Interactive RAG
1.0.0
เจ้าหน้าที่กำลังปฏิวัติวิธีที่เราใช้โมเดลภาษาเพื่อการตัดสินใจและการปฏิบัติงาน ตัวแทนคือระบบที่ใช้โมเดลภาษาในการตัดสินใจและดำเนินงาน ได้รับการออกแบบมาเพื่อจัดการกับสถานการณ์ที่ซับซ้อนและให้ความยืดหยุ่นมากกว่าเมื่อเทียบกับวิธีการแบบเดิม เอเจนต์ถือเป็นกลไกการให้เหตุผลที่ใช้ประโยชน์จากโมเดลภาษาในการประมวลผลข้อมูล ดึงข้อมูลที่เกี่ยวข้อง นำเข้า (ก้อน/ฝัง) และสร้างการตอบกลับ
ในอนาคต เจ้าหน้าที่จะมีบทบาทสำคัญในการประมวลผลข้อความ ทำงานอัตโนมัติ และปรับปรุงการโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์เมื่อโมเดลภาษาก้าวหน้า
ในตัวอย่างนี้ เราจะเน้นไปที่การใช้ประโยชน์จากตัวแทนในการสร้างการเรียกข้อมูลเสริมแบบไดนามิก (RAG) แบบไดนามิก เมื่อใช้ ActionWeaver และ MongoDB Atlas คุณจะสามารถปรับเปลี่ยนกลยุทธ์ RAG ของคุณแบบเรียลไทม์ผ่านการโต้ตอบทางการสนทนา ไม่ว่าจะเป็นการเลือกชิ้นส่วนเพิ่มเติม เพิ่มขนาดชิ้นส่วน หรือปรับแต่งพารามิเตอร์อื่นๆ คุณสามารถปรับแต่งแนวทาง RAG ของคุณเพื่อให้ได้คุณภาพและความแม่นยำในการตอบสนองที่ต้องการ คุณสามารถเพิ่ม/ลบแหล่งข้อมูลไปยังฐานข้อมูลเวกเตอร์ของคุณโดยใช้ภาษาธรรมชาติได้!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
การแยกข้อความเป็นชิ้นๆ นั้นเยี่ยมยอด แต่คุณจะเก็บไว้ได้อย่างไร?
การสรุปช่วยประหยัดพื้นที่และเพิ่มความเร็ว แต่อาจทำให้สูญเสียรายละเอียดได้
การจัดเก็บข้อมูลดิบมีความแม่นยำ แต่เทอะทะ ช้ากว่า และ "รบกวน"
ข้อดีของการสรุป:
ข้อเสียของการสรุป:
อะไรที่เหมาะกับคุณ? ขึ้นอยู่กับความต้องการของคุณ! พิจารณา:
สาธิต 1
สร้างสภาพแวดล้อม Python ใหม่
python3 -m venv envเปิดใช้งานสภาพแวดล้อม Python ใหม่
source env/bin/activateติดตั้งข้อกำหนด
pip3 install -r requirements.txtตั้งค่าพารามิเตอร์ใน params.py:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
สร้างดัชนีการค้นหาด้วยคำจำกัดความต่อไปนี้
