system design primer
1.0.0
อังกฤษ ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ εллηνικά ∙ עברית ∙ Italiano ∙ 한어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Viết ∙ Français | เพิ่มคำแปล
ช่วยแปลคู่มือนี้!
เรียนรู้วิธีการออกแบบระบบขนาดใหญ่
เตรียมการสัมภาษณ์การออกแบบระบบ
การเรียนรู้วิธีออกแบบระบบที่ปรับขนาดได้จะช่วยให้คุณเป็นวิศวกรที่ดีขึ้นได้
การออกแบบระบบเป็นหัวข้อกว้างๆ มี ทรัพยากรจำนวนมากมายกระจายอยู่ทั่วเว็บ เกี่ยวกับหลักการออกแบบระบบ
Repo นี้เป็น คอลเลกชันทรัพยากรที่จัดระเบียบ เพื่อช่วยให้คุณเรียนรู้วิธีสร้างระบบในวงกว้าง
นี่เป็นโครงการโอเพ่นซอร์สที่ได้รับการอัปเดตอย่างต่อเนื่อง
ยินดีบริจาค!
นอกเหนือจากการสัมภาษณ์การเขียนโค้ดแล้ว การออกแบบระบบยังเป็น องค์ประกอบที่จำเป็น ของ กระบวนการสัมภาษณ์ทางเทคนิค ของบริษัทเทคโนโลยีหลายแห่ง
ฝึกฝนคำถามสัมภาษณ์การออกแบบระบบทั่วไป และ เปรียบเทียบ ผลลัพธ์ของคุณกับ โซลูชันตัวอย่าง เช่น การอภิปราย โค้ด และไดอะแกรม
หัวข้อเพิ่มเติมสำหรับการเตรียมตัวสัมภาษณ์:
ชุดแฟลชการ์ด Anki ที่ให้มาใช้การเว้นระยะห่างเพื่อช่วยให้คุณคงแนวคิดการออกแบบระบบที่สำคัญไว้
เหมาะสำหรับการใช้งานในขณะเดินทาง
กำลังมองหาแหล่งข้อมูลที่จะช่วยคุณเตรียมตัวสำหรับ การสัมภาษณ์เรื่องการเขียนโค้ด ใช่ไหม
ลองดู Interactive Coding Challenges ของ repo ในเครือ ซึ่งมีสำรับ Anki เพิ่มเติม:
เรียนรู้จากชุมชน
อย่าลังเลที่จะส่งคำขอดึงเพื่อช่วย:
เนื้อหาที่ต้องการการปรับปรุงอยู่ระหว่างการพัฒนา
ทบทวนแนวทางการมีส่วนร่วม
สรุปหัวข้อการออกแบบระบบต่างๆ รวมถึงข้อดีและข้อเสีย ทุกสิ่งทุกอย่างคือการแลกเปลี่ยน
แต่ละส่วนมีลิงก์ไปยังแหล่งข้อมูลเชิงลึกเพิ่มเติม
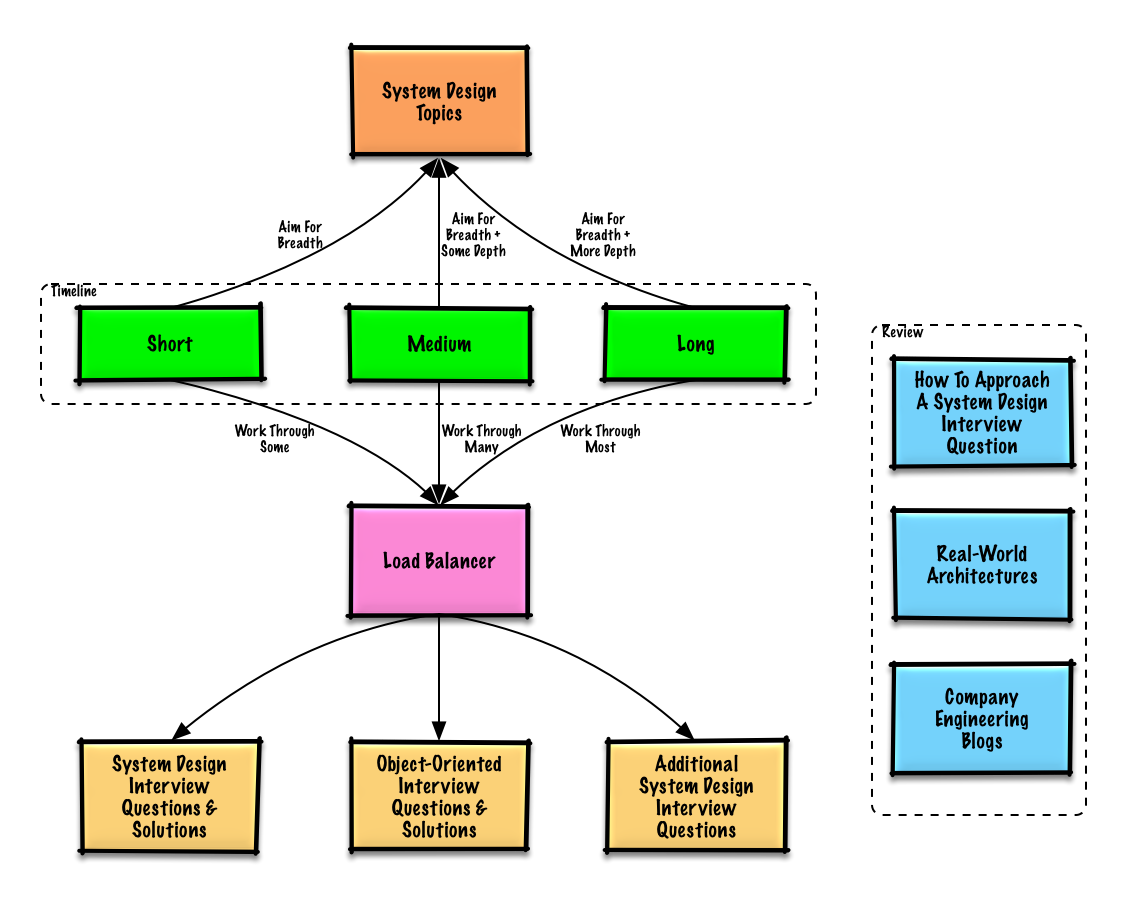
หัวข้อที่แนะนำเพื่อทบทวนตามระยะเวลาการสัมภาษณ์ของคุณ (สั้น กลาง ยาว)
ถาม: ในการสัมภาษณ์ ฉันจำเป็นต้องรู้ทุกอย่างที่นี่หรือไม่?
ตอบ: ไม่ คุณไม่จำเป็นต้องรู้ทุกอย่างที่นี่เพื่อเตรียมตัวสำหรับการสัมภาษณ์
สิ่งที่คุณจะถูกถามในการสัมภาษณ์ขึ้นอยู่กับตัวแปรต่างๆ เช่น:
โดยทั่วไปแล้วผู้สมัครที่มีประสบการณ์มากกว่าจะมีความรู้เพิ่มเติมเกี่ยวกับการออกแบบระบบ สถาปนิกหรือหัวหน้าทีมอาจถูกคาดหวังให้รู้จักมากกว่าผู้ร่วมให้ข้อมูลรายบุคคล บริษัทเทคโนโลยีชั้นนำมีแนวโน้มที่จะมีรอบสัมภาษณ์การออกแบบอย่างน้อยหนึ่งรอบ
เริ่มต้นในวงกว้างและเจาะลึกลงไปในบางพื้นที่ การรู้เล็กน้อยเกี่ยวกับหัวข้อการออกแบบระบบคีย์ต่างๆ จะช่วยได้มาก ปรับคำแนะนำต่อไปนี้ตามไทม์ไลน์ ประสบการณ์ ตำแหน่งที่คุณกำลังสัมภาษณ์ และบริษัทที่คุณกำลังสัมภาษณ์ด้วย
| สั้น | ปานกลาง | ยาว | |
|---|---|---|---|
| อ่านหัวข้อการออกแบบระบบเพื่อทำความเข้าใจวิธีการทำงานของระบบอย่างกว้างๆ | - | - | - |
| อ่านบทความบางส่วนในบล็อกวิศวกรรมของบริษัทสำหรับบริษัทที่คุณกำลังสัมภาษณ์ด้วย | - | - | - |
| อ่านสถาปัตยกรรมโลกแห่งความเป็นจริงบางส่วน | - | - | - |
| ทบทวนวิธีตอบคำถามสัมภาษณ์การออกแบบระบบ | - | - | - |
| ทำงานผ่านคำถามสัมภาษณ์การออกแบบระบบพร้อมวิธีแก้ปัญหา | บาง | มากมาย | ที่สุด |
| ทำงานผ่านคำถามสัมภาษณ์การออกแบบเชิงวัตถุพร้อมวิธีแก้ปัญหา | บาง | มากมาย | ที่สุด |
| ทบทวนคำถามสัมภาษณ์การออกแบบระบบเพิ่มเติม | บาง | มากมาย | ที่สุด |
วิธีจัดการกับคำถามสัมภาษณ์การออกแบบระบบ
การสัมภาษณ์การออกแบบระบบเป็นการ สนทนาปลายเปิด คุณถูกคาดหวังให้เป็นผู้นำ
คุณสามารถใช้ขั้นตอนต่อไปนี้เพื่อเป็นแนวทางในการอภิปราย เพื่อช่วยทำให้กระบวนการนี้มีความเข้มแข็ง ให้ดำเนินการผ่านส่วนคำถามสัมภาษณ์การออกแบบระบบพร้อมโซลูชันโดยใช้ขั้นตอนต่อไปนี้
รวบรวมข้อกำหนดและกำหนดขอบเขตของปัญหา ถามคำถามเพื่อชี้แจงกรณีการใช้งานและข้อจำกัด อภิปรายการสมมติฐาน
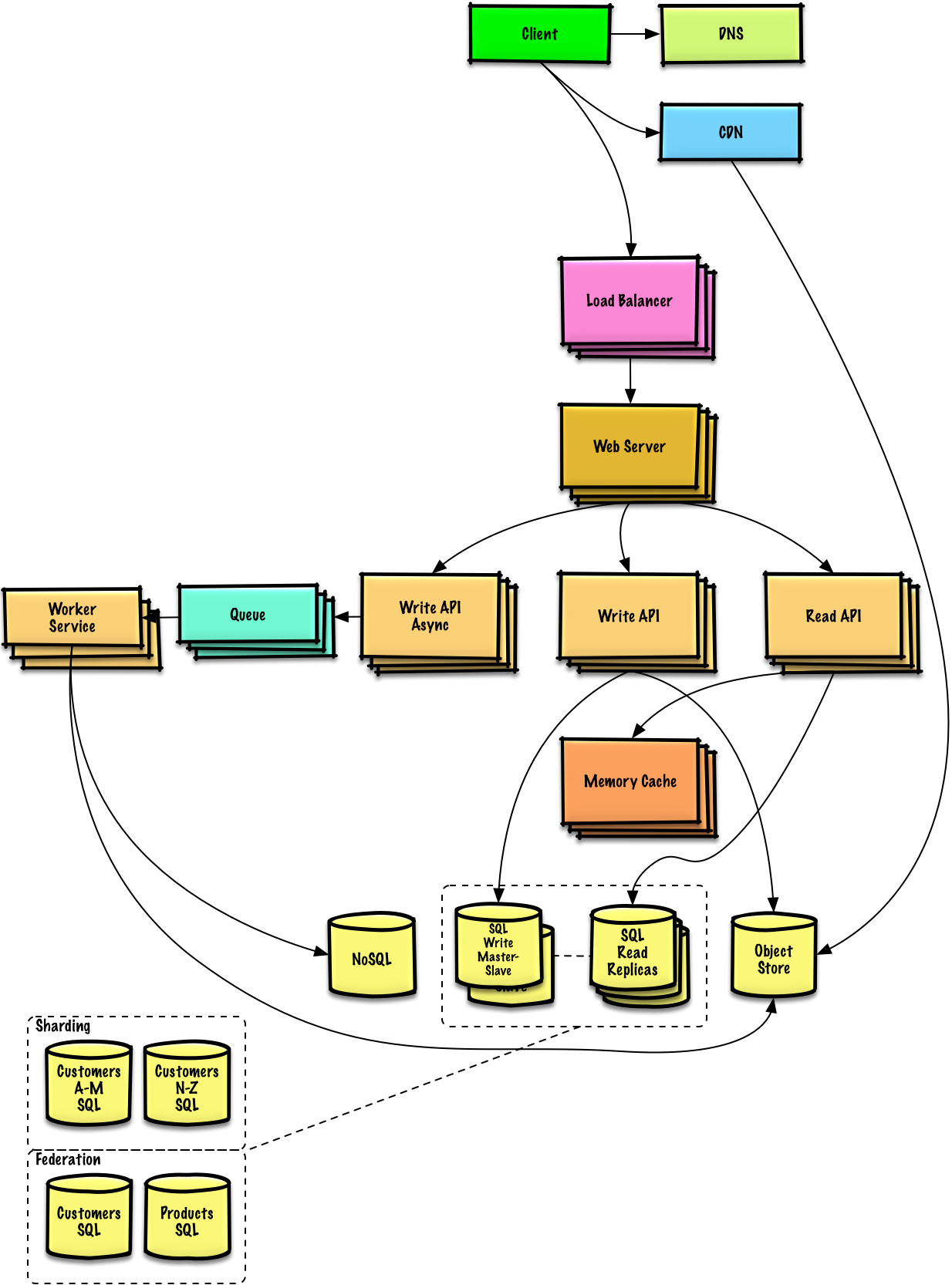
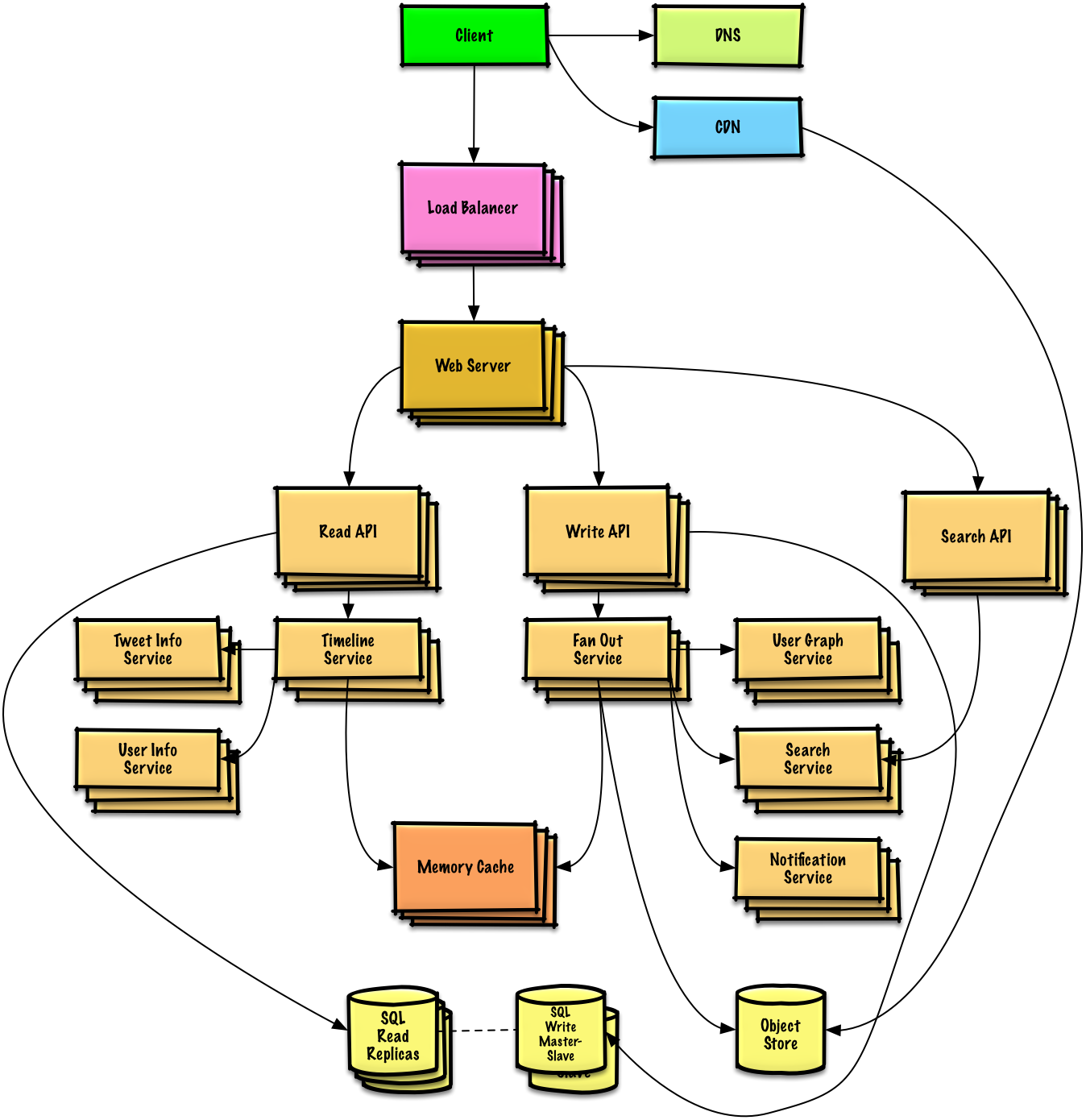
สรุปการออกแบบระดับสูงพร้อมส่วนประกอบที่สำคัญทั้งหมด
เจาะลึกรายละเอียดสำหรับแต่ละองค์ประกอบหลัก ตัวอย่างเช่น หากคุณถูกขอให้ออกแบบบริการย่อ URL ให้พูดคุยเรื่อง:
ระบุและแก้ไขจุดติดขัดตามข้อจำกัด ตัวอย่างเช่น คุณต้องการสิ่งต่อไปนี้เพื่อแก้ไขปัญหาความสามารถในการปรับขนาดหรือไม่
หารือเกี่ยวกับแนวทางแก้ไขที่เป็นไปได้และข้อดีข้อเสีย ทุกสิ่งทุกอย่างคือการแลกเปลี่ยน แก้ไขปัญหาคอขวดโดยใช้หลักการออกแบบระบบที่ปรับขนาดได้
คุณอาจถูกขอให้ประมาณการด้วยมือ โปรดดูภาคผนวกสำหรับแหล่งข้อมูลต่อไปนี้:
ลองดูลิงก์ต่อไปนี้เพื่อทำความเข้าใจสิ่งที่คาดหวังให้ดียิ่งขึ้น:
คำถามสัมภาษณ์การออกแบบระบบทั่วไปพร้อมตัวอย่างการสนทนา โค้ด และไดอะแกรม
โซลูชันที่เชื่อมโยงกับเนื้อหาใน
solutions/โฟลเดอร์
| คำถาม | |
|---|---|
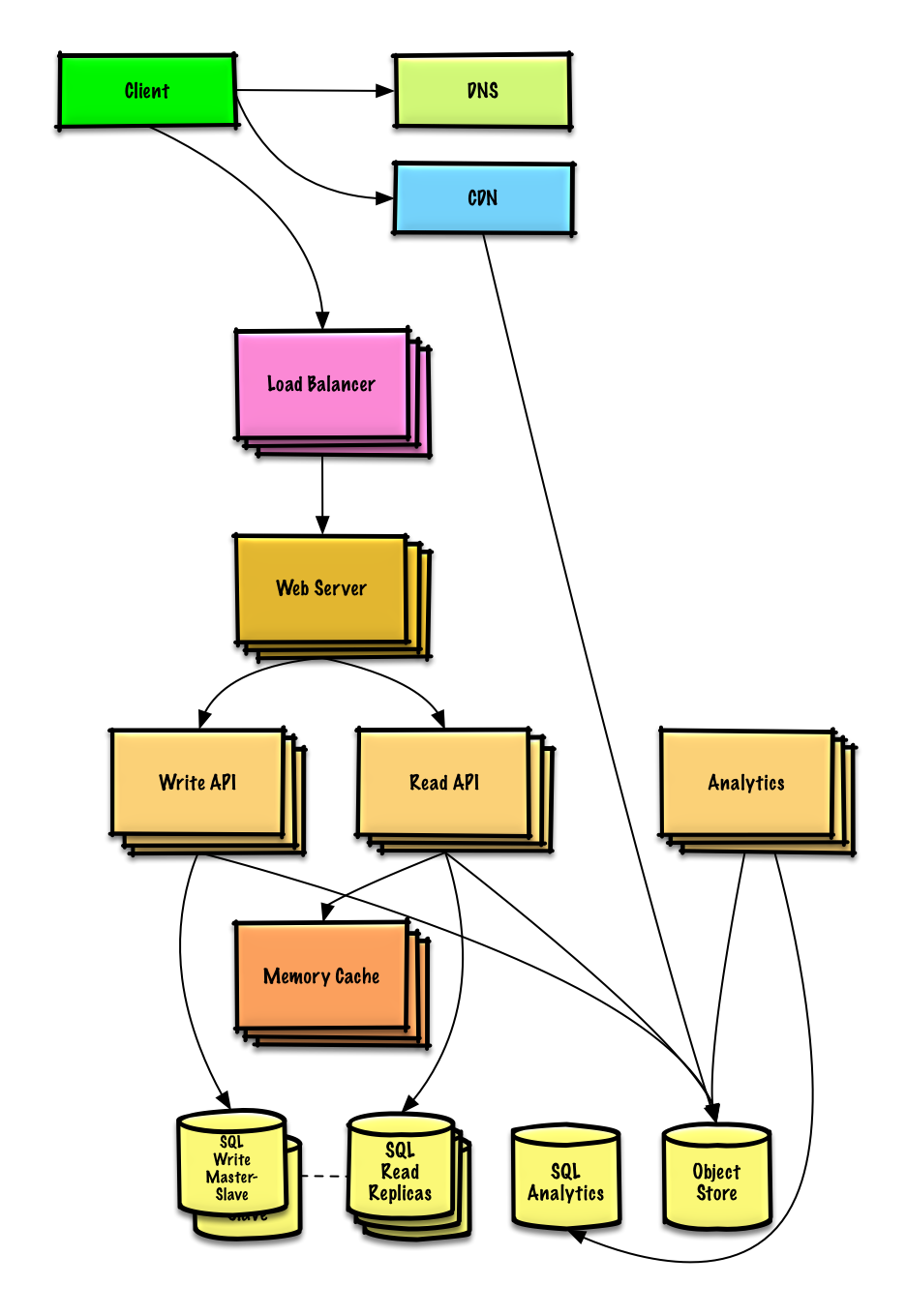
| ออกแบบ Pastebin.com (หรือ Bit.ly) | สารละลาย |
| ออกแบบไทม์ไลน์และการค้นหาของ Twitter (หรือฟีดและการค้นหาของ Facebook) | สารละลาย |
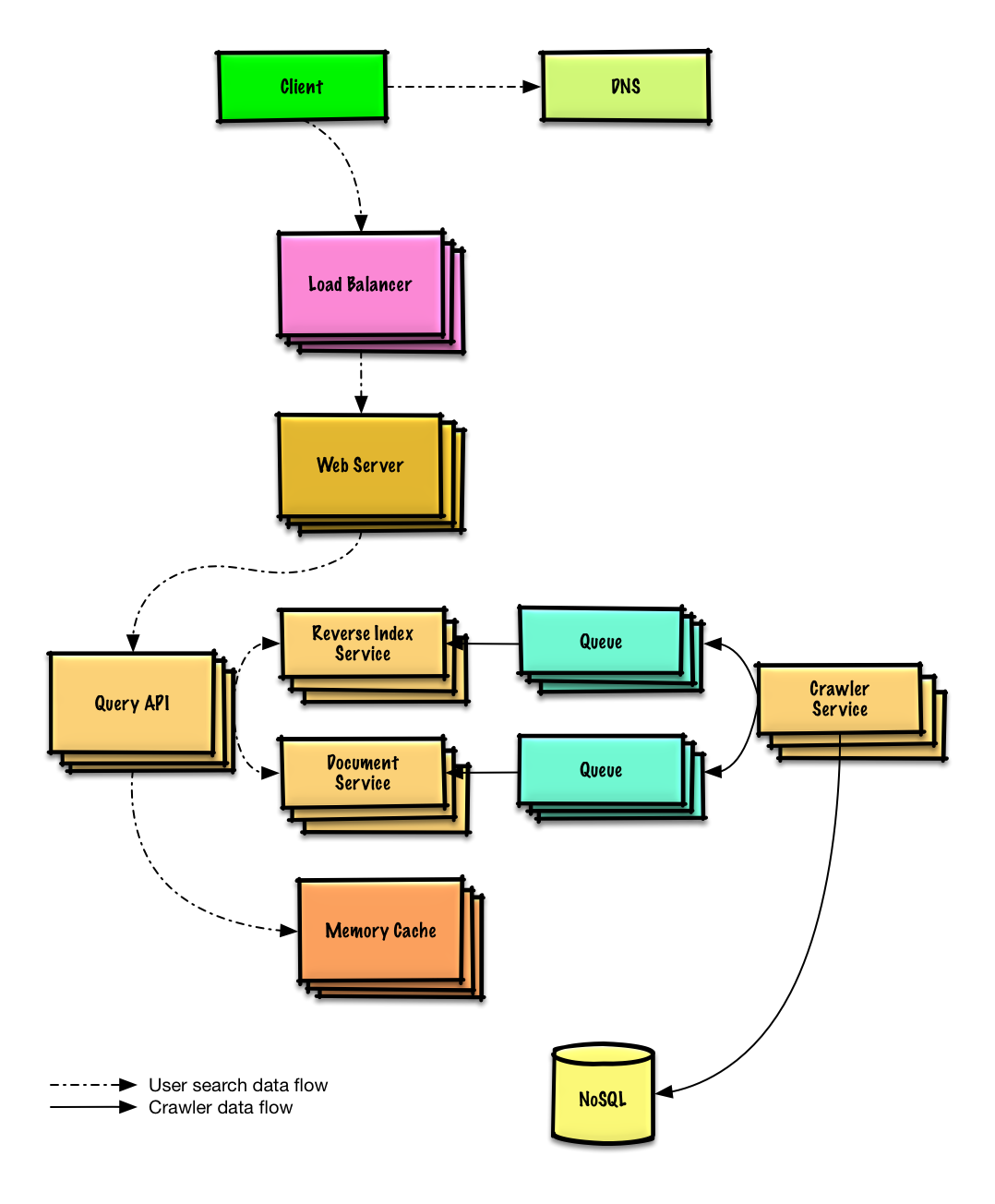
| ออกแบบโปรแกรมรวบรวมข้อมูลเว็บ | สารละลาย |
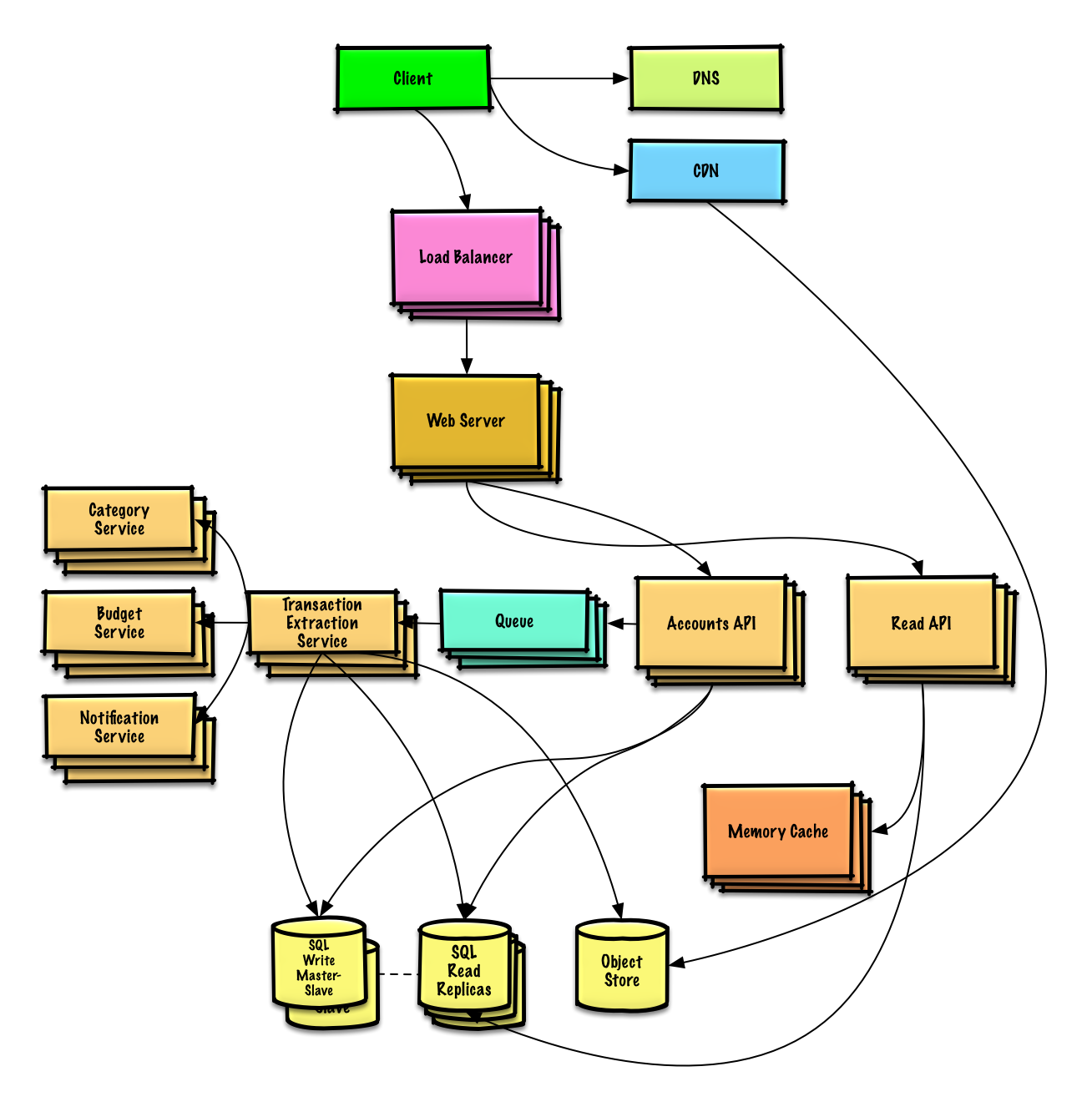
| ดีไซน์ มิ้นท์.คอม | สารละลาย |
| ออกแบบโครงสร้างข้อมูลสำหรับเครือข่ายโซเชียล | สารละลาย |
| ออกแบบที่เก็บคีย์-ค่าสำหรับเครื่องมือค้นหา | สารละลาย |
| ออกแบบฟีเจอร์การจัดอันดับยอดขายของ Amazon ตามหมวดหมู่ | สารละลาย |
| ออกแบบระบบที่ปรับขนาดตามผู้ใช้หลายล้านคนบน AWS | สารละลาย |
| เพิ่มคำถามการออกแบบระบบ | มีส่วนช่วย |
ดูแบบฝึกหัดและวิธีแก้ปัญหา
ดูแบบฝึกหัดและวิธีแก้ปัญหา
ดูแบบฝึกหัดและวิธีแก้ปัญหา
ดูแบบฝึกหัดและวิธีแก้ปัญหา
ดูแบบฝึกหัดและวิธีแก้ปัญหา
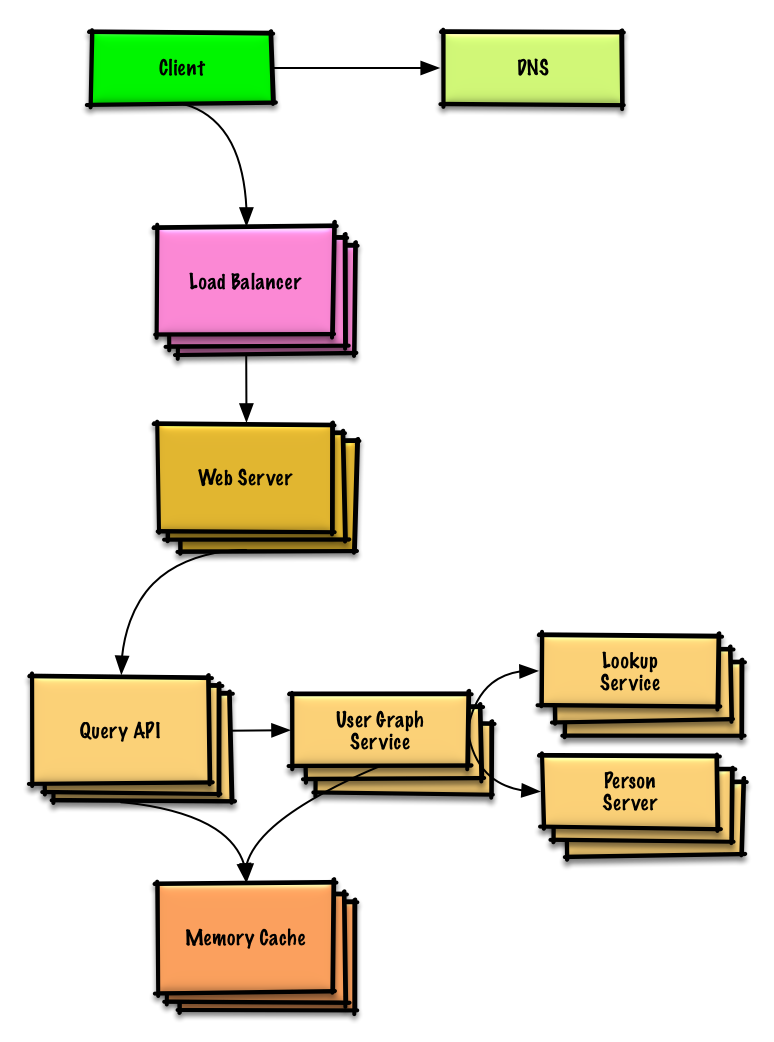
ดูแบบฝึกหัดและวิธีแก้ปัญหา
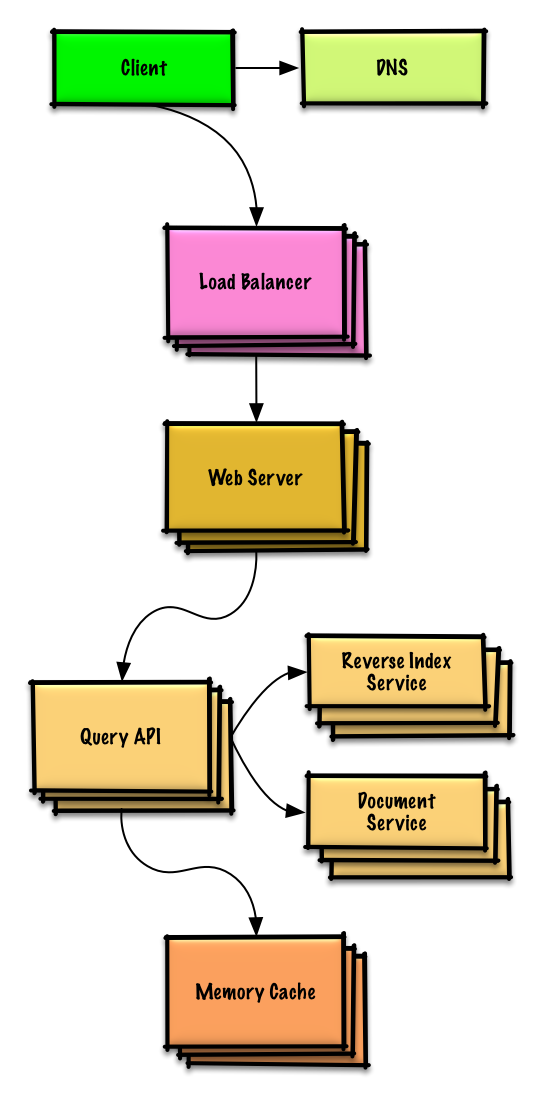
ดูแบบฝึกหัดและวิธีแก้ปัญหา
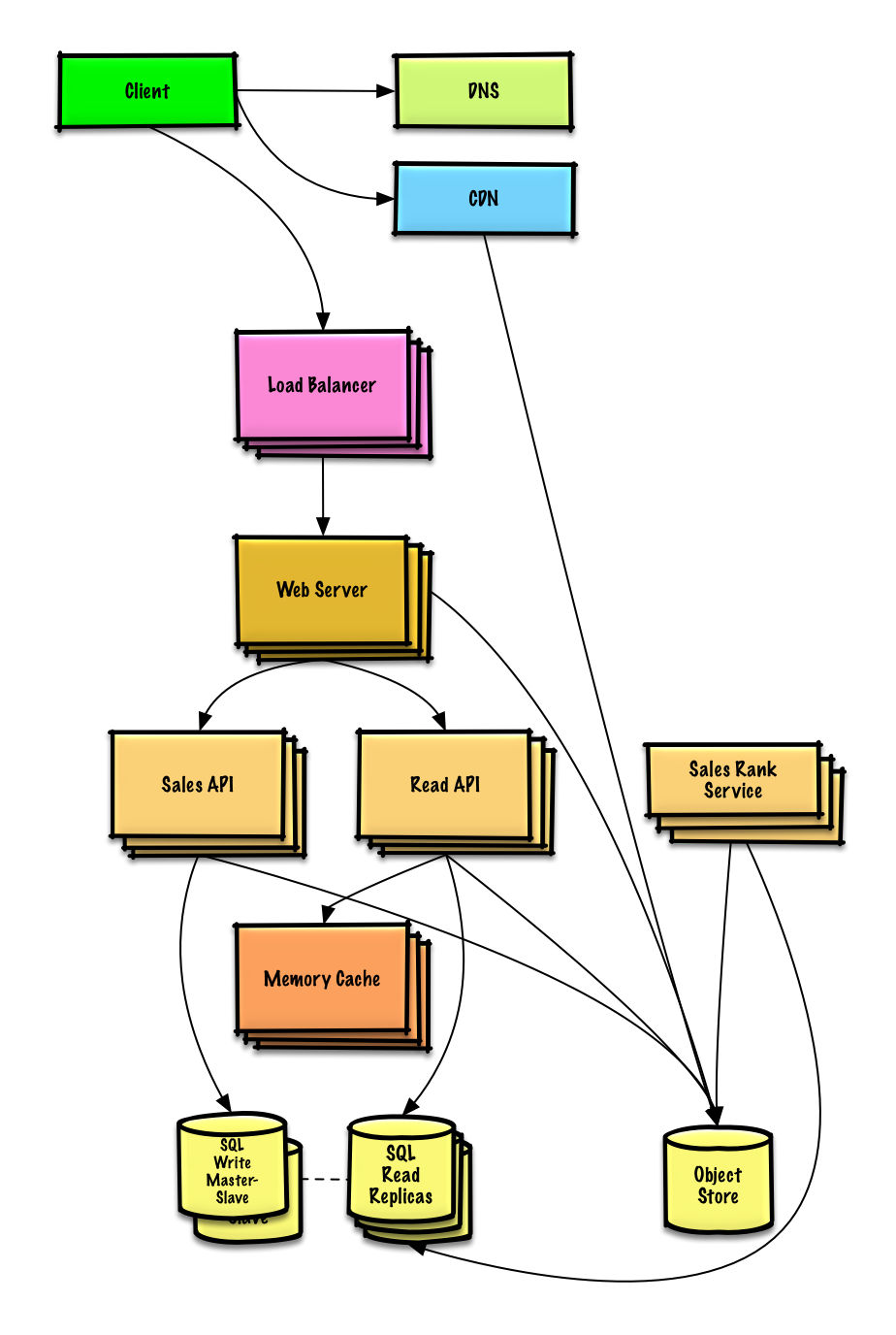
