อัลปาก้า-rlhf
การปรับแต่ง LLaMA ด้วย RLHF (การเรียนรู้แบบเสริมแรงพร้อมผลตอบรับจากมนุษย์)
การสาธิตออนไลน์
การปรับเปลี่ยน DeepSpeed Chat
ขั้นตอนที่ 1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- ฝึกเฉพาะการตอบกลับและเพิ่ม eos
- ลบ end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# รับรายการ
- ป้ายกำกับแตกต่างจากอินพุต
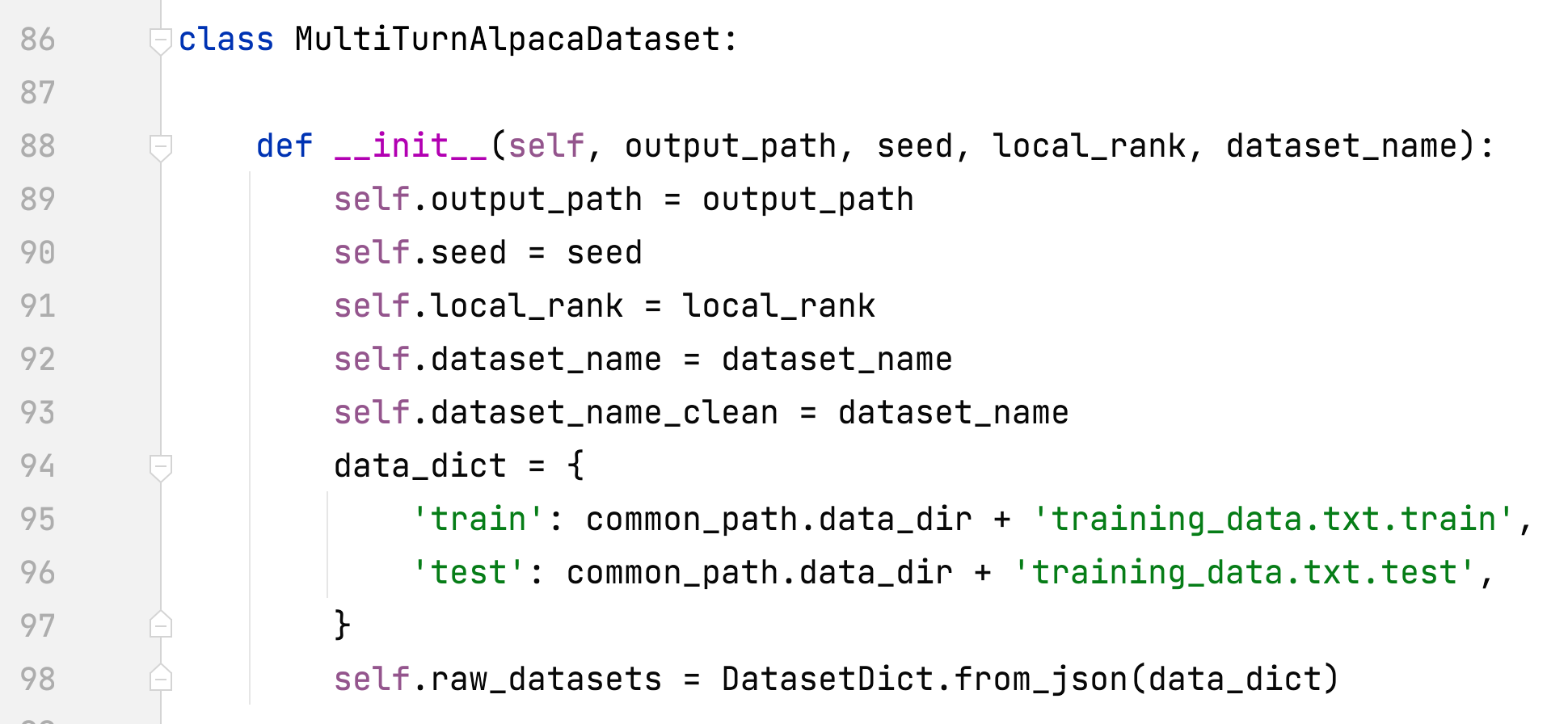
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- เพิ่ม MultiTurnAlpacaDataset
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
- รองรับชื่อโมดูลหลายชื่อสำหรับ lora
ขั้นตอนที่ 2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- แก้ไขความไม่แน่นอนของตัวเลข
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- ลบ end_of_conversation_token
ขั้นตอนที่ 3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- แก้ไขข้อผิดพลาดความยาวสูงสุด
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# โทร
- แก้ไขข้อบกพร่องด้านช่องว่างภายใน
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
ทีละขั้นตอน
- ใช้งานทั้งสามขั้นตอนบน 2 x A100 80G
- ชุดข้อมูล
- กระดาษ Dahoas/rm-static Huggingface GitHub
- มัลติเทิร์นอัลปาก้า
- นี่เป็นชุดข้อมูล alpaca เวอร์ชันหลายรอบและสร้างขึ้นจาก AlpacaDataCleaned และ ChatAlpaca
- ป้อนไดเร็กทอรี ./alpaca_rlhf ก่อน จากนั้นรันคำสั่งต่อไปนี้:
- ขั้นตอนที่ 1: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- เมื่อมีการเพิ่ม --sft_only_data_path MultiTurnAlpaca โปรดแตกไฟล์ data/data.zip ก่อน
- ขั้นตอนที่ 2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
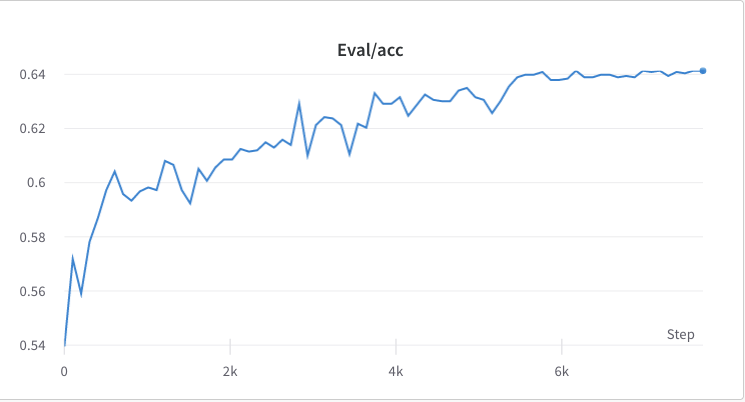
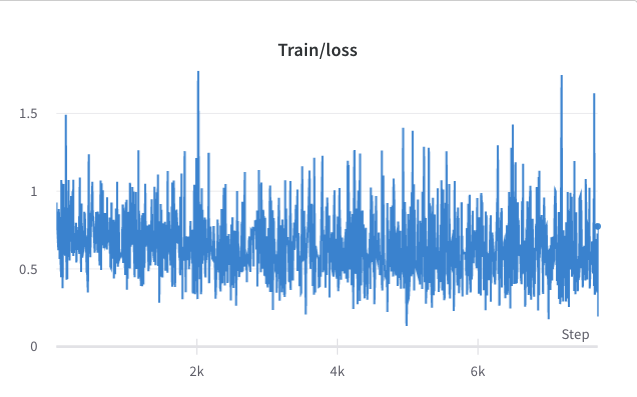
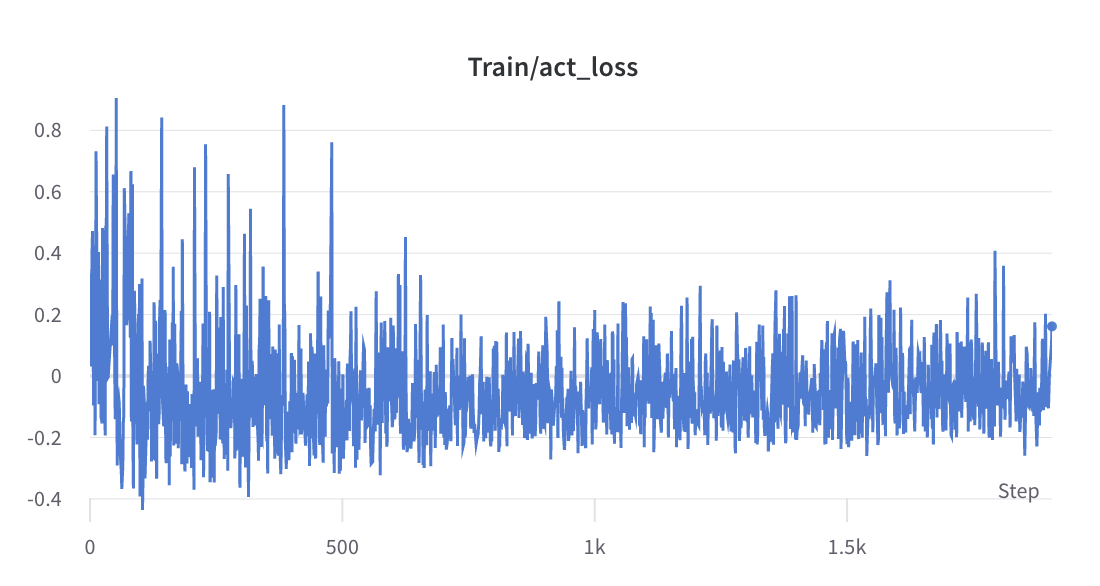
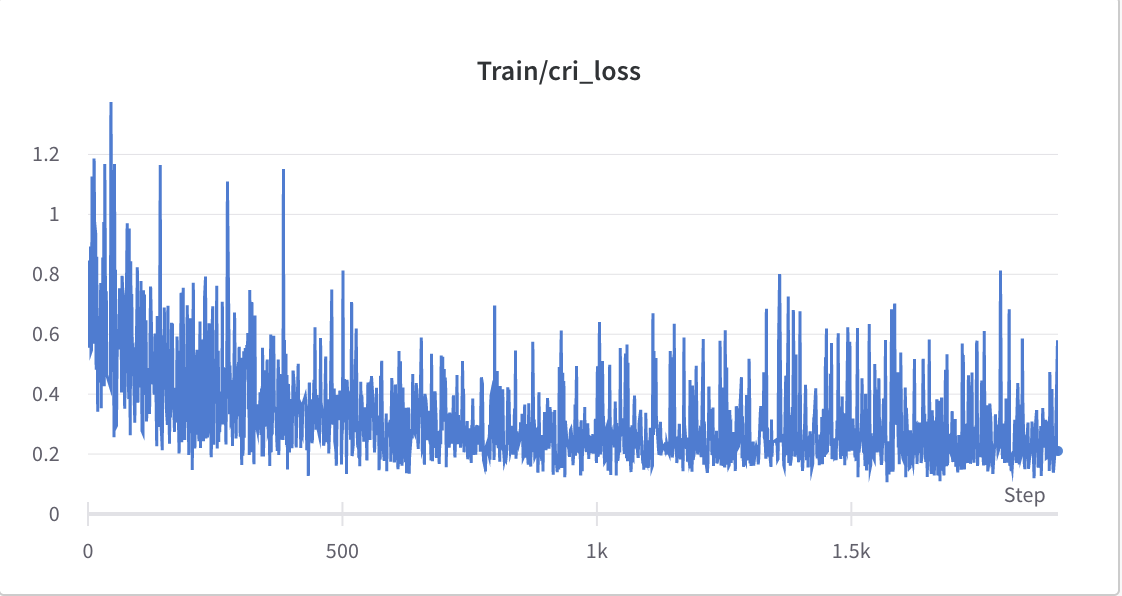
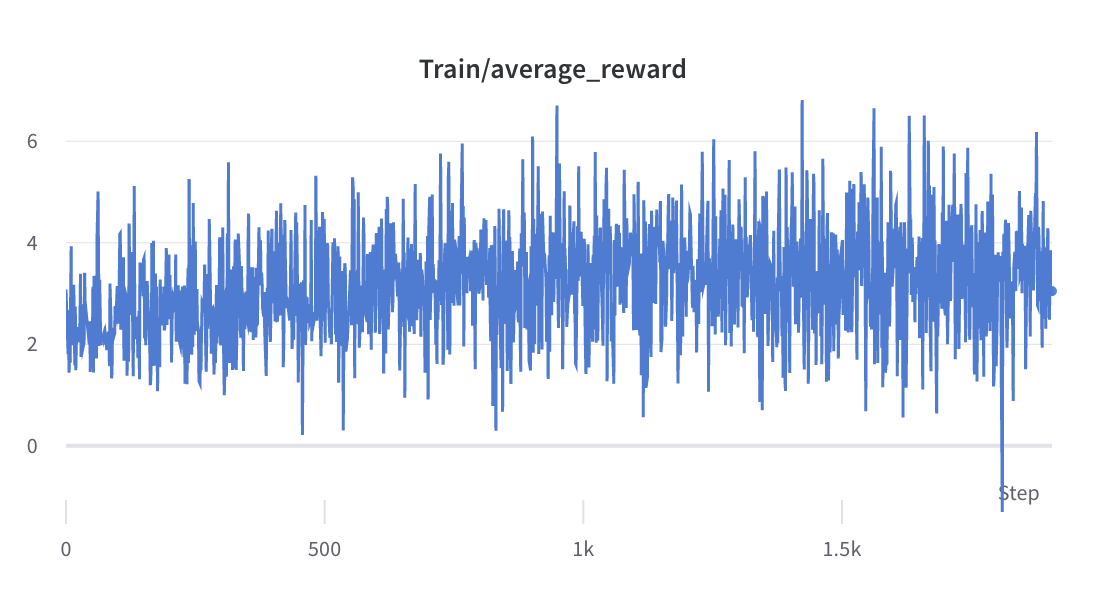
- กระบวนการฝึกอบรมขั้นตอนที่ 2
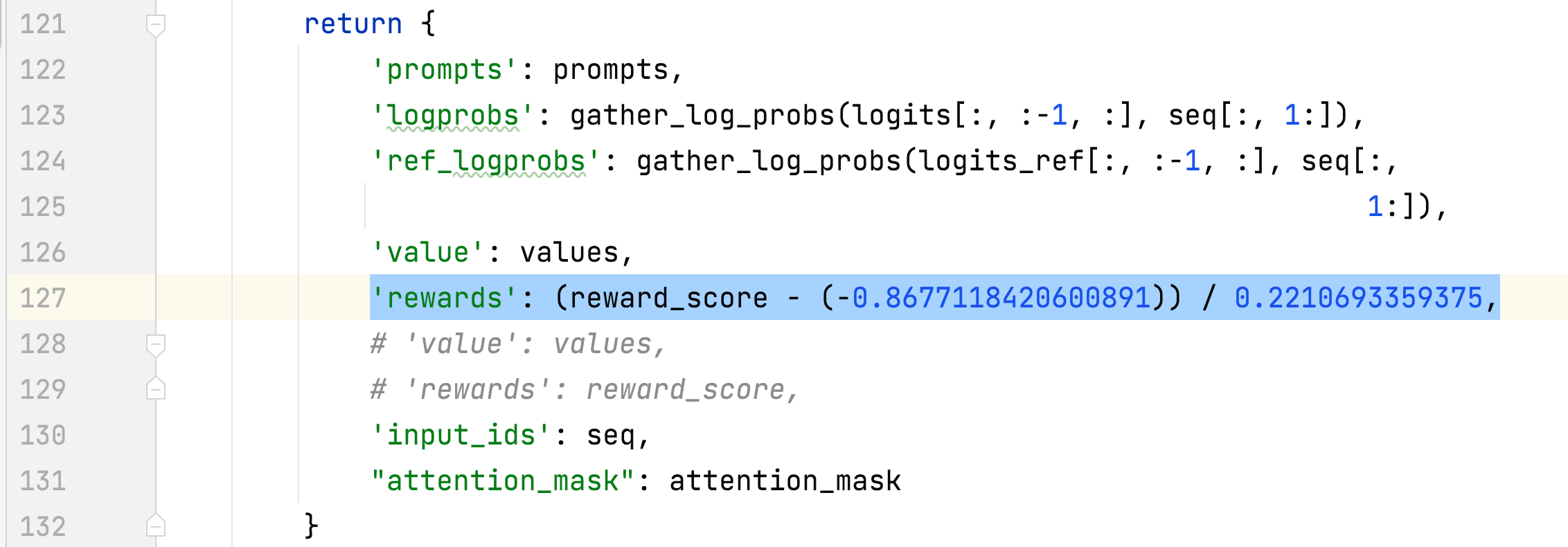
- ค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานของรางวัลของคำตอบที่เลือกจะถูกรวบรวมและใช้ในการทำให้รางวัลเป็นมาตรฐานในขั้นตอนที่ 3 ในการทดลองหนึ่ง ค่าเหล่านั้นคือ -0.8677118420600891 และ 0.2210693359375 ตามลำดับ และใช้ใน alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience วิธีการ: 'รางวัล': (reward_score - (-0.8677118420600891)) / 0.2210693359375
- ขั้นตอนที่ 3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/นักแสดง/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
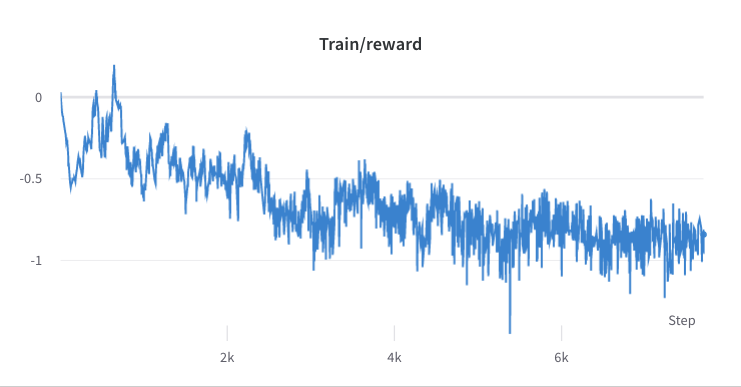
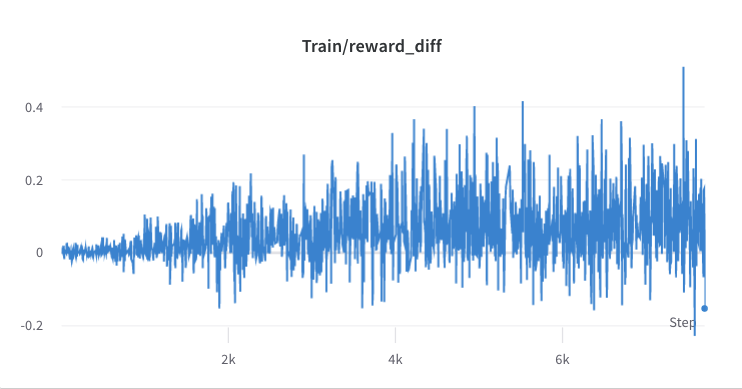
- กระบวนการฝึกอบรมขั้นตอนที่ 3
- การอนุมาน
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
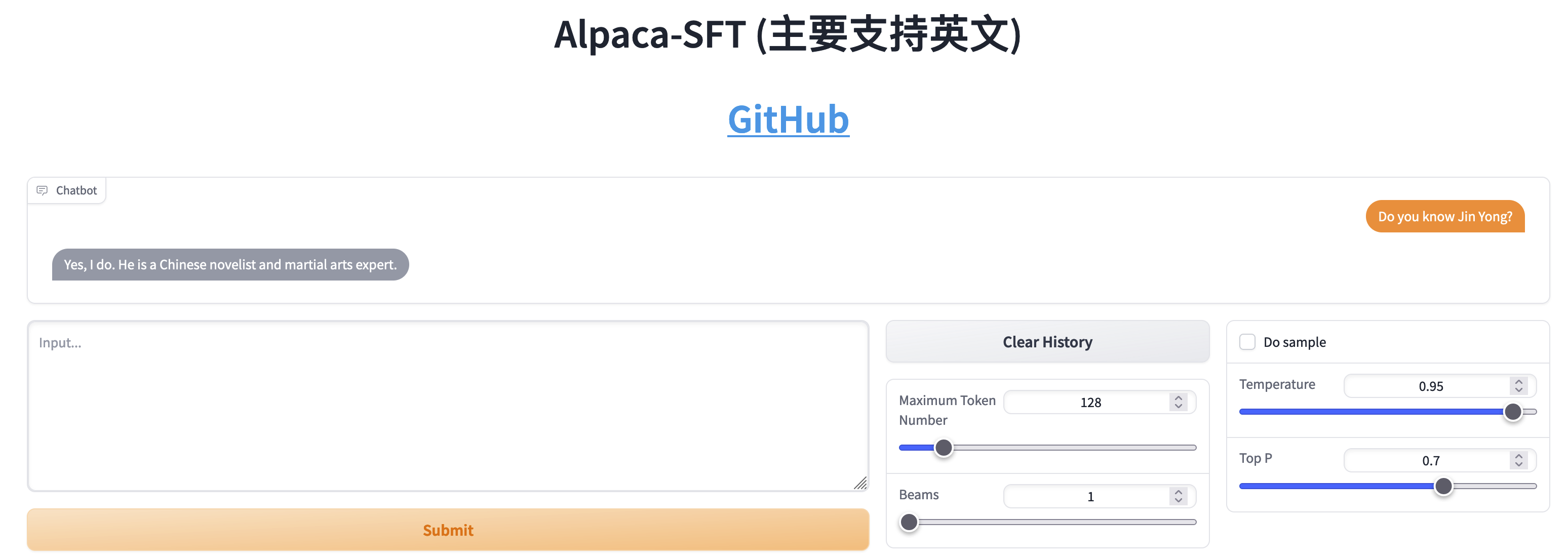
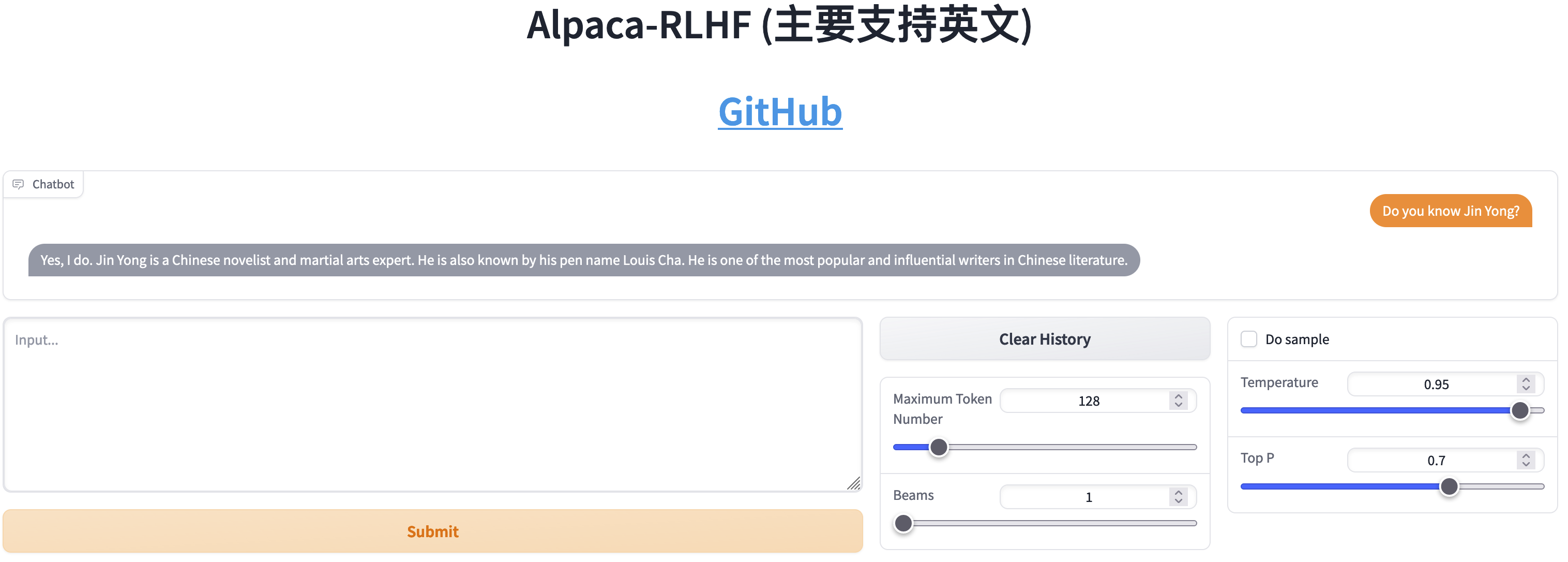
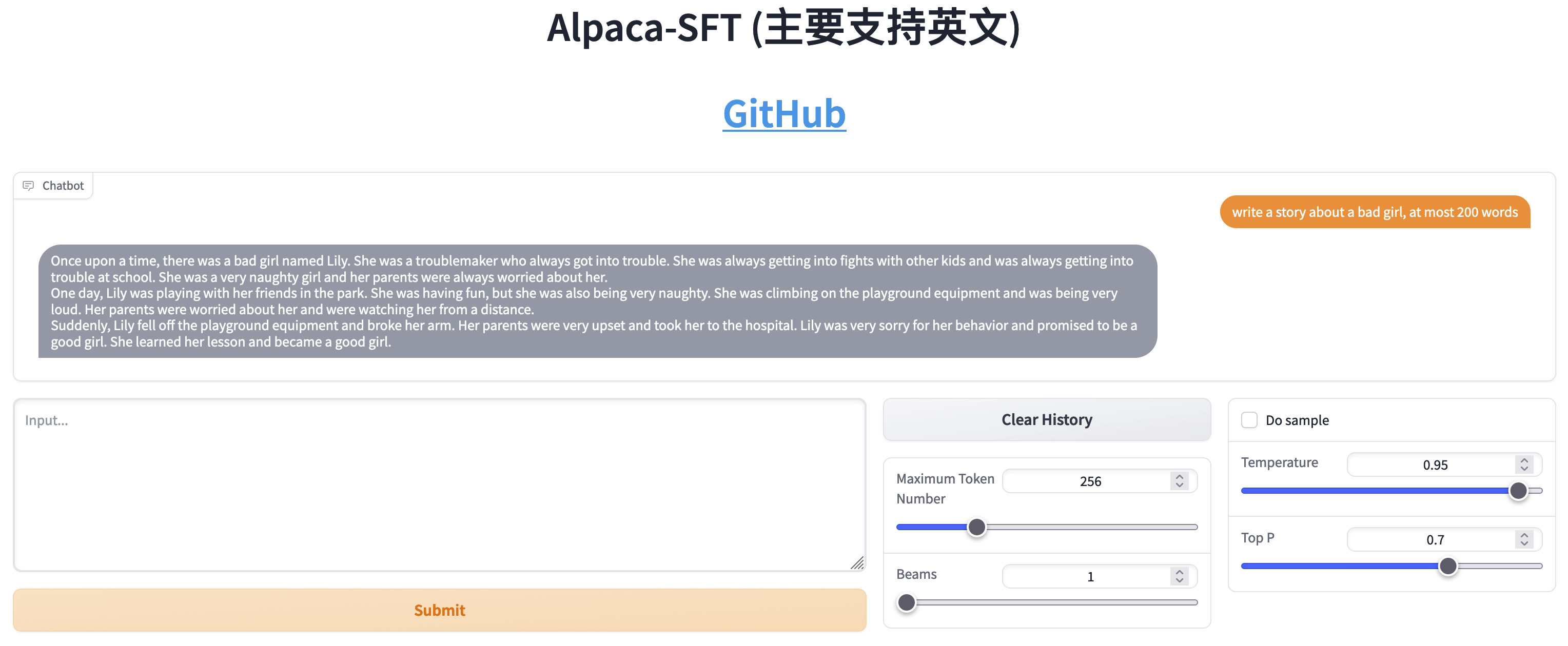
การเปรียบเทียบระหว่าง SFT และ RLHF
อ้างอิง
บทความ
- 如何正确复现 สอน GPT / RLHF หรือไม่?
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
แหล่งที่มา
เครื่องมือ
ชุดข้อมูล
- ชุดข้อมูลการตั้งค่าของมนุษย์สแตนฟอร์ด (SHP)
- HH-RLHF
- hh-rlhf
- การฝึกอบรมผู้ช่วยที่เป็นประโยชน์และไม่เป็นอันตรายด้วยการเรียนรู้แบบเสริมกำลังจากผลตอบรับของมนุษย์ [กระดาษ]
- Dahoas/คงที่-hh
- Dahoas/rm-คงที่
- GPT-4-LLM
- เปิดผู้ช่วย
ที่เก็บข้อมูลที่เกี่ยวข้อง
- อัลปาก้าของฉัน
- อัลปาก้าหลายรอบ