Lihang
1.0.0
หนังสือเล่มนี้ตีพิมพ์ฉบับที่สองแล้ว การอัปเดตเนื้อหาทั้งหมดหลังเดือนพฤษภาคม 2019 หมายถึงการพิมพ์ครั้งแรกของฉบับพิมพ์ครั้งที่สอง
สำหรับเนื้อหาของฉบับพิมพ์ครั้งแรก โปรดดูที่ Release first_edition
[สารบัญ]
เพื่ออำนวยความสะดวกในการเรียนรู้ จึงได้รวบรวมคำอธิบายเครื่องมือบางอย่างไว้
หากคุณต้องการอ้างอิง Repo นี้:
รูปแบบ: SmirkCao, Lihang, (2018), GitHub repository, https://github.com/SmirkCao/Lihang
หรือ
@misc{SmirkCao,
author = {SmirkCao},
title = {Lihang},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/SmirkCao/Lihang}},
commit = {c5624a9bd757a5cc88e78b85b89e9221deb08270}
}
เนื้อหาส่วนนี้ไม่ตรงกับคำนำใน "วิธีการเรียนรู้เชิงสถิติ" เช่นกัน คำนำ ในหนังสือก็เขียนไว้อย่างดีและยกมาดังนี้
- ในส่วนของการเลือกเนื้อหา เราเน้นที่การแนะนำวิธีการที่สำคัญที่สุดและใช้กันทั่วไป โดยเฉพาะวิธีการที่เกี่ยวข้องกับปัญหา การจำแนกประเภทและการติดฉลาก
- พยายามใช้กรอบงานที่เป็นหนึ่งเดียวเพื่อหารือถึงวิธีการทั้งหมดเพื่อให้หนังสือทั้งเล่มไม่สูญเสียความเป็นระบบ
- ใช้ได้กับนักศึกษาวิทยาลัยและนักศึกษาระดับบัณฑิตศึกษาสาขาวิชาเอกการสืบค้นข้อมูลและการประมวลผลภาษาธรรมชาติ
อีกสิ่งหนึ่งที่ควรทราบคือประวัติการทำงานของผู้เขียน
ผู้เขียนมีส่วนร่วมในการวิจัยเกี่ยวกับการประมวลผลข้อมูลข้อความอัจฉริยะต่างๆ โดยใช้วิธีการเรียนรู้ทางสถิติ รวมถึงการประมวลผลภาษาธรรมชาติ การดึงข้อมูล และการขุดข้อมูลข้อความ
หากคุณใช้แบบจำลองของฉันในการค้นหาความคล้ายคลึงกัน หนังสือที่คล้ายกับหนังสือของ Mr. Li คือ "Semiconductor Optoelectronic Devices" เสียดายที่ไม่ได้อ่านซ้ำๆ สมัยเด็กๆ
