
Repo นี้ประกอบด้วยคำถามและแบบฝึกหัดในหัวข้อทางเทคนิคต่างๆ ซึ่งบางครั้งเกี่ยวข้องกับ DevOps และ SRE
ขณะนี้มีแบบฝึกหัดและคำถาม 2,624 ข้อ
คุณสามารถใช้สิ่งเหล่านี้เพื่อเตรียมตัวสำหรับการสัมภาษณ์ แต่คำถามและแบบฝึกหัดส่วนใหญ่ไม่ได้เป็นตัวแทนของการสัมภาษณ์จริง โปรดอ่านหน้าคำถามที่พบบ่อยเพื่อดูรายละเอียดเพิ่มเติม
- หากคุณสนใจที่จะประกอบอาชีพวิศวกร DevOps การเรียนรู้แนวคิดบางอย่างที่กล่าวถึงในที่นี้จะมีประโยชน์ แต่คุณควรรู้ว่ามันไม่เกี่ยวกับการเรียนรู้หัวข้อและเทคโนโลยีทั้งหมดที่กล่าวถึงในพื้นที่เก็บข้อมูลนี้
คุณสามารถเพิ่มแบบฝึกหัดเพิ่มเติมได้โดยส่งคำขอดึง :) อ่านเกี่ยวกับแนวทางการบริจาคได้ที่นี่

DevOps | 
คอมไพล์ | 
เครือข่าย | 
ฮาร์ดแวร์ | 
คูเบอร์เนเตส |

การพัฒนาซอฟต์แวร์ | 
หลาม | 
ไป | 
ภาษาเพิร์ล | 
นิพจน์ทั่วไป |

คลาวด์ | 
AWS | 
สีฟ้า | 
แพลตฟอร์มคลาวด์ของ Google | 
โอเพ่นสแต็ค |

ระบบปฏิบัติการ | 
ลินุกซ์ | 
การจำลองเสมือน | 
DNS | 
การเขียนสคริปต์เชลล์ |

ฐานข้อมูล | 
SQL | 
มองโก | 
การทดสอบ | 
ข้อมูลขนาดใหญ่ |

ซีไอ/ซีดี | 
ใบรับรอง | 
ตู้คอนเทนเนอร์ | 
โอเพ่นชิฟท์ | 
พื้นที่จัดเก็บ |

เทอร์ราฟอร์ม | 
หุ่นเชิด | 
กระจาย | 
คำถามที่คุณสามารถถามได้ | 
เข้าใจได้ |

ความสามารถในการสังเกต | 
โพรมีธีอุส | 
วงกลมซีไอ | 
| 
กราฟาน่า |

อาร์โก้ | 
ทักษะด้านซอฟท์ | 
ความปลอดภัย | 
การออกแบบระบบ |

วิศวกรรมความโกลาหล | 
เบ็ดเตล็ด | 
ยืดหยุ่น | 
คาฟคา | 
โหนดJs |
เครือข่าย
โดยทั่วไปคุณต้องการอะไรในการสื่อสาร?
- ภาษากลาง (เพื่อให้ทั้งสองฝ่ายเข้าใจ)
- วิธีที่จะกล่าวถึงคนที่คุณต้องการสื่อสารด้วย
- A Connection (เพื่อให้เนื้อหาของการสื่อสารสามารถเข้าถึงผู้รับได้)
TCP/IP คืออะไร?
ชุดโปรโตคอลที่กำหนดวิธีที่อุปกรณ์ตั้งแต่สองเครื่องขึ้นไปสามารถสื่อสารระหว่างกันได้
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ TCP/IP โปรดอ่านที่นี่
อีเธอร์เน็ตคืออะไร?
อีเธอร์เน็ตหมายถึงประเภทเครือข่ายท้องถิ่น (LAN) ที่ใช้บ่อยที่สุดในปัจจุบัน LAN—ตรงกันข้ามกับ WAN (Wide Area Network) ซึ่งครอบคลุมพื้นที่ทางภูมิศาสตร์ที่ใหญ่กว่า—คือเครือข่ายคอมพิวเตอร์ที่เชื่อมต่อกันในพื้นที่ขนาดเล็ก เช่น สำนักงาน วิทยาเขตวิทยาลัย หรือแม้แต่ที่บ้านของคุณ
ที่อยู่ MAC คืออะไร? มันใช้ทำอะไร?
ที่อยู่ MAC คือหมายเลขประจำตัวหรือรหัสเฉพาะที่ใช้ระบุอุปกรณ์แต่ละเครื่องบนเครือข่าย
แพ็กเก็ตที่ส่งบนอีเธอร์เน็ตจะมาจากที่อยู่ MAC และส่งไปยังที่อยู่ MAC เสมอ หากอะแดปเตอร์เครือข่ายได้รับแพ็กเก็ต แสดงว่ากำลังเปรียบเทียบที่อยู่ MAC ปลายทางของแพ็กเก็ตกับที่อยู่ MAC ของอะแดปเตอร์เอง
ที่อยู่ MAC นี้จะใช้เมื่อใด: ff:ff:ff:ff:ff:ff
เมื่ออุปกรณ์ส่งแพ็กเก็ตไปยังที่อยู่ MAC ของการออกอากาศ (FF:FF:FF:FF:FF:FF) อุปกรณ์จะถูกส่งไปยังทุกสถานีบนเครือข่ายท้องถิ่น การออกอากาศอีเทอร์เน็ตใช้เพื่อแก้ไขที่อยู่ IP เป็นที่อยู่ MAC (โดย ARP) ที่ดาต้าลิงค์เลเยอร์
ที่อยู่ IP คืออะไร?
ที่อยู่อินเทอร์เน็ตโปรโตคอล (ที่อยู่ IP) คือป้ายตัวเลขที่กำหนดให้กับแต่ละอุปกรณ์ที่เชื่อมต่อกับเครือข่ายคอมพิวเตอร์ที่ใช้อินเทอร์เน็ตโปรโตคอลเพื่อการสื่อสาร ที่อยู่ IP ทำหน้าที่หลักสองหน้าที่: การระบุโฮสต์หรืออินเทอร์เฟซเครือข่าย และการระบุตำแหน่ง
อธิบายซับเน็ตมาสก์และยกตัวอย่าง
ซับเน็ตมาสก์คือหมายเลข 32 บิตที่ปกปิดที่อยู่ IP และแบ่งที่อยู่ IP ออกเป็นที่อยู่เครือข่ายและที่อยู่โฮสต์ Subnet Mask สร้างขึ้นโดยการตั้งค่าบิตเครือข่ายเป็น "1" ทั้งหมด และตั้งค่าบิตโฮสต์เป็น "0" ทั้งหมด ภายในเครือข่ายที่กำหนด จากที่อยู่โฮสต์ที่ใช้งานได้ทั้งหมด สองรายการจะถูกสงวนไว้สำหรับวัตถุประสงค์เฉพาะเสมอ และไม่สามารถจัดสรรให้กับโฮสต์ใดๆ ได้ ที่อยู่เหล่านี้เป็นที่อยู่แรกซึ่งสงวนไว้เป็นที่อยู่เครือข่าย (หรือที่เรียกว่า ID เครือข่าย) และที่อยู่สุดท้ายที่ใช้สำหรับการออกอากาศผ่านเครือข่าย
ตัวอย่าง
ที่อยู่ IP ส่วนตัวคืออะไร? ในสถานการณ์/การออกแบบระบบใดที่เราควรใช้
ที่อยู่ IP ส่วนตัวถูกกำหนดให้กับโฮสต์ในเครือข่ายเดียวกันเพื่อสื่อสารระหว่างกัน ตามที่ชื่อ "ส่วนตัว" แนะนำ อุปกรณ์ที่มีที่อยู่ IP ส่วนตัวที่กำหนดไม่สามารถเข้าถึงได้โดยอุปกรณ์จากเครือข่ายภายนอกใดๆ ตัวอย่างเช่น หากฉันอาศัยอยู่ในโฮสเทลและต้องการให้เพื่อนร่วมหอพักเข้าร่วมเซิร์ฟเวอร์เกมที่ฉันโฮสต์ไว้ ฉันจะขอให้พวกเขาเข้าร่วมผ่านที่อยู่ IP ส่วนตัวของเซิร์ฟเวอร์ของฉัน เนื่องจากเครือข่ายอยู่ในพื้นที่ของโฮสเทล ที่อยู่ IP สาธารณะคืออะไร? ในสถานการณ์/การออกแบบระบบใดที่เราควรใช้
ที่อยู่ IP สาธารณะคือที่อยู่ IP ที่เปิดเผยต่อสาธารณะ ในกรณีที่คุณโฮสต์เซิร์ฟเวอร์เกมที่คุณต้องการให้เพื่อนของคุณเข้าร่วม คุณจะต้องให้ที่อยู่ IP สาธารณะแก่เพื่อนของคุณเพื่อให้คอมพิวเตอร์ของพวกเขาสามารถระบุและค้นหาเครือข่ายและเซิร์ฟเวอร์ของคุณเพื่อให้การเชื่อมต่อเกิดขึ้น ครั้งหนึ่งที่คุณไม่จำเป็นต้องใช้ที่อยู่ IP สาธารณะคือในกรณีที่คุณกำลังเล่นกับเพื่อน ๆ ที่เชื่อมต่อกับเครือข่ายเดียวกันกับคุณ ในกรณีนี้ คุณจะใช้ที่อยู่ IP ส่วนตัว เพื่อให้ใครบางคนสามารถเชื่อมต่อกับเซิร์ฟเวอร์ของคุณที่อยู่ภายใน คุณจะต้องตั้งค่าพอร์ตไปข้างหน้าเพื่อแจ้งให้เราเตอร์ของคุณอนุญาตให้รับส่งข้อมูลจากโดเมนสาธารณะเข้าสู่เครือข่ายของคุณและในทางกลับกัน อธิบายแบบจำลอง OSI มีชั้นอะไรบ้าง? แต่ละชั้นมีหน้าที่รับผิดชอบอะไรบ้าง?
- แอปพลิเคชัน: ส่วนปลายผู้ใช้ (HTTP อยู่ที่นี่)
- การนำเสนอ: สร้างบริบทระหว่างเอนทิตีเลเยอร์แอปพลิเคชัน (การเข้ารหัสอยู่ที่นี่)
- เซสชัน: สร้าง จัดการ และยุติการเชื่อมต่อ
- การขนส่ง: ถ่ายโอนลำดับข้อมูลที่มีความยาวผันแปรจากต้นทางไปยังโฮสต์ปลายทาง (TCP & UDP อยู่ที่นี่)
- เครือข่าย: ถ่ายโอนดาตาแกรมจากเครือข่ายหนึ่งไปยังอีกเครือข่ายหนึ่ง (IP อยู่ที่นี่)
- ลิงค์ข้อมูล: ให้การเชื่อมโยงระหว่างสองโหนดที่เชื่อมต่อโดยตรง (MAC อยู่ที่นี่)
- ทางกายภาพ: ข้อมูลจำเพาะทางไฟฟ้าและทางกายภาพของการเชื่อมต่อข้อมูล (บิตอยู่ที่นี่)
คุณสามารถอ่านเพิ่มเติมเกี่ยวกับโมเดล OSI ได้ใน Penguintutor.com
สำหรับแต่ละสิ่งต่อไปนี้จะกำหนดว่าเลเยอร์ OSI นั้นเป็นของอะไร:- แก้ไขข้อผิดพลาด
- การกำหนดเส้นทางแพ็คเก็ต
- สายไฟและสัญญาณไฟฟ้า
- ที่อยู่ MAC
- ที่อยู่ IP
- ยุติการเชื่อมต่อ
- การจับมือ 3 ทาง
การแก้ไขข้อผิดพลาด - การกำหนดเส้นทางแพ็กเก็ตลิงก์ข้อมูล - สายเคเบิลเครือข่ายและสัญญาณไฟฟ้า - ที่อยู่ MAC ทางกายภาพ - ที่อยู่ IP ของลิงก์ข้อมูล - เครือข่าย ยุติการเชื่อมต่อ - เซสชัน จับมือ 3 ทาง-ขนส่ง คุณคุ้นเคยกับแผนการจัดส่งแบบใด
Unicast: การสื่อสารแบบหนึ่งต่อหนึ่งที่มีผู้ส่งและผู้รับหนึ่งราย
ออกอากาศ: ส่งข้อความถึงทุกคนในเครือข่าย ที่อยู่ ff:ff:ff:ff:ff:ff ใช้สำหรับการออกอากาศ โปรโตคอลทั่วไปสองโปรโตคอลที่ใช้การออกอากาศคือ ARP และ DHCP
Multicast: การส่งข้อความไปยังกลุ่มสมาชิก อาจเป็นแบบหนึ่งต่อกลุ่มหรือหลายกลุ่มต่อกลุ่มก็ได้
CSMA/ซีดีคืออะไร? ใช้ในเครือข่ายอีเธอร์เน็ตสมัยใหม่หรือไม่?
CSMA/CD ย่อมาจาก Carrier Sense Multiple Access / Collision Detection จุดสนใจหลักคือการจัดการการเข้าถึงสื่อ/บัสที่ใช้ร่วมกัน โดยมีเพียงโฮสต์เดียวเท่านั้นที่สามารถส่งข้อมูล ณ เวลาที่กำหนด
อัลกอริธึม CSMA/ซีดี:
ก่อนที่จะส่งเฟรม จะตรวจสอบว่าโฮสต์อื่นกำลังส่งเฟรมอยู่แล้วหรือไม่- ถ้าไม่มีใครส่งสัญญาณ มันก็จะเริ่มส่งสัญญาณเฟรม
- หากโฮสต์สองเครื่องส่งพร้อมกัน เราจะเกิดการชนกัน
- โฮสต์ทั้งสองหยุดส่งเฟรมและส่ง 'สัญญาณรบกวน' ให้ทุกคนแจ้งให้ทุกคนทราบว่าเกิดการชนกัน
- พวกเขากำลังรอเวลาสุ่มก่อนที่จะส่งอีกครั้ง
- เมื่อแต่ละโฮสต์รอเวลาสุ่ม พวกเขาจะพยายามส่งเฟรมอีกครั้ง และดังนั้นวงจรจึงเริ่มต้นอีกครั้ง
อธิบายอุปกรณ์เครือข่ายต่อไปนี้และความแตกต่างระหว่างอุปกรณ์เหล่านี้:
เราเตอร์ สวิตช์ และฮับเป็นอุปกรณ์เครือข่ายทั้งหมดที่ใช้ในการเชื่อมต่ออุปกรณ์ในเครือข่ายท้องถิ่น (LAN) อย่างไรก็ตาม อุปกรณ์แต่ละชิ้นทำงานแตกต่างกันและมีกรณีการใช้งานเฉพาะของตัวเอง ต่อไปนี้เป็นคำอธิบายโดยย่อของแต่ละอุปกรณ์และความแตกต่าง:
เราเตอร์: อุปกรณ์เครือข่ายที่เชื่อมต่อส่วนเครือข่ายหลายส่วนเข้าด้วยกัน ทำงานที่เลเยอร์เครือข่าย (เลเยอร์ 3) ของโมเดล OSI และใช้โปรโตคอลการกำหนดเส้นทางเพื่อกำหนดทิศทางข้อมูลระหว่างเครือข่าย เราเตอร์ใช้ที่อยู่ IP เพื่อระบุอุปกรณ์และกำหนดเส้นทางแพ็กเก็ตข้อมูลไปยังปลายทางที่ถูกต้อง- สวิตช์: อุปกรณ์เครือข่ายที่เชื่อมต่ออุปกรณ์หลายเครื่องบน LAN ทำงานที่ดาต้าลิงค์เลเยอร์ (เลเยอร์ 2) ของโมเดล OSI และใช้ที่อยู่ MAC เพื่อระบุอุปกรณ์และกำหนดเส้นทางแพ็กเก็ตข้อมูลไปยังปลายทางที่ถูกต้อง สวิตช์ช่วยให้อุปกรณ์บนเครือข่ายเดียวกันสามารถสื่อสารระหว่างกันได้อย่างมีประสิทธิภาพมากขึ้น และสามารถป้องกันการชนกันของข้อมูลที่อาจเกิดขึ้นเมื่ออุปกรณ์หลายเครื่องส่งข้อมูลพร้อมกัน
- ฮับ: อุปกรณ์เครือข่ายที่เชื่อมต่ออุปกรณ์หลายเครื่องผ่านสายเคเบิลเส้นเดียว และใช้เชื่อมต่ออุปกรณ์หลายเครื่องโดยไม่ต้องแบ่งเครือข่าย อย่างไรก็ตาม มันทำงานที่เลเยอร์กายภาพ (เลเยอร์ 1) ของโมเดล OSI ซึ่งต่างจากสวิตช์ตรง และเพียงกระจายแพ็กเก็ตข้อมูลไปยังอุปกรณ์ทั้งหมดที่เชื่อมต่ออยู่ ไม่ว่าอุปกรณ์นั้นจะเป็นผู้รับที่ตั้งใจไว้หรือไม่ก็ตาม ซึ่งหมายความว่าการชนกันของข้อมูลอาจเกิดขึ้นได้ และทำให้ประสิทธิภาพของเครือข่ายลดลง โดยทั่วไปฮับจะไม่ใช้ในการตั้งค่าเครือข่ายสมัยใหม่ เนื่องจากสวิตช์มีประสิทธิภาพมากกว่าและให้ประสิทธิภาพเครือข่ายที่ดีกว่า
"โดเมนการชนกัน" คืออะไร?