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}กำหนดสภาพแวดล้อม
export OPENAI_API_KEY=เพื่อเรียกใช้แอปพลิเคชัน RAG
env/bin/streamlit run rag/app.pyข้อมูลบันทึกที่สร้างโดยแอปพลิเคชันจะถูกผนวกเข้ากับ app.log
บอทนี้รองรับการดำเนินการต่อไปนี้: ตอบคำถาม ค้นหาเว็บ อ่าน URL ลบแหล่งที่มา แสดงรายการแหล่งที่มาทั้งหมด และรีเซ็ตข้อความ นอกจากนี้ยังรองรับการดำเนินการที่เรียกว่า iRAG ซึ่งช่วยให้คุณควบคุมกลยุทธ์ RAG ของตัวแทนของคุณได้แบบไดนามิก
เช่น "ตั้งค่าการกำหนดค่า RAG เป็น 3 แหล่งที่มาและขนาดชิ้น 1250" => การกำหนดค่า RAG ใหม่:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
หากบอทไม่สามารถให้คำตอบสำหรับคำถามจากข้อมูลที่จัดเก็บไว้ในร้านค้า Atlas Vector และกลยุทธ์ RAG ของคุณ (จำนวนแหล่งที่มา ขนาดก้อน min_rel_score ฯลฯ) บอทจะเริ่มการค้นหาเว็บเพื่อค้นหาข้อมูลที่เกี่ยวข้อง จากนั้นคุณสามารถสั่งให้บอทอ่านและเรียนรู้จากผลลัพธ์เหล่านั้นได้
RAG นั้นเจ๋งและทั้งหมดนั้น แต่การคิด "กลยุทธ์ RAG" ที่ถูกต้องนั้นเป็นเรื่องยาก ขนาดก้อนและจำนวนแหล่งที่มาที่ไม่ซ้ำกันจะมีผลกระทบโดยตรงต่อการตอบสนองที่สร้างโดย LLM
ในการพัฒนากลยุทธ์ RAG ที่มีประสิทธิภาพ กระบวนการนำเข้าแหล่งที่มาของเว็บ การแยกส่วน การฝัง ขนาดชิ้น และจำนวนแหล่งที่มาที่ใช้มีบทบาทสำคัญ การแบ่งกลุ่มข้อความที่ป้อนเพื่อความเข้าใจที่ดีขึ้น การฝังจะจับความหมาย และจำนวนแหล่งที่มาส่งผลต่อความหลากหลายของการตอบสนอง การค้นหาสมดุลที่เหมาะสมระหว่างขนาดชิ้นส่วนและจำนวนแหล่งที่มาถือเป็นสิ่งสำคัญสำหรับการตอบสนองที่แม่นยำและเกี่ยวข้อง จำเป็นต้องมีการทดลองและการปรับแต่งอย่างละเอียดเพื่อกำหนดการตั้งค่าที่เหมาะสมที่สุด
ก่อนที่เราจะเจาะลึกเรื่อง "การดึงข้อมูล" เรามาพูดถึง "กระบวนการนำเข้า" ก่อน
เหตุใดจึงต้องมีกระบวนการแยกต่างหากในการ "นำเข้า" เนื้อหาของคุณไปยังฐานข้อมูลเวกเตอร์ของคุณ ด้วยการใช้ความมหัศจรรย์ของตัวแทน เราจึงสามารถเพิ่มเนื้อหาใหม่ลงในฐานข้อมูลเวกเตอร์ได้อย่างง่ายดาย
