icl selective annotation
1.0.0
รหัสสำหรับกระดาษ คำอธิบายประกอบแบบเลือกทำให้แบบจำลองภาษาดีขึ้นสำหรับผู้เรียนเพียงไม่กี่คน
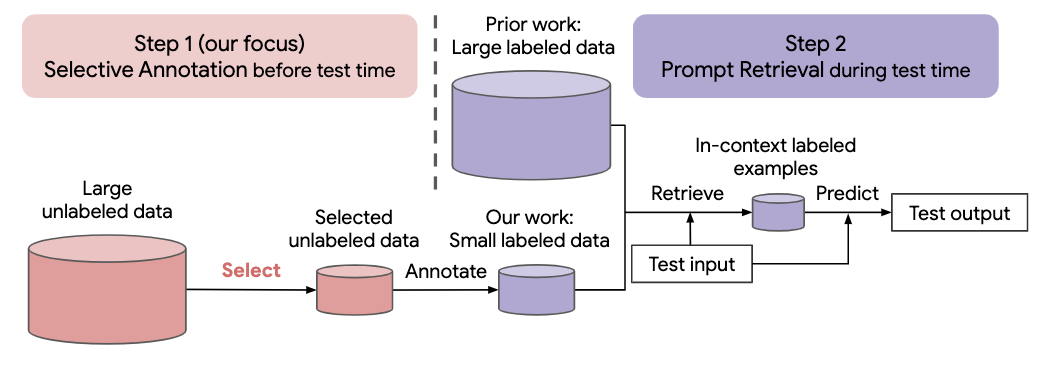
แนวทางการทำงานด้านภาษาธรรมชาติล่าสุดจำนวนมากสร้างขึ้นจากความสามารถที่โดดเด่นของแบบจำลองภาษาขนาดใหญ่ โมเดลภาษาขนาดใหญ่สามารถทำการเรียนรู้ในบริบท โดยที่เรียนรู้งานใหม่จากการสาธิตงานเพียงไม่กี่อย่าง โดยไม่ต้องอัปเดตพารามิเตอร์ใดๆ งานนี้ตรวจสอบผลกระทบของการเรียนรู้ในบริบทสำหรับการสร้างชุดข้อมูลสำหรับงานภาษาธรรมชาติใหม่ ออกจากวิธีการเรียนรู้ในบริบทล่าสุด เรากำหนดเฟรมเวิร์กสองขั้นตอนที่มีประสิทธิภาพในการใส่คำอธิบายประกอบ: คำอธิบายประกอบแบบเลือก ที่เลือกกลุ่มตัวอย่างเพื่อใส่คำอธิบายประกอบจากข้อมูลที่ไม่มีป้ายกำกับไว้ล่วงหน้า ตามด้วยการเรียกข้อมูลพร้อมท์ที่ดึงตัวอย่างงานจากกลุ่มที่มีคำอธิบายประกอบที่ เวลาทดสอบ จากกรอบการทำงานนี้ เราขอเสนอวิธีการเพิ่มความคิดเห็นแบบเลือกตามกราฟแบบไม่มีผู้ดูแล ซึ่ง ก็คือ vote-k เพื่อเลือกตัวอย่างที่เป็นตัวแทนที่หลากหลายสำหรับใส่คำอธิบายประกอบ การทดลองอย่างกว้างขวางกับชุดข้อมูล 10 ชุด (ครอบคลุมการจำแนกประเภท การใช้เหตุผลทั่วไป บทสนทนา และการสร้างข้อความ/โค้ด) แสดงให้เห็นว่าวิธีการใส่คำอธิบายประกอบแบบเลือกสรรของเราช่วยปรับปรุงประสิทธิภาพของงานได้มาก โดยเฉลี่ยแล้ว vote-k ได้รับ ความสัมพันธ์เพิ่มขึ้น 12.9%/11.4% ภายใต้งบประมาณคำอธิบายประกอบที่ 18/100 เมื่อเปรียบเทียบกับการเลือกตัวอย่างแบบสุ่มเพื่อใส่คำอธิบายประกอบ เมื่อเปรียบเทียบกับแนวทางการปรับแต่งที่มีการควบคุมดูแลที่ล้ำสมัย ก็ให้ประสิทธิภาพที่ใกล้เคียงกัน โดยมี ค่าใช้จ่ายคำอธิบายประกอบน้อยกว่า 10-100 เท่า ใน 10 งาน เรายังวิเคราะห์ประสิทธิภาพของกรอบงานของเราเพิ่มเติมในสถานการณ์ต่างๆ: โมเดลภาษาที่มีขนาดแตกต่างกัน วิธีการเลือกคำอธิบายประกอบแบบอื่น และกรณีที่มีการเปลี่ยนแปลงโดเมนข้อมูลทดสอบ เราหวังว่าการศึกษาของเราจะทำหน้าที่เป็นพื้นฐานสำหรับคำอธิบายประกอบข้อมูล เนื่องจากแบบจำลองภาษาขนาดใหญ่ถูกนำไปใช้กับงานใหม่ๆ มากขึ้น
เรียกใช้คำสั่งต่อไปนี้เพื่อโคลน repo นี้
git clone https://github.com/HKUNLP/icl-selective-annotation
หากต้องการสร้างสภาพแวดล้อม ให้รันโค้ดนี้ในเชลล์:
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
นั่นจะสร้างสภาพแวดล้อมแบบ selector_annotation ที่เราใช้
เปิดใช้งานสภาพแวดล้อมโดยการรัน
conda activate selective_annotation
GPT-J เป็นรูปแบบการเรียนรู้ในบริบท DBpedia เป็นงาน และ vote-k เป็นวิธีคำอธิบายประกอบแบบเลือก (1 GPU, หน่วยความจำ 40GB)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
หากคุณพบว่างานของเรามีประโยชน์ โปรดอ้างอิงถึงเรา
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