โดเมนการชนกันคือส่วนเครือข่ายที่อุปกรณ์อาจรบกวนซึ่งกันและกันโดยพยายามส่งข้อมูลในเวลาเดียวกัน เมื่ออุปกรณ์สองเครื่องส่งข้อมูลพร้อมกัน อาจทำให้เกิดการชนกัน ส่งผลให้ข้อมูลสูญหายหรือเสียหายได้ ในโดเมนการชนกัน อุปกรณ์ทั้งหมดใช้แบนด์วิธเดียวกัน และอุปกรณ์ใดๆ ก็ตามอาจรบกวนการส่งข้อมูลโดยอุปกรณ์อื่นได้ "โดเมนการออกอากาศ" คืออะไร?
โดเมนการออกอากาศคือส่วนเครือข่ายที่อุปกรณ์ทั้งหมดสามารถสื่อสารระหว่างกันโดยการส่งข้อความการออกอากาศ ข้อความบรอดแคสต์คือข้อความที่ส่งไปยังอุปกรณ์ทั้งหมดในเครือข่าย แทนที่จะเป็นอุปกรณ์เฉพาะ ในโดเมนการออกอากาศ อุปกรณ์ทั้งหมดสามารถรับและประมวลผลข้อความการออกอากาศได้ ไม่ว่าข้อความนั้นจะมีไว้สำหรับอุปกรณ์เหล่านั้นหรือไม่ก็ตาม คอมพิวเตอร์สามเครื่องเชื่อมต่อกับสวิตช์ มีโดเมนการชนกันกี่โดเมน? โดเมนออกอากาศมีกี่โดเมน?
โดเมนการชนกันสามโดเมนและโดเมนการออกอากาศหนึ่งโดเมน
เราเตอร์ทำงานอย่างไร?
เราเตอร์คืออุปกรณ์ทางกายภาพหรือเสมือนที่ส่งข้อมูลระหว่างเครือข่ายคอมพิวเตอร์ที่สลับแพ็กเก็ตตั้งแต่สองเครือข่ายขึ้นไป เราเตอร์ตรวจสอบที่อยู่ Internet Protocol (ที่อยู่ IP) ปลายทางของแพ็กเก็ตข้อมูลที่กำหนด คำนวณวิธีที่ดีที่สุดเพื่อให้ไปถึงปลายทาง จากนั้นส่งต่อตามนั้น
แนทคืออะไร?
การแปลที่อยู่เครือข่าย (NAT) เป็นกระบวนการที่ที่อยู่ IP ในเครื่องตั้งแต่หนึ่งรายการขึ้นไปถูกแปลเป็นที่อยู่ IP ทั่วโลกตั้งแต่ 1 รายการขึ้นไป และในทางกลับกัน เพื่อให้การเข้าถึงอินเทอร์เน็ตแก่โฮสต์ในเครื่อง
พร็อกซีคืออะไร? มันทำงานอย่างไร? เราต้องการมันเพื่ออะไร?
พร็อกซีเซิร์ฟเวอร์ทำหน้าที่เป็นเกตเวย์ระหว่างคุณกับอินเทอร์เน็ต เป็นเซิร์ฟเวอร์ตัวกลางที่แยกผู้ใช้ออกจากเว็บไซต์ที่พวกเขาเรียกดู
หากคุณใช้พร็อกซีเซิร์ฟเวอร์ การรับส่งข้อมูลอินเทอร์เน็ตจะไหลผ่านพร็อกซีเซิร์ฟเวอร์ไปยังที่อยู่ที่คุณร้องขอ จากนั้นคำขอจะกลับมาผ่านพร็อกซีเซิร์ฟเวอร์เดียวกันนั้น (มีข้อยกเว้นสำหรับกฎนี้) จากนั้นพร็อกซีเซิร์ฟเวอร์จะส่งต่อข้อมูลที่ได้รับจากเว็บไซต์ถึงคุณ
พร็อกซีเซิร์ฟเวอร์มีระดับการทำงาน ความปลอดภัย และความเป็นส่วนตัวที่แตกต่างกัน ขึ้นอยู่กับกรณีการใช้งาน ความต้องการ หรือนโยบายของบริษัท
ทีพีซีคืออะไร? มันทำงานอย่างไร? การจับมือ 3 ทางคืออะไร?
TCP 3-way handshake หรือ three-way handshake เป็นกระบวนการที่ใช้ในเครือข่าย TCP/IP เพื่อสร้างการเชื่อมต่อระหว่างเซิร์ฟเวอร์และไคลเอนต์
การจับมือแบบสามทางใช้เพื่อสร้างการเชื่อมต่อซ็อกเก็ต TCP เป็นหลัก มันใช้งานได้เมื่อ:
โหนดไคลเอนต์ส่งแพ็กเก็ตข้อมูล SYN ผ่านเครือข่าย IP ไปยังเซิร์ฟเวอร์บนเครือข่ายเดียวกันหรือเครือข่ายภายนอก วัตถุประสงค์ของแพ็กเก็ตนี้คือการถาม/อนุมานว่าเซิร์ฟเวอร์เปิดสำหรับการเชื่อมต่อใหม่หรือไม่- เซิร์ฟเวอร์เป้าหมายต้องมีพอร์ตเปิดที่สามารถยอมรับและเริ่มต้นการเชื่อมต่อใหม่ได้ เมื่อเซิร์ฟเวอร์ได้รับแพ็กเก็ต SYN จากโหนดไคลเอนต์ เซิร์ฟเวอร์จะตอบสนองและส่งกลับใบเสร็จรับเงินการยืนยัน – แพ็กเก็ต ACK หรือแพ็กเก็ต SYN/ACK
- โหนดไคลเอ็นต์ได้รับ SYN/ACK จากเซิร์ฟเวอร์และตอบสนองด้วยแพ็กเก็ต ACK
ความล่าช้าในการเดินทางไปกลับหรือเวลาไปกลับคืออะไร?
จากวิกิพีเดีย: "ระยะเวลาที่ใช้ในการส่งสัญญาณบวกระยะเวลาที่ใช้ในการรับทราบสัญญาณนั้นที่จะได้รับ"
คำถามพิเศษ: RTT ของ LAN คืออะไร
การจับมือ SSL ทำงานอย่างไร
SSL handshake เป็นกระบวนการที่สร้างการเชื่อมต่อที่ปลอดภัยระหว่างไคลเอนต์และเซิร์ฟเวอร์ ไคลเอ็นต์ส่งข้อความ Hello ของไคลเอ็นต์ไปยังเซิร์ฟเวอร์ ซึ่งรวมถึงเวอร์ชันของโปรโตคอล SSL/TLS ของไคลเอ็นต์ รายการอัลกอริธึมการเข้ารหัสที่ไคลเอ็นต์สนับสนุน และค่าสุ่ม- เซิร์ฟเวอร์ตอบกลับด้วยข้อความ Server Hello ซึ่งรวมถึงเวอร์ชันของโปรโตคอล SSL/TLS ของเซิร์ฟเวอร์ ค่าสุ่ม และรหัสเซสชัน
- เซิร์ฟเวอร์ส่งข้อความใบรับรองซึ่งประกอบด้วยใบรับรองของเซิร์ฟเวอร์
- เซิร์ฟเวอร์ส่งข้อความ Server Hello Done ซึ่งระบุว่าเซิร์ฟเวอร์ส่งข้อความสำหรับเฟส Hello ของเซิร์ฟเวอร์เสร็จแล้ว
- ไคลเอ็นต์ส่งข้อความ Client Key Exchange ซึ่งมีคีย์สาธารณะของไคลเอ็นต์
- ไคลเอนต์ส่งข้อความ Change Cipher Spec ซึ่งจะแจ้งให้เซิร์ฟเวอร์ทราบว่าไคลเอนต์กำลังจะส่งข้อความที่เข้ารหัสด้วยข้อมูลจำเพาะการเข้ารหัสใหม่
- ไคลเอ็นต์ส่งข้อความ Encrypted Handshake ซึ่งมีข้อมูลลับเบื้องต้นที่เข้ารหัสด้วยคีย์สาธารณะของเซิร์ฟเวอร์
- เซิร์ฟเวอร์ส่งข้อความ Change Cipher Spec ซึ่งจะแจ้งให้ไคลเอ็นต์ทราบว่าเซิร์ฟเวอร์กำลังจะส่งข้อความที่เข้ารหัสด้วยข้อกำหนดการเข้ารหัสใหม่
- เซิร์ฟเวอร์ส่งข้อความ Encrypted Handshake ซึ่งประกอบด้วยข้อมูลลับเบื้องต้นที่เข้ารหัสด้วยรหัสสาธารณะของไคลเอ็นต์
- ไคลเอนต์และเซิร์ฟเวอร์สามารถแลกเปลี่ยนข้อมูลแอปพลิเคชันได้แล้ว
TCP และ UDP แตกต่างกันอย่างไร?
TCP สร้างการเชื่อมต่อระหว่างไคลเอนต์และเซิร์ฟเวอร์เพื่อรับประกันลำดับของแพ็คเกจ ในทางกลับกัน UDP ไม่ได้สร้างการเชื่อมต่อระหว่างไคลเอนต์และเซิร์ฟเวอร์ และไม่จัดการลำดับแพ็คเกจ สิ่งนี้ทำให้ UDP มีน้ำหนักเบากว่า TCP และเป็นตัวเลือกที่สมบูรณ์แบบสำหรับบริการเช่นการสตรีม
Penguintutor.com ให้คำอธิบายที่ดี
คุณคุ้นเคยกับโปรโตคอล TCP/IP ใด
อธิบาย "เกตเวย์เริ่มต้น"
เกตเวย์เริ่มต้นทำหน้าที่เป็นจุดเข้าใช้งานหรือเราเตอร์ IP ที่คอมพิวเตอร์ในเครือข่ายใช้เพื่อส่งข้อมูลไปยังคอมพิวเตอร์ในเครือข่ายอื่นหรืออินเทอร์เน็ต
เออาร์พีคืออะไร? มันทำงานอย่างไร?
ARP ย่อมาจาก Address Resolution Protocol เมื่อคุณพยายามส่ง Ping ไปยังที่อยู่ IP บนเครือข่ายท้องถิ่นของคุณ เช่น 192.168.1.1 ระบบของคุณจะต้องเปลี่ยนที่อยู่ IP 192.168.1.1 ให้เป็นที่อยู่ MAC สิ่งนี้เกี่ยวข้องกับการใช้ ARP เพื่อแก้ไขที่อยู่ จึงเป็นที่มาของชื่อ
ระบบจะเก็บตารางค้นหา ARP ไว้ซึ่งเก็บข้อมูลเกี่ยวกับที่อยู่ IP ที่เกี่ยวข้องกับที่อยู่ MAC ใด เมื่อพยายามส่งแพ็กเก็ตไปยังที่อยู่ IP ระบบจะดูตารางนี้ก่อนเพื่อดูว่ารู้ที่อยู่ MAC อยู่แล้วหรือไม่ หากมีค่าแคชไว้ ระบบจะไม่ใช้ ARP
ทีทีแอลคืออะไร? ช่วยป้องกันอะไรได้บ้าง?
TTL (Time to Live) คือค่าในแพ็กเก็ต IP (Internet Protocol) ที่กำหนดจำนวนฮอปหรือเราเตอร์ที่แพ็กเก็ตสามารถเดินทางได้ก่อนที่จะถูกทิ้ง แต่ละครั้งที่เราเตอร์ส่งต่อแพ็กเก็ต ค่า TTL จะลดลงหนึ่งค่า เมื่อค่า TTL ถึงศูนย์ แพ็กเก็ตจะหายไป และข้อความ ICMP (Internet Control Message Protocol) จะถูกส่งกลับไปยังผู้ส่งเพื่อระบุว่าแพ็กเก็ตหมดอายุแล้ว- TTL ใช้เพื่อป้องกันไม่ให้แพ็กเก็ตไหลเวียนอย่างไม่มีกำหนดในเครือข่าย ซึ่งอาจทำให้เกิดความแออัดและลดประสิทธิภาพของเครือข่าย
- นอกจากนี้ยังช่วยป้องกันไม่ให้แพ็กเก็ตติดอยู่ในลูปการกำหนดเส้นทาง โดยที่แพ็กเก็ตจะเดินทางอย่างต่อเนื่องระหว่างเราเตอร์ชุดเดียวกันโดยไม่ต้องไปถึงจุดหมายปลายทาง
- นอกจากนี้ TTL ยังสามารถใช้เพื่อช่วยตรวจจับและป้องกันการโจมตีด้วยการปลอมแปลง IP โดยที่ผู้โจมตีพยายามปลอมแปลงเป็นอุปกรณ์อื่นบนเครือข่ายโดยใช้ที่อยู่ IP ปลอมหรือปลอม ด้วยการจำกัดจำนวนฮ็อปที่แพ็กเก็ตสามารถเดินทางได้ TTL สามารถช่วยป้องกันไม่ให้แพ็กเก็ตถูกส่งไปยังปลายทางที่ไม่ถูกต้องตามกฎหมาย
DHCP คืออะไร? มันทำงานอย่างไร?
