Dropout NeuralNetworks
1.0.0
ในโครงการวิจัยนี้ ผมจะมุ่งเน้นไปที่ผลกระทบของการเปลี่ยนแปลงอัตราการออกกลางคันในชุดข้อมูล MNIST เป้าหมายของฉันคือการจำลองภาพด้านล่างด้วยข้อมูลที่ใช้ในรายงานการวิจัย วัตถุประสงค์ของโปรเจ็กต์นี้คือเพื่อเรียนรู้วิธีการผลิตฟิกเกอร์แมชชีนเลิร์นนิง โดยเฉพาะการเรียนรู้เกี่ยวกับผลกระทบของข้อผิดพลาดในการจำแนกประเภทเมื่อเปลี่ยนแปลง/ไม่เปลี่ยนความน่าจะเป็นที่ออกจากกลางคัน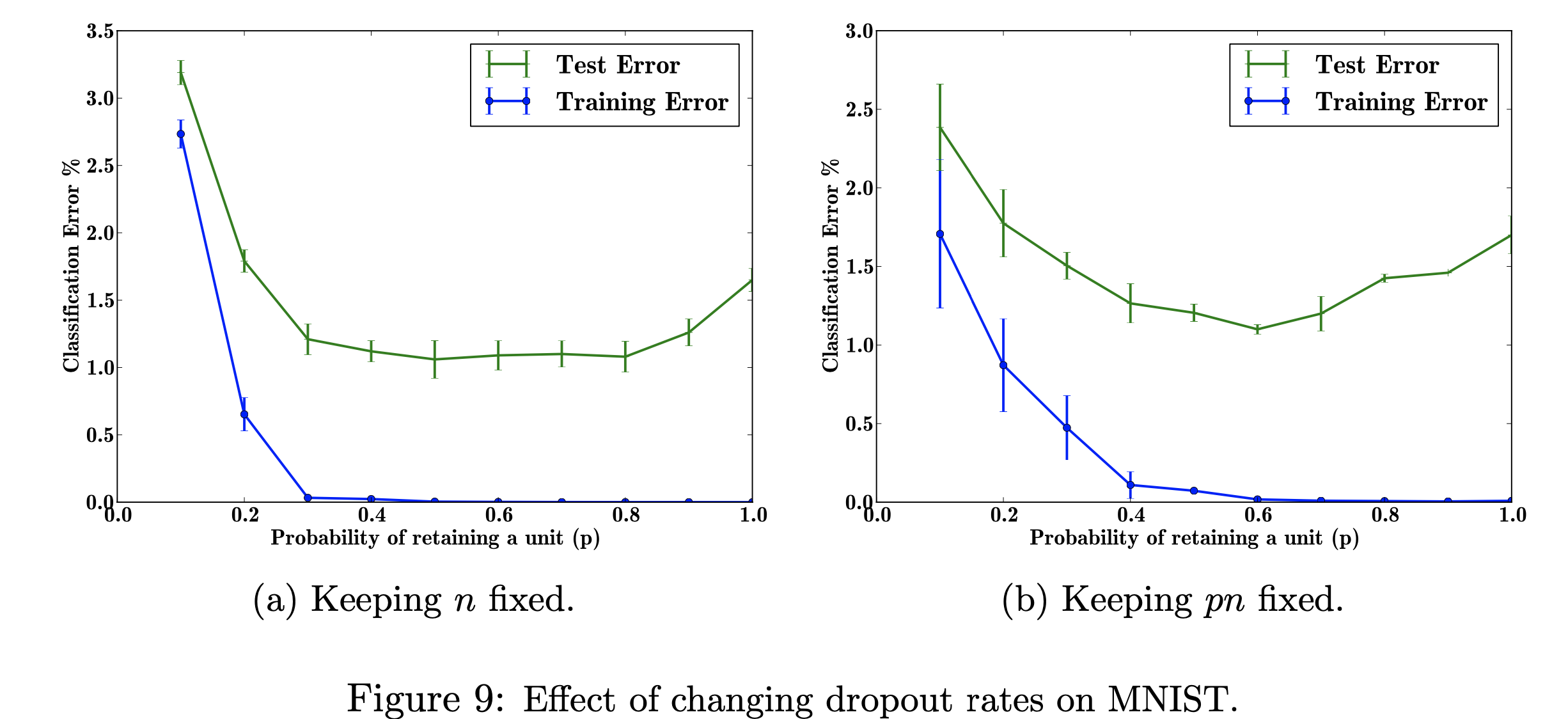 รูปที่อ้างอิงจาก: Srivastava, N., Hinton, G.,Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: วิธีง่ายๆ ในการป้องกัน Neural Networks จากการติดตั้งมากเกินไป รูปที่ 9
รูปที่อ้างอิงจาก: Srivastava, N., Hinton, G.,Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: วิธีง่ายๆ ในการป้องกัน Neural Networks จากการติดตั้งมากเกินไป รูปที่ 9
ฉันใช้ TensorFlow เพื่อเรียกใช้การออกกลางคันบนชุดข้อมูล MNIST, Matplotlib เพื่อช่วยในการสร้างตัวเลขใหม่ในกระดาษ ฉันยังใช้ไลบรารีทศนิยมในตัวเพื่อคำนวณค่าต่างๆ ของ p ตั้งแต่ 0.0 ถึง 1.0 นำเข้าไลบรารี "csv" เพื่อเพิ่มข้อมูลที่รันก่อนหน้านี้ลงในไฟล์ CSV เพื่อประหยัดเวลาในการคำนวณค่า p ที่คำนวณไว้แล้ว Numpy ถูกนำเข้าเพื่อให้การพล็อตมีขนาดขั้นตอนเท่ากันบนแกน x และ y สุดท้ายนี้ ฉันนำเข้า "os" เพื่อจะได้กำจัดข้อผิดพลาดเนื่องจากการใช้ CPU แทนที่จะเป็น GPU
การสำรวจผลกระทบของค่าต่างๆ ของไฮเปอร์พารามิเตอร์ที่ปรับได้ 'p' (ความน่าจะเป็นในการรักษาหน่วยในเครือข่าย) และจำนวนเลเยอร์ที่ซ่อนอยู่ 'n' ที่ส่งผลต่ออัตราข้อผิดพลาด เมื่อผลคูณของ p และ n ได้รับการแก้ไข เราจะเห็นว่าขนาดของข้อผิดพลาดสำหรับค่าเล็กๆ ของ p ลดลง (รูปที่ 9a) เมื่อเทียบกับการรักษาจำนวนเลเยอร์ที่ซ่อนอยู่ให้คงที่ (รูปที่ 9b)
ด้วยข้อมูลการฝึกที่จำกัด ความสัมพันธ์ที่ซับซ้อนมากมายระหว่างอินพุต/เอาท์พุตจะเป็นผลมาจากสัญญาณรบกวนจากการสุ่มตัวอย่าง สิ่งเหล่านี้จะมีอยู่ในชุดการฝึก แต่ไม่ใช่ในข้อมูลการทดสอบจริง แม้ว่าจะดึงมาจากการแจกแจงแบบเดียวกันก็ตาม ภาวะแทรกซ้อนนี้นำไปสู่การฟิตติ้งมากเกินไป นี่เป็นหนึ่งในอัลกอริธึมที่ช่วยป้องกันไม่ให้เกิดขึ้น ข้อมูลเข้าสำหรับตัวเลขนี้เป็นชุดข้อมูลของตัวเลขที่เขียนด้วยลายมือ และผลลัพธ์หลังจากเพิ่มการออกกลางคันเป็นค่าที่แตกต่างกันซึ่งอธิบายผลลัพธ์ของการใช้วิธีการออกกลางคัน โดยรวมแล้ว ข้อผิดพลาดจะน้อยลงหลังจากเพิ่มการออกกลางคัน
ปัญหาในโลกแห่งความเป็นจริงที่สามารถนำไปใช้กับสิ่งนี้ได้คือการค้นหาใน Google บางคนอาจค้นหาชื่อภาพยนตร์ แต่พวกเขาอาจค้นหาเพียงรูปภาพเพราะพวกเขาเป็นผู้เรียนรู้จากภาพมากกว่า ดังนั้นการตัดข้อความออกหรือคำอธิบายสั้นๆ จะช่วยให้คุณมุ่งเน้นไปที่คุณลักษณะของรูปภาพได้ บทความระบุว่าดึงข้อมูลจากที่ใด (http://yann.lecun.com/exdb/mnist/) แต่ละภาพมีขนาด 28x28 หลัก ป้ายกำกับ y ดูเหมือนจะเป็นคอลัมน์ข้อมูลรูปภาพ
เป้าหมายของฉันในการทำซ้ำตัวเลขนี้คือการทดสอบ/ฝึกข้อมูลและคำนวณข้อผิดพลาดในการจำแนกประเภทสำหรับความน่าจะเป็นของ p แต่ละรายการ (ความน่าจะเป็นที่จะคงหน่วยไว้ในเครือข่าย) เป้าหมายของฉันคือการให้ p เพิ่มขึ้นเมื่อข้อผิดพลาดลดลงเพื่อแสดงว่าการใช้งานของฉันถูกต้อง และฉันจะปรับพารามิเตอร์ไฮเปอร์นี้เพื่อให้ได้ผลลัพธ์เดียวกัน ฉันจะทำสิ่งนี้โดยการวนซ้ำข้อมูลการฝึกอบรมและการทดสอบทั้งหมดโดยใช้สถาปัตยกรรม 784-2048-2048-2048-10 และให้ n คงที่ จากนั้นเปลี่ยน pn เป็นการแก้ไข จากนั้นฉันจะรวบรวม/เขียนข้อมูลลงในไฟล์ CSV ไฟล์ csv นี้จะมีข้อมูลที่จำเป็นทั้งหมดเพื่อแสดงตัวเลข ในโปรเจ็กต์นี้ ฉันจะเรียนรู้ว่าอัตราการออกกลางคันจะเป็นประโยชน์ต่อข้อผิดพลาดโดยรวมในโครงข่ายประสาทเทียมได้อย่างไร
คลิกเพื่อดู