มีฐานข้อมูลหลายประเภทที่สามารถจัดเก็บการฝังเหล่านี้ได้ โดยแต่ละประเภทจะใช้งานพิเศษของตัวเอง แต่สำหรับงานที่เกี่ยวข้องกับแอปพลิเคชัน GenAI ฉันขอแนะนำ MongoDB
คิดว่า MongoDB เป็นเค้กที่คุณทั้งกินและกินได้ มันให้พลังของภาษาในการสืบค้น Mongo Query Language มันยังรวมคุณสมบัติที่ยอดเยี่ยมทั้งหมดของ MongoDB ไว้ด้วย ยิ่งไปกว่านั้น มันยังช่วยให้คุณจัดเก็บบล็อคส่วนประกอบเหล่านี้ (การฝังเวกเตอร์) และดำเนินการทางคณิตศาสตร์กับพวกมันได้ ทั้งหมดในที่เดียว สิ่งนี้ทำให้ MongoDB Atlas เป็นร้านค้าครบวงจรสำหรับทุกความต้องการในการฝังเวกเตอร์ของคุณ!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
การใช้ ActionWeaver ซึ่งเป็น wrapper น้ำหนักเบาสำหรับการเรียกฟังก์ชัน API เราสามารถสร้างตัวแทนพร็อกซีผู้ใช้ที่ดึงและนำเข้าข้อมูลที่เกี่ยวข้องได้อย่างมีประสิทธิภาพโดยใช้ MongoDB Atlas
ตัวแทนพร็อกซีคือคนกลางที่ส่งคำขอไคลเอ็นต์ไปยังเซิร์ฟเวอร์หรือทรัพยากรอื่น จากนั้นจึงนำการตอบกลับกลับมา
เอเจนต์นี้นำเสนอข้อมูลแก่ผู้ใช้ในลักษณะโต้ตอบและปรับแต่งได้ ซึ่งจะช่วยยกระดับประสบการณ์ผู้ใช้โดยรวม
UserProxyAgent มีพารามิเตอร์ RAG หลายตัวที่สามารถปรับแต่งได้ เช่น chunk_size (เช่น 1000), num_sources (เช่น 2), unique (เช่น True) และ min_rel_score (เช่น 0.00)
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
ต่อไปนี้เป็นประโยชน์หลักบางประการที่มีอิทธิพลต่อการตัดสินใจเลือก ActionWeaver:
โดยพื้นฐานแล้วตัวแทนเป็นเพียงโปรแกรมคอมพิวเตอร์หรือระบบที่ออกแบบมาเพื่อรับรู้สภาพแวดล้อม ตัดสินใจ และบรรลุเป้าหมายเฉพาะ
คิดว่าตัวแทนเป็นเอนทิตีซอฟต์แวร์ที่แสดงความเป็นอิสระในระดับหนึ่งและดำเนินการในสภาพแวดล้อมในนามของผู้ใช้หรือเจ้าของ แต่ในลักษณะที่ค่อนข้างเป็นอิสระ ใช้ความคิดริเริ่มในการดำเนินการด้วยตนเองโดยการพิจารณาทางเลือกต่างๆ เพื่อให้บรรลุเป้าหมาย แนวคิดหลักของตัวแทนคือการใช้แบบจำลองภาษาเพื่อเลือกลำดับการดำเนินการที่จะดำเนินการ ตรงกันข้ามกับเชนที่ลำดับของการกระทำถูกฮาร์ดโค้ดในโค้ด เจ้าหน้าที่ใช้แบบจำลองภาษาเป็นเครื่องมือให้เหตุผลเพื่อกำหนดว่าจะต้องดำเนินการใดและเรียงลำดับอย่างไร