ดูแบบฝึกหัดและวิธีแก้ปัญหา
คำถามสัมภาษณ์งานออกแบบเชิงวัตถุทั่วไปพร้อมตัวอย่างการสนทนา โค้ด และไดอะแกรม
โซลูชันที่เชื่อมโยงกับเนื้อหาใน
solutions/โฟลเดอร์
หมายเหตุ: ส่วนนี้อยู่ระหว่างการพัฒนา
| คำถาม | |
|---|---|
| ออกแบบแผนที่แฮช | สารละลาย |
| ออกแบบแคชที่ใช้ล่าสุดน้อยที่สุด | สารละลาย |
| ออกแบบศูนย์บริการทางโทรศัพท์ | สารละลาย |
| ออกแบบสำรับไพ่ | สารละลาย |
| ออกแบบลานจอดรถ | สารละลาย |
| ออกแบบเซิร์ฟเวอร์แชท | สารละลาย |
| ออกแบบอาร์เรย์แบบวงกลม | มีส่วนช่วย |
| เพิ่มคำถามการออกแบบเชิงวัตถุ | มีส่วนช่วย |
ยังใหม่กับการออกแบบระบบใช่ไหม?
ขั้นแรก คุณจะต้องมีความเข้าใจพื้นฐานเกี่ยวกับหลักการทั่วไป เรียนรู้ว่าหลักการเหล่านี้คืออะไร วิธีนำไปใช้ และข้อดีข้อเสีย
การบรรยายเรื่อง Scalability ที่ Harvard
ความสามารถในการขยายขนาด
ต่อไป เราจะดูการแลกเปลี่ยนในระดับสูง:
โปรดทราบว่า ทุกอย่างเป็นการแลกเปลี่ยน
จากนั้นเราจะเจาะลึกหัวข้อที่เฉพาะเจาะจงมากขึ้น เช่น DNS, CDN และโหลดบาลานเซอร์
บริการสามารถ ปรับขนาดได้ หากส่งผลให้ ประสิทธิภาพ เพิ่มขึ้นในลักษณะที่เป็นสัดส่วนกับทรัพยากรที่เพิ่ม โดยทั่วไปแล้ว ประสิทธิภาพที่เพิ่มขึ้นหมายถึงการให้บริการหน่วยงานมากขึ้น แต่ก็สามารถจัดการหน่วยงานที่ใหญ่ขึ้นได้เช่นกัน เช่น เมื่อชุดข้อมูลเติบโตขึ้น 1
อีกวิธีในการดูประสิทธิภาพเทียบกับความสามารถในการขยาย:
เวลาแฝง คือเวลาที่จะดำเนินการบางอย่างหรือสร้างผลลัพธ์บางอย่าง
ปริมาณงาน คือจำนวนการกระทำหรือผลลัพธ์ดังกล่าวต่อหน่วยเวลา
โดยทั่วไป คุณควรมุ่งเป้าไปที่ ปริมาณงานสูงสุด ด้วย เวลาแฝงที่ยอมรับได้
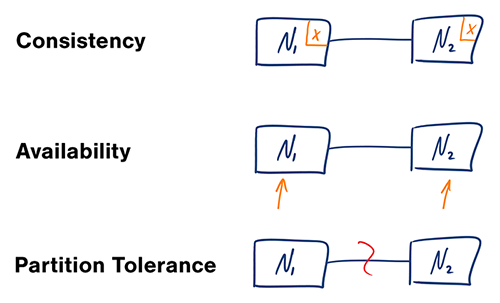
ที่มา: ทบทวนทฤษฎีบท CAP
ในระบบคอมพิวเตอร์แบบกระจาย คุณสามารถสนับสนุนการรับประกันสองรายการต่อไปนี้เท่านั้น:
เครือข่ายไม่น่าเชื่อถือ ดังนั้นคุณจะต้องรองรับความทนทานต่อพาร์ติชัน คุณจะต้องสร้างความแตกต่างระหว่างความสม่ำเสมอและความพร้อมใช้งานของซอฟต์แวร์
การรอการตอบสนองจากโหนดที่แบ่งพาร์ติชันอาจทำให้เกิดข้อผิดพลาดการหมดเวลา CP เป็นตัวเลือกที่ดีหากความต้องการทางธุรกิจของคุณจำเป็นต้องมีการอ่านและเขียนแบบอะตอมมิก
การตอบกลับจะส่งคืนข้อมูลในเวอร์ชันที่พร้อมใช้งานมากที่สุดบนโหนดใดๆ ซึ่งอาจไม่ใช่เวอร์ชันล่าสุด การเขียนอาจใช้เวลาสักครู่เพื่อเผยแพร่เมื่อพาร์ติชันได้รับการแก้ไข
AP เป็นตัวเลือกที่ดีหากธุรกิจจำเป็นต้องให้เกิดความสอดคล้องกันในที่สุด หรือเมื่อระบบจำเป็นต้องทำงานต่อไปแม้จะมีข้อผิดพลาดจากภายนอกก็ตาม
ด้วยสำเนาข้อมูลเดียวกันหลายชุด เราต้องเผชิญกับทางเลือกในการซิงโครไนซ์ข้อมูลเหล่านั้น เพื่อให้ไคลเอนต์มีมุมมองข้อมูลที่สอดคล้องกัน จำคำจำกัดความของความสอดคล้องจากทฤษฎีบท CAP - การอ่านทุกครั้งจะได้รับการเขียนล่าสุดหรือข้อผิดพลาด
หลังจากเขียนแล้ว อ่านแล้วอาจจะเห็นหรือไม่เห็นก็ได้ มีการใช้แนวทางความพยายามอย่างดีที่สุด
วิธีการนี้พบเห็นได้ในระบบเช่น memcached ความสม่ำเสมอที่อ่อนแอทำงานได้ดีในกรณีการใช้งานแบบเรียลไทม์ เช่น VoIP วิดีโอแชท และเกมหลายผู้เล่นแบบเรียลไทม์ ตัวอย่างเช่น หากคุณใช้สายโทรศัพท์และสูญเสียการรับสัญญาณไปสองสามวินาที เมื่อคุณเชื่อมต่อได้อีกครั้ง คุณจะไม่ได้ยินสิ่งที่พูดระหว่างที่การเชื่อมต่อขาดหาย
หลังจากเขียนแล้ว การอ่านจะเห็นในที่สุด (โดยทั่วไปภายในมิลลิวินาที) ข้อมูลถูกจำลองแบบอะซิงโครนัส
วิธีการนี้พบเห็นได้ในระบบเช่น DNS และอีเมล ความสอดคล้องในที่สุดจะทำงานได้ดีในระบบที่มีความพร้อมใช้งานสูง
หลังจากเขียนแล้วผู้อ่านจะเห็นมัน ข้อมูลถูกจำลองแบบพร้อมกัน
วิธีการนี้มีให้เห็นในระบบไฟล์และ RDBMSes ความสม่ำเสมอที่แข็งแกร่งทำงานได้ดีในระบบที่ต้องการธุรกรรม
มีรูปแบบเสริมสองรูปแบบเพื่อรองรับความพร้อมใช้งานสูง: การแทนที่เมื่อเกิดข้อผิดพลาด และ การจำลองแบบ
เมื่อใช้ระบบเฟลโอเวอร์แบบแอคทีฟ-พาสซีฟ ฮาร์ทบีทจะถูกส่งระหว่างเซิร์ฟเวอร์แอคทีฟและพาสซีฟในโหมดสแตนด์บาย หากการเต้นของหัวใจถูกขัดจังหวะ เซิร์ฟเวอร์แบบพาสซีฟจะเข้าควบคุมที่อยู่ IP ที่ใช้งานอยู่และกลับมาให้บริการต่อ
ระยะเวลาของการหยุดทำงานจะขึ้นอยู่กับว่าเซิร์ฟเวอร์แบบพาสซีฟกำลังทำงานในโหมดสแตนด์บาย 'ร้อน' อยู่แล้ว หรือจำเป็นต้องเริ่มต้นระบบจากการสแตนด์บาย 'เย็น' หรือไม่ เฉพาะเซิร์ฟเวอร์ที่ใช้งานอยู่เท่านั้นที่จัดการการรับส่งข้อมูล
การเฟลโอเวอร์แบบแอ็คทีฟ-พาสซีฟยังสามารถเรียกว่าเฟลโอเวอร์แบบมาสเตอร์-สเลฟได้ด้วย
ในโหมดแอคทีฟแอคทีฟ เซิร์ฟเวอร์ทั้งสองกำลังจัดการทราฟฟิก โดยกระจายโหลดระหว่างเซิร์ฟเวอร์ทั้งสอง
หากเซิร์ฟเวอร์เป็นแบบสาธารณะ DNS จะต้องทราบเกี่ยวกับ IP สาธารณะของทั้งสองเซิร์ฟเวอร์ หากเซิร์ฟเวอร์หันหน้าเข้าหากันภายใน ตรรกะของแอปพลิเคชันจะต้องทราบเกี่ยวกับเซิร์ฟเวอร์ทั้งสองเครื่อง
Active-active Failover ยังเรียกอีกอย่างว่า Failover หลัก-หลัก
หัวข้อนี้จะกล่าวถึงเพิ่มเติมในส่วนฐานข้อมูล:
ความพร้อมใช้งานมักจะวัดจากเวลาทำงาน (หรือเวลาหยุดทำงาน) เป็นเปอร์เซ็นต์ของเวลาที่พร้อมให้บริการ โดยทั่วไปความพร้อมใช้งานจะวัดเป็นจำนวน 9 วินาที โดยบริการที่มีความพร้อมใช้งาน 99.99% จะถูกอธิบายว่ามี 9 วินาทีสี่ครั้ง
| ระยะเวลา | การหยุดทำงานที่ยอมรับได้ |
|---|---|
| การหยุดทำงานต่อปี | 8 ชม. 45 นาที 57 วินาที |
| การหยุดทำงานต่อเดือน | 43นาที 49.7วิ |
| การหยุดทำงานต่อสัปดาห์ | 10 นาที 4.8 วินาที |
| เวลาหยุดทำงานต่อวัน | 1 นาที 26.4 วินาที |
| ระยะเวลา | การหยุดทำงานที่ยอมรับได้ |
|---|---|
| การหยุดทำงานต่อปี | 52 นาที 35.7 วินาที |
| การหยุดทำงานต่อเดือน | 4น. 23ส |
| การหยุดทำงานต่อสัปดาห์ | 1 นาที 5 วินาที |
| เวลาหยุดทำงานต่อวัน | 8.6วิ |
หากบริการประกอบด้วยส่วนประกอบหลายชิ้นที่มีแนวโน้มที่จะเกิดความล้มเหลว ความพร้อมใช้งานโดยรวมของบริการจะขึ้นอยู่กับว่าส่วนประกอบต่างๆ เรียงตามลำดับหรือขนานกัน
