tabled
1.0.0
Tabled เป็นไลบรารีขนาดเล็กสำหรับการตรวจจับและแยกตาราง โดยจะใช้ Surya เพื่อค้นหาตารางทั้งหมดใน PDF ระบุแถว/คอลัมน์ และจัดรูปแบบเซลล์เป็น markdown, csv หรือ html
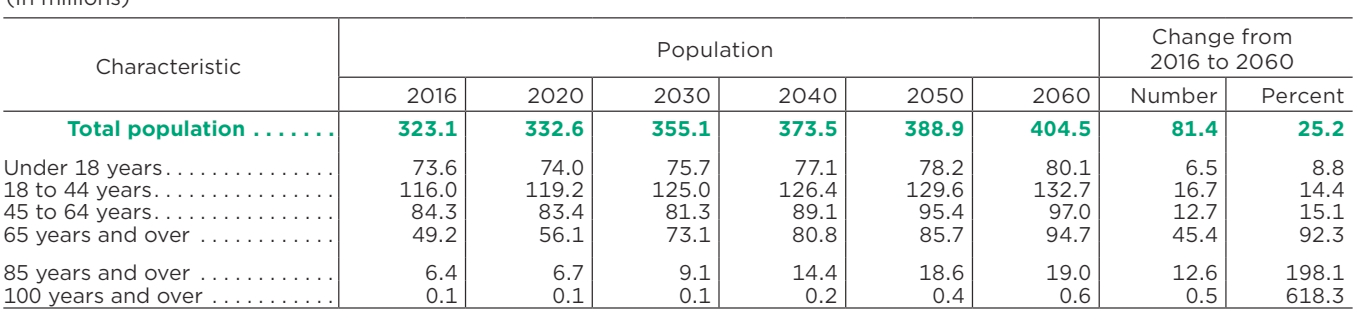
| ลักษณะเฉพาะ | ประชากร | เปลี่ยนจากปี 2016 เป็น 2060 | ||||||
|---|---|---|---|---|---|---|---|---|
| 2559 | 2020 | 2030 | 2040 | 2050 | 2060 | ตัวเลข | เปอร์เซ็นต์ | |
| จำนวนประชากรทั้งหมด | 323.1 | 332.6 | 355.1 | 373.5 | 388.9 | 404.5 | 81.4 | 25.2 |
| อายุต่ำกว่า 18 ปี | 73.6 | 74.0 | 75.7 | 77.1 | 78.2 | 80.1 | 6.5 | 8.8 |
| 18 ถึง 44 ปี | 116.0 | 119.2 | 125.0 | 126.4 | 129.6 | 132.7 | 16.7 | 14.4 |
| 45 ถึง 64 ปี | 84.3 | 83.4 | 81.3 | 89.1 | 95.4 | 97.0 | 12.7 | 15.1 |
| 65 ปีขึ้นไป | 49.2 | 56.1 | 73.1 | 80.8 | 85.7 | 94.7 | 45.4 | 92.3 |
| 85 ปีขึ้นไป | 6.4 | 6.7 | 9.1 | 14.4 | 18.6 | 19.0 | 12.6 | 198.1 |
| 100 ปีขึ้นไป | 0.1 | 0.1 | 0.1 | 0.2 | 0.4 | 0.6 | 0.5 | 618.3 |
Discord คือที่ที่เราหารือเกี่ยวกับการพัฒนาในอนาคต
มีโฮสต์ API สำหรับ tabled ที่นี่:
ใช้งานได้กับ PDF, รูปภาพ, เอกสารคำ และ PowerPoint
ความเร็วที่สม่ำเสมอโดยไม่มีความล่าช้าเพิ่มขึ้น
ความน่าเชื่อถือและเวลาทำงานสูง
ฉันต้องการให้ Table สามารถเข้าถึงได้ในวงกว้างที่สุดเท่าที่จะเป็นไปได้ ในขณะที่ยังคงให้ทุนในการพัฒนา/การฝึกอบรมของฉัน การวิจัยและการใช้งานส่วนบุคคลเป็นเรื่องปกติ แต่มีข้อจำกัดบางประการในการใช้งานเชิงพาณิชย์
น้ำหนักสำหรับโมเดลต่างๆ ได้รับใบอนุญาต cc-by-nc-sa-4.0 แต่ฉันจะยกเว้นไว้สำหรับองค์กรใดๆ ที่มีรายได้รวมต่ำกว่า 5 ล้านเหรียญสหรัฐในช่วง 12 เดือนล่าสุด และต่ำกว่า 5 ล้านเหรียญสหรัฐในการระดมทุนตลอดชีพ VC/angel ที่ยกขึ้น. คุณต้องไม่แข่งขันกับ Datalab API หากคุณต้องการลบข้อกำหนดใบอนุญาต GPL (ใบอนุญาตแบบคู่) และ/หรือใช้น้ำหนักในเชิงพาณิชย์เกินขีดจำกัดรายได้ โปรดดูตัวเลือกที่นี่
คุณจะต้องมี python 3.10+ และ PyTorch คุณอาจต้องติดตั้ง Torch เวอร์ชัน CPU ก่อน หากคุณไม่ได้ใช้ Mac หรือเครื่อง GPU ดูที่นี่สำหรับรายละเอียดเพิ่มเติม
