Seq2seq Chatbot for Keras
1.0.0
พื้นที่เก็บข้อมูลนี้มี Chatbot โมเดลเจนเนอเรชั่นใหม่ซึ่งอิงตามการสร้างแบบจำลอง seq2seq รายละเอียดเพิ่มเติมเกี่ยวกับแบบจำลองนี้สามารถพบได้ในส่วนที่ 3 ของรายงานการเรียนรู้ฝ่ายตรงข้ามแบบ end-to-end สำหรับตัวแทนการสนทนาแบบ Generative ในกรณีที่ตีพิมพ์โดยใช้แนวคิดหรือโค้ดจากแหล่งเก็บข้อมูลนี้ โปรดอ้างอิงบทความนี้
โมเดลที่ได้รับการฝึกอบรมที่นี่ใช้ชุดข้อมูลขนาดเล็กที่ประกอบด้วยคู่บริบทประมาณ 8,000 คู่ (คำพูดสองเสียงสุดท้ายของบทสนทนาจนถึงจุดปัจจุบัน) และการตอบกลับตามลำดับ รวบรวมข้อมูลจากบทสนทนาของหลักสูตรภาษาอังกฤษออนไลน์ โมเดลที่ผ่านการฝึกอบรมนี้สามารถปรับแต่งได้อย่างละเอียดโดยใช้ชุดข้อมูลโดเมนปิดกับแอปพลิเคชันในโลกแห่งความเป็นจริง
โมเดล seq2seq แบบบัญญัติได้รับความนิยมในการแปลด้วยเครื่องนิวรัล ซึ่งเป็นงานที่มีการแจกแจงความน่าจะเป็นก่อนหน้านี้ที่แตกต่างกันสำหรับคำที่อยู่ในลำดับอินพุตและเอาท์พุต เนื่องจากคำพูดอินพุตและเอาท์พุตเขียนด้วยภาษาที่แตกต่างกัน สถาปัตยกรรมที่นำเสนอในที่นี้ถือว่าการแจกแจงก่อนหน้าเหมือนกันสำหรับคำอินพุตและเอาต์พุต ดังนั้นจึงแชร์เลเยอร์การฝัง (การฝังคำที่ผ่านการฝึกอบรมล่วงหน้าของ Glove) ระหว่างกระบวนการเข้ารหัสและถอดรหัสผ่านการนำโมเดลใหม่มาใช้ เพื่อปรับปรุงความไวของบริบท เวกเตอร์ความคิด (เช่น เอาท์พุตตัวเข้ารหัส) จะเข้ารหัสคำพูดสองคำสุดท้ายของการสนทนาจนถึงจุดปัจจุบัน เพื่อหลีกเลี่ยงการลืมบริบทในระหว่างการสร้างคำตอบ เวกเตอร์ความคิดจะถูกต่อเข้ากับเวกเตอร์หนาแน่นที่เข้ารหัสคำตอบที่ไม่สมบูรณ์ที่สร้างขึ้นจนถึงจุดปัจจุบัน เวกเตอร์ที่ได้จะถูกจัดเตรียมให้กับเลเยอร์หนาแน่นที่ทำนายโทเค็นปัจจุบันของคำตอบ ดูส่วนที่ 3.1 ของรายงานของเราสำหรับข้อมูลเชิงลึกที่ดีขึ้นเกี่ยวกับข้อดีของแบบจำลองของเรา
อัลกอริธึมจะวนซ้ำโดยรวมโทเค็นที่คาดการณ์ไว้ในคำตอบที่ไม่สมบูรณ์ และป้อนกลับไปยังเลเยอร์อินพุตทางด้านขวามือของแบบจำลองที่แสดงด้านล่าง
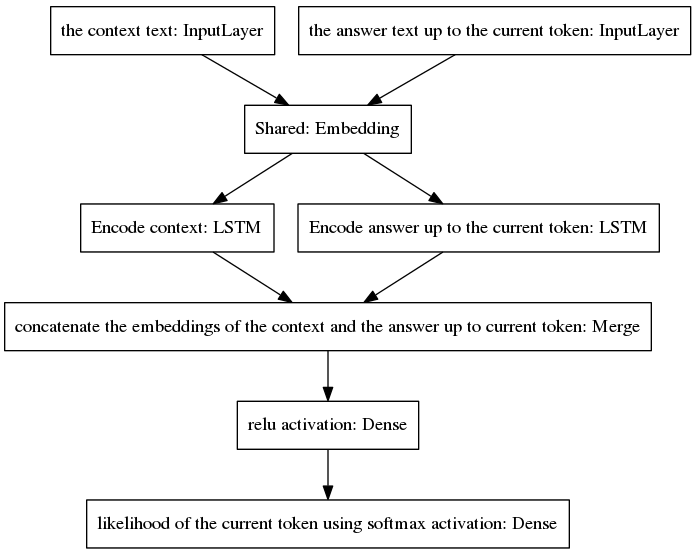