ย่อมาจาก Dynamic Host Configuration Protocol และจัดสรรที่อยู่ IP, ซับเน็ตมาสก์ และเกตเวย์ให้กับโฮสต์ นี่คือวิธีการทำงาน:
- โฮสต์เมื่อเข้าสู่เครือข่ายจะออกอากาศข้อความเพื่อค้นหาเซิร์ฟเวอร์ DHCP (DHCP DISCOVER)
- ข้อความข้อเสนอจะถูกส่งกลับโดยเซิร์ฟเวอร์ DHCP เป็นแพ็กเก็ตที่มีเวลาการเช่า ซับเน็ตมาสก์ ที่อยู่ IP ฯลฯ (ข้อเสนอ DHCP)
- ขึ้นอยู่กับข้อเสนอที่ยอมรับ ไคลเอนต์ส่งการตอบกลับเพื่อแจ้งให้เซิร์ฟเวอร์ DHCP ทั้งหมดทราบ (คำขอ DHCP)
- เซิร์ฟเวอร์ส่งการตอบรับ (DHCP ACK)
อ่านเพิ่มเติมได้ที่นี่
คุณสามารถมีเซิร์ฟเวอร์ DHCP สองตัวบนเครือข่ายเดียวกันได้หรือไม่? มันทำงานอย่างไร?
เป็นไปได้ที่จะมีเซิร์ฟเวอร์ DHCP สองตัวบนเครือข่ายเดียวกัน อย่างไรก็ตาม ไม่แนะนำ และสิ่งสำคัญคือต้องกำหนดค่าอย่างระมัดระวังเพื่อป้องกันความขัดแย้งและปัญหาการกำหนดค่า
เมื่อมีการกำหนดค่าเซิร์ฟเวอร์ DHCP สองตัวบนเครือข่ายเดียวกัน มีความเสี่ยงที่เซิร์ฟเวอร์ทั้งสองจะกำหนดที่อยู่ IP และการตั้งค่าการกำหนดค่าเครือข่ายอื่นๆ ให้กับอุปกรณ์เดียวกัน ซึ่งอาจทำให้เกิดข้อขัดแย้งและปัญหาการเชื่อมต่อได้ นอกจากนี้ หากเซิร์ฟเวอร์ DHCP ได้รับการกำหนดค่าด้วยการตั้งค่าเครือข่ายหรือตัวเลือกที่แตกต่างกัน อุปกรณ์บนเครือข่ายอาจได้รับการตั้งค่าการกำหนดค่าที่ขัดแย้งหรือไม่สอดคล้องกัน- อย่างไรก็ตาม ในบางกรณี อาจจำเป็นต้องมีเซิร์ฟเวอร์ DHCP สองตัวบนเครือข่ายเดียวกัน เช่น ในเครือข่ายขนาดใหญ่ที่เซิร์ฟเวอร์ DHCP ตัวเดียวอาจไม่สามารถรองรับคำขอทั้งหมดได้ ในกรณีเช่นนี้ เซิร์ฟเวอร์ DHCP สามารถกำหนดค่าให้ให้บริการช่วงที่อยู่ IP ที่แตกต่างกันหรือเครือข่ายย่อยที่แตกต่างกันได้ เพื่อไม่ให้รบกวนซึ่งกันและกัน
SSL tunneling คืออะไร? มันทำงานอย่างไร?
- SSL (Secure Sockets Layer) tunneling เป็นเทคนิคที่ใช้เพื่อสร้างการเชื่อมต่อที่ปลอดภัยและเข้ารหัสระหว่างจุดปลายสองจุดผ่านเครือข่ายที่ไม่ปลอดภัย เช่น อินเทอร์เน็ต ทันเนล SSL ถูกสร้างขึ้นโดยการห่อหุ้มการรับส่งข้อมูลภายในการเชื่อมต่อ SSL ซึ่งให้การรักษาความลับ ความสมบูรณ์ และการรับรองความถูกต้อง
ต่อไปนี้เป็นวิธีการทำงานของอุโมงค์ SSL:
ไคลเอ็นต์เริ่มต้นการเชื่อมต่อ SSL ไปยังเซิร์ฟเวอร์ ซึ่งเกี่ยวข้องกับกระบวนการแฮนด์เชคเพื่อสร้างเซสชัน SSL- เมื่อสร้างเซสชัน SSL แล้ว ไคลเอนต์และเซิร์ฟเวอร์จะเจรจาต่อรองพารามิเตอร์การเข้ารหัส เช่น อัลกอริธึมการเข้ารหัสและความยาวของคีย์ จากนั้นแลกเปลี่ยนใบรับรองดิจิทัลเพื่อตรวจสอบความถูกต้องซึ่งกันและกัน
- จากนั้นไคลเอ็นต์จะส่งการรับส่งข้อมูลผ่านอุโมงค์ SSL ไปยังเซิร์ฟเวอร์ ซึ่งจะถอดรหัสการรับส่งข้อมูลและส่งต่อไปยังปลายทาง
- เซิร์ฟเวอร์ส่งการรับส่งข้อมูลกลับผ่านอุโมงค์ SSL ไปยังไคลเอนต์ ซึ่งจะถอดรหัสการรับส่งข้อมูลและส่งต่อไปยังแอปพลิเคชัน
ซ็อกเก็ตคืออะไร? คุณสามารถดูรายการซ็อกเก็ตในระบบของคุณได้ที่ไหน?
ซ็อกเก็ตเป็นจุดสิ้นสุดของซอฟต์แวร์ที่ช่วยให้สามารถสื่อสารสองทางระหว่างกระบวนการต่างๆ บนเครือข่าย ซ็อกเก็ตจัดเตรียมอินเทอร์เฟซมาตรฐานสำหรับการสื่อสารผ่านเครือข่าย ช่วยให้แอปพลิเคชันสามารถส่งและรับข้อมูลผ่านเครือข่ายได้ หากต้องการดูรายการซ็อกเก็ตที่เปิดอยู่บนระบบ Linux: netstat -an- คำสั่งนี้แสดงรายการซ็อกเก็ตที่เปิดอยู่ทั้งหมด พร้อมด้วยโปรโตคอล ที่อยู่ภายในเครื่อง ที่อยู่ต่างประเทศ และรัฐ
IPv6 คืออะไร? เหตุใดเราจึงควรพิจารณาใช้หากเรามี IPv4
- IPv6 (Internet Protocol เวอร์ชัน 6) คือเวอร์ชันล่าสุดของ Internet Protocol (IP) ซึ่งใช้ในการระบุและสื่อสารกับอุปกรณ์บนเครือข่าย ที่อยู่ IPv6 เป็นที่อยู่ 128 บิต และแสดงในรูปแบบเลขฐานสิบหก เช่น 2001:0db8:85a3:0000:0000:8a2e:0370:7334
มีสาเหตุหลายประการที่เราควรพิจารณาใช้ IPv6 บน IPv4:
พื้นที่ที่อยู่: IPv4 มีพื้นที่ที่อยู่จำกัด ซึ่งถูกใช้จนหมดแล้วในหลายส่วนของโลก IPv6 มอบพื้นที่ที่อยู่ที่ใหญ่กว่ามาก ทำให้มีที่อยู่ IP ที่ไม่ซ้ำกันนับล้านล้านรายการ- ความปลอดภัย: IPv6 มีการรองรับ IPsec ในตัว ซึ่งให้การเข้ารหัสจากต้นทางถึงปลายทางและการรับรองความถูกต้องสำหรับการรับส่งข้อมูลเครือข่าย
- ประสิทธิภาพ: IPv6 มีคุณสมบัติที่สามารถช่วยปรับปรุงประสิทธิภาพเครือข่าย เช่น การกำหนดเส้นทางแบบหลายผู้รับ ซึ่งช่วยให้แพ็กเก็ตเดียวสามารถส่งไปยังปลายทางหลายแห่งพร้อมกันได้
- การกำหนดค่าเครือข่ายที่ง่ายขึ้น: IPv6 มีคุณสมบัติที่ทำให้การกำหนดค่าเครือข่ายง่ายขึ้น เช่น การกำหนดค่าอัตโนมัติแบบไร้สถานะ ซึ่งช่วยให้อุปกรณ์สามารถกำหนดค่าที่อยู่ IPv6 ของตนเองได้โดยอัตโนมัติโดยไม่ต้องใช้เซิร์ฟเวอร์ DHCP
- การสนับสนุนด้านการเคลื่อนที่ที่ดีขึ้น: IPv6 มีคุณลักษณะที่สามารถปรับปรุงการสนับสนุนด้านการเคลื่อนที่ได้ เช่น Mobile IPv6 ซึ่งช่วยให้อุปกรณ์สามารถรักษาที่อยู่ IPv6 ของตนไว้ได้ในขณะที่เคลื่อนที่ระหว่างเครือข่ายต่างๆ
วีแลนคืออะไร?
- VLAN (Virtual Local Area Network) คือเครือข่ายลอจิคัลที่จัดกลุ่มชุดอุปกรณ์บนเครือข่ายทางกายภาพเข้าด้วยกัน โดยไม่คำนึงถึงตำแหน่งทางกายภาพของอุปกรณ์เหล่านั้น VLAN ถูกสร้างขึ้นโดยการกำหนดค่าสวิตช์เครือข่ายเพื่อกำหนด VLAN ID เฉพาะให้กับเฟรมที่ส่งโดยอุปกรณ์ที่เชื่อมต่อกับพอร์ตหรือกลุ่มพอร์ตเฉพาะบนสวิตช์
มธ. คืออะไร?
MTU ย่อมาจาก Maximum Transmission Unit เป็นขนาดของ PDU (หน่วยข้อมูลโปรโตคอล) ที่ใหญ่ที่สุดที่สามารถส่งได้ในธุรกรรมเดียว
จะเกิดอะไรขึ้นหากคุณส่งแพ็คเก็ตที่ใหญ่กว่า MTU?
ด้วยโปรโตคอล IPv4 เราเตอร์สามารถกระจาย PDU และส่ง PDU ที่กระจัดกระจายทั้งหมดผ่านธุรกรรม
ด้วยโปรโตคอล IPv6 จะทำให้เกิดข้อผิดพลาดกับคอมพิวเตอร์ของผู้ใช้
จริงหรือเท็จ? Ping กำลังใช้ UDP เนื่องจากไม่สนใจการเชื่อมต่อที่เชื่อถือได้
เท็จ. จริงๆ แล้ว Ping กำลังใช้ ICMP (Internet Control Message Protocol) ซึ่งเป็นโปรโตคอลเครือข่ายที่ใช้ในการส่งข้อความวินิจฉัยและควบคุมข้อความที่เกี่ยวข้องกับการสื่อสารในเครือข่าย
SDN คืออะไร?
SDN ย่อมาจาก Software-Defined Networking เป็นแนวทางในการจัดการเครือข่ายที่เน้นการรวมศูนย์การควบคุมเครือข่าย ช่วยให้ผู้ดูแลระบบสามารถจัดการพฤติกรรมเครือข่ายผ่านซอฟต์แวร์ที่เป็นนามธรรม- ในเครือข่ายแบบดั้งเดิม อุปกรณ์เครือข่าย เช่น เราเตอร์ สวิตช์ และไฟร์วอลล์ได้รับการกำหนดค่าและจัดการแยกกัน โดยใช้ซอฟต์แวร์พิเศษหรืออินเทอร์เฟซบรรทัดคำสั่ง ในทางตรงกันข้าม SDN จะแยกส่วนควบคุมเครือข่ายออกจากส่วนข้อมูล ทำให้ผู้ดูแลระบบสามารถจัดการพฤติกรรมเครือข่ายผ่านตัวควบคุมซอฟต์แวร์แบบรวมศูนย์
ICMP คืออะไร? มันใช้ทำอะไร?
- ICMP ย่อมาจาก Internet Control Message Protocol เป็นโปรโตคอลที่ใช้เพื่อวัตถุประสงค์ในการวินิจฉัยและควบคุมในเครือข่าย IP เป็นส่วนหนึ่งของชุด Internet Protocol ซึ่งทำงานที่เลเยอร์เครือข่าย
ข้อความ ICMP ใช้เพื่อวัตถุประสงค์ที่หลากหลาย ได้แก่:
การรายงานข้อผิดพลาด: ข้อความ ICMP ใช้เพื่อรายงานข้อผิดพลาดที่เกิดขึ้นในเครือข่าย เช่น แพ็กเก็ตที่ไม่สามารถส่งไปยังปลายทางได้- ปิง: ICMP ใช้เพื่อส่งข้อความปิง ซึ่งใช้เพื่อทดสอบว่าโฮสต์หรือเครือข่ายสามารถเข้าถึงได้หรือไม่ และเพื่อวัดเวลาไปกลับของแพ็กเก็ต
- การค้นพบ Path MTU: ICMP ใช้เพื่อค้นหา Maximum Transmission Unit (MTU) ของพาธ ซึ่งเป็นขนาดแพ็กเก็ตที่ใหญ่ที่สุดที่สามารถส่งได้โดยไม่มีการกระจายตัว
- Traceroute: ICMP ถูกใช้โดยยูทิลิตี้ Traceroute เพื่อติดตามเส้นทางที่แพ็กเก็ตใช้ผ่านเครือข่าย
- การค้นพบเราเตอร์: ICMP ใช้เพื่อค้นหาเราเตอร์ในเครือข่าย
แนทคืออะไร? มันทำงานอย่างไร?
NAT ย่อมาจาก Network Address Translation เป็นวิธีการจับคู่ที่อยู่ส่วนตัวในพื้นที่หลายแห่งกับที่อยู่สาธารณะก่อนที่จะถ่ายโอนข้อมูล องค์กรที่ต้องการให้อุปกรณ์หลายเครื่องใช้ที่อยู่ IP เดียว ให้ใช้ NAT เช่นเดียวกับเราเตอร์ตามบ้านส่วนใหญ่ ตัวอย่างเช่น IP ส่วนตัวของคอมพิวเตอร์ของคุณอาจเป็น 192.168.1.100 แต่เราเตอร์ของคุณจับคู่การรับส่งข้อมูลกับ IP สาธารณะ (เช่น 1.1.1.1) อุปกรณ์ใดๆ บนอินเทอร์เน็ตจะเห็นการรับส่งข้อมูลที่มาจาก IP สาธารณะของคุณ (1.1.1.1) แทนที่จะเป็น IP ส่วนตัวของคุณ (192.168.1.100)
หมายเลขพอร์ตใดที่ใช้ในแต่ละโปรโตคอลต่อไปนี้:- สสส
- SMTP
- HTTP
- DNS
- HTTPS
- เอฟทีพี
- เอสเอฟทีพี
สสช - 22- เอสเอ็มทีพี - 25
- HTTP - 80
- DNS - 53
- HTTPS - 443
- เอฟทีพี - 21
- เอสเอฟทีพี - 22
ปัจจัยใดที่ส่งผลต่อประสิทธิภาพของเครือข่าย?
