cassandra lucene index
2.1.20.0
Cassandra Lucene Index ของ Stratio ซึ่งได้มาจาก Stratio Cassandra เป็นปลั๊กอินสำหรับ Apache Cassandra ที่ขยายฟังก์ชันการทำงานของดัชนีเพื่อให้การค้นหาแบบเรียลไทม์ที่ใกล้เคียง เช่น ElasticSearch หรือ Solr รวมถึงความสามารถในการค้นหาข้อความแบบเต็มและการค้นหาหลายตัวแปร เชิงพื้นที่ และ bitmporal ฟรี สามารถทำได้โดยการใช้ดัชนีรองของ Cassandra ที่ใช้ Apache Lucene โดยที่แต่ละโหนดของคลัสเตอร์จะจัดทำดัชนีข้อมูลของตนเอง ดัชนี Cassandra ของ Stratio เป็นหนึ่งในโมดูลหลักที่ใช้แพลตฟอร์ม BigData ของ Stratio
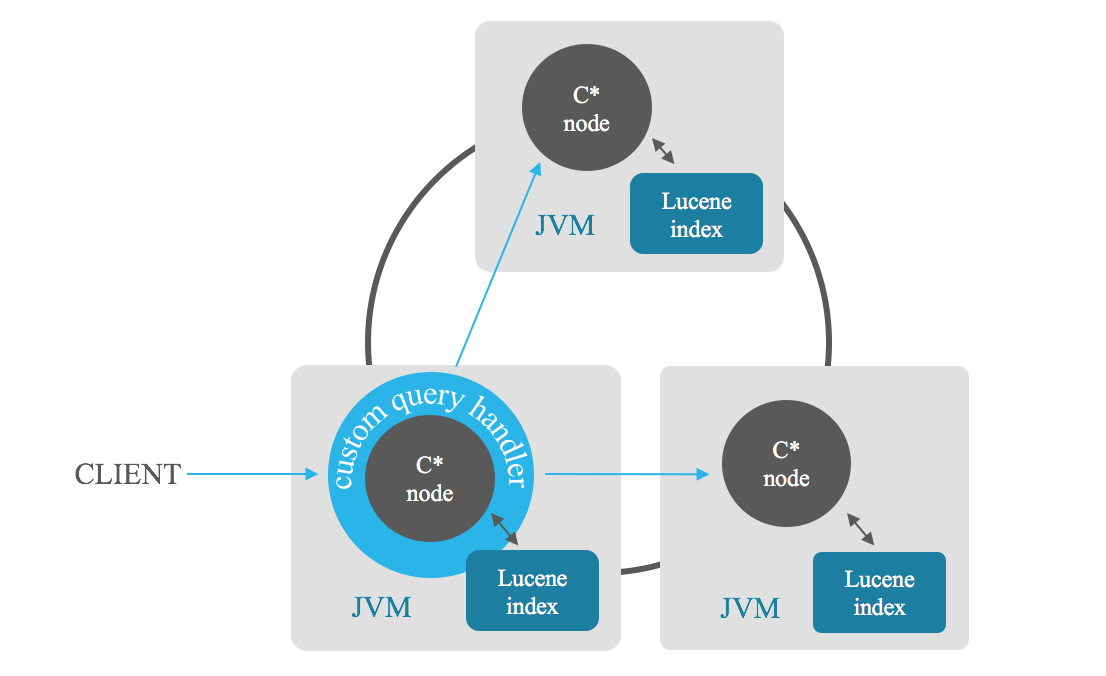
การค้นหาความเกี่ยวข้องของดัชนีช่วยให้คุณสามารถเรียกค้นผลลัพธ์ที่เกี่ยวข้อง มากกว่า และน่าพอใจในการค้นหา โหนดผู้ประสานงานจะส่งการค้นหาไปยังแต่ละโหนดในคลัสเตอร์ แต่ละโหนดส่งคืนผลลัพธ์ที่ดีที่สุด n รายการ จากนั้นผู้ประสานงานจะรวมผลลัพธ์บางส่วนเหล่านี้และให้สิ่งที่ดี ที่สุด แก่คุณ โดยหลีกเลี่ยงการสแกนแบบเต็ม คุณยังสามารถยึดการเรียงลำดับโดยใช้ฟิลด์ต่างๆ รวมกันได้
เซลล์ใดๆ ในตารางสามารถจัดทำดัชนีได้ รวมถึงเซลล์ในคีย์หลักและคอลเลกชันด้วย รองรับแถวกว้างด้วย คุณสามารถสแกนช่วงโทเค็น/คีย์ ใช้ส่วนคำสั่ง CQL3 เพิ่มเติมและหน้าในผลลัพธ์ที่กรองได้
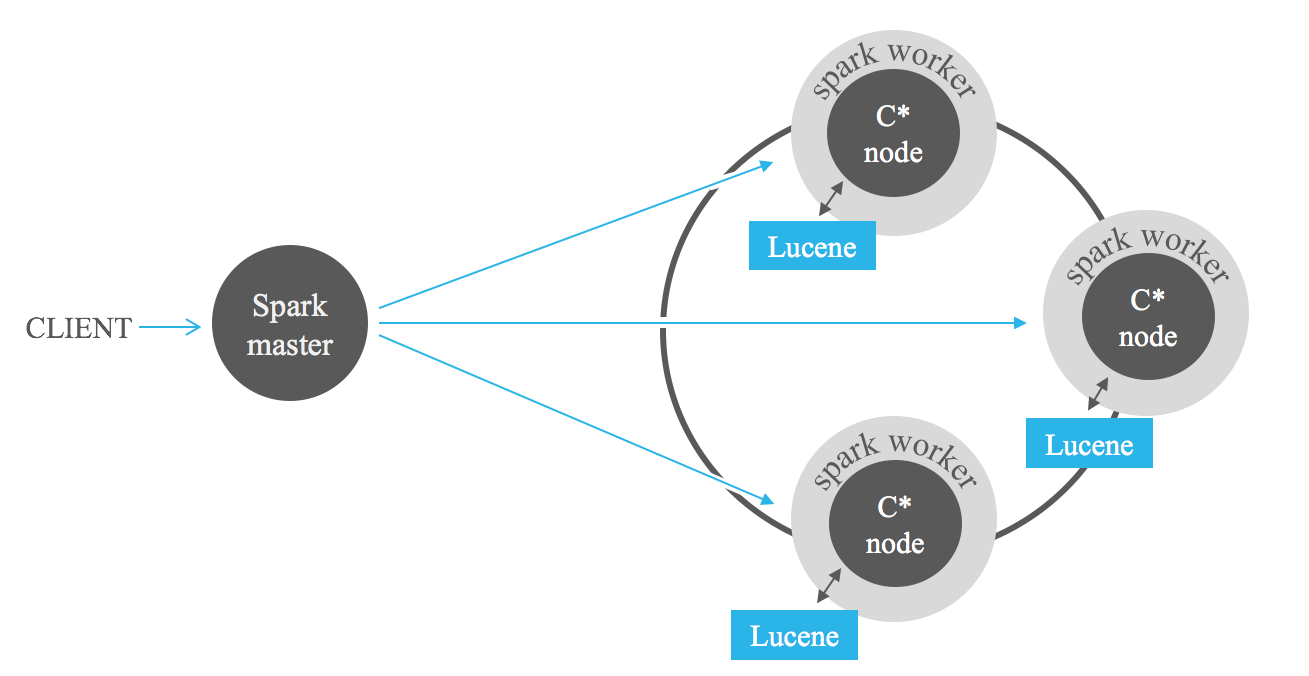
การค้นหาที่กรองด้วยดัชนีเป็นตัวช่วยที่มีประสิทธิภาพในการวิเคราะห์ข้อมูลที่จัดเก็บไว้ใน Cassandra ด้วยเฟรมเวิร์ก MapReduce เช่น Apache Hadoop หรือที่ดียิ่งขึ้นคือ Apache Spark การเพิ่มตัวกรอง Lucene ในอินพุตงานสามารถลดปริมาณข้อมูลที่ต้องประมวลผลได้อย่างมาก และหลีกเลี่ยงการสแกนแบบเต็ม
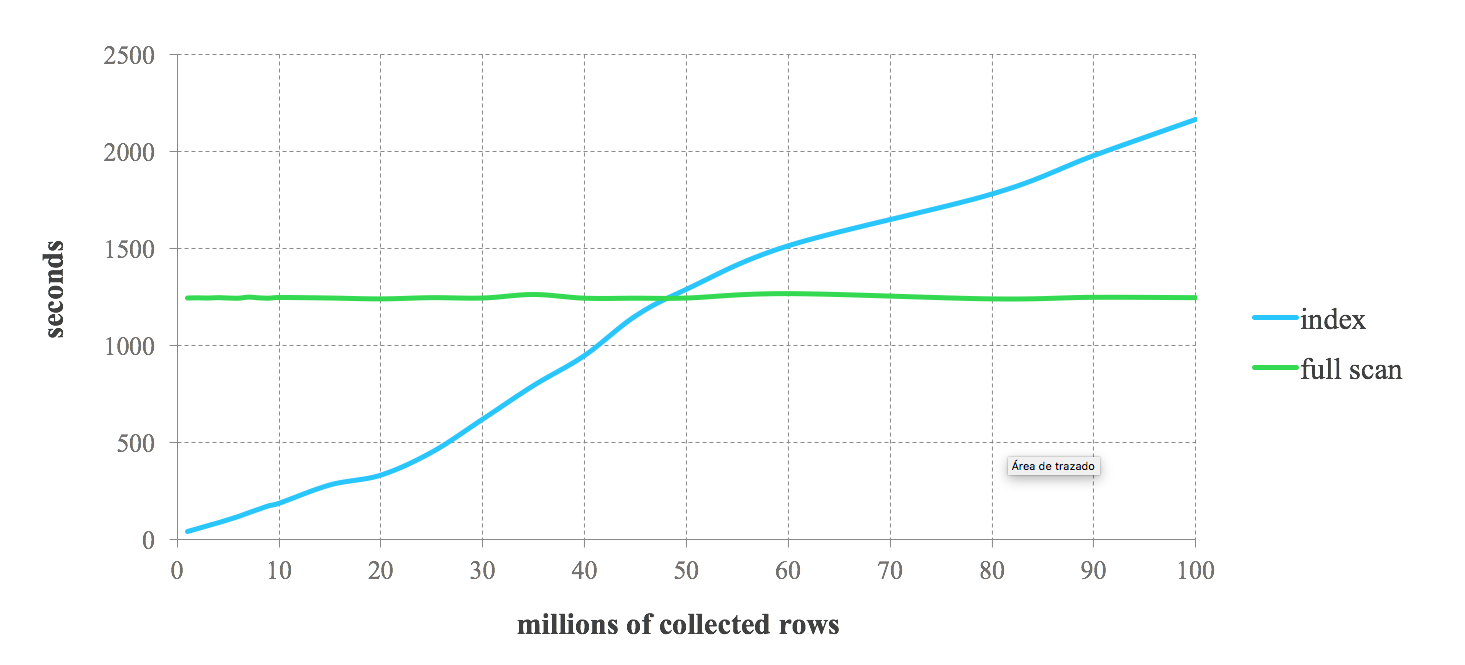
ผลลัพธ์การวัดประสิทธิภาพต่อไปนี้สามารถให้แนวคิดเกี่ยวกับประสิทธิภาพที่คาดหวังได้เมื่อรวมดัชนี Lucene กับ Spark เราทำการสืบค้นต่อเนื่องโดยขอจาก 1% ถึง 100% ของข้อมูลที่เก็บไว้ เราจะเห็นว่าดัชนีมีประสิทธิภาพสูงสำหรับการสืบค้นที่ขอข้อมูลที่กรองอย่างเข้มงวด อย่างไรก็ตาม ประสิทธิภาพจะลดลงเมื่อมีการสืบค้นที่มีข้อจำกัดน้อยกว่า เมื่อจำนวนระเบียนที่ส่งคืนจากการสืบค้นเพิ่มขึ้น เราก็มาถึงจุดที่ดัชนีจะช้ากว่าการสแกนแบบเต็ม ดังนั้นการตัดสินใจใช้ดัชนีในงาน Spark ของคุณจึงขึ้นอยู่กับการเลือกคิวรี ข้อดีข้อเสียระหว่างทั้งสองวิธีขึ้นอยู่กับกรณีการใช้งานเฉพาะ โดยทั่วไป แนะนำให้รวมดัชนี Lucene กับ Spark สำหรับงานที่ดึงข้อมูลไม่เกิน 25% ของข้อมูลที่เก็บไว้
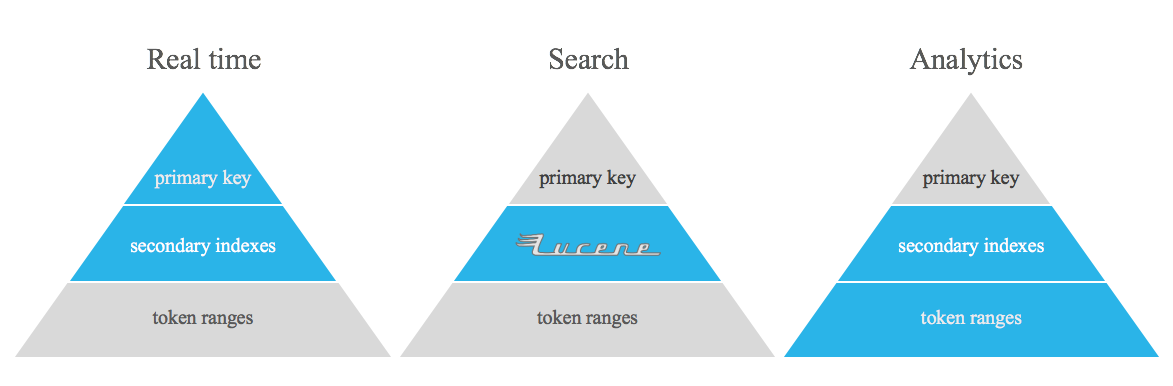
โปรเจ็กต์นี้ไม่ได้มีวัตถุประสงค์เพื่อแทนที่ตารางที่ทำให้ปกติของ Apache Cassandra ดัชนีแบบกลับด้าน และ/หรือดัชนีรอง มันเป็นเพียงเครื่องมือในการสืบค้นบางประเภทที่แก้ไขได้ยากโดยใช้ฟีเจอร์ Apache Cassandra ที่พร้อมใช้งานทันที ซึ่งช่วยเติมเต็มช่องว่างระหว่างเรียลไทม์และการวิเคราะห์
ดูข้อมูลโดยละเอียดเพิ่มเติมได้ที่เอกสาร Cassandra Lucene Index ของ Stratio
การรวมเทคโนโลยีการค้นหาของ Lucene เข้ากับ Cassandra ช่วยให้:
Cassandra Lucene Index ของ Stratio และการบูรณาการกับเทคโนโลยีการค้นหา Lucene ช่วยให้:
ยังไม่รองรับ:
counter นับดัชนีCassandra Lucene Index ของ Stratio ได้รับการเผยแพร่เป็นปลั๊กอินสำหรับ Apache Cassandra ดังนั้นคุณเพียงแค่ต้องสร้าง JAR ที่มีปลั๊กอินและเพิ่มลงใน classpath ของ Cassandra:
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/เวอร์ชันดัชนี Cassandra Lucene เฉพาะเจาะจงมีเป้าหมายเป็นเวอร์ชัน Apache Cassandra เฉพาะ ดังนั้น cassandra-lucene-index ABCX มีวัตถุประสงค์เพื่อใช้กับ Apache Cassandra ABC เช่น cassandra-lucene-index:3.0.7.1 สำหรับ cassandra:3.0.7 โปรดทราบว่ารีลีสที่พร้อมสำหรับการใช้งานจริงคือแท็กเวอร์ชัน (เช่น 3.0.6.3) อย่าใช้สาขา-X หรือสาขาหลักในการใช้งานจริง
อีกทางหนึ่ง การแพตช์สามารถทำได้ด้วยโปรไฟล์ Maven นี้ โดยระบุเส้นทางของการติดตั้ง Cassandra ของคุณ งานนี้จะลบเวอร์ชัน JAR ของปลั๊กอินก่อนหน้าในไดเร็กทอรี CASSANDRA_HOME/lib/ ด้วย:
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >หากคุณไม่มี Cassandra เวอร์ชันที่ติดตั้งไว้ ยังมีโปรไฟล์อื่นเพื่อให้ Maven ดาวน์โหลดและแพตช์ Apache Cassandra เวอร์ชันที่เหมาะสม:
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >ตอนนี้คุณสามารถรัน Cassandra และทำการทดสอบบางอย่างโดยใช้ Cassandra Query Language:
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh ไฟล์ดัชนีของ Lucene จะถูกจัดเก็บไว้ในไดเร็กทอรีเดียวกับที่ไฟล์ของ Cassandra อยู่ ไดเร็กทอรีข้อมูลเริ่มต้นคือ /var/lib/cassandra/data และแต่ละดัชนีจะถูกวางไว้ถัดจาก SSTables ของตระกูลคอลัมน์ที่จัดทำดัชนี
โปรดจำไว้ว่าหากคุณใช้การค้นหารูปร่างทางภูมิศาสตร์ คุณจะต้องรวม JTS jar ด้วย
สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ Apache Cassandra โปรดดูเอกสารประกอบ
เราจะสร้างตารางต่อไปนี้เพื่อจัดเก็บทวีต:
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);ตอนนี้คุณสามารถสร้างดัชนี Lucene แบบกำหนดเองได้โดยใช้คำสั่งต่อไปนี้:
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; การดำเนินการนี้จะสร้างดัชนีคอลัมน์ทั้งหมดในตารางตามประเภทที่ระบุ และจะมีการรีเฟรชหนึ่งครั้งต่อวินาที หรือคุณสามารถรีเฟรชชาร์ดดัชนีทั้งหมดอย่างชัดเจนด้วยการค้นหาว่าง ๆ ที่มีความสอดคล้องกัน ALL :
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMตอนนี้ หากต้องการค้นหาทวีตภายในช่วงวันที่ที่กำหนด:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );การค้นหาเดียวกันสามารถทำได้โดยบังคับให้มีการรีเฟรชชาร์ดดัชนีที่เกี่ยวข้องอย่างชัดเจน:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;ตอนนี้เพื่อค้นหาทวีตที่เกี่ยวข้องมากกว่า 100 อันดับแรกโดยที่ ฟิลด์เนื้อหา มีวลี “ข้อมูลขนาดใหญ่ให้องค์กร” ภายในช่วงวันที่ดังกล่าว:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;หากต้องการปรับแต่งการค้นหาเพื่อให้ได้เฉพาะทวีตที่เขียนโดยผู้ใช้ที่ชื่อขึ้นต้นด้วย "a":
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;หากต้องการรับผลลัพธ์ที่กรองล่าสุด 100 รายการ คุณสามารถใช้ตัวเลือก การจัดเรียง :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;การค้นหาก่อนหน้านี้สามารถจำกัดเฉพาะทวีตที่สร้างขึ้นใกล้กับตำแหน่งทางภูมิศาสตร์:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;นอกจากนี้ยังสามารถจัดเรียงผลลัพธ์ตามระยะทางไปยังตำแหน่งทางภูมิศาสตร์ได้:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;สุดท้ายแต่ไม่ท้ายสุด คุณสามารถกำหนดเส้นทางการค้นหาไปยังช่วงโทเค็นหรือพาร์ติชันที่ต้องการได้ ในลักษณะที่จะเข้าถึงเฉพาะโหนดคลัสเตอร์บางส่วนเท่านั้น ซึ่งช่วยประหยัดทรัพยากรอันมีค่า:
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;สุดท้ายนี้เป็นพื้นฐานสำหรับการรองรับ Hadoop, Spark และเฟรมเวิร์ก MapReduce อื่นๆ
โปรดดูเอกสารประกอบ Cassandra Lucene Index ของ Stratio ที่ครอบคลุม