การดำเนินการคือฟังก์ชันที่ตัวแทนสามารถเรียกใช้ได้ มีข้อควรพิจารณาการออกแบบที่สำคัญสองประการเกี่ยวกับการดำเนินการ:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
หากไม่คิดถึงทั้งสองอย่าง คุณจะไม่สามารถสร้างตัวแทนที่ทำงานได้ หากคุณไม่ให้สิทธิ์แก่ตัวแทนในการเข้าถึงชุดการดำเนินการที่ถูกต้อง ตัวแทนจะไม่สามารถบรรลุวัตถุประสงค์ที่คุณให้ไว้ได้ หากคุณอธิบายการกระทำได้ไม่ดี เจ้าหน้าที่ก็จะใช้งานไม่ถูกต้อง
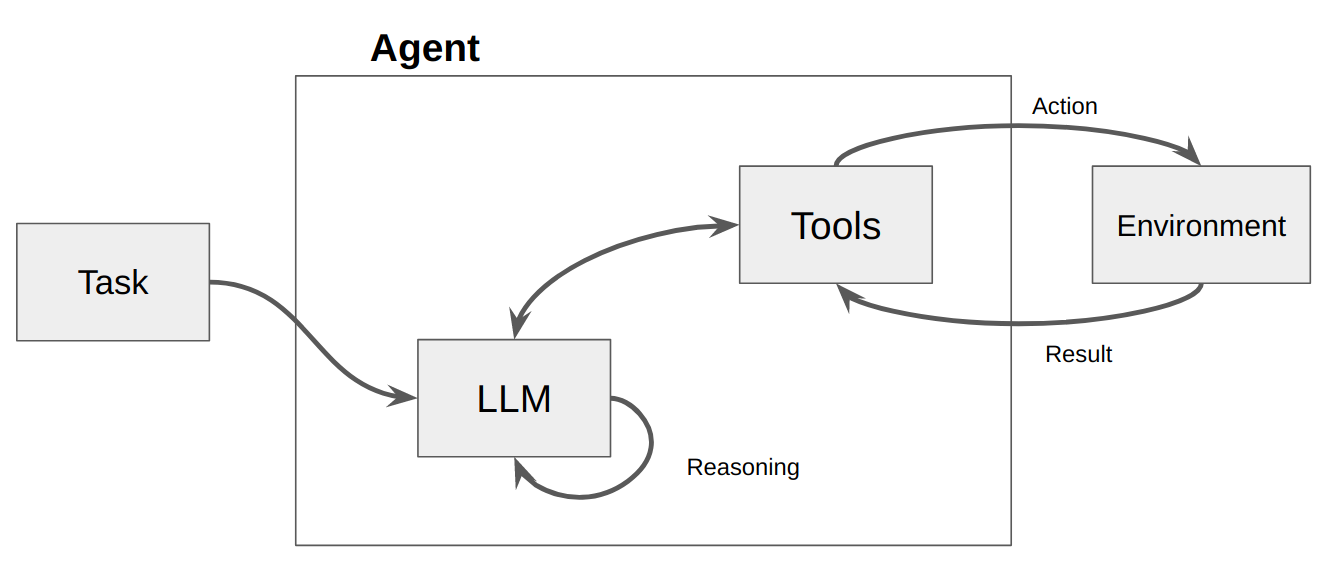
จากนั้นจะเรียก LLM ส่งผลให้มีการตอบสนองต่อผู้ใช้หรือการดำเนินการที่จะดำเนินการ หากมีการพิจารณาแล้วว่าจำเป็นต้องมีการตอบสนอง การตอบสนองนั้นจะถูกส่งต่อไปยังผู้ใช้ และรอบนั้นก็จะสิ้นสุดลง ถ้าถูกกำหนดว่าจำเป็นต้องมีการดำเนินการ การดำเนินการนั้นจะถูกดำเนินการ และจะมีการสังเกต (ผลการดำเนินการ) การกระทำและการสังเกตที่เกี่ยวข้องนั้นจะถูกเพิ่มกลับเข้าไปในพรอมต์ (เราเรียกว่า "เอเจนต์สแครชแพด") และการวนซ้ำจะรีเซ็ต เช่น LLM ถูกเรียกอีกครั้ง (พร้อมกับ scratchpad ของเอเจนต์ที่อัปเดต)
ใน ActionWeaver เราสามารถมีอิทธิพลต่อการวนซ้ำโดยเพิ่ม stop=True|False ให้กับการกระทำ หาก stop=True LLM จะส่งคืนเอาต์พุตของฟังก์ชันทันที นอกจากนี้ยังจะจำกัด LLM ไม่ให้ทำการเรียกใช้ฟังก์ชันหลายรายการด้วย ในการสาธิตนี้ เราจะใช้เพียง stop=True เท่านั้น
ActionWeaver ยังรองรับการควบคุมลูปที่ซับซ้อนมากขึ้นโดยใช้ orch_expr(SelectOne[actions]) และ orch_expr(RequireNext[actions]) แต่ฉันจะปล่อยไว้สำหรับส่วนที่ II
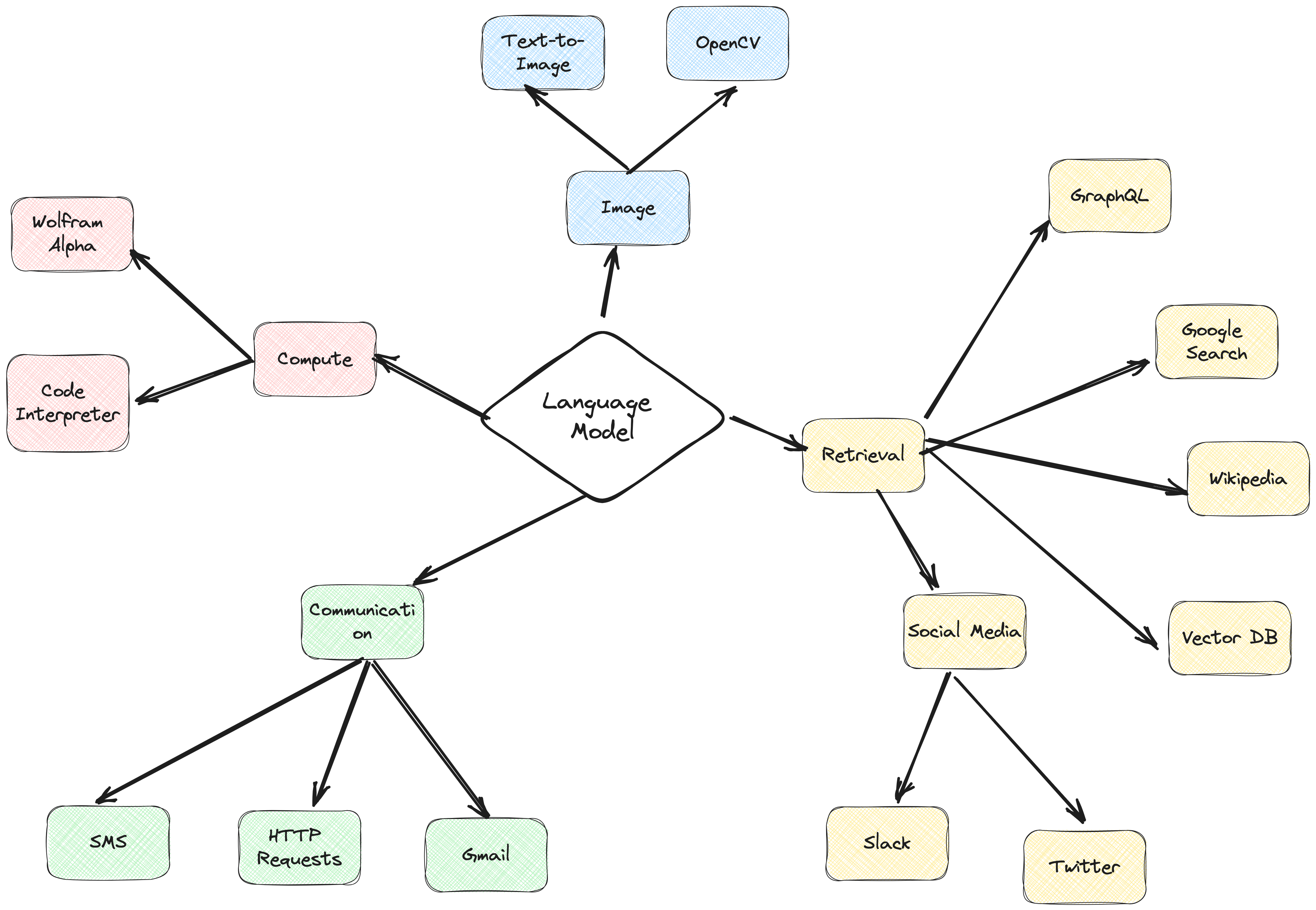