ปัจจัยหลายประการอาจส่งผลต่อประสิทธิภาพของเครือข่าย ได้แก่:
แบนด์วิดท์: แบนด์วิธที่มีอยู่ของการเชื่อมต่อเครือข่ายอาจส่งผลกระทบอย่างมากต่อประสิทธิภาพการทำงาน เครือข่ายที่มีแบนด์วิธจำกัดอาจมีอัตราการถ่ายโอนข้อมูลช้า เวลาแฝงสูง และการตอบสนองไม่ดี- เวลาแฝง: เวลาแฝงหมายถึงความล่าช้าที่เกิดขึ้นเมื่อข้อมูลถูกส่งจากจุดหนึ่งในเครือข่ายไปยังอีกจุดหนึ่ง เวลาแฝงที่สูงอาจส่งผลให้ประสิทธิภาพของเครือข่ายช้าลง โดยเฉพาะอย่างยิ่งสำหรับแอปพลิเคชันแบบเรียลไทม์ เช่น การประชุมทางวิดีโอและเกมออนไลน์
- ความแออัดของเครือข่าย: เมื่อมีอุปกรณ์จำนวนมากเกินไปใช้เครือข่ายในเวลาเดียวกัน ความแออัดของเครือข่ายอาจเกิดขึ้นได้ ส่งผลให้อัตราการถ่ายโอนข้อมูลช้าลงและประสิทธิภาพของเครือข่ายไม่ดี
- การสูญเสียแพ็คเก็ต: การสูญเสียแพ็คเก็ตเกิดขึ้นเมื่อแพ็คเก็ตข้อมูลหลุดระหว่างการส่ง ซึ่งอาจส่งผลให้ความเร็วเครือข่ายช้าลงและประสิทธิภาพเครือข่ายโดยรวมลดลง
- โทโพโลยีเครือข่าย: รูปแบบทางกายภาพของเครือข่าย รวมถึงตำแหน่งของสวิตช์ เราเตอร์ และอุปกรณ์เครือข่ายอื่นๆ อาจส่งผลกระทบต่อประสิทธิภาพของเครือข่าย
- โปรโตคอลเครือข่าย: โปรโตคอลเครือข่ายที่แตกต่างกันมีลักษณะการทำงานที่แตกต่างกัน ซึ่งอาจส่งผลกระทบต่อประสิทธิภาพของเครือข่าย ตัวอย่างเช่น TCP เป็นโปรโตคอลที่เชื่อถือได้ซึ่งสามารถรับประกันการส่งข้อมูลได้ แต่ก็อาจส่งผลให้ประสิทธิภาพช้าลงด้วย เนื่องจากมีค่าใช้จ่ายที่จำเป็นสำหรับการตรวจสอบข้อผิดพลาดและการส่งซ้ำ
- ความปลอดภัยของเครือข่าย: มาตรการรักษาความปลอดภัย เช่น ไฟร์วอลล์และการเข้ารหัสอาจส่งผลกระทบต่อประสิทธิภาพของเครือข่าย โดยเฉพาะอย่างยิ่งหากมาตรการดังกล่าวต้องการพลังการประมวลผลจำนวนมากหรือทำให้เกิดเวลาแฝงเพิ่มเติม
- ระยะทาง: ระยะห่างทางกายภาพระหว่างอุปกรณ์บนเครือข่ายอาจส่งผลต่อประสิทธิภาพของเครือข่าย โดยเฉพาะอย่างยิ่งสำหรับเครือข่ายไร้สายที่ความแรงของสัญญาณและการรบกวนอาจส่งผลต่อการเชื่อมต่อและอัตราการถ่ายโอนข้อมูล
APIPA คืออะไร?
APIPA คือชุดที่อยู่ IP ที่อุปกรณ์ได้รับการจัดสรรเมื่อเซิร์ฟเวอร์ DHCP หลักไม่สามารถเข้าถึงได้
APIPA ใช้ช่วง IP ใด
APIPA ใช้ช่วง IP: 169.254.0.1 - 169.254.255.254
ระนาบควบคุมและระนาบข้อมูล
"เครื่องบินควบคุม" หมายถึงอะไร?
Control Plane เป็นส่วนหนึ่งของเครือข่ายที่ตัดสินใจว่าจะกำหนดเส้นทางและส่งต่อแพ็กเก็ตไปยังตำแหน่งอื่นอย่างไร
"ระนาบข้อมูล" หมายถึงอะไร
ส่วนข้อมูลเป็นส่วนหนึ่งของเครือข่ายที่ส่งต่อข้อมูล/แพ็กเก็ตจริงๆ
“ระนาบการจัดการ” หมายถึงอะไร?
มันหมายถึงฟังก์ชั่นการตรวจสอบและการจัดการ
การสร้างตารางเส้นทางอยู่ในระนาบใด (ข้อมูล, การควบคุม, ...)
เครื่องบินควบคุม
อธิบาย Spanning Tree Protocol (STP)
การรวมลิงก์คืออะไร? ทำไมมันถึงใช้?
การกำหนดเส้นทางแบบอสมมาตรคืออะไร? จะจัดการกับมันอย่างไร?
คุณคุ้นเคยกับโปรโตคอลโอเวอร์เลย์ (ทันเนล) ใด
GRE คืออะไร? มันทำงานอย่างไร?
VXLAN คืออะไร? มันทำงานอย่างไร?
SNAT คืออะไร?
อธิบาย OSPF
OSPF (Open Shortest Path First) เป็นโปรโตคอลการกำหนดเส้นทางที่สามารถนำไปใช้กับเราเตอร์ประเภทต่างๆ โดยทั่วไป OSPF ได้รับการสนับสนุนบนเราเตอร์สมัยใหม่ส่วนใหญ่ รวมถึงเราเตอร์จากผู้จำหน่าย เช่น Cisco, Juniper และ Huawei โปรโตคอลได้รับการออกแบบให้ทำงานกับเครือข่ายที่ใช้ IP รวมถึง IPv4 และ IPv6 นอกจากนี้ ยังใช้การออกแบบเครือข่ายแบบลำดับชั้น โดยที่เราเตอร์จะถูกจัดกลุ่มตามพื้นที่ โดยแต่ละพื้นที่จะมีแผนผังโทโพโลยีและตารางเส้นทางของตัวเอง การออกแบบนี้ช่วยลดปริมาณข้อมูลเส้นทางที่ต้องแลกเปลี่ยนระหว่างเราเตอร์และปรับปรุงความสามารถในการปรับขนาดเครือข่าย
เราเตอร์ประเภท OSPF 4 คือ:
- เราเตอร์ภายใน
- เราเตอร์ชายแดนพื้นที่
- เราเตอร์ขอบเขตระบบอัตโนมัติ
- แบ็คโบนเราเตอร์
เรียนรู้เพิ่มเติมเกี่ยวกับประเภทเราเตอร์ OSPF: https://www.educba.com/ospf-router-types/
เวลาแฝงคืออะไร?
เวลาแฝงคือเวลาที่ข้อมูลไปถึงปลายทางจากแหล่งที่มา
แบนด์วิธคืออะไร?
แบนด์วิดธ์คือความสามารถของช่องทางการสื่อสารในการวัดปริมาณข้อมูลที่สามารถรองรับได้ในช่วงเวลาที่กำหนด แบนด์วิธที่มากขึ้นจะหมายถึงการจัดการการรับส่งข้อมูลที่มากขึ้นและการถ่ายโอนข้อมูลที่มากขึ้น
ปริมาณงานคืออะไร?
ปริมาณงานหมายถึงการวัดจำนวนข้อมูลที่แท้จริงที่ถ่ายโอนในช่วงเวลาหนึ่งผ่านช่องทางการส่งสัญญาณใดๆ
เมื่อดำเนินการค้นหา อะไรคือสิ่งที่สำคัญกว่า เวลาแฝง หรือปริมาณงาน? และจะมั่นใจได้อย่างไรว่าเราจัดการโครงสร้างพื้นฐานระดับโลก?
เวลาแฝง เพื่อให้มีเวลาแฝงที่ดี ควรส่งต่อคำค้นหาไปยังศูนย์ข้อมูลที่ใกล้ที่สุด
เมื่ออัปโหลดวิดีโอ อะไรคือสิ่งที่สำคัญกว่า เวลาแฝง หรือปริมาณการประมวลผล? แล้วจะมั่นใจได้อย่างไร?
ปริมาณงาน เพื่อให้มีปริมาณงานที่ดี สตรีมการอัปโหลดควรถูกกำหนดเส้นทางไปยังลิงก์ที่ใช้งานน้อยเกินไป
มีข้อควรพิจารณาอื่นๆ อีกบ้าง (ยกเว้นเวลาแฝงและปริมาณการประมวลผล) เมื่อทำการส่งต่อคำขอ
- อัปเดตแคชอยู่เสมอ (ซึ่งหมายความว่าคำขอสามารถส่งต่อได้ไม่ใช่ศูนย์ข้อมูลที่ใกล้เคียงที่สุด)
อธิบายกระดูกสันหลังและใบ
"Spine & Leaf" คือโทโพโลยีเครือข่ายที่ใช้กันทั่วไปในสภาพแวดล้อมของศูนย์ข้อมูลเพื่อเชื่อมต่อสวิตช์หลายตัวและจัดการการรับส่งข้อมูลเครือข่ายอย่างมีประสิทธิภาพ มีชื่อเรียกอีกอย่างว่าสถาปัตยกรรม "กระดูกสันหลังใบ" หรือโทโพโลยี "กระดูกสันหลังใบ" การออกแบบนี้ให้แบนด์วิธสูง เวลาแฝงต่ำ และความสามารถในการปรับขนาด ทำให้เหมาะสำหรับศูนย์ข้อมูลสมัยใหม่ที่จัดการข้อมูลและการรับส่งข้อมูลปริมาณมาก ภายในเครือข่าย Spine & Leaf มีเคล็ดลับหลักสองประการของสวิตช์:
- สวิตช์สไปน์: สวิตช์สไปน์เป็นสวิตช์ประสิทธิภาพสูงที่จัดเรียงอยู่ในชั้นสไปน์ สวิตช์เหล่านี้ทำหน้าที่เป็นแกนหลักของเครือข่าย และโดยทั่วไปจะเชื่อมต่อกับสวิตช์ลีฟแต่ละตัว สวิตช์สไปน์แต่ละตัวเชื่อมต่อกับสวิตช์ลีฟทั้งหมดในศูนย์ข้อมูล
- สวิตช์ลีฟ: สวิตช์ลีฟเชื่อมต่อกับอุปกรณ์ปลายทาง เช่น เซิร์ฟเวอร์ อาเรย์จัดเก็บข้อมูล และอุปกรณ์เครือข่ายอื่นๆ สวิตช์ลีฟแต่ละตัวเชื่อมต่อกับสวิตช์สไปน์ทุกตัวในศูนย์ข้อมูล สิ่งนี้จะสร้างการเชื่อมต่อแบบตาข่ายเต็มรูปแบบที่ไม่มีการปิดกั้นระหว่างสวิตช์ลีฟและสไปน์ ทำให้มั่นใจได้ว่าสวิตช์ลีฟใด ๆ จะสามารถสื่อสารกับสวิตช์ลีฟอื่น ๆ ที่มีปริมาณงานสูงสุด
สถาปัตยกรรม Spine & Leaf ได้รับความนิยมเพิ่มมากขึ้นในศูนย์ข้อมูล เนื่องจากความสามารถในการจัดการกับความต้องการของการประมวลผลบนคลาวด์สมัยใหม่ การจำลองเสมือน และแอปพลิเคชันข้อมูลขนาดใหญ่ โดยให้โครงสร้างพื้นฐานเครือข่ายที่ปรับขนาดได้ ประสิทธิภาพสูง และเชื่อถือได้
ความแออัดของเครือข่ายคืออะไร? อะไรทำให้เกิดสิ่งนี้ได้?
ความแออัดของเครือข่ายเกิดขึ้นเมื่อมีข้อมูลมากเกินไปในการส่งบนเครือข่าย และไม่มีความจุเพียงพอที่จะรองรับความต้องการ
สิ่งนี้สามารถนำไปสู่เวลาแฝงที่เพิ่มขึ้นและการสูญเสียแพ็กเก็ต สาเหตุอาจมีหลายประการ เช่น การใช้งานเครือข่ายสูง การถ่ายโอนไฟล์ขนาดใหญ่ มัลแวร์ ปัญหาฮาร์ดแวร์ หรือปัญหาการออกแบบเครือข่าย
เพื่อป้องกันความแออัดของเครือข่าย การตรวจสอบการใช้งานเครือข่ายของคุณเป็นสิ่งสำคัญ และใช้กลยุทธ์เพื่อจำกัดหรือจัดการความต้องการ
คุณสามารถบอกฉันเกี่ยวกับรูปแบบแพ็กเก็ต UDP ได้อย่างไร แล้วรูปแบบแพ็คเก็ต TCP ล่ะ? มันแตกต่างกันอย่างไร?
อัลกอริธึม Backoff แบบเอ็กซ์โปเนนเชียลคืออะไร? มันใช้ที่ไหน?
เมื่อใช้รหัส Hamming คำรหัสสำหรับคำข้อมูลต่อไปนี้ 100111010001101 จะเป็นอย่างไร
00110011110100011101
ยกตัวอย่างโปรโตคอลที่พบในเลเยอร์แอปพลิเคชัน
Hypertext Transfer Protocol (HTTP) - ใช้สำหรับหน้าเว็บบนอินเทอร์เน็ต- Simple Mail Transfer Protocol (SMTP) - การส่งอีเมล
- เครือข่ายโทรคมนาคม - (TELNET) - การจำลองเทอร์มินัลเพื่อให้ไคลเอนต์เข้าถึงเซิร์ฟเวอร์เทลเน็ต
- File Transfer Protocol (FTP) - อำนวยความสะดวกในการถ่ายโอนไฟล์ระหว่างสองเครื่อง
- ระบบชื่อโดเมน (DNS) - การแปลชื่อโดเมน
- Dynamic Host Configuration Protocol (DHCP) - จัดสรรที่อยู่ IP ซับเน็ตมาสก์ และเกตเวย์ให้กับโฮสต์
- Simple Network Management Protocol (SNMP) - รวบรวมข้อมูลบนอุปกรณ์บนเครือข่าย
ยกตัวอย่างโปรโตคอลที่พบใน Network Layer
Internet Protocol (IP) - ช่วยในการกำหนดเส้นทางแพ็กเก็ตจากเครื่องหนึ่งไปยังอีกเครื่องหนึ่ง- Internet Control Message Protocol (ICMP) - ช่วยให้รู้ว่าเกิดอะไรขึ้น เช่น ข้อความแสดงข้อผิดพลาดและข้อมูลการแก้ไขข้อบกพร่อง
HSTS คืออะไร?
HTTP Strict Transport Security คือคำสั่งเว็บเซิร์ฟเวอร์ที่แจ้งให้ตัวแทนผู้ใช้และเว็บเบราว์เซอร์ทราบถึงวิธีจัดการการเชื่อมต่อผ่านส่วนหัวการตอบกลับที่ส่งตั้งแต่เริ่มต้นและกลับไปยังเบราว์เซอร์ ซึ่งจะบังคับการเชื่อมต่อผ่านการเข้ารหัส HTTPS โดยไม่สนใจการเรียกสคริปต์ใดๆ เพื่อโหลดทรัพยากรใดๆ ในโดเมนนั้นผ่าน HTTP อ่านเพิ่มเติม[ที่นี่](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security %20(HSTS และ%20กลับ%20ถึง%20%20เบราว์เซอร์)
เครือข่าย - เบ็ดเตล็ด
อินเทอร์เน็ตคืออะไร? มันเหมือนกับเวิลด์ไวด์เว็บหรือไม่?
อินเทอร์เน็ตหมายถึงเครือข่ายเครือข่ายที่ถ่ายโอนข้อมูลจำนวนมหาศาลทั่วโลก
World Wide Web เป็นแอปพลิเคชันที่ใช้เซิร์ฟเวอร์นับล้านบนอินเทอร์เน็ตเข้าถึงได้ผ่านสิ่งที่เรียกว่าเว็บเบราว์เซอร์
ISP คืออะไร?
