vit pytorch
1.9.1
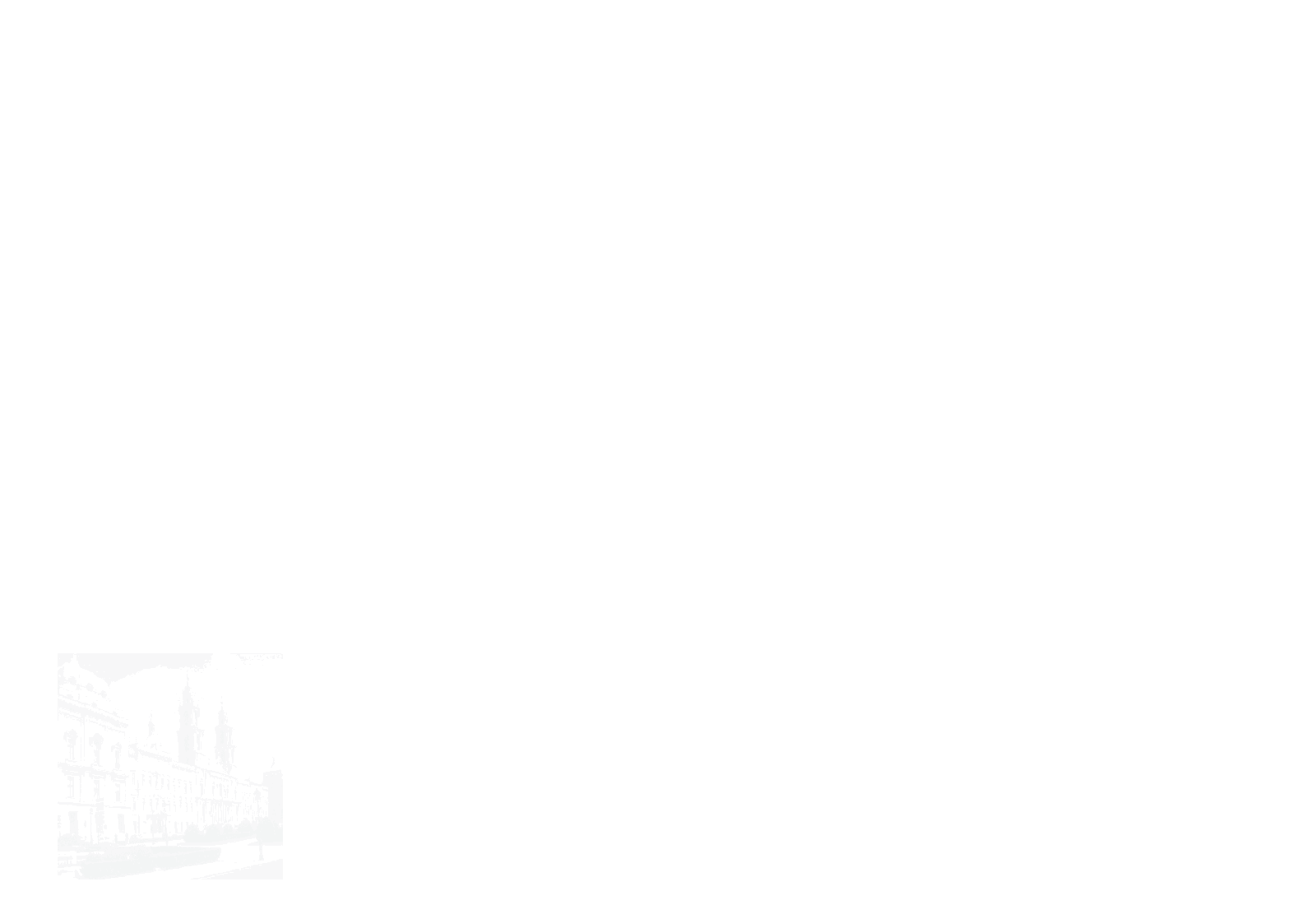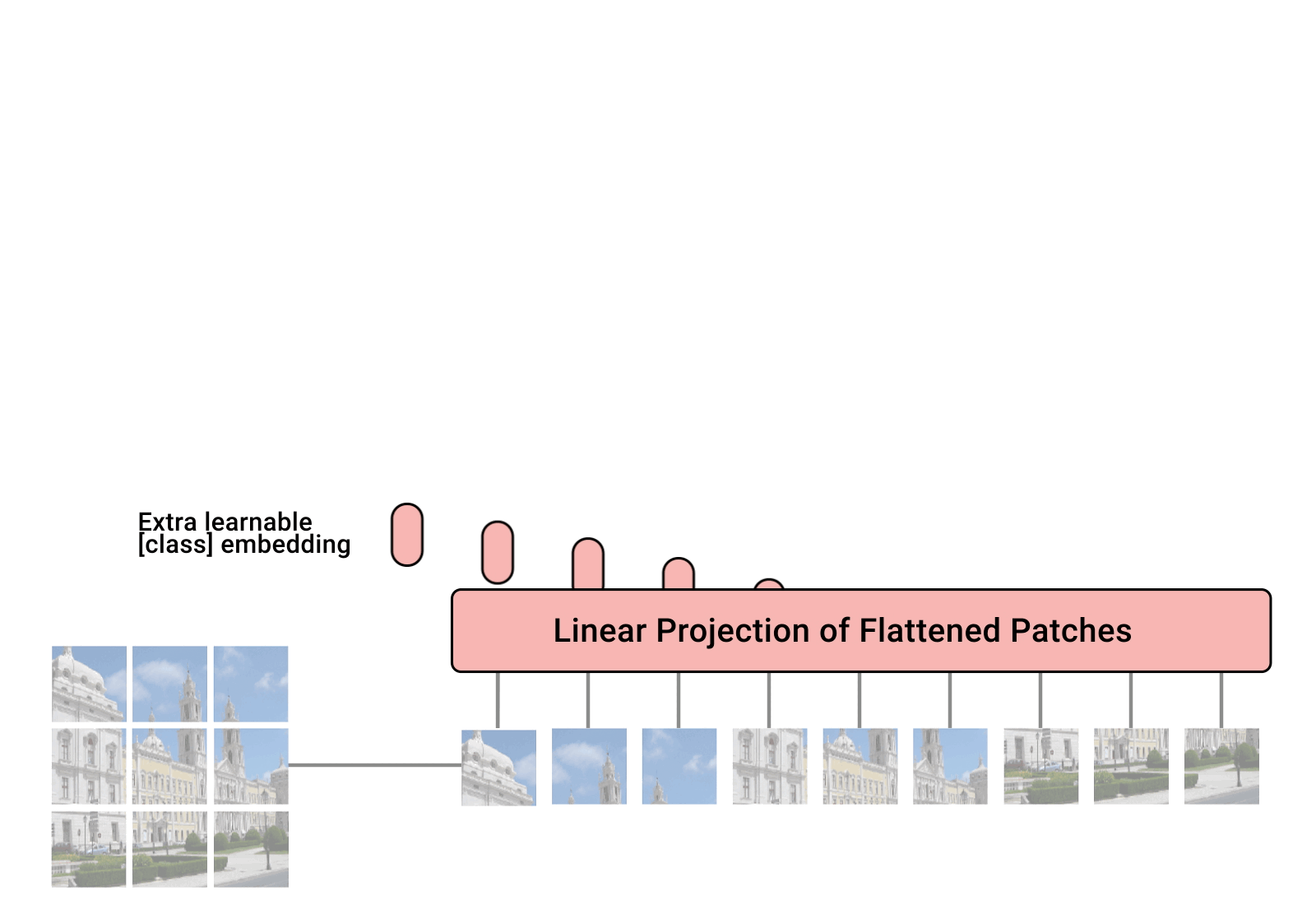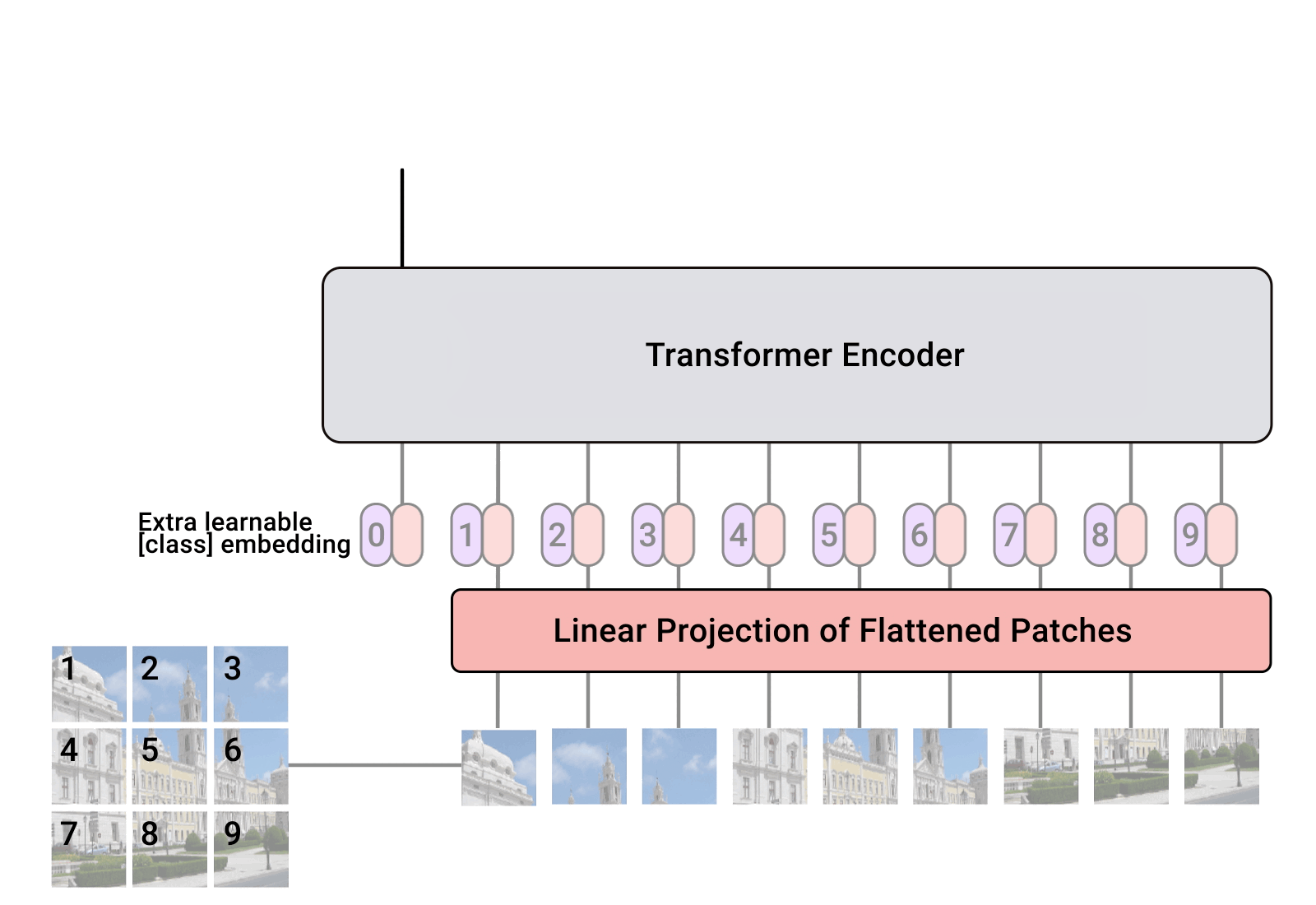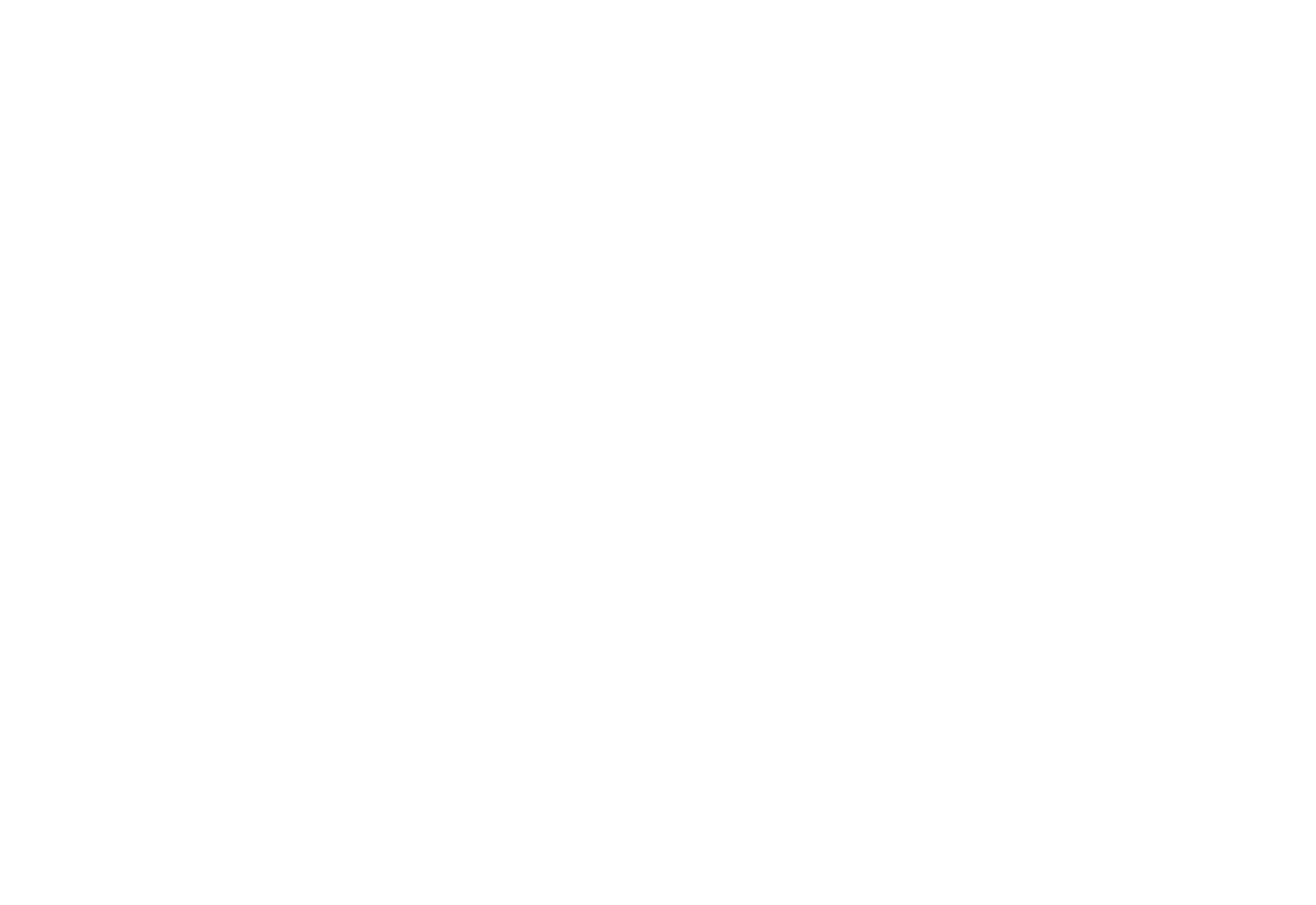
การใช้งาน Vision Transformer ซึ่งเป็นวิธีง่ายๆ เพื่อให้ได้ SOTA ในการจำแนกประเภทการมองเห็นด้วยตัวเข้ารหัสหม้อแปลงเพียงตัวเดียวใน Pytorch ความสำคัญมีการอธิบายเพิ่มเติมในวิดีโอของ Yannic Kilcher จริงๆ แล้วไม่มีอะไรให้เขียนโค้ดมากนัก แต่อาจสำหรับทุกคนด้วย ดังนั้นเราจึงเร่งการปฏิวัติความสนใจ
สำหรับการใช้งาน Pytorch กับโมเดลที่ผ่านการฝึกอบรมแล้ว โปรดดูพื้นที่เก็บข้อมูลของ Ross Wightman ที่นี่
ที่เก็บ Jax อย่างเป็นทางการอยู่ที่นี่
มีการแปล tensorflow2 ที่นี่ด้วย สร้างโดยนักวิทยาศาสตร์การวิจัย Junho Kim!
