊 緣 人 收 到 地 震 警 報 了
- Ground Truth: 都 跑 到 窗 邊 了 才 來
- Predict: 都 跑 到 <UNK> 邊 了 才 來
- Source: 車 震
- Ground Truth: 沒 被 刪 版 主 是 有 眼 睛 der
- Predict: 沒 被 刪 版 主 是 有 眼 睛 der
- Source: 在 家 跌 倒 的 八 卦 `
- Ground Truth: 傷 到 腦 袋 - 可 憐
- Predict: 傷 到 腦 袋 - 可 憐
- Source: 大 家 很 討 厭 核 核 嗎 `
- Ground Truth: 核 核 欠 幹 阿
- Predict: 核 核 欠 幹 阿
- Source: 館 長 跟 黎 明 打 誰 贏 -
- Ground Truth: 我 愛 黎 明 - 我 愛 黎 明 -
- Predict: 我 愛 <UNK> 明 - 我 愛 <UNK> 明 -
- Source: 嘻 嘻 打 打
- Ground Truth: 媽 的 智 障 姆 咪 滾 喇 幹
- Predict: 媽 的 智 障 姆 咪 滾 喇 幹
- Source: 經 典 電 影 台 詞
- Ground Truth: 超 時 空 要 愛 裡 滿 滿 的 梗
- Predict: 超 時 空 要 愛 裡 滿 滿 滿 的
- Source: 2B 守 得 住 街 亭 嗎 `
- Ground Truth: 被 病 毒 滅 亡 真 的 會 -
- Predict: <UNK> 守 得 住
หากคุณพยายามใช้ AutoGraph เพื่อเร่งกระบวนการฝึกอบรมของคุณ โปรดตรวจสอบให้แน่ใจว่าชุดข้อมูลนั้นมีความยาวคงที่ เนื่องจากการดำเนินการสร้างกราฟใหม่จะถูกเปิดใช้งานระหว่างการฝึกซึ่งอาจส่งผลต่อประสิทธิภาพการทำงาน โค้ดของเรารับประกันประสิทธิภาพของเวอร์ชัน 2.0 เท่านั้น และโค้ดที่ต่ำกว่าสามารถลองอ้างอิงได้
ขอบคุณสำหรับ Transformer และ Tensorflow