ISP (ผู้ให้บริการอินเทอร์เน็ต) เป็นผู้ให้บริการ บริษัท อินเทอร์เน็ตในพื้นที่
ระบบปฏิบัติการ
แบบฝึกหัดระบบปฏิบัติการ
| ชื่อ | หัวข้อ | วัตถุประสงค์และคำแนะนำ | สารละลาย | ความคิดเห็น |
|---|
| ส้อม 101 | ส้อม | ลิงค์ | ลิงค์ | |
| ส้อม 102 | ส้อม | ลิงค์ | ลิงค์ | |
ระบบปฏิบัติการ - การประเมินตนเอง
ระบบปฏิบัติการคืออะไร?
จากหนังสือ "ระบบปฏิบัติการ: สามชิ้นง่าย":
"รับผิดชอบในการทำให้ง่ายต่อการเรียกใช้โปรแกรม (แม้จะช่วยให้คุณทำงานได้หลายอย่างในเวลาเดียวกัน) ช่วยให้โปรแกรมสามารถแบ่งปันหน่วยความจำทำให้โปรแกรมสามารถโต้ตอบกับอุปกรณ์และสิ่งสนุกอื่น ๆ เช่นนั้น"
ระบบปฏิบัติการ - กระบวนการ
คุณสามารถอธิบายกระบวนการคืออะไร?
กระบวนการคือโปรแกรมที่กำลังทำงานอยู่ โปรแกรมคือหนึ่งคำแนะนำหรือมากกว่าและโปรแกรม (หรือกระบวนการ) ดำเนินการโดยระบบปฏิบัติการ
หากคุณต้องออกแบบ API สำหรับกระบวนการในระบบปฏิบัติการ API นี้จะเป็นอย่างไร
มันจะสนับสนุนสิ่งต่อไปนี้:
สร้าง - อนุญาตให้สร้างกระบวนการใหม่- ลบ - อนุญาตให้ลบ/ทำลายกระบวนการ
- รัฐ - อนุญาตให้ตรวจสอบสถานะของกระบวนการไม่ว่าจะทำงานหยุดหยุดรอ ฯลฯ
- หยุด - อนุญาตให้หยุดกระบวนการทำงาน
กระบวนการถูกสร้างขึ้นอย่างไร?
ระบบปฏิบัติการกำลังอ่านรหัสของโปรแกรมและข้อมูลที่เกี่ยวข้องเพิ่มเติมใด ๆ- รหัสของโปรแกรมถูกโหลดลงในหน่วยความจำหรือโดยเฉพาะอย่างยิ่งในพื้นที่ที่อยู่ของกระบวนการ
- หน่วยความจำได้รับการจัดสรรสำหรับสแต็กของโปรแกรม (AKA Run-Time Stack) สแต็คยังเริ่มต้นโดยระบบปฏิบัติการด้วยข้อมูลเช่น Argv, ARGC และพารามิเตอร์ไปยัง Main ()
- หน่วยความจำได้รับการจัดสรรสำหรับกองโปรแกรมซึ่งจำเป็นสำหรับข้อมูลที่จัดสรรแบบไดนามิกเช่นโครงสร้างข้อมูลที่เชื่อมโยงและตารางแฮช
- งานการเริ่มต้น I/O จะดำเนินการเช่นในระบบที่ใช้ UNIX/Linux ซึ่งแต่ละกระบวนการมี 3 ตัวอธิบายไฟล์ (อินพุต, เอาต์พุตและข้อผิดพลาด)
- OS กำลังเรียกใช้โปรแกรมเริ่มต้นจาก Main ()
จริงหรือเท็จ? การโหลดโปรแกรมลงในหน่วยความจำจะทำอย่างกระตือรือร้น (ทั้งหมดในครั้งเดียว)
เท็จ. มันเป็นความจริงในอดีต แต่ระบบปฏิบัติการของวันนี้ทำการโหลดขี้เกียจซึ่งหมายความว่าเฉพาะชิ้นส่วนที่เกี่ยวข้องที่จำเป็นสำหรับกระบวนการในการทำงานจะถูกโหลดก่อน
สถานะของกระบวนการต่างกันคืออะไร?
Running - มันกำลังดำเนินการตามคำแนะนำ- พร้อม - พร้อมที่จะวิ่ง แต่ด้วยเหตุผลที่แตกต่างกันมันถูกระงับไว้
- บล็อก - กำลังรอให้การดำเนินการเสร็จสมบูรณ์เช่นคำขอดิสก์ I/O
มีเหตุผลอะไรบ้างที่กระบวนการที่จะถูกบล็อก?
การดำเนินการ I/O (เช่นการอ่านจากดิสก์)- กำลังรอแพ็คเก็ตจากเครือข่าย
Inter Process Communication (IPC) คืออะไร?
การสื่อสารระหว่างกระบวนการ (IPC) หมายถึงกลไกที่จัดทำโดยระบบปฏิบัติการที่อนุญาตให้กระบวนการจัดการข้อมูลที่ใช้ร่วมกัน
"การแบ่งปันเวลา" คืออะไร?
แม้ว่าเมื่อใช้ระบบที่มี CPU ทางกายภาพหนึ่งตัวก็เป็นไปได้ที่จะอนุญาตให้ผู้ใช้หลายคนทำงานและเรียกใช้โปรแกรม สิ่งนี้เป็นไปได้ด้วยการแบ่งปันเวลาซึ่งทรัพยากรการคำนวณจะถูกแชร์ในลักษณะที่ผู้ใช้ดูเหมือนว่าระบบจะมีซีพียูหลายตัว แต่ในความเป็นจริงแล้วมันเป็นเพียง CPU เดียวที่ใช้ร่วมกันโดยใช้มัลติโปรแกรมและมัลติทาสก์
"การแบ่งปันพื้นที่" คืออะไร?
ค่อนข้างตรงกันข้ามกับการแบ่งปันเวลา ในขณะที่การแชร์ทรัพยากรในเวลานั้นใช้เวลาหนึ่งเอนทิตีจากนั้นทรัพยากรเดียวกันสามารถใช้ทรัพยากรอื่นได้ในการแบ่งปันอวกาศพื้นที่จะถูกแชร์โดยหลายหน่วยงาน แต่ในลักษณะที่ไม่ได้ถูกถ่ายโอนระหว่างพวกเขา
มันถูกใช้โดยหนึ่งเอนทิตีจนกว่านิติบุคคลนี้จะตัดสินใจกำจัดมัน ยกตัวอย่างการจัดเก็บ ในการจัดเก็บไฟล์เป็นของคุณจนกว่าคุณจะตัดสินใจลบ
องค์ประกอบใดที่กำหนดกระบวนการใดที่ทำงานในช่วงเวลาที่กำหนด?
CPU Scheduler
ระบบปฏิบัติการ - หน่วยความจำ
"หน่วยความจำเสมือน" คืออะไรและมีจุดประสงค์อะไร?
หน่วยความจำเสมือนจริงรวม RAM ของคอมพิวเตอร์ของคุณเข้ากับพื้นที่ชั่วคราวบนฮาร์ดดิสก์ของคุณ เมื่อ RAM ทำงานต่ำหน่วยความจำเสมือนจะช่วยย้ายข้อมูลจาก RAM ไปยังพื้นที่ที่เรียกว่าไฟล์เพจ การย้ายข้อมูลไปยังไฟล์เพจสามารถเพิ่ม RAM ได้เพื่อให้คอมพิวเตอร์ของคุณสามารถทำงานให้เสร็จได้ โดยทั่วไปยิ่งคอมพิวเตอร์ของคุณมีความสามารถมากเท่าไหร่โปรแกรมก็จะทำงานได้เร็วขึ้นเท่านั้น https://www.minitool.com/lib/virtual-memory.html
อุปสงค์คืออะไร?
ความต้องการเพจเพจเป็นเทคนิคการจัดการหน่วยความจำที่โหลดหน้าลงในหน่วยความจำทางกายภาพเฉพาะเมื่อเข้าถึงโดยกระบวนการ มันเพิ่มประสิทธิภาพการใช้งานหน่วยความจำโดยการโหลดหน้าเว็บตามความต้องการลดเวลาแฝงเริ่มต้นและค่าใช้จ่ายในพื้นที่ อย่างไรก็ตามมันแนะนำเวลาแฝงบางอย่างเมื่อเข้าถึงหน้าเป็นครั้งแรก โดยรวมแล้วเป็นวิธีการที่คุ้มค่าสำหรับการจัดการทรัพยากรหน่วยความจำในระบบปฏิบัติการ
Copy-on-Write คืออะไร?
Copy-on-Write (COW) เป็นแนวคิดการจัดการทรัพยากรโดยมีเป้าหมายเพื่อลดการคัดลอกข้อมูลที่ไม่จำเป็น มันเป็นแนวคิดที่นำมาใช้เช่นภายใน Posix Fork Syscall ซึ่งสร้างกระบวนการที่ซ้ำกันของกระบวนการเรียก ความคิด:
หากทรัพยากรถูกแชร์ระหว่าง 2 หน่วยงานหรือมากกว่า (เช่นกลุ่มหน่วยความจำที่ใช้ร่วมกันระหว่าง 2 กระบวนการ) ทรัพยากรไม่จำเป็นต้องคัดลอกสำหรับทุกเอนทิตี แต่ทุกเอนทิตีทุกหน่วยงานมีสิทธิ์การเข้าถึงการดำเนินการอ่านในทรัพยากรที่ใช้ร่วมกัน (กลุ่มที่ใช้ร่วมกันถูกทำเครื่องหมายว่าเป็นการอ่านอย่างเดียว) (คิดว่าทุกเอนทิตีที่มีตัวชี้ไปยังตำแหน่งของทรัพยากรที่ใช้ร่วมกันซึ่งสามารถอ่านค่าได้เพื่ออ่านค่า)- หากนิติบุคคลหนึ่งจะดำเนินการเขียนบนทรัพยากรที่ใช้ร่วมกันปัญหาจะเกิดขึ้นเนื่องจากทรัพยากรจะเปลี่ยนไปอย่างถาวรสำหรับเอนทิตีอื่น ๆ ทั้งหมดที่แบ่งปัน (คิดว่ากระบวนการปรับเปลี่ยนตัวแปรบางอย่างบนสแต็กหรือจัดสรรข้อมูลบางอย่างแบบไดนามิกบนฮีปการเปลี่ยนแปลงทรัพยากรที่ใช้ร่วมกันเหล่านี้จะนำไปใช้กับกระบวนการอื่น ๆ ทั้งหมดนี่เป็นพฤติกรรมที่ไม่พึงประสงค์อย่างแน่นอน)
- ในฐานะที่เป็นวิธีแก้ปัญหาเท่านั้นหากการดำเนินการเขียนกำลังจะดำเนินการบนทรัพยากรที่ใช้ร่วมกันทรัพยากรนี้จะถูกคัดลอกก่อนแล้วจึงใช้การเปลี่ยนแปลง
เคอร์เนลคืออะไรและมันทำอะไร?
เคอร์เนลเป็นส่วนหนึ่งของระบบปฏิบัติการและรับผิดชอบงานเช่น:
การจัดสรรหน่วยความจำ- กำหนดเวลากระบวนการ
- ซีพียูควบคุม
จริงหรือเท็จ? บางชิ้นของรหัสในเคอร์เนลจะถูกโหลดลงในพื้นที่คุ้มครองของหน่วยความจำเพื่อให้แอปพลิเคชันไม่สามารถเขียนทับได้
จริง
Posix คืออะไร?
POSIX (อินเทอร์เฟซระบบปฏิบัติการแบบพกพา) เป็นชุดของมาตรฐานที่กำหนดอินเทอร์เฟซระหว่างระบบปฏิบัติการที่เหมือน UNIX และโปรแกรมแอปพลิเคชัน
อธิบายว่าเซมาฟอร์คืออะไรและบทบาทในระบบปฏิบัติการ
Semaphore เป็นแบบดั้งเดิมที่ใช้ในระบบปฏิบัติการและการเขียนโปรแกรมพร้อมกันเพื่อควบคุมการเข้าถึงทรัพยากรที่ใช้ร่วมกัน มันเป็นประเภทข้อมูลตัวแปรหรือนามธรรมที่ทำหน้าที่เป็นตัวนับหรือกลไกการส่งสัญญาณสำหรับการจัดการการเข้าถึงทรัพยากรโดยกระบวนการหรือเธรดที่หลากหลาย
แคชคืออะไร? บัฟเฟอร์คืออะไร?
แคช: แคชมักจะใช้เมื่อกระบวนการกำลังอ่านและเขียนลงในดิสก์เพื่อให้กระบวนการเร็วขึ้นโดยการสร้างข้อมูลที่คล้ายกันโดยโปรแกรมที่แตกต่างกันสามารถเข้าถึงได้ง่าย บัฟเฟอร์: สถานที่ที่สงวนไว้ใน RAM ซึ่งใช้เพื่อเก็บข้อมูลเพื่อวัตถุประสงค์ชั่วคราว
การทำให้เสมือนจริง
การจำลองเสมือนคืออะไร?
การจำลองเสมือนใช้ซอฟต์แวร์เพื่อสร้างเลเยอร์ที่เป็นนามธรรมผ่านฮาร์ดแวร์คอมพิวเตอร์ซึ่งช่วยให้องค์ประกอบฮาร์ดแวร์ของคอมพิวเตอร์เครื่องประมวลผลเครื่องประมวลผลหน่วยความจำการจัดเก็บและอื่น ๆ - เพื่อแบ่งออกเป็นคอมพิวเตอร์เสมือนจริงหลายเครื่องซึ่งเรียกว่าเครื่องเสมือน (VM)
ไฮเปอร์ไวเซอร์คืออะไร?
Red Hat: "Hypervisor เป็นซอฟต์แวร์ที่สร้างและเรียกใช้เครื่องเสมือน (VMS). hypervisor บางครั้งเรียกว่าเครื่องตรวจสอบเครื่องเสมือน (VMM) แยกระบบปฏิบัติการและทรัพยากรไฮเปอร์ไวเซอร์จากเครื่องเสมือน vms. "
อ่านเพิ่มเติมได้ที่นี่
มี hypervisors ประเภทใดบ้าง?
โฮสต์ hypervisors และ hypervisors โลหะเปลือย
อะไรคือข้อดีและข้อเสียของไฮเปอร์ไวเซอร์โลหะเปลือยผ่านไฮเปอร์ไวเซอร์โฮสต์?
เนื่องจากการมีไดรเวอร์ของตัวเองและการเข้าถึงส่วนประกอบฮาร์ดแวร์โดยตรง hypervisor baremetal มักจะมีประสิทธิภาพที่ดีขึ้นพร้อมกับความมั่นคงและความสามารถในการปรับขนาด
ในทางกลับกันอาจมีข้อ จำกัด บางประการเกี่ยวกับการโหลดไดรเวอร์ (ใด ๆ ) ดังนั้น hypervisor ที่โฮสต์จะได้รับประโยชน์จากการมีความเข้ากันได้ของฮาร์ดแวร์ที่ดีขึ้น
มีการจำลองเสมือนประเภทใดบ้าง?
ระบบปฏิบัติการระบบการจำลองเสมือนจริงฟังก์ชั่นการจำลองเสมือนเดสก์ท็อปการจำลองเสมือนจริง
containerization เป็นประเภทของการจำลองเสมือนจริงหรือไม่?