แปลผ้าลินินโดย Enrico Shippole!
$ pip install vit-pytorch import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) image_size : int.patch_size : int.image_size ต้องหารด้วย patch_size ลงตัวn = (image_size // patch_size) ** 2 และ n ต้องมากกว่า 16num_classes : int.dim : int.nn.Linear(..., dim)depth : int.heads : int.mlp_dim : int.channels : int, ค่าเริ่มต้น 3 .dropout : ลอยระหว่าง [0, 1] , ค่าเริ่มต้น 0. .emb_dropout : ลอยระหว่าง [0, 1] ค่าเริ่มต้น 0pool : string ไม่ว่าจะเป็นการรวมโทเค็น cls หรือการรวมค่า mean การอัปเดตจากผู้เขียนบทความต้นฉบับบางคนเสนอการลดความซับซ้อนให้กับ ViT ซึ่งช่วยให้ฝึกอบรมได้เร็วและดีขึ้น
ท่ามกลางการลดความซับซ้อนเหล่านี้ ได้แก่ การฝังตำแหน่งไซน์ซอยด์ 2 มิติ การรวมค่าเฉลี่ยทั่วโลก (ไม่มีโทเค็น CLS) ไม่มีการดรอปเอาท์ ขนาดแบตช์ 1024 แทนที่จะเป็น 4096 และการใช้การเพิ่ม RandAugment และ MixUp นอกจากนี้ยังแสดงให้เห็นว่าเส้นตรงแบบธรรมดาที่ส่วนท้ายไม่ได้แย่ไปกว่าหัว MLP ดั้งเดิมมากนัก
คุณสามารถใช้มันได้โดยการนำเข้า SimpleViT ดังที่แสดงด้านล่าง
import torch
from vit_pytorch import SimpleViT
v = SimpleViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 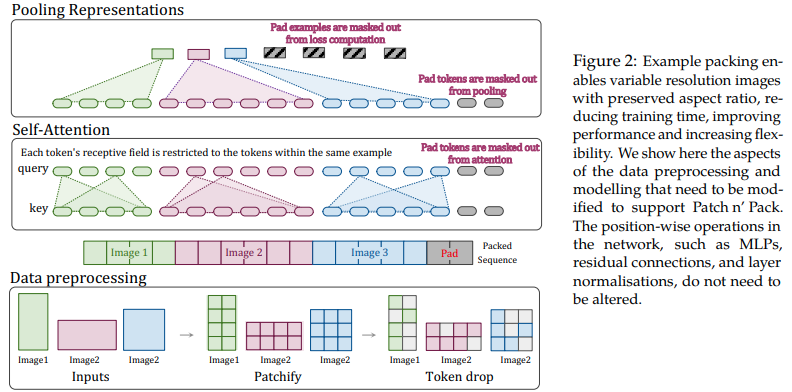
บทความนี้เสนอให้ใช้ประโยชน์จากความยืดหยุ่นของความสนใจและการมาสก์สำหรับลำดับที่มีความยาวผันแปรได้ เพื่อฝึกภาพที่มีความละเอียดหลายระดับ โดยบรรจุไว้ในชุดเดียว พวกเขาแสดงให้เห็นถึงการฝึกอบรมที่เร็วขึ้นมากและปรับปรุงความแม่นยำ โดยมีค่าใช้จ่ายเพียงอย่างเดียวคือความซับซ้อนเพิ่มเติมในสถาปัตยกรรมและการโหลดข้อมูล พวกเขาใช้การเข้ารหัสตำแหน่ง 2d แบบแยกตัวประกอบ การลดโทเค็น และการทำให้เป็นมาตรฐานของคีย์คิวรี
คุณสามารถใช้มันได้ดังนี้
import torch
from vit_pytorch . na_vit import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
token_dropout_prob = 0.1 # token dropout of 10% (keep 90% of tokens)
)
# 5 images of different resolutions - List[List[Tensor]]
# for now, you'll have to correctly place images in same batch element as to not exceed maximum allowed sequence length for self-attention w/ masking
images = [
[ torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 )],
[ torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 )],
[ torch . randn ( 3 , 64 , 256 )]
]
preds = v ( images ) # (5, 1000) - 5, because 5 images of different resolution aboveหรือหากคุณต้องการให้เฟรมเวิร์กจัดกลุ่มรูปภาพโดยอัตโนมัติเป็นลำดับความยาวผันแปรได้ซึ่งไม่เกินความยาวสูงสุดที่กำหนด
images = [
torch . randn ( 3 , 256 , 256 ),
torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ),
torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v (
images ,
group_images = True ,
group_max_seq_len = 64
) # (5, 1000) สุดท้ายนี้ หากคุณต้องการใช้รสชาติของ NaViT โดยใช้เทนเซอร์ที่ซ้อนกัน (ซึ่งจะละเว้นการมาสก์และช่องว่างภายในจำนวนมาก) ตรวจสอบให้แน่ใจว่าคุณใช้เวอร์ชัน 2.5 และนำเข้าดังนี้
import torch
from vit_pytorch . na_vit_nested_tensor import NaViT
v = NaViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0. ,
emb_dropout = 0. ,
token_dropout_prob = 0.1
)
# 5 images of different resolutions - List[Tensor]
images = [
torch . randn ( 3 , 256 , 256 ), torch . randn ( 3 , 128 , 128 ),
torch . randn ( 3 , 128 , 256 ), torch . randn ( 3 , 256 , 128 ),
torch . randn ( 3 , 64 , 256 )
]
preds = v ( images )
assert preds . shape == ( 5 , 1000 )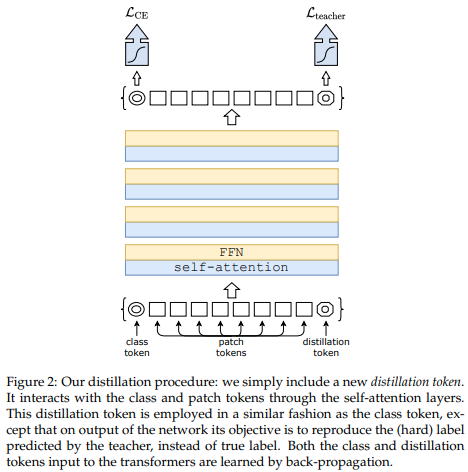
บทความล่าสุดได้แสดงให้เห็นว่าการใช้โทเค็นการกลั่นเพื่อกลั่นความรู้จากตาข่ายแบบขดไปยังหม้อแปลงวิชั่นสามารถให้วิชันหม้อแปลงขนาดเล็กและมีประสิทธิภาพได้ พื้นที่เก็บข้อมูลนี้นำเสนอวิธีการกลั่นได้อย่างง่ายดาย
อดีต. กลั่นจาก Resnet50 (หรืออาจารย์คนใดก็ได้) ไปจนถึงเครื่องแปลงวิชั่น
import torch
from torchvision . models import resnet50
from vit_pytorch . distill import DistillableViT , DistillWrapper
teacher = resnet50 ( pretrained = True )
v = DistillableViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
distiller = DistillWrapper (
student = v ,
teacher = teacher ,
temperature = 3 , # temperature of distillation
alpha = 0.5 , # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch . randn ( 2 , 3 , 256 , 256 )
labels = torch . randint ( 0 , 1000 , ( 2 ,))
loss = distiller ( img , labels )
loss . backward ()
