optuna
v4.1.0
- เว็บไซต์ | - เอกสาร | คู่มือการติดตั้ง | บทช่วยสอน | ตัวอย่าง | ทวิตเตอร์ | ลิงค์อิน | ปานกลาง
Optuna คือเฟรมเวิร์กซอฟต์แวร์เพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์อัตโนมัติ ซึ่งได้รับการออกแบบมาเพื่อการเรียนรู้ของเครื่องโดยเฉพาะ มันมี API ผู้ใช้สไตล์ ที่กำหนดโดยรัน ที่จำเป็น ต้องขอบคุณ API แบบกำหนดโดยรัน ของเรา โค้ดที่เขียนด้วย Optuna จึงมีความเป็นโมดูลสูงและผู้ใช้ Optuna ก็สามารถสร้างพื้นที่การค้นหาสำหรับไฮเปอร์พารามิเตอร์แบบไดนามิกได้
Terminator ซึ่งได้รับการขยายใน Optuna 4.0JournalStorage ซึ่งมีความเสถียรใน Optuna 4.0pip install -U optuna ค้นหาข้อมูลล่าสุดได้ที่นี่และตรวจสอบบทความของเรา Optuna มีฟังก์ชันการทำงานที่ทันสมัยดังนี้:
เราใช้เงื่อนไข การศึกษา และ ทดลอง ดังนี้:
โปรดดูโค้ดตัวอย่างด้านล่าง เป้าหมายของ การศึกษา คือการค้นหาชุดค่าไฮเปอร์พารามิเตอร์ที่เหมาะสมที่สุด (เช่น regressor และ svr_c ) ผ่าน การทดลอง หลายครั้ง (เช่น n_trials=100 ) Optuna เป็นเฟรมเวิร์กที่ออกแบบมาสำหรับระบบอัตโนมัติและการเร่งความเร็วของ การศึกษา การปรับให้เหมาะสม
import ...
# Define an objective function to be minimized.
def objective ( trial ):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial . suggest_categorical ( 'regressor' , [ 'SVR' , 'RandomForest' ])
if regressor_name == 'SVR' :
svr_c = trial . suggest_float ( 'svr_c' , 1e-10 , 1e10 , log = True )
regressor_obj = sklearn . svm . SVR ( C = svr_c )
else :
rf_max_depth = trial . suggest_int ( 'rf_max_depth' , 2 , 32 )
regressor_obj = sklearn . ensemble . RandomForestRegressor ( max_depth = rf_max_depth )
X , y = sklearn . datasets . fetch_california_housing ( return_X_y = True )
X_train , X_val , y_train , y_val = sklearn . model_selection . train_test_split ( X , y , random_state = 0 )
regressor_obj . fit ( X_train , y_train )
y_pred = regressor_obj . predict ( X_val )
error = sklearn . metrics . mean_squared_error ( y_val , y_pred )
return error # An objective value linked with the Trial object.
study = optuna . create_study () # Create a new study.
study . optimize ( objective , n_trials = 100 ) # Invoke optimization of the objective function. บันทึก
ตัวอย่างเพิ่มเติมสามารถพบได้ใน optuna/optuna-examples
ตัวอย่างครอบคลุมถึงการตั้งค่าปัญหาที่หลากหลาย เช่น การเพิ่มประสิทธิภาพหลายวัตถุประสงค์ การเพิ่มประสิทธิภาพที่มีข้อจำกัด การตัด และการเพิ่มประสิทธิภาพแบบกระจาย
Optuna มีให้บริการที่ Python Package Index และบน Anaconda Cloud
# PyPI
$ pip install optuna # Anaconda Cloud
$ conda install -c conda-forge optunaสำคัญ
Optuna รองรับ Python 3.8 หรือใหม่กว่า
นอกจากนี้ เรายังจัดเตรียมอิมเมจ Optuna docker บน DockerHub อีกด้วย
Optuna มีคุณสมบัติบูรณาการกับไลบรารีบุคคลที่สามต่างๆ สามารถดูการรวมระบบได้ใน optuna/optuna-integration และมีเอกสารอยู่ที่นี่
Optuna Dashboard คือเว็บแดชบอร์ดแบบเรียลไทม์สำหรับ Optuna คุณสามารถตรวจสอบประวัติการเพิ่มประสิทธิภาพ ความสำคัญของไฮเปอร์พารามิเตอร์ ฯลฯ ได้ในกราฟและตาราง คุณไม่จำเป็นต้องสร้างสคริปต์ Python เพื่อเรียกใช้ฟังก์ชันการแสดงภาพของ Optuna ยินดีต้อนรับการร้องขอคุณสมบัติและรายงานข้อผิดพลาด!