ความพร้อมใช้งานโดยรวมจะลดลงเมื่อองค์ประกอบสองรายการที่มีความพร้อมใช้งาน < 100% เรียงตามลำดับ:
Availability (Total) = Availability (Foo) * Availability (Bar)
หากทั้ง Foo และ Bar ต่างก็มีความพร้อมใช้งาน 99.9% ความพร้อมใช้งานทั้งหมดตามลำดับจะเป็น 99.8%
ความพร้อมใช้งานโดยรวมจะเพิ่มขึ้นเมื่อองค์ประกอบสองรายการที่มีความพร้อมใช้งาน < 100% ขนานกัน:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
หากทั้ง Foo และ Bar ต่างก็มีความพร้อมใช้งาน 99.9% ความพร้อมใช้งานทั้งหมดพร้อมกันจะเป็น 99.9999%
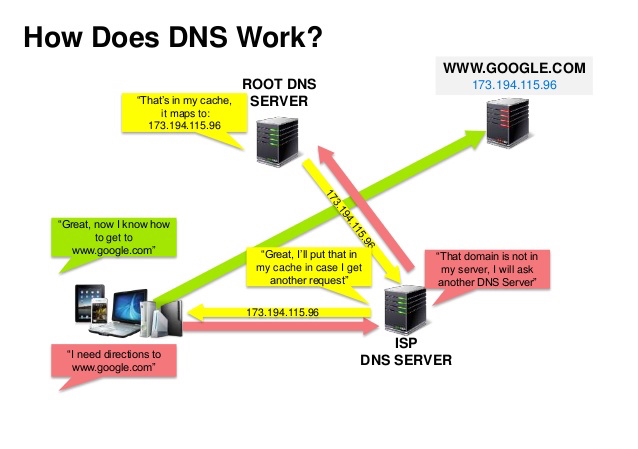
ที่มา: การนำเสนอความปลอดภัยของ DNS
ระบบชื่อโดเมน (DNS) แปลชื่อโดเมน เช่น www.example.com เป็นที่อยู่ IP
DNS เป็นแบบลำดับชั้น โดยมีเซิร์ฟเวอร์ที่เชื่อถือได้สองสามตัวที่ระดับบนสุด เราเตอร์หรือ ISP ของคุณให้ข้อมูลเกี่ยวกับเซิร์ฟเวอร์ DNS ที่จะติดต่อเมื่อทำการค้นหา การแมปแคชเซิร์ฟเวอร์ DNS ระดับล่าง ซึ่งอาจกลายเป็นข้อมูลเก่าเนื่องจากความล่าช้าในการเผยแพร่ DNS ผลลัพธ์ DNS ยังสามารถแคชโดยเบราว์เซอร์หรือระบบปฏิบัติการของคุณในช่วงระยะเวลาหนึ่ง โดยพิจารณาจาก time to live (TTL)
CNAME (example.com ไปยัง www.example.com) หรือไปยังระเบียน Aบริการต่างๆ เช่น CloudFlare และ Route 53 ให้บริการ DNS ที่มีการจัดการ บริการ DNS บางอย่างสามารถกำหนดเส้นทางการรับส่งข้อมูลได้หลายวิธี:
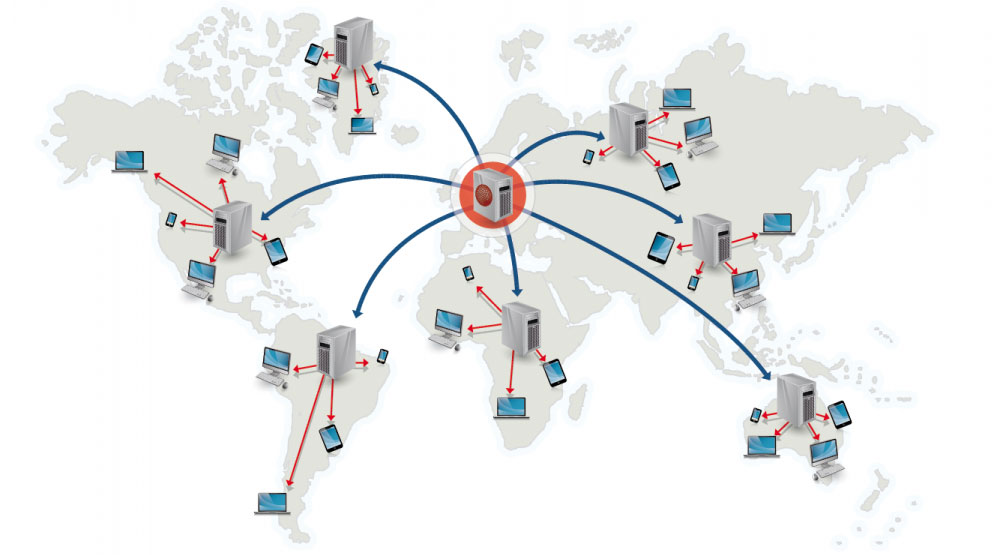
ที่มา: เหตุใดจึงต้องใช้ CDN
เครือข่ายการจัดส่งเนื้อหา (CDN) คือเครือข่ายพร็อกซีเซิร์ฟเวอร์ที่กระจายทั่วโลก ซึ่งให้บริการเนื้อหาจากตำแหน่งที่ใกล้กับผู้ใช้มากขึ้น โดยทั่วไป ไฟล์คงที่ เช่น HTML/CSS/JS รูปภาพ และวิดีโอจะให้บริการจาก CDN แม้ว่า CDN บางตัว เช่น CloudFront ของ Amazon จะรองรับเนื้อหาแบบไดนามิกก็ตาม การแก้ไข DNS ของไซต์จะบอกลูกค้าว่าเซิร์ฟเวอร์ใดที่จะติดต่อ
การแสดงเนื้อหาจาก CDN สามารถปรับปรุงประสิทธิภาพได้อย่างมากด้วยสองวิธี:
Push CDN จะได้รับเนื้อหาใหม่ทุกครั้งที่มีการเปลี่ยนแปลงเกิดขึ้นบนเซิร์ฟเวอร์ของคุณ คุณรับผิดชอบอย่างเต็มที่ในการจัดหาเนื้อหา อัปโหลดไปยัง CDN โดยตรง และเขียน URL ใหม่เพื่อชี้ไปที่ CDN คุณสามารถกำหนดค่าเมื่อเนื้อหาหมดอายุและเมื่อใดที่มีการอัปเดต เนื้อหาจะถูกอัปโหลดเฉพาะเมื่อเป็นเนื้อหาใหม่หรือมีการเปลี่ยนแปลง เพื่อลดปริมาณการรับส่งข้อมูล แต่เพิ่มพื้นที่จัดเก็บข้อมูลให้สูงสุด
ไซต์ที่มีปริมาณการเข้าชมน้อยหรือไซต์ที่มีเนื้อหาที่ไม่ได้รับการอัปเดตมักจะทำงานได้ดีกับ Push CDN เนื้อหาจะถูกวางบน CDN เพียงครั้งเดียว แทนที่จะถูกดึงซ้ำเป็นระยะๆ
ดึง CDN ดึงเนื้อหาใหม่จากเซิร์ฟเวอร์ของคุณเมื่อผู้ใช้รายแรกร้องขอเนื้อหา คุณทิ้งเนื้อหาไว้บนเซิร์ฟเวอร์ของคุณและเขียน URL ใหม่เพื่อชี้ไปที่ CDN ซึ่งส่งผลให้คำขอช้าลงจนกว่าเนื้อหาจะถูกแคชไว้ใน CDN
Time-to-Live (TTL) จะกำหนดระยะเวลาในการแคชเนื้อหา การดึง CDN ลดพื้นที่จัดเก็บข้อมูลบน CDN แต่สามารถสร้างการรับส่งข้อมูลที่ซ้ำซ้อนได้หากไฟล์หมดอายุและถูกดึงก่อนที่จะมีการเปลี่ยนแปลงจริง
ไซต์ที่มีการรับส่งข้อมูลจำนวนมากทำงานได้ดีกับ Pull CDN เนื่องจากการรับส่งข้อมูลจะกระจายอย่างเท่าเทียมกันมากขึ้นโดยมีเพียงเนื้อหาที่ขอล่าสุดเท่านั้นที่เหลืออยู่ใน CDN
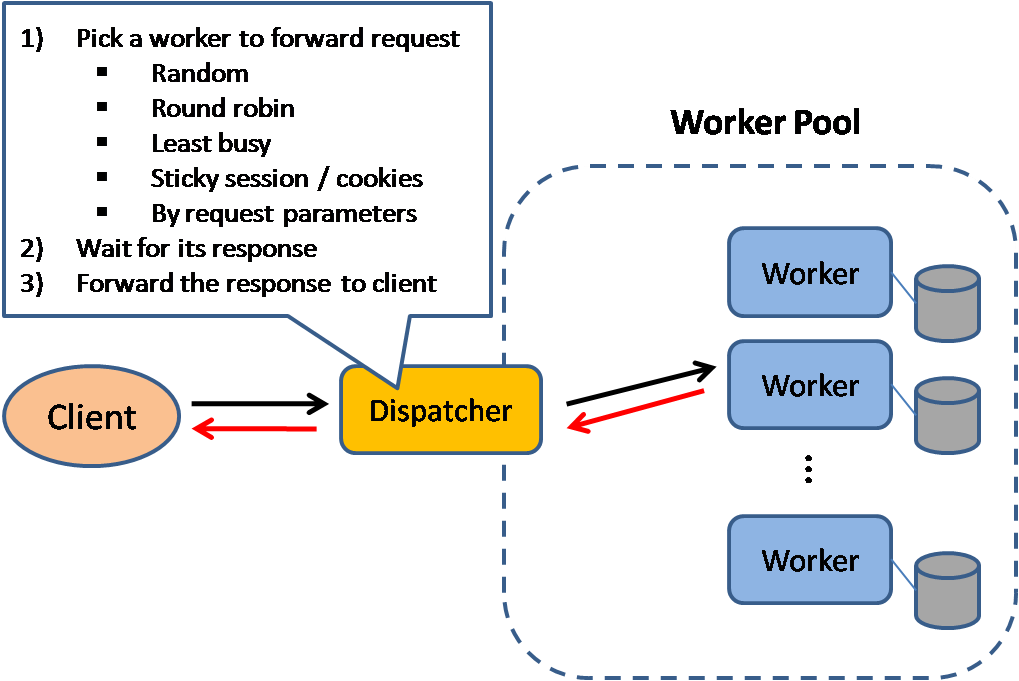
ที่มา: รูปแบบการออกแบบระบบที่ปรับขนาดได้
โหลดบาลานเซอร์จะกระจายคำขอไคลเอ็นต์ขาเข้าไปยังทรัพยากรการประมวลผล เช่น แอปพลิเคชันเซิร์ฟเวอร์และฐานข้อมูล ในแต่ละกรณี โหลดบาลานเซอร์จะส่งคืนการตอบสนองจากทรัพยากรการประมวลผลไปยังไคลเอนต์ที่เหมาะสม โหลดบาลานเซอร์มีประสิทธิภาพที่:
โหลดบาลานเซอร์สามารถใช้งานได้กับฮาร์ดแวร์ (ราคาแพง) หรือกับซอฟต์แวร์ เช่น HAProxy
สิทธิประโยชน์เพิ่มเติม ได้แก่:
เพื่อป้องกันความล้มเหลว เป็นเรื่องปกติที่จะต้องตั้งค่าโหลดบาลานเซอร์หลายตัว ทั้งในโหมดแอคทีฟ-พาสซีฟหรือแอคทีฟ-แอคทีฟ
ตัวจัดสรรภาระงานสามารถกำหนดเส้นทางการรับส่งข้อมูลตามตัวชี้วัดต่างๆ รวมถึง:
โหลดบาลานเซอร์เลเยอร์ 4 จะดูข้อมูลที่เลเยอร์การขนส่งเพื่อตัดสินใจว่าจะกระจายคำขออย่างไร โดยทั่วไป สิ่งนี้เกี่ยวข้องกับต้นทาง ที่อยู่ IP ปลายทาง และพอร์ตในส่วนหัว แต่ไม่ใช่เนื้อหาของแพ็กเก็ต โหลดบาลานเซอร์เลเยอร์ 4 ส่งต่อแพ็กเก็ตเครือข่ายไปยังและจากเซิร์ฟเวอร์อัปสตรีม โดยดำเนินการแปลที่อยู่เครือข่าย (NAT)
โหลดบาลานเซอร์ของเลเยอร์ 7 จะพิจารณาที่เลเยอร์แอปพลิเคชันเพื่อตัดสินใจว่าจะกระจายคำขออย่างไร ซึ่งอาจเกี่ยวข้องกับเนื้อหาของส่วนหัว ข้อความ และคุกกี้ โหลดบาลานเซอร์ของเลเยอร์ 7 ยุติการรับส่งข้อมูลเครือข่าย อ่านข้อความ ทำการตัดสินใจเกี่ยวกับโหลดบาลานซ์ จากนั้นเปิดการเชื่อมต่อกับเซิร์ฟเวอร์ที่เลือก ตัวอย่างเช่น โหลดบาลานเซอร์เลเยอร์ 7 สามารถนำการรับส่งข้อมูลวิดีโอไปยังเซิร์ฟเวอร์ที่โฮสต์วิดีโอ ในขณะเดียวกันก็กำหนดเส้นทางการรับส่งข้อมูลการเรียกเก็บเงินของผู้ใช้ที่มีความละเอียดอ่อนมากขึ้นไปยังเซิร์ฟเวอร์ที่มีการรักษาความปลอดภัย
ด้วยต้นทุนด้านความยืดหยุ่น การปรับสมดุลโหลดของเลเยอร์ 4 ต้องใช้เวลาและทรัพยากรการประมวลผลน้อยกว่าเลเยอร์ 7 แม้ว่าผลกระทบด้านประสิทธิภาพอาจมีน้อยมากกับฮาร์ดแวร์สินค้าโภคภัณฑ์สมัยใหม่
โหลดบาลานเซอร์ยังสามารถช่วยในการปรับขนาดแนวนอน ปรับปรุงประสิทธิภาพและความพร้อมใช้งาน การขยายขนาดโดยใช้เครื่องสินค้าโภคภัณฑ์จะคุ้มค่ากว่าและส่งผลให้มีความพร้อมใช้งานสูงกว่าการขยายขนาดเซิร์ฟเวอร์เดี่ยวบนฮาร์ดแวร์ราคาแพงกว่าที่เรียกว่า Vertical Scaling นอกจากนี้ การจ้างผู้มีความสามารถที่ทำงานด้านฮาร์ดแวร์สินค้าโภคภัณฑ์ยังง่ายกว่าการจ้างระบบองค์กรเฉพาะทางอีกด้วย
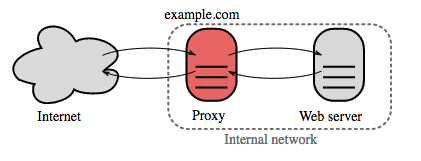
ที่มา: วิกิพีเดีย
