Stable Diffusion เกิดขึ้นได้ด้วยความร่วมมือกับ Stability AI และ Runway และต่อยอดจากงานก่อนหน้านี้ของเรา:
การสังเคราะห์ภาพความละเอียดสูงด้วยแบบจำลองการแพร่กระจายแฝง
โรบิน รอมบัค*, อันเดรียส แบลตต์มันน์*, โดมินิค ลอเรนซ์, แพทริค เอสเซอร์, บียอร์น ออมเมอร์
CVPR '22 ออรัล | GitHub | arXiv | หน้าโครงการ
 Stable Diffusion คือโมเดลการแพร่กระจายข้อความเป็นรูปภาพแฝง ขอขอบคุณการบริจาคประมวลผลอย่างเอื้อเฟื้อจาก Stability AI และการสนับสนุนจาก LAION เราจึงสามารถฝึก Latent Diffusion Model บนรูปภาพขนาด 512x512 จากชุดย่อยของฐานข้อมูล LAION-5B ได้ เช่นเดียวกับ Imagen ของ Google โมเดลนี้ใช้ตัวเข้ารหัสข้อความ CLIP ViT-L/14 แบบแช่แข็งเพื่อกำหนดเงื่อนไขโมเดลบนข้อความแจ้ง ด้วยตัวเข้ารหัส 860M UNet และ 123M โมเดลนี้จึงมีน้ำหนักเบาและทำงานบน GPU ที่มี VRAM อย่างน้อย 10GB ดูส่วนนี้ด้านล่างและการ์ดโมเดล
Stable Diffusion คือโมเดลการแพร่กระจายข้อความเป็นรูปภาพแฝง ขอขอบคุณการบริจาคประมวลผลอย่างเอื้อเฟื้อจาก Stability AI และการสนับสนุนจาก LAION เราจึงสามารถฝึก Latent Diffusion Model บนรูปภาพขนาด 512x512 จากชุดย่อยของฐานข้อมูล LAION-5B ได้ เช่นเดียวกับ Imagen ของ Google โมเดลนี้ใช้ตัวเข้ารหัสข้อความ CLIP ViT-L/14 แบบแช่แข็งเพื่อกำหนดเงื่อนไขโมเดลบนข้อความแจ้ง ด้วยตัวเข้ารหัส 860M UNet และ 123M โมเดลนี้จึงมีน้ำหนักเบาและทำงานบน GPU ที่มี VRAM อย่างน้อย 10GB ดูส่วนนี้ด้านล่างและการ์ดโมเดล
สภาพแวดล้อม conda ที่เหมาะสมชื่อ ldm สามารถสร้างและเปิดใช้งานได้ด้วย:
conda env create -f environment.yaml
conda activate ldm
คุณยังสามารถอัปเดตสภาพแวดล้อมการแพร่กระจายแฝงที่มีอยู่ได้โดยการเรียกใช้
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 หมายถึงการกำหนดค่าเฉพาะของสถาปัตยกรรมโมเดลที่ใช้ตัวเข้ารหัสอัตโนมัติ downsampling-factor 8 พร้อมด้วยตัวเข้ารหัสข้อความ 860M UNet และ CLIP ViT-L/14 สำหรับโมเดลการแพร่กระจาย แบบจำลองนี้ได้รับการฝึกล่วงหน้ากับรูปภาพขนาด 256x256 จากนั้นจึงปรับแต่งรูปภาพขนาด 512x512
หมายเหตุ: Stable Diffusion v1 เป็นแบบจำลองการแพร่กระจายข้อความเป็นรูปภาพทั่วไป ดังนั้นจึงสะท้อนอคติและแนวความคิด (ผิด) ที่มีอยู่ในข้อมูลการฝึก รายละเอียดเกี่ยวกับขั้นตอนและข้อมูลการฝึกอบรม รวมถึงวัตถุประสงค์การใช้งานแบบจำลองสามารถดูได้ในการ์ดโมเดลที่เกี่ยวข้อง