ติดตั้งด้วย:
pip ติดตั้ง tabled-pdf
หลังการติดตั้ง:
ตรวจสอบการตั้งค่าใน tabled/settings.py คุณสามารถแทนที่การตั้งค่าใดๆ ด้วยตัวแปรสภาพแวดล้อมได้
อุปกรณ์คบเพลิงของคุณจะถูกตรวจพบโดยอัตโนมัติ แต่คุณสามารถแทนที่สิ่งนี้ได้ ตัวอย่างเช่น TORCH_DEVICE=cuda
ตุ้มน้ำหนักโมเดลจะดาวน์โหลดโดยอัตโนมัติในครั้งแรกที่คุณเรียกใช้ Table
ทำตาราง DATA_PATH
DATA_PATH อาจเป็นรูปภาพ, pdf หรือโฟลเดอร์ของรูปภาพ/pdf
--format ระบุรูปแบบเอาต์พุตสำหรับแต่ละตาราง ( markdown , html หรือ csv )
--save_json บันทึกข้อมูลแถวและคอลัมน์เพิ่มเติมในไฟล์ json
--save_debug_images บันทึกรูปภาพที่แสดงแถวและคอลัมน์ที่ตรวจพบ
--skip_detection หมายความว่ารูปภาพที่คุณส่งเป็นตารางที่ครอบตัดทั้งหมด และไม่จำเป็นต้องตรวจจับตารางใดๆ
--detect_cell_boxes โดยค่าเริ่มต้น tabled จะพยายามดึงข้อมูลเซลล์ออกจาก pdf หากคุณต้องการให้โมเดลการตรวจจับตรวจพบเซลล์ ให้ระบุสิ่งนี้ (โดยปกติคุณจะต้องการสิ่งนี้เฉพาะกับไฟล์ PDF ที่มีข้อความฝังไม่ถูกต้อง)
--save_images ระบุว่าควรบันทึกรูปภาพของแถว/คอลัมน์และเซลล์ที่ตรวจพบ
หลังจากรันสคริปต์ ไดเร็กทอรีเอาต์พุตจะมีโฟลเดอร์ที่มีชื่อฐานเดียวกันกับชื่อไฟล์อินพุต ภายในโฟลเดอร์เหล่านั้นจะเป็นไฟล์มาร์กดาวน์สำหรับแต่ละตารางในเอกสารต้นฉบับ นอกจากนี้ยังจะมีตัวเลือกรูปภาพของตารางอีกด้วย
จะมีไฟล์ results.json อยู่ในรูทของไดเร็กทอรีเอาต์พุตด้วย ไฟล์นี้จะมีพจนานุกรม json โดยที่คีย์เป็นชื่อไฟล์อินพุตที่ไม่มีนามสกุล แต่ละค่าจะเป็นรายการพจนานุกรม หนึ่งรายการต่อตารางในเอกสาร พจนานุกรมแต่ละตารางประกอบด้วย:
cells - ข้อความและกรอบขอบเขตที่ตรวจพบสำหรับแต่ละเซลล์ตาราง
bbox - bbox ของเซลล์ภายในตาราง bbox
text - ข้อความของเซลล์
row_ids - รหัสของแถวที่มีเซลล์อยู่
col_ids - รหัสของคอลัมน์ที่มีเซลล์นั้นอยู่
order - ลำดับของเซลล์นี้ภายในเซลล์แถว/คอลัมน์ที่กำหนด (เรียงตามแถว ตามด้วยคอลัมน์ แล้วเรียงลำดับ)
rows - bboxes ของแถวที่ตรวจพบ
bbox - bbox ของแถวในรูปแบบ (x1, x2, y1, y2)
row_id - รหัสเฉพาะของแถว