Reverse proxy คือเว็บเซิร์ฟเวอร์ที่รวมศูนย์บริการภายในและจัดเตรียมอินเทอร์เฟซแบบรวมให้กับสาธารณะ คำขอจากไคลเอนต์จะถูกส่งต่อไปยังเซิร์ฟเวอร์ที่สามารถตอบสนองได้ก่อนที่พร็อกซีย้อนกลับจะส่งคืนการตอบสนองของเซิร์ฟเวอร์ไปยังไคลเอนต์
สิทธิประโยชน์เพิ่มเติม ได้แก่:
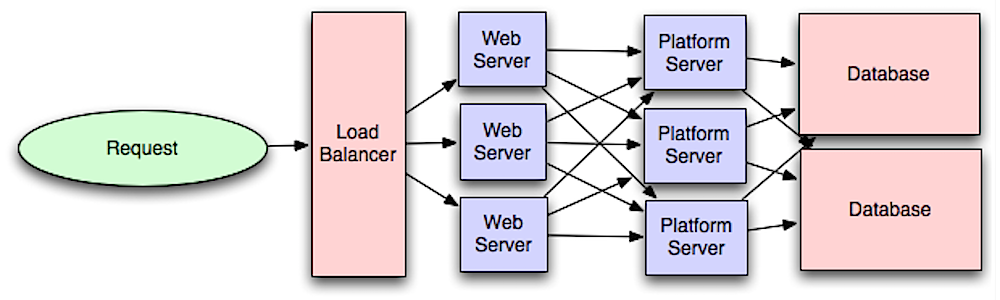
ที่มา: ข้อมูลเบื้องต้นเกี่ยวกับระบบการออกแบบสถาปัตยกรรมสำหรับขนาด
การแยกเลเยอร์เว็บออกจากเลเยอร์แอปพลิเคชัน (หรือที่เรียกว่าเลเยอร์แพลตฟอร์ม) ช่วยให้คุณสามารถปรับขนาดและกำหนดค่าทั้งสองเลเยอร์ได้อย่างอิสระ การเพิ่มผลลัพธ์ API ใหม่ในการเพิ่มเซิร์ฟเวอร์แอปพลิเคชันโดยไม่จำเป็นต้องเพิ่มเว็บเซิร์ฟเวอร์เพิ่มเติม หลักการความรับผิดชอบเดียว สนับสนุนบริการขนาดเล็กและเป็นอิสระที่ทำงานร่วมกัน ทีมขนาดเล็กที่มีบริการขนาดเล็กสามารถวางแผนเชิงรุกได้มากขึ้นเพื่อการเติบโตที่รวดเร็ว
ผู้ปฏิบัติงานในเลเยอร์แอปพลิเคชันยังช่วยเปิดใช้งานความไม่ตรงกันอีกด้วย
ที่เกี่ยวข้องกับการสนทนานี้คือไมโครเซอร์วิส ซึ่งสามารถอธิบายได้ว่าเป็นชุดบริการขนาดเล็กแบบแยกส่วนที่สามารถปรับใช้ได้อย่างอิสระ แต่ละบริการดำเนินกระบวนการเฉพาะและสื่อสารผ่านกลไกที่มีการกำหนดไว้อย่างดีและมีน้ำหนักเบาเพื่อตอบสนองเป้าหมายทางธุรกิจ 1
ตัวอย่างเช่น Pinterest อาจมีไมโครเซอร์วิสต่อไปนี้: โปรไฟล์ผู้ใช้ ผู้ติดตาม ฟีด การค้นหา การอัปโหลดรูปภาพ ฯลฯ
ระบบต่างๆ เช่น Consul, Etcd และ Zookeeper สามารถช่วยให้บริการต่างๆ ค้นหากันได้โดยการติดตามชื่อ ที่อยู่ และท่าเรือที่ลงทะเบียนไว้ การตรวจสุขภาพช่วยยืนยันความสมบูรณ์ของบริการ และมักดำเนินการโดยใช้ตำแหน่งข้อมูล HTTP ทั้งกงสุลและ Etcd มีที่เก็บคีย์-ค่าในตัวซึ่งมีประโยชน์สำหรับการจัดเก็บค่าการกำหนดค่าและข้อมูลอื่นๆ ที่แชร์
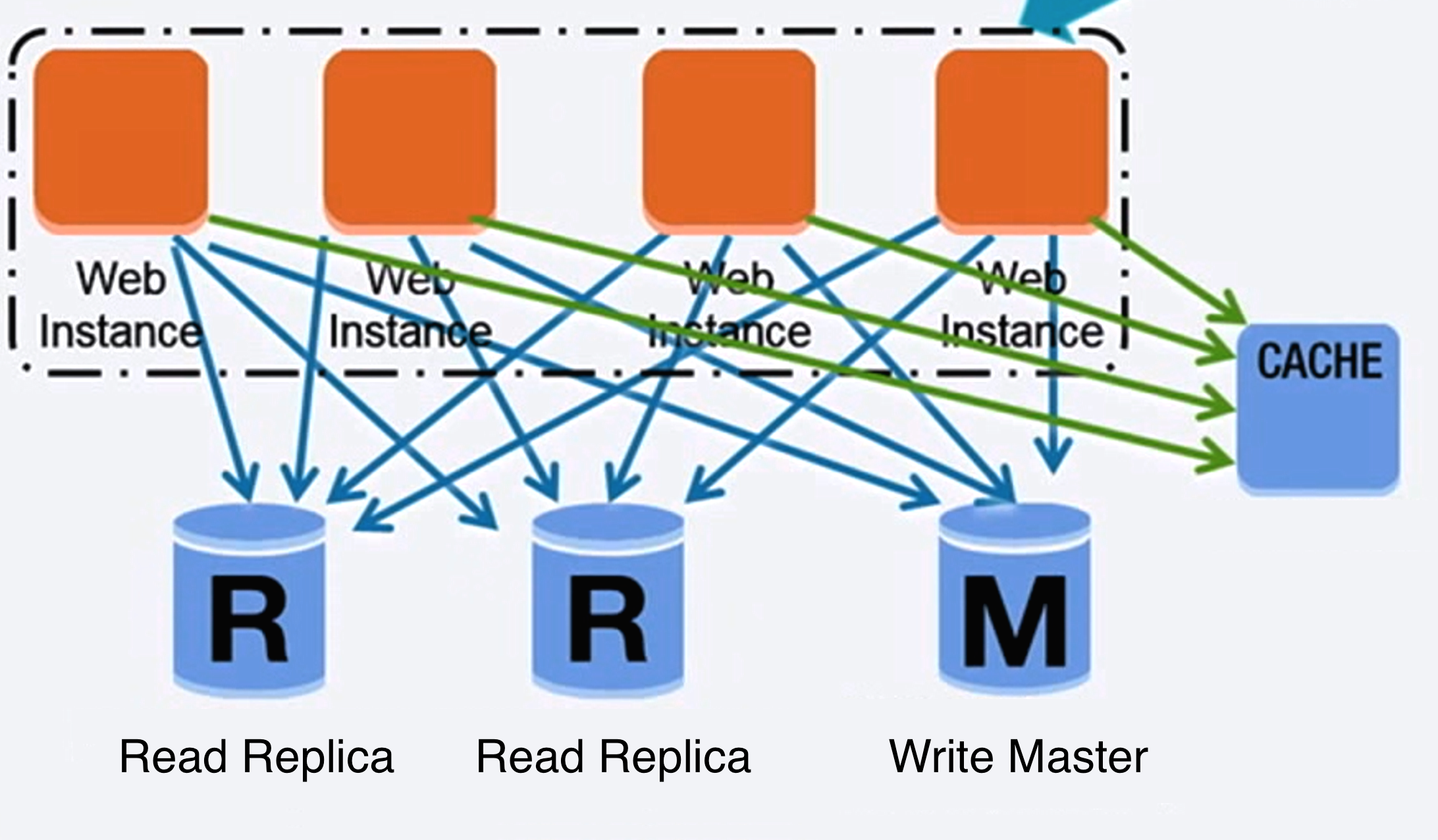
แหล่งที่มา: ขยายขนาดผู้ใช้ 10 ล้านคนแรกของคุณ
ฐานข้อมูลเชิงสัมพันธ์เช่น SQL คือชุดของรายการข้อมูลที่จัดอยู่ในตาราง
ACID คือชุดของคุณสมบัติของธุรกรรมฐานข้อมูลเชิงสัมพันธ์
มีเทคนิคมากมายในการปรับขนาดฐานข้อมูลเชิงสัมพันธ์: การจำลองแบบมาสเตอร์-สเลฟ การจำลองแบบมาสเตอร์-มาสเตอร์ การรวมศูนย์ การแบ่งส่วน การ ทำให้ปกติดีนอร์มัลไลซ์ และ การปรับแต่ง SQL
ต้นแบบทำหน้าที่อ่านและเขียน โดยจำลองการเขียนไปยังทาสตั้งแต่หนึ่งตัวขึ้นไป ซึ่งให้บริการเฉพาะการอ่านเท่านั้น ทาสยังสามารถทำซ้ำกับทาสเพิ่มเติมในลักษณะคล้ายต้นไม้ได้ หากต้นแบบออฟไลน์ ระบบสามารถทำงานต่อไปในโหมดอ่านอย่างเดียวได้จนกว่าทาสจะได้รับการเลื่อนระดับเป็นต้นแบบหรือจัดเตรียมต้นแบบใหม่
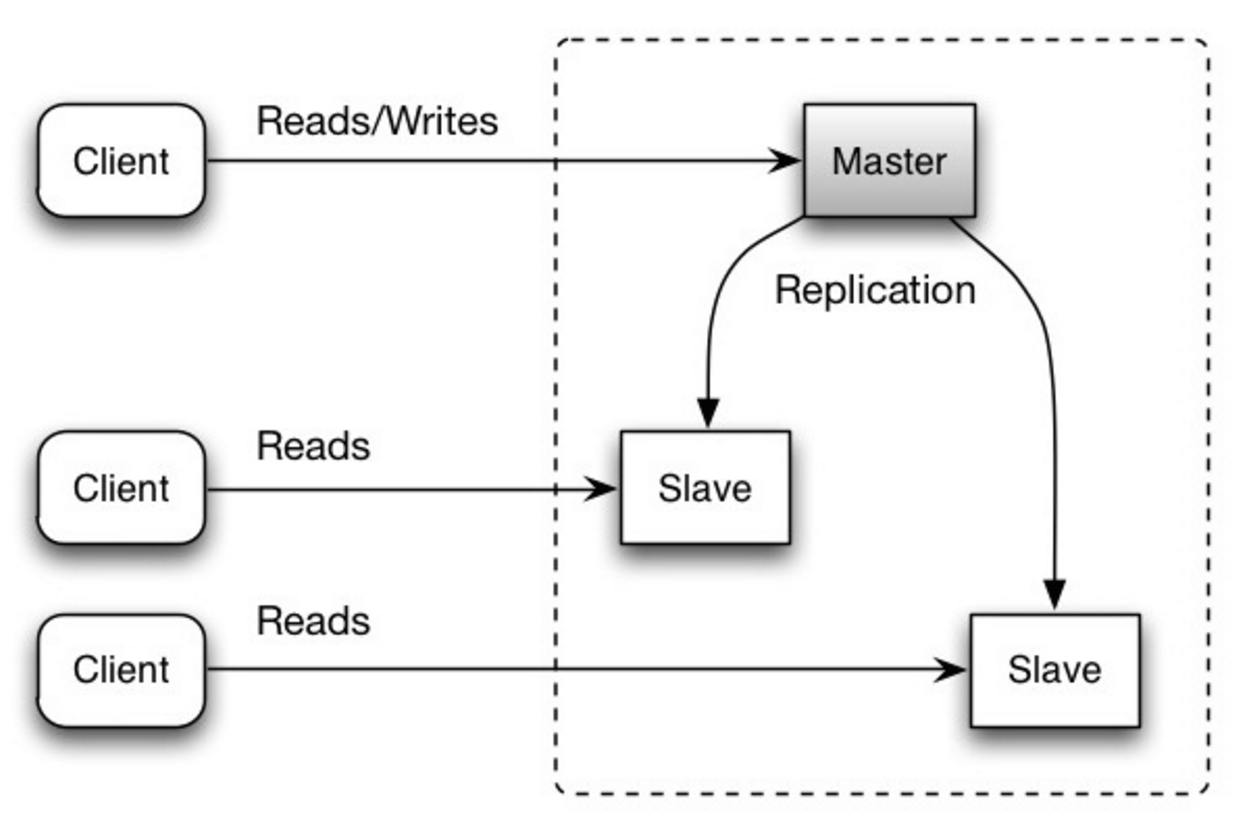
ที่มา: ความสามารถในการปรับขนาด ความพร้อมใช้งาน ความเสถียร รูปแบบ
ปรมาจารย์ทั้งสองให้บริการการอ่านและเขียนและประสานงานในการเขียนซึ่งกันและกัน หากต้นแบบตัวใดตัวหนึ่งหยุดทำงาน ระบบสามารถทำงานต่อไปได้ทั้งการอ่านและเขียน
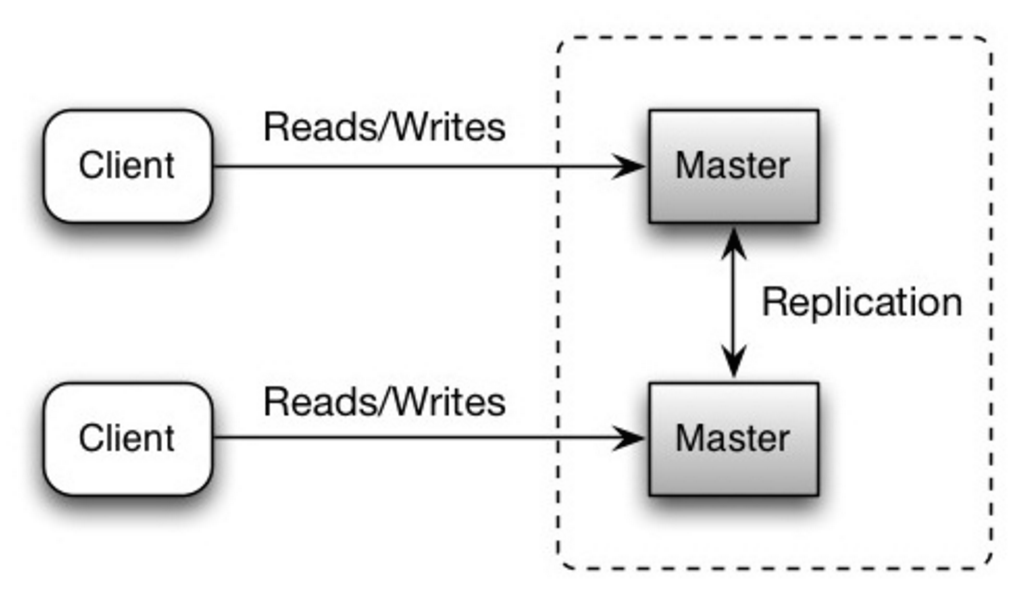
ที่มา: ความสามารถในการปรับขนาด ความพร้อมใช้งาน ความเสถียร รูปแบบ
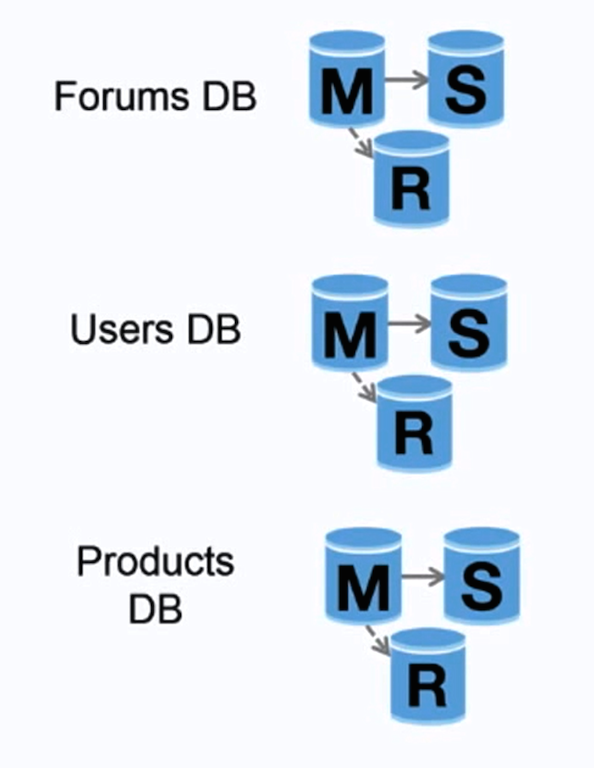
แหล่งที่มา: ขยายขนาดผู้ใช้ 10 ล้านคนแรกของคุณ
สหพันธรัฐ (หรือการแบ่งพาร์ติชันตามหน้าที่) จะแยกฐานข้อมูลตามฟังก์ชัน ตัวอย่างเช่น แทนที่จะมีฐานข้อมูลขนาดใหญ่เพียงแห่งเดียว คุณสามารถมีฐานข้อมูลได้สามฐานข้อมูล: ฟอรัม ผู้ใช้ และ ผลิตภัณฑ์ ส่งผลให้ปริมาณการอ่านและเขียนไปยังฐานข้อมูลแต่ละฐานข้อมูลน้อยลง และด้วยเหตุนี้จึงมีความล่าช้าในการจำลองน้อยลง ฐานข้อมูลที่มีขนาดเล็กลงส่งผลให้มีข้อมูลที่สามารถบรรจุในหน่วยความจำได้มากขึ้น ซึ่งส่งผลให้มีการเข้าถึงแคชมากขึ้นเนื่องจากตำแหน่งแคชที่ได้รับการปรับปรุง เมื่อไม่มีการเขียนซีเรียลไลซ์ต้นแบบส่วนกลางเพียงรายการเดียว คุณจึงสามารถเขียนแบบขนานได้ ซึ่งช่วยเพิ่มปริมาณงาน
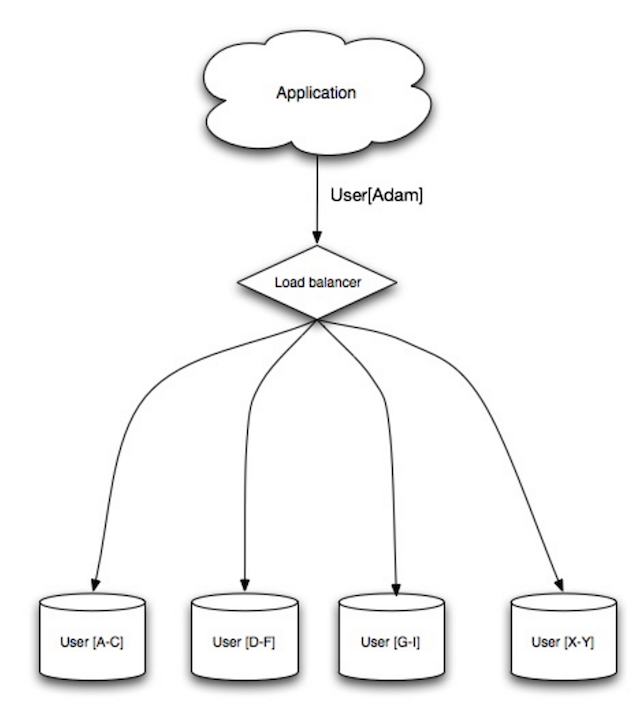
แหล่งที่มา: ความสามารถในการขยาย ความพร้อมใช้งาน ความเสถียร รูปแบบ
Sharding กระจายข้อมูลไปยังฐานข้อมูลต่างๆ เพื่อให้แต่ละฐานข้อมูลสามารถจัดการข้อมูลได้เพียงบางส่วนเท่านั้น ยกตัวอย่างฐานข้อมูลผู้ใช้ เมื่อจำนวนผู้ใช้เพิ่มขึ้น ชาร์ดก็จะถูกเพิ่มเข้าไปในคลัสเตอร์มากขึ้น
เช่นเดียวกับข้อดีของการรวมศูนย์ การแบ่งส่วนส่งผลให้มีปริมาณการอ่านและเขียนน้อยลง การจำลองน้อยลง และการเข้าถึงแคชมากขึ้น ขนาดดัชนีก็ลดลงด้วย ซึ่งโดยทั่วไปจะปรับปรุงประสิทธิภาพด้วยการสืบค้นที่เร็วขึ้น หากชาร์ดตัวหนึ่งใช้งานไม่ได้ ส่วนชาร์ดอื่นๆ จะยังคงใช้งานได้ แม้ว่าคุณจะต้องการเพิ่มรูปแบบการจำลองเพื่อหลีกเลี่ยงข้อมูลสูญหายก็ตาม เช่นเดียวกับสหพันธรัฐไม่มีการเขียนแบบอนุกรมหลักหลักเพียงอย่างเดียวทำให้คุณสามารถเขียนควบคู่ไปกับปริมาณงานที่เพิ่มขึ้น
วิธีการทั่วไปในการทำลายตารางผู้ใช้นั้นผ่านนามสกุลเริ่มต้นของผู้ใช้หรือที่ตั้งทางภูมิศาสตร์ของผู้ใช้
Denormalization พยายามปรับปรุงประสิทธิภาพการอ่านด้วยค่าใช้จ่ายของประสิทธิภาพการเขียนบางอย่าง สำเนาข้อมูลซ้ำซ้อนถูกเขียนในหลายตารางเพื่อหลีกเลี่ยงการเข้าร่วมที่มีราคาแพง RDBMS บางตัวเช่น PostgreSQL และ Oracle สนับสนุนมุมมองที่เป็นรูปธรรมซึ่งจัดการงานของการจัดเก็บข้อมูลซ้ำซ้อนและรักษาสำเนาซ้ำซ้อนที่สอดคล้องกัน
เมื่อข้อมูลมีการแจกจ่ายด้วยเทคนิคต่าง ๆ เช่นสหพันธรัฐและการจัดวางการจัดการการรวมข้ามศูนย์ข้อมูลจะเพิ่มความซับซ้อนมากขึ้น Denormalization อาจหลีกเลี่ยงความจำเป็นในการเข้าร่วมที่ซับซ้อนเช่นนี้
ในระบบส่วนใหญ่การอ่านสามารถมีจำนวนมากกว่าการเขียน 100: 1 หรือ 1,000: 1 การอ่านทำให้เกิดการเข้าร่วมฐานข้อมูลที่ซับซ้อนอาจมีราคาแพงมากใช้เวลาในการดำเนินการดิสก์เป็นจำนวนมาก
การปรับแต่ง SQL เป็นหัวข้อที่กว้างและมีการเขียนหนังสือหลายเล่มเป็นข้อมูลอ้างอิง
สิ่งสำคัญคือ เกณฑ์มาตรฐาน และ โปรไฟล์ ในการจำลองและค้นพบคอขวด
การเปรียบเทียบและการทำโปรไฟล์อาจชี้ให้คุณเห็นถึงการเพิ่มประสิทธิภาพต่อไปนี้
