YAYI UIE
1.0.0

[README] [?HF Repo] [?เวอร์ชันเว็บ]
จีน |. อังกฤษ
[2024.03.28] โมเดลและข้อมูลทั้งหมดถูกอัปโหลดไปยัง Magic Community
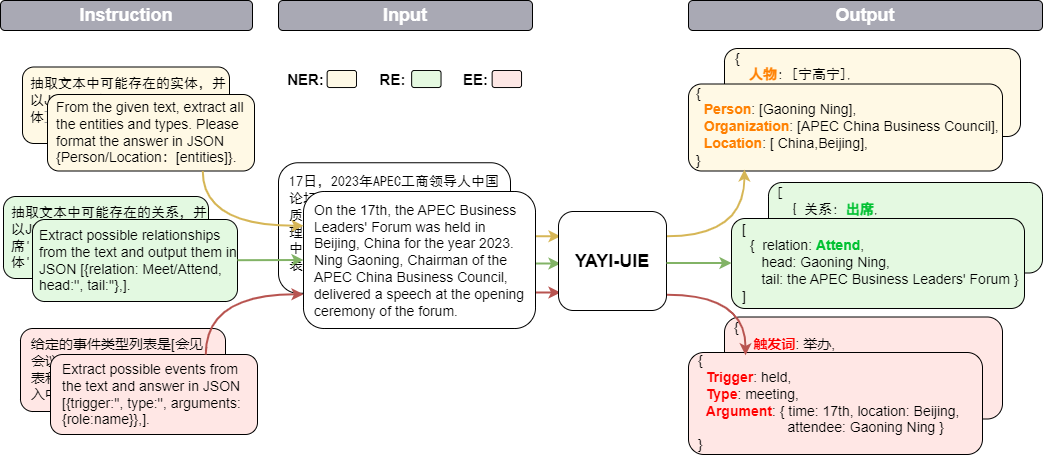
Yayi Information Extraction Unified Large Model (YAYI-UIE) ปรับแต่งคำสั่งอย่างละเอียดเกี่ยวกับข้อมูลการแยกข้อมูลคุณภาพสูงที่สร้างขึ้นด้วยตนเองหลายล้านรายการ งานการแยกข้อมูลการฝึกอบรมแบบรวมศูนย์ประกอบด้วยการจดจำเอนทิตีที่มีชื่อ (NER) การแยกความสัมพันธ์ (RE) และการแยกเหตุการณ์ ( EE) เพื่อให้บรรลุการสกัดแบบมีโครงสร้างโดยทั่วไป ความปลอดภัย การเงิน ชีวภาพ การแพทย์ เชิงพาณิชย์ ส่วนบุคคล ยานพาหนะ ภาพยนตร์ อุตสาหกรรม ร้านอาหาร วิทยาศาสตร์ และสถานการณ์อื่น ๆ
เราจะสนับสนุนการพัฒนาของชุมชนโอเพนซอร์สโมเดลขนาดใหญ่ที่ได้รับการฝึกอบรมล่วงหน้าของจีน เราจะสร้างระบบนิเวศโมเดลขนาดใหญ่ของ Yayi ร่วมกับพันธมิตรทุกรายผ่านโอเพ่นซอร์สของโมเดลขนาดใหญ่ Yayi UIE สำหรับรายละเอียดทางเทคนิคเพิ่มเติม โปรดอ่านรายงานทางเทคนิคของเรา YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction
| ชื่อ | ? การระบุรุ่น HF | ดาวน์โหลดที่อยู่ | โลโก้โมเดลเมจิก | ดาวน์โหลดที่อยู่ |
|---|---|---|---|---|
| YAYI-UIE | wenge-การวิจัย/yayi-uie | ดาวน์โหลดโมเดล | wenge-การวิจัย/yayi-uie | ดาวน์โหลดโมเดล |
| ข้อมูล YAYI-UIE | wenge-การวิจัย/yayi_uie_sft_data | ดาวน์โหลดชุดข้อมูล | wenge-การวิจัย/yayi_uie_sft_data | ดาวน์โหลดชุดข้อมูล |
54% ของคลังข้อมูลระดับล้านเป็นภาษาจีน และ 46% เป็นภาษาอังกฤษ ชุดข้อมูลประกอบด้วย 12 สาขา ได้แก่ การเงิน สังคม ชีววิทยา การพาณิชย์ การผลิตทางอุตสาหกรรม เคมี ยานพาหนะ วิทยาศาสตร์ โรคและการรักษาพยาบาล ชีวิตส่วนตัว ความปลอดภัย และ ทั่วไป. ครอบคลุมหลายร้อยสถานการณ์
git clone https://github.com/wenge-research/yayi-uie.git
cd yayi-uieconda create --name uie python=3.8
conda activate uiepip install -r requirements.txt ไม่แนะนำให้ใช้รุ่น torch และ transformers ให้ต่ำกว่ารุ่นที่แนะนำ
