cracking the data science interview
1.0.0
นี่คือส่วนต่างๆ:
ในส่วนนี้ประกอบด้วยเอกสารสรุปแนวคิดพื้นฐานด้านวิทยาการข้อมูลที่จะถามในการสัมภาษณ์:
ในส่วนนี้ประกอบด้วยหนังสือที่ฉันเคยอ่านเกี่ยวกับวิทยาศาสตร์ข้อมูลและการเรียนรู้ของเครื่อง:
ส่วนนี้ประกอบด้วยคำถามตัวอย่างที่ถูกถามในการสัมภาษณ์วิทยาศาสตร์ข้อมูลจริง:
ส่วนนี้ประกอบด้วยคำถามกรณีศึกษาที่เกี่ยวข้องกับการออกแบบระบบการเรียนรู้ของเครื่องเพื่อแก้ไขปัญหาเชิงปฏิบัติ
ส่วนนี้ประกอบด้วยผลงานโครงการวิทยาศาสตร์ข้อมูลที่ฉันทำเพื่อวัตถุประสงค์ด้านวิชาการ การเรียนรู้ด้วยตนเอง และงานอดิเรก
หากต้องการประสบการณ์การเรียกดูพอร์ตโฟลิโอที่น่าพึงพอใจยิ่งขึ้น โปรดดูที่ jameskle.com/data-portfolio
Transfer Rec: งานวิจัยที่กำลังดำเนินอยู่ของฉันซึ่งผสมผสานการเรียนรู้เชิงลึกและระบบการแนะนำ
การแนะนำภาพยนตร์: ออกแบบโมเดลที่แตกต่างกัน 4 แบบที่แนะนำรายการต่างๆ บนชุดข้อมูล MovieLens