CHAR แทน VARCHAR สำหรับฟิลด์ความยาวคงที่CHAR ช่วยให้สามารถเข้าถึงได้อย่างรวดเร็วและสุ่มในขณะที่กับ VARCHAR คุณต้องหาจุดสิ้นสุดของสตริงก่อนที่จะย้ายไปยังอีกอันTEXT สำหรับบล็อกข้อความขนาดใหญ่เช่นโพสต์บล็อก TEXT ยังอนุญาตให้ทำการค้นหาแบบบูลีน การใช้ฟิลด์ TEXT ในการจัดเก็บตัวชี้บนดิสก์ที่ใช้เพื่อค้นหาบล็อกข้อความINT สำหรับตัวเลขที่ใหญ่กว่า 2^32 หรือ 4 พันล้านDECIMAL สำหรับสกุลเงินเพื่อหลีกเลี่ยงข้อผิดพลาดในการแสดงจุดลอยตัวBLOBS ขนาดใหญ่เก็บตำแหน่งของตำแหน่งที่จะรับวัตถุแทนVARCHAR(255) เป็นจำนวนอักขระที่ใหญ่ที่สุดที่สามารถนับได้ในหมายเลข 8 บิตมักจะเพิ่มการใช้ไบต์ใน RDBMS บางตัวNOT NULL ซึ่งใช้เพื่อปรับปรุงประสิทธิภาพการค้นหา SELECT , GROUP BY , ORDER BY , JOIN ) อาจเร็วขึ้นด้วยดัชนีNOSQL เป็นชุดของรายการข้อมูลที่แสดงใน ร้านค้าคีย์-ค่า ที่เก็บเอกสาร ที่เก็บคอลัมน์กว้าง หรือ ฐานข้อมูลกราฟ ข้อมูลถูก denormalized และโดยทั่วไปจะทำในรหัสแอปพลิเคชัน ร้านค้า NOSQL ส่วนใหญ่ขาดธุรกรรมกรดที่แท้จริงและให้ความสำคัญกับความสอดคล้องในที่สุด
ฐาน มักจะใช้เพื่ออธิบายคุณสมบัติของฐานข้อมูล NOSQL ในการเปรียบเทียบกับทฤษฎีบทหมวกฐานเลือกความพร้อมใช้งานมากกว่าความสอดคล้อง
นอกเหนือจากการเลือกระหว่าง SQL หรือ NOSQL แล้วยังมีประโยชน์ที่จะเข้าใจว่าฐานข้อมูล NOSQL ประเภทใดที่เหมาะกับกรณีการใช้งานของคุณ เราจะตรวจสอบ ร้านค้าคีย์-ค่า ที่เก็บเอกสาร ที่เก็บคอลัมน์กว้าง และ ฐานข้อมูลกราฟ ในส่วนถัดไป
นามธรรม: ตารางแฮช
โดยทั่วไปแล้วร้านค้าคีย์-ค่าอนุญาตสำหรับการอ่านและเขียน O (1) และมักจะได้รับการสนับสนุนโดยหน่วยความจำหรือ SSD ที่เก็บข้อมูลสามารถรักษาคีย์ตามลำดับพจนานุกรมได้ช่วยให้สามารถดึงช่วงที่สำคัญได้อย่างมีประสิทธิภาพ ร้านค้าคีย์-ค่าสามารถอนุญาตให้จัดเก็บข้อมูลเมตาด้วยค่า
ร้านค้าคีย์-ค่าให้ประสิทธิภาพสูงและมักจะใช้สำหรับแบบจำลองข้อมูลอย่างง่ายหรือสำหรับข้อมูลที่เปลี่ยนแปลงอย่างรวดเร็วเช่นชั้นแคชในหน่วยความจำ เนื่องจากพวกเขาเสนอเพียงชุดการดำเนินงานที่ จำกัด ความซับซ้อนจึงถูกเปลี่ยนเป็นเลเยอร์แอปพลิเคชันหากจำเป็นต้องมีการดำเนินการเพิ่มเติม
ร้านค้าคีย์-ค่าเป็นพื้นฐานสำหรับระบบที่ซับซ้อนมากขึ้นเช่นที่เก็บเอกสารและในบางกรณีฐานข้อมูลกราฟ
Abstraction: ร้านค้าคีย์-ค่าพร้อมเอกสารที่เก็บไว้เป็นค่า
ร้านเอกสารมีศูนย์กลางอยู่ที่เอกสาร (XML, JSON, Binary, ฯลฯ ) ซึ่งเอกสารเก็บข้อมูลทั้งหมดสำหรับวัตถุที่กำหนด ที่เก็บเอกสารให้ APIs หรือภาษาสืบค้นเพื่อสอบถามตามโครงสร้างภายในของเอกสารเอง หมายเหตุร้านค้าคีย์-ค่าหลายแห่งรวมถึงคุณสมบัติสำหรับการทำงานกับข้อมูลเมตาของค่าเบลอเส้นระหว่างสองประเภทที่เก็บข้อมูลนี้
จากการดำเนินการพื้นฐานเอกสารจะถูกจัดระเบียบโดยคอลเลกชันแท็กเมตาหรือไดเรกทอรี แม้ว่าเอกสารสามารถจัดระเบียบหรือจัดกลุ่มเข้าด้วยกันเอกสารอาจมีฟิลด์ที่แตกต่างกันอย่างสิ้นเชิง
ร้านเอกสารบางแห่งเช่น MongoDB และ CouchDB ยังให้ภาษาที่มีลักษณะคล้าย SQL เพื่อทำการสืบค้นที่ซับซ้อน DynamoDB รองรับทั้งค่าคีย์และเอกสาร
ที่เก็บเอกสารให้ความยืดหยุ่นสูงและมักใช้สำหรับการทำงานกับการเปลี่ยนแปลงข้อมูลเป็นครั้งคราว
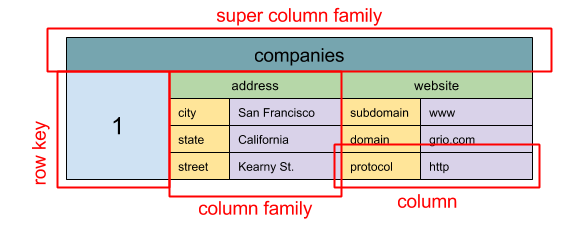
ที่มา: SQL & NOSQL ประวัติโดยย่อ
Abstraction:
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
หน่วยข้อมูลพื้นฐานของคอลัมน์กว้างคือคอลัมน์ (คู่ชื่อ/ค่า) คอลัมน์สามารถจัดกลุ่มในตระกูลคอลัมน์ (คล้ายกับตาราง SQL) ตระกูลคอลัมน์ซุปเปอร์คอลัมน์คอลัมน์เพิ่มเติม คุณสามารถเข้าถึงแต่ละคอลัมน์ได้อย่างอิสระด้วยคีย์แถวและคอลัมน์ที่มีคีย์แถวเดียวกันเป็นแถวเป็นแถว แต่ละค่ามีการประทับเวลาสำหรับการกำหนดเวอร์ชันและสำหรับการแก้ไขข้อขัดแย้ง
Google แนะนำ BigTable เป็นร้านค้าคอลัมน์กว้างแห่งแรกซึ่งมีอิทธิพลต่อ HBase โอเพนซอร์สที่ใช้บ่อยในระบบนิเวศ Hadoop และ Cassandra จาก Facebook ร้านค้าเช่น BigTable, HBase และ Cassandra รักษากุญแจตามลำดับพจนานุกรมทำให้การดึงช่วงคีย์เลือกอย่างมีประสิทธิภาพ
ร้านค้าคอลัมน์กว้างมีความพร้อมใช้งานสูงและปรับขนาดได้สูง พวกเขามักจะใช้สำหรับชุดข้อมูลขนาดใหญ่มาก
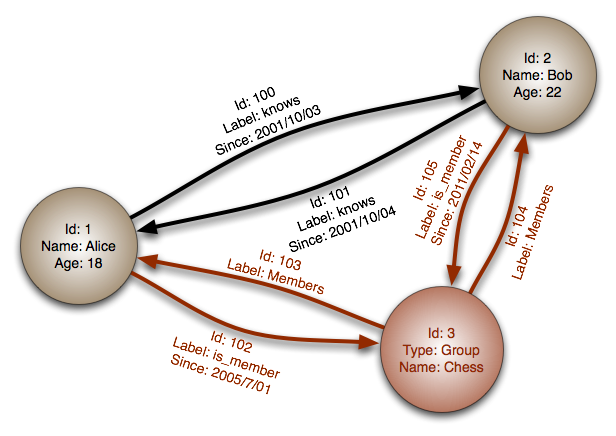
ที่มา: ฐานข้อมูลกราฟ
นามธรรม: กราฟ
ในฐานข้อมูลกราฟแต่ละโหนดจะเป็นระเบียนและแต่ละอาร์คเป็นความสัมพันธ์ระหว่างสองโหนด ฐานข้อมูลกราฟได้รับการปรับให้เหมาะสมเพื่อแสดงถึงความสัมพันธ์ที่ซับซ้อนกับคีย์ต่างประเทศจำนวนมากหรือความสัมพันธ์แบบหลายต่อหลายครั้ง
ฐานข้อมูลกราฟมีประสิทธิภาพสูงสำหรับแบบจำลองข้อมูลที่มีความสัมพันธ์ที่ซับซ้อนเช่นเครือข่ายโซเชียล พวกเขาค่อนข้างใหม่และยังไม่ได้ใช้กันอย่างแพร่หลาย อาจเป็นเรื่องยากกว่าที่จะค้นหาเครื่องมือและทรัพยากรการพัฒนา กราฟจำนวนมากสามารถเข้าถึงได้ด้วย REST API เท่านั้น
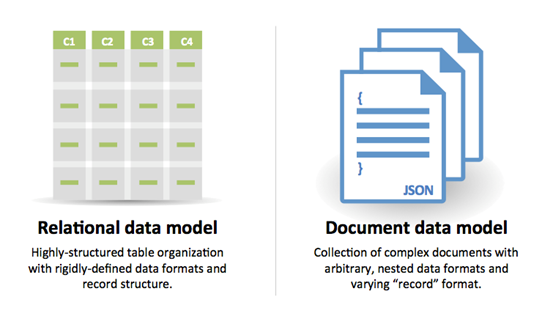
ที่มา: การเปลี่ยนจาก RDBMS เป็น NOSQL
เหตุผลสำหรับ SQL :
เหตุผลสำหรับ NOSQL :
ตัวอย่างข้อมูลที่เหมาะสมสำหรับ NOSQL:
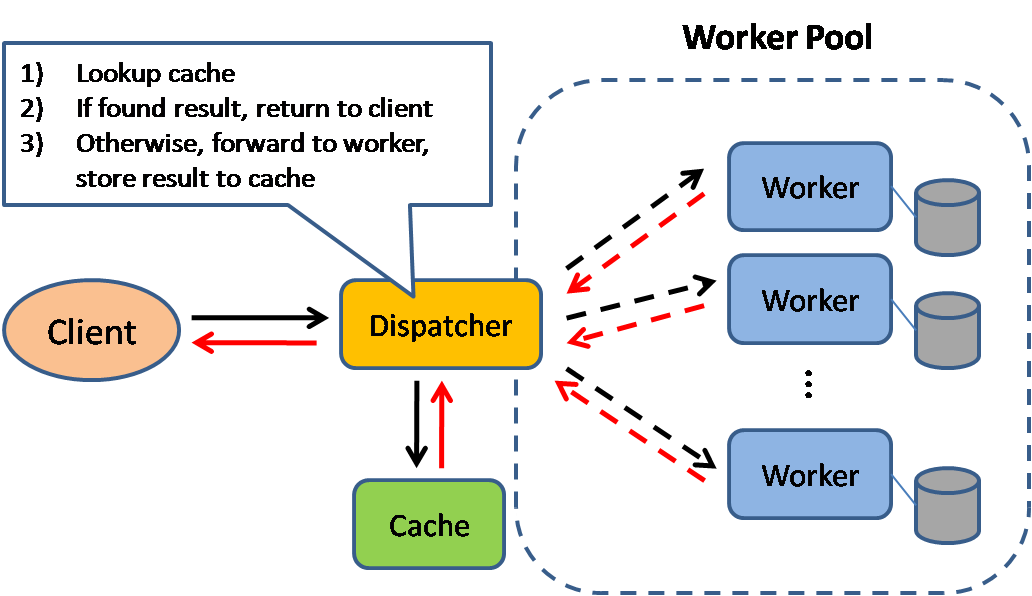
ที่มา: รูปแบบการออกแบบระบบที่ปรับขนาดได้
การแคชปรับปรุงเวลาโหลดหน้าเว็บและสามารถลดการโหลดบนเซิร์ฟเวอร์และฐานข้อมูลของคุณ ในรุ่นนี้ผู้แจกจ่ายจะทำการค้นหาก่อนหากมีการร้องขอมาก่อนและพยายามค้นหาผลลัพธ์ก่อนหน้าเพื่อส่งคืนเพื่อบันทึกการดำเนินการจริง
ฐานข้อมูลมักได้รับประโยชน์จากการกระจายการอ่านและการเขียนที่สม่ำเสมอในพาร์ติชัน รายการยอดนิยมสามารถเบี่ยงเบนการแจกจ่ายทำให้เกิดปัญหาคอขวด การวางแคชไว้ด้านหน้าของฐานข้อมูลสามารถช่วยดูดซับโหลดที่ไม่สม่ำเสมอและแหลมในการจราจร
แคชสามารถอยู่ที่ฝั่งไคลเอ็นต์ (ระบบปฏิบัติการหรือเบราว์เซอร์) ด้านเซิร์ฟเวอร์หรือในชั้นแคชที่แตกต่างกัน
CDN ถือเป็นแคชประเภทหนึ่ง
