Phi2 mini Chinese
1.0.0
โปรเจ็กต์นี้เป็นโปรเจ็กต์ทดลองที่มีโค้ดโอเพ่นซอร์สและน้ำหนักโมเดล และข้อมูลก่อนการฝึกอบรมน้อยกว่า หากคุณต้องการโมเดลภาษาจีนขนาดเล็กที่ดีกว่า คุณสามารถดูโปรเจ็กต์ ChatLM-mini- Chinese
คำเตือน
โปรเจ็กต์นี้เป็นโปรเจ็กต์ทดลองและอาจมีการเปลี่ยนแปลงครั้งใหญ่ได้ตลอดเวลา รวมถึงข้อมูลการฝึกอบรม โครงสร้างโมเดล โครงสร้างไดเร็กทอรีไฟล์ ฯลฯ รุ่นแรกของรุ่นและโปรดตรวจสอบ tag v1.0
ตัวอย่างเช่น การเพิ่มจุดท้ายประโยค การแปลงภาษาจีนตัวเต็มเป็นภาษาจีนตัวย่อ การลบเครื่องหมายวรรคตอนซ้ำ (เช่น เนื้อหาบทสนทนาบางรายการมี "。。。。。" จำนวนมาก) การกำหนดมาตรฐาน NFKC Unicode (ปัญหาหลักคือปัญหาเต็ม- การแปลงความกว้างเป็นข้อมูลครึ่งความกว้างและข้อมูลหน้าเว็บ u3000 xa0) ฯลฯ
สำหรับกระบวนการล้างข้อมูลเฉพาะ โปรดดูโครงการ ChatLM-mini- Chinese
โปรเจ็กต์นี้ใช้โทเค็น BPE byte level มีรหัสการฝึกอบรมสองประเภทสำหรับตัวแบ่งส่วนคำ: char level และ byte level
หลังการฝึก โทเค็นไนเซอร์จะจำไว้ว่าต้องตรวจสอบว่ามีสัญลักษณ์พิเศษทั่วไปในคำศัพท์หรือไม่ เช่น t , n ฯลฯ คุณสามารถลอง encode และ decode ข้อความที่มีอักขระพิเศษเพื่อดูว่าสามารถกู้คืนได้หรือไม่ หากไม่รวมอักขระพิเศษเหล่านี้ ให้เพิ่มผ่านฟังก์ชัน add_tokens ใช้ len(tokenizer) เพื่อดูขนาดคำศัพท์ tokenizer.vocab_size ไม่นับอักขระที่เพิ่มผ่านฟังก์ชัน add_tokens
การฝึกอบรม Tokenizer ใช้หน่วยความจำมาก:
การฝึก 100 ล้านอักขระ byte level ต้องใช้หน่วยความจำอย่างน้อย 32G (อันที่จริง 32G ยังไม่เพียงพอ และการสลับจะถูกเรียกใช้บ่อยครั้ง) การฝึก 13600k ใช้เวลาประมาณหนึ่งชั่วโมง
การฝึกอบรม char level 650 ล้านอักขระ (ซึ่งเท่ากับปริมาณข้อมูลในวิกิพีเดียภาษาจีน) ต้องใช้หน่วยความจำอย่างน้อย 32G เนื่องจากการสลับถูกทริกเกอร์หลายครั้ง การใช้งานจริงจึงมากกว่า 32G มาก การฝึกอบรม 13600K ใช้เวลาประมาณครึ่งชั่วโมง ชั่วโมง.
ดังนั้น เมื่อชุดข้อมูลมีขนาดใหญ่ (ระดับ GB) ขอแนะนำให้สุ่มตัวอย่างจากชุดข้อมูลเมื่อฝึก tokenizer
ใช้ข้อความจำนวนมากสำหรับการฝึกอบรมล่วงหน้าแบบไม่มีผู้ดูแล โดยใช้ชุดข้อมูล BELLE จาก bell open source เป็นหลัก
รูปแบบชุดข้อมูล: หนึ่งประโยคสำหรับหนึ่งตัวอย่าง หากยาวเกินไป สามารถตัดทอนและแบ่งออกเป็นหลายตัวอย่างได้
ในระหว่างกระบวนการฝึกอบรมล่วงหน้าของ CLM อินพุตและเอาท์พุตของโมเดลจะเหมือนกัน และเมื่อคำนวณการสูญเสียเอนโทรปีข้าม จะต้องเลื่อนหนึ่งบิต ( shift )
เมื่อประมวลผลคลังข้อมูลสารานุกรม ขอแนะนำให้เพิ่มเครื่องหมาย '[EOS]' ที่ท้ายแต่ละรายการ การประมวลผลคลังข้อมูลอื่นๆ จะคล้ายกัน ส่วนท้ายของ doc (ซึ่งอาจเป็นจุดสิ้นสุดของบทความหรือส่วนท้ายของย่อหน้า) จะต้องมีเครื่องหมาย '[EOS]' สามารถเพิ่มเครื่องหมายเริ่มต้น '[BOS]' ได้หรือไม่
ส่วนใหญ่ใช้ชุดข้อมูลของ bell open source ขอบคุณเจ้านายเบลล์
รูปแบบข้อมูลสำหรับการฝึกอบรม SFT มีดังนี้:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" เมื่อแบบจำลองคำนวณการสูญเสีย โมเดลจะเพิกเฉยต่อส่วนที่อยู่หน้าเครื่องหมาย "##回答:" ( "##回答:" จะถูกละเว้นด้วย) โดยเริ่มจากส่วนท้ายของ "##回答:"
อย่าลืมเพิ่มเครื่องหมายพิเศษท้ายประโยค EOS ไม่เช่นนั้นคุณจะไม่รู้ว่าเมื่อใดควรหยุดเมื่อ decode โมเดล เครื่องหมายเริ่มต้นประโยค BOS สามารถเติมหรือเว้นว่างไว้ได้
ใช้วิธีการเพิ่มประสิทธิภาพการตั้งค่า DPO ที่ง่ายและประหยัดหน่วยความจำมากขึ้น
ปรับแต่งโมเดล SFT ตามความต้องการส่วนบุคคล ชุดข้อมูลควรสร้าง 3 คอลัมน์ ได้แก่ prompt chosen และ rejected คอลัมน์ rejected มีข้อมูลบางส่วนจากโมเดลหลักในระยะ sft (เช่น sft ฝึก 4 epoch และใช้ แบบจำลองจุดตรวจสอบ epoch 0.5) สร้าง หากความคล้ายคลึงกันระหว่างที่สร้างขึ้น rejected และ chosen มากกว่า 0.9 ก็ไม่จำเป็นต้องใช้ข้อมูลนี้
มีสองโมเดลในกระบวนการ DPO หนึ่งคือโมเดลที่จะฝึกอบรม และอีกโมเดลคือโมเดลอ้างอิง เมื่อโหลด จริงๆ แล้วจะเป็นโมเดลเดียวกัน แต่โมเดลอ้างอิงไม่มีส่วนร่วมในการอัพเดตพารามิเตอร์
ที่เก็บน้ำหนัก huggingface โมเดล: Phi2-China-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
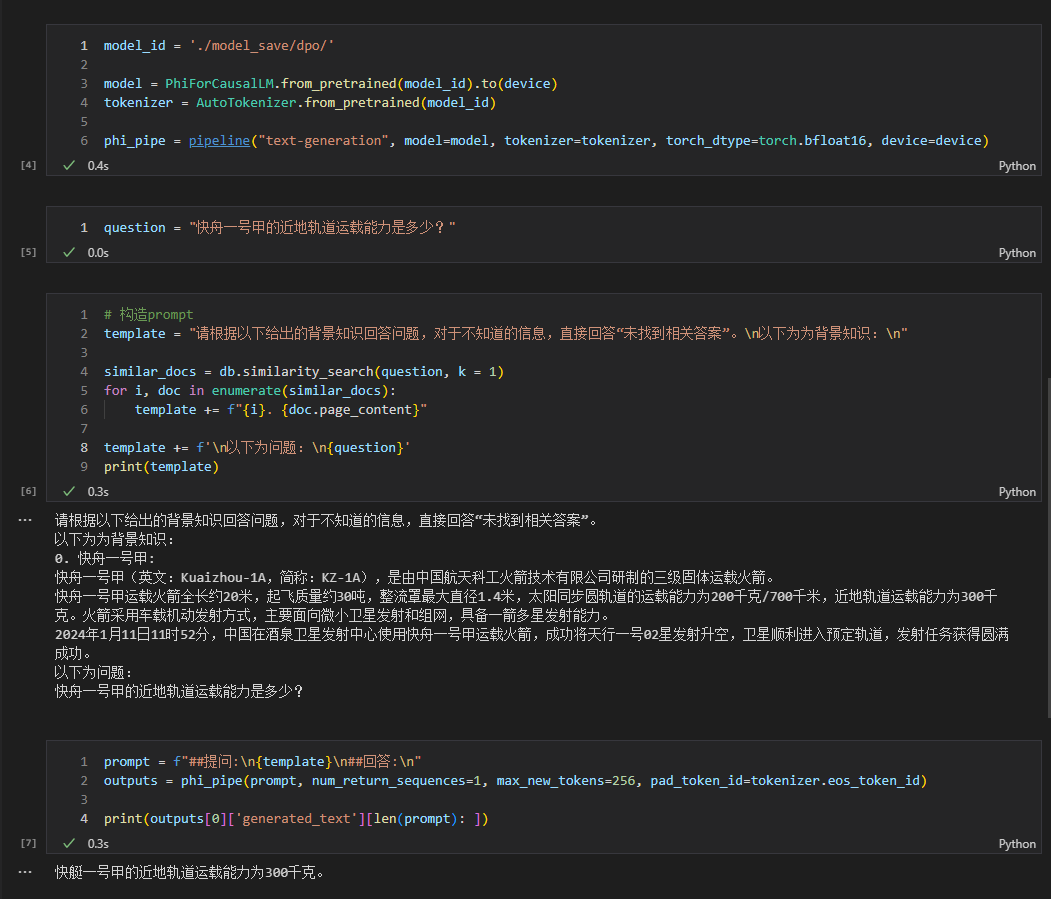
- 另外,如果感冒了,建议及时就医。 ดู rag_with_langchain.ipynb สำหรับโค้ดเฉพาะ
หากคุณคิดว่าโครงการนี้เป็นประโยชน์กับคุณ กรุณาอ้างอิง
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
โครงการนี้ไม่รับความเสี่ยงและความรับผิดชอบด้านความปลอดภัยของข้อมูลและความเสี่ยงต่อความคิดเห็นสาธารณะที่เกิดจากโมเดลและโค้ดโอเพ่นซอร์ส หรือความเสี่ยงและความรับผิดชอบที่เกิดจากโมเดลใดๆ ที่ถูกทำให้เข้าใจผิด ถูกนำไปใช้ในทางที่ผิด เผยแพร่ หรือใช้ประโยชน์อย่างไม่เหมาะสม