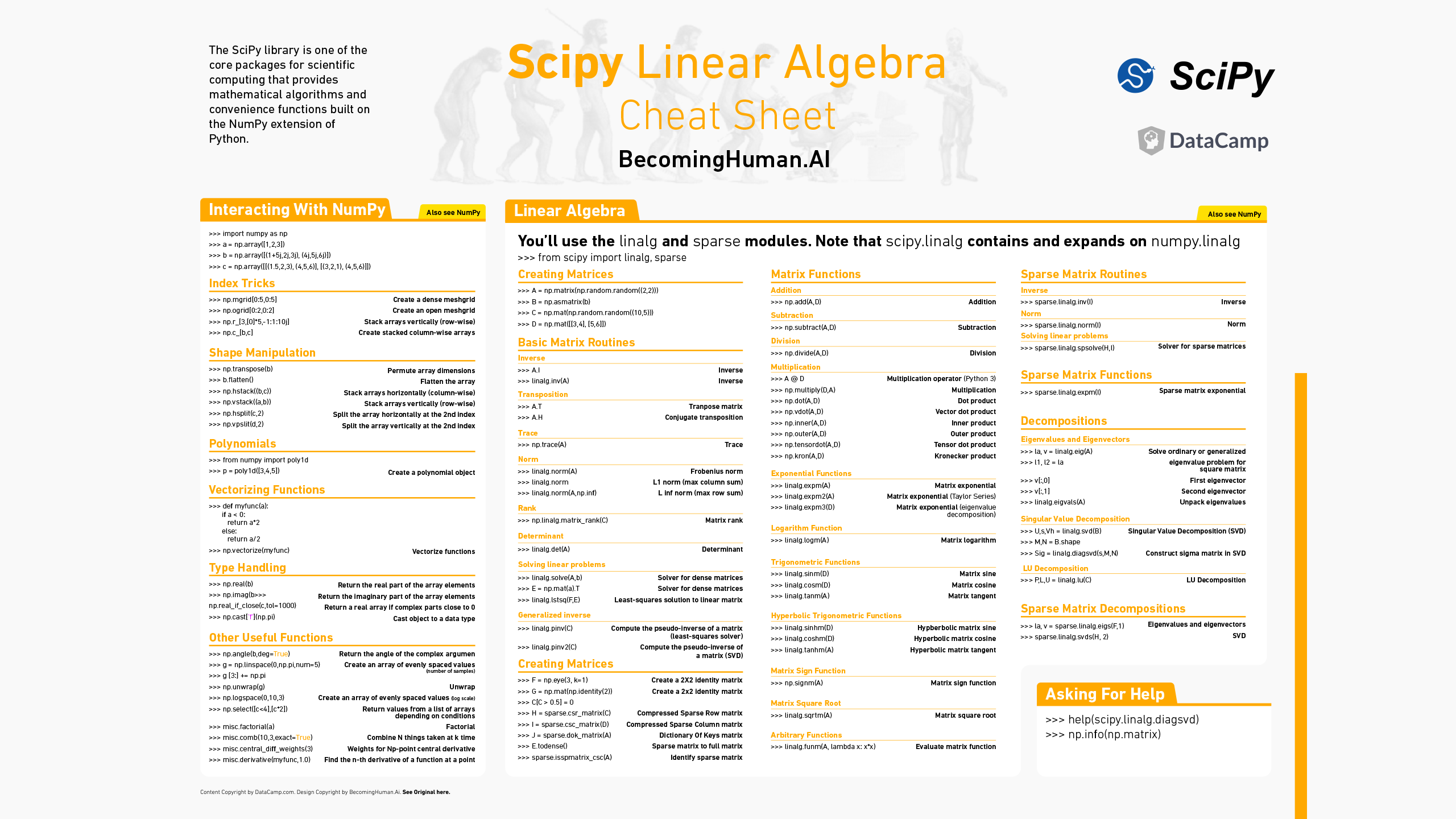
เครื่องมือ: PyTorch, TensorBoard, Keras, Pandas, NumPy, SciPy, Matplotlib, Seaborn, Scikit-Learn, เซอร์ไพรส์, Wordcloud
เครื่องมือเพิ่มประสิทธิภาพการเดินทาง: ใช้ XGBoost และอัลกอริธึมเชิงวิวัฒนาการเพื่อปรับเวลาการเดินทางให้เหมาะสมสำหรับรถแท็กซี่ในนิวยอร์กซิตี้
การวิเคราะห์ตะกร้าตลาดของ Instacart: จัดการกับความท้าทายในการวิเคราะห์ตะกร้าตลาดของ Instacart เพื่อคาดการณ์ว่าผลิตภัณฑ์ใดจะอยู่ในคำสั่งซื้อถัดไปของผู้ใช้
เครื่องมือ: Pandas, NumPy, Matplotlib, XGBoost, Geopy, Scikit-Learn
คำแนะนำด้านแฟชั่น: สร้างโมเดลที่ใช้ ResNet ซึ่งจัดประเภทและแนะนำรูปภาพแฟชั่นในฐานข้อมูล DeepFashion ตามความคล้ายคลึงกันทางความหมาย
การจัดประเภทแฟชั่น: พัฒนา Convolutional Neural Networks 4 แบบที่แตกต่างกันซึ่งจัดประเภทภาพในชุดข้อมูล Fashion MNIST
การจำแนกพันธุ์สุนัข: ออกแบบโครงข่ายประสาทเทียมแบบ Convolutional ที่ระบุสายพันธุ์สุนัข