พร็อกซีย้อนกลับและแคชเช่นเคลือบเงาสามารถให้บริการเนื้อหาแบบคงที่และไดนามิกได้โดยตรง เว็บเซิร์ฟเวอร์ยังสามารถแคชคำขอส่งคืนคำตอบโดยไม่ต้องติดต่อเซิร์ฟเวอร์แอปพลิเคชัน
ฐานข้อมูลของคุณมักจะมีการแคชระดับหนึ่งในการกำหนดค่าเริ่มต้นที่ได้รับการปรับให้เหมาะสมสำหรับกรณีการใช้งานทั่วไป การปรับแต่งการตั้งค่าเหล่านี้สำหรับรูปแบบการใช้งานที่เฉพาะเจาะจงสามารถเพิ่มประสิทธิภาพได้
แคชในหน่วยความจำเช่น memcached และ redis เป็นที่เก็บคีย์-ค่าระหว่างแอปพลิเคชันของคุณและการจัดเก็บข้อมูลของคุณ เนื่องจากข้อมูลถูกเก็บไว้ใน RAM จึงเร็วกว่าฐานข้อมูลทั่วไปที่เก็บข้อมูลไว้ในดิสก์ RAM มี จำกัด มากกว่าดิสก์ดังนั้นอัลกอริธึมการทำให้เป็นโมฆะแคชเช่นที่ใช้อย่างน้อยเมื่อเร็ว ๆ นี้ (LRU) สามารถช่วยให้รายการ 'เย็น' ถูกทำให้เป็นโมฆะและเก็บข้อมูล 'ร้อน' ใน RAM
Redis มีคุณสมบัติเพิ่มเติมดังต่อไปนี้:
มีหลายระดับที่คุณสามารถแคชที่แบ่งออกเป็นสองหมวดหมู่ทั่วไป: การสืบค้นฐานข้อมูล และ วัตถุ :
โดยทั่วไปคุณควรพยายามหลีกเลี่ยงการแคชที่ใช้ไฟล์เนื่องจากทำให้การโคลนนิ่งและการปรับขนาดอัตโนมัติยากขึ้น
เมื่อใดก็ตามที่คุณสอบถามฐานข้อมูลแฮชเคียวรีเป็นคีย์และเก็บผลลัพธ์ไว้ในแคช วิธีการนี้ได้รับความทุกข์ทรมานจากปัญหาการหมดอายุ:
ดูข้อมูลของคุณเป็นวัตถุคล้ายกับสิ่งที่คุณทำกับรหัสแอปพลิเคชันของคุณ ให้แอปพลิเคชันของคุณรวบรวมชุดข้อมูลจากฐานข้อมูลเป็นอินสแตนซ์คลาสหรือโครงสร้างข้อมูล:
คำแนะนำเกี่ยวกับสิ่งที่จะแคช:
เนื่องจากคุณสามารถจัดเก็บข้อมูลจำนวน จำกัด ในแคชคุณจะต้องกำหนดกลยุทธ์การอัปเดตแคชที่ดีที่สุดสำหรับกรณีการใช้งานของคุณ
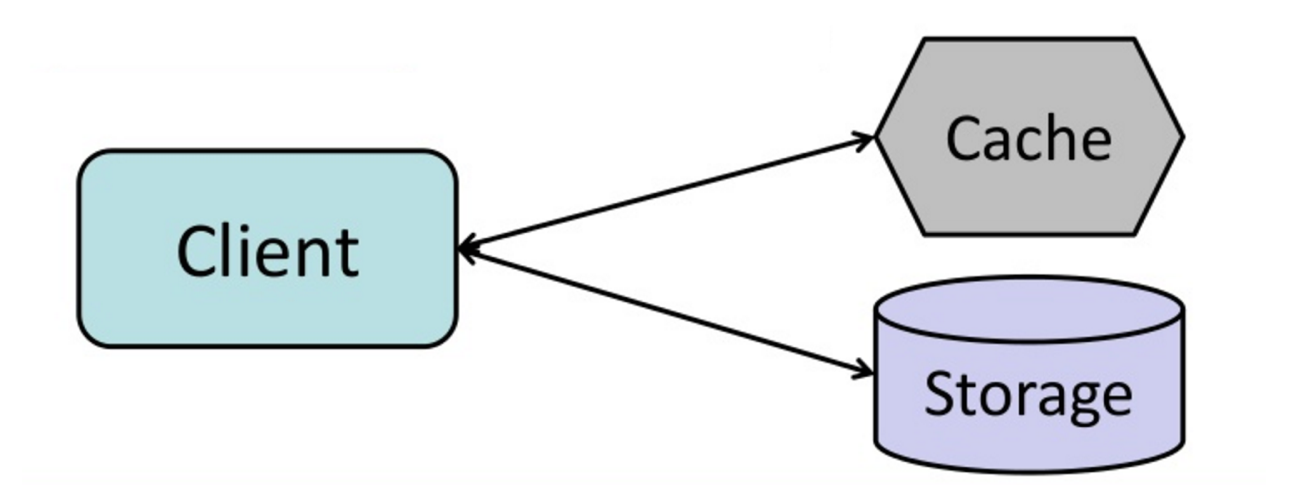
ที่มา: จากแคชไปจนถึงตารางข้อมูลในหน่วยความจำ
แอปพลิเคชันมีหน้าที่รับผิดชอบในการอ่านและการเขียนจากที่เก็บข้อมูล แคชไม่ได้โต้ตอบกับที่เก็บโดยตรง แอปพลิเคชันทำดังต่อไปนี้:
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return userโดยทั่วไปจะใช้ Memcached ในลักษณะนี้
การอ่านข้อมูลที่เพิ่มขึ้นในแคชนั้นรวดเร็ว แคช-อ้อยยังเรียกว่าการโหลดขี้เกียจ ข้อมูลที่ร้องขอเท่านั้นจะถูกแคชซึ่งหลีกเลี่ยงการเติมแคชด้วยข้อมูลที่ไม่ได้ร้องขอ
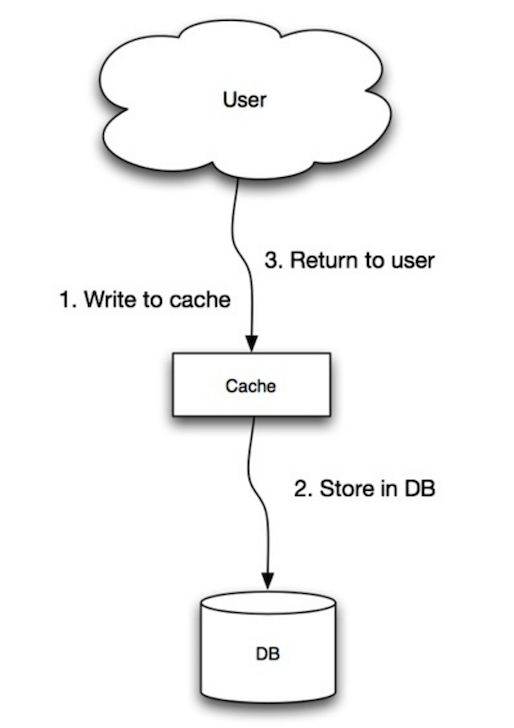
ที่มา: ความสามารถในการปรับขนาดความพร้อมใช้งานความเสถียรรูปแบบ
แอปพลิเคชันใช้แคชเป็นที่เก็บข้อมูลหลักการอ่านและการเขียนข้อมูลลงไปในขณะที่แคชรับผิดชอบการอ่านและการเขียนลงในฐานข้อมูล:
รหัสแอปพลิเคชัน:
set_user ( 12345 , { "foo" : "bar" })รหัสแคช:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )Write-through เป็นการดำเนินการโดยรวมที่ช้าเนื่องจากการดำเนินการเขียน แต่การอ่านข้อมูลที่เขียนเพียงครั้งต่อไปนั้นรวดเร็ว โดยทั่วไปผู้ใช้จะทนต่อเวลาแฝงเมื่ออัปเดตข้อมูลมากกว่าการอ่านข้อมูล ข้อมูลในแคชไม่ค้าง
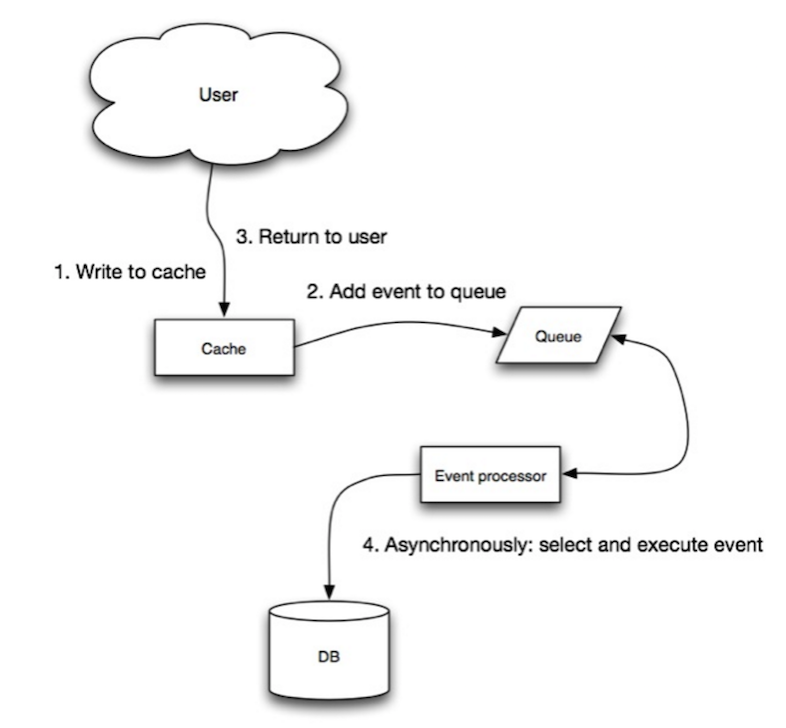
ที่มา: ความสามารถในการปรับขนาดความพร้อมใช้งานความเสถียรรูปแบบ
ในการเขียนที่อยู่ข้างหลังแอปพลิเคชันดังต่อไปนี้:
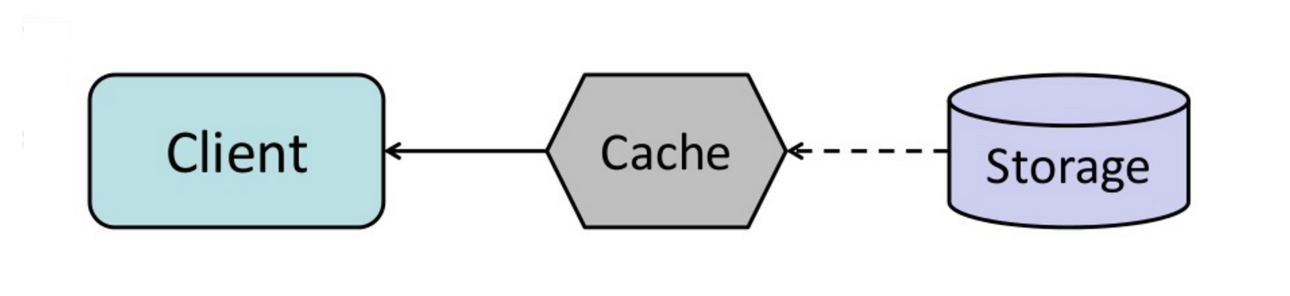
ที่มา: จากแคชไปจนถึงตารางข้อมูลในหน่วยความจำ
คุณสามารถกำหนดค่าแคชเพื่อรีเฟรชรายการแคชที่เข้าถึงได้เมื่อเร็ว ๆ นี้โดยอัตโนมัติก่อนที่จะหมดอายุ
Refresh-Ahead อาจส่งผลให้เวลาแฝงที่ลดลงเทียบกับการอ่านผ่านหากแคชสามารถทำนายได้ว่ารายการใดที่มีแนวโน้มว่าจะจำเป็นในอนาคต
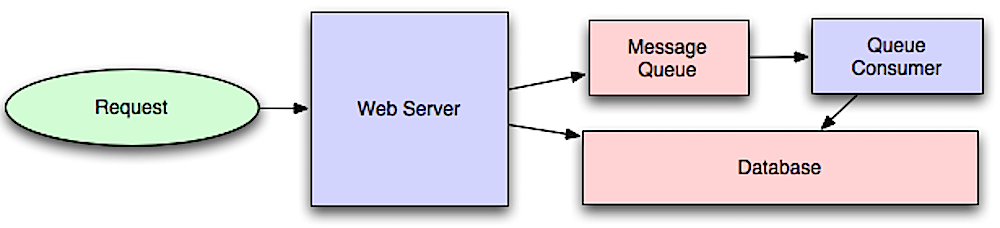
ที่มา: อินโทรสู่ระบบสถาปัตยกรรมสำหรับสเกล
เวิร์กโฟลว์แบบอะซิงโครนัสช่วยลดเวลาการร้องขอสำหรับการดำเนินงานที่มีราคาแพงซึ่งจะดำเนินการในบรรทัด พวกเขายังสามารถช่วยได้โดยการทำงานที่ใช้เวลานานล่วงหน้าเช่นการรวมข้อมูลเป็นระยะ
คิวข้อความได้รับถือและส่งข้อความ หากการดำเนินการช้าเกินไปที่จะดำเนินการแบบอินไลน์คุณสามารถใช้คิวข้อความกับเวิร์กโฟลว์ต่อไปนี้:
ผู้ใช้ไม่ได้ถูกบล็อกและงานจะถูกประมวลผลในพื้นหลัง ในช่วงเวลานี้ลูกค้าอาจเลือกการประมวลผลจำนวนเล็กน้อยเพื่อให้ดูเหมือนว่างานจะเสร็จสมบูรณ์ ตัวอย่างเช่นหากโพสต์ทวีตทวีตอาจถูกโพสต์ลงในไทม์ไลน์ของคุณทันที แต่อาจใช้เวลาสักครู่ก่อนที่ทวีตของคุณจะถูกส่งไปยังผู้ติดตามทั้งหมดของคุณ
Redis มีประโยชน์ในฐานะนายหน้าข้อความง่าย ๆ แต่ข้อความอาจหายไป
RabbitMQ เป็นที่นิยม แต่ต้องการให้คุณปรับตัวเข้ากับโปรโตคอล 'AMQP' และจัดการโหนดของคุณเอง
Amazon SQS เป็นเจ้าภาพ แต่สามารถมีความล่าช้าสูงและมีความเป็นไปได้ที่จะส่งข้อความสองครั้ง
คิวงานได้รับงานและข้อมูลที่เกี่ยวข้องของพวกเขาเรียกใช้พวกเขาจากนั้นให้ผลลัพธ์ของพวกเขา พวกเขาสามารถรองรับการกำหนดเวลาและสามารถใช้ในการทำงานที่ต้องใช้การคำนวณอย่างมากในพื้นหลัง
คื่นฉ่าย มีการสนับสนุนสำหรับการจัดตารางเวลาและส่วนใหญ่มีการสนับสนุน Python
หากคิวเริ่มเติบโตอย่างมีนัยสำคัญขนาดคิวอาจมีขนาดใหญ่กว่าหน่วยความจำส่งผลให้แคชพลาดการอ่านดิสก์และแม้กระทั่งประสิทธิภาพที่ช้าลง แรงดันย้อนกลับสามารถช่วยได้โดยการ จำกัด ขนาดคิวดังนั้นจึงรักษาอัตราการรับส่งข้อมูลที่สูงและเวลาตอบสนองที่ดีสำหรับงานที่อยู่ในคิว เมื่อคิวกรอกข้อมูลลูกค้าจะได้รับเซิร์ฟเวอร์ไม่ว่างหรือรหัสสถานะ HTTP 503 เพื่อลองอีกครั้งในภายหลัง ลูกค้าสามารถลองคำขออีกครั้งในภายหลังบางทีอาจมี backoff แบบเอ็กซ์โปเนนเชียล
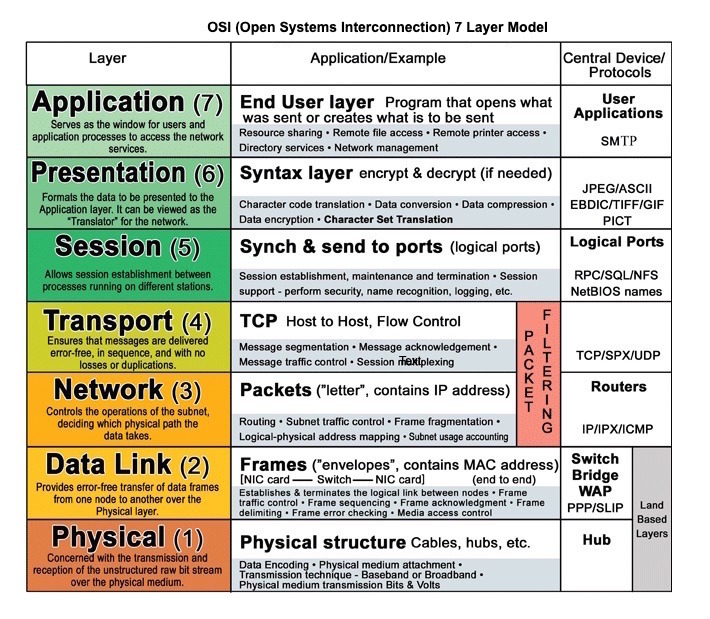
ที่มา: รุ่น OSI 7 เลเยอร์
HTTP เป็นวิธีการเข้ารหัสและการขนส่งข้อมูลระหว่างไคลเอนต์และเซิร์ฟเวอร์ มันเป็นโปรโตคอลคำขอ/ตอบกลับ: การร้องขอการออกและเซิร์ฟเวอร์ออกการตอบกลับด้วยเนื้อหาที่เกี่ยวข้องและข้อมูลสถานะการเสร็จสิ้นเกี่ยวกับคำขอ HTTP มีอยู่ในตัวเองช่วยให้การร้องขอและการตอบสนองต่อการไหลผ่านเราเตอร์ระดับกลางและเซิร์ฟเวอร์จำนวนมากที่ดำเนินการบาลานซ์โหลดการแคชการเข้ารหัสและการบีบอัด
