genai with confluent
1.0.0
นี่คือการสาธิต AI ที่สร้างแบบเรียลไทม์ด้วย Confluent Cloud แนวคิดนี้ได้รับอิทธิพลจากการฝึกอบรมที่ยอดเยี่ยมใน Udemy ซึ่งนำโดย Eden Marco (LangChain- พัฒนาแอปพลิเคชันที่ขับเคลื่อนด้วย LLM ด้วย LangChain) Eden Marco ให้ลิงก์ที่โปรโมตแก่ฉัน Eden Marco ทำทุกคำแนะนำที่ดีเกี่ยวกับการพัฒนา Lngchain LLM ใน Python ฉันนำแนวคิด Ice Breaker นี้มาปรับใช้กับกรณีการใช้งานจริงที่ใช้ Data in Motion with Confluent และ AI
repo จะปรับใช้:
กรุณาโคลนที่เก็บนี้บนเดสก์ท็อปของคุณ:
cd $HOME # or what-ever directory you want to use
git clone https://github.com/ora0600/genai-with-confluent.git
cd genai-with-confluent/terraform/การดำเนินการสาธิตนั้นเป็นแบบอัตโนมัติทั้งหมด แต่ก่อนดำเนินการ คุณต้องตั้งค่าสองสามอย่างที่นี่:
สร้างบัญชี Salesforce Developer ลงทะเบียนที่นี่ กำหนดค่า Salesforce CDC ดูติดตามการตั้งค่าของฉันพร้อมภาพหน้าจอที่นี่ ขั้นตอนระดับสูง:
คุณต้องมีพารามิเตอร์ทั้งหมดสำหรับ Salesforce CDC Connector ดังนั้นโปรดเก็บไว้อย่างปลอดภัย
คุณต้องมีบัญชีที่ใช้งานได้สำหรับ Confluent Cloud การลงทะเบียนกับ Confluent Cloud นั้นง่ายมาก และคุณจะได้รับงบประมาณ $400 สำหรับการทดลองใช้ครั้งแรกฟรี หากคุณไม่มีบัญชี Confluent Cloud ที่ใช้งานได้ โปรดสมัครใช้งาน Confluent Cloud
pip3 install confluent_kafka
pip3 install requests
pip3 install fastavro
pip3 install avro
pip3 install jproperties
pip3 install langchain
pip3 install openai
pip3 install langchain_openai
pip3 install -U langchain-community
pip3 install google-search-results
pip3 install Flask
pip3 install langchain_core
