Sound Content Music Recommendation System
1.0.0

ถ้าคุณเป็นเหมือนฉัน คุณจะรักเสียงดนตรี ฉันชอบดนตรีและชอบค้นหาเพลงใหม่ๆ Spotify เป็นหนึ่งในบริการสตรีมมิ่งเพลงบนอินเทอร์เน็ตชั้นนำ และมีเครื่องมือที่น่าทึ่งที่ช่วยให้คุณค้นพบเพลงใหม่ตามสิ่งที่คุณฟังอยู่แล้ว โดยทำสิ่งนี้ผ่านการผสมผสานของอัลกอริธึมที่แตกต่างกัน รวมถึงการกรองการทำงานร่วมกันซึ่งมีการติดตามการใช้งานที่คล้ายกันระหว่างผู้ใช้ และสร้างคำแนะนำหรือคำแนะนำตามเนื้อหาที่แนะนำเพลงใหม่ตามข้อมูลที่คล้ายคลึงกันระหว่างข้อมูลที่เชื่อมโยงกับเพลง ชอบเพลงเหรอ? บน Spotify คุณสามารถฟัง 'วิทยุ' ของเพลงนั้นได้ ซึ่งจะรวบรวมกลุ่มเพลงที่คล้ายกับเพลงนั้นในทางใดทางหนึ่งหรือหลายทางรวมกัน จะเป็นอย่างไรถ้าคุณชอบเพลง แต่ไม่สนใจข้อมูลอื่นใดนอกจากเสียงในเพลงล่ะ? บางครั้งนั่นคือทั้งหมดที่ฉันอยากได้ยิน
ฉันสร้างโปรเจ็กต์นี้เพื่อสร้างระบบแนะนำเพลงโดยอาศัยข้อมูลในเสียงดนตรีเพียงอย่างเดียว จะช่วยให้ผู้ใช้ค้นหาเพลงใหม่ผ่านเพลงที่มีเสียงคล้ายกัน ในการทำเช่นนั้น มันยังจะสำรวจความคล้ายคลึงกันระหว่างดนตรีทั้งหมด และพยายามจับเสียง จังหวะ และสไตล์ของเพลงในทางคณิตศาสตร์
เสียงอยู่รอบตัวเราเสมอ ตลอดชีวิตของเรา เราจะแยกแยะเสียงที่แตกต่างจากเสียงอื่นๆ ได้ ดนตรีก็ไม่แตกต่างกัน - ดนตรีมีหลายประเภท และดนตรีมักเป็นการผสมผสานระหว่างเสียงและจังหวะหลายประเภทที่เราแยกแยะออกจากประเภทอื่นๆ ได้ แต่เราสามารถหาปริมาณข้อมูลนั้นเพื่อตัวเราเองได้หรือไม่? บางครั้ง ดนตรีก็ถูกจัดหมวดหมู่เป็นแนวเพลง ซึ่งหมายความว่าแนวเพลงคือกลุ่มนักดนตรีที่มีคุณสมบัติด้านสไตล์ รูปทรง จังหวะ จังหวะ เครื่องดนตรี หรือวัฒนธรรมที่คล้ายคลึงกัน แต่ไม่ใช่ว่าศิลปินทุกคนจะสร้างเสียงในแนวเพลงเดียวกัน และไม่ใช่ทุกแนวที่มีเพลงประเภทเดียวกัน เสียงคืออะไร และเราจะแยกแยะเสียงประเภทต่างๆ ได้อย่างไร
เสียงคือการสั่นสะเทือนของคลื่นเสียงที่เรารับรู้ผ่านหูของเราเมื่อคลื่นเหล่านั้นสั่นสะเทือนแก้วหูของเรา คลื่นเสียงเป็นสัญญาณและความเร็วของการสั่นสะเทือนของสัญญาณนั้นเรียกว่าความถี่ หากความถี่เสียงสูงขึ้น เราจะรับรู้ว่าเสียงนั้นมีระดับเสียงที่สูงกว่า ในดนตรี เครื่องดนตรีอย่างเบสหรือกลองเบสจะสร้างเสียงที่สั่นสะเทือนที่ความถี่ต่ำกว่า ในขณะที่ระดับเสียงสูงจะมีความถี่ที่สูงกว่า เสียงเหมือนการปะทะกันของฉาบหรือไฮแฮทเป็นการผสมผสานระหว่างคลื่นหลายๆ คลื่นในความถี่ที่ต่างกัน และแสดงด้วยคลื่นที่ 'มีเสียงดัง' แทบจะดูเหมือนสุ่ม
เสียงมีลักษณะอย่างไร? วิธีหนึ่งที่เราสามารถมองเห็นเสียงได้คือการวางสัญญาณข้ามเวลา:
เมื่อเราลดระยะเวลาในแต่ละแผนย่อยลง เราก็จะมองเห็นสัญญาณเสียงได้ใกล้ยิ่งขึ้น สังเกตในภาพขยายที่สุดของสัญญาณ คลื่นคือชุดของความถี่ที่แตกต่างกัน อาจมีสัญญาณความถี่ต่ำหนึ่งสัญญาณที่รวมกับสัญญาณความถี่สูงที่มีขนาดเล็กกว่า
ดังนั้นเราจึงเห็นภาพสัญญาณในช่วงเวลาหนึ่งได้ แต่เราบอกได้เลยว่าเป็นเรื่องยากที่จะเข้าใจมากเกี่ยวกับคลื่นเสียงนั้นเพียงแค่ดูจากการแสดงภาพนี้ ความถี่ประเภทใดที่มีอยู่ในหน้าต่าง 0.01 วินาทีนั้น เพื่อตอบคำถามนี้ เราจะใช้การแปลงฟูริเยร์ในการคำนวณสเปกโตรแกรม
การแปลงฟูริเยร์เป็นวิธีการคำนวณความกว้างของความถี่ที่ปรากฏในส่วนของสัญญาณเสียง ดังที่คุณเห็นในกราฟด้านบน คลื่นอาจมีความซับซ้อนและการแปรผันของสัญญาณแต่ละครั้งแสดงถึงความถี่ที่แตกต่างกัน (ความเร็วของการสั่น) การแปลงฟูริเยร์จะดึงความถี่สำหรับแต่ละส่วนของเวลาและสร้างอาร์เรย์ 2 มิติของแอมพลิจูดความถี่เทียบกับเวลา ผลคูณของการแปลงฟูริเยร์คือสเปกโตรแกรม จากสเปกโตรแกรม เราจะแปลงความถี่ที่สร้างขึ้นเป็นสเกลเมลเพื่อสร้างสเปกโตรแกรมเมล เมลสเปกโตรแกรมจะแสดงถึงระยะห่างที่รับรู้ระหว่างความถี่ต่างๆ ได้ดีขึ้นเมื่อเราได้ยิน
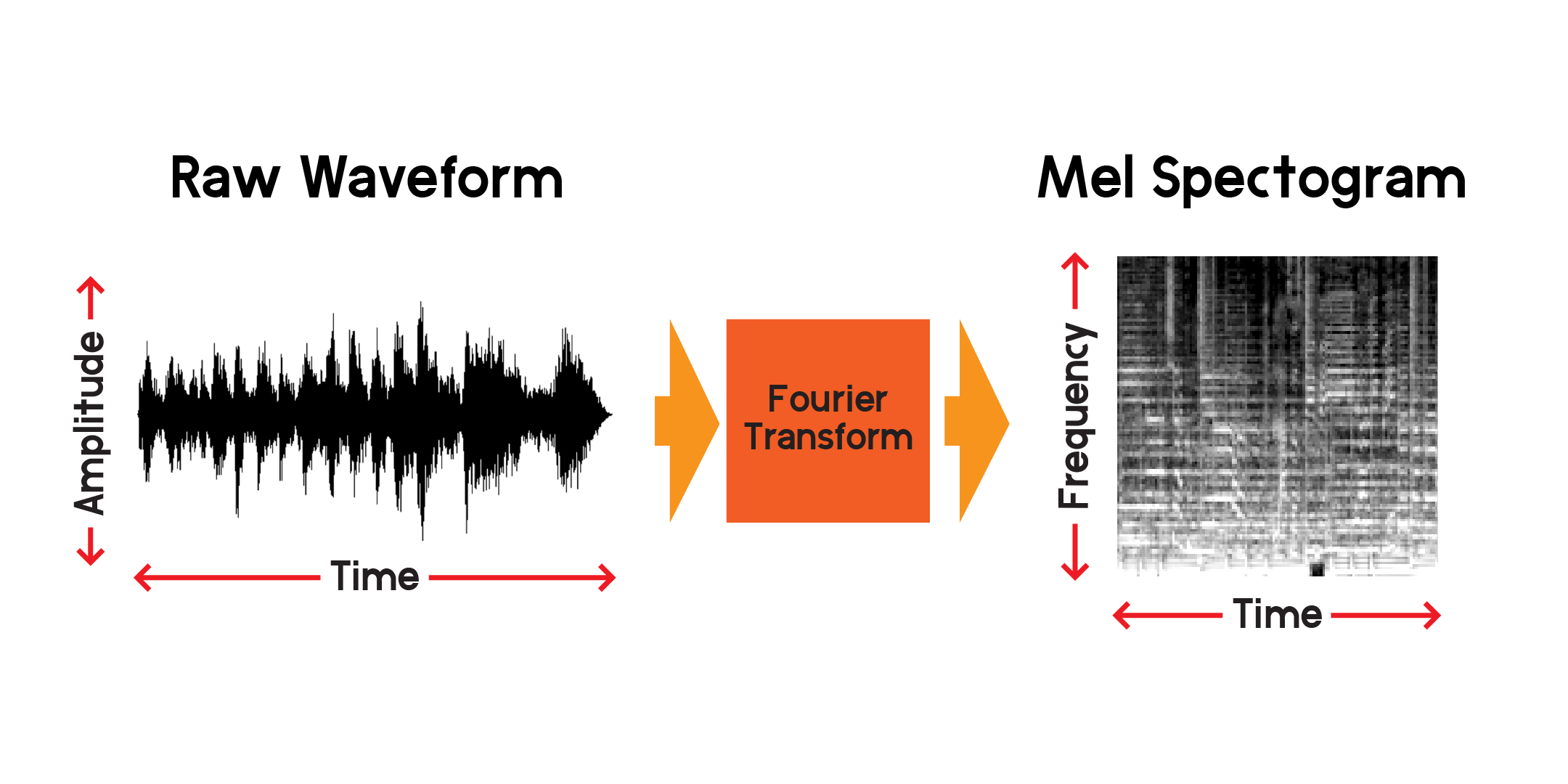
เรามาพล็อตตัวอย่างของเมลสเปกโตรแกรมจากตัวอย่างเสียงเดียวกันกับที่เราวางแผนไว้ข้างต้น:
ฉันคัดลอกข้อมูลเพลงในสมุดบันทึกก่อนหน้าโดยใช้ Public API ของ Spotify จากนั้นฉันสามารถดาวน์โหลดตัวอย่าง MP3 ความยาว 30 วินาทีของแต่ละเพลงและแปลงเป็นเมลสเปกโตรแกรมเพื่อใช้ในโครงข่ายประสาทเทียมที่ฝึกฝนรูปภาพ ก่อนอื่น มาดู data frame กันก่อน เราจะใช้ในการรวบรวมตัวอย่าง mp3
ในสมุดบันทึกอื่น ฉันใช้ลิงก์แสดงตัวอย่างจาก Spotify API ดาวน์โหลด MP3 และแปลงไฟล์เสียงเป็นภาพคอมโพสิตที่มี mel spectrogram, Mel Frequency Cepstral Coefficient และ Chromagram ฉันสร้างภาพคอมโพสิตนี้ด้วยความตั้งใจว่าจะใช้การแปลงอื่นๆ เหล่านี้ แต่สำหรับโปรเจ็กต์นี้ ฉันจะฝึกโครงข่ายประสาทเทียมบนเมลสเปกโตรแกรมเท่านั้น
หากต้องการแนะนำเพลงที่คล้ายกันตามเนื้อหาเสียงเพียงอย่างเดียว ฉันจะต้องสร้างฟีเจอร์ที่อธิบายเนื้อหาของเพลงในทางใดทางหนึ่ง นอกจากนี้ เพื่อให้ดำเนินการได้รวดเร็ว ฉันจะต้องบีบอัดข้อมูลของแต่ละเพลงให้เป็นชุดตัวเลขที่เล็กกว่าอินพุตของเมลสเปกโตรแกรม
สำหรับไฟล์ตัวอย่างเพลงแต่ละไฟล์จะมีตัวอย่างมากกว่า 600,000 ตัวอย่าง ในแต่ละเมลสเปกโตรแกรมจะมีขนาด 512 x 128 พิกเซล รวมเป็น 65,536 พิกเซล แม้แต่รูปภาพขนาด 128x128 ก็มีจำนวน 16,384 พิกเซล รูปแบบการเข้ารหัสอัตโนมัตินี้จะบีบอัดเนื้อหาของเพลงให้เหลือเพียง 256 หมายเลข เมื่อโปรแกรมเข้ารหัสอัตโนมัติได้รับการฝึกฝนอย่างเพียงพอ เครือข่ายจะสามารถสร้างเพลงขึ้นใหม่จากเวกเตอร์ที่มีความยาว 256 โดยสูญเสียน้อยที่สุด
ตัว เข้ารหัสอัตโนมัติ คือโครงข่ายประสาทเทียมประเภทหนึ่งที่ประกอบด้วย ตัวเข้ารหัส และ ตัวถอดรหัส ขั้นแรก ตัวเข้ารหัสจะบีบอัดข้อมูลของอินพุตให้เป็นข้อมูลจำนวนน้อยกว่ามาก และเครื่องถอดรหัสจะสร้างข้อมูลขึ้นมาใหม่ให้ใกล้เคียงกับเอาต์พุตดั้งเดิมมากที่สุด
โปรแกรมเข้ารหัสอัตโนมัติยังเป็นโครงข่ายประสาทเทียมชนิดพิเศษที่ไม่ได้รับการดูแล แม้ว่าจะไม่ได้ไม่ได้รับการดูแลก็ตาม มีการดูแลตนเองเนื่องจากใช้อินพุตเพื่อฝึกเอาต์พุตของโมเดล
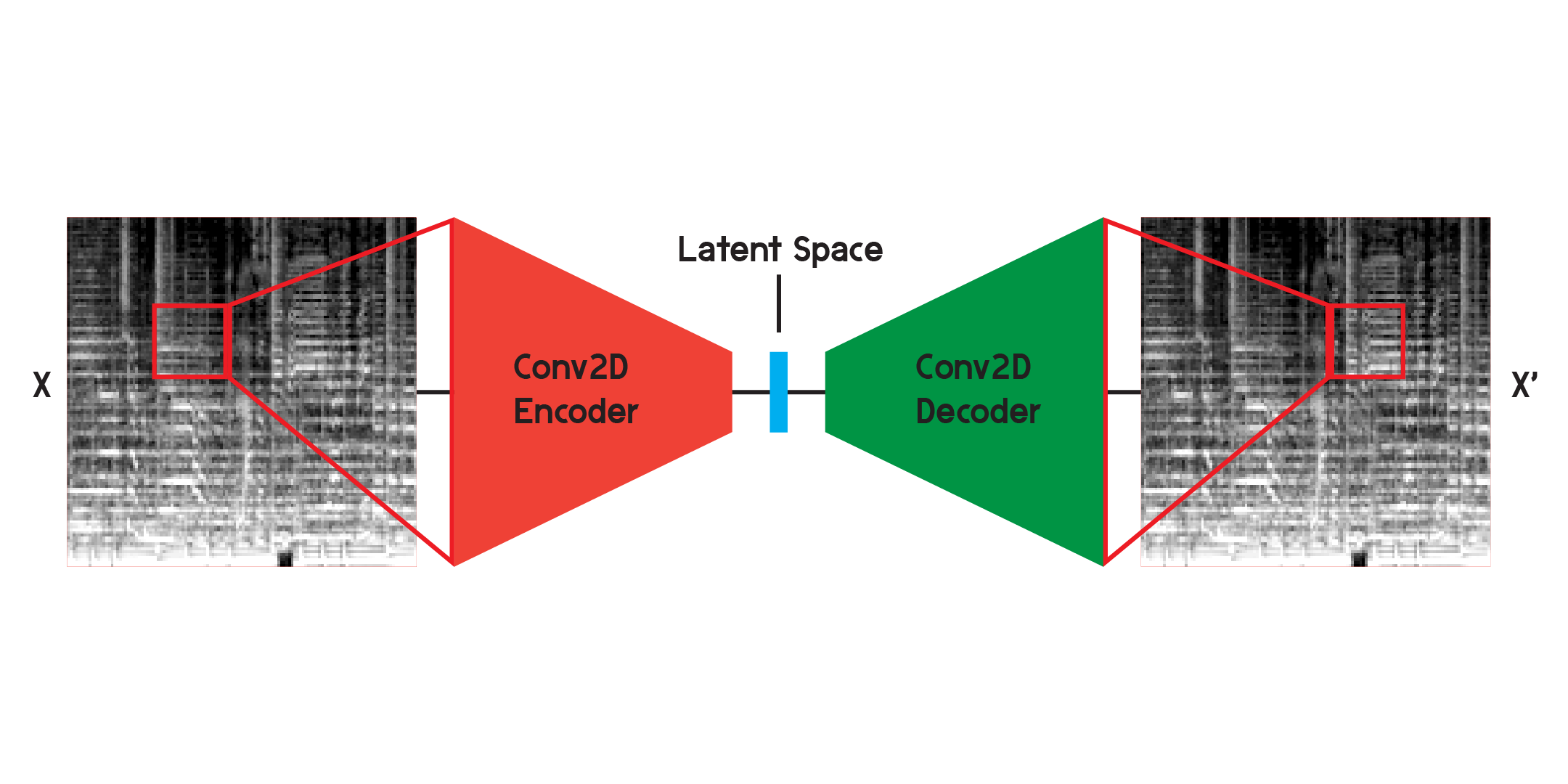
เมื่อทำงานกับรูปภาพ ตัวเข้ารหัสคือลำดับของเลเยอร์แบบบิดเบี้ยวสองมิติ ซึ่งสร้างตัวกรองแบบถ่วงน้ำหนักเพื่อแยกรูปแบบในภาพ ขณะเดียวกันก็บีบอัดรูปภาพให้เป็นรูปร่างที่เล็กลงและเล็กลง ตัวถอดรหัสเป็นการสะท้อนกระจกของกระบวนการในตัวเข้ารหัส โดยการปรับรูปร่างใหม่และขยายข้อมูลจำนวนเล็กน้อยให้ใหญ่ขึ้น แบบจำลองจะลดค่าคลาดเคลื่อนกำลังสองเฉลี่ยระหว่างต้นฉบับและการสร้างใหม่ให้เหลือน้อยที่สุด เมื่อได้รับการฝึกอบรมอย่างเพียงพอ ความคลาดเคลื่อนกำลังสองเฉลี่ยระหว่างต้นฉบับและเอาท์พุตของแบบจำลองจะมีน้อยมาก แม้ว่าค่าคลาดเคลื่อนกำลังสองเฉลี่ยจะน้อยมาก แต่ก็ยังมีความแตกต่างที่มองเห็นได้ระหว่างการสร้างใหม่กับภาพต้นฉบับ โดยเฉพาะอย่างยิ่งในรายละเอียดที่เล็กที่สุด ตัวเข้ารหัสอัตโนมัติเป็นตัวลดเสียงรบกวน เราต้องการแยกรายละเอียดให้ได้มากที่สุด แต่ท้ายที่สุดแล้ว โปรแกรมเข้ารหัสอัตโนมัติจะผสมผสานรายละเอียดบางอย่างเข้าด้วยกัน
ในตอนแรกฉันฝึกเครือข่ายโดยใช้โครงสร้างที่แสดงด้านบน แต่พบว่ารายละเอียดหลายอย่างขาดหายไปในการสร้างใหม่ เลเยอร์แบบม้วนจะค้นหารูปแบบที่เป็นเพียงส่วนเล็กๆ ของรูปภาพทั้งหมด แต่หลังจากการฝึกอบรมและการสังเกตตัวกรองแล้ว เป็นการยากที่จะหยั่งรู้ถึงรูปแบบที่แยกออกมา
ตัวเข้ารหัสอัตโนมัติเช่นนี้สามารถใช้ได้กับปัญหาต่างๆ มากมาย และด้วยเลเยอร์แบบหมุนวน จึงมีแอปพลิเคชันมากมายสำหรับการจดจำและสร้างภาพ แต่เนื่องจากเมลสเปกโตรแกรมไม่เพียงแต่เป็นภาพเท่านั้น แต่ยังเป็นกราฟของความถี่ในเนื้อหาเสียงในช่วงเวลาหนึ่ง ฉันจึงเชื่อว่าโครงสร้างที่แตกต่างกันเล็กน้อยสามารถนำมาใช้เพื่อลดการสูญเสียในการสร้างใหม่ได้ ในขณะเดียวกันก็ลดความไม่แน่นอนที่สร้างขึ้นโดยการหมุนวนแบบ 2 มิติให้เหลือน้อยที่สุด ชั้น
ในโมเดลที่ใช้สำหรับผลลัพธ์สุดท้ายของโมเดล ฉันแบ่งตัวเข้ารหัสออกเป็นสองตัวแยกกัน ตัวเข้ารหัสแต่ละตัวใช้ เลเยอร์แบบหมุนวนหนึ่งมิติ เพื่อบีบอัดพื้นที่ของรูปภาพ ตัวเข้ารหัสตัวหนึ่งกำลังฝึกบน X ในขณะที่อีกตัวกำลังฝึกบน X transpose หรืออินพุตเวอร์ชันที่หมุนได้ 90 องศา วิธีนี้ตัวเข้ารหัสตัวหนึ่งกำลังเรียนรู้ข้อมูลจากแกนเวลาของภาพ และอีกตัวคือการเรียนรู้จากแกนความถี่
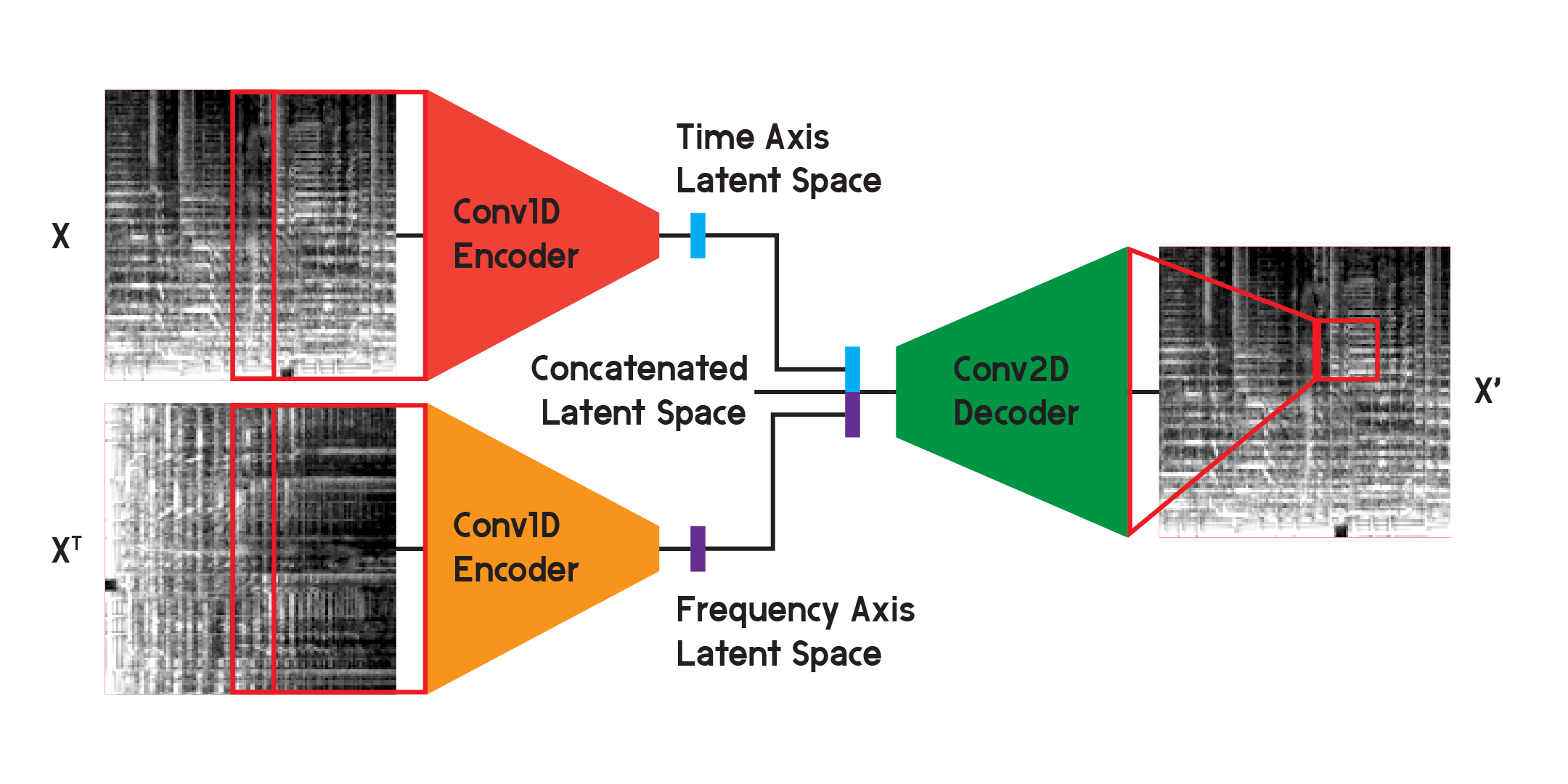
หลังจากที่อินพุทรันผ่านตัวเข้ารหัสแต่ละตัว เวกเตอร์ที่เข้ารหัสที่ได้จะถูกต่อเข้าด้วยกันเป็นเวกเตอร์เดียวและอินพุทเข้าไปใน ตัวถอดรหัสแบบหมุนวนสองมิติ ดังที่แสดงไว้ก่อนหน้านี้ เอาต์พุตได้รับการฝึกอบรมเพื่อลดการสูญเสียระหว่างอินพุตให้เหลือน้อยที่สุดเหมือนเมื่อก่อน
ในท้ายที่สุด การสูญเสียในแบบจำลองขั้นสุดท้ายยังต่ำกว่าโครงสร้างพื้นฐานมาก โดยไปถึงค่าคลาดเคลื่อนกำลังสองเฉลี่ยที่ 0.0037 (การฝึกอบรม) และ 0.0037 (การตรวจสอบความถูกต้อง) หลังจาก 20 ยุค โดยมีรูปภาพ 125,440 ภาพในชุดการฝึกอบรม และ 2560 ภาพในชุดการฝึกอบรม และ 2560 ภาพในชุดการฝึกอบรม ชุดการตรวจสอบ
เราจะสร้างโมเดลที่นี่เพื่อจุดประสงค์ในการสาธิตเท่านั้น ในขณะที่ฉันฝึกโมเดลในสมุดบันทึกอีกเครื่องหนึ่ง และจะโหลดน้ำหนักจากโมเดลที่ได้รับการฝึกเมื่อสร้างขึ้นแล้ว
การใช้คลาสที่กำหนดเองสำหรับการอนุมานผ่านเครือข่ายและการบันทึกผลลัพธ์ เราสามารถสร้างพื้นที่แฝงสำหรับเมลสเปกโตรแกรมทุกอันที่เรามี เราสามารถทำได้โดยการเรียกใช้ข้อมูลผ่านตัวเข้ารหัสเท่านั้น และรับเวกเตอร์ขนาดที่เราเริ่มต้นโมเดลด้วย ในกรณีนี้คือ 256 มิติ
ในการสำรวจภูมิทัศน์เชิงนามธรรมที่สร้างขึ้นโดยพื้นที่แฝงของข้อมูลผ่านแบบจำลอง เราสามารถใช้การลดขนาดได้ UMAP เช่นเดียวกับ T-SNE สามารถลดพื้นที่หลายมิติเป็น 2 มิติสำหรับการแสดงภาพในพล็อต
คลาส LatentSpace แบบกำหนดเองจะค้นหาคำแนะนำโดยใช้ความคล้ายคลึงโคไซน์สำหรับเวกเตอร์แต่ละตัว
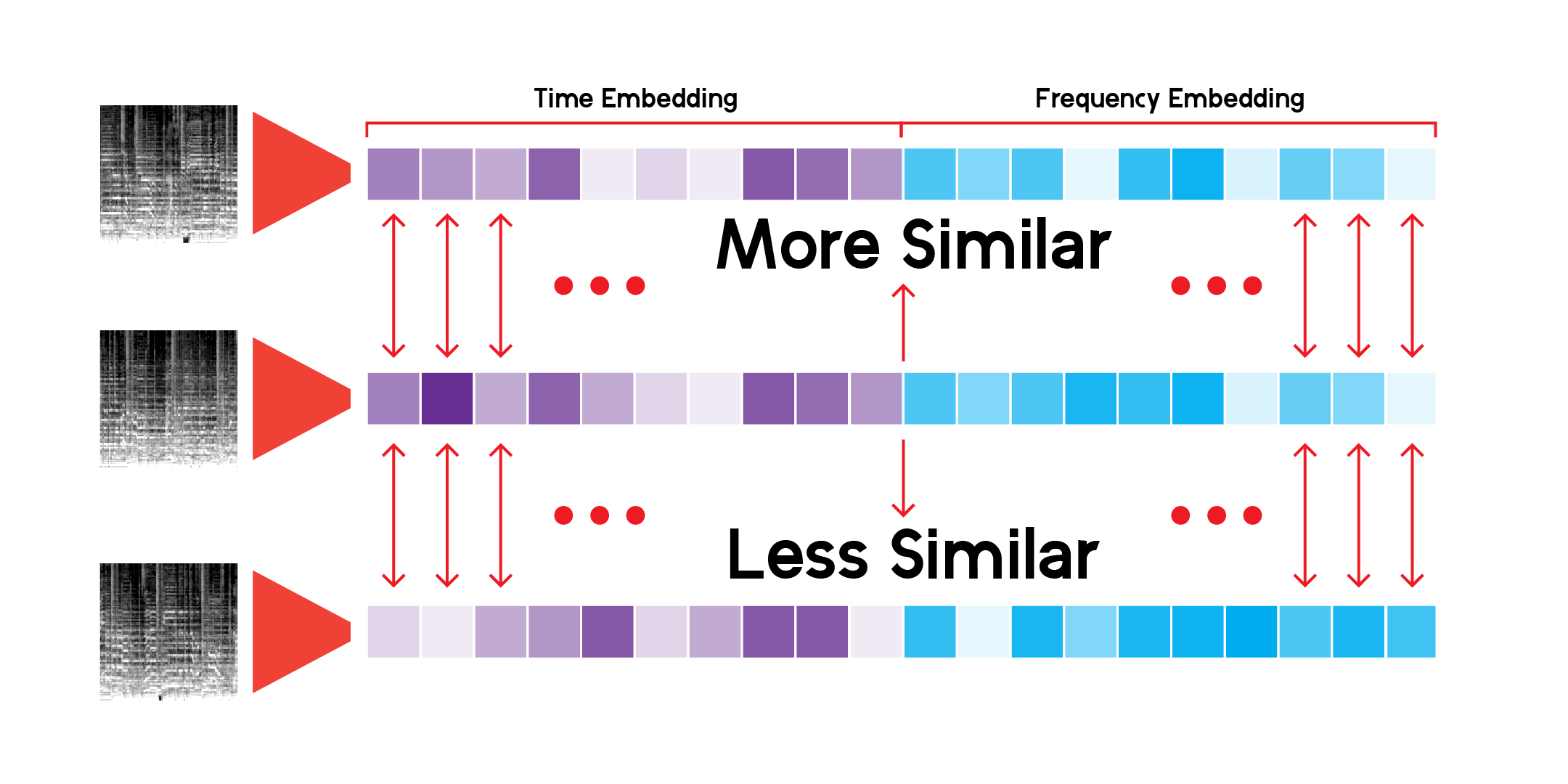
ฉันได้ค้นหาระบบการแนะนำนี้อย่างไม่สิ้นสุด และฉันพอใจที่โมเดลนี้สามารถเลือกความเชื่อมโยงที่น่าสนใจมากระหว่างเสียงดนตรีที่แตกต่างกันแต่ก็คล้ายกันได้ นี่คือข้อสรุปบางส่วนของฉัน:
สิ่งที่ฉันหมายถึงคือโมเดลกำลังให้คำแนะนำตามเนื้อหาเสียงในแต่ละเพลง แต่ไม่ได้ฟังเพลง โดยจะสร้างเมลสเปกโตรแกรมและทำการเปรียบเทียบทางคณิตศาสตร์
บางครั้งระบบจะให้คำแนะนำเพลงตามอายุ หากเพลงถูกบันทึกเมื่อนานมาแล้ว โมเดลจะเลือกความถี่เฉพาะของวัสดุหรืออุปกรณ์ในการบันทึกและแสดงผลลัพธ์
นอกจากนี้ตัวแบบยังสามารถรับเสียงหรือเครื่องดนตรีเฉพาะได้ดีมาก ด้วยเหตุนี้ หากเพลงมีการพูดคุยหรือพูด-ร้องเพลงเป็นจำนวนมาก อาจแนะนำเฉพาะแทร็กคำพูดเท่านั้น นอกจากนี้ หากเพลงมีความผิดเพี้ยนมาก อาจแนะนำเสียงฝนหรือเพลงนก
ตัวอย่างแทร็กบางรายการไม่สามารถใช้งานได้ใน Spotify API ดังที่ระบุไว้ใน EDA เริ่มต้นของฉัน ดังนั้นการสนับสนุนแบบจำลองจึงขาดหายไปและจะไม่เป็นคำแนะนำเมื่ออาจเหมาะสมที่สุดสำหรับแบบจำลอง ตัวอย่างเช่น ไม่มีเพลงของ James Brown, the Beatles หรือ Prince ต้องการข้อมูลเพิ่มเติม
ระบบใช้ตัวอย่างมากกว่า 278,000 รายการเพื่อให้คำแนะนำ และยังไม่เพียงพอ เมื่อดูการฉายภาพ UMAP ของทุกแทร็กแล้ว ข้อมูลมีความต่อเนื่องมาก แต่ก็มีช่องโหว่อยู่บ้าง ตามหลักการแล้ว ระบบสามารถใช้ข้อมูลจำนวนมากเพื่อดึงข้อมูลออกมาได้
สิ่งที่ทำให้ระบบ/บริการการแนะนำ เช่น Spotify ให้คำแนะนำได้ดีก็คือ การรวมเอาระบบการแนะนำประเภทต่างๆ และคุณสมบัติต่างๆ มากมายเช่นนี้เพื่อให้คำแนะนำ ตั้งแต่การติดตามสิ่งที่คุณฟังเป็นประจำ ไปจนถึงการใช้การกรองร่วมกันเพื่อค้นหาคำแนะนำตามการใช้งานที่คล้ายกันของผู้ใช้ Spotify สามารถสร้างการคาดการณ์ที่สมดุลมากขึ้นสำหรับสิ่งที่ใครบางคนจะชอบและฟัง ฉันพบว่าโมเดลนี้น่าสนใจสำหรับการคาดการณ์ แต่สามารถปรับปรุงได้โดยการเพิ่มคุณสมบัติเพิ่มเติม เช่น ประเภทที่คล้ายกัน ปีที่วางจำหน่าย และข้อมูลผู้ใช้ที่คล้ายกันเพื่อให้สามารถคาดการณ์ได้ดีขึ้น
โดยรวมแล้ว นอกเหนือจากการคาดเดาและให้คำแนะนำแล้ว ฉันรู้สึกว่าโมเดลนี้มีความสำคัญอย่างแท้จริงในการอธิบายความต่อเนื่องและสเปกตรัมของภาษาและเสียงดนตรี แนวเพลงคือป้ายกำกับที่ผู้คนพูดถึงศิลปินหรือเสียง แต่แนวเพลงผสมผสานและเสียงทุกเสียงมีอยู่ในพื้นที่ที่ต่อเนื่องกันนี้ อย่างน้อยก็ในทางคณิตศาสตร์
นอกจากนี้ดนตรีก็ไม่มีอุปสรรค ส่วนใหญ่แล้วเมื่อค้นหาเพลงในระบบการแนะนำ ผลลัพธ์จะมาจากยุคสมัยและที่ต่างกันทั้งหมด เนื่องจากไม่มีข้อมูลเมตาของเพลงเป็นอินพุตสำหรับโปรแกรมเข้ารหัสอัตโนมัติ ผลลัพธ์จึงขึ้นอยู่กับความคล้ายคลึงกันของเสียง และไม่มีอะไรเพิ่มเติม