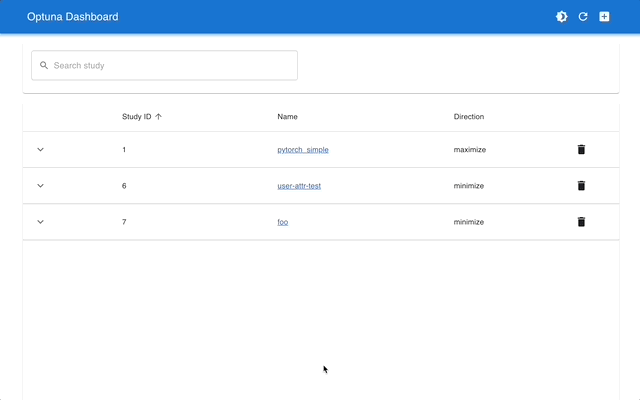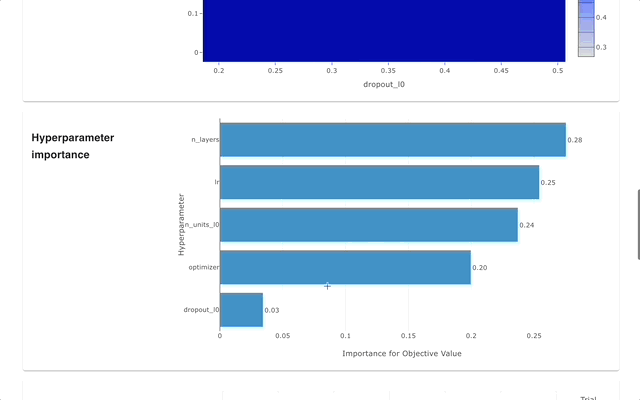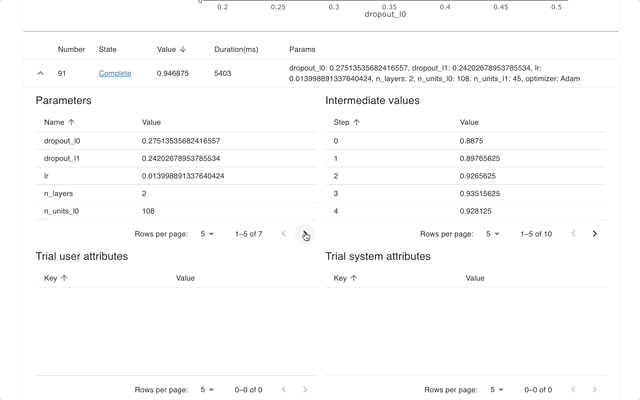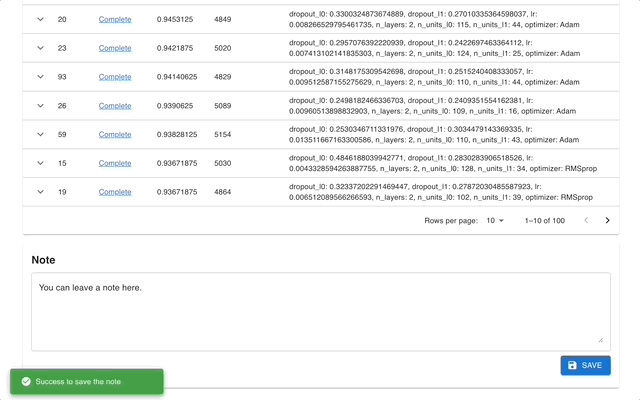
optuna-dashboard สามารถติดตั้งผ่าน pip:
$ pip install optuna-dashboardเคล็ดลับ
โปรดตรวจสอบความสะดวกของ Optuna Dashboard โดยใช้โค้ดตัวอย่างด้านล่าง
บันทึกโค้ดต่อไปนี้เป็น optimize_toy.py
import optuna
def objective ( trial ):
x1 = trial . suggest_float ( "x1" , - 100 , 100 )
x2 = trial . suggest_float ( "x2" , - 100 , 100 )
return x1 ** 2 + 0.01 * x2 ** 2
study = optuna . create_study ( storage = "sqlite:///db.sqlite3" ) # Create a new study with database.
study . optimize ( objective , n_trials = 100 )จากนั้นลองใช้คำสั่งด้านล่าง:
# Run the study specified above
$ python optimize_toy.py
# Launch the dashboard based on the storage `sqlite:///db.sqlite3`
$ optuna-dashboard sqlite:///db.sqlite3
...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.OptunaHub เป็นแพลตฟอร์มแบ่งปันฟีเจอร์สำหรับ Optuna คุณสามารถใช้คุณสมบัติที่ลงทะเบียนและเผยแพร่แพ็คเกจของคุณ
optunahub สามารถติดตั้งผ่าน pip:
$ pip install optunahub
# Install AutoSampler dependencies (CPU only is sufficient for PyTorch)
$ pip install cmaes scipy torch --extra-index-url https://download.pytorch.org/whl/cpu คุณสามารถโหลดโมดูลที่ลงทะเบียนด้วย optunahub.load_module
import optuna
import optunahub
def objective ( trial : optuna . Trial ) -> float :
x = trial . suggest_float ( "x" , - 5 , 5 )
y = trial . suggest_float ( "y" , - 5 , 5 )
return x ** 2 + y ** 2
module = optunahub . load_module ( package = "samplers/auto_sampler" )
study = optuna . create_study ( sampler = module . AutoSampler ())
study . optimize ( objective , n_trials = 10 )
print ( study . best_trial . value , study . best_trial . params )สำหรับรายละเอียดเพิ่มเติม โปรดดูเอกสารประกอบของ Optunahub
คุณสามารถเผยแพร่แพ็คเกจของคุณผ่านทาง optunahub-registry ดูบทช่วยสอน OptunaHub
เรายินดีอย่างยิ่งที่จะมีส่วนร่วมกับ Optuna!
หากคุณยังใหม่กับ Optuna โปรดตรวจสอบปัญหาแรกที่ดี สิ่งเหล่านี้ค่อนข้างเรียบง่าย มีการกำหนดชัดเจน และมักเป็นจุดเริ่มต้นที่ดีเพื่อให้คุณคุ้นเคยกับขั้นตอนการทำงานสนับสนุนและนักพัฒนาอื่นๆ
หากคุณได้มีส่วนร่วมกับ Optuna แล้ว เราขอแนะนำปัญหาอื่นๆ ที่เกี่ยวข้องกับการต้อนรับ
สำหรับแนวทางทั่วไปเกี่ยวกับวิธีการมีส่วนร่วมในโครงการ โปรดดูที่ CONTRIBUTING.md
หากคุณใช้ Optuna ในโครงการวิจัยของคุณ โปรดอ้างอิงรายงาน KDD ของเราเรื่อง "Optuna: A Next-gen Hyperparameter Optimization Framework":
@inproceedings { akiba2019optuna ,
title = { {O}ptuna: A Next-Generation Hyperparameter Optimization Framework } ,
author = { Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori } ,
booktitle = { The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining } ,
pages = { 2623--2631 } ,
year = { 2019 }
}ใบอนุญาต MIT (ดูใบอนุญาต)
Optuna ใช้รหัสจากโครงการ SciPy และ fdlibm (ดู LICENSE_THIRD_PARTY)