pip3 install pydanticสำหรับ Confluent Cloud: สร้างคีย์ API ใน Confluent Cloud ผ่าน CLI:
confluent login
confluent api-key create --resource cloud --description " API for terraform "
# It may take a couple of minutes for the API key to be ready.
# Save the API key and secret. The secret is not retrievable later.
# +------------+------------------------------------------------------------------+
# | API Key | <your generated key> |
# | API Secret | <your generated secret> |
# +------------+------------------------------------------------------------------+ คัดลอกพารามิเตอร์ทั้งหมดสำหรับ Confluent Cloud ลงในไฟล์ terraform.tfvars โดยดำเนินการคำสั่งต่อไปนี้พร้อมกับข้อมูลของคุณ:
cat > $PWD /terraform/terraform.tfvars << EOF
confluent_cloud_api_key = "{Cloud API Key}"
confluent_cloud_api_secret = "{Cloud API Key Secret}"
sf_user= "salesforce user"
sf_password = "password"
sf_cdc_name = "LeadChangeEvent"
sf_password_token = "password token"
sf_consumer_key = "consumer key of connected app"
sf_consumer_secret = "consumer secret of connect app"
EOFTerraform จะใช้พารามิเตอร์เหล่านี้ทั้งหมดและทำการกำหนดค่าให้กับคุณ และสุดท้ายจะปรับใช้ทรัพยากรระบบคลาวด์ที่ไหลมารวมกันทั้งหมด รวมถึงบัญชีบริการและการเชื่อมโยงบทบาท
เราใช้ langchain LLM เวอร์ชัน 0.1 Langchain Docu
คำใบ้:
| ตอนนี้มันจะต้องใช้เงิน น่าเสียดายที่ API ไม่ใช่บริการฟรี ฉันใช้จ่าย 10$ สำหรับ open AI, 10$ สำหรับ ProxyCurl API และ SERP API ยังคงอยู่ในสถานะฟรี |
ก่อนอื่นเราต้องมีคีย์ที่ช่วยให้เราใช้ OpenAI ได้ ทำตามขั้นตอนจากที่นี่เพื่อสร้างบัญชี จากนั้นจึงสร้างคีย์ API เท่านั้น