โมเดลนี้เป็นแบบโอเพ่นซอร์สในคลังเก็บโมเดล Huggingface ของเรา และคุณสามารถดาวน์โหลดและใช้งานได้ ต่อไปนี้เป็นโค้ดตัวอย่างที่เรียก YAYI-UIE สำหรับการอนุมานงานดาวน์สตรีม โดยสามารถรันบน GPU ตัวเดียว เช่น A100/A800 โดยจะใช้หน่วยความจำวิดีโอประมาณ 33GB เมื่อใช้การอนุมานที่แม่นยำของ bf16:
> >> import torch
> >> from transformers import AutoModelForCausalLM , AutoTokenizer
> >> from transformers . generation . utils import GenerationConfig
> >> tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi-uie" , use_fast = False , trust_remote_code = True )
> >> model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi-uie" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
> >> generation_config = GenerationConfig . from_pretrained ( "wenge-research/yayi-uie" )
> >> prompt = "文本:氧化锆陶瓷以其卓越的物理和化学特性在多个行业中发挥着关键作用。这种材料因其高强度、高硬度和优异的耐磨性,广泛应用于医疗器械、切削工具、磨具以及高端珠宝制品。在制造这种高性能陶瓷时,必须遵循严格的制造标准,以确保其最终性能。这些标准涵盖了从原材料选择到成品加工的全过程,保障产品的一致性和可靠性。氧化锆的制造过程通常包括粉末合成、成型、烧结和后处理等步骤。原材料通常是高纯度的氧化锆粉末,通过精确控制的烧结工艺,这些粉末被转化成具有特定微观结构的坚硬陶瓷。这种独特的微观结构赋予氧化锆陶瓷其显著的抗断裂韧性和耐腐蚀性。此外,氧化锆陶瓷的热膨胀系数与铁类似,使其在高温应用中展现出良好的热稳定性。因此,氧化锆陶瓷不仅在工业领域,也在日常生活中的应用日益增多,成为现代材料科学中的一个重要分支。 n抽取文本中可能存在的实体,并以json{制造品名称/制造过程/制造材料/工艺参数/应用/生物医学/工程特性:[实体]}格式输出。"
> >> # "<reserved_13>" is a reserved token for human, "<reserved_14>" is a reserved token for assistant
>> > prompt = "<reserved_13>" + prompt + "<reserved_14>"
> >> inputs = tokenizer ( prompt , return_tensors = "pt" ). to ( model . device )
> >> response = model . generate ( ** inputs , max_new_tokens = 512 , temperature = 0 )
> >> print ( tokenizer . decode ( response [ 0 ], skip_special_tokens = True ))บันทึก:
文本:xx
【实体抽取】抽取文本中可能存在的实体,并以json{人物/机构/地点:[实体]}格式输出。
文本:xx
【关系抽取】已知关系列表是[注资,拥有,纠纷,自己,增持,重组,买资,签约,持股,交易]。根据关系列表抽取关系三元组,按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式输出。
文本:xx
抽取文本中可能存在的关系,并以json[{'关系':'会见/出席', '头实体':'', '尾实体':''}, ]格式输出。
文本:xx
已知论元角色列表是[时间,地点,会见主体,会见对象],请根据论元角色列表从给定的输入中抽取可能的论元,以json{角色:论元}格式输出。
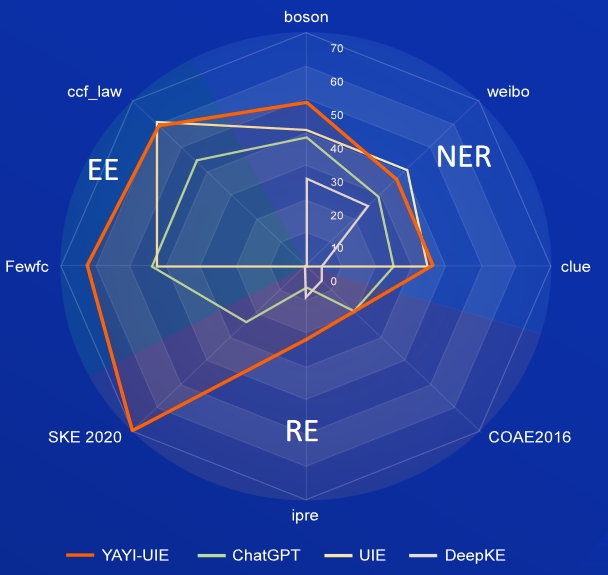
AI วรรณกรรม ดนตรี การเมือง และวิทยาศาสตร์เป็นชุดข้อมูลภาษาอังกฤษ ส่วน boson เบาะแส และ weibo เป็นชุดข้อมูลของจีน
| แบบอย่าง | AI | วรรณกรรม | ดนตรี | การเมือง | ศาสตร์ | ภาษาอังกฤษโดยเฉลี่ย | โบซอน | เบาะแส | เวยป๋อ | ค่าเฉลี่ยของจีน |
|---|---|---|---|---|---|---|---|---|---|---|
| ดาวินชี่ | 2.97 | 9.87 | 13.83 | 18.42 | 10.04 | 11.03 | - | - | - | 31.09 |
| ChatGPT 3.5 | 54.4 | 54.07 | 61.24 | 59.12 | 63 | 58.37 | 38.53 | 25.44 | 29.3 | |
| UIE | 31.14 | 38.97 | 33.91 | 46.28 | 41.56 | 38.37 | 40.64 | 34.91 | 40.79 | 38.78 |
| USM | 28.18 | 56 | 44.93 | 36.1 | 44.09 | 41.86 | - | - | - | - |
| InstructUIE | 49 | 47.21 | 53.16 | 48.15 | 49.3 | 49.36 | - | - | - | - |
| ความรู้LM | 13.76 | 20.18 | 14.78 | 33.86 | 9.19 | 18.35 | 25.96 | 4.44 | 25.2 | 18.53 |
| YAYI-UIE | 52.4 | 45.99 | 51.2 | 51.82 | 50.53 | 50.39 | 49.25 | 36.46 | 36.78 | 40.83 |
FewRe, Wiki-ZSL เป็นชุดข้อมูลภาษาอังกฤษ, SKE 2020, COAE2016, IPRE เป็นชุดข้อมูลภาษาจีน
| แบบอย่าง | ไม่กี่เรล | Wiki-ZSL | ภาษาอังกฤษโดยเฉลี่ย | เอสเคอี 2020 | COAE2016 | ไอพีอาร์ | ค่าเฉลี่ยของจีน |
|---|---|---|---|---|---|---|---|
| ChatGPT 3.5 | 9.96 | 13.14 | 11.55 24.47 | 19.31 | 6.73 | 16.84 | |
| เซตต์(T5-เล็ก) | 30.53 | 31.74 | 31.14 | - | - | - | - |
| ZETT (ฐาน T5) | 33.71 | 31.17 | 32.44 | - | - | - | - |
| InstructUIE | 39.55 | 35.2 | 37.38 | - | - | - | - |
| ความรู้LM | 17.46 | 15.33 | 16.40 | 0.4 | 6.56 | 9.75 | 5.57 |
| YAYI-UIE | 36.09 | 41.07 | 38.58 | 70.8 | 19.97 | 22.97 | 37.91 |
ข่าวสินค้าโภคภัณฑ์เป็นชุดข้อมูลภาษาอังกฤษ FewFC ccf_law คือชุดข้อมูลภาษาจีน
EET (การระบุประเภทเหตุการณ์)
| แบบอย่าง | ข่าวสินค้าโภคภัณฑ์ | ไม่กี่เอฟซี | ccf_law | ค่าเฉลี่ยของจีน |
