nlp lt
1.0.0
จุดประสงค์หลักของการวิจัยนี้คือเพื่อศึกษาและเรียนรู้หลักการประมวลผลภาษาธรรมชาติ (NLP) สำหรับภาษาลิทัวเนีย เป็นเรื่องน่าสนใจที่จะวิเคราะห์วิธี NLP แบบคลาสสิกและดูวิธีการทำงาน ดังนั้นในงานนี้ ฉันจึงใช้การจัดหมวดหมู่ข้อความ การแยกหัวข้อ ข้อความค้นหา และแนวคิดการจัดกลุ่ม รายละเอียดการดำเนินการและข้อมูลอื่นๆ ถูกเก็บไว้ที่ paper/paper.pdf
การวิเคราะห์ข้อมูลไม่สามารถสร้างขึ้นได้หากไม่มีข้อมูลที่เป็นข้อความ เนื่องจากงานของฉันเริ่มต้นจากการได้รับข้อมูลดิบจากเว็บไซต์ข่าวยอดนิยมส่วนใหญ่ www.delfi.lt ฉันตัดสินใจรวบรวมข้อมูลบทความจาก 5 หมวดหมู่ (อาชญากร [227 บทความ] เพลง [120 บทความ] ภาพยนตร์ [167 บทความ] กีฬา [136 บทความ] วิทยาศาสตร์ [204 บทความ])
ประสิทธิภาพการจำแนกประเภทวัดโดยใช้เมทริกซ์ความสับสน โดยที่แถวเป็นหมวดหมู่ที่แท้จริงและหมวดหมู่ที่คาดการณ์ของคอลัมน์ นอกจากนี้ วิธีการดังกล่าวยังช่วยให้เรียกคืนได้มากกว่า 90% และมีความแม่นยำถึง 90% 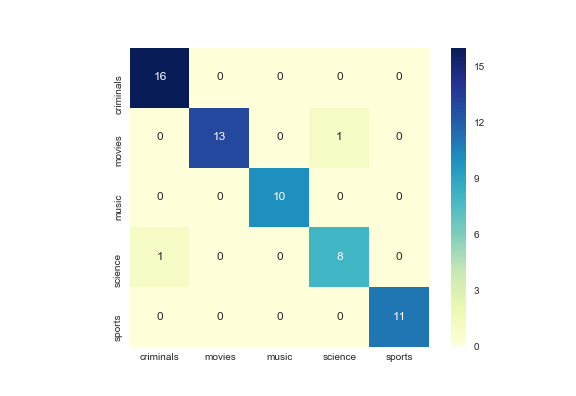
รูปแสดงส่วนประกอบ 6 ชิ้นพร้อมโทเค็น 10 ชิ้นสำหรับแต่ละส่วนประกอบ จากผลลัพธ์เหล่านี้ เราสามารถตรวจจับคำที่สำคัญที่สุดและเดาหัวข้อสำหรับแต่ละองค์ประกอบหลักได้อย่างสังหรณ์ใจ ตัวอย่างเช่น 4 องค์ประกอบหลักเก็บข้อมูลเกี่ยวกับกีฬาและดนตรี ในขณะที่ 6 องค์ประกอบหลักเก็บข้อมูลเกี่ยวกับอาชญากร
ผลลัพธ์หลักแสดงไว้ด้านล่าง: 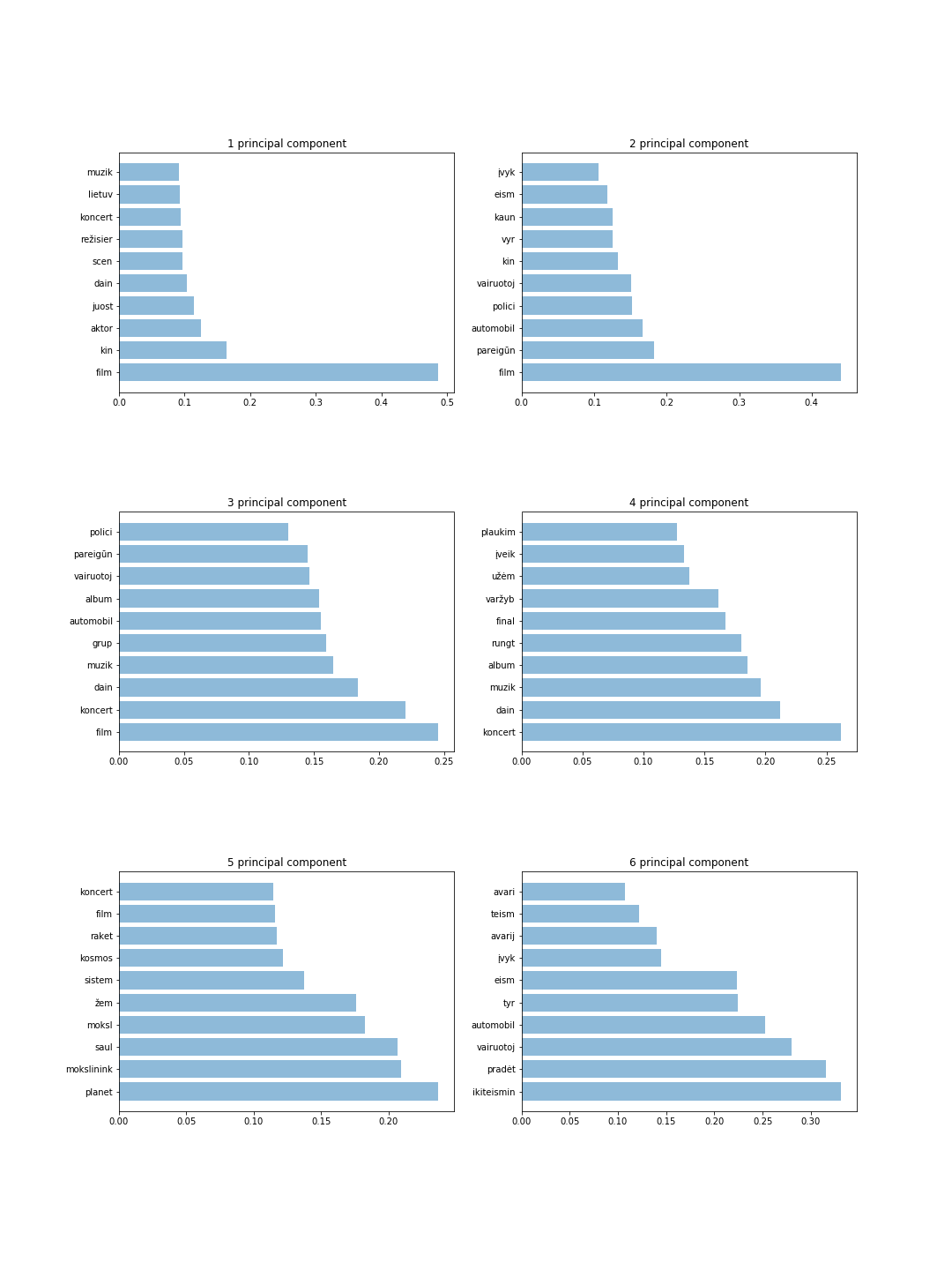
การค้นหาอ้างอิงจากบทความ http://webhome.cs.uvic.ca/~thomo/svd.pdf โดยที่ lsa ถูกนำมาใช้เพื่อค้นหาเอกสารที่เกี่ยวข้อง ซึ่งไม่เพียงแต่ใช้ความคล้ายคลึงกันของข้อความค้นหาเท่านั้น แต่ยังมีความสัมพันธ์ที่ลึกซึ้งระหว่างเอกสารอีกด้วย 
Query = "švietim apdovanojam"
ผลลัพธ์:
อยู่ระหว่างดำเนินการ