เฟรมเวิร์กตัวแทน ActionWeaver คือเฟรมเวิร์กแอปพลิเคชัน AI ที่ให้การเรียกใช้ฟังก์ชันเป็นแกนหลัก ได้รับการออกแบบมาเพื่อให้สามารถผสานระบบคอมพิวเตอร์แบบดั้งเดิมเข้ากับความสามารถในการให้เหตุผลอันทรงพลังของโมเดลภาษาได้อย่างลงตัว ActionWeaver สร้างขึ้นตามแนวคิดของการเรียกใช้ฟังก์ชัน LLM ในขณะที่เฟรมเวิร์กยอดนิยม เช่น Langchain และ Haystack ถูกสร้างขึ้นตามแนวคิดของไปป์ไลน์

อ่านเพิ่มเติมได้ที่: https://thinhdanggroup.github.io/function-calling-openai/
นักพัฒนาสามารถแนบฟังก์ชัน Python ใดๆ เป็นเครื่องมือที่มีมัณฑนากรที่เรียบง่ายได้ ในตัวอย่างต่อไปนี้ เราแนะนำการดำเนินการ get_sources_list ซึ่งจะถูกเรียกใช้โดย OpenAI API
ActionWeaver ใช้ลายเซ็นและสตริงเอกสารของเมธอดที่ได้รับการตกแต่งเป็นคำอธิบาย โดยส่งต่อไปยัง Function API ของ OpenAI
ActionWeaver จัดเตรียม light wrapper ที่ดูแลการแปลงข้อมูล docstring/มัณฑนากร ให้เป็นรูปแบบที่ถูกต้องสำหรับ OpenAI API
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True เมื่อเพิ่มในการดำเนินการหมายความว่า LLM จะส่งคืนเอาต์พุตของฟังก์ชันทันที แต่ยังจำกัด LLM ไม่ให้ทำการเรียกใช้ฟังก์ชันหลายรายการด้วย ตัวอย่างเช่น หากถามเกี่ยวกับสภาพอากาศในนิวยอร์คและซานฟรานซิสโก แบบจำลองจะเรียกใช้ฟังก์ชันสองหน้าที่แยกกันตามลำดับสำหรับแต่ละเมือง อย่างไรก็ตาม ด้วย stop=True กระบวนการนี้จะถูกขัดจังหวะเมื่อฟังก์ชันแรกส่งคืนข้อมูลสภาพอากาศสำหรับ NYC หรือ San Francisco ขึ้นอยู่กับเมืองที่ค้นหาก่อน
หากต้องการทำความเข้าใจเชิงลึกเพิ่มเติมเกี่ยวกับวิธีการทำงานของบอทนี้ โปรดดูที่ไฟล์ bot.py นอกจากนี้ คุณยังสามารถสำรวจพื้นที่เก็บข้อมูล ActionWeaver เพื่อดูรายละเอียดเพิ่มเติมได้
การสร้างการติดตามการให้เหตุผลช่วยให้แบบจำลองสามารถกระตุ้น ติดตาม และปรับปรุงแผนปฏิบัติการ และแม้กระทั่งจัดการข้อยกเว้น ตัวอย่างนี้ใช้ ReAct ร่วมกับห่วงโซ่แห่งความคิด (CoT)
ห่วงโซ่แห่งความคิด
การใช้เหตุผล+การกระทำ
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
ทั้ง Chain of Thought (CoT) และเทคนิคการกระตุ้น ReAct เข้ามามีบทบาทในตัวอย่างนี้ มีวิธีดังนี้:
ห่วงโซ่แห่งความคิด (CoT) การกระตุ้นเตือน:
โต้ตอบพร้อมท์:
โดยสรุป ทั้ง CoT และ ReAct มีบทบาทสำคัญในตัวอย่างเหล่านี้ CoT ช่วยให้โมเดลให้เหตุผลทีละขั้นตอนและเลือกการดำเนินการที่เหมาะสม ในขณะที่ ReAct ขยายฟังก์ชันการทำงานนี้โดยอนุญาตให้โมเดลโต้ตอบกับสภาพแวดล้อมและอัปเดตแผนตามนั้น การผสมผสานระหว่างการใช้เหตุผลและการกระทำทำให้โมเดลภาษาขนาดใหญ่มีความยืดหยุ่นและหลากหลายมากขึ้น ทำให้สามารถจัดการกับงานและสถานการณ์ได้หลากหลายมากขึ้น
เริ่มต้นด้วยการถามคำถามกับตัวแทนของเรา ในกรณีนี้ "มะม่วงคืออะไร" - สิ่งแรกที่จะเกิดขึ้นคือมันจะพยายาม "เรียกคืน" ข้อมูลที่เกี่ยวข้องโดยใช้ความคล้ายคลึงกันของการฝังเวกเตอร์ จากนั้นจะกำหนดคำตอบด้วยเนื้อหาที่ "เรียกคืน" หรือจะดำเนินการค้นหาเว็บ เนื่องจากฐานความรู้ของเราว่างเปล่า เราจึงต้องเพิ่มแหล่งข้อมูลก่อนที่จะสามารถกำหนดคำตอบได้
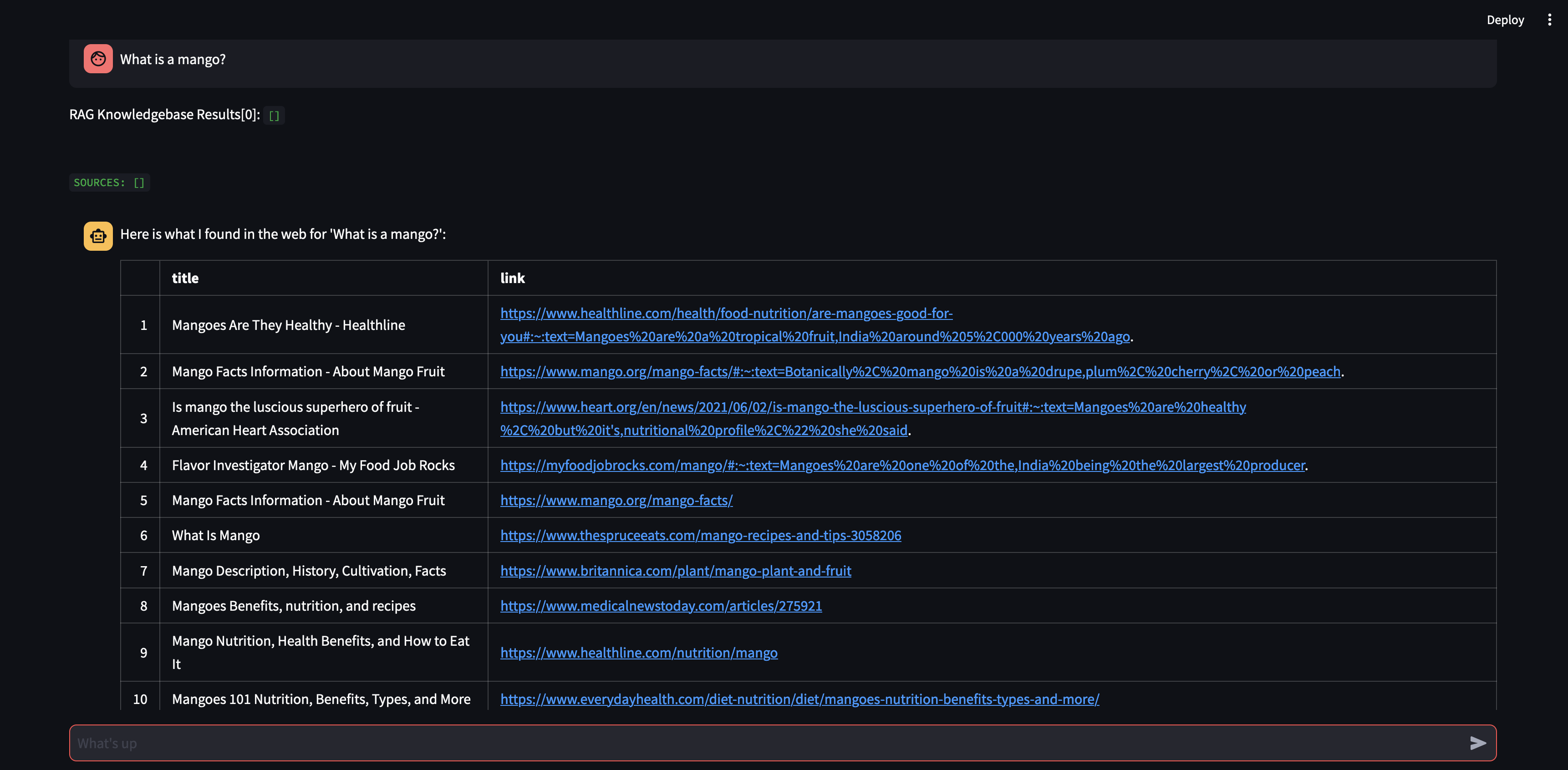
เนื่องจากบอทไม่สามารถให้คำตอบโดยใช้เนื้อหาในฐานข้อมูลเวกเตอร์ได้ จึงเริ่มการค้นหาโดย Google เพื่อค้นหาข้อมูลที่เกี่ยวข้อง ตอนนี้เราสามารถบอกได้ว่าควร "เรียนรู้" จากแหล่งใด ในกรณีนี้ เราจะบอกให้เรียนรู้แหล่งที่มาสองรายการแรกจากผลการค้นหา
ต่อไปเรามาปรับเปลี่ยนกลยุทธ์ RAG กันดีกว่า! เรามาทำให้มันใช้เพียงแหล่งเดียว และให้มันมีขนาดอันเล็กเพียง 500 อักขระ
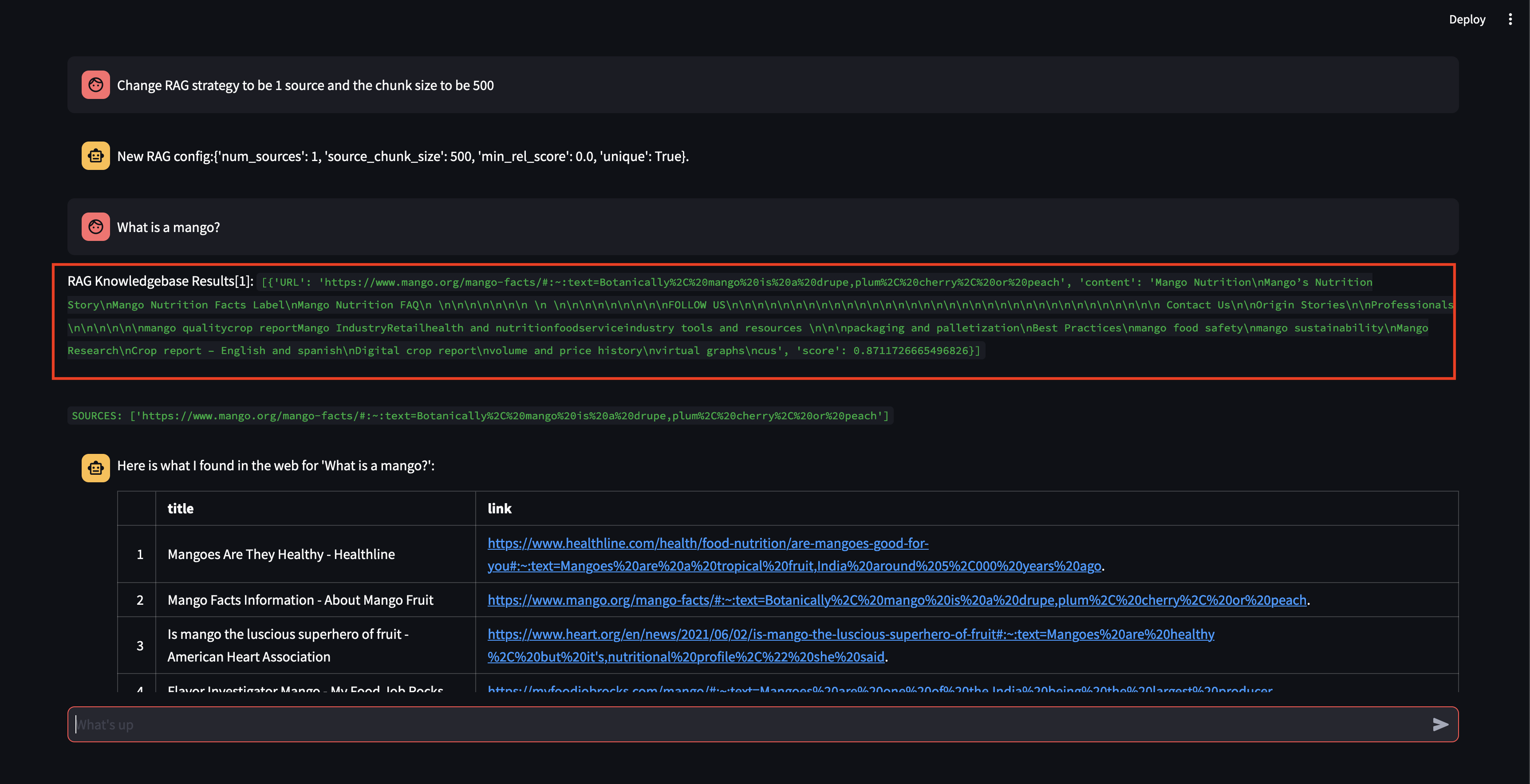
โปรดสังเกตว่าแม้ว่าจะสามารถดึงข้อมูลก้อนข้อมูลได้โดยมีคะแนนความเกี่ยวข้องค่อนข้างสูง แต่ก็ไม่สามารถสร้างการตอบกลับได้เนื่องจากขนาดก้อนเล็กเกินไปและเนื้อหาก้อนนั้นไม่เกี่ยวข้องเพียงพอที่จะกำหนดคำตอบได้ เนื่องจากไม่สามารถโต้ตอบกับส่วนเล็กๆ ได้ จึงทำการค้นหาเว็บในนามของผู้ใช้
มาดูกันว่าเกิดอะไรขึ้นถ้าเราเพิ่มขนาดก้อนเป็น 3,000 อักขระแทนที่จะเป็น 500
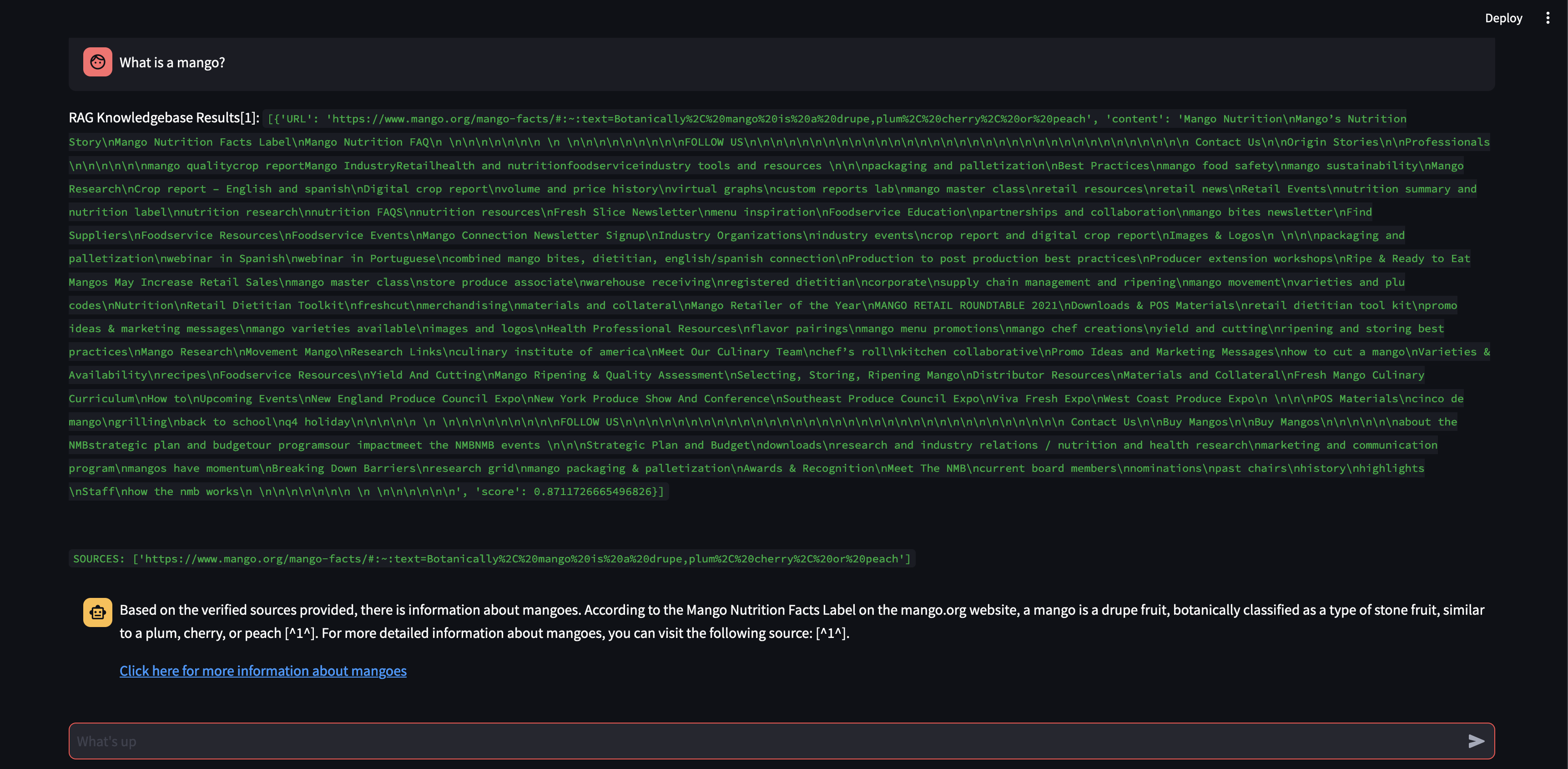
ขณะนี้ ด้วยขนาดก้อนที่ใหญ่ขึ้น จึงสามารถกำหนดการตอบสนองได้อย่างแม่นยำโดยใช้ความรู้จากฐานข้อมูลเวกเตอร์!