การแบ่งส่วนถนน: ใช้เครือข่าย Convolutional เต็มรูปแบบสำหรับงานการแบ่งส่วนความหมายในชุดข้อมูล Kitty Road
เครื่องมือ: TensorFlow, Keras, Pandas, NumPy, Matplotlib, Scikit-Learn, TensorBoard
การวิเคราะห์ทีมฟุตบอลโลก 2018: การวิเคราะห์และการแสดงภาพชุดข้อมูล FIFA 18 เพื่อทำนายรายชื่อผู้เล่นตัวจริงของทีมต่างประเทศที่ดีที่สุดสำหรับ 10 ทีมในฟุตบอลโลก 2018 ในรัสเซีย
การวิเคราะห์ศิลปิน Spotify: การวิเคราะห์และการแสดงภาพสไตล์ดนตรีจากศิลปินที่แตกต่างกัน 50 คนพร้อมแนวเพลงที่หลากหลายบน Spotify
เครื่องมือ: Pandas, NumPy, Matplotlib, Rspotify, httr, dplyr, tidyr, Radarchart, ggplot2
ส่วนนี้ประกอบด้วยผลงานบทความวารสารศาสตร์ข้อมูลที่ฉันจัดทำสำหรับลูกค้าอิสระและเพื่อการเรียนรู้ด้วยตนเอง
หากต้องการประสบการณ์การเรียกดูพอร์ตโฟลิโอที่น่าพึงพอใจยิ่งขึ้น โปรดดูที่ jameskle.com/data-journalism
เทคนิคทางสถิติ 10 ประการที่นักวิทยาศาสตร์ข้อมูลจำเป็นต้องเชี่ยวชาญ