ใช่มันเป็นเวอร์ชวลไลเซชันระดับปฏิบัติการระดับระบบที่มีการแชร์เคอร์เนลและอนุญาตให้ใช้อินสแตนซ์ของผู้ใช้พื้นที่แยกหลายอินสแตนซ์
การแนะนำเครื่องเสมือนจริงเปลี่ยนอุตสาหกรรมและวิธีการใช้งานแอปพลิเคชันได้อย่างไร
การแนะนำเครื่องเสมือนจริงทำให้ บริษัท สามารถปรับใช้แอปพลิเคชันธุรกิจหลายรายการในฮาร์ดแวร์เดียวกันในขณะที่แต่ละแอปพลิเคชันจะถูกแยกออกจากกันอย่างปลอดภัย
เครื่องเสมือนจริง
เราต้องการเครื่องเสมือนจริงในยุคของภาชนะบรรจุหรือไม่? พวกเขายังคงเกี่ยวข้องหรือไม่?
ใช่เครื่องเสมือนยังคงมีความเกี่ยวข้องแม้ในยุคของภาชนะบรรจุ ในขณะที่คอนเทนเนอร์มีทางเลือกที่มีน้ำหนักเบาและพกพาสำหรับเครื่องเสมือนจริง แต่ก็มีข้อ จำกัด บางประการ เครื่องเสมือนจริงยังคงมีความสำคัญเนื่องจากมีความโดดเดี่ยวและความปลอดภัยสามารถเรียกใช้ระบบปฏิบัติการที่แตกต่างกันและเป็นแอพดั้งเดิมที่ดี ข้อ จำกัด ของคอนเทนเนอร์เช่นการแชร์เคอร์เนลโฮสต์
โพรมีธีอุส
โพรคืออะไร? คุณสมบัติหลักของโพรโพรอุสมีอะไรบ้าง?
Prometheus เป็นชุดการตรวจสอบระบบโอเพนซอร์ซยอดนิยมและการแจ้งเตือนชุดเครื่องมือ แต่เดิมพัฒนาที่ SoundCloud มันถูกออกแบบมาเพื่อรวบรวมและจัดเก็บข้อมูลอนุกรมเวลาและเพื่อให้สามารถสอบถามและวิเคราะห์ข้อมูลนั้นได้โดยใช้ภาษาคิวรีที่ทรงพลังที่เรียกว่า PROMQL Prometheus มักใช้ในการตรวจสอบแอปพลิเคชั่นคลาวด์เจ้าของระบบไมโครไซต์และโครงสร้างพื้นฐานที่ทันสมัยอื่น ๆ
คุณสมบัติหลักบางอย่างของ Prometheus ได้แก่ :
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
โดยรวมแล้วโพรเป็นเครื่องมือที่ทรงพลังและยืดหยุ่นสำหรับการตรวจสอบและวิเคราะห์ระบบและแอพพลิเคชั่นและมีการใช้กันอย่างแพร่หลายในอุตสาหกรรมสำหรับการตรวจสอบและการสังเกตแบบคลาวด์
ในสถานการณ์ใดมันอาจจะดีกว่าที่จะไม่ใช้ Prometheus?
จากเอกสารประกอบโพร: "หากคุณต้องการความแม่นยำ 100% เช่นการเรียกเก็บเงินตามคำตอบ"
อธิบายสถาปัตยกรรมและส่วนประกอบของโพร
สถาปัตยกรรมโพรประกอบด้วยสี่องค์ประกอบหลัก:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
โดยรวมแล้วสถาปัตยกรรม Prometheus ได้รับการออกแบบให้ปรับขนาดได้และยืดหยุ่นได้สูง ห้องสมุดเซิร์ฟเวอร์และไคลเอนต์สามารถปรับใช้ในแบบกระจายเพื่อรองรับการตรวจสอบในสภาพแวดล้อมขนาดใหญ่ที่มีพลวัตสูง
คุณสามารถเปรียบเทียบโพรกับโซลูชันอื่น ๆ เช่น InfluxDB ได้หรือไม่?
เมื่อเปรียบเทียบกับโซลูชันการตรวจสอบอื่น ๆ เช่น influxDB Prometheus เป็นที่รู้จักกันดีในด้านประสิทธิภาพและความยืดหยุ่นที่สูง มันสามารถจัดการข้อมูลจำนวนมากและสามารถรวมเข้ากับเครื่องมืออื่น ๆ ในระบบการตรวจสอบได้อย่างง่ายดาย ในทางกลับกัน InfluxDB เป็นที่รู้จักกันดีในการใช้งานและความเรียบง่าย มีอินเทอร์เฟซที่ใช้งานง่ายและให้ API ที่ใช้งานง่ายสำหรับการรวบรวมและสอบถามข้อมูล
โซลูชันที่ได้รับความนิยมอีกอย่างหนึ่งคือ Nagios เป็นระบบการตรวจสอบแบบดั้งเดิมที่อาศัยโมเดลแบบพุชที่ใช้ในการรวบรวมข้อมูล Nagios มีมานานแล้วและเป็นที่รู้จักในเรื่องความมั่นคงและความน่าเชื่อถือ อย่างไรก็ตามเมื่อเปรียบเทียบกับโพรแล้ว Nagios ขาดคุณสมบัติขั้นสูงบางอย่างเช่นรูปแบบข้อมูลหลายมิติและภาษาคิวรีที่ทรงพลัง
โดยรวมแล้วการเลือกโซลูชันการตรวจสอบขึ้นอยู่กับความต้องการและข้อกำหนดเฉพาะขององค์กร ในขณะที่ Prometheus เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการตรวจสอบและแจ้งเตือนขนาดใหญ่ แต่ InfluxDB อาจเหมาะสมกว่าสำหรับสภาพแวดล้อมขนาดเล็กที่ต้องใช้ความสะดวกในการใช้งานและความเรียบง่าย Nagios ยังคงเป็นทางเลือกที่ดีสำหรับองค์กรที่จัดลำดับความสำคัญความมั่นคงและความน่าเชื่อถือมากกว่าคุณสมบัติขั้นสูง
การแจ้งเตือนคืออะไร?
ในโพรการแจ้งเตือนคือการแจ้งเตือนที่เกิดขึ้นเมื่อมีเงื่อนไขหรือเกณฑ์เฉพาะ การแจ้งเตือนสามารถกำหนดค่าให้ทริกเกอร์เมื่อตัวชี้วัดบางอย่างข้ามเกณฑ์ที่แน่นอนหรือเมื่อเหตุการณ์เฉพาะเกิดขึ้น เมื่อมีการแจ้งเตือนแล้วจะสามารถส่งไปยังช่องทางต่าง ๆ เช่นอีเมลเพจเจอร์หรือแชทเพื่อแจ้งทีมหรือบุคคลที่เกี่ยวข้องให้ดำเนินการที่เหมาะสม การแจ้งเตือนเป็นองค์ประกอบที่สำคัญของระบบการตรวจสอบใด ๆ เนื่องจากพวกเขาอนุญาตให้ทีมตรวจจับและตอบสนองต่อปัญหาเชิงรุกก่อนที่จะส่งผลกระทบต่อผู้ใช้หรือทำให้ระบบหยุดทำงาน อินสแตนซ์คืออะไร? งานคืออะไร?
ในโพรอินสแตนซ์หมายถึงเป้าหมายเดียวที่กำลังตรวจสอบ ตัวอย่างเช่นเซิร์ฟเวอร์หรือบริการเดียว งานคือชุดของอินสแตนซ์ที่ทำหน้าที่เดียวกันเช่นชุดของเว็บเซิร์ฟเวอร์ที่ให้บริการแอปพลิเคชันเดียวกัน งานอนุญาตให้คุณกำหนดและจัดการกลุ่มเป้าหมายด้วยกัน
ในสาระสำคัญอินสแตนซ์เป็นเป้าหมายของแต่ละบุคคลที่โพรลิสต์รวบรวมตัวชี้วัดจากในขณะที่งานเป็นชุดของอินสแตนซ์ที่คล้ายกันที่สามารถจัดการเป็นกลุ่ม
ประเภทตัวชี้วัดหลักที่ Prometheus รองรับ?
Prometheus รองรับการวัดหลายประเภทรวมถึง: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
Prometheus ยังสนับสนุนฟังก์ชั่นและตัวดำเนินการต่าง ๆ สำหรับการรวมและจัดการตัวชี้วัดเช่นผลรวม, สูงสุด, ขั้นต่ำและอัตรา คุณสมบัติเหล่านี้ทำให้เป็นเครื่องมือที่ทรงพลังสำหรับการตรวจสอบและแจ้งเตือนในการวัดระบบ
ผู้ส่งออกคืออะไร? มันใช้ทำอะไร?
ผู้ส่งออกทำหน้าที่เป็นสะพานเชื่อมระหว่างระบบหรือแอปพลิเคชันของบุคคลที่สามและ Prometheus ทำให้ Prometheus สามารถตรวจสอบและรวบรวมข้อมูลจากระบบหรือแอปพลิเคชันนั้นได้ ผู้ส่งออกทำหน้าที่เป็นเซิร์ฟเวอร์โดยฟังพอร์ตเครือข่ายเฉพาะสำหรับคำขอจาก Prometheus ไปยัง Scrape Metrics มันรวบรวมการวัดจากระบบของบุคคลที่สามหรือแอปพลิเคชันและแปลงเป็นรูปแบบที่โพรโพรอุสสามารถเข้าใจได้ จากนั้นผู้ส่งออกจะเปิดเผยตัวชี้วัดเหล่านี้ไปยัง Prometheus ผ่านจุดสิ้นสุด HTTP ทำให้สามารถรวบรวมและวิเคราะห์ได้
ผู้ส่งออกมักใช้เพื่อตรวจสอบส่วนประกอบโครงสร้างพื้นฐานประเภทต่าง ๆ เช่นฐานข้อมูลเว็บเซิร์ฟเวอร์และระบบจัดเก็บข้อมูล ตัวอย่างเช่นมีผู้ส่งออกสำหรับการตรวจสอบฐานข้อมูลยอดนิยมเช่น MySQL และ PostgreSQL รวมถึงเว็บเซิร์ฟเวอร์เช่น Apache และ Nginx
โดยรวมแล้วผู้ส่งออกเป็นองค์ประกอบที่สำคัญของระบบนิเวศของโพรทำให้สามารถตรวจสอบระบบและแอพพลิเคชั่นที่หลากหลายและให้ความยืดหยุ่นและยืดหยุ่นในระดับสูงกับแพลตฟอร์ม
แนวปฏิบัติที่ดีที่สุดของโพรโพร
นี่คือสามของพวกเขา: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
จะรับคำขอทั้งหมดในช่วงเวลาที่กำหนดได้อย่างไร?
ในการรับคำขอทั้งหมดในช่วงเวลาที่กำหนดโดยใช้ Prometheus คุณสามารถใช้ฟังก์ชั่น * SUM * พร้อมกับฟังก์ชัน * อัตรา * นี่คือตัวอย่างการสืบค้นที่จะให้จำนวนคำขอทั้งหมดในชั่วโมงสุดท้าย: sum(rate(http_requests_total[1h]))
ในแบบสอบถามนี้ HTTP_REQUESTS_TOTAL เป็นชื่อของตัวชี้วัดที่ติดตามจำนวนการร้องขอ HTTP ทั้งหมดและฟังก์ชั่น อัตรา จะคำนวณอัตราการร้องขอต่อวินาทีในช่วงชั่วโมงสุดท้าย ฟังก์ชั่น ผลรวม จะเพิ่มคำขอทั้งหมดเพื่อให้จำนวนคำขอทั้งหมดแก่คุณในชั่วโมงสุดท้าย
คุณสามารถปรับช่วงเวลาโดยการเปลี่ยนระยะเวลาในฟังก์ชัน อัตรา ตัวอย่างเช่นหากคุณต้องการรับจำนวนคำขอทั้งหมดในวันสุดท้ายคุณสามารถเปลี่ยนฟังก์ชั่นเป็น อัตรา (http_requests_total [1d])
HA ในโพรหมายถึงอะไร?
HA ย่อมาจากความพร้อมใช้งานสูง ซึ่งหมายความว่าระบบได้รับการออกแบบให้มีความน่าเชื่อถือสูงและพร้อมใช้งานอยู่เสมอแม้จะเผชิญกับความล้มเหลวหรือปัญหาอื่น ๆ ในทางปฏิบัติสิ่งนี้มักจะเกี่ยวข้องกับการตั้งค่าหลายกรณีของโพรและทำให้มั่นใจว่าพวกเขาทั้งหมดซิงโครไนซ์และสามารถทำงานร่วมกันได้อย่างราบรื่น สิ่งนี้สามารถทำได้ผ่านเทคนิคที่หลากหลายเช่นกลไกการปรับสมดุลโหลดการจำลองแบบและกลไกการล้มเหลว ด้วยการใช้ HA ในโพรเมตส์ผู้ใช้สามารถมั่นใจได้ว่าข้อมูลการตรวจสอบของพวกเขานั้นมีอยู่เสมอและทันสมัยแม้จะเผชิญกับความล้มเหลวของฮาร์ดแวร์หรือซอฟต์แวร์ปัญหาเครือข่ายหรือปัญหาอื่น ๆ ที่อาจทำให้เกิดการหยุดทำงานหรือการสูญเสียข้อมูล
คุณเข้าร่วมสองเมตริกได้อย่างไร?
ในโพรการเข้าร่วมสองตัวชี้วัดสามารถทำได้โดยใช้ฟังก์ชัน * join () * ฟังก์ชั่น * เข้าร่วม () * รวมอนุกรมเวลาสองชุดขึ้นไปตามค่าฉลากของพวกเขา ต้องใช้อาร์กิวเมนต์สองข้อบังคับ: *บน *และ *ตาราง * อาร์กิวเมนต์ ON ระบุป้ายกำกับเพื่อเข้าร่วม * บน * และ Table * Table * ระบุชุดเวลาเพื่อเข้าร่วม นี่คือตัวอย่างของวิธีการเข้าร่วมสองตัวชี้วัดโดยใช้ฟังก์ชั่น การเข้าร่วม () :
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
ในตัวอย่างนี้ฟังก์ชั่น การเข้าร่วม () รวมชุดเวลา request_count_total และ error_count_total ตาม ค่าบริการ และค่าฉลาก อินสแตนซ์ ของพวกเขา ฟังก์ชั่น sum_series () จากนั้นคำนวณผลรวมของอนุกรมเวลาที่เกิดขึ้น
จะเขียนแบบสอบถามที่ส่งคืนค่าของฉลากได้อย่างไร?
ในการเขียนแบบสอบถามที่ส่งคืนค่าของฉลากใน Prometheus คุณสามารถใช้ฟังก์ชัน * label_values * ฟังก์ชั่น * labela_values * ใช้สองอาร์กิวเมนต์: ชื่อของฉลากและชื่อของตัวชี้วัด ตัวอย่างเช่นหากคุณมีตัวชี้วัดที่เรียกว่า http_requests_total ด้วยฉลากที่เรียกว่า เมธอด และคุณต้องการส่งคืนค่าทั้งหมดของป้ายกำกับ เมธอด คุณสามารถใช้แบบสอบถามต่อไปนี้:
label_values(http_requests_total, method)
สิ่งนี้จะส่งคืนรายการค่าทั้งหมดสำหรับฉลาก เมธอด ในตัวชี้วัด http_requests_total จากนั้นคุณสามารถใช้รายการนี้ในการสืบค้นเพิ่มเติมหรือกรองข้อมูลของคุณ
คุณจะแปลง CPU_USER_SECONDS เป็น CPU เป็นเปอร์เซ็นต์ได้อย่างไร?
ในการแปลง * CPU_USER_SECONDS * เป็นการใช้ CPU เป็นเปอร์เซ็นต์คุณต้องหารด้วยเวลาทั้งหมดที่ผ่านไปและจำนวนคอร์ CPU จากนั้นคูณด้วย 100 สูตรดังต่อไปนี้: 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
ที่นี่, เป็นชื่อของงานที่คุณต้องการสอบถาม เป็นช่วงเวลาที่คุณต้องการสอบถาม (เช่น 5m , 1h ) และ จำนวนคอร์ CPU บนเครื่องที่คุณกำลังสอบถาม
ตัวอย่างเช่นเพื่อให้การใช้งาน CPU เป็นเปอร์เซ็นต์ในช่วง 5 นาทีสุดท้ายสำหรับงานชื่อ My-Job ที่ทำงานบนเครื่องที่มี 4 CPU Cores คุณสามารถใช้แบบสอบถามต่อไปนี้:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
ไป
คุณลักษณะบางอย่างของภาษาการเขียนโปรแกรม GO คืออะไร?
- การพิมพ์ที่แข็งแกร่งและคงที่ - ประเภทของตัวแปรไม่สามารถเปลี่ยนแปลงได้เมื่อเวลาผ่านไปและพวกเขาจะต้องกำหนดในเวลาคอมไพล์เวลา
- ที่เรียบง่าย
- เวลาคอมไพล์เวลาที่รวดเร็ว
- ในตัวขยะพร้อมกันใน
- การรวบรวม
- แพลตฟอร์ม
- การรวบรวมอิสระเป็นไบนารีแบบสแตนด์อโลน - อะไรก็ตามที่คุณต้องการเรียกใช้แอปของคุณ จะถูกรวบรวมเป็นไบนารีเดียว มีประโยชน์มากสำหรับการจัดการเวอร์ชันในเวลาทำงาน
ไปยังมีชุมชนที่ดี
ความแตกต่างระหว่าง var x int = 2 และ x := 2 คืออะไร?
ผลลัพธ์จะเหมือนกันตัวแปรที่มีค่า 2
ด้วย var x int = 2 เรากำลังตั้งค่าประเภทตัวแปรเป็นจำนวนเต็มในขณะที่มี x := 2 เรากำลังปล่อยให้เป็นตัวของตัวเอง
จริงหรือเท็จ? ใน Go เราสามารถ redeclare ตัวแปรและเมื่อประกาศแล้วเราต้องใช้มัน
เท็จ. เราไม่สามารถใช้ตัวแปรใหม่ได้ แต่ใช่เราต้องใช้ตัวแปรที่ประกาศ
คุณใช้ไลบรารีอะไร?
ควรตอบตามการใช้งานของคุณ แต่ตัวอย่างบางส่วนคือ:
ปัญหาเกี่ยวกับบล็อกของรหัสต่อไปนี้คืออะไร? จะแก้ไขได้อย่างไร? func main() {
var x float32 = 13.5
var y int
y = x
}
บล็อกของรหัสต่อไปนี้พยายามที่จะแปลงจำนวนเต็ม 101 เป็นสตริง แต่เราจะได้รับ "E" แทน ทำไมเป็นเช่นนั้น? จะแก้ไขได้อย่างไร? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
มันดูว่าค่า Unicode ถูกตั้งค่าไว้ที่ 101 และใช้สำหรับการแปลงจำนวนเต็มเป็นสตริง หากคุณต้องการรับ "101" คุณควรใช้แพ็คเกจ "stronconv" และแทนที่ y = string(x) ด้วย y = strconv.Itoa(x)
มีอะไรผิดปกติกับรหัสต่อไปนี้: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
ค่าคงที่ใน GO สามารถประกาศได้โดยใช้นิพจน์คงที่ แต่ x , y และผลรวมของพวกเขาเป็นตัวแปร
const initializer x + y is not a constant
ผลลัพธ์ของบล็อกของรหัสต่อไปนี้จะเป็นอย่างไร: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
ตัวระบุ IOTA ของ Go ใช้ในการประกาศ const เพื่อลดความซับซ้อนของคำจำกัดความของตัวเลขที่เพิ่มขึ้น เนื่องจากมันสามารถใช้ในการแสดงออกจึงมีความสามารถทั่วไปเกินกว่าการแจกแจงอย่างง่าย
x และ y ในกลุ่ม IOTA แรก z ในครั้งที่สอง
หน้า iota ใน Go Wiki
_ ใช้อะไรใน GO?
มันหลีกเลี่ยงการประกาศตัวแปรทั้งหมดสำหรับค่าผลตอบแทน มันถูกเรียกว่าตัวระบุว่างเปล่า
คำตอบใน SO
ผลลัพธ์ของบล็อกของรหัสต่อไปนี้จะเป็นอย่างไร: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
เนื่องจาก IOTA แรกได้รับการประกาศด้วยค่า 3 ( + 3 ) อันถัดไปมีค่า 4
ผลลัพธ์ของบล็อกของรหัสต่อไปนี้จะเป็นอย่างไร: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
เอาท์พุท: 2 1 3
aritcle เกี่ยวกับการซิงค์/waitgroup
การซิงค์แพ็คเกจ Golang
ผลลัพธ์ของบล็อกของรหัสต่อไปนี้จะเป็นอย่างไร: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
เอาท์พุท:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
ใน mod1 a คือลิงก์และเมื่อเราใช้ a[i] เรากำลังเปลี่ยนค่า s1 เป็น แต่ใน mod2 append สร้างชิ้นใหม่และเรากำลังเปลี่ยนเฉพาะ a ไม่ใช่ s2
aritcle เกี่ยวกับอาร์เรย์โพสต์บล็อกเกี่ยวกับ append
ผลลัพธ์ของบล็อกของรหัสต่อไปนี้จะเป็นอย่างไร: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
เอาท์พุท: 3
Golang Container/Heap Package
Mongo
ข้อดีของ MongoDB คืออะไร? หรือกล่าวอีกนัยหนึ่งว่าทำไมต้องเลือก MongoDB และไม่ใช่การใช้งานอื่น ๆ ของ NOSQL?
ข้อดีของ MongoDB มีดังนี้:
- แผนผัง
- ง่ายต่อการขยายออก
- ไม่มีการรวมที่ซับซ้อน
- โครงสร้างของวัตถุเดียวชัดเจน
ความแตกต่างระหว่าง SQL และ NOSQL คืออะไร?
ความแตกต่างที่สำคัญคือฐานข้อมูล SQL มีโครงสร้าง (ข้อมูลถูกเก็บไว้ในรูปแบบของตารางที่มีแถวและคอลัมน์ - เช่นตารางสเปรดชีต Excel) ในขณะที่ NOSQL ไม่มีโครงสร้างและการจัดเก็บข้อมูลอาจแตกต่างกันไปขึ้นอยู่กับวิธีการตั้งค่า NOSQL DB เช่นคู่คีย์-ค่าที่มุ่งเน้นเอกสาร ฯลฯ
คุณต้องการใช้ NOSQL/Mongo มากกว่า SQL ในสถานการณ์ใดบ้าง
ข้อมูลที่แตกต่างกันซึ่งเปลี่ยนแปลงบ่อยครั้ง- ความสอดคล้องของข้อมูลและความสมบูรณ์ไม่ได้มีความสำคัญสูงสุด
- ดีที่สุดถ้าฐานข้อมูลจำเป็นต้องปรับขนาดอย่างรวดเร็ว
เอกสารคืออะไร? คอลเลกชันคืออะไร?
เอกสารเป็นบันทึกใน MongoDB ซึ่งถูกเก็บไว้ในรูปแบบ BSON (Binary JSON) และเป็นหน่วยพื้นฐานของข้อมูลใน MongoDB- คอลเลกชันเป็นกลุ่มของเอกสารที่เกี่ยวข้องที่เก็บไว้ในฐานข้อมูลเดียวใน MongoDB
ผู้รวบรวมคืออะไร?
- ผู้รวบรวมเป็นกรอบใน MongoDB ที่ดำเนินการในชุดข้อมูลเพื่อส่งคืนผลลัพธ์ที่คำนวณได้เพียงครั้งเดียว
อะไรดีกว่ากัน? เอกสารที่ฝังอยู่หรืออ้างอิง?
- ไม่มีคำตอบที่ชัดเจนซึ่งดีกว่าขึ้นอยู่กับกรณีการใช้งานเฉพาะและข้อกำหนด คำอธิบายบางอย่าง: เอกสารที่ฝังตัวให้การอัปเดตอะตอมในขณะที่เอกสารอ้างอิงอนุญาตให้มีการทำให้เป็นมาตรฐานที่ดีขึ้น
คุณได้ทำการเพิ่มประสิทธิภาพการดึงข้อมูลใน Mongo หรือไม่? ถ้าไม่คุณสามารถคิดเกี่ยวกับวิธีการเพิ่มประสิทธิภาพการดึงข้อมูลที่ช้าได้หรือไม่?
- บางวิธีในการเพิ่มประสิทธิภาพการดึงข้อมูลใน MongoDB คือ: การจัดทำดัชนีการออกแบบสคีมาที่เหมาะสมการเพิ่มประสิทธิภาพแบบสอบถามและการปรับสมดุลการโหลดฐานข้อมูล
การสอบถาม
อธิบายคำถามนี้: db.books.find({"name": /abc/})
อธิบายคำถามนี้: db.books.find().sort({x:1})
ความแตกต่างระหว่าง Find () และ find_one () คืออะไร?
find() ส่งคืนเอกสารทั้งหมดที่ตรงกับเงื่อนไขการสืบค้น- find_one () ส่งคืนเอกสารเดียวที่ตรงกับเงื่อนไขการสืบค้น (หรือ null หากไม่พบการจับคู่)
คุณจะส่งออกข้อมูลจาก Mongo DB ได้อย่างไร
Mongoexport- ภาษาการเขียนโปรแกรม
SQL
แบบฝึกหัด SQL
| ชื่อ | หัวข้อ | วัตถุประสงค์และคำแนะนำ | สารละลาย | ความคิดเห็น |
|---|
| ฟังก์ชั่นกับการเปรียบเทียบ | การปรับปรุงการสอบถาม | ออกกำลังกาย | สารละลาย | |
การประเมินตนเองของ SQL
SQL คืออะไร?
SQL (ภาษาคิวรีที่มีโครงสร้าง) เป็นภาษามาตรฐานสำหรับฐานข้อมูลเชิงสัมพันธ์ (เช่น MySQL, Mariadb, ... )
มันใช้สำหรับการอ่านอัปเดตการลบและการสร้างข้อมูลในฐานข้อมูลเชิงสัมพันธ์
SQL แตกต่างจาก NOSQL อย่างไร
ความแตกต่างที่สำคัญคือฐานข้อมูล SQL มีโครงสร้าง (ข้อมูลถูกเก็บไว้ในรูปแบบของตารางที่มีแถวและคอลัมน์ - เช่นตารางสเปรดชีต Excel) ในขณะที่ NOSQL ไม่มีโครงสร้างและการจัดเก็บข้อมูลอาจแตกต่างกันไปขึ้นอยู่กับวิธีการตั้งค่า NOSQL DB เช่นคู่คีย์-ค่าที่มุ่งเน้นเอกสาร ฯลฯ
ควรใช้ SQL เมื่อใด nosql?
SQL - ใช้งานได้ดีที่สุดเมื่อความสมบูรณ์ของข้อมูลเป็นสิ่งสำคัญ โดยทั่วไปแล้ว SQL จะถูกนำไปใช้กับธุรกิจและพื้นที่หลายแห่งภายในสาขาการเงินเนื่องจากการปฏิบัติตามกรด
NOSQL - ยอดเยี่ยมถ้าคุณต้องการขยายสิ่งต่างๆอย่างรวดเร็ว NOSQL ได้รับการออกแบบโดยคำนึงถึงเว็บแอปพลิเคชันดังนั้นจึงใช้งานได้ดีหากคุณต้องการกระจายข้อมูลเดียวกันไปยังเซิร์ฟเวอร์หลายเครื่องได้อย่างรวดเร็ว
นอกจากนี้เนื่องจาก NOSQL ไม่ได้ยึดติดกับตารางที่เข้มงวดกับโครงสร้างคอลัมน์และโครงสร้างแถวที่ฐานข้อมูลเชิงสัมพันธ์ต้องการคุณสามารถจัดเก็บประเภทข้อมูลที่แตกต่างกันเข้าด้วยกัน
SQL ในทางปฏิบัติ - พื้นฐาน
สำหรับคำถามเหล่านี้เราจะใช้ลูกค้าและตารางคำสั่งซื้อที่แสดงด้านล่าง:
ลูกค้า
| customer_id | customer_name | itemit_in_cart | cash_spent_to_date |
|---|
| 100204 | จอห์นสมิ ธ | 0 | 20.00 น |
| 100205 | เจนสมิ ธ | 3 | 40.00 น |
| 100206 | บ๊อบบี้แฟรงค์ | 1 | 100.20 |
คำสั่งซื้อ
| customer_id | order_id | รายการ | ราคา | วันที่ _sold |
|---|
| 100206 | A123 | Ducky ยาง | 2.20 | 2019-09-18 |
| 100206 | A123 | อ่างอาบน้ำฟอง | 8.00 น | 2019-09-18 |
| 100206 | Q987 | 80 แพ็ค TP | 90.00 น | 2019-09-20 |
| 100205 | Z001 | อาหารแมว - ปลาทูน่า | 10.00 น | 2019-08-05 |
| 100205 | Z001 | อาหารแมว - ไก่ | 10.00 น | 2019-08-05 |
| 100205 | Z001 | อาหารแมว - เนื้อวัว | 10.00 น | 2019-08-05 |
| 100205 | Z001 | อาหารแมว - คิตตี้ quesadilla | 10.00 น | 2019-08-05 |
| 100204 | x202 | กาแฟ | 20.00 น | 2019-04-29 |
ฉันจะเลือกฟิลด์ทั้งหมดจากตารางนี้ได้อย่างไร?
เลือก *
จากลูกค้า;
รถเข็นของจอห์นมีกี่รายการ?
เลือก itemit_in_cart
จากลูกค้า
โดยที่ customer_name = "John Smith";
ผลรวมของเงินสดทั้งหมดที่ใช้ไปกับลูกค้าทั้งหมดคืออะไร?
เลือกผลรวม (cash_spent_to_date) เป็น sum_cash
จากลูกค้า;
มีกี่คนที่มีสิ่งของในรถเข็นของพวกเขา?
เลือกนับ (1) เป็น number_of_people_w_items
จากลูกค้า
โดยที่รายการ _in_cart> 0;
คุณจะเข้าร่วมตารางลูกค้าไปยังตารางการสั่งซื้อได้อย่างไร?
คุณจะเข้าร่วมกับคีย์ที่ไม่ซ้ำกัน ในกรณีนี้คีย์ที่ไม่ซ้ำกันคือ customer_id ทั้งในตารางลูกค้าและคำสั่งซื้อ
คุณจะแสดงว่าลูกค้ารายใดสั่งซื้อรายการใด
เลือก c.customer_name, o.item
จากลูกค้า c
คำสั่งซื้อเข้าร่วมซ้าย o
บน c.customer_id = o.customer_id;
การใช้คำสั่งพร้อมคุณจะแสดงให้เห็นว่าใครสั่งอาหารแมวและจำนวนเงินทั้งหมดที่ใช้ไป?
ด้วย cat_food เป็น (
เลือก customer_id, sum (ราคา) เป็น total_price
จากคำสั่งซื้อ
รายการเช่น "%cat food%"
กลุ่มโดย customer_id
-
เลือก customer_name, total_price
จากลูกค้า c
เข้าร่วม cat_food f
บน c.customer_id = f.customer_id
โดยที่ c.customer_id ใน (เลือก customer_id จาก cat_food);
แม้ว่านี่จะเป็นคำสั่งง่ายๆ แต่ประโยค "กับ" จะส่องแสงจริงๆเมื่อต้องใช้การสืบค้นที่ซับซ้อนบนโต๊ะก่อนเข้าร่วมอีก ด้วยข้อความที่ดีเพราะคุณสร้างอุณหภูมิหลอกเมื่อเรียกใช้การสืบค้นของคุณแทนที่จะสร้างตารางใหม่ทั้งหมด
ผลรวมของการซื้ออาหารแมวทั้งหมดไม่พร้อมใช้งานดังนั้นเราจึงใช้คำสั่งเพื่อสร้างตารางหลอกเพื่อดึงผลรวมของราคาที่ลูกค้าแต่ละรายใช้แล้วเข้าร่วมตารางตามปกติ
คุณจะใช้คิวรีใดต่อไปนี้ SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
เมื่อคุณใช้ฟังก์ชั่น ( YEAR(purchased_at) ) จะต้องสแกนฐานข้อมูลทั้งหมดเมื่อเทียบกับการใช้ดัชนีและโดยทั่วไปคอลัมน์ตามที่เป็นอยู่ในสถานะธรรมชาติ
โอเพ่นสแต็ค
คุณคุ้นเคยกับส่วนประกอบ/โครงการของ OpenStack อย่างไร?
คุณช่วยบอกฉันได้ไหมว่าบริการ/โครงการต่อไปนี้มีหน้าที่รับผิดชอบอะไร:- โนวา
- นิวตรอน
- ถ่าน
- ภาพรวม
- จุดสำคัญ
โนวา - จัดการอินสแตนซ์เสมือนจริง- นิวตรอน - จัดการเครือข่ายโดยการจัดหาเครือข่ายเป็นบริการ (NAAS)
- Cinder - บล็อกที่เก็บข้อมูล
- ภาพรวม - จัดการรูปภาพสำหรับเครื่องเสมือนและคอนเทนเนอร์ (ค้นหารับและลงทะเบียน)
- Keystone - บริการการตรวจสอบความถูกต้องทั่วคลาวด์
ระบุบริการ/โครงการที่ใช้สำหรับแต่ละรายการต่อไปนี้:- คัดลอกหรือสแนปชอตอินสแตนซ์
- GUI สำหรับการดูและแก้ไขทรัพยากร
- บล็อกที่เก็บข้อมูล
- จัดการอินสแตนซ์เสมือนจริง
ภาพรวม - บริการรูปภาพ ยังใช้สำหรับการคัดลอกหรืออินสแตนซ์สแน็ปช็อต- Horizon - GUI สำหรับการดูและแก้ไขทรัพยากร
- Cinder - บล็อกที่เก็บข้อมูล
- โนวา - จัดการอินสแตนซ์เสมือนจริง
ผู้เช่า/โครงการคืออะไร?
กำหนดจริงหรือเท็จ:- OpenStack ใช้ได้ฟรี
- บริการที่รับผิดชอบในการสร้างเครือข่ายคือภาพรวม
- วัตถุประสงค์ของผู้เช่า/โครงการคือการแบ่งปันทรัพยากรระหว่างโครงการต่าง ๆ และผู้ใช้ OpenStack
อธิบายรายละเอียดว่าคุณนำอินสแตนซ์ด้วย IP ลอยตัวอย่างไร
คุณได้รับโทรศัพท์จากลูกค้าที่พูดว่า: "ฉันสามารถ ping อินสแตนซ์ของฉันได้ แต่ไม่สามารถเชื่อมต่อ (ssh) ได้" ปัญหาอะไร
เครือข่ายประเภทใดที่ OpenStack รองรับ?
คุณแก้ไขปัญหาการจัดเก็บ OpenStack ได้อย่างไร? (เครื่องมือบันทึก ... )
คุณแก้ไขปัญหาการคำนวณ OpenStack ได้อย่างไร? (เครื่องมือบันทึก ... )
OpenStack การปรับใช้และ tripleo
คุณเคยปรับใช้ OpenStack ในอดีตหรือไม่? ถ้าใช่คุณสามารถอธิบายได้ว่าคุณทำได้อย่างไร?
คุณคุ้นเคยกับ Tripleo หรือไม่? แตกต่างจาก Devstack หรือ Packstack อย่างไร?
คุณสามารถอ่านเกี่ยวกับ Tripleo ได้ที่นี่
OpenStack Compute
คุณสามารถอธิบายรายละเอียดของโนวาได้หรือไม่?
ใช้ในการจัดหาและจัดการอินสแตนซ์เสมือนจริง- รองรับการเช่าหลายระดับในระดับที่แตกต่างกัน-การบันทึกการควบคุมผู้ใช้ปลายทางการตรวจสอบ ฯลฯ
- ปรับขนาดได้สูง
- การรับรองความถูกต้องสามารถทำได้โดยใช้ระบบภายในหรือ LDAP
- รองรับการจัดเก็บบล็อกหลายประเภท
- พยายามที่จะเป็นฮาร์ดแวร์และ hypervisor agnostice
คุณรู้อะไรเกี่ยวกับสถาปัตยกรรมและส่วนประกอบของโนวา?
Nova -Api - เซิร์ฟเวอร์ที่ให้บริการข้อมูลเมตาและคำนวณ APIs- ส่วนประกอบของโนวาที่แตกต่างกันสื่อสารโดยใช้คิว (RabbitMQ โดยปกติ) และฐานข้อมูล
- คำขอสำหรับการสร้างอินสแตนซ์จะถูกตรวจสอบโดย Nova-Scheduler ซึ่งกำหนดว่าจะสร้างและทำงานอินสแตนซ์ที่ใด
- Nova-Compute เป็นส่วนประกอบที่รับผิดชอบในการสื่อสารกับ Hypervisor สำหรับการสร้างอินสแตนซ์และจัดการวงจรชีวิตของมัน
OpenStack Networking (นิวตรอน)
อธิบายรายละเอียดนิวตรอน
หนึ่งในองค์ประกอบหลักของ OpenStack และโครงการสแตนด์อโลน- นิวตรอนมุ่งเน้นไปที่การส่งมอบเครือข่ายเป็นบริการ
- ด้วยนิวตรอนผู้ใช้สามารถตั้งค่าเครือข่ายในคลาวด์และกำหนดค่าและจัดการบริการเครือข่ายที่หลากหลาย
- นิวตรอนโต้ตอบกับ:
Keystone - อนุญาตการโทร API
- โนวา - โนวาสื่อสารกับนิวตรอนเพื่อเสียบ NICS เข้ากับเครือข่าย
- Horizon - รองรับเอนทิตีเครือข่ายในแดชบอร์ดและยังมีมุมมองโทโพโลยีซึ่งรวมถึงรายละเอียดเครือข่าย
อธิบายแต่ละองค์ประกอบต่อไปนี้:- นิวตรอน DHCP-agent
- นิวตรอน -L3-agent
- เอเจนต์นิวตรอน
- นิวตรอน-*-agtent
- เซิร์ฟเวอร์นิวตรอน
Neutron-L3-Agent-การส่งต่อ L3/NAT (ให้การเข้าถึงเครือข่ายภายนอกสำหรับ VMS เป็นต้น)- Neutron-DHCP-Agent-บริการ DHCP
- นิวตรอนเมตร-เอเจนต์-การวัดปริมาณการใช้งาน L3
- นิวตรอน-*-Agtent-จัดการการกำหนดค่า VSWITCH ในแต่ละรายการในแต่ละการคำนวณ (ขึ้นอยู่กับปลั๊กอินที่เลือก)
- Neutron -Server - เปิดเผย API เครือข่ายและส่งคำขอไปยังปลั๊กอินอื่น ๆ หากจำเป็น
อธิบายประเภทเครือข่ายเหล่านี้:- เครือข่ายการจัดการ
- เครือข่ายแขกรับเชิญ
- เครือข่าย API
- เครือข่ายภายนอก
เครือข่ายการจัดการ - ใช้สำหรับการสื่อสารภายในระหว่างส่วนประกอบ OpenStack ที่อยู่ IP ใด ๆ ในเครือข่ายนี้สามารถเข้าถึงได้ภายใน Datacetner เท่านั้น- เครือข่ายแขก - ใช้สำหรับการสื่อสารระหว่างอินสแตนซ์/VMS
- API Network - ใช้สำหรับบริการการสื่อสาร API ที่อยู่ IP ใด ๆ ในเครือข่ายนี้สามารถเข้าถึงได้แบบสาธารณะ
- เครือข่ายภายนอก - ใช้สำหรับการสื่อสารสาธารณะ ที่อยู่ IP ใด ๆ ในเครือข่ายนี้สามารถเข้าถึงได้โดยทุกคนบนอินเทอร์เน็ต
คุณควรลบเอนทิตีต่อไปนี้:- เครือข่าย
- ท่าเรือ
- เราเตอร์
- ซับเน็ต
- เครือข่าย
- เรา
- เตอร์
ซับเน็ต - พอร์ต
มีหลายเหตุผลสำหรับสิ่งนั้น ตัวอย่างหนึ่ง: คุณไม่สามารถลบเราเตอร์ได้หากมีพอร์ตที่ใช้งานอยู่
What is a provider network?
What components and services exist for L2 and L3?
What is the ML2 plug-in? Explain its architecture
What is the L2 agent? How does it works and what is it responsible for?
What is the L3 agent? How does it works and what is it responsible for?
Explain what the Metadata agent is responsible for
What networking entities Neutron supports?
How do you debug OpenStack networking issues? (tools, logs, ...)
OpenStack - Glance
Explain Glance in detail
Glance is the OpenStack image service- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
True or False? there can be two objects with the same name in the same container but not in two different containers
เท็จ. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- บทบาท
- Tenant/Project
- บริการ
- Endpoint
- โทเค็น
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
โดยใช้:
ชื่อ- หมายเลขประจำตัวประชาชน
- พิมพ์
- คำอธิบาย
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- สวิฟท์
- ซาฮารา
- Ironic
- โทรฟ
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- แพม
- เมคแคช
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
หุ่นเชิด
What is Puppet? มันทำงานอย่างไร?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
ยืดหยุ่น
What is the Elastic Stack?
The Elastic Stack consists of:
- การค้นหาแบบยืดหยุ่น
- คิบานะ
- ล็อกสแตช
- Beats
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
การค้นหาแบบยืดหยุ่น
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. มันหมายความว่าอะไร? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
True or False? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
เท็จ. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". มันหมายความว่าอะไร?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? What would you use it for?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
ล็อกสแตช
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
คิบานะ
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". มันหมายความว่าอะไร?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Read here
True or False? a single harvester harvest multiple files, according to the limits set in filebeat.yml
เท็จ. One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
กองยืดหยุ่น
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
Distributed
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
เครือข่าย- ซีพียู
- หน่วยความจำ
- ดิสก์
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
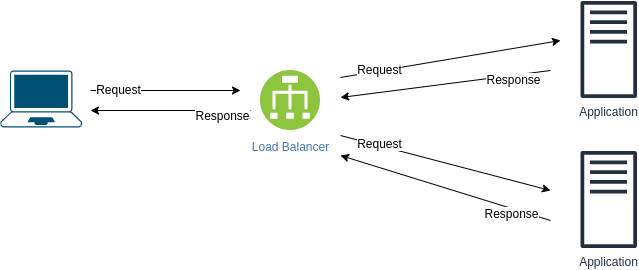
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage , หน่วยความจำ, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
เบ็ดเตล็ด
| ชื่อ | หัวข้อ | Objective & Instructions | สารละลาย | ความคิดเห็น |
|---|
| Highly Available "Hello World" | ออกกำลังกาย | สารละลาย | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
เอพีไอ
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
True or False? API Definition is the same as API Specification
เท็จ. From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
ข้อดี:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
การอนุญาต- การบันทึก
- การรับรองความถูกต้อง
- Ordering
- Front-end
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use? ทำไม
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
True or False? Any valid JSON file is also a valid YAML file
จริง. Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
เจสัน What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
Firmware
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
คาสซานดรา
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
What is HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP response
True or False? HTTP is stateful
เท็จ. It doesn't maintain state for incoming request.
How HTTP request looks like?
It consists of:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
รับ- โพสต์
- ศีรษะ
- ใส่
- ลบ
- เชื่อมต่อ
- ตัวเลือก
- ติดตาม
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. มันหมายความว่าอะไร?
The server didn't receive a response from another server it communicates with in a timely manner.
What is a proxy?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Round Robin- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
จุดด้อย:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
คุกกี้ There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Round Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
ใบอนุญาต
Are you familiar with "Creative Commons"? What do you know about it?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
สุ่ม
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache. แหล่งที่มา
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
พื้นที่จัดเก็บ
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
ข้อดี:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
ข้อดี:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
การทดสอบ
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- Capacity Testing
- Volume Testing
- Endurance Testing
Regex
Given a text file, perform the following exercises
สารสกัด
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
แทนที่
Replace tabs with four spaces
Replace 'red' with 'green'
System Design
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. ความสามารถในการขยายขนาด
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
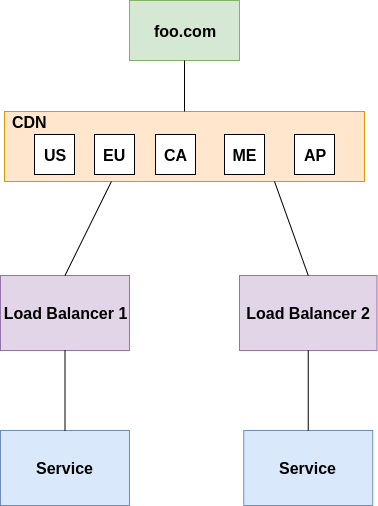
What is the problem with the following architecture and how would you fix it?
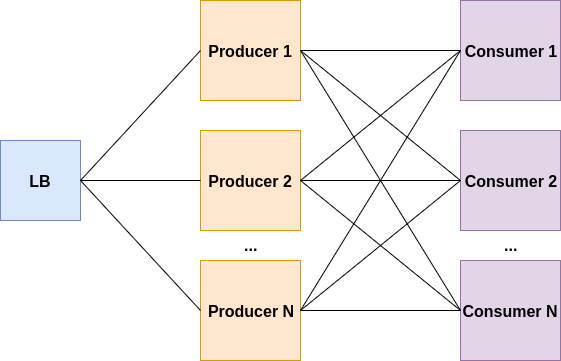
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?

How would you scale the architecture from the previous question to hundreds of users?
Cache
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
ลองดูที่นี่
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrations
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

ฮาร์ดแวร์
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
ภายนอก- Machine check
- ฉัน/โอ
- Program
- รีสตาร์ท
- Supervisor call (SVC)
Big Data
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers. True or False? Ceph favor consistency and correctness over performances
จริง Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
เฝ้าสังเกต- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- ผู้จัดการ
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? มันทำงานอย่างไร?
Packer
What is Packer? มันใช้ทำอะไร?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
ปล่อย
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
ใบรับรอง
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. ขอให้โชคดี :)
AWS
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
สีฟ้า
- AZ-900 (Latest update: 2021)
Kubernetes
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




เครดิต
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
ใบอนุญาต