ดังที่เห็นในภาพด้านบน LSTM ทั้งสองถูกจัดเรียงขนานกัน ในขณะที่ canonical seq2seq มีเลเยอร์ของตัวเข้ารหัสและตัวถอดรหัสที่เกิดซ้ำจัดเรียงเป็นอนุกรม เลเยอร์ที่เกิดซ้ำจะถูกเปิดออกในระหว่างการขยายพันธุ์แบบย้อนกลับเมื่อเวลาผ่านไป ส่งผลให้มีฟังก์ชันที่ซ้อนกันจำนวนมาก ดังนั้น จึงมีความเสี่ยงสูงที่จะเกิดการไล่ระดับสีที่หายไป ซึ่งแย่ลงด้วยการเรียงซ้อนของเลเยอร์ที่เกิดซ้ำของโมเดล canonical seq2seq แม้ในกรณีของสถาปัตยกรรมที่มีรั้วรอบขอบชิด เช่น LSTM ฉันเชื่อว่านี่คือสาเหตุหนึ่งที่ทำให้โมเดลของฉันทำงานได้ดีขึ้นในระหว่างการฝึกมากกว่า Canonical seq2seq
รหัสเทียมต่อไปนี้จะอธิบายอัลกอริทึม

การฝึกอบรมโมเดลใหม่นี้มาบรรจบกันในไม่กี่ยุคสมัย เมื่อใช้ชุดข้อมูลตัวอย่างการฝึกอบรม 8K ของเรา จำเป็นต้องใช้เวลาเพียง 100 ยุคในการสูญเสียเอนโทรปีข้ามหมวดหมู่ที่ 0.0318 โดยมีค่าใช้จ่าย 139 วินาที/ยุคที่ทำงานใน GPU GTX980 ประสิทธิภาพของโมเดลที่ได้รับการฝึกอบรมนี้ (มีให้ในพื้นที่เก็บข้อมูลนี้) ดูเหมือนจะน่าเชื่อถือพอๆ กับประสิทธิภาพของโมเดล vanilla seq2seq ที่ได้รับการฝึกอบรมในตัวอย่างการฝึกอบรม ~ 300K ของ Cornell Movie Dialogs Corpus แต่ต้องใช้ความพยายามในการคำนวณน้อยกว่ามากในการฝึกอบรม
วิธีสนทนากับโมเดลที่ได้รับการฝึกล่วงหน้า:
ดาวน์โหลดไฟล์ python "conversation.py" ไฟล์คำศัพท์ "vocabulary_movie" และน้ำหนักสุทธิ "my_model_weights20" ซึ่งสามารถพบได้ที่นี่ ;
เรียกใช้การสนทนา.py
หากต้องการสนทนากับโมเดลใหม่ที่ได้รับการฝึกอบรมโดยอัลกอริธึมการฝึกอบรมที่ใช้ GAN ใหม่ของเรา:
ดาวน์โหลดไฟล์ python "conversation_discriminator.py" ไฟล์คำศัพท์ "vocabulary_movie" และน้ำหนักสุทธิ "my_model_weights20.h5", "my_model_weights.h5" และ "my_model_weights_discriminator.h5" ซึ่งสามารถพบได้ที่นี่ ;
เรียกใช้ Conversation_discriminator.py
โมเดลนี้มีประสิทธิภาพที่ดีกว่าโดยใช้ข้อมูลการฝึกเดียวกัน ตัวแยกแยะของแบบจำลองที่ใช้ GAN ใช้เพื่อเลือกคำตอบที่ดีที่สุดระหว่างสองแบบจำลอง แบบจำลองหนึ่งได้รับการฝึกอบรมโดยการบังคับของครู และอีกแบบจำลองหนึ่งได้รับการฝึกอบรมโดยวิธีการฝึกอบรมที่คล้ายกับ GAN ใหม่ของเรา ซึ่งมีรายละเอียดอยู่ในบทความนี้