บทช่วยสอนการถดถอยโลจิสติก
การสอนต้นไม้การตัดสินใจ
สนับสนุนการสอนเครื่องเวกเตอร์
บทนำที่เป็นมิตรเกี่ยวกับการตลาดที่ขับเคลื่อนด้วยข้อมูลสำหรับผู้นำธุรกิจ
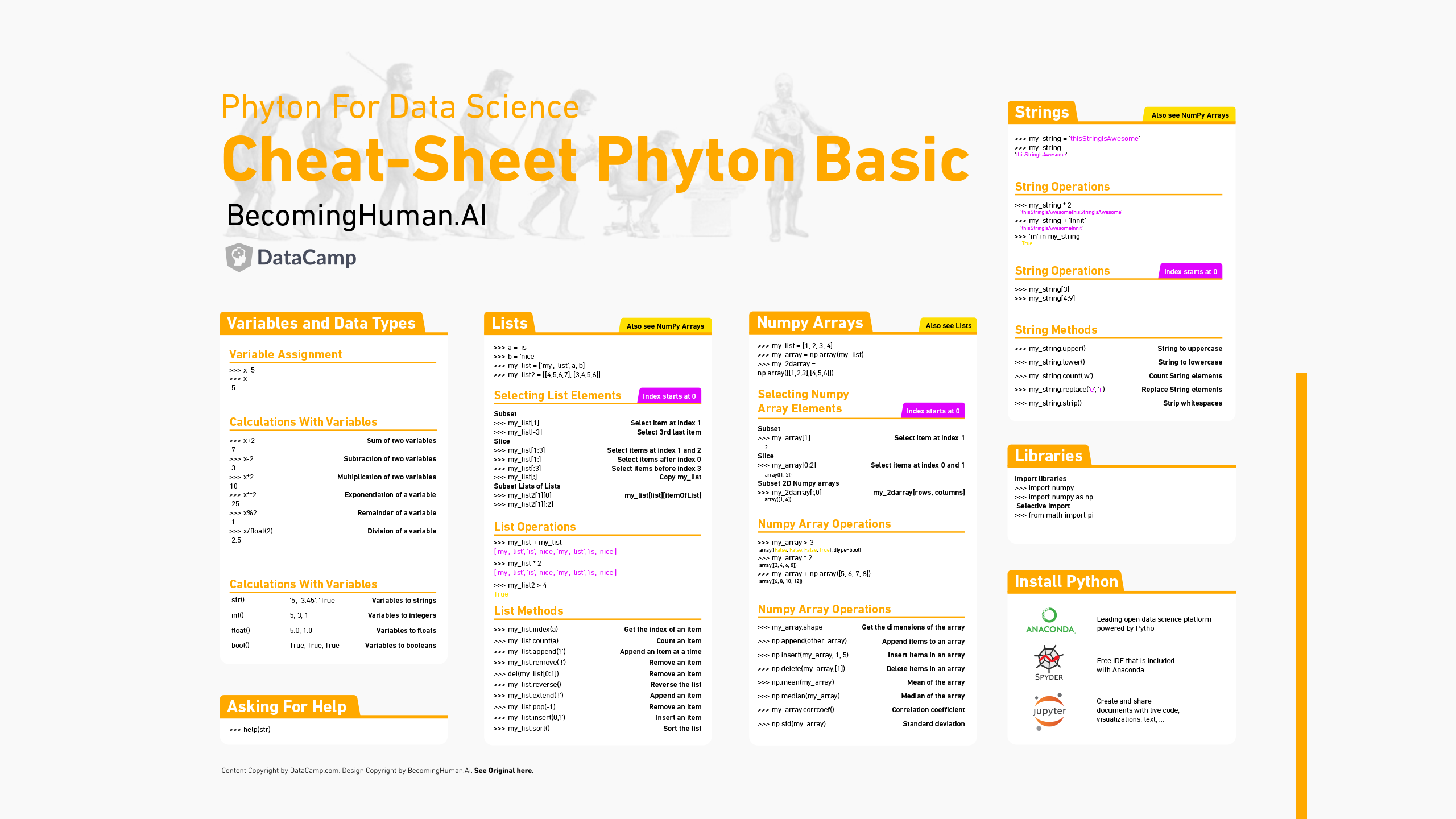
วิศวกรแมชชีนเลิร์นนิง 10 อัลกอริธึมจำเป็นต้องรู้
12 สิ่งที่ควรรู้เกี่ยวกับการเรียนรู้ของเครื่อง
ทัวร์ชมอัลกอริทึม 10 อันดับแรกสำหรับมือใหม่ด้านการเรียนรู้ของเครื่อง
เทคนิคการทำเหมืองข้อมูล 10 ข้อที่นักวิทยาศาสตร์ข้อมูลต้องการสำหรับกล่องเครื่องมือของพวกเขา
การจัดกลุ่มและการจำแนกประเภทในอีคอมเมิร์ซ
ABCs ของการเรียนรู้เพื่อจัดอันดับ
6 วิธีในการดีบักโมเดลการเรียนรู้ของเครื่อง
เส้นทางอาชีพแมชชีนเลิร์นนิง 8 เส้นทางที่ต้องก้าวไปสู่วันนี้
10 วิธีการเรียนรู้เชิงลึกที่ผู้ปฏิบัติงาน AI จำเป็นต้องนำไปใช้
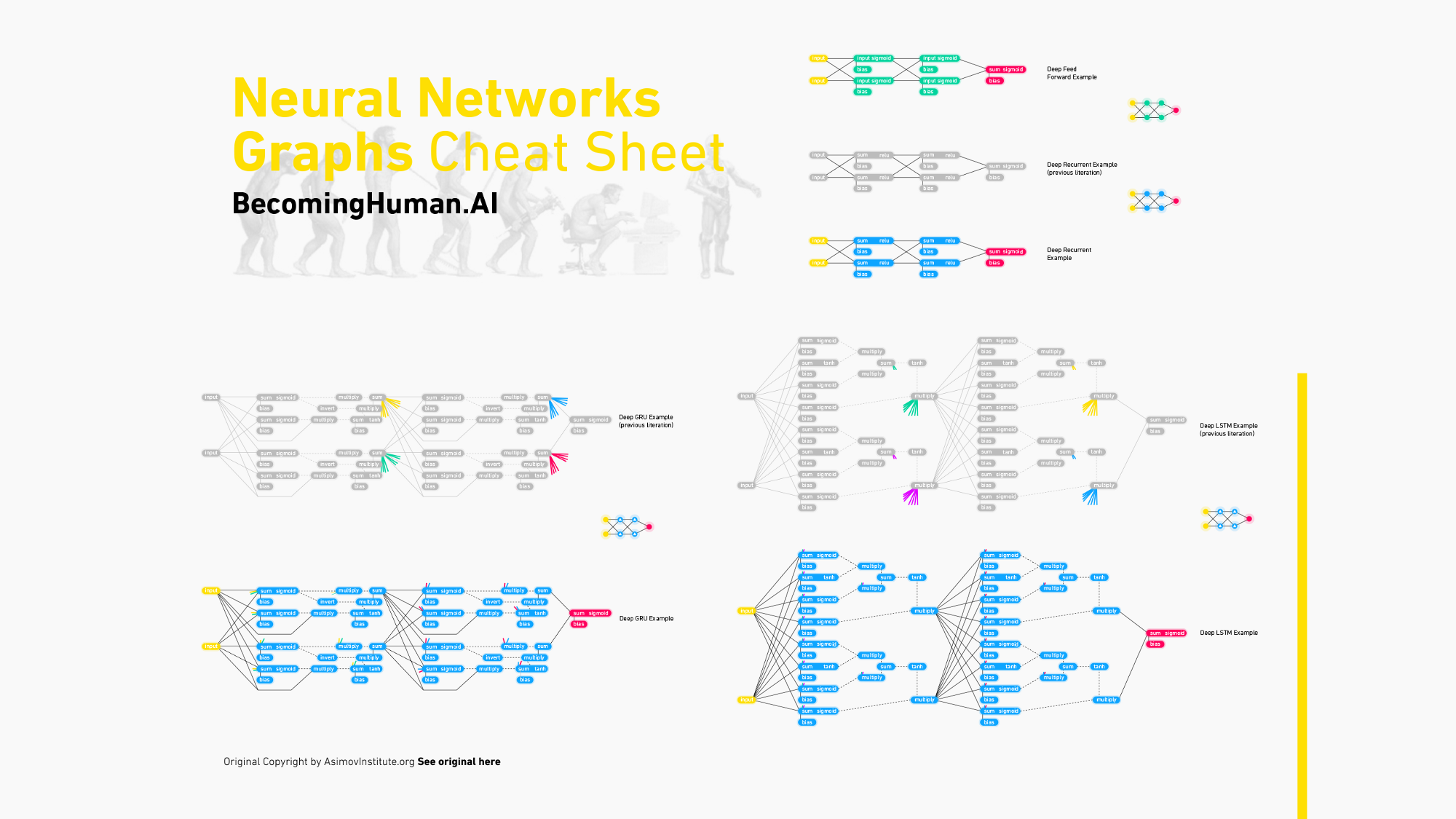
สถาปัตยกรรม Neural Network 8 แบบที่นักวิจัย ML จำเป็นต้องเรียนรู้
