linformer pytorch
version
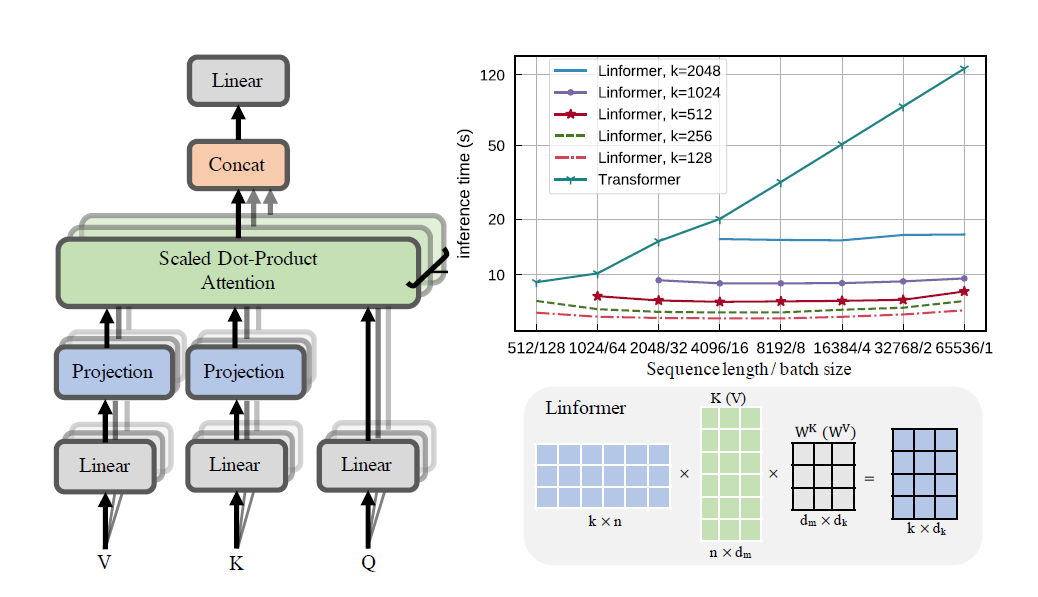
การนำเอกสาร Linformer ไปใช้ในทางปฏิบัติ นี่คือความสนใจที่มีความซับซ้อนเชิงเส้นใน n เท่านั้น ทำให้สามารถจัดการความยาวลำดับที่ยาวมาก (1mil+) บนฮาร์ดแวร์สมัยใหม่
repo นี้เป็นหม้อแปลงสไตล์ Attention Is All You Need พร้อมด้วยโมดูลตัวเข้ารหัสและตัวถอดรหัส ความแปลกใหม่ก็คือ ในปัจจุบัน เราสามารถทำให้ความสนใจมุ่งหน้าเป็นเส้นตรงได้ ตรวจสอบวิธีการใช้งานด้านล่าง
นี่อยู่ระหว่างการตรวจสอบความถูกต้องบน wikitext-2 ในปัจจุบัน ทำงานในระดับเดียวกับกลไกความสนใจแบบกระจัดกระจายอื่นๆ เช่น Sinkhorn Transformer แต่ยังคงต้องหาไฮเปอร์พารามิเตอร์ที่ดีที่สุด
การแสดงภาพศีรษะก็เป็นไปได้เช่นกัน หากต้องการดูข้อมูลเพิ่มเติม โปรดดูส่วนการแสดงภาพด้านล่าง
ฉันไม่ใช่ผู้เขียนบทความนี้
โทเค็น 1.23m
pip install linformer-pytorch
อีกทางหนึ่ง
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
แบบจำลองภาษา Linformer
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer ความสนใจในตนเอง, กอง MHAttention และ FeedForward s
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Linformer Multihead สนใจ
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)หัวความสนใจเชิงเส้น ความแปลกใหม่ของกระดาษ
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)โมดูลตัวเข้ารหัส/ตัวถอดรหัส
หมายเหตุ: สำหรับลำดับเชิงสาเหตุ เราสามารถตั้งค่าสถานะ causal=True ใน LinformerLM เพื่อปกปิดมุมขวาบนในเมทริกซ์ความสนใจ (n,k)
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) วิธีง่ายๆ ในการรับเมทริกซ์ E และ F สามารถทำได้โดยการเรียกใช้ฟังก์ชัน get_EF ตามตัวอย่าง สำหรับ n ของ 1000 และ k ของ 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) ด้วยแฟล็ก method เราสามารถตั้งค่าวิธีการที่ linformer ทำการสุ่มตัวอย่างต่ำได้ ปัจจุบันรองรับสามวิธี:
learnable : วิธีการลดขนาดตัวอย่างนี้จะสร้างโมดูล n,k nn.Linear ที่สามารถเรียนรู้ได้convolution : วิธีการลดขนาดตัวอย่างนี้สร้าง Convolution 1d โดยมีความยาวก้าวและขนาดเคอร์เนล n/kno_params : สิ่งนี้สร้างเมทริกซ์ n,k คงที่พร้อมค่า fron N(0,1/k)ในอนาคตอาจรวมการรวมกันหรืออย่างอื่นด้วย แต่สำหรับตอนนี้ นี่คือตัวเลือกที่มีอยู่
เพื่อเป็นความพยายามที่จะแนะนำการประหยัดหน่วยความจำเพิ่มเติม แนวคิดของระดับจุดตรวจจึงถูกนำมาใช้ ระดับจุดตรวจสามระดับในปัจจุบันคือ C0 , C1 และ C2 เมื่อขึ้นระดับจุดตรวจ จะต้องสละความเร็วเพื่อรักษาหน่วยความจำ นั่นคือด่านระดับ C0 นั้นเร็วที่สุด แต่ใช้พื้นที่บน GPU มากที่สุด ในขณะที่ C2 นั้นช้าที่สุด แต่ใช้พื้นที่บน GPU น้อยที่สุด รายละเอียดของแต่ละด่านมีดังนี้
C0 : ไม่มีจุดตรวจ โมเดลเหล่านี้ทำงานโดยยังคงรักษาส่วนหัวของความสนใจและเลเยอร์ ff ทั้งหมดไว้ในหน่วยความจำ GPUC1 : ตรวจสอบความสนใจของ MultiHead แต่ละอันและเลเยอร์ ff แต่ละอัน ด้วยเหตุนี้ การเพิ่ม depth จึงควรมีผลกระทบต่อหน่วยความจำน้อยที่สุดC2 : พร้อมกับการปรับให้เหมาะสมที่ระดับ C1 ให้ตรวจสอบแต่ละหัวในแต่ละเลเยอร์ MultiHead Attention ด้วยเหตุนี้ การเพิ่ม nhead จึงน่าจะมีผลกระทบต่อหน่วยความจำน้อยลง อย่างไรก็ตาม การต่อส่วนหัวเข้ากับ torch.cat ยังคงใช้หน่วยความจำจำนวนมาก และหวังว่าจะได้รับการปรับให้เหมาะสมในอนาคตยังไม่ทราบรายละเอียดประสิทธิภาพ แต่มีตัวเลือกสำหรับผู้ใช้ที่ต้องการลอง
ความพยายามที่จะแนะนำการประหยัดหน่วยความจำในรายงานก็คือการแนะนำการใช้พารามิเตอร์ร่วมกันระหว่างการฉายภาพ สิ่งนี้ถูกกล่าวถึงในส่วนที่ 4 ของบทความนี้ โดยเฉพาะอย่างยิ่งมีการแชร์พารามิเตอร์ 4 ประเภทที่ผู้เขียนพูดคุย และทั้งหมดได้ถูกนำไปใช้ใน repo นี้ ตัวเลือกแรกใช้หน่วยความจำมากที่สุด และแต่ละตัวเลือกเพิ่มเติมจะลดความต้องการหน่วยความจำที่จำเป็น
none : นี่คือไม่มีการแชร์พารามิเตอร์ สำหรับทุกส่วนหัวและทุกเลเยอร์ จะมีการคำนวณเมทริกซ์ E ใหม่และเมทริกซ์ F ใหม่สำหรับทุกส่วนหัวในแต่ละเลเยอร์headwise : แต่ละเลเยอร์มีเมทริกซ์ E และ F ที่ไม่ซ้ำกัน หัวทั้งหมดในเลเยอร์ใช้เมทริกซ์นี้ร่วมกันkv : แต่ละเลเยอร์มีเมทริกซ์การฉายภาพที่ไม่ซ้ำกัน P และ E = F = P สำหรับแต่ละเลเยอร์ หัวทั้งหมดใช้เมทริกซ์การฉายภาพร่วมกัน Playerwise : มีหนึ่งเมทริกซ์การฉายภาพ P และทุกหัวในทุกเลเยอร์ใช้ E = F = P ตามที่เริ่มต้นในบทความนี้ หมายความว่าสำหรับเครือข่าย 12 เลเยอร์ 12 หัว จะมีเมทริกซ์การฉายภาพที่แตกต่างกัน 288 , 24 , 12 และ 1 รายการตามลำดับ
โปรดทราบว่าด้วยตัวเลือก k_reduce_by_layer ตัวเลือก layerwise จะไม่ได้ผล เนื่องจากจะใช้มิติของ k สำหรับเลเยอร์แรก ดังนั้น หากค่าของค่า k_reduce_by_layer มากกว่า 0 ก็ไม่น่าจะใช้ตัวเลือกการแชร์ layerwise
นอกจากนี้ โปรดทราบว่าตามที่ผู้เขียนระบุในรูปที่ 3 การแบ่งปันพารามิเตอร์นี้ไม่ส่งผลกระทบต่อผลลัพธ์สุดท้ายมากนัก ดังนั้นจึงอาจเป็นการดีที่สุดที่จะยึดติดกับการแบ่งปัน layerwise สำหรับทุกสิ่ง แต่มีตัวเลือกให้ผู้ใช้ทดลองใช้งาน