cols - bboxes ของคอลัมน์ที่ตรวจพบ
bbox - bbox ของคอลัมน์ในรูปแบบ (x1, x2, y1, y2)
col_id - รหัสเฉพาะของคอลัมน์
image_bbox - bbox สำหรับรูปภาพในรูปแบบ (x1, y1, x2, y2) (x1, y1) คือมุมซ้ายบน และ (x2, y2) คือมุมขวาล่าง bbox ของตารางสัมพันธ์กับสิ่งนี้
bbox - กรอบขอบเขตของตารางภายใน bbox รูปภาพ
pnum - หมายเลขหน้าภายในเอกสาร
tnum - ดัชนีตารางบนหน้า
ฉันได้รวมแอป streamlit ที่ให้คุณลองทำตารางแบบโต้ตอบกับรูปภาพหรือไฟล์ PDF ได้ เรียกใช้ด้วย:
pip ติดตั้ง streamlit tabled_gui
จาก tabled.extract นำเข้า extract_tablesfrom tabled.fileinput นำเข้า load_pdfs_imagesfrom tabled.inference.models นำเข้า load_detection_models, load_recognition_modelsdet_models, rec_models = load_detection_models(), load_recognition_models()images, highres_images, ชื่อ, text_lines = load_pdfs_images(IN_PATH)page_results = extract_tables (รูปภาพ, highres_images, text_lines, det_models, rec_models)
| คะแนนเฉลี่ย | เวลาต่อโต๊ะ | ตารางทั้งหมด |
|---|---|---|
| 0.847 | 0.029 | 688 |
การรับข้อมูลความจริงภาคพื้นดินที่ดีสำหรับตารางนั้นเป็นเรื่องยาก เนื่องจากคุณถูกจำกัดให้ใช้เลย์เอาต์ที่เรียบง่ายที่สามารถแยกวิเคราะห์และเรนเดอร์ตามหลักการศึกษาได้ หรือคุณต้องใช้ LLM ซึ่งทำให้ผิดพลาดได้ ฉันเลือกใช้การทำนายตาราง GPT-4 เป็นความจริงหลอก
Tabled ได้รับคะแนนการจัดตำแหน่ง .847 เมื่อเปรียบเทียบกับ GPT-4 ซึ่งระบุการจัดตำแหน่งระหว่างข้อความในแถว/เซลล์ของตาราง การจัดแนวที่ไม่ตรงบางส่วนเกิดจากความผิดพลาดของ GPT-4 หรือความไม่สอดคล้องกันเล็กน้อยในสิ่งที่ GPT-4 พิจารณาว่าเป็นเส้นขอบของตาราง โดยทั่วไปคุณภาพการสกัดค่อนข้างสูง
ทำงานบน A10G ที่มีการใช้งาน VRAM 10GB และขนาดแบทช์ 64 ทำตารางใช้เวลา .029 วินาทีต่อตาราง
รันการวัดประสิทธิภาพด้วย:
หลามมาตรฐาน/benchmark.py out.json
ขอขอบคุณ Peter Jansen สำหรับชุดข้อมูลการเปรียบเทียบ และสำหรับการอภิปรายเกี่ยวกับการแยกวิเคราะห์ตาราง
Huggingface สำหรับโค้ดอนุมานและการโฮสต์โมเดล
PyTorch สำหรับการฝึกอบรม/การอนุมาน