# after lots of training above ...
pred = v ( img ) # (2, 1000) คลาส DistillableViT นั้นเหมือนกับ ViT ยกเว้นวิธีจัดการกับการส่งต่อ ดังนั้นคุณควรจะสามารถโหลดพารามิเตอร์กลับไปที่ ViT ได้หลังจากที่คุณเสร็จสิ้นการฝึกอบรมการกลั่นแล้ว
คุณยังสามารถใช้เมธอด .to_vit ที่มีประโยชน์บนอินสแตนซ์ DistillableViT เพื่อเรียกคืนอินสแตนซ์ ViT ได้อีกด้วย
v = v . to_vit ()
type ( v ) # <class 'vit_pytorch.vit_pytorch.ViT'> บทความนี้ตั้งข้อสังเกตว่า ViT พยายามดิ้นรนเพื่อเข้าร่วมในระดับความลึกที่มากขึ้น (เกิน 12 เลเยอร์ไปแล้ว) และแนะนำให้ผสมความสนใจของโพสต์ซอฟต์แม็กซ์แต่ละหัวเข้าด้วยกันเป็นวิธีแก้ปัญหา ที่เรียกว่า Re-attention ผลลัพธ์สอดคล้องกับรายงาน Talking Heads จาก NLP
คุณสามารถใช้มันได้ดังนี้
import torch
from vit_pytorch . deepvit import DeepViT
v = DeepViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) เอกสารนี้ยังกล่าวถึงความยากลำบากในการฝึกอบรม Vision Transformer ในระดับความลึกที่มากขึ้น และเสนอวิธีแก้ปัญหา 2 ข้อ ขั้นแรกเสนอให้ทำการคูณเอาต์พุตของบล็อกที่เหลือต่อช่องสัญญาณ ประการที่สอง เสนอให้แพทช์ดูแลซึ่งกันและกัน และอนุญาตให้โทเค็น CLS เข้าร่วมกับแพตช์ในสองสามเลเยอร์สุดท้ายเท่านั้น
พวกเขายังเพิ่ม Talking Heads โดยสังเกตการปรับปรุง
คุณสามารถใช้โครงร่างนี้ได้ดังนี้
import torch
from vit_pytorch . cait import CaiT
v = CaiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of transformer for patch to patch attention only
cls_depth = 2 , # depth of cross attention of CLS tokens to patch
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 # randomly dropout 5% of the layers
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 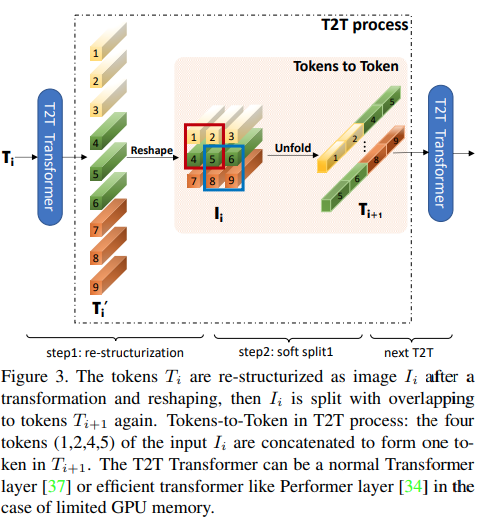
บทความนี้เสนอว่าสองสามเลเยอร์แรกควรลดขนาดลำดับรูปภาพลงโดยการกางออก ซึ่งนำไปสู่ข้อมูลรูปภาพที่ทับซ้อนกันในแต่ละโทเค็นดังแสดงในรูปด้านบน คุณสามารถใช้ ViT รุ่นนี้ได้ดังนี้
import torch
from vit_pytorch . t2t import T2TViT
v = T2TViT (
dim = 512 ,
image_size = 224 ,
depth = 5 ,
heads = 8 ,
mlp_dim = 512 ,
num_classes = 1000 ,
t2t_layers = (( 7 , 4 ), ( 3 , 2 ), ( 3 , 2 )) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) CCT เสนอหม้อแปลงขนาดกะทัดรัดโดยใช้การโน้มน้าวใจแทนการแพตช์และดำเนินการรวมลำดับ ซึ่งช่วยให้ CCT มีความแม่นยำสูงและมีพารามิเตอร์จำนวนน้อย
คุณสามารถใช้สิ่งนี้ได้สองวิธี
import torch
from vit_pytorch . cct import CCT
cct = CCT (
img_size = ( 224 , 448 ),
embedding_dim = 384 ,
n_conv_layers = 2 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)
img = torch . randn ( 1 , 3 , 224 , 448 )
pred = cct ( img ) # (1, 1000) หรือคุณสามารถใช้หนึ่งในโมเดลที่กำหนดไว้ล่วงหน้า [2,4,6,7,8,14,16] ซึ่งกำหนดล่วงหน้าจำนวนเลเยอร์ จำนวนส่วนหัวของความสนใจ อัตราส่วน mlp และมิติการฝัง
import torch
from vit_pytorch . cct import cct_14
cct = cct_14 (
img_size = 224 ,
n_conv_layers = 1 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_classes = 1000 ,
positional_embedding = 'learnable' , # ['sine', 'learnable', 'none']
