Multi Modality Arena
1.0.0
Multi-Modality Arena เป็นแพลตฟอร์มการประเมินผลสำหรับโมเดลหลายรูปแบบขนาดใหญ่ หลังจาก Fastchat โมเดลที่ไม่ระบุตัวตนสองโมเดลจะถูกเปรียบเทียบเคียงข้างกันในงานตอบคำถามด้วยภาพ เราเปิด ตัวการสาธิต และยินดีต้อนรับการมีส่วนร่วมของทุกคนในโครงการริเริ่มการประเมินผลนี้
ชุดข้อมูล OmniMedVQA: ประกอบด้วยรูปภาพ 118,010 ภาพพร้อมรายการ QA 127,995 รายการ ครอบคลุม 12 รูปแบบที่แตกต่างกัน และอ้างอิงถึงบริเวณกายวิภาคของมนุษย์มากกว่า 20 แห่ง สามารถดาวน์โหลดชุดข้อมูลได้จากที่นี่
12 รุ่น: LVLM โดเมนทั่วไป 8 รายการ และ LVLM เฉพาะทางการแพทย์ 4 รายการ
ชุดข้อมูลขนาดเล็ก: เพียง 50 ตัวอย่างที่เลือกแบบสุ่มสำหรับแต่ละชุดข้อมูล เช่น การวัดประสิทธิภาพภาพที่เกี่ยวข้องกับข้อความ 42 รายการ และตัวอย่างทั้งหมด 2.1,000 ตัวอย่างเพื่อความสะดวกในการใช้งาน
รุ่นเพิ่มเติม : อีก 4 รุ่น ได้แก่ รวม 12 รุ่น รวม Google Bard .
ChatGPT Ensemble Evalution : ปรับปรุงข้อตกลงกับการประเมินโดยมนุษย์มากกว่าวิธีจับคู่คำแบบเดิม
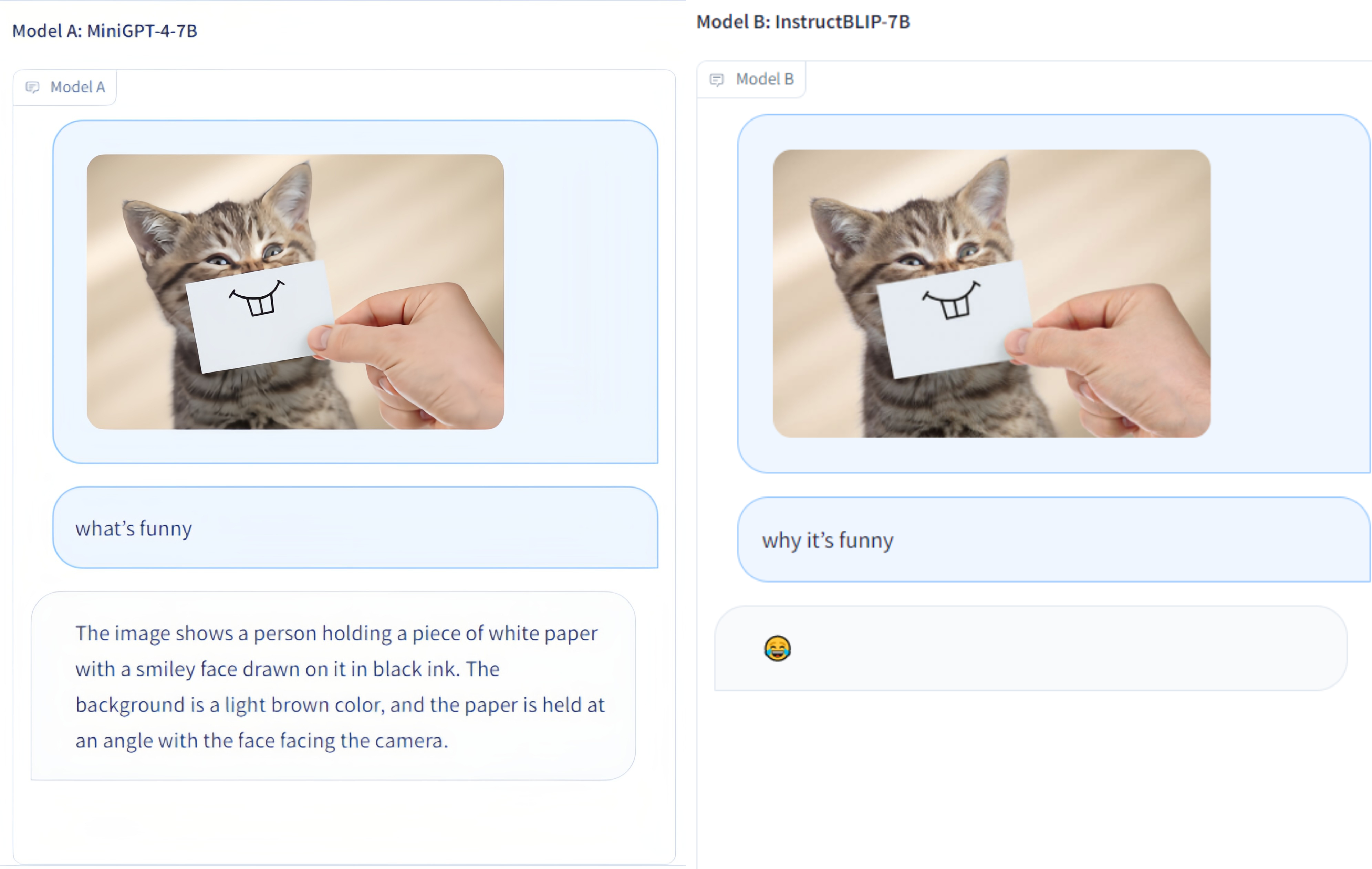
LVLM-eHub เป็นเกณฑ์มาตรฐานการประเมินที่ครอบคลุมสำหรับโมเดลหลายรูปแบบขนาดใหญ่ (LVLM) ที่เผยแพร่ต่อสาธารณะ มันประเมินอย่างกว้างขวาง
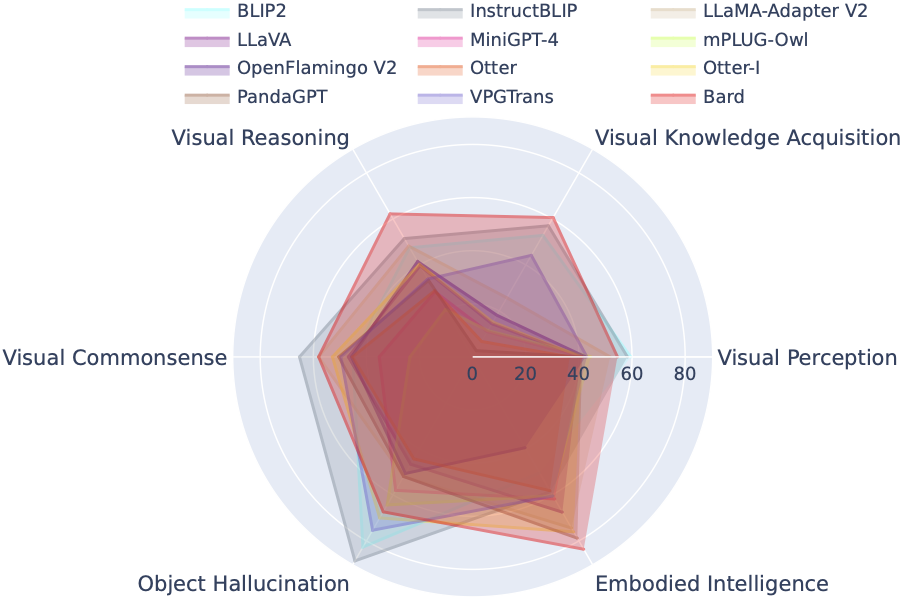