หากต้องการฝึกโมเดลใหม่หรือปรับแต่งข้อมูลของคุณเอง ให้ทำดังนี้
หากคุณต้องการฝึกตั้งแต่ต้น ให้ลบไฟล์ my_model_weights20.h5 หากต้องการปรับแต่งข้อมูลของคุณอย่างละเอียด ให้เก็บไฟล์นี้ไว้
ดาวน์โหลดโฟลเดอร์ Glove 'glove.6B' และรวมโฟลเดอร์นี้ไว้ในไดเร็กทอรีของแชทบอท (คุณจะพบโฟลเดอร์นี้ได้ที่นี่) อัลกอริธึมนี้ใช้การถ่ายโอนการเรียนรู้โดยใช้การฝังคำที่ผ่านการฝึกอบรมมาแล้ว ซึ่งได้รับการปรับแต่งอย่างละเอียดในระหว่างการฝึกอบรม
เรียกใช้ split_qa.py เพื่อแบ่งเนื้อหาของข้อมูลการฝึกอบรมของคุณออกเป็นสองไฟล์: 'context' และ 'answers' และ get_train_data.py เพื่อจัดเก็บประโยคที่เสริมไว้ในไฟล์ 'Padded_context' และ 'Padded_answers';
เรียกใช้ train_bot.py เพื่อฝึกแชทบอต (ขอแนะนำให้ใช้ GPU โดยพิมพ์: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,Exception_verbosity=high python train_bot.py);
ตั้งชื่อข้อมูลการฝึกของคุณเป็น "data.txt" ไฟล์นี้ต้องมีหนึ่งคำพูดของบทสนทนาต่อบรรทัด หากชุดข้อมูลของคุณมีขนาดใหญ่ ให้ตั้งค่าตัวแปร num_subsets (ในบรรทัดที่ 29 ของ train_bot.py) ให้เป็นตัวเลขที่มากขึ้น
Weights_file = 'my_model_weights20.h5' Weights_file_GAN = 'my_model_weights.h5' Weights_file_discrim = 'my_model_weights_discriminator.h5'
คุณสามารถดูภาพรวมที่ดีของการใช้งานโมเดลการสนทนาทางประสาทในปัจจุบันสำหรับเฟรมเวิร์กที่แตกต่างกัน (รวมถึงผลลัพธ์บางส่วน) ได้ที่นี่
โมเดลของเราสามารถนำไปใช้กับงาน NLP อื่นๆ ได้ เช่น การสรุปข้อความ ดูตัวอย่าง Alternate 2: Recursive Model A เราสนับสนุนให้นำโมเดลของเราไปใช้ในงานอื่นๆ ในกรณีนี้ เราขอให้คุณอ้างอิงงานของเราเท่าที่สามารถทำได้ สามารถดูได้ในเอกสารนี้ ซึ่งจดทะเบียนในเดือนกรกฎาคม 2017
รหัสเหล่านี้สามารถทำงานได้ใน Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0 และ Keras 2.0.4 การใช้การกำหนดค่าอื่นอาจต้องมีการปรับเปลี่ยนเล็กน้อย