)พื้นที่เก็บข้อมูลอย่างเป็นทางการมีลิงก์ไปยังจุดตรวจโมเดลที่ได้รับการฝึกล่วงหน้า
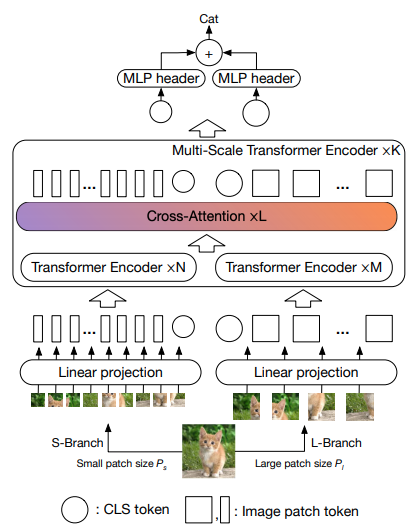
บทความนี้เสนอให้มีวิชันทรานส์ฟอร์มเมอร์สองตัวที่ประมวลผลภาพในระดับที่แตกต่างกัน โดยครอสโอเวอร์กับตัวหนึ่งบ่อยครั้ง พวกเขาแสดงการปรับปรุงที่ด้านบนของหม้อแปลงวิชันซิสเต็มฐาน
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 , # number of multi-scale encoding blocks
sm_dim = 192 , # high res dimension
sm_patch_size = 16 , # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2 , # high res depth
sm_enc_heads = 8 , # high res heads
sm_enc_mlp_dim = 2048 , # high res feedforward dimension
lg_dim = 384 , # low res dimension
lg_patch_size = 64 , # low res patch size
lg_enc_depth = 3 , # low res depth
lg_enc_heads = 8 , # low res heads
lg_enc_mlp_dim = 2048 , # low res feedforward dimensions
cross_attn_depth = 2 , # cross attention rounds
cross_attn_heads = 8 , # cross attention heads
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = v ( img ) # (1, 1000) 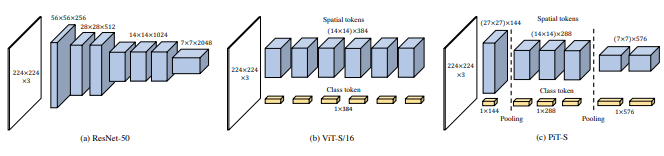
บทความนี้เสนอให้สุ่มตัวอย่างโทเค็นผ่านขั้นตอนการรวมกลุ่มโดยใช้การบิดแบบเชิงลึก
import torch
from vit_pytorch . pit import PiT
v = PiT (
image_size = 224 ,
patch_size = 14 ,
dim = 256 ,
num_classes = 1000 ,
depth = ( 3 , 3 , 3 ), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 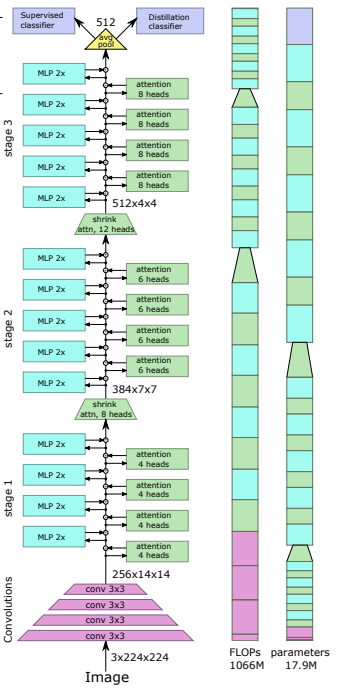
บทความนี้เสนอการเปลี่ยนแปลงจำนวนหนึ่ง รวมถึง (1) การฝังแบบหมุนวนแทนการฉายภาพแบบแพตช์ (2) การสุ่มตัวอย่างในขั้นตอน (3) ความไม่เชิงเส้นที่เพิ่มขึ้นในความสนใจ (4) อคติเชิงตำแหน่งสัมพัทธ์ 2 มิติ แทนอคติเชิงตำแหน่งสัมบูรณ์เริ่มต้น (5 ) แบทช์นอร์มแทนที่เลเยอร์นอร์ม
พื้นที่เก็บข้อมูลอย่างเป็นทางการ
import torch
from vit_pytorch . levit import LeViT
levit = LeViT (
image_size = 224 ,
num_classes = 1000 ,
stages = 3 , # number of stages
dim = ( 256 , 384 , 512 ), # dimensions at each stage
depth = 4 , # transformer of depth 4 at each stage
heads = ( 4 , 6 , 8 ), # heads at each stage
mlp_mult = 2 ,
dropout = 0.1
)
img = torch . randn ( 1 , 3 , 224 , 224 )
levit ( img ) # (1, 1000) 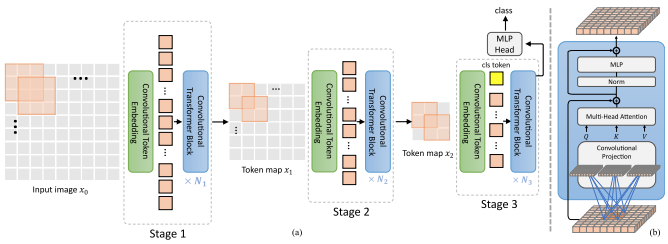
บทความนี้เสนอการผสมผสานระหว่างการโน้มน้าวใจและความสนใจ โดยเฉพาะอย่างยิ่ง การโน้มน้าวใจจะใช้ในการฝังและย่อขนาดรูปภาพ/แผนที่คุณลักษณะในสามขั้นตอน นอกจากนี้ Convoltion ในเชิงลึกยังใช้ในการฉายคิวรี คีย์ และค่าที่เรียกร้องความสนใจอีกด้วย
import torch
from vit_pytorch . cvt import CvT
v = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 , # stage 1 - dimension
s1_emb_kernel = 7 , # stage 1 - conv kernel
s1_emb_stride = 4 , # stage 1 - conv stride
s1_proj_kernel = 3 , # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2 , # stage 1 - attention key / value projection stride
s1_heads = 1 , # stage 1 - heads
s1_depth = 1 , # stage 1 - depth
s1_mlp_mult = 4 , # stage 1 - feedforward expansion factor
s2_emb_dim = 192 , # stage 2 - (same as above)
