eye in the sky
1.0.0
การจำแนกภาพดาวเทียม, InterIIT Techmeet 2018, IIT Bombay
ทีม: Manideep Kolla, Aniket Mandle, Apoorva Kumar
พื้นที่เก็บข้อมูลนี้มีการใช้งานอัลกอริธึมสองตัว ได้แก่ U-Net: Convolutional Networks for Biomedical Image Segmentation และ Pyramid Scene Parsing Network ที่ได้รับการแก้ไขสำหรับปัญหาการจำแนกภาพดาวเทียม
main_unet.py : รหัส Python สำหรับฝึกอัลกอริทึมด้วยสถาปัตยกรรม U-Net รวมถึงการเข้ารหัสความจริงภาคพื้นดินunet.py : ประกอบด้วยการใช้งานเลเยอร์ U-Net ของเราtest_unet.py : รหัสสำหรับการทดสอบ การคำนวณความแม่นยำ การคำนวณเมทริกซ์ความสับสนสำหรับการฝึกอบรมและการตรวจสอบ และบันทึกการคาดการณ์โดยแบบจำลอง U-Net ในการฝึกอบรม การตรวจสอบ และการทดสอบรูปภาพInter-IIT-CSRE : ประกอบด้วยข้อมูลการฝึกอบรมและการทดสอบโฆษณาเพื่อการตรวจสอบความถูกต้องทั้งหมดComparison_Test.pdf : การเปรียบเทียบข้อมูลการทดสอบแบบเคียงข้างกันกับการคาดการณ์แบบจำลอง U-Net บนข้อมูลtrain_predictions : การคาดการณ์โมเดล U-Net เกี่ยวกับรูปภาพการฝึกอบรมและการตรวจสอบความถูกต้องplots : แผนความแม่นยำและการสูญเสียสำหรับการฝึกอบรมและการตรวจสอบความถูกต้องสำหรับสถาปัตยกรรม U-NetTest_images , Test_outputs : มีรูปภาพทดสอบและการคาดคะเนของโมเดล U-Netclass_masks , compare_pred_to_gt , images_for_doc : มีหลายภาพสำหรับเอกสารประกอบPSPNet : มีไฟล์การฝึกอบรมสำหรับการใช้งานอัลกอริธึม PSPNet ในการจัดหมวดหมู่ภาพดาวเทียม โคลนพื้นที่เก็บข้อมูล เปลี่ยนไดเร็กทอรีการทำงานปัจจุบันของคุณเป็นไดเร็กทอรีที่โคลน สร้างโฟลเดอร์ที่มีชื่อ train_predictions และ test_outputs เพื่อบันทึกผลลัพธ์ที่คาดการณ์ของโมเดลในอิมเมจการฝึกอบรมและการทดสอบ (ไม่จำเป็นในขณะนี้เนื่องจาก repo มีโฟลเดอร์เหล่านี้อยู่แล้ว)
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
สำหรับการฝึกโมเดล U-Net และประหยัดน้ำหนัก ให้รันคำสั่งด้านล่าง
$ python3 main_unet.py
เพื่อทดสอบแบบจำลอง U-Net คำนวณความแม่นยำ คำนวณเมทริกซ์ความสับสนสำหรับการฝึกอบรมและการตรวจสอบ และบันทึกการคาดการณ์โดยแบบจำลองในการฝึกอบรม การตรวจสอบ และการทดสอบภาพ
$ python3 test_unet.py
คุณอาจได้รับข้อผิดพลาด xrange is not defined ในขณะที่รันโค้ดของเรา ข้อผิดพลาดนี้ไม่ได้เกิดจากข้อผิดพลาดในโค้ดของเรา แต่เนื่องจากแพ็คเกจ python ที่ชื่อ libtiff ไม่ทันสมัย (บางส่วนของซอร์สโค้ดของแพ็คเกจอยู่ใน python2 และบางส่วนอยู่ใน python3) ซึ่งเราใช้เพื่ออ่านชุดข้อมูลซึ่งใน รูปภาพอยู่ในรูปแบบ .tif เราไม่สามารถใช้ไลบรารีอื่น เช่น openCV หรือ PIL เพื่ออ่านรูปภาพได้ เนื่องจากไลบรารีเหล่านี้ไม่รองรับการอ่านรูปภาพ .tif แบบ 4 แชนเนลอย่างเหมาะสม
ข้อผิดพลาดนี้สามารถแก้ไขได้โดยการแก้ไขซอร์สโค้ดของไลบรารี libtiff
ไปที่ไฟล์ในซอร์สโค้ดของไลบรารีที่เกิดข้อผิดพลาด (ชื่อไฟล์จะปรากฏในเทอร์มินัลเมื่อมีการแสดงข้อผิดพลาด) และแทนที่ฟังก์ชัน xrange() (python2) ทั้งหมดในไฟล์เป็น range() (หลาม3)
เรามีตุ้มน้ำหนักที่ผ่านการฝึกอย่างดีพอสมควรที่นี่ เพื่อให้ผู้ใช้ไม่ต้องฝึกตั้งแต่เริ่มต้น
| คำอธิบาย | งาน | ชุดข้อมูล | แบบอย่าง |
|---|---|---|---|
| สถาปัตยกรรม UNet | การจำแนกภาพดาวเทียม | ชุดข้อมูล IITB (อ้างอิงโฟลเดอร์ Inter-IIT-CSRE ) | ดาวน์โหลด (.h5) |
หากต้องการใช้ตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้า ให้เปลี่ยนชื่อไฟล์ .h5 (ไฟล์ตุ้มน้ำหนัก) ที่กล่าวถึงใน test_unet.py เพื่อให้ตรงกับชื่อไฟล์ตุ้มน้ำหนักที่คุณดาวน์โหลดไว้ในตำแหน่งที่จำเป็น
ตอนนี้เรามาหารือกัน
1. โครงการนี้เกี่ยวกับอะไร
2. สถาปัตยกรรมที่เราใช้และทดลองด้วยและ
3. กลยุทธ์การฝึกอบรมใหม่ๆ ที่เราใช้ในโครงการ
การสำรวจระยะไกลเป็นศาสตร์แห่งการรับข้อมูลเกี่ยวกับวัตถุหรือพื้นที่จากระยะไกล โดยทั่วไปจากเครื่องบินหรือดาวเทียม
เราตระหนักถึงปัญหาการจัดหมวดหมู่ภาพดาวเทียมว่าเป็นปัญหาการแบ่งส่วนความหมาย และสร้างอัลกอริธึมการแบ่งส่วนความหมายในการเรียนรู้เชิงลึกเพื่อแก้ไขปัญหานี้
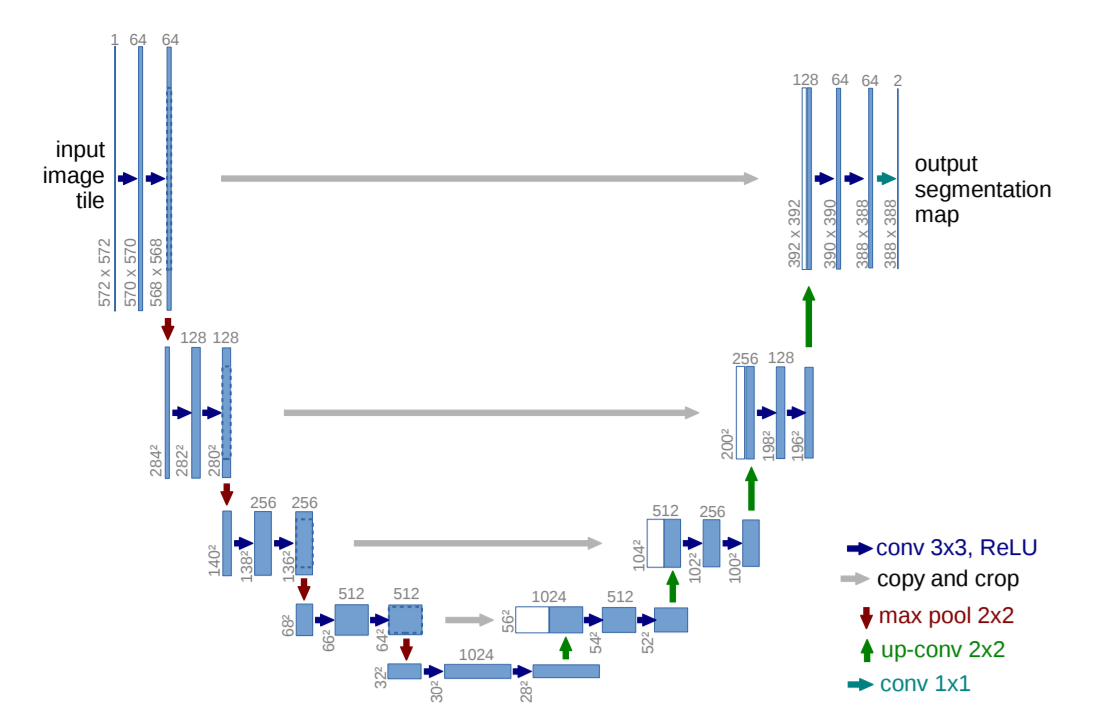
U-Net: เครือข่ายแบบ Convolutional สำหรับการแบ่งส่วนภาพทางชีวการแพทย์
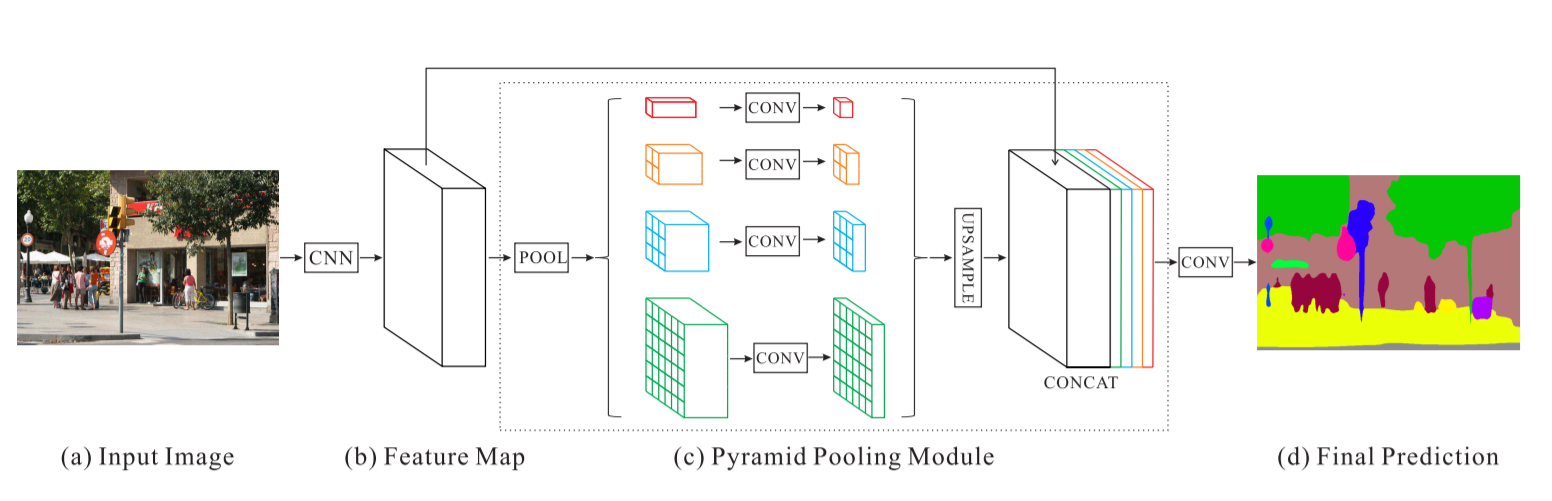
เครือข่ายการแยกวิเคราะห์ฉากพีระมิด - PSPNet
ความจริงภาคพื้นดินที่ให้ไว้คือภาพ RGB 3 แชนเนล ในชุดข้อมูลปัจจุบัน มีค่า RGB ที่ไม่ซ้ำกันเพียง 9 ค่าในความจริงภาคพื้นดิน เนื่องจากมี 9 คลาสที่ต้องถูกจัดประเภท ค่า RGB ที่แตกต่างกัน 9 ค่าเหล่านี้ได้รับการเข้ารหัสแบบร้อนแรงเพื่อสร้างความจริงภาคพื้นดินที่เข้ารหัส 9 แชนเนล โดยแต่ละแชนเนลเป็นตัวแทนของคลาสเฉพาะ
ด้านล่างนี้เป็นรูปแบบการเข้ารหัส
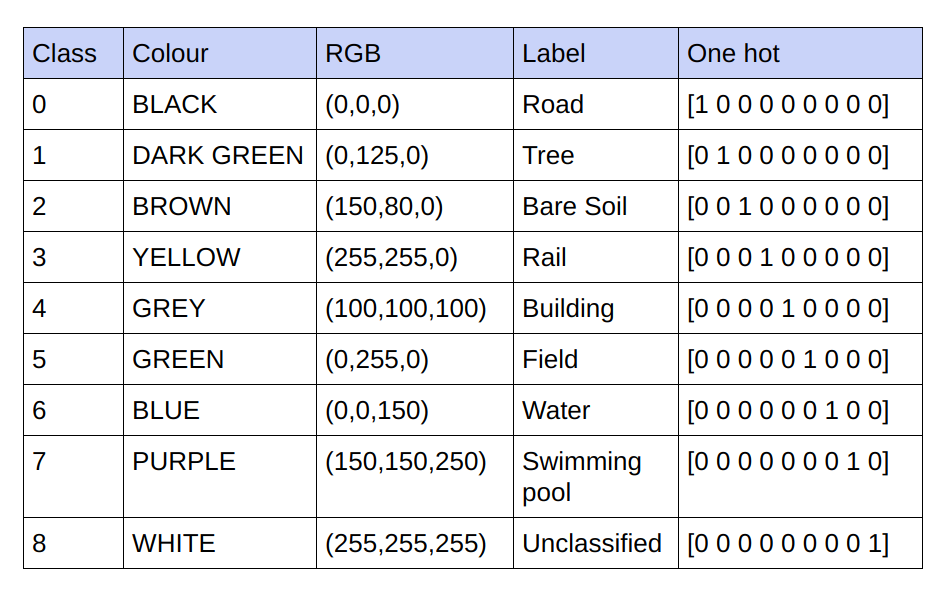
การรับรู้ของแต่ละช่องทางในความจริงพื้นดินที่เข้ารหัสเป็นชั้นเรียน

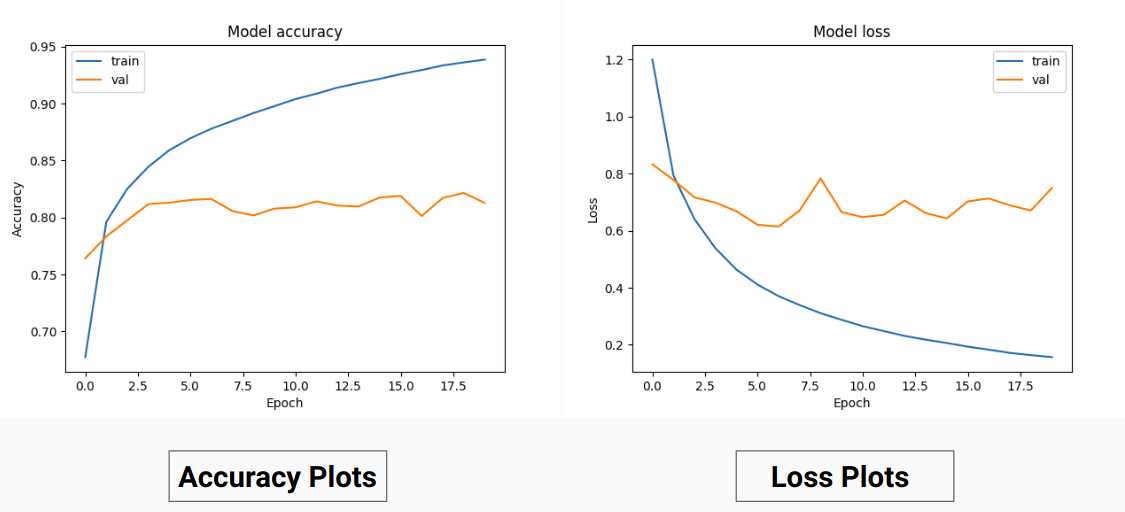
ดังนั้นแทนที่จะฝึกฝนค่า RGB ของความจริงภาคพื้นดิน เราได้แปลงพวกมันให้เป็นค่าที่ร้อนแรงของคลาสต่างๆ วิธีการนี้ทำให้เราได้รับความแม่นยำในการตรวจสอบความถูกต้อง 85% และความแม่นยำในการฝึกอบรม 92% เมื่อเทียบกับความแม่นยำในการตรวจสอบความถูกต้อง 71% และความแม่นยำในการฝึกอบรม 65% เมื่อเราใช้ค่าความจริงภาคพื้นดิน RGB สำหรับการฝึกอบรม
นี่อาจเป็นเพราะความแปรปรวนและค่าเฉลี่ยของความจริงพื้นฐานที่ลดลงของข้อมูลการฝึกอบรม เนื่องจากข้อมูลดังกล่าวทำหน้าที่เป็นเทคนิคการทำให้เป็นมาตรฐานที่มีประสิทธิผล ประสิทธิภาพที่ดีขึ้นของเทคนิคการฝึกอบรมนี้เป็นเพราะโมเดลให้เอาต์พุตด้วยแผนที่คุณลักษณะ 9 รายการ แต่ละแผนที่ระบุคลาส กล่าวคือ เทคนิคการฝึกอบรมนี้ทำหน้าที่เหมือนกับว่าโมเดลได้รับการฝึกฝนในแต่ละคลาสจาก 9 คลาสแยกกันในระดับหนึ่ง ( แต่ที่นี่การทำนายช่องหนึ่งซึ่งสอดคล้องกับคลาสใดคลาสหนึ่งนั้นขึ้นอยู่กับช่องอื่นอย่างแน่นอน)
ผลลัพธ์ของเราเกี่ยวกับ PSPNet สำหรับการจัดหมวดหมู่ภาพดาวเทียม:
ความแม่นยำในการฝึกอบรม - 49% ความแม่นยำในการตรวจสอบ - 60%
เหตุผล:
ยู-เน็ต:
แก้ไข U-Net:
สำหรับการฝึกอบรมและการตรวจสอบความถูกต้อง เราได้ใช้อิมเมจ '.tif' จำนวน 14 รูปในโฟลเดอร์ Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset
สำหรับการฝึกอบรม เราได้ใช้รูปภาพ 13 ภาพแรกในชุดข้อมูล และสำหรับการตรวจสอบความถูกต้อง เราใช้รูปภาพที่ 14
ภาพดาวเทียมแต่ละภาพในโฟลเดอร์ sat มี 4 ช่อง ได้แก่ R (แบนด์ 1), G (แบนด์ 2), B (แบนด์ 3) และ NIR (แบนด์ 4)
รูปภาพความจริงภาคพื้นดินในไดเร็กทอรี gt เป็นภาพ RGB และพรรณนาถึง 8 คลาส ได้แก่ ถนน อาคาร ต้นไม้ หญ้า ดินเปล่า น้ำ ทางรถไฟ และสระว่ายน้ำ
เหตุผลที่เราพิจารณาเพียงรูปภาพเดียว (ภาพที่ 14) เป็นชุดการตรวจสอบความถูกต้อง เนื่องจากเป็นรูปภาพที่เล็กที่สุดในชุดข้อมูล และเราไม่ต้องการทิ้งข้อมูลไว้น้อยลงสำหรับการฝึกอบรม เนื่องจากชุดข้อมูลมีขนาดค่อนข้างเล็ก ชุดตรวจสอบความถูกต้อง (ภาพที่ 14) ที่เราพิจารณาไม่มี 3 คลาส (ดินเปล่า ราง และแบบสำรวจ Swimmimg) ซึ่งมีความแม่นยำในการฝึกค่อนข้างสูง ความแม่นยำในการตรวจสอบความถูกต้องจะดีกว่าถ้าเราพิจารณารูปภาพที่มีคลาสทั้งหมดอยู่ในนั้น (ไม่มีรูปภาพในชุดข้อมูลที่มีคลาสทั้งหมด มีอย่างน้อยหนึ่งคลาสที่ขาดหายไปในภาพทั้งหมด)
การครอบตัดแบบ Strided:
เพื่อให้มีข้อมูลการฝึกอบรมที่เพียงพอจากการครอบตัดรูปภาพที่มีความคมชัดสูงที่กำหนด จำเป็นต้องฝึกตัวแยกประเภทซึ่งมีพารามิเตอร์ประมาณ 31M ของการใช้งาน U-Net ของเรา ขนาดการครอบตัดที่ 64x64 เราพบว่ามีการนำเสนอน้อยกว่าความเป็นจริงของแต่ละคลาส และเรขาคณิตและความต่อเนื่องของวัตถุก็หายไป ส่งผลให้ขอบเขตการมองเห็นของการบิดเบี้ยวลดลง
การใช้หน้าต่างการครอบตัดขนาด 128x128 พิกเซลพร้อมผลลัพธ์ 32 ขั้นตอนจาก 15887 การฝึก 414 รูปภาพการตรวจสอบ
ขนาดภาพ:
ก่อนการครอบตัด ขนาดของภาพการฝึกจะถูกแปลงเป็นก้าวทวีคูณเพื่อความสะดวกในระหว่างการครอบตัดแบบก้าว
สำหรับกรณีที่ไม่มี ของการครอบตัดไม่ใช่ขนาดภาพหลายเท่าที่เราลองใช้การเติมช่องว่างเป็นศูนย์ เราพบว่าการเพิ่มการเติมจะเพิ่มสิ่งที่ไม่ต้องการในรูปแบบของพิกเซลสีดำในการฝึกและทดสอบภาพที่นำไปสู่การฝึกเกี่ยวกับข้อมูลเท็จและขอบเขตของรูปภาพ
หรืออีกทางหนึ่ง เราได้เปลี่ยนขนาดภาพอย่างถูกต้องโดยการเพิ่มพิกเซลพิเศษที่ด้านขวาสุดและด้านล่างของภาพ ดังนั้นเราจึงเพิ่มความแตกต่างจากส่วนซ้ายส่วนใหญ่ของภาพไปยังจุดสิ้นสุดด้านขวา และด้านบนและด้านล่างของภาพในทำนองเดียวกัน
ตัวอย่างการฝึกอบรม 1: รูปภาพ '2.tif' จากข้อมูลการฝึกอบรม
ตัวอย่างการฝึกอบรม 2: รูปภาพ '4.tif' จากข้อมูลการฝึกอบรม
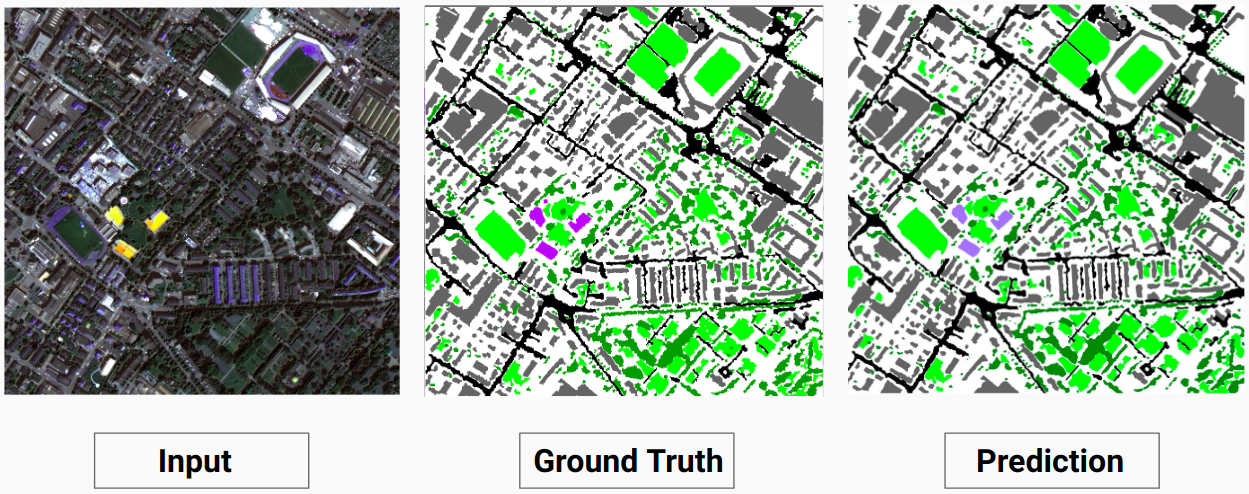
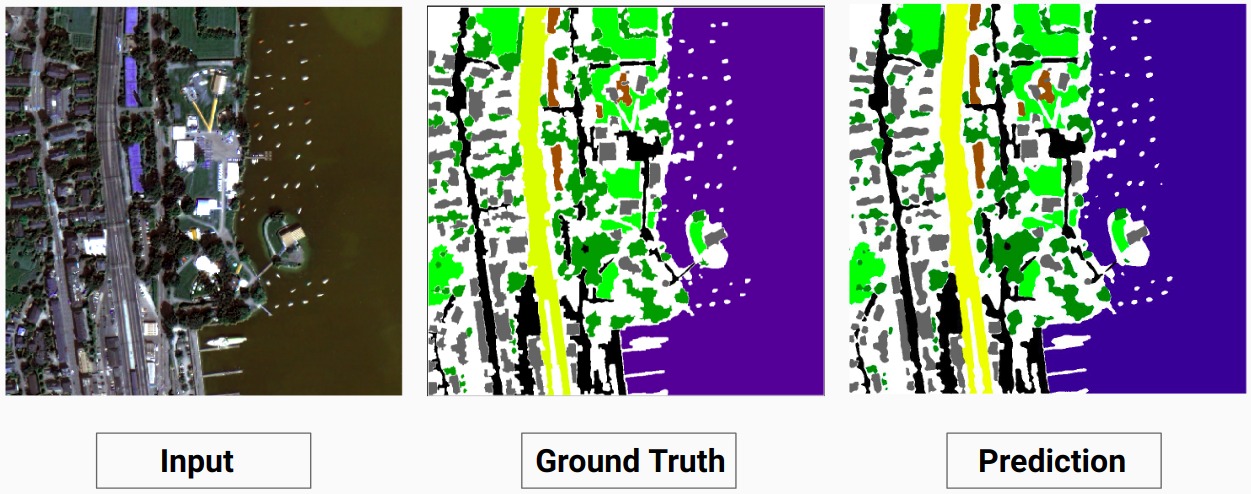
ตัวอย่างการตรวจสอบ: รูปภาพ '14.tif' จากชุดข้อมูล

แบบจำลองของเราสามารถทำนายคลาสบางคลาสที่นักอธิบายประกอบที่เป็นมนุษย์ไม่สามารถทำได้ คลาสที่ไม่สามารถระบุตัวตนได้ในภาพจะถูกระบุว่าเป็นพิกเซลสีขาวโดยผู้อธิบายประกอบที่เป็นมนุษย์ แบบจำลองของเราสามารถทำนายพิกเซลสีขาวเหล่านี้บางส่วนได้อย่างถูกต้องเหมือนกับคลาสบางคลาส แต่สิ่งนี้ทำให้ความแม่นยำโดยรวมลดลง เนื่องจากพิกเซลสีขาวนั้นถือเป็นคลาสที่แยกจากกันตามโมเดล
ในที่นี้แบบจำลองสามารถทำนายพิกเซลสีขาวเป็นสิ่งปลูกสร้างได้ถูกต้องและมองเห็นได้ชัดเจนในภาพอินพุต
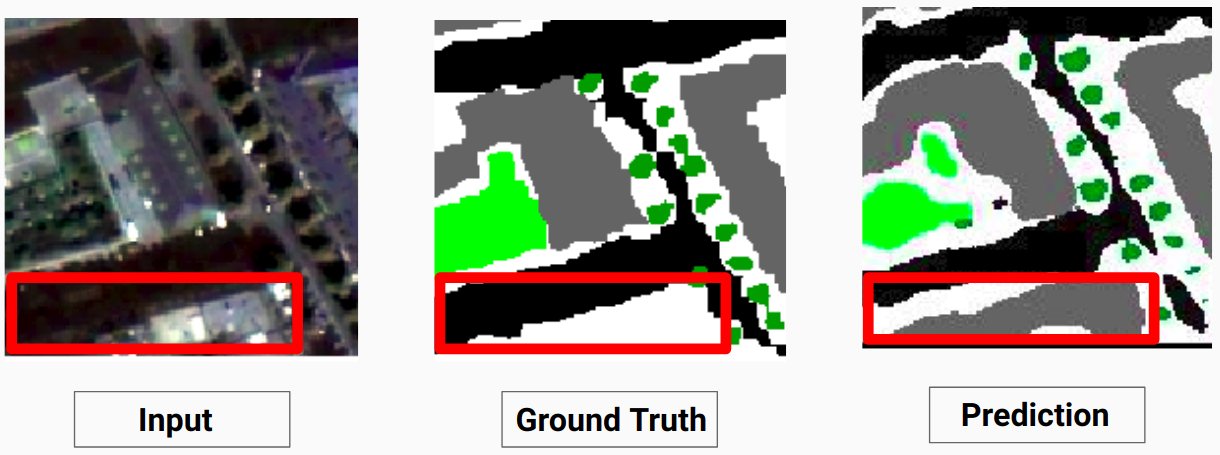
ตรวจสอบ Comparison_Test.pdf เพื่อเปรียบเทียบระหว่างภาพทดสอบกับผลลัพธ์ที่คาดการณ์ไว้ตามแบบจำลอง
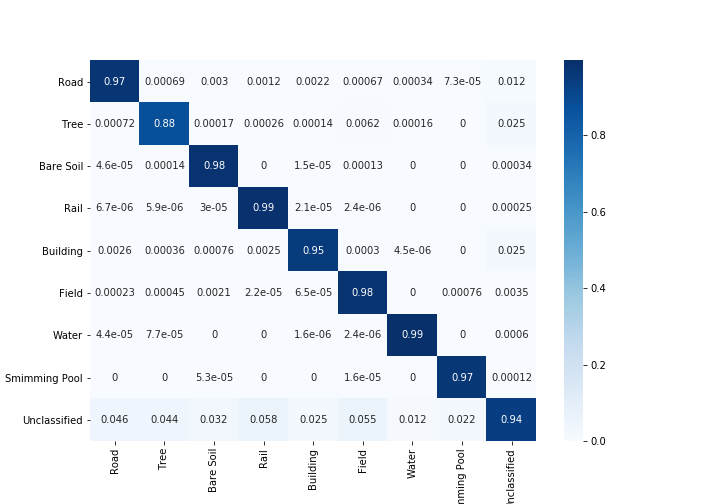
ค่าสัมประสิทธิ์คัปปาที่มีและไม่มีการพิจารณาพิกเซลที่ไม่จำแนกประเภท
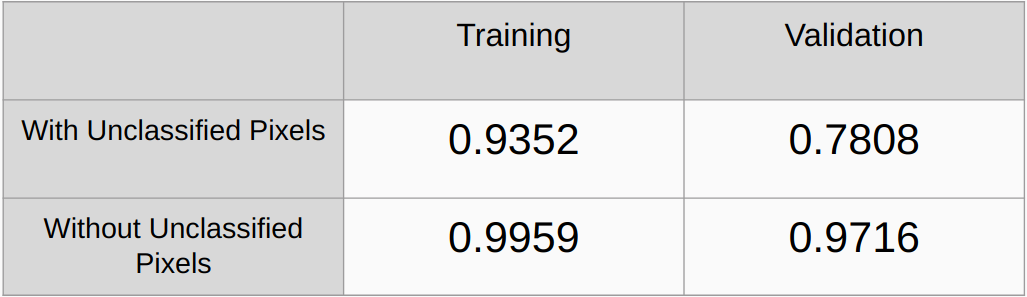
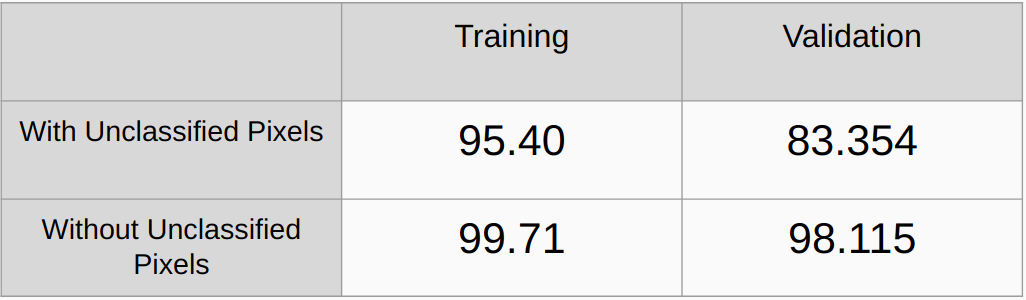
ความแม่นยำโดยรวมทั้งแบบมีและไม่พิจารณาพิกเซลที่ไม่จำแนกประเภท
จำเป็นต้องเพิ่มวิธีการทำให้เป็นมาตรฐาน เช่น L2 Regularizarion และ Droupout และตรวจสอบประสิทธิภาพ
ใช้อัลกอริธึมเพื่อตรวจจับค่า RGB ที่ไม่ซ้ำกันทั้งหมดโดยอัตโนมัติในความจริงภาคพื้นดิน และเข้ารหัสค่าเหล่านั้นทันทีแทนที่จะค้นหาค่า RGB ด้วยตนเอง
1 U-Net: เครือข่าย Convolutional สำหรับการแบ่งส่วนภาพชีวการแพทย์, Olaf Ronneberger, Philipp Fischer และ Thomas Brox
[2] เครือข่ายการแยกวิเคราะห์ฉากพีระมิด, เหิงซวง จ้าว, เจียนผิง สือ, เสี่ยวจวน ฉี, เสี่ยวกัง หวาง, เจียยา เจีย
(3) คู่มือปี 2017 เกี่ยวกับการแบ่งส่วนความหมายด้วยการเรียนรู้เชิงลึก Sasank Chilamkurthy