ฉันหวังว่าในกระบวนการอ่านซ้ำ หนังสือทั้งเล่มจะหนาขึ้นและบางลง เอกสารและรหัสทั้งหมดในชุดนี้ เว้นแต่จะระบุไว้เป็นอย่างอื่น คำอธิบาย "ในหนังสือ" หมายถึง "วิธีการเรียนรู้ทางสถิติ" โดยครู Li Hang เนื้อหาในการอ้างอิงอื่น ๆ จะถูกเชื่อมโยงหากมีการอ้างอิง
ข้อมูลอ้างอิงบางรายการอยู่ใน Refs ซึ่งบางรายการมีประโยชน์มากสำหรับการทำความเข้าใจเนื้อหาของหนังสือ คำอธิบายและคำอธิบายของไฟล์เหล่านี้จะถูกเพิ่มใน Refs/README.md ที่สอดคล้องกับส่วนการอ้างอิง หมายเหตุบางประการเกี่ยวกับการอ้างอิงอื่นๆ ได้ถูกเพิ่มลงในเอกสารนี้ด้วย
เพื่ออำนวยความสะดวกในการดาวน์โหลดข้อมูลอ้างอิง จึงมีการเพิ่ม ref_downloader.sh ในระหว่างการตรวจสอบ 02 ซึ่งสามารถใช้เพื่อดาวน์โหลดข้อมูลอ้างอิงที่ระบุไว้ในหนังสือ กระบวนการอัปเดตจะค่อยๆ เสร็จสิ้นเมื่อการตรวจสอบ 02 ดำเนินไป
นอกจากนี้ หนังสือเล่มนี้ของอาจารย์หลี่ฮาง บางจริงๆ (รุ่นสองไม่บางแล้ว) แต่เกือบทุกประโยคก็ดึงประเด็นออกมาได้มากมายและควรค่าแก่การอ่านซ้ำแล้วซ้ำอีก
มีตารางสัญลักษณ์อยู่หลังสารบัญในหนังสือซึ่งอธิบายคำจำกัดความของสัญลักษณ์ ดังนั้นหากมีสัญลักษณ์ที่คุณไม่เข้าใจก็ดูได้จากตารางซึ่งมีดัชนีอยู่ด้านหลังหนังสือ และคุณสามารถใช้ดัชนีเพื่อค้นหาความหมายของสัญลักษณ์ที่เกี่ยวข้องที่ปรากฏในหนังสือได้ ใน Repo นี้ glossary_index.md จะได้รับการปรับปรุงเพื่อเพิ่มคำอธิบายให้กับสัญลักษณ์ที่เกี่ยวข้องและทำเครื่องหมายหมายเลขหน้าที่สอดคล้องกับสัญลักษณ์โดยตรง ความคืบหน้าจะได้รับการอัปเดตพร้อมกับการตรวจสอบ
หลังจากแต่ละอัลกอริทึมหรือตัวอย่าง จะมี ◼️ บ่งชี้ว่าอัลกอริทึมหรือตัวอย่างสิ้นสุดที่นี่ สิ่งนี้เรียกว่าสัญลักษณ์สิ้นสุดการพิสูจน์ คุณจะรู้ได้หากคุณอ่านวรรณกรรมเพิ่มเติม
เมื่ออ่าน เรามักจะมีคำถามเกี่ยวกับฐานของลอการิทึม บางคำถามที่สำคัญกว่านั้นจะถูกเน้นย้ำในหนังสือเล่มนี้ บางส่วนที่ไม่ได้เน้นสามารถเข้าใจได้จากบริบท นอกจากนี้ เนื่องจากมีสูตรในการเปลี่ยนฐาน จึงไม่สำคัญว่าฐานจะเป็นเท่าใด ความแตกต่างจึงอยู่ที่ค่าสัมประสิทธิ์คงที่ อย่างไรก็ตาม การเลือกฐานที่แตกต่างกันจะมีความหมายทางกายภาพและข้อควรพิจารณาในการแก้ปัญหา สำหรับการวิเคราะห์ปัญหานี้ คุณสามารถดูการอภิปรายเกี่ยวกับเอนโทรปีใน PRML 1.6 เพื่อทำความเข้าใจ
นอกจากนี้ ในเรื่องค่าสัมประสิทธิ์คงที่ในสูตร หากใช้วิธีแก้ปัญหาแบบวนซ้ำและบางครั้งสูตรถูกทำให้ง่ายขึ้นในระดับหนึ่ง ความเร็วของการลู่เข้าอาจดีขึ้น รายละเอียดสามารถค่อยๆเข้าใจได้ในทางปฏิบัติ
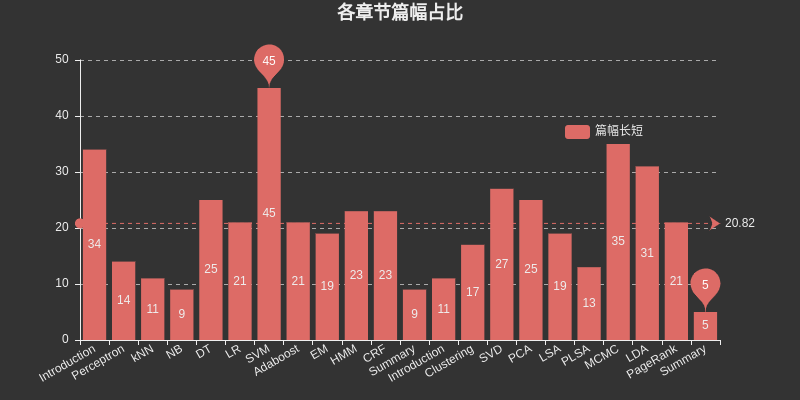
แทรกแผนภูมิที่นี่เพื่อแสดงรายการพื้นที่ที่แต่ละบทครอบครอง SVM ใช้พื้นที่ที่ใหญ่ที่สุดในบรรดาการเรียนรู้แบบมีผู้สอน MCMC ใช้พื้นที่ที่ใหญ่ที่สุดในบรรดาการเรียนรู้แบบไม่มีผู้ดูแล และ DT, HMM, CRF, SVD, PCA, LDA และ PageRank ยังครอบครองพื้นที่ที่ใหญ่ที่สุด
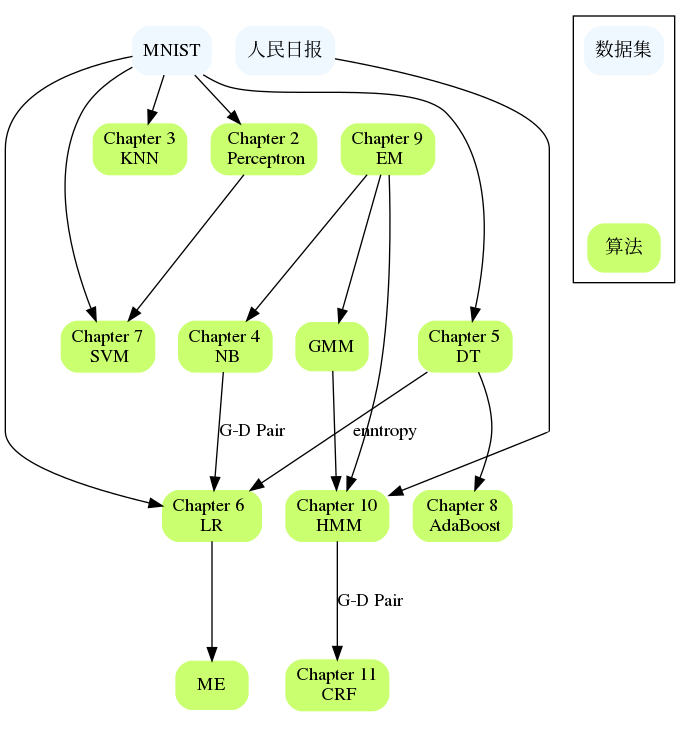
บทต่างๆ มีความเกี่ยวข้องกัน เช่น NB และ LR, DT และ AdaBoost, Perceptron และ SVM, HMM และ CRF เป็นต้น หากคุณประสบปัญหาในบทใหญ่ คุณสามารถตรวจสอบเนื้อหาของบทที่แล้วหรือตรวจสอบข้อมูลอ้างอิง โดยทั่วไปจะมีการอ้างอิงที่อธิบายปัญหาโดยละเอียดและอาจอธิบายว่าคุณติดขัดตรงไหน
การแนะนำ
องค์ประกอบสามประการของวิธีการเรียนรู้ทางสถิติ:
แบบอย่าง
กลยุทธ์
อัลกอริทึม
ฉบับพิมพ์ครั้งที่สองได้จัดโครงสร้างไดเร็กทอรีของบทนี้ใหม่เพื่อให้ชัดเจนยิ่งขึ้น
เพอร์เซปตรอน
เคเอ็นเอ็น
เอ็นบี
ดีที
แอลอาร์
เกี่ยวกับการศึกษาเอนโทรปีสูงสุด ขอแนะนำให้อ่านเอกสารอ้างอิง [1] ในบทนี้ Berger, 1996 ซึ่งมีประโยชน์ในการทำความเข้าใจตัวอย่างในหนังสือและเข้าใจหลักการของเอนโทรปีสูงสุด
แล้ว เหตุใด LR และ Maxent จึงถูกจัดอยู่ในบทเดียว?
ทั้งหมดอยู่ในแบบจำลองเชิงเส้นลอการิทึม
ทั้งสองสามารถใช้สำหรับการจำแนกไบนารีและหลายการจำแนกประเภท
โดยทั่วไป วิธีการเรียนรู้ของทั้งสองโมเดลจะใช้การประมาณค่าความน่าจะเป็นสูงสุด หรือการประมาณค่าความน่าจะเป็นสูงสุดแบบปกติ ซึ่งสามารถทำให้เป็นทางการได้ว่าเป็นปัญหาการปรับให้เหมาะสมที่ไม่มีข้อจำกัด และวิธีการแก้ไข ได้แก่ IIS, GD, BFGS เป็นต้น
มีการอธิบายไว้ดังต่อไปนี้ในการถดถอยโลจิสติก
แม้ว่าชื่อของมันจะเป็นแบบจำลองเชิงเส้นก็ตาม การถดถอยแบบลอจิสติกยังเป็นที่รู้จักในชื่อ logit regression, maximum-entropy Classifier (MaxEnt) หรือ log-linear classifier ในแบบจำลองนี้ ความน่าจะเป็นที่อธิบายไว้ ผลลัพธ์ที่เป็นไปได้ของการทดลองครั้งเดียวได้รับการสร้างแบบจำลองโดยใช้ฟังก์ชันลอจิสติก
นอกจากนี้ยังมีคำอธิบายดังกล่าว
การถดถอยโลจิสติกเป็นกรณีพิเศษของเอนโทรปีสูงสุดโดยมีป้ายกำกับสองรายการคือ +1 และ −1
ที่มาในบทนี้ใช้คุณสมบัติของ $yin mathcal{Y}={0,1}$
บางครั้งเราบอกว่าการถดถอยลอจิสติกส์เรียกว่า Maxent ใน NLP
สวีเอ็ม
การส่งเสริม
มาดูรายละเอียดกันตรงนี้ เพราะ HMM และ CRF มักจะนำไปสู่การแนะนำโมเดลกราฟิกที่น่าจะเป็นในภายหลัง ใน "Machine Learning, Zhou Zhihua" บท ของโมเดลกราฟิกความน่าจะเป็น ที่แยกจากกันจะถูกนำมาใช้เพื่อรวม HMM, MRF, CRF และเนื้อหาอื่นๆ นอกจากนี้ยังมีประเด็นที่เกี่ยวข้องมากมายตั้งแต่ HMM ถึง CRF เอง
ในบทแรกของหนังสือ มีการอธิบายการประยุกต์ใช้การเรียนรู้แบบมีผู้สอนสามประการ: การจำแนกประเภท การติดฉลาก และการถดถอย มีภาคผนวกในบทที่ 12 หนังสือเล่มนี้พิจารณาวิธีการเรียนรู้ของสองเล่มแรกเป็นหลัก ดังนั้นการแบ่งส่วนจึงมีความเหมาะสมที่นี่
อีเอ็ม
อัลกอริธึม EM เป็นอัลกอริธึมวนซ้ำที่ใช้สำหรับ การประมาณค่าความน่าจะเป็นสูงสุด ของพารามิเตอร์โมเดลความน่าจะเป็นที่มีตัวแปรที่ซ่อนอยู่ หรือการประมาณค่าความน่าจะเป็นหลังสูงสุด (การประมาณความน่าจะเป็นสูงสุดและการประมาณความน่าจะเป็นภายหลังสูงสุดในที่นี้คือ กลยุทธ์การเรียนรู้ )
หากตัวแปรของแบบจำลองความน่าจะเป็นเป็นตัวแปรที่สังเกตได้ทั้งหมด เมื่อได้รับข้อมูลแล้ว พารามิเตอร์ของแบบจำลองสามารถประมาณได้โดยตรงโดยใช้วิธีการประมาณค่าความน่าจะเป็นสูงสุดหรือวิธีการประมาณค่าแบบเบย์
โปรดทราบว่าหากคุณไม่เข้าใจคำอธิบายนี้ในหนังสือ โปรดดูส่วนการประมาณค่าพารามิเตอร์ของวิธี Naive Bayes ใน CH04
โค้ดส่วนนี้ใช้ BMM และ GMM ซึ่งคุ้มค่าที่จะดู
เกี่ยวกับ EM ยังไม่มีการเขียนเกี่ยวกับบทนี้มากนัก EM เป็นหนึ่งในสิบอัลกอริทึมยอดนิยม EM และ Hinton ตีพิมพ์บทความที่สองของ Capsule Network "Matrix Capsules with EM Routing" ที่ ICLR ในปี 2018
ใน CH22 อัลกอริทึม EM ถูกจัดประเภทเป็นวิธีการเรียนรู้ของเครื่องขั้นพื้นฐาน และไม่เกี่ยวข้องกับโมเดลการเรียนรู้ของเครื่องที่เฉพาะเจาะจง สามารถใช้สำหรับการเรียนรู้แบบไม่มีผู้ดูแล การเรียนรู้แบบมีผู้สอน และการเรียนรู้แบบกึ่งมีผู้ดูแล
อืม
ซีอาร์เอฟ
สรุป
บทนี้มีเพียงไม่กี่หน้า คุณสามารถพิจารณากิจวัตรการอ่านต่อไปนี้:
อ่านต่อกับบทที่ 1
หากคุณพบคำถามที่ไม่ชัดเจนในการศึกษาก่อนหน้านี้ โปรดอ่านบทนี้อีกครั้ง
อ่านบทนี้อย่างละเอียดและขยายจากบทนี้ไปยังบทอื่นๆ อีกสิบบท
โปรดทราบว่ามีรูปที่ 12.2 ในบทนี้ ซึ่งกล่าวถึงฟังก์ชันการสูญเสียลอจิสติกส์ที่นี่ควรกำหนดไว้ใน $cal{Y}={+1,-1}$ กำหนดไว้ที่ $cal{Y}={0,1}$ โปรดทราบที่นี่
หนังสือของครูหลี่ทำให้คุณได้รับสิ่งใหม่ๆ ทุกครั้งที่อ่านจริงๆ
ฉบับที่สองเพิ่มวิธีการเรียนรู้แบบไม่มีผู้ดูแลแปดวิธี ได้แก่ การจัดกลุ่ม การแบ่งแยกค่าเอกพจน์ การวิเคราะห์องค์ประกอบหลัก การวิเคราะห์ความหมายแฝง การวิเคราะห์ความหมายแฝงที่น่าจะเป็น วิธีมาร์คอฟเชนมอนติคาร์โล การจัดสรรไดริชเลต์แฝง และเพจแรงก์
การแนะนำ
การจัดกลุ่ม
แต่ละบทในหนังสือเล่มนี้ไม่ได้เป็นอิสระอย่างสมบูรณ์ ส่วนนี้หวังที่จะจัดระเบียบการเชื่อมต่อระหว่างบทและชุดข้อมูลที่เกี่ยวข้อง อัลกอริธึมถูกนำไปใช้ไกลแค่ไหนและชุดข้อมูลใดที่อัลกอริธึมสามารถรันได้ก็ถือเป็นแง่มุมหนึ่งเช่นกัน