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 , # stage 3 - (same as above)
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = v ( img ) # (1, 1000) 
บทความนี้เสนอการผสมผสานความสนใจในระดับท้องถิ่นและระดับโลก พร้อมด้วยตัวสร้างการเข้ารหัสตำแหน่ง (เสนอใน CPVT) และการรวมกลุ่มค่าเฉลี่ยทั่วโลก เพื่อให้ได้ผลลัพธ์เช่นเดียวกับ Swin โดยไม่ต้องมีความซับซ้อนเป็นพิเศษของหน้าต่างที่ถูกเลื่อน โทเค็น CLS หรือการฝังตำแหน่ง
import torch
from vit_pytorch . twins_svt import TwinsSVT
model = TwinsSVT (
num_classes = 1000 , # number of output classes
s1_emb_dim = 64 , # stage 1 - patch embedding projected dimension
s1_patch_size = 4 , # stage 1 - patch size for patch embedding
s1_local_patch_size = 7 , # stage 1 - patch size for local attention
s1_global_k = 7 , # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1 , # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128 , # stage 2 (same as above)
s2_patch_size = 2 ,
s2_local_patch_size = 7 ,
s2_global_k = 7 ,
s2_depth = 1 ,
s3_emb_dim = 256 , # stage 3 (same as above)
s3_patch_size = 2 ,
s3_local_patch_size = 7 ,
s3_global_k = 7 ,
s3_depth = 5 ,
s4_emb_dim = 512 , # stage 4 (same as above)
s4_patch_size = 2 ,
s4_local_patch_size = 7 ,
s4_global_k = 7 ,
s4_depth = 4 ,
peg_kernel_size = 3 , # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 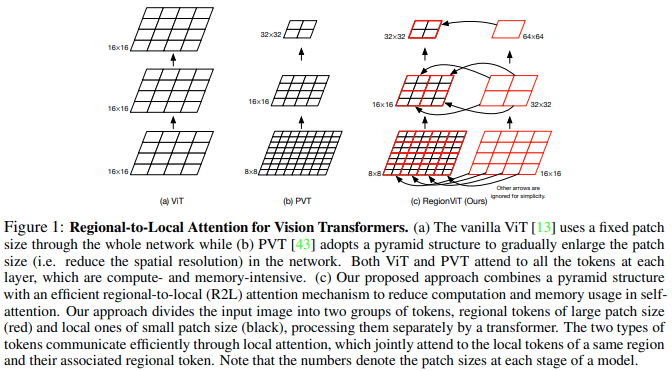
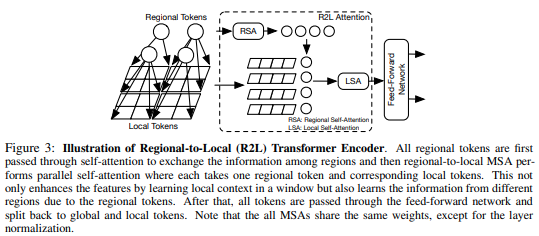
บทความนี้เสนอให้แบ่งแผนผังคุณลักษณะออกเป็นภูมิภาคท้องถิ่น โดยที่โทเค็นท้องถิ่นจะเชื่อมโยงกัน แต่ละภูมิภาคท้องถิ่นมีโทเค็นภูมิภาคของตนเอง ซึ่งจะเข้าร่วมโทเค็นท้องถิ่นทั้งหมด รวมถึงโทเค็นภูมิภาคอื่นๆ
คุณสามารถใช้มันได้ดังนี้
import torch
from vit_pytorch . regionvit import RegionViT
model = RegionViT (
dim = ( 64 , 128 , 256 , 512 ), # tuple of size 4, indicating dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of the region to local transformer at each stage
window_size = 7 , # window size, which should be either 7 or 14
num_classes = 1000 , # number of output classes
tokenize_local_3_conv = False , # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False , # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 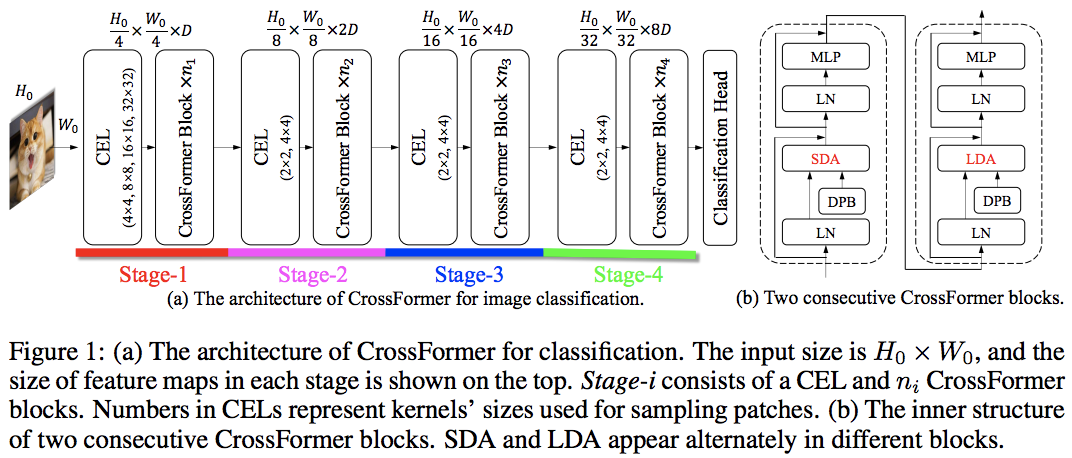
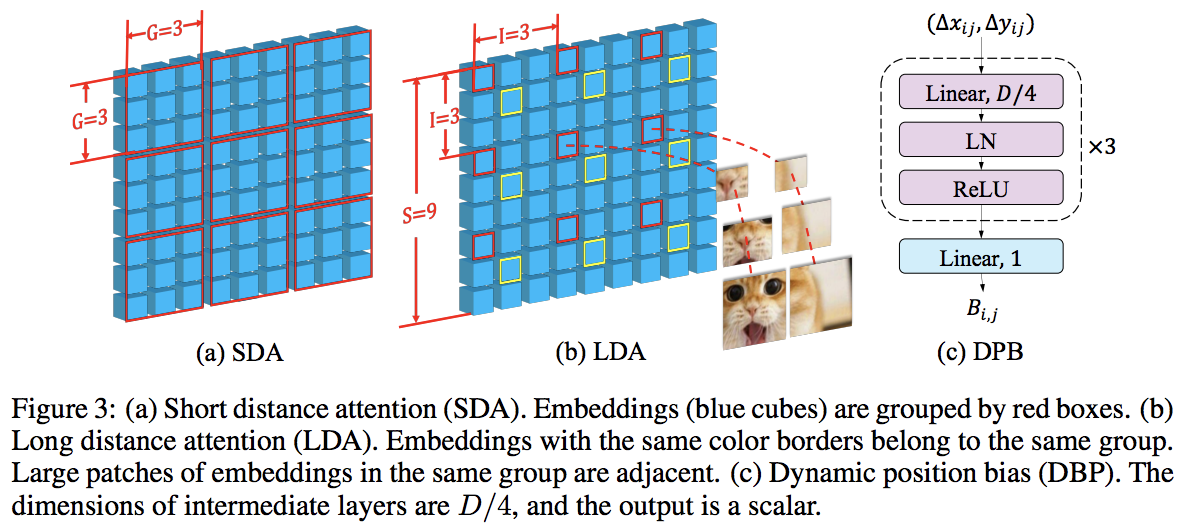
บทความนี้เอาชนะ PVT และ Swin โดยใช้ความสนใจในระดับท้องถิ่นและระดับโลกสลับกัน ความสนใจทั่วโลกดำเนินการทั่วทั้งมิติหน้าต่างเพื่อลดความซับซ้อน เช่นเดียวกับรูปแบบที่ใช้สำหรับความสนใจในแนวแกน
พวกเขายังมีเลเยอร์การฝังแบบข้ามสเกล ซึ่งแสดงให้เห็นว่าเป็นเลเยอร์ทั่วไปที่สามารถปรับปรุงวิชั่นทรานส์ฟอร์มเมอร์ทั้งหมดได้ อคติเชิงตำแหน่งสัมพัทธ์แบบไดนามิกยังถูกกำหนดขึ้นเพื่อให้เน็ตสามารถสรุปภาพที่มีความละเอียดสูงกว่าได้
import torch
from vit_pytorch . crossformer import CrossFormer
model = CrossFormer (
num_classes = 1000 , # number of output classes
dim = ( 64 , 128 , 256 , 512 ), # dimension at each stage
