LLaMA LoRA Tuner
v0.0.20230421
ทำให้การประเมินและการปรับแต่งโมเดล LLaMA อย่างละเอียดด้วยการปรับอันดับต่ำ (LoRA) เป็นเรื่องง่าย
อัปเดต :
ในสาขา
devมี Chat UI ใหม่และการกำหนดค่า โหมดสาธิต ใหม่ซึ่งเป็นวิธีที่ง่ายและสะดวกในการสาธิตโมเดลใหม่อย่างไรก็ตาม เวอร์ชันใหม่ยังไม่มีฟีเจอร์การปรับแต่งอย่างละเอียดและไม่สามารถเข้ากันได้แบบย้อนหลัง เนื่องจากใช้วิธีใหม่ในการกำหนดวิธีการโหลดโมเดล และยังมีรูปแบบใหม่ของเทมเพลตพร้อมท์ (จาก LangChain)
สำหรับข้อมูลเพิ่มเติม โปรดดูที่: #28
LLM.Tuner.Chat.UI.in.Demo.Mode.mp4
ดูการสาธิตบน Hugging Face * ให้บริการเฉพาะการสาธิต UI เท่านั้น หากต้องการลองฝึกหรือสร้างข้อความ ให้เรียกใช้บน Colab
คลิก 1 ครั้งและทำงานใน Google Colab ด้วยรันไทม์ GPU มาตรฐาน
โหลดและจัดเก็บข้อมูลใน Google Drive
ประเมินโมเดล LLaMA LoRA ต่างๆ ที่จัดเก็บไว้ในโฟลเดอร์ของคุณหรือจาก Hugging Face 
สลับระหว่างโมเดลพื้นฐาน เช่น decapoda-research/llama-7b-hf , nomic-ai/gpt4all-j , databricks/dolly-v2-7b , EleutherAI/gpt-j-6b หรือ EleutherAI/pythia-6.9b
ปรับแต่งโมเดล LLaMA อย่างละเอียดด้วยเทมเพลตพร้อมต์และรูปแบบชุดข้อมูลการฝึกอบรมที่แตกต่างกัน 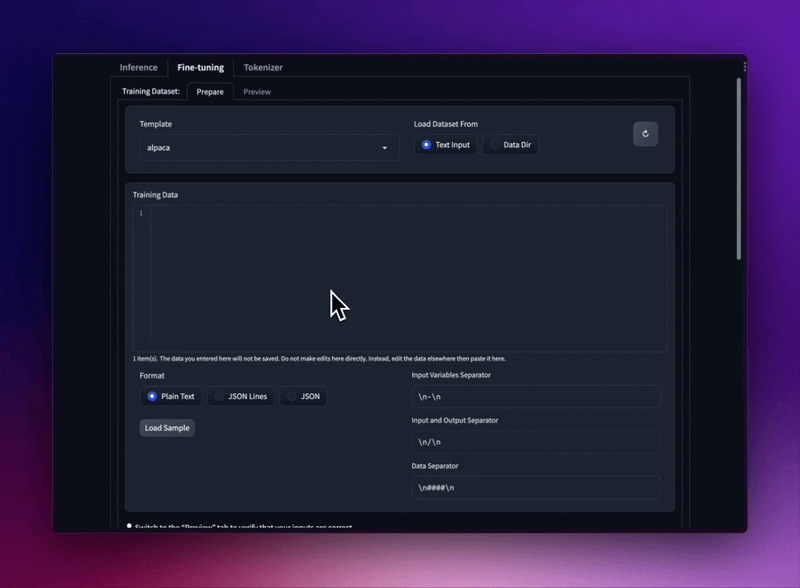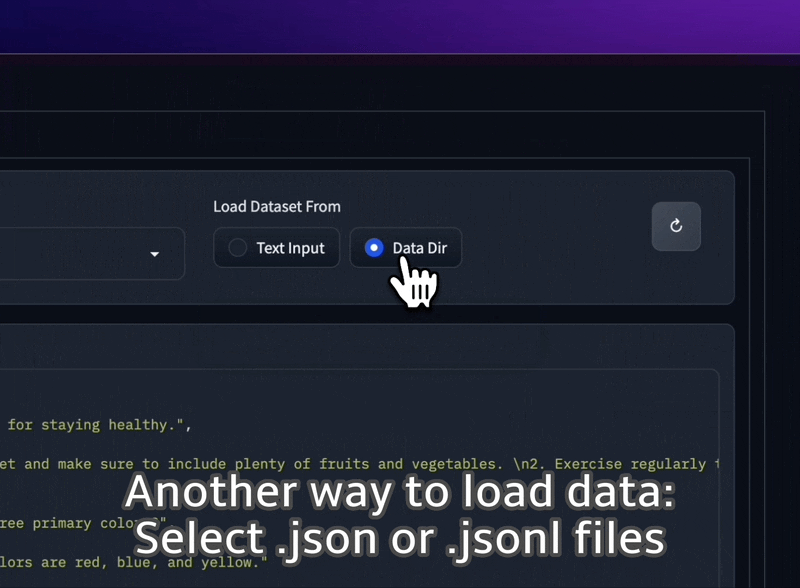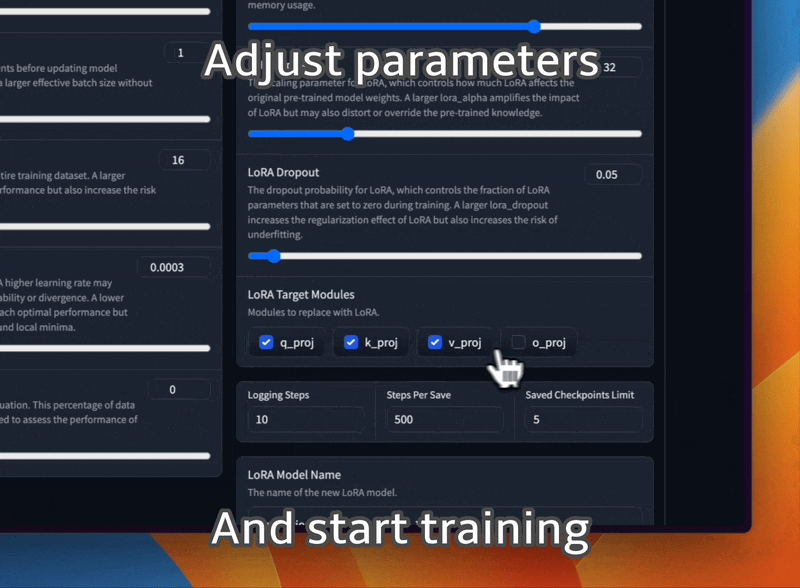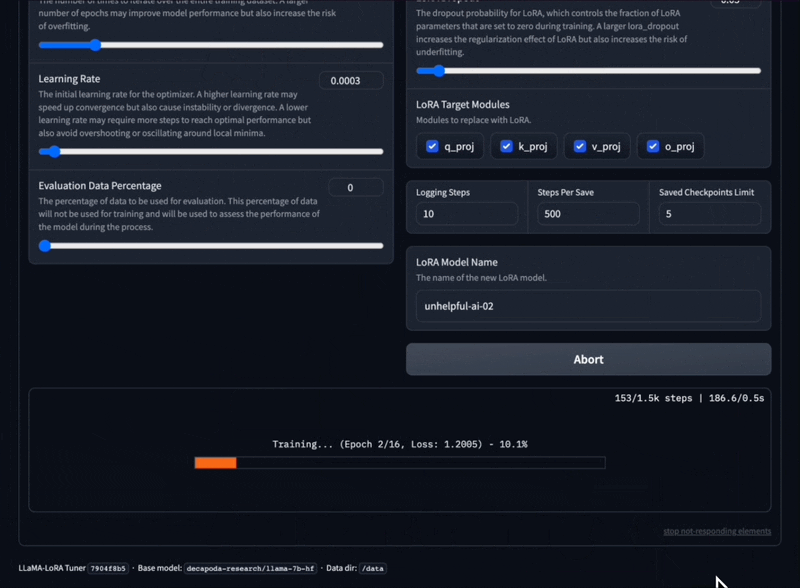
โหลดชุดข้อมูล JSON และ JSONL จากโฟลเดอร์ของคุณ หรือแม้แต่วางข้อความธรรมดาลงใน UI โดยตรง
รองรับรูปแบบ Stanford Alpaca seed_tasks, alpaca_data และ OpenAI "prompt"-"completion"
ใช้เทมเพลตพร้อมท์เพื่อให้ชุดข้อมูลของคุณแห้ง
มีหลายวิธีในการเรียกใช้แอพนี้:
ทำงานบน Google Colab : วิธีที่ง่ายที่สุดในการเริ่มต้น สิ่งที่คุณต้องมีคือบัญชี Google รันไทม์ของ GPU มาตรฐาน (ฟรี) เพียงพอสำหรับเรียกใช้การสร้างและการฝึกด้วยขนาดไมโครแบทช์ที่ 8 อย่างไรก็ตาม การสร้างข้อความและการฝึกจะช้ากว่าบริการระบบคลาวด์อื่นๆ มาก และ Colab อาจยุติการดำเนินการโดยไม่มีการใช้งานขณะทำงานที่ใช้เวลานาน
เรียกใช้บริการคลาวด์ผ่าน SkyPilot : หากคุณมีบัญชีบริการคลาวด์ (Lambda Labs, GCP, AWS หรือ Azure) คุณสามารถใช้ SkyPilot เพื่อเรียกใช้แอปบนบริการคลาวด์ได้ สามารถติดตั้งที่เก็บข้อมูลบนคลาวด์เพื่อรักษาข้อมูลของคุณได้
ทำงานในพื้นที่ : ขึ้นอยู่กับฮาร์ดแวร์ที่คุณมี
ดูวิดีโอสำหรับคำแนะนำทีละขั้นตอน
เปิดสมุดบันทึก Colab นี้แล้วเลือก รันไทม์ > เรียกใช้ทั้งหมด ( ⌘/Ctrl+F9 )
คุณจะได้รับแจ้งให้อนุญาตการเข้าถึง Google Drive เนื่องจาก Google Drive จะถูกใช้เพื่อจัดเก็บข้อมูลของคุณ ดูส่วน "การกำหนดค่า"/"Google ไดรฟ์" สำหรับการตั้งค่าและข้อมูลเพิ่มเติม
หลังจากใช้งานไปประมาณ 5 นาที คุณจะเห็น URL สาธารณะในผลลัพธ์ของส่วน "Launch"/"Start Gradio UI " (เช่น Running on public URL: https://xxxx.gradio.live ) เปิด URL ในเบราว์เซอร์ของคุณเพื่อใช้แอป
หลังจากทำตามคำแนะนำการติดตั้ง SkyPilot แล้ว ให้สร้าง .yaml เพื่อกำหนดงานสำหรับการเรียกใช้แอป:
# llm-tuner.yamlresources: ตัวเร่งความเร็ว: A10:1 # 1x NVIDIA A10 GPU ประมาณ US$ 0.6 / ชม. บน Lambda Cloud เรียกใช้ `sky show-gpus` สำหรับประเภท GPU ที่รองรับ และ `sky show-gpus [GPU_NAME]` สำหรับข้อมูลโดยละเอียดของประเภท GPU
เมฆ: แลมบ์ดา # ตัวเลือก; หากปล่อยทิ้งไว้ SkyPilot จะเลือก cloud.file_mounts ที่ถูกที่สุดโดยอัตโนมัติ: # ติดตั้งที่เก็บข้อมูลบนคลาวด์ที่มีอยู่ซึ่งจะใช้เป็นไดเร็กทอรีข้อมูล
# (เพื่อจัดเก็บชุดข้อมูลรถไฟรุ่นที่ได้รับการฝึกอบรม)
# ดู https://skypilot.readthedocs.io/en/latest/reference/storage.html สำหรับรายละเอียด
/data:name: llm-tuner-data # ตรวจสอบให้แน่ใจว่าชื่อนี้ไม่ซ้ำกัน หรือคุณเป็นเจ้าของที่เก็บข้อมูลนี้ หากไม่มีอยู่ SkyPilot จะพยายามสร้างบัคเก็ตด้วยชื่อนี้ store: s3 # อาจเป็นโหมดใดโหมดหนึ่ง [s3, gcs]: MOUNT# โคลน repo LLaMA-LoRA Tuner และติดตั้ง dependencies.setup: | conda create -q python=3.8 -n llm-tuner -y conda เปิดใช้งาน llm-tuner # โคลน repo LLaMA-LoRA Tuner และติดตั้งการขึ้นต่อกัน [ ! -d llm_tuner ] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo 'กำลังติดตั้งการอ้างอิง ...' pip install -r llm_tuner/requirements.lock.txt # ตัวเลือกเสริม: ติดตั้ง wandb ไปที่ เปิดใช้งานการบันทึกไปยัง Weights & Biases pip ติดตั้ง wandb # ตัวเลือก: แก้ไขบิตแซนด์ไบต์เป็นข้อผิดพลาดในการแก้ปัญหา "libbitsandbytes_cpu.so: สัญลักษณ์ที่ไม่ได้กำหนด: cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitsandbytes | grep 'Location' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo 'การแก้ไขบิตแซนด์ไบต์เพื่อรองรับ GPU...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" && cp "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" conda install -q cudatoolkit -y echo 'การติดตั้งการพึ่งพา' # ทางเลือก: ติดตั้งและตั้งค่า Cloudflare Tunnel เพื่อแสดงแอปบนอินเทอร์เน็ตด้วยชื่อโดเมนที่กำหนดเอง [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "การติดตั้ง Cloudflare" && curl -L --output cloudflared.deb https: //github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && ถอนการติดตั้งบริการ sudo cloudflared || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # ตัวเลือกเสริม: โมเดลการดาวน์โหลดล่วงหน้า echo "การดาวน์โหลดโมเดลพื้นฐานล่วงหน้า เพื่อที่คุณจะได้ไม่ต้องรอ เป็นเวลานานเมื่อแอปพร้อมแล้ว..." python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# เริ่มแอป `hf_access_token`, `wandb_api_key` และ `wandb_project` เป็นทางเลือกรัน: | conda เปิดใช้งาน llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt | tr -d 'n')" --wandb_project='llm-tuner' --timezone='แอตแลนติก/เรคยาวิก' --base_model= 'decapoda-การวิจัย/llama-7b-hf' --base_model_choices='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j,databricks/dolly-v2-7b' --shareจากนั้นเปิดคลัสเตอร์เพื่อรันงาน:
sky launch -c llm-tuner llm-tuner.yaml