ปัญหาเล็กน้อยอย่างหนึ่งในการใช้งาน Linformer ในปัจจุบันคือความยาวของลำดับของคุณจะต้องตรงกับแฟล็ก input_size ของโมเดล Padder จะรองขนาดอินพุตเพื่อให้สามารถป้อนเทนเซอร์เข้าสู่เครือข่ายได้ ตัวอย่าง:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 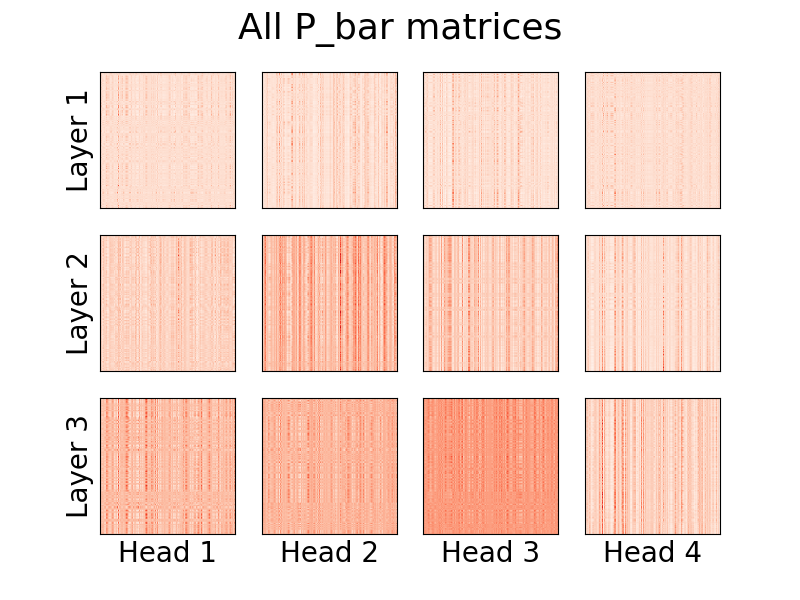
ตั้งแต่เวอร์ชัน 0.8.0 เป็นต้นไป ตอนนี้เราสามารถเห็นภาพความสนใจของ linformer ได้แล้ว! หากต้องการดูการดำเนินการนี้ เพียงนำเข้าคลาส Visualizer และเรียกใช้ฟังก์ชัน plot_all_heads() เพื่อดูรูปภาพของหัวความสนใจทั้งหมดในแต่ละระดับขนาด (n,k) ตรวจสอบให้แน่ใจว่าคุณระบุ visualize=True ในการส่งต่อ เนื่องจากจะเป็นการบันทึกเมทริกซ์ P_bar เพื่อให้คลาส Visualizer สามารถมองเห็นส่วนหัวได้อย่างเหมาะสม
ตัวอย่างการทำงานของโค้ดมีอยู่ด้านล่าง และโค้ดเดียวกันนี้สามารถพบได้ใน ./examples/example_vis.py :
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)คำอธิบายโดยละเอียดเกี่ยวกับความหมายของหัวเหล่านี้มีอยู่ใน #15
เช่นเดียวกับ Reformer ฉันจะพยายามสร้างโมดูลตัวเข้ารหัส/ตัวถอดรหัส เพื่อให้การฝึกอบรมง่ายขึ้น ใช้งานได้เหมือน 2 คลาส LinformerLM พารามิเตอร์สามารถปรับแยกกันได้สำหรับแต่ละรายการ โดยตัวเข้ารหัสจะมีคำนำหน้า enc_ สำหรับไฮเปอร์พารามิเตอร์ทั้งหมด และตัวถอดรหัสจะมีคำนำหน้า dec_ ในลักษณะเดียวกัน จนถึงขณะนี้ สิ่งที่ดำเนินการคือ:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )ฉันกำลังวางแผนที่จะมีวิธีสร้างลำดับข้อความสำหรับสิ่งนี้
ff_intermediate ตอนนี้ มิติของแบบจำลองอาจแตกต่างกันในเลเยอร์กลาง การเปลี่ยนแปลงนี้ใช้กับโมดูล ff และในตัวเข้ารหัสเท่านั้น ตอนนี้ หากแฟล็ก ff_intermediate ไม่ใช่ None เลเยอร์จะมีลักษณะดังนี้:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
ตรงข้ามกับ
channels -> ff_dim -> channels (For all layers)
input_size และ dim_k ตามลำดับapex ควรใช้งานได้ อย่างไรก็ตาม ในทางปฏิบัติยังไม่ได้ทดสอบinput_size , k= dim_k และ d= dim_d LinformerEncDec นี่เป็นครั้งแรกที่ฉันทำซ้ำผลลัพธ์จากรายงาน ดังนั้นอาจมีบางอย่างผิดพลาด หากคุณเห็นปัญหา โปรดเปิดปัญหาและเราจะพยายามแก้ไขปัญหานั้น
ขอบคุณ lucidrains ซึ่งแหล่งเก็บข้อมูลอื่น ๆ ที่ไม่ค่อยสนใจช่วยฉันในการออกแบบ Linformer Repo นี้
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}“จงฟังอย่างตั้งใจ...”