depth = ( 2 , 2 , 8 , 2 ), # depth of transformer at each stage
global_window_size = ( 8 , 4 , 2 , 1 ), # global window sizes at each stage
local_window_size = 7 , # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = model ( img ) # (1, 1000) 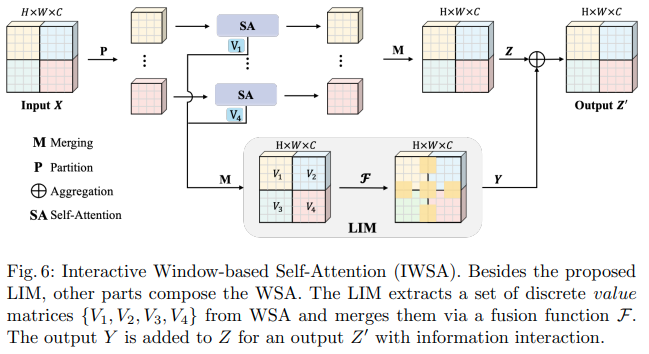
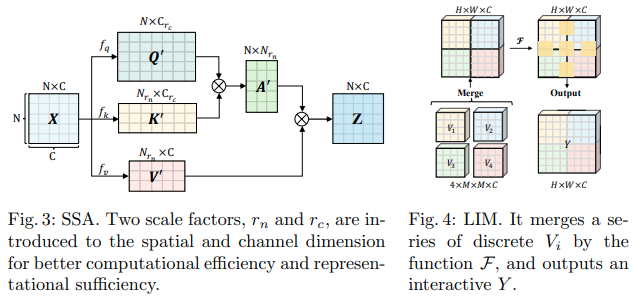
เอกสาร Bytedance AI นี้เสนอโมดูล Scalable Self Attention (SSA) และ Interactive Windowed Self Attention (IWSA) SSA บรรเทาการคำนวณที่จำเป็นในระยะก่อนหน้านี้โดยลดการแมปคุณลักษณะคีย์ / ค่าลงตามปัจจัยบางอย่าง ( reduction_factor ) ขณะเดียวกันก็ปรับมิติของการสืบค้นและคีย์ ( ssa_dim_key ) IWSA ดำเนินการให้ความสนใจตนเองภายในหน้าต่างท้องถิ่น คล้ายกับเอกสาร Vision Transformer อื่นๆ อย่างไรก็ตาม พวกเขาเพิ่มค่าที่เหลือซึ่งส่งผ่านการบิดของเคอร์เนลขนาด 3 ซึ่งพวกเขาตั้งชื่อว่า Local Interactive Module (LIM)
พวกเขาอ้างในเอกสารนี้ว่ารูปแบบนี้มีประสิทธิภาพเหนือกว่า Swin Transformer และยังแสดงให้เห็นถึงประสิทธิภาพที่แข่งขันกับ Crossformer ได้อีกด้วย
คุณสามารถใช้ได้ดังต่อไปนี้ (เช่น ScalableViT-S)
import torch
from vit_pytorch . scalable_vit import ScalableViT
model = ScalableViT (
num_classes = 1000 ,
dim = 64 , # starting model dimension. at every stage, dimension is doubled
heads = ( 2 , 4 , 8 , 16 ), # number of attention heads at each stage
depth = ( 2 , 2 , 20 , 2 ), # number of transformer blocks at each stage
ssa_dim_key = ( 40 , 40 , 40 , 32 ), # the dimension of the attention keys (and queries) for SSA. in the paper, they represented this as a scale factor on the base dimension per key (ssa_dim_key / dim_key)
reduction_factor = ( 8 , 4 , 2 , 1 ), # downsampling of the key / values in SSA. in the paper, this was represented as (reduction_factor ** -2)
window_size = ( 64 , 32 , None , None ), # window size of the IWSA at each stage. None means no windowing needed
dropout = 0.1 , # attention and feedforward dropout
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = model ( img ) # (1, 1000) 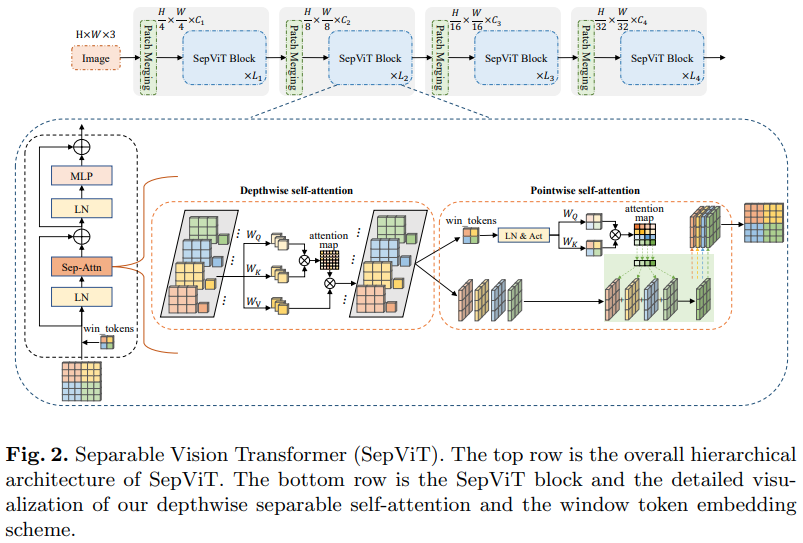
บทความ Bytedance AI อีกฉบับ นำเสนอเลเยอร์การใส่ใจในเชิงลึกตามจุดซึ่งดูเหมือนว่าได้รับแรงบันดาลใจส่วนใหญ่มาจากการบิดเบี้ยวที่แยกส่วนเชิงลึกของ mobilenet สิ่งที่น่าสนใจที่สุดคือการนำแผนผังคุณลักษณะจากระยะความสนใจในตนเองเชิงลึกกลับมาใช้ใหม่เป็นค่าสำหรับการใส่ใจตนเองตามจุด ดังที่แสดงในแผนภาพด้านบน
ฉันได้ตัดสินใจที่จะรวมเฉพาะเวอร์ชันของ SepViT เข้ากับเลเยอร์การใส่ใจตนเองเฉพาะนี้ เนื่องจากเลเยอร์ความสนใจที่จัดกลุ่มนั้นไม่ได้โดดเด่นหรือแปลกใหม่ และผู้แต่งยังไม่ชัดเจนว่าพวกเขาปฏิบัติต่อโทเค็นหน้าต่างสำหรับเลเยอร์การเอาใจใส่ตนเองของกลุ่มอย่างไร นอกจากนี้ ดูเหมือนว่าด้วยเลเยอร์ DSSA เพียงอย่างเดียว พวกเขาสามารถเอาชนะ Swin ได้
อดีต. SepViT-Lite
import torch
from vit_pytorch . sep_vit import SepViT
v = SepViT (
num_classes = 1000 ,
dim = 32 , # dimensions of first stage, which doubles every stage (32, 64, 128, 256) for SepViT-Lite
dim_head = 32 , # attention head dimension