กรอบการเรียนรู้เชิงลึก 5 ประการที่ผู้เรียนเครื่องที่จริงจังทุกคนควรทำความคุ้นเคย
5 เทคนิคคอมพิวเตอร์วิทัศน์ที่จะเปลี่ยนวิธีการมองเห็นโลกของคุณ
โครงข่ายประสาทเทียมแบบ Convolutional: แบบจำลองที่ได้รับแรงบันดาลใจทางชีวภาพ
โครงข่ายประสาทเทียมที่เกิดซ้ำ: ขุมพลังแห่งการสร้างแบบจำลองภาษา
เทคนิค NLP 7 ประการที่จะเปลี่ยนวิธีการสื่อสารของคุณในอนาคต
5 เทรนด์ครอบงำวิสัยทัศน์คอมพิวเตอร์ในปี 2561
กรอบการเรียนรู้เชิงลึก 3 แบบสำหรับการรู้จำเสียงจากต้นทางถึงปลายทางที่ขับเคลื่อนอุปกรณ์ของคุณ
5 อัลกอริทึมสำหรับการอนุมานการเรียนรู้เชิงลึกอย่างมีประสิทธิภาพบนอุปกรณ์ขนาดเล็ก
เทคนิคการวิจัย 4 ข้อเพื่อฝึกฝนโมเดลโครงข่ายประสาทเทียมระดับลึกอย่างมีประสิทธิภาพมากขึ้น
สถาปัตยกรรมฮาร์ดแวร์ 2 แบบสำหรับการฝึกอบรมและการอนุมาน Deep Nets อย่างมีประสิทธิภาพ
10 แนวทางปฏิบัติที่ดีที่สุดในการเรียนรู้เชิงลึกที่ควรคำนึงถึงในปี 2020
เอกสารสรุป PDF เหล่านี้มาจาก BecomingHuman.AI