|---|---|---|---|---|
| ChatGPT 3.5 | 1.41 | 16.15 | 0 | 8.08 |
| UIE | - | 50.23 | 2.16 | 26.20 |
| InstructUIE | 23.26 | - | - | - |
| YAYI-UIE | 12.45 | 81.28 | 12.87 | 47.08 |
EEA (การแยกอาร์กิวเมนต์เหตุการณ์)
| แบบอย่าง | ข่าวสินค้าโภคภัณฑ์ | ไม่กี่เอฟซี | ccf_law | ค่าเฉลี่ยของจีน |
|---|---|---|---|---|
| ChatGPT 3.5 | 8.6 | 44.4 | 44.57 | 44.49 |
| UIE | - | 43.02 | 60.85 | 51.94 |
| สอน UIE | 21.78 | - | - | - |
| YAYI-UIE | 19.74 | 63.06 | 59.42 | 61.24 |
โมเดล SFT ที่ได้รับการฝึกตามข้อมูลปัจจุบันและโมเดลพื้นฐานยังคงมีปัญหาในแง่ของประสิทธิภาพดังต่อไปนี้:
จากข้อจำกัดของโมเดลข้างต้น เรากำหนดให้นักพัฒนาใช้เฉพาะโค้ดโอเพ่นซอร์ส ข้อมูล แบบจำลอง และอนุพันธ์ที่ตามมาซึ่งสร้างโดยโครงการนี้เพื่อวัตถุประสงค์ในการวิจัยเท่านั้น ไม่ใช่เพื่อวัตถุประสงค์ทางการค้าหรือการใช้งานอื่นใดที่จะก่อให้เกิดอันตรายต่อสังคม โปรดใช้ความระมัดระวังในการระบุและใช้เนื้อหาที่สร้างโดย Yayi Big Model และอย่าเผยแพร่เนื้อหาที่เป็นอันตรายที่สร้างขึ้นไปยังอินเทอร์เน็ต หากเกิดผลเสียใดๆ ผู้สื่อสารจะต้องรับผิดชอบ โครงการนี้สามารถใช้เพื่อวัตถุประสงค์ในการวิจัยเท่านั้น และผู้พัฒนาโครงการจะไม่รับผิดชอบต่อความเสียหายหรือความสูญเสียใดๆ ที่เกิดจากการใช้โครงการนี้ (รวมถึงแต่ไม่จำกัดเพียงข้อมูล แบบจำลอง รหัส ฯลฯ) โปรดดูข้อจำกัดความรับผิดชอบสำหรับรายละเอียด
รหัสและข้อมูลในโครงการนี้เป็นโอเพ่นซอร์สตามโปรโตคอล Apache-2.0 เมื่อชุมชนใช้โมเดล YAYI UIE หรืออนุพันธ์ โปรดปฏิบัติตามข้อตกลงชุมชนและข้อตกลงทางการค้าของ Baichuan2
หากคุณใช้แบบจำลองของเราในการทำงาน คุณสามารถอ้างอิงรายงานของเรา:
@article{YAYI-UIE,
author = {Xinglin Xiao, Yijie Wang, Nan Xu, Yuqi Wang, Hanxuan Yang, Minzheng Wang, Yin Luo, Lei Wang, Wenji Mao, Dajun Zeng}},
title = {YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction},
journal = {arXiv preprint arXiv:2312.15548},
url = {https://arxiv.org/abs/2312.15548},
year = {2023}
}