กระดานผู้นำ LVLM จัดหมวดหมู่ชุดข้อมูลที่โดดเด่นในการประเมิน LVLM แบบจิ๋วอย่างเป็นระบบตามความสามารถเป้าหมายเฉพาะ รวมถึงการรับรู้ทางสายตา การใช้เหตุผลด้วยภาพ การใช้สามัญสำนึกทางการมองเห็น การได้มาซึ่งความรู้ทางภาพ และภาพหลอนของวัตถุ บอร์ดผู้นำนี้รวมโมเดลที่เพิ่งเปิดตัวเพื่อเสริมความครอบคลุม
คุณสามารถดาวน์โหลดเกณฑ์มาตรฐานได้จากที่นี่ และรายละเอียดเพิ่มเติมสามารถพบได้ที่นี่
| อันดับ | แบบอย่าง | เวอร์ชัน | คะแนน |
|---|---|---|---|
| 1 | ฝึกงานVL | InternVL-แชท | 327.61 |
| 2 | ฝึกงานLM-XComposer-VL | ฝึกงานLM-XComposer-VL-7B | 322.51 |
| 3 | กวี | กวี | 319.59 |
| 4 | Qwen-VL-แชท | Qwen-VL-แชท | 316.81 |
| 5 | แอลลาวา-1.5 | วิคูนา-7B | 307.17 |
| 6 | สอน BLIP | วิคูนา-7B | 300.64 |
| 7 | ฝึกงานLM-XComposer | ฝึกงานLM-XComposer-7B | 288.89 |
| 8 | บลิป2 | ขนลุกT5xl | 284.72 |
| 9 | บลิวา | วิคูนา-7B | 284.17 |
| 10 | คม | วิคูนา-7B | 279.24 |
| 11 | เสือชีตาห์ | วิคูนา-7B | 258.91 |
| 12 | LLaMA-อะแดปเตอร์-v2 | ลามา-7บี | 229.16 |
| 13 | วีพีจีทรานส์ | วิคูนา-7B | 218.91 |
| 14 | นาก-รูปภาพ | Otter-9B-LA-InContext | 216.43 |
| 15 | วิชวลจีแอลเอ็ม-6บี | วิชวลจีแอลเอ็ม-6บี | 211.98 |
| 16 | mPLUG-นกฮูก | ลามา-7บี | 209.40 |
| 17 | ลาวา | วิคูนา-7B | 200.93 |
| 18 | มินิ GPT-4 | วิคูนา-7B | 192.62 |
| 19 | นาก | นาก-9B | 180.87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176.37 |
| 21 | แพนด้าGPT | วิคูนา-7B | 174.25 |
| 22 | ลาวิน | ลามา-7บี | 97.51 |
| 23 | ไมค์ | ขนลุกT5xl | 94.09 |
31 มี.ค. 2024 เราเปิดตัว OmniMedVQA ซึ่งเป็นเกณฑ์มาตรฐานการประเมินที่ครอบคลุมขนาดใหญ่สำหรับ LVLM ทางการแพทย์ ในขณะเดียวกัน เรามี LVLM โดเมนทั่วไป 8 รายการ และ LVLM เฉพาะทางทางการแพทย์ 4 รายการ สำหรับรายละเอียดเพิ่มเติม โปรดไปที่ MedicalEval
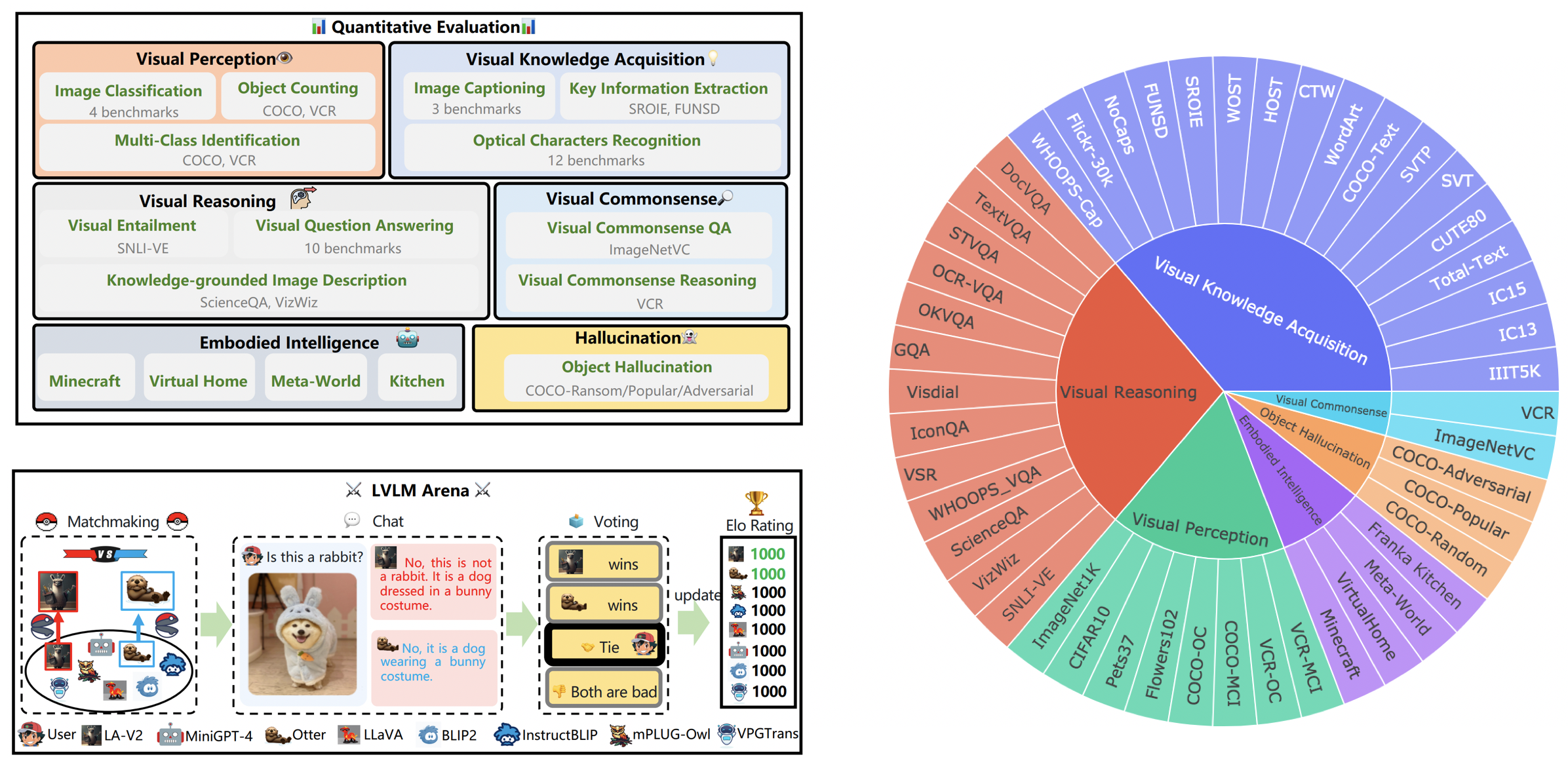
16 ต.ค. 2023 เรานำเสนอการแยกชุดข้อมูลระดับความสามารถที่ได้มาจาก LVLM-eHub เสริมด้วยการรวมโมเดลที่เพิ่งเปิดตัวแปดโมเดล สำหรับการเข้าถึงการแยกชุดข้อมูล โค้ดการประเมินผล ผลลัพธ์การอนุมานโมเดล และตารางประสิทธิภาพที่ครอบคลุม โปรดไปที่ Tiny_lvlm_evaluetion ✅
8 ส.ค. 2023 เราเปิดตัว [Tiny LVLM-eHub] ซอร์สโค้ดการประเมินและผลการอนุมานแบบจำลองเป็นแบบโอเพ่นซอร์สภายใต้ Tiny_lvlm_evalue
15 มิ.ย. 2023 เราเปิดตัว [LVLM-eHub] ซึ่งเป็นเกณฑ์มาตรฐานการประเมินสำหรับโมเดลภาษาวิชั่นขนาดใหญ่ รหัสจะมาเร็ว ๆ นี้
8 มิ.ย. 2023 ขอขอบคุณ ดร. จาง ผู้เขียน VPGTrans สำหรับการแก้ไข ผู้เขียน VPGTrans ส่วนใหญ่มาจาก NUS และ Tsinghua University ก่อนหน้านี้เราประสบปัญหาเล็กน้อยเมื่อนำ VPGTrans ไปใช้ใหม่ แต่เราพบว่าประสิทธิภาพของมันดีขึ้นจริงๆ สำหรับผู้เขียนแบบจำลองเพิ่มเติม โปรดติดต่อฉันเพื่อพูดคุยได้ที่อีเมล นอกจากนี้ โปรดปฏิบัติตามรายการจัดอันดับแบบจำลองของเรา ซึ่งจะมีผลลัพธ์ที่แม่นยำยิ่งขึ้น
อาจ. 22 ต.ค. 2023 ขอขอบคุณ Dr. Ye ผู้เขียน mPLUG-Owl สำหรับการแก้ไข เราแก้ไขปัญหาเล็กน้อยในการใช้งาน mPLIG-Owl
โมเดลต่อไปนี้เกี่ยวข้องกับการรบแบบสุ่มในปัจจุบัน
KAUST/มินิGPT-4
พนักงานขาย/BLIP2
พนักงานขาย/สอน BLIP
DAMO Academy/mPLUG-Owl
NTU/นาก
มหาวิทยาลัยวิสคอนซิน-แมดิสัน/LLaVA
เซี่ยงไฮ้ AI Lab/llama_adapter_v2
NUS/VPGทรานส์
ดูรายละเอียดเพิ่มเติมเกี่ยวกับรุ่นเหล่านี้ได้ที่ . ./model_detail/.model.jpg เราจะพยายามจัดกำหนดการทรัพยากรการประมวลผลเพื่อโฮสต์โมเดลที่หลากหลายมากขึ้นในเวทีนี้
หากคุณสนใจแพลตฟอร์ม VLarena ของเรา โปรดเข้าร่วมกลุ่ม Wechat ได้เลย

สร้างสภาพแวดล้อม conda
conda create -n เวทีหลาม = 3.10 conda เปิดใช้งานเวที
ติดตั้งแพ็คเกจที่จำเป็นสำหรับการรันคอนโทรลเลอร์และเซิร์ฟเวอร์
pip ติดตั้ง numpy gradio uvicorn fastapi
จากนั้น สำหรับแต่ละรุ่น อาจต้องใช้แพ็คเกจ Python เวอร์ชันที่ขัดแย้งกัน เราขอแนะนำให้สร้างสภาพแวดล้อมเฉพาะสำหรับแต่ละรุ่นตามที่เก็บ GitHub
หากต้องการให้บริการโดยใช้ UI ของเว็บ คุณต้องมีองค์ประกอบหลัก 3 ส่วน ได้แก่ เว็บเซิร์ฟเวอร์ที่เชื่อมต่อกับผู้ใช้ คนทำงานโมเดลที่โฮสต์โมเดลตั้งแต่สองโมเดลขึ้นไป และตัวควบคุมเพื่อประสานงานเว็บเซิร์ฟเวอร์และผู้ทำงานโมเดล
ต่อไปนี้เป็นคำสั่งที่ต้องปฏิบัติตามในเทอร์มินัลของคุณ:
หลาม controller.py
คอนโทรลเลอร์นี้จัดการพนักงานแบบกระจาย
หลาม model_worker.py -- ชื่อรุ่น SELECTED_MODEL -- อุปกรณ์ TARGET_DEVICE
รอจนกว่ากระบวนการโหลดโมเดลเสร็จสิ้น และคุณจะเห็นข้อความ "Uvicorn ทำงานบน ... " ผู้ปฏิบัติงานโมเดลจะลงทะเบียนตัวเองกับคอนโทรลเลอร์ สำหรับผู้ปฏิบัติงานโมเดลแต่ละคน คุณต้องระบุรุ่นและอุปกรณ์ที่คุณต้องการใช้
หลาม server_demo.py
นี่คืออินเทอร์เฟซผู้ใช้ที่ผู้ใช้จะโต้ตอบด้วย
เมื่อทำตามขั้นตอนเหล่านี้ คุณจะสามารถให้บริการโมเดลของคุณโดยใช้ UI ของเว็บได้ คุณสามารถเปิดเบราว์เซอร์และแชทกับโมเดลได้ทันที หากโมเดลไม่ปรากฏขึ้น ให้ลองรีบูตเว็บเซิร์ฟเวอร์ gradio
เราให้ความสำคัญอย่างยิ่งต่อการมีส่วนร่วมทั้งหมดที่มีจุดมุ่งหมายเพื่อเพิ่มคุณภาพของการประเมินของเรา ส่วนนี้ประกอบด้วยสองส่วนหลัก: Contributions to LVLM Evaluation และ Contributions to LVLM Arena
คุณสามารถเข้าถึงโค้ดการประเมินผลเวอร์ชันล่าสุดได้ในโฟลเดอร์ LVLM_evalue ไดเร็กทอรีนี้ประกอบด้วยชุดโค้ดการประเมินที่ครอบคลุม พร้อมด้วยชุดข้อมูลที่จำเป็น หากคุณมีความกระตือรือร้นที่จะมีส่วนร่วมในกระบวนการประเมิน โปรดอย่าลังเลที่จะแบ่งปันผลการประเมินหรือ API การอนุมานแบบจำลองกับเราผ่านทางอีเมลที่ [email protected]
เราขอขอบคุณสำหรับความสนใจในการรวมโมเดลของคุณเข้ากับ LVLM Arena ของเรา! หากคุณต้องการรวมโมเดลของคุณเข้ากับ Arena ของเรา โปรดเตรียมผู้ทดสอบโมเดลที่มีโครงสร้างดังนี้:
class ModelTester:def __init__(self, device=None) -> None:# TODO: การเริ่มต้นของโมเดลและตัวประมวลผลล่วงหน้าที่จำเป็นdef move_to_device(self, device) -> None:# TODO: ฟังก์ชั่นนี้ใช้เพื่อถ่ายโอนโมเดลระหว่าง CPU และ GPU (เป็นทางเลือก) def สร้าง (ตัวเอง, รูปภาพ, คำถาม) -> str: # TODO: รหัสการอนุมานโมเดล
นอกจากนี้ เรายังเปิดรับลิงก์การอนุมานโมเดลออนไลน์ เช่น ลิงก์ที่จัดทำโดยแพลตฟอร์ม เช่น Gradio การมีส่วนร่วมของคุณได้รับการชื่นชมอย่างสุดใจ
เราแสดงความขอบคุณต่อทีมงานที่นับถือที่ ChatBot Arena และรายงานของพวกเขาที่ตัดสิน LLM ในฐานะผู้ตัดสินสำหรับงานที่มีอิทธิพลของพวกเขา ซึ่งทำหน้าที่เป็นแรงบันดาลใจสำหรับความพยายามในการประเมิน LVLM ของเรา นอกจากนี้เรายังอยากจะแสดงความขอบคุณอย่างจริงใจต่อผู้ให้บริการ LVLM ซึ่งการมีส่วนร่วมอันมีค่ามีส่วนสำคัญต่อความก้าวหน้าและความก้าวหน้าของโมเดลภาษาวิสัยทัศน์ขนาดใหญ่ สุดท้ายนี้ เราขอขอบคุณผู้ให้บริการชุดข้อมูลที่ใช้ใน LVLM-eHub ของเรา
โครงการนี้เป็นเครื่องมือวิจัยเชิงทดลองเพื่อวัตถุประสงค์ที่ไม่ใช่เชิงพาณิชย์เท่านั้น มีการป้องกันที่จำกัดและอาจสร้างเนื้อหาที่ไม่เหมาะสม ไม่สามารถนำไปใช้เพื่อสิ่งผิดกฎหมาย เป็นอันตราย รุนแรง เหยียดเชื้อชาติ หรือทางเพศได้