คำขอ HTTP พื้นฐานประกอบด้วยคำกริยา (วิธีการ) และทรัพยากร (จุดสิ้นสุด) ด้านล่างนี้เป็นคำกริยา HTTP ทั่วไป:
| กริยา | คำอธิบาย | idempotent* | ปลอดภัย | ที่แคชได้ |
|---|---|---|---|---|
| รับ | อ่านทรัพยากร | ใช่ | ใช่ | ใช่ |
| โพสต์ | สร้างทรัพยากรหรือทริกเกอร์กระบวนการที่จัดการข้อมูล | เลขที่ | เลขที่ | ใช่ถ้าการตอบกลับมีข้อมูลความสดใหม่ |
| ใส่ | สร้างหรือแทนที่ทรัพยากร | ใช่ | เลขที่ | เลขที่ |
| แพทช์ | อัปเดตทรัพยากรบางส่วน | เลขที่ | เลขที่ | ใช่ถ้าการตอบกลับมีข้อมูลความสดใหม่ |
| ลบ | ลบทรัพยากร | ใช่ | เลขที่ | เลขที่ |
*สามารถเรียกได้หลายครั้งโดยไม่มีผลลัพธ์ที่แตกต่างกัน
HTTP เป็นโปรโตคอลเลเยอร์แอปพลิเคชันที่อาศัยโปรโตคอลระดับล่างเช่น TCP และ UDP
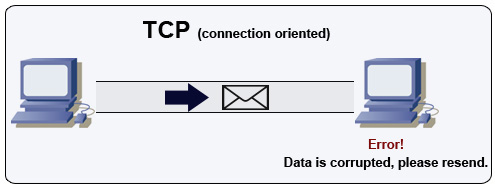
ที่มา: วิธีสร้างเกมผู้เล่นหลายคน
TCP เป็นโปรโตคอลที่มุ่งเน้นการเชื่อมต่อผ่านเครือข่าย IP การเชื่อมต่อถูกสร้างและยกเลิกโดยใช้การจับมือกัน แพ็คเก็ตทั้งหมดที่ส่งได้รับการรับประกันว่าจะไปถึงปลายทางในลำดับเดิมและไม่มีการทุจริตผ่าน:
หากผู้ส่งไม่ได้รับการตอบกลับที่ถูกต้องก็จะส่งแพ็กเก็ตอีกครั้ง หากมีการหมดเวลาหลายครั้งการเชื่อมต่อจะลดลง TCP ยังใช้การควบคุมการไหลและการควบคุมความแออัด การรับประกันเหล่านี้ทำให้เกิดความล่าช้าและโดยทั่วไปส่งผลให้มีการส่งผ่านที่มีประสิทธิภาพน้อยกว่า UDP
เพื่อให้แน่ใจว่าปริมาณงานสูงเว็บเซิร์ฟเวอร์สามารถเปิดการเชื่อมต่อ TCP จำนวนมากส่งผลให้มีการใช้หน่วยความจำสูง อาจมีราคาแพงที่จะมีการเชื่อมต่อแบบเปิดจำนวนมากระหว่างเธรดเว็บเซิร์ฟเวอร์และพูดว่าเซิร์ฟเวอร์ memcached การรวมการเชื่อมต่อสามารถช่วยได้นอกเหนือจากการเปลี่ยนไปใช้ UDP ในกรณีที่มี
TCP มีประโยชน์สำหรับแอปพลิเคชันที่ต้องการความน่าเชื่อถือสูง แต่มีเวลาน้อยกว่าที่สำคัญ ตัวอย่างบางส่วน ได้แก่ เว็บเซิร์ฟเวอร์ข้อมูลฐานข้อมูล SMTP, FTP และ SSH
ใช้ TCP ผ่าน UDP เมื่อ:
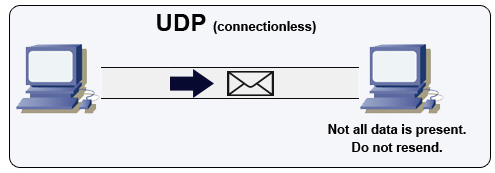
ที่มา: วิธีสร้างเกมผู้เล่นหลายคน
UDP ไม่มีการเชื่อมต่อ DataGrams (คล้ายกับแพ็คเก็ต) รับประกันได้เฉพาะในระดับดาต้าแกรม DataGrams อาจไปถึงปลายทางของพวกเขาตามคำสั่งหรือไม่เลย UDP ไม่รองรับการควบคุมความแออัด โดยไม่ต้องรับประกันว่าการสนับสนุน TCP UDP จะมีประสิทธิภาพมากกว่า
UDP สามารถออกอากาศส่งข้อมูลไปยังอุปกรณ์ทั้งหมดบนซับเน็ต สิ่งนี้มีประโยชน์กับ DHCP เนื่องจากไคลเอนต์ยังไม่ได้รับที่อยู่ IP ดังนั้นจึงป้องกันวิธีการให้ TCP สตรีมโดยไม่ต้องใช้ที่อยู่ IP
UDP มีความน่าเชื่อถือน้อยกว่า แต่ใช้งานได้ดีในกรณีการใช้งานจริงเช่น VoIP, วิดีโอแชทสตรีมมิ่งและเกมผู้เล่นหลายคนแบบเรียลไทม์
ใช้ UDP ผ่าน TCP เมื่อ:
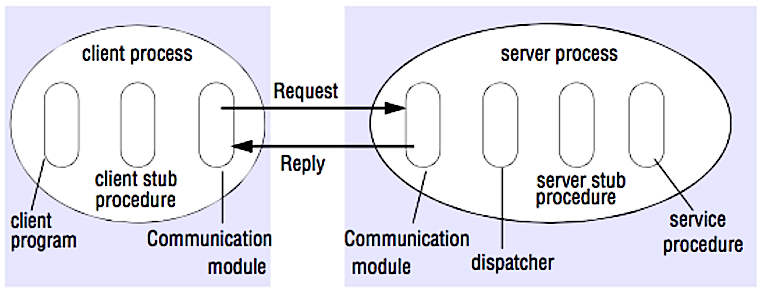
ที่มา: Crack the System Design Interview
ใน RPC ไคลเอนต์ทำให้เกิดขั้นตอนในการดำเนินการบนพื้นที่ที่อยู่อื่นโดยปกติจะเป็นเซิร์ฟเวอร์ระยะไกล ขั้นตอนนี้ถูกเข้ารหัสราวกับว่าเป็นการโทรขั้นตอนในท้องถิ่นโดยไม่ต้องใช้รายละเอียดของวิธีการสื่อสารกับเซิร์ฟเวอร์จากโปรแกรมไคลเอนต์ การโทรจากระยะไกลมักจะช้ากว่าและเชื่อถือได้น้อยกว่าการโทรในท้องถิ่นดังนั้นจึงมีประโยชน์ในการแยกความแตกต่างของการโทร RPC จากการโทรในท้องถิ่น เฟรมเวิร์ก RPC ยอดนิยม ได้แก่ Protobuf, Thrift และ Avro
RPC เป็นโปรโตคอลการตอบสนองการร้องขอ:
ตัวอย่างการโทร RPC:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC มุ่งเน้นไปที่การเปิดเผยพฤติกรรม RPCs มักใช้เพื่อเหตุผลด้านประสิทธิภาพด้วยการสื่อสารภายในเนื่องจากคุณสามารถโทรแบบแฮนด์ได้เพื่อให้พอดีกับกรณีการใช้งานของคุณได้ดีขึ้น
เลือกไลบรารีดั้งเดิม (aka SDK) เมื่อ:
HTTP APIs ต่อไป นี้ มีแนวโน้มที่จะใช้บ่อยขึ้นสำหรับ API สาธารณะ
REST เป็นรูปแบบสถาปัตยกรรมที่บังคับใช้โมเดลไคลเอนต์/เซิร์ฟเวอร์ที่ไคลเอนต์ทำหน้าที่ในชุดทรัพยากรที่จัดการโดยเซิร์ฟเวอร์ เซิร์ฟเวอร์ให้การเป็นตัวแทนของทรัพยากรและการกระทำที่สามารถจัดการหรือรับการแสดงทรัพยากรใหม่ การสื่อสารทั้งหมดจะต้องไร้สัญชาติและแคช
มีคุณสมบัติสี่ประการของอินเทอร์เฟซที่พักผ่อน:
ตัวอย่างที่เหลือ:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
REST มุ่งเน้นไปที่การเปิดเผยข้อมูล มันลดการมีเพศสัมพันธ์ระหว่างไคลเอนต์/เซิร์ฟเวอร์และมักจะใช้สำหรับ API HTTP สาธารณะ REST ใช้วิธีการทั่วไปและสม่ำเสมอมากขึ้นในการเปิดเผยทรัพยากรผ่าน URIS การเป็นตัวแทนผ่านส่วนหัวและการกระทำผ่านคำกริยาเช่นรับโพสต์ใส่ลบลบและแพทช์ การไร้สัญชาติการพักผ่อนเป็นสิ่งที่ดีสำหรับการปรับขนาดและการแบ่งพาร์ติชันในแนวนอน
| การดำเนินการ | อาร์พีซี | พักผ่อน |
|---|---|---|
| สมัครสมาชิก | โพสต์ /ลงทะเบียน | โพสต์ /บุคคล |
| ลาออก | โพสต์ /ลาออก - "personid": "1234" - | ลบ /บุคคล /1234 |
| อ่านบุคคล | รับ /readperson? personid = 1234 | รับ /บุคคล /1234 |
| อ่านรายการรายการของบุคคล | รับ /readusersitemslist? personid = 1234 | รับ /บุคคล/1234/รายการ |
| เพิ่มรายการลงในรายการของบุคคล | โพสต์ /addItemTouSerItemSlist - "personid": "1234"; "itemid": "456" - | โพสต์ /บุคคล/1234/รายการ - "itemid": "456" - |
| อัปเดตรายการ | โพสต์ /modifyItem - "itemid": "456"; "คีย์": "ค่า" - | ใส่ /รายการ /456 - "คีย์": "ค่า" - |
| ลบรายการ | โพสต์ /ลบ - "itemid": "456" - | ลบ /รายการ /456 |
แหล่งที่มา: คุณรู้หรือไม่ว่าทำไมคุณถึงชอบพักผ่อนมากกว่า RPC
ส่วนนี้สามารถใช้การอัปเดตบางอย่าง พิจารณามีส่วนร่วม!
ความปลอดภัยเป็นหัวข้อที่กว้าง เว้นแต่คุณจะมีประสบการณ์มากมายภูมิหลังด้านความปลอดภัยหรือการสมัครตำแหน่งที่ต้องใช้ความรู้ด้านความปลอดภัยคุณอาจไม่จำเป็นต้องรู้มากกว่าพื้นฐาน:
บางครั้งคุณจะถูกขอให้ทำการประมาณการ 'back-of-envelope' ตัวอย่างเช่นคุณอาจต้องกำหนดระยะเวลาในการสร้างภาพขนาดย่อภาพ 100 ภาพจากดิสก์หรือโครงสร้างข้อมูลที่จะใช้หน่วยความจำมากแค่ไหน พลังของสองตาราง และ หมายเลขแฝงโปรแกรมเมอร์ทุกคนควรรู้ ว่ามีการอ้างอิงที่มีประโยชน์
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
ตัวชี้วัดที่มีประโยชน์ตามตัวเลขด้านบน:
คำถามสัมภาษณ์การออกแบบระบบทั่วไปพร้อมลิงค์ไปยังแหล่งข้อมูลเกี่ยวกับวิธีการแก้ปัญหาแต่ละอย่าง
| คำถาม | อ้างอิง |
|---|---|
| ออกแบบบริการซิงค์ไฟล์เช่น Dropbox | youtube.com |
| ออกแบบเครื่องมือค้นหาเช่น Google | queue.acm.org stackexchange.com ardendertat.com stanford.edu |
| ออกแบบตัวรวบรวมข้อมูลเว็บที่ปรับขนาดได้เช่น Google | quora.com |
| ออกแบบ Google เอกสาร | code.google.com neil.fraser.name |
| ออกแบบร้านค้าคีย์-ค่าเช่น Redis | slideshare.net |
| ออกแบบระบบแคชเช่น Memcached | slideshare.net |
| ออกแบบระบบคำแนะนำเช่น Amazon's | hulu.com ijcai13.org |
| ออกแบบระบบเล็ก ๆ เช่น Bitly | n00tc0d3r.blogspot.com |
| ออกแบบแอพแชทเช่น whatsapp | highscalability.com |
| ออกแบบระบบแบ่งปันรูปภาพเช่น Instagram | highscalability.com highscalability.com |
| ออกแบบฟังก์ชั่นฟีดข่าว Facebook | quora.com quora.com slideshare.net |
| ออกแบบฟังก์ชั่นไทม์ไลน์ Facebook | facebook.com highscalability.com |
| ออกแบบฟังก์ชั่นการแชท Facebook | erlang-factory.com facebook.com |
| ออกแบบฟังก์ชั่นการค้นหากราฟเช่น Facebook | facebook.com facebook.com facebook.com |
| ออกแบบเครือข่ายการส่งเนื้อหาเช่น CloudFlare | figshare.com |
| ออกแบบระบบหัวข้อที่ได้รับความนิยมเช่น Twitter | michael-noll.com snikolov .wordpress.com |
| ออกแบบระบบการสร้าง ID แบบสุ่ม | blog.twitter.com github.com |
| ส่งคืนคำขอ K ด้านบนในช่วงเวลา | cs.ucsb.edu wpi.edu |
| ออกแบบระบบที่ให้บริการข้อมูลจากศูนย์ข้อมูลหลายแห่ง | highscalability.com |
| ออกแบบเกมการ์ดหลายคนออนไลน์ | indieflashblog.com buildNewGames.com |
| ออกแบบระบบเก็บขยะ | stuffwithstuff.com Washington.edu |
| ออกแบบตัว จำกัด อัตรา API | https://stripe.com/blog/ |
| ออกแบบตลาดหลักทรัพย์ (เช่น Nasdaq หรือ Binance) | ถนนเจน การใช้งาน Golang ไปดำเนินการ |
| เพิ่มคำถามการออกแบบระบบ | มีส่วนช่วย |
บทความเกี่ยวกับวิธีการออกแบบระบบโลกแห่งความเป็นจริง
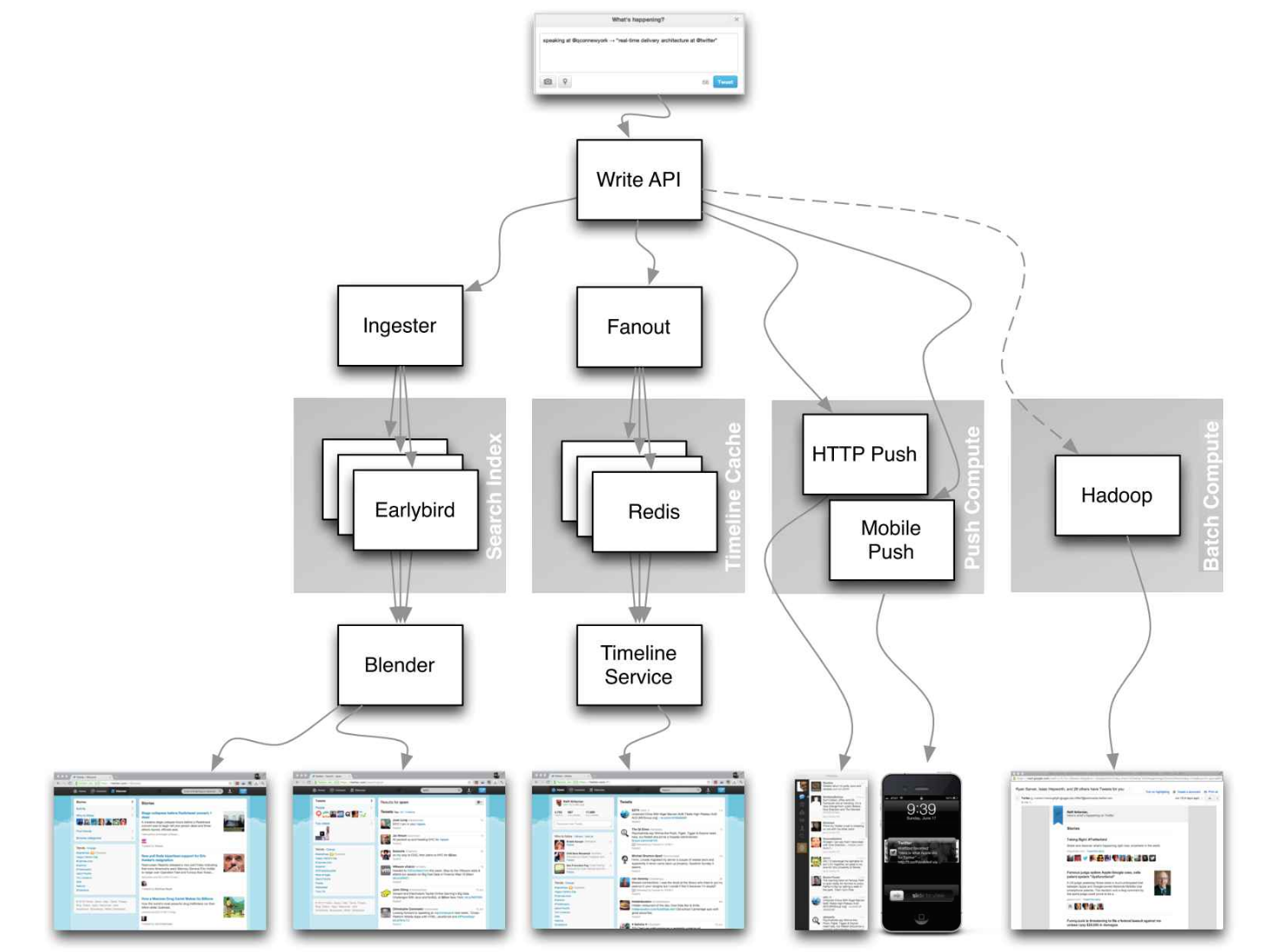
ที่มา: Twitter Timelines ในระดับ
อย่ามุ่งเน้นไปที่รายละเอียดที่มีความสำคัญสำหรับบทความต่อไปนี้แทน:
| พิมพ์ | ระบบ | อ้างอิง |
|---|---|---|
| การประมวลผลข้อมูล | MapReduce - การประมวลผลข้อมูลแบบกระจายจาก Google | research.google.com |
| การประมวลผลข้อมูล | Spark - การประมวลผลข้อมูลแบบกระจายจาก Databricks | slideshare.net |
| การประมวลผลข้อมูล | พายุ - การประมวลผลข้อมูลแบบกระจายจาก Twitter | slideshare.net |
| ที่เก็บข้อมูล | BigTable - ฐานข้อมูลเชิงคอลัมน์แบบกระจายจาก Google | harvard.edu |
| ที่เก็บข้อมูล | HBASE - การใช้งานโอเพนซอร์สของ BigTable | slideshare.net |
| ที่เก็บข้อมูล | Cassandra - ฐานข้อมูลเชิงคอลัมน์แบบกระจายจาก Facebook | slideshare.net |
| ที่เก็บข้อมูล | DynamoDB - Document-oriented database from Amazon | harvard.edu |
| Data store | MongoDB - Document-oriented database | slideshare.net |
| Data store | Spanner - Globally-distributed database from Google | research.google.com |
| Data store | Memcached - Distributed memory caching system | slideshare.net |
| Data store | Redis - Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) - Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| เบ็ดเตล็ด | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| เบ็ดเตล็ด | Dapper - Distributed systems tracing infrastructure | research.google.com |
| เบ็ดเตล็ด | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| เบ็ดเตล็ด | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | มีส่วนช่วย |
| บริษัท | Reference(s) |
|---|---|
| อเมซอน | Amazon architecture |
| Cinchcast | Producing 1,500 hours of audio every day |
| DataSift | Realtime datamining At 120,000 tweets per second |
| ดรอปบ็อกซ์ | How we've scaled Dropbox |
| อีเอสพีเอ็น | Operating At 100,000 duh nuh nuhs per second |
| Google architecture | |
| อินสตาแกรม | 14 million users, terabytes of photos What powers Instagram |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| เฟสบุ๊ค | Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers |
| ฟลิคเกอร์ | Flickr architecture |
| ตู้ไปรษณีย์ | From 0 to one million users in 6 weeks |
| เน็ตฟลิกซ์ | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| พินเทอเรสต์ | From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| พนักงานขาย | How they handle 1.3 billion transactions a day |
| กองล้น | Stack Overflow architecture |
| ทริปแอดไวเซอร์ | 40M visitors, 200M dynamic page views, 30TB data |
| ทัมเบลอร์ | 15 billion page views a month |
| ทวิตเตอร์ | Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second |
| อูเบอร์ | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| วอทส์แอพพ์ | The WhatsApp architecture Facebook bought for $19 billion |
| ยูทูบ | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? มีส่วนช่วย!
Credits and sources are provided throughout this repo.
ขอขอบคุณเป็นพิเศษสำหรับ:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