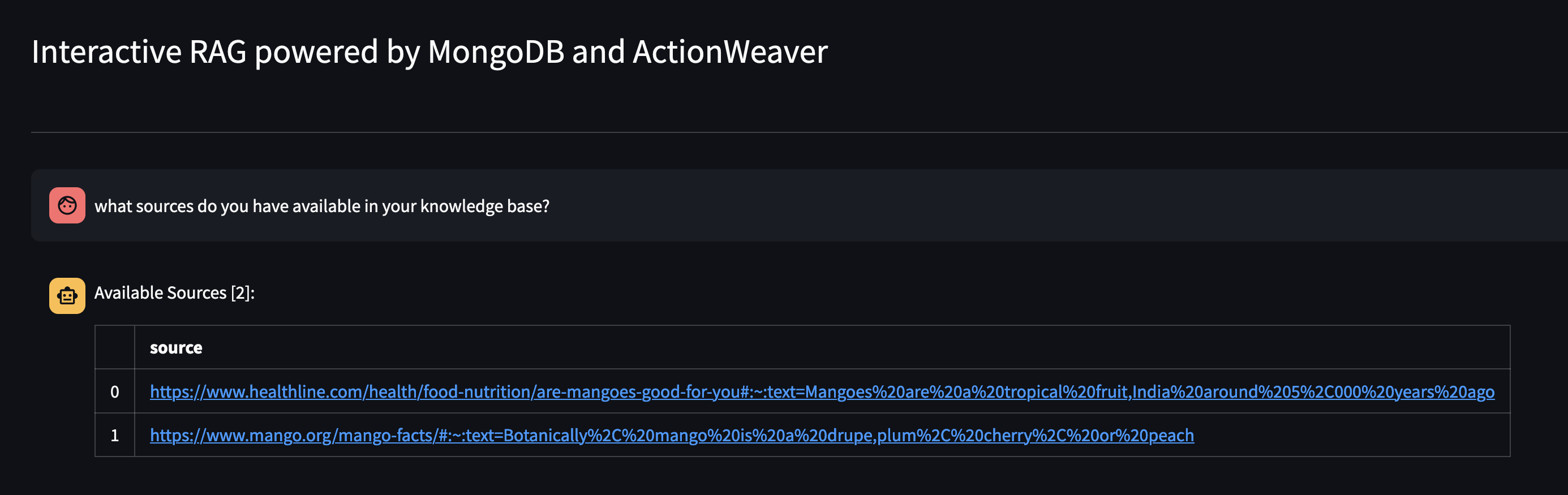
มาดูกันว่ามีอะไรอยู่ในฐานความรู้ของ Agent โดยถามมัน: คุณมีแหล่งใดบ้างในฐานความรู้ของคุณ?
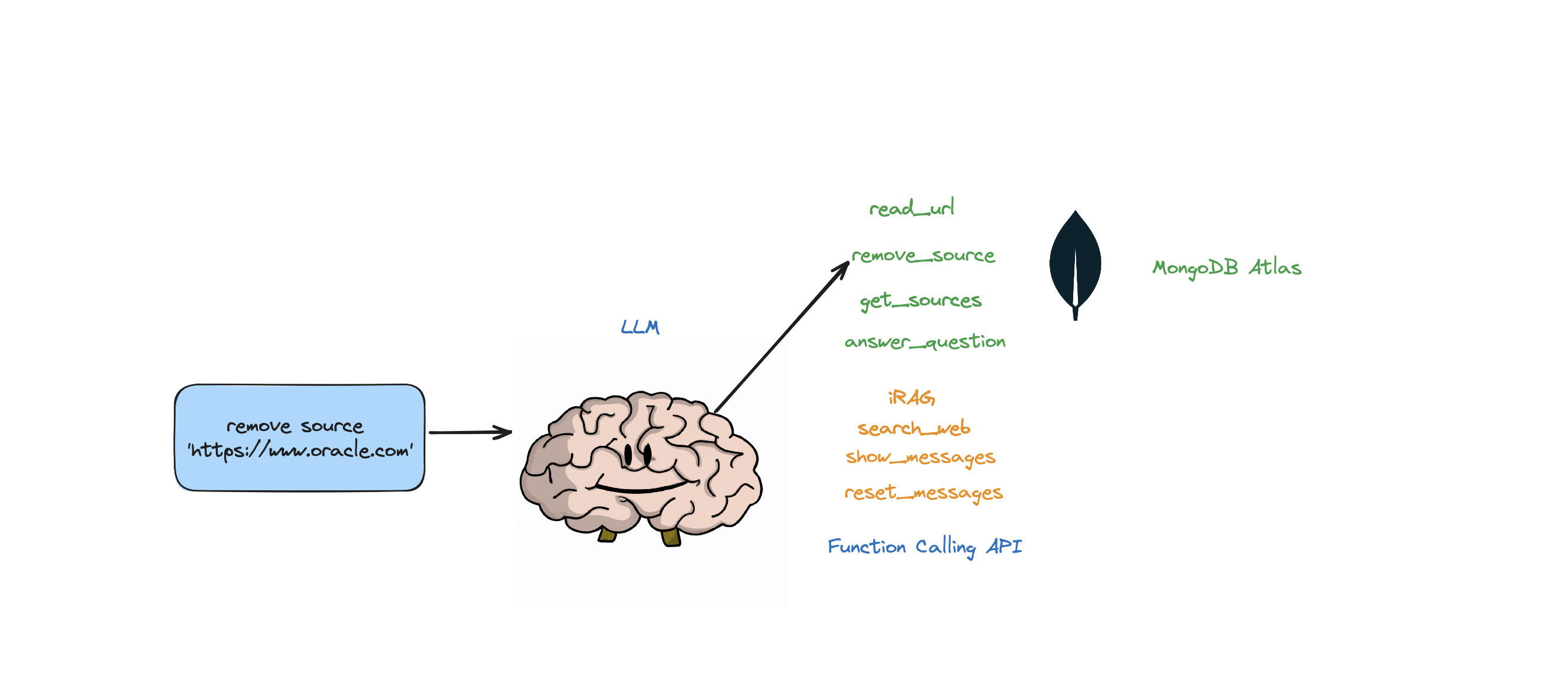
หากคุณต้องการลบทรัพยากรที่เฉพาะเจาะจงออก คุณสามารถดำเนินการดังนี้:
USER: remove source 'https://www.oracle.com' from the knowledge base
หากต้องการลบแหล่งที่มาทั้งหมดในคอลเลกชัน - เราสามารถดำเนินการดังนี้:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
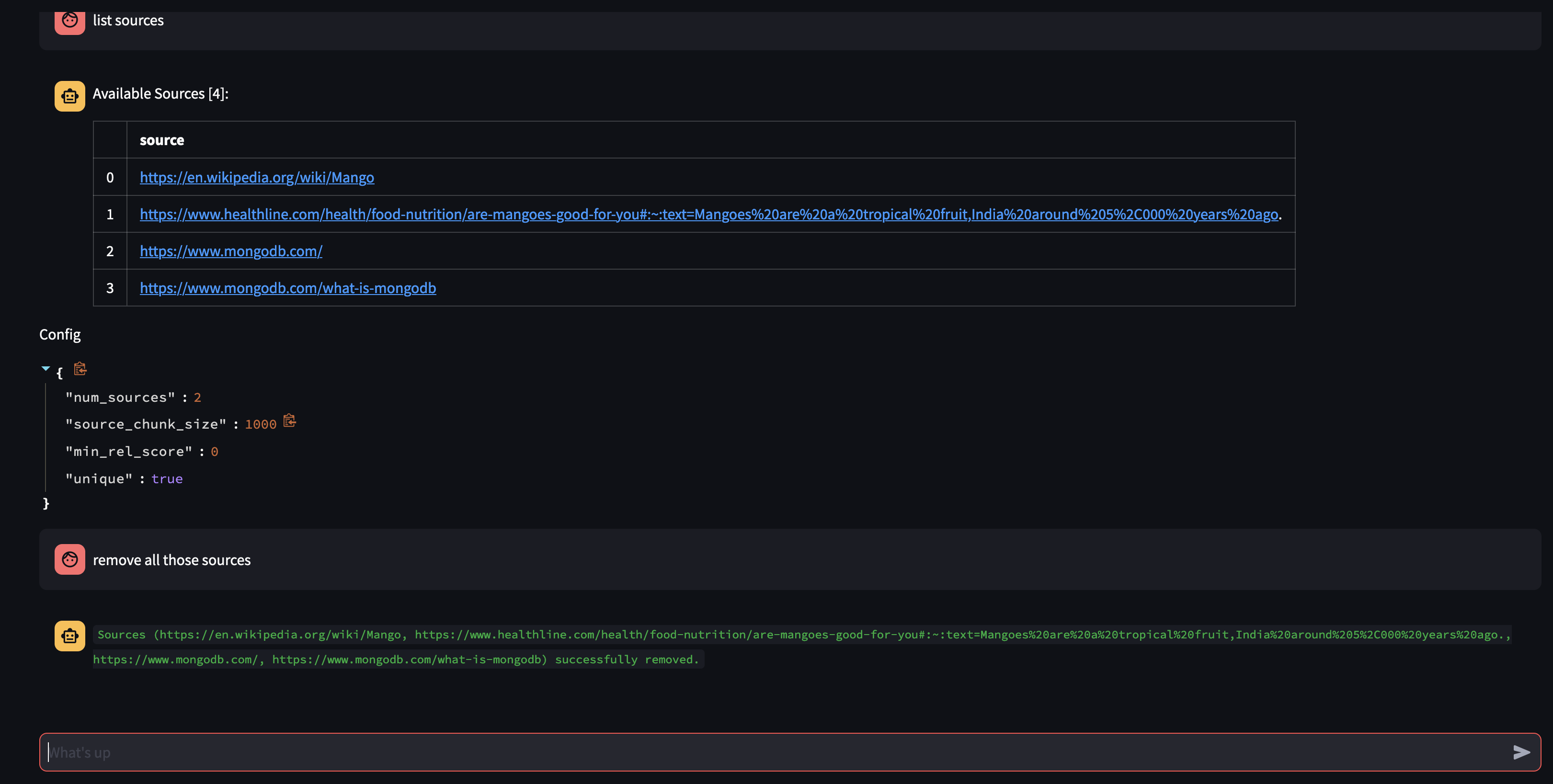
การสาธิตนี้ได้เผยให้เห็นการทำงานภายในของตัวแทน AI ของเรา ซึ่งแสดงให้เห็นความสามารถในการเรียนรู้และตอบคำถามของผู้ใช้ในลักษณะเชิงโต้ตอบ เราได้เห็นแล้วว่าบริษัทผสมผสานฐานความรู้ภายในเข้ากับการค้นหาเว็บแบบเรียลไทม์ได้อย่างราบรื่นเพื่อส่งมอบข้อมูลที่ครอบคลุมและถูกต้องได้อย่างไร ศักยภาพของเทคโนโลยีนี้มีมากมายเกินกว่าการตอบคำถามธรรมดาๆ สิ่งเหล่านี้จะเป็นไปไม่ได้เลยหากไม่มีความมหัศจรรย์ของ Function Calling API
สิ่งนี้ได้รับแรงบันดาลใจจากhttps://github.com/TengHu/Interactive-RAG
เรายินดีรับการสนับสนุนจากชุมชนโอเพ่นซอร์ส
ใบอนุญาต Apache 2.0