-c ... เป็นแฟล็กทางเลือกเพื่อระบุชื่อคลัสเตอร์ หากไม่ได้ระบุ SkyPilot จะสร้างขึ้นมาโดยอัตโนมัติ
คุณจะเห็น URL สาธารณะของแอปในเทอร์มินัล เปิด URL ในเบราว์เซอร์ของคุณเพื่อใช้แอป
โปรดทราบว่าการออกจาก sky launch จะออกจากการสตรีมบันทึกเท่านั้น และจะไม่หยุดงาน คุณสามารถใช้ sky queue --skip-finished เพื่อดูสถานะของงานที่กำลังทำงานอยู่หรืองานที่ค้างอยู่ sky logs <cluster_name> <job_id> เชื่อมต่อกลับไปยังการสตรีมบันทึก และ sky cancel <cluster_name> <job_id> เพื่อหยุดงาน
เมื่อเสร็จแล้ว ให้รัน sky stop <cluster_name> เพื่อหยุดคลัสเตอร์ หากต้องการยุติคลัสเตอร์แทน ให้รัน sky down <cluster_name>
อย่าลืมหยุดหรือปิดคลัสเตอร์เมื่อดำเนินการเสร็จแล้วเพื่อหลีกเลี่ยงค่าใช้จ่ายที่ไม่คาดคิด เรียกใช้ sky cost-report เพื่อดูต้นทุนของคลัสเตอร์ของคุณ
หากต้องการเข้าสู่ระบบเครื่องคลาวด์ ให้รัน ssh <cluster_name> เช่น ssh llm-tuner
หากคุณได้ติดตั้ง sshfs บนเครื่องของคุณ คุณสามารถเมานต์ระบบไฟล์ของเครื่องคลาวด์บนเครื่องคอมพิวเตอร์ของคุณได้โดยการรันคำสั่งดังต่อไปนี้:
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda create -y python=3.8 -n llm-tuner conda เปิดใช้งาน llm-tuner
pip ติดตั้ง -r ข้อกำหนด lock.txt หลาม app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='Atlantic/Reykjavik' --share
คุณจะเห็น URL ท้องถิ่นและสาธารณะของแอปในเทอร์มินัล เปิด URL ในเบราว์เซอร์ของคุณเพื่อใช้แอป
สำหรับตัวเลือกเพิ่มเติม โปรดดูที่ python app.py --help
หากต้องการทดสอบ UI โดยไม่ต้องโหลดโมเดลภาษา ให้ใช้แฟล็ก --ui_dev_mode :
หลาม app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
หากต้องการใช้ Gradio Auto-Reloading จำเป็นต้องมีไฟล์
config.yamlเนื่องจากไม่รองรับอาร์กิวเมนต์บรรทัดคำสั่ง มีไฟล์ตัวอย่างที่จะเริ่มต้นด้วย:cp config.yaml.sample config.yamlจากนั้นให้รันgradio app.py
ดูวิดีโอบน YouTube
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
-
จะแจ้งภายหลัง