heads = ( 1 , 2 , 4 , 8 ), # number of heads per stage
depth = ( 1 , 2 , 6 , 2 ), # number of transformer blocks per stage
window_size = 7 , # window size of DSS Attention block
dropout = 0.1 # dropout
)
img = torch . randn ( 1 , 3 , 224 , 224 )
preds = v ( img ) # (1, 1000) 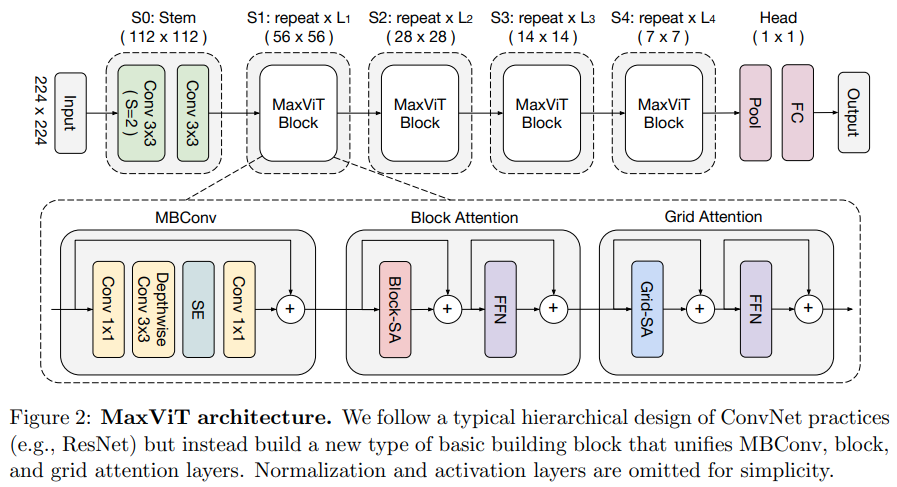
บทความนี้เสนอเครือข่าย Convolutional / Attention แบบไฮบริด โดยใช้ MBConv จากด้าน Convolution จากนั้นบล็อก / Grid ตามแนวแกนของความสนใจ
พวกเขายังอ้างว่าเครื่องแปลงสัญญาณภาพเฉพาะนี้ดีสำหรับโมเดลกำเนิด (GAN)
อดีต. แม็กซ์ไวที-เอส
import torch
from vit_pytorch . max_vit import MaxViT
v = MaxViT (
num_classes = 1000 ,
dim_conv_stem = 64 , # dimension of the convolutional stem, would default to dimension of first layer if not specified
dim = 96 , # dimension of first layer, doubles every layer
dim_head = 32 , # dimension of attention heads, kept at 32 in paper
depth = ( 2 , 2 , 5 , 2 ), # number of MaxViT blocks per stage, which consists of MBConv, block-like attention, grid-like attention
window_size = 7 , # window size for block and grids
mbconv_expansion_rate = 4 , # expansion rate of MBConv
mbconv_shrinkage_rate = 0.25 , # shrinkage rate of squeeze-excitation in MBConv
dropout = 0.1 # dropout
)
img = torch . randn ( 2 , 3 , 224 , 224 )
preds = v ( img ) # (2, 1000) 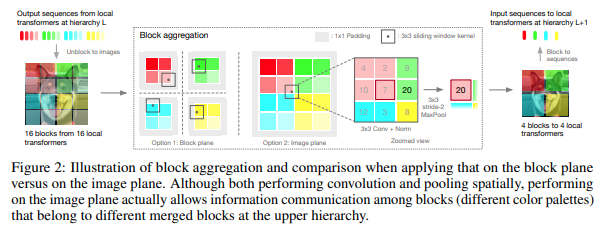
บทความนี้ตัดสินใจที่จะประมวลผลรูปภาพในลำดับชั้น โดยให้ความสนใจเฉพาะภายในโทเค็นของบล็อกในเครื่อง ซึ่งจะรวมเข้าด้วยกันเมื่อเลื่อนลำดับชั้นขึ้นไป การรวมเสร็จสิ้นในระนาบรูปภาพ และมีการบิดและ Maxpool ที่ตามมาเพื่อให้ส่งข้อมูลข้ามขอบเขตได้
คุณสามารถใช้รหัสต่อไปนี้ (เช่น NestT-T)
import torch
from vit_pytorch . nest import NesT
nest = NesT (
image_size = 224 ,
patch_size = 4 ,
dim = 96 ,
heads = 3 ,
num_hierarchies = 3 , # number of hierarchies
block_repeats = ( 2 , 2 , 8 ), # the number of transformer blocks at each hierarchy, starting from the bottom
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 224 , 224 )
pred = nest ( img ) # (1, 1000) 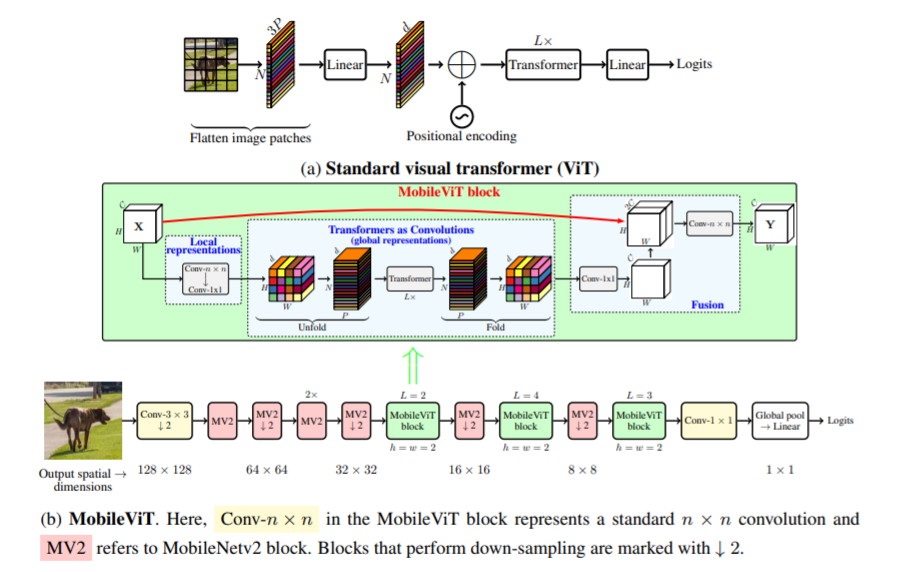
บทความนี้แนะนำ MobileViT ซึ่งเป็นวิชันทรานส์ฟอร์มเมอร์น้ำหนักเบาและใช้งานทั่วไปสำหรับอุปกรณ์เคลื่อนที่ MobileViT นำเสนอมุมมองที่แตกต่างสำหรับการประมวลผลข้อมูลทั่วโลกด้วยหม้อแปลง
คุณสามารถใช้รหัสต่อไปนี้ (เช่น mobilevit_xs)
import torch
from vit_pytorch . mobile_vit import MobileViT
mbvit_xs = MobileViT (
image_size = ( 256 , 256 ),
dims = [ 96 , 120 , 144 ],
channels = [ 16 , 32 , 48 , 48 , 64 , 64 , 80 , 80 , 96 , 96 , 384 ],
num_classes = 1000
)
img = torch . randn ( 1 , 3 , 256 , 256 )
pred = mbvit_xs ( img ) # (1, 1000) 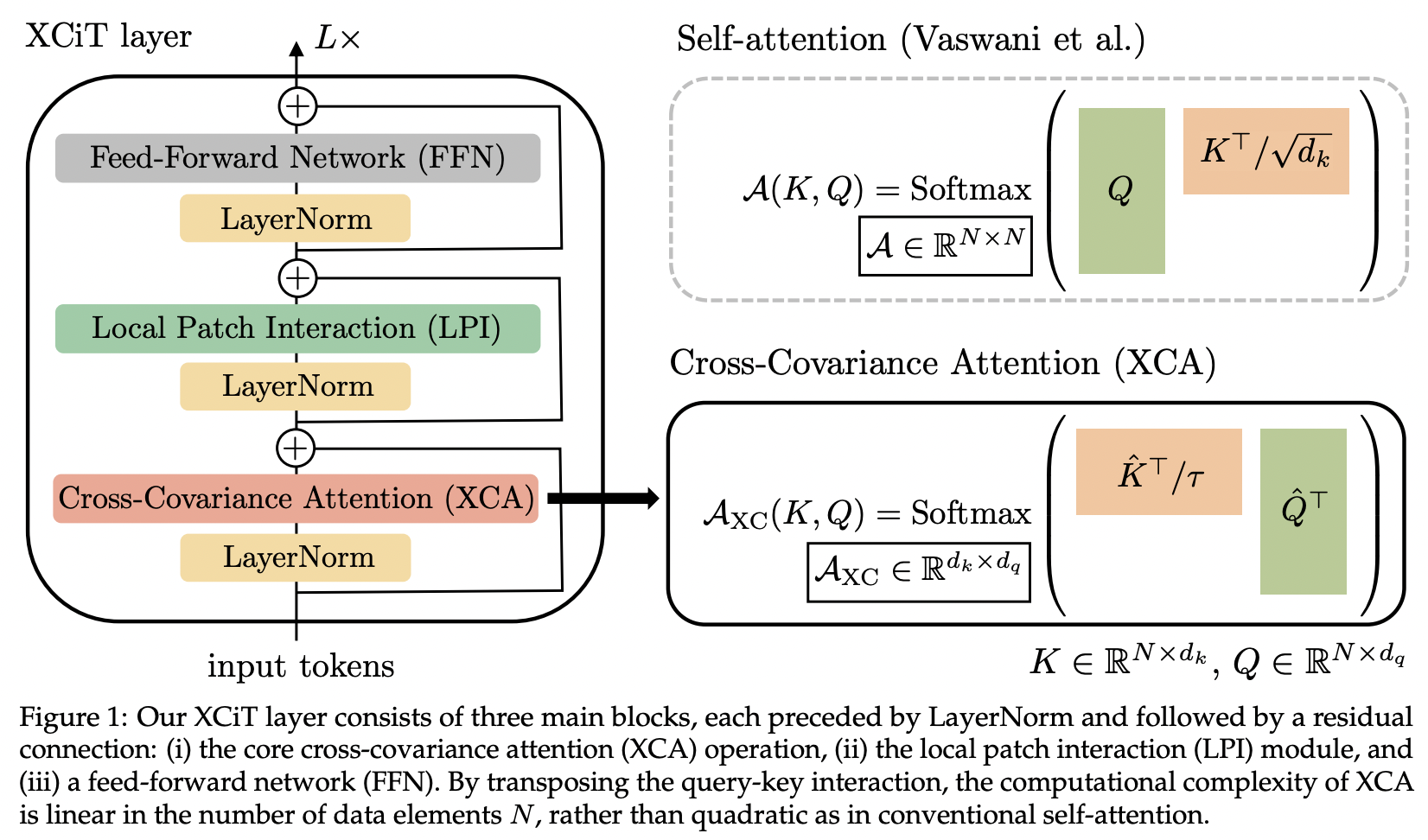
บทความนี้จะแนะนำความสนใจเกี่ยวกับความแปรปรวนร่วมข้าม (ตัวย่อ XCA) เราสามารถคิดว่ามันเป็นการให้ความสนใจในมิติคุณสมบัติมากกว่ามิติเชิงพื้นที่ (มุมมองอื่นจะเป็นการบิดแบบไดนามิก 1x1 เคอร์เนลเป็นแผนที่ความสนใจที่กำหนดโดยความสัมพันