gutenberg dialog
1.0.0
รหัสสำหรับการดาวน์โหลดและสร้างชุดข้อมูล Gutenberg Dialog เวอร์ชันของคุณเอง ขยายได้อย่างง่ายดายด้วยภาษาใหม่ ลองใช้แชทบอทที่ผ่านการฝึกอบรมในภาษาต่างๆ ที่นี่: https://ricsinaruto.github.io/chatbot.html
| ลิงค์ดาวน์โหลด | จำนวนคำพูด | ความยาวคำพูดเฉลี่ย | จำนวนบทสนทนา | ความยาวบทสนทนาโดยเฉลี่ย |
|---|---|---|---|---|
| ภาษาอังกฤษ | 14 773 741 | 22.17 | 2 526 877 | 5.85 |
| เยอรมัน | 226 015 | 24.44 | 43 440 | 5.20 |
| ภาษาดัตช์ | 129 471 | 24.26 | 23 541 | 5.50 |
| สเปน | 58 174 | 18.62 | 6 912 | 8.42 |
| ภาษาอิตาลี | 41 388 | 19.47 | 6 664 | 6.21 |
| ภาษาฮังการี | 18 816 | 14.68 | 2 826 | 6.66 |
| โปรตุเกส | 16 228 | 21.40 | 2 233 | 7.27 |
- สร้างชุดข้อมูลของคุณเองโดยการปรับพารามิเตอร์ที่ส่งผลต่อการแลกเปลี่ยนคุณภาพขนาดชุดข้อมูล
อินเทอร์เฟซแบบโมดูลาร์ทำให้ง่ายต่อการขยายชุดข้อมูลเป็นภาษาอื่น
- คุณสามารถยกเว้นหนังสือด้วยตนเองได้อย่างง่ายดายเมื่อสร้างชุดข้อมูล
เรียกใช้ setup.py ซึ่งติดตั้งแพ็คเกจที่จำเป็น
python setup.py
ควรเรียกไฟล์หลักจากรูทของ repo คำสั่งด้านล่างเรียกใช้ไปป์ไลน์การสร้างชุดข้อมูลสำหรับภาษาที่คั่นด้วยเครื่องหมายจุลภาคที่กำหนดเป็นอาร์กิวเมนต์ ปัจจุบันรองรับภาษาอังกฤษ เยอรมัน ดัตช์ สเปน โปรตุเกส อิตาลี และฮังการี
python code/main.py -l=en,de,nl,es,pt,it,hu -a
อาร์กิวเมนต์ที่ตั้งค่าได้ทั้งหมดสามารถดูได้ด้านล่าง: 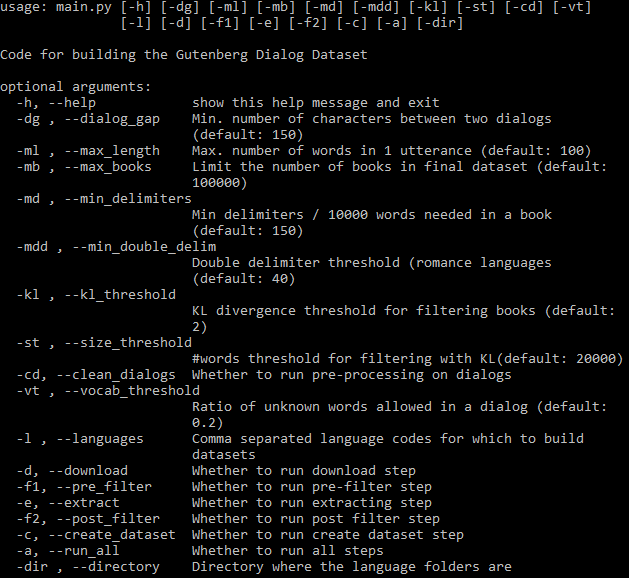
แฟล็ก -a ควบคุมว่าจะรันไปป์ไลน์ทั้งหมดโดยอัตโนมัติหรือไม่ หากละเว้น -a จะต้องระบุขั้นตอนย่อยโดยใช้แฟล็ก (ดูวิธีใช้ด้านบน) เมื่อขั้นตอนเสร็จสิ้น เอาต์พุตจะสามารถนำมาใช้ในขั้นตอนต่อๆ ไปได้ และจะมีการทำงานอีกครั้งหากพารามิเตอร์หรือโค้ดที่เกี่ยวข้องกับขั้นตอนนั้นมีการเปลี่ยนแปลงเท่านั้น ขั้นตอนทั้งหมดทำงานแยกกันสำหรับแต่ละภาษา
ดาวน์โหลดหนังสือสำหรับภาษาที่กำหนด
หมายเหตุ: หากหนังสือทั้งหมดไม่สามารถดาวน์โหลดโดยมีข้อผิดพลาด "ไม่สามารถดาวน์โหลดหนังสือ" สาเหตุที่เป็นไปได้คือมิเรอร์เริ่มต้นที่ใช้โดยแพ็คเกจ Gutenberg ไม่สามารถเข้าถึงได้ ในกรณีที่เกิดเหตุการณ์นี้ขึ้น คุณสามารถใช้มิเรอร์ทางเลือกใดๆ ที่ระบุไว้ใน https://www.gutenberg.org/MIRRORS.ALL ผ่านทางตัวแปรสภาพแวดล้อม GUTENBERG_MIRROR ตัวอย่างเช่น:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
การกรองล่วงหน้าจะลบหนังสือเก่าและเสียงรบกวนบางส่วนออก
กล่องโต้ตอบถูกดึงมาจากหนังสือ เมื่อขยายชุดข้อมูลเป็นภาษาใหม่ (ดูส่วนด้านล่าง) นี่คือขั้นตอนที่สามารถแก้ไขได้ ดังนั้นจึงสามารถข้ามขั้นตอนก่อนหน้าได้เมื่อเสร็จสิ้น
ขั้นตอนการกรองขั้นที่สองจะลบกล่องโต้ตอบบางรายการตามคำศัพท์
รวบรวมชุดข้อมูลสุดท้ายและแยกออกเป็นข้อมูลการฝึกอบรม/การพัฒนา/การทดสอบ ขั้นตอนสุดท้ายจะสร้างไฟล์ author_and_title.txt ในไดเร็กทอรีเอาต์พุตที่มีหนังสือทั้งหมด (รวมถึงชื่อเรื่องและผู้แต่ง) ที่ใช้ในการแยกชุดข้อมูลสุดท้าย ผู้ใช้สามารถคัดลอกบรรทัดจากไฟล์นี้ไปยัง bann_books.txt ที่เกี่ยวข้องกับหนังสือที่ไม่ควรได้รับอนุญาตในชุดข้อมูลได้ด้วยตนเอง ในการเรียกใช้ขั้นตอนใดๆ ในภายหลัง หนังสือในไฟล์นี้จะไม่นำมาพิจารณา
สามารถขยายโค้ดเพื่อประมวลผลภาษาอื่นได้อย่างง่ายดาย ต้องสร้างไฟล์ชื่อ <รหัสภาษา>.py ในโฟลเดอร์ภาษา ในที่นี้ควรกำหนดคลาสโดยใช้ชื่อรหัสภาษาตัวพิมพ์ใหญ่ (เช่น En สำหรับภาษาอังกฤษ) โดยมี LANG หรือคลาสย่อยอื่นๆ เป็นพาเรนต์ ด้วยพารามิเตอร์การกำหนดค่า self.cfg สามารถเข้าถึงได้ ภายในคลาสนี้ จะต้องกำหนดฟังก์ชัน 3 รายการด้านล่างนี้ โปรดดู it.py เป็นตัวอย่าง
สถิติภาษา
ฟังก์ชันนี้ควรส่งคืนพจนานุกรมโดยที่คีย์เป็นตัวคั่นที่เป็นไปได้ สำหรับตัวคั่นแต่ละตัว ควรกำหนดค่าฟังก์ชัน (ค่าในพจนานุกรม) ซึ่งใช้เป็นบรรทัดป้อนและส่งกลับตัวเลข จำนวนนี้สามารถเป็นเช่น จำนวนตัวคั่น แฟล็กว่ามีตัวคั่นอยู่ในบรรทัดหรือไม่ เป็นต้น โดยปกติแล้ว แนะนำให้ใช้การนับแบบถ่วงน้ำหนัก ขึ้นอยู่กับความสำคัญของตัวคั่นที่แตกต่างกัน ค่าจะถูกใช้เพื่อกำหนดตัวคั่นที่ควรใช้ในหนังสือที่เกี่ยวข้อง (ส่งผ่านไปยังฟังก์ชันด้านล่าง) และสำหรับการกรองหนังสือที่มีตัวคั่นจำนวนน้อย en.py มีตัวอย่างของตัวคั่นหลายตัว
ฟังก์ชันนี้ควรแยกกล่องโต้ตอบออกจากหนังสือและต่อท้าย self.dialogs ซึ่งเป็นรายการกล่องโต้ตอบ และแต่ละกล่องโต้ตอบจะเป็นรายการคำพูดที่ต่อเนื่องกัน Paragraph_list มีหนังสือเป็นรายการย่อหน้าต่อเนื่องกัน ตัวคั่น เป็นตัวคั่นที่พบบ่อยที่สุดในไฟล์นี้ซึ่งควรใช้เพื่อแยกกล่องโต้ตอบ
ฟังก์ชันนี้ใช้สำหรับกล่องโต้ตอบหลังการประมวลผล (เช่น ลบอักขระบางตัว) ใช้เป็นคำพูด โปรดทราบว่าโทเค็นคำ nltk จะทำงานโดยอัตโนมัติ
โครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT - ดูรายละเอียดในไฟล์ใบอนุญาต
โปรดใส่ลิงก์ไปยัง repo นี้หากคุณใช้ชุดข้อมูลหรือโค้ดใดๆ ในงานของคุณและพิจารณาอ้างอิงเอกสารต่อไปนี้:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