งานถัดไป: สร้างคีย์ proxycurl api ProxyCurl จะถูกใช้เพื่อคัดลอก Linkedin ลงทะเบียนเพื่อ proxyurl และซื้อเครดิตในราคา 10$ (หรืออะไรก็ตามที่คุณคิดว่าเพียงพอ บางทีคุณอาจเริ่มมากขึ้นน้อยลง) ทำตามขั้นตอนเหล่านี้
เพื่อให้สามารถค้นหา URL โปรไฟล์ LinkedIn ที่ถูกต้องใน Google เราจำเป็นต้องมีคีย์ API ของ SERP API จากที่นี่
ตอนนี้ใส่คีย์ทั้งหมดลงในไฟล์ env-vars โดยดำเนินการคำสั่ง:
cat > $PWD /terraform/env.vars << EOF
export PYTHONPATH=/YOURPATH
export OPENAI_API_KEY=YOUR openAI Key
export PROXYCURL_API_KEY=YOUR ProxyURL Key
export SERPAPI_API_KEY=Your SRP API KEy
EOFยินดีด้วย การเตรียมการเสร็จสิ้นแล้ว ฉันรู้นี่เป็นการตั้งค่าครั้งใหญ่
ตอนนี้มาถึงส่วนที่ง่าย เพียงดำเนินการ Terraform ดำเนินการ Terraform และทรัพยากรคลาวด์ที่ไหลมารวมกันทั้งหมดจะถูกปรับใช้โดยอัตโนมัติ:
cd terraform
terraform init
terraform plan
terraform applyการดำเนินการนี้จะใช้เวลาสักครู่ ทรัพยากร Confluent Cloud จะถูกจัดเตรียม หากเสร็จสิ้น เทอร์มินัล iterm2 จะถูกเปิดโดยอัตโนมัติและดำเนินการบริการสามรายการ
ตกลง ตอนนี้คุณต้องเพิ่มลูกค้าเป้าหมายใหม่ลงใน Salesforce นี่เป็นขั้นตอนสุดท้ายที่ต้องดำเนินการด้วยตนเอง
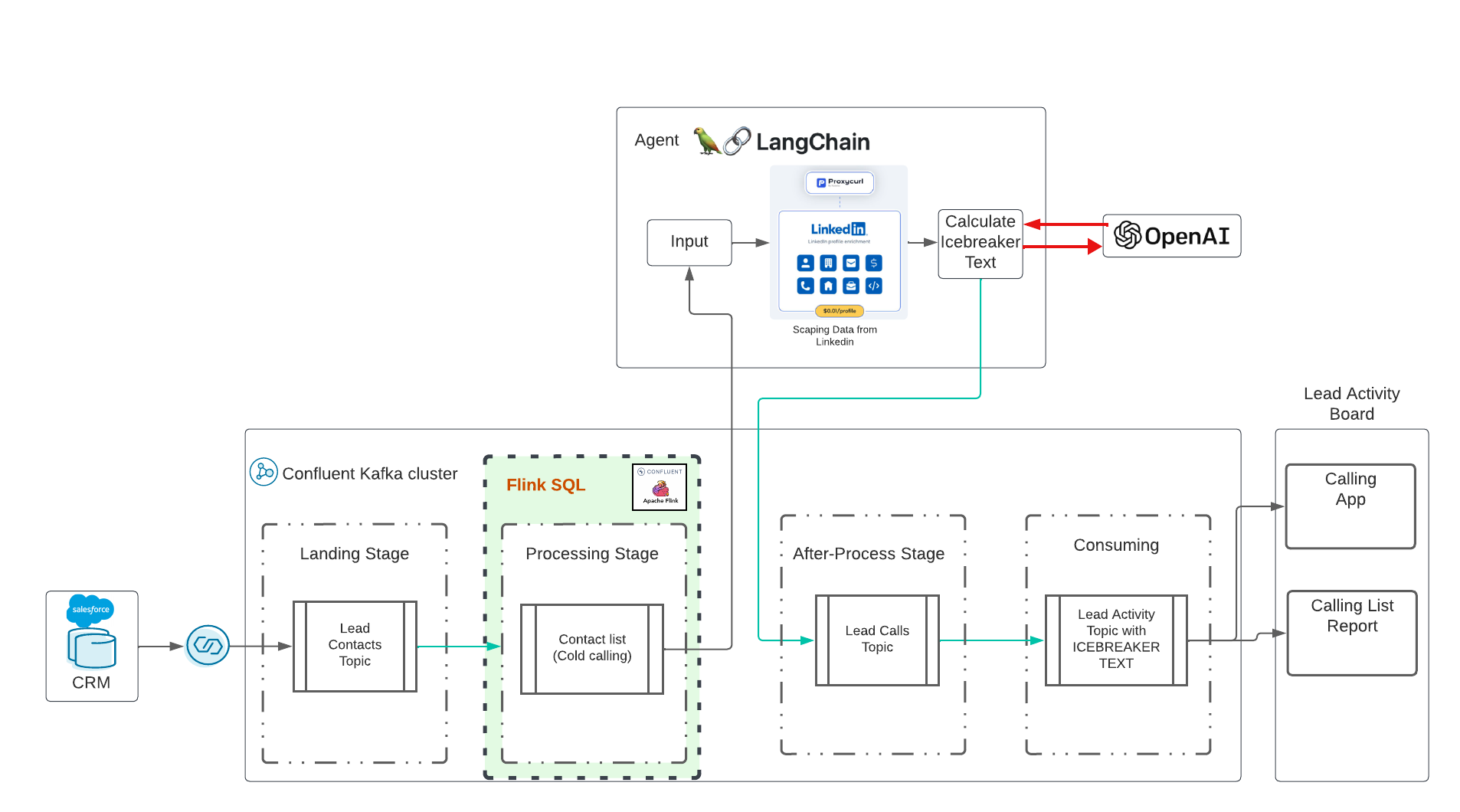
AI เจนเนอเรทีฟจะรับคำสั่งใหม่จากคลัสเตอร์ Kafka และดำเนินการ LLM โดยรับข้อมูลจาก Linkedin และดำเนินการพร้อมท์โดยอัตโนมัติและแบบเรียลไทม์ 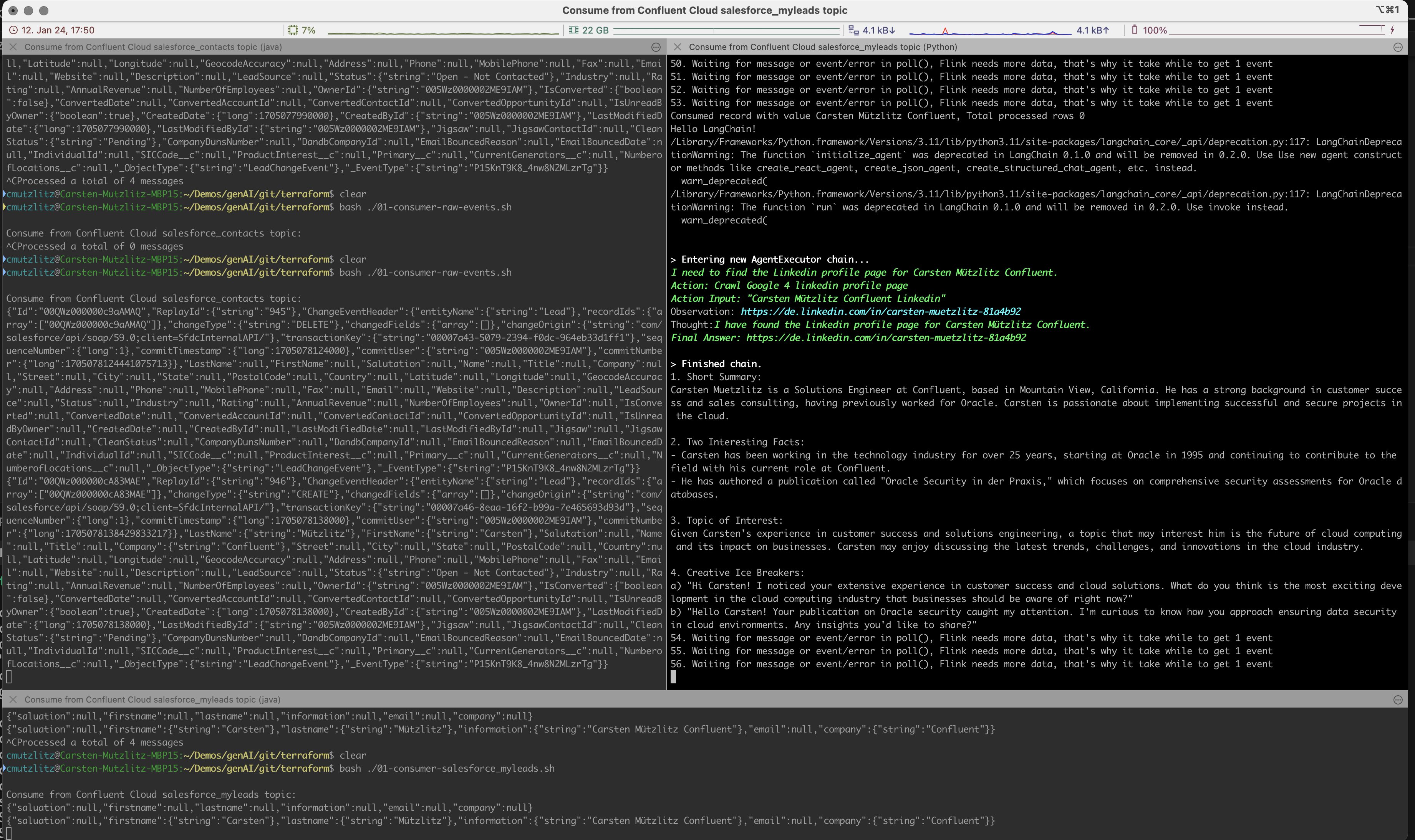
พรอมต์จะถูกมองว่าเป็นงานสำหรับ Chatgpt เรากำหนดไว้ว่า C>hatgpt ควรกำหนดเนื้อหาต่อไปนี้:
เรากำลังใช้งานรุ่น chatgpt-3.5-turbo ในการสาธิตนี้ โมเดลนี้มีโทเค็นจำกัด แต่ปัจจุบันเป็นรุ่นที่เร็วและเก่าแก่ที่สุด และแน่นอนว่าถูกที่สุด หากคุณลองใช้ Kai Waehner เป็น Lead คุณจะเห็นว่าโทเค็นของโมเดลปัจจุบันยังไม่เพียงพอ สิ่งที่คุณทำได้คือเปลี่ยนโมเดล นี่จะเป็นวิธีที่ง่ายที่สุด อีกวิธีหนึ่งคือการแบ่งเนื้อหาออกเป็นชิ้นๆ โปรดดูรุ่นปัจจุบันเพื่อตรวจสอบจำนวนโทเค็นต่อรุ่น
ฉันเริ่มต้นด้วยการทดสอบ:
model_name="gpt-4-turbo" ใน ice_breaker.py บรรทัด 135 และรีสตาร์ทไคลเอ็นต์การสาธิตอย่างง่ายไม่ใช่กรณีการใช้งานสำหรับรูปแบบการดึงข้อมูล Augmented Generation (RAG) ในความคิดของฉัน เราได้รับข้อมูลทั้งหมดจาก API ที่กำหนด ดังนั้นจึงไม่มีเหตุผลที่จะจัดเก็บข้อมูลไว้ในฐานข้อมูลเวกเตอร์ การโหลดข้อมูลผ่าน API แบบเรียลไทม์จะมีประสิทธิภาพมากกว่ามาก จึงเป็นข้อมูลใหม่ ใช้โมเดลที่ถูกต้องสำหรับกรณีการใช้งานของคุณ ในกรณีของเรา ควรเป็นโมเดลที่รวดเร็วและมีปริมาณโทเค็นสูงกว่า
Salesforce รีเซ็ตรหัสผ่านของคุณ และคุณจำเป็นต้องเปลี่ยนรหัสผ่านเป็นครั้งคราว หากคุณเปลี่ยนรหัสผ่าน คุณจะได้รับโทเค็นความปลอดภัยของรหัสผ่านใหม่ด้วย โปรดอย่าลืมเปลี่ยนสิ่งนี้ในไฟล์ terraform.tfvars
เมื่อดำเนินการเสร็จแล้ว คุณสามารถหยุดโปรแกรมใน Terminal ด้วย CTRL+c และทำลายทุกอย่างใน Confluent Cloud:
terraform destroyหากคุณมีข้อผิดพลาด ให้ดำเนินการทำลายอีกครั้ง จนกว่าทุกอย่างจะถูกลบ คุณค่อนข้างแน่ใจว่าไม่มีทรัพยากรใดทำงานอยู่และใช้ต้นทุน
terraform destroyคุณต้องมีบัญชี Confluent Cloud (บัญชีใหม่จะได้รับเครดิต 400$ ฟรี) คุณต้องมีบัญชี OPENAI พร้อมเครดิตปัจจุบัน คุณต้องมีบัญชี ProxyCurl API พร้อมด้วยเครดิตปัจจุบัน คุณต้องการบัญชี SERP API ที่นี่ คุณจะมีจำนวนการเชื่อมต่อเริ่มต้น แค่นี้ก็เพียงพอแล้วในกรณีของฉัน
โดยรวมแล้ว ฉันใช้จ่ายไป 20 ดอลลาร์ (Open AI, ProxyCurl) และฉันยังไม่หมดเครดิต