ตุ้มน้ำหนักมีจำหน่ายผ่านองค์กร CompVis ที่ Hugging Face ภายใต้ใบอนุญาตซึ่งมีข้อจำกัดตามการใช้งานเฉพาะ เพื่อป้องกันการใช้ในทางที่ผิดและอันตรายตามที่แจ้งไว้ในการ์ดรุ่น แต่อย่างอื่นยังคงได้รับอนุญาต แม้ว่าการใช้งานเชิงพาณิชย์จะได้รับอนุญาตภายใต้เงื่อนไขของใบอนุญาต เราไม่แนะนำให้ใช้น้ำหนักที่ให้ไว้สำหรับบริการหรือผลิตภัณฑ์โดยไม่มีกลไกและข้อพิจารณาด้านความปลอดภัยเพิ่มเติม เนื่องจากมีข้อจำกัดและความลำเอียงของน้ำหนักที่ทราบอยู่แล้ว และการวิจัยเกี่ยวกับการปรับใช้อย่างปลอดภัยและมีจริยธรรม โมเดลข้อความเป็นรูปภาพทั่วไปเป็นความพยายามอย่างต่อเนื่อง ตุ้มน้ำหนักเป็นสิ่งประดิษฐ์ในการวิจัยและควรได้รับการปฏิบัติเช่นนี้
ใบอนุญาต CreativeML OpenRAIL M เป็นใบอนุญาต Open RAIL M ซึ่งดัดแปลงมาจากงานที่ BigScience และ RAIL Initiative ร่วมกันดำเนินการในด้านการออกใบอนุญาต AI ที่มีความรับผิดชอบ โปรดดูบทความเกี่ยวกับใบอนุญาต BLOOM Open RAIL ซึ่งเป็นใบอนุญาตของเรา
ขณะนี้เรามีจุดตรวจดังต่อไปนี้:
sd-v1-1.ckpt : 237k ขั้นตอนที่ความละเอียด 256x256 บน laion2B-en 194,000 ขั้นที่ความละเอียด 512x512 บน laion ความละเอียดสูง (ตัวอย่าง 170 ล้านตัวอย่างจาก LAION-5B ที่มีความละเอียด >= 1024x1024 )sd-v1-2.ckpt : ดำเนินการต่อจาก sd-v1-1.ckpt 515,000 ขั้นตอนที่ความละเอียด 512x512 บน laion-aesthetics v2 5+ (ชุดย่อยของ laion2B-en ที่มีคะแนนสุนทรียภาพโดยประมาณ > 5.0 และกรองเพิ่มเติมเป็นรูปภาพที่มีขนาดดั้งเดิม >= 512x512 และความน่าจะเป็นของลายน้ำโดยประมาณ < 0.5 มาจากข้อมูลเมตา LAION-5B คะแนนความสวยงามประเมินโดยใช้ LAION-Aesthetics ผู้ทำนาย V2)sd-v1-3.ckpt : ดำเนินการต่อจาก sd-v1-2.ckpt 195,000 ขั้นตอนที่ความละเอียด 512x512 ใน "laion-aesthetics v2 5+" และการลดการปรับสภาพข้อความลง 10% เพื่อปรับปรุงการสุ่มตัวอย่างคำแนะนำแบบไม่มีตัวแยกประเภทsd-v1-4.ckpt : ดำเนินการต่อจาก sd-v1-2.ckpt 225,000 ขั้นตอนที่ความละเอียด 512x512 ใน "laion-aesthetics v2 5+" และการลดการปรับสภาพข้อความ 10% เพื่อปรับปรุงการสุ่มตัวอย่างคำแนะนำแบบไม่มีตัวแยกประเภท การประเมินด้วยมาตราส่วนการสุ่มตัวอย่างแบบไม่มีตัวแยกประเภทที่แตกต่างกัน (1.5, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) และขั้นตอนการสุ่มตัวอย่าง 50 PLMS แสดงให้เห็นการปรับปรุงสัมพัทธ์ของจุดตรวจ: 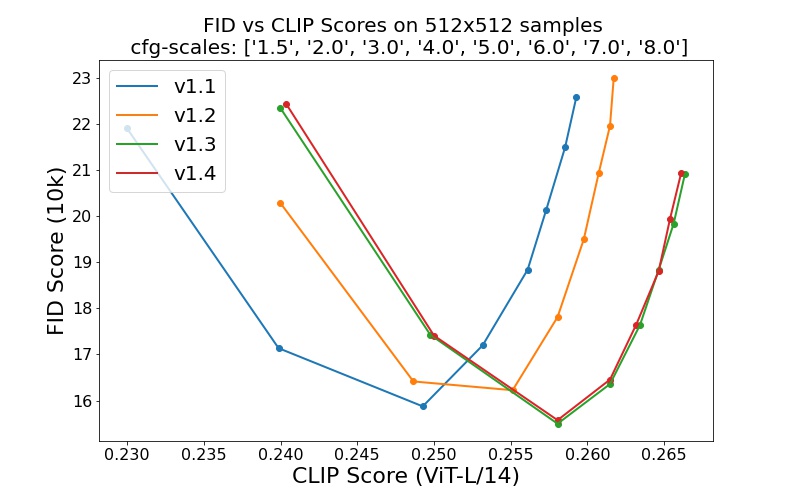


Stable Diffusion คือโมเดลการแพร่กระจายแฝงซึ่งมีเงื่อนไขในการฝังข้อความ (ไม่รวมกลุ่ม) ของตัวเข้ารหัสข้อความ CLIP ViT-L/14 เราจัดเตรียมสคริปต์อ้างอิงสำหรับการสุ่มตัวอย่าง แต่ก็มีการบูรณาการตัวกระจายอยู่ด้วย ซึ่งเราคาดว่าจะเห็นการพัฒนาชุมชนที่กระตือรือร้นมากขึ้น
เรามีสคริปต์การสุ่มตัวอย่างอ้างอิงซึ่งประกอบด้วย
หลังจากได้รับตุ้มน้ำหนัก stable-diffusion-v1-*-original แล้ว ให้เชื่อมโยงพวกมัน
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
และตัวอย่างด้วย
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
ตามค่าเริ่มต้น สิ่งนี้จะใช้มาตราส่วนการนำทาง --scale 7.5 ซึ่งเป็นการนำตัวอย่าง PLMS ของ Katherine Crowson ไปใช้ และเรนเดอร์รูปภาพขนาด 512x512 (ซึ่งได้รับการฝึกฝน) ใน 50 ขั้นตอน อาร์กิวเมนต์ที่รองรับทั้งหมดแสดงอยู่ด้านล่าง (ประเภท python scripts/txt2img.py --help )
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
หมายเหตุ: การกำหนดค่าการอนุมานสำหรับเวอร์ชัน v1 ทั้งหมดได้รับการออกแบบมาให้ใช้กับจุดตรวจสอบ EMA เท่านั้น ด้วยเหตุนี้ use_ema=False จึงถูกตั้งค่าไว้ในการกำหนดค่า ไม่เช่นนั้นโค้ดจะพยายามเปลี่ยนจากน้ำหนักที่ไม่ใช่ EMA เป็น EMA หากคุณต้องการตรวจสอบผลกระทบของ EMA เทียบกับไม่มี EMA เรามีจุดตรวจสอบ "เต็ม" ซึ่งประกอบด้วยน้ำหนักทั้งสองประเภท สำหรับสิ่งเหล่านี้ use_ema=False จะโหลดและใช้น้ำหนักที่ไม่ใช่ EMA
วิธีง่ายๆ ในการดาวน์โหลดและตัวอย่าง Stable Diffusion คือการใช้ไลบรารีตัวกระจาย:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )ด้วยการใช้กลไกการลดสัญญาณรบกวนการแพร่กระจายตามที่เสนอครั้งแรกโดย SDEdit โมเดลนี้สามารถใช้กับงานที่แตกต่างกันได้ เช่น การแปลรูปภาพเป็นรูปภาพพร้อมข้อความนำทางและการลดขนาด เช่นเดียวกับสคริปต์สุ่มตัวอย่าง txt2img เรามีสคริปต์สำหรับแก้ไขรูปภาพด้วย Stable Diffusion
ข้อมูลต่อไปนี้จะอธิบายตัวอย่างที่ภาพร่างคร่าวๆ ที่ทำใน Pinta ถูกแปลงเป็นงานศิลปะที่มีรายละเอียด
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
ในที่นี้ ความแรงคือค่าระหว่าง 0.0 ถึง 1.0 ซึ่งควบคุมปริมาณสัญญาณรบกวนที่เพิ่มให้กับภาพที่นำเข้า ค่าที่เข้าใกล้ 1.0 ทำให้เกิดการเปลี่ยนแปลงได้มากมาย แต่ยังจะสร้างภาพที่ไม่สอดคล้องกับความหมายทางความหมายด้วย ดูตัวอย่างต่อไปนี้
ป้อนข้อมูล

เอาท์พุต


ตัวอย่างเช่น ขั้นตอนนี้สามารถใช้ในการยกระดับตัวอย่างจากแบบจำลองพื้นฐานได้เช่นกัน
โค้ดเบสของเราสำหรับโมเดลการแพร่กระจายนั้นสร้างขึ้นอย่างมากบนโค้ดเบส ADM ของ OpenAI และ https://github.com/lucidrains/denoising-diffusion-pytorch ขอบคุณสำหรับโอเพ่นซอร์ส!
การใช้งานตัวเข้ารหัสหม้อแปลงนั้นมาจาก x-transformers โดย lucidrains
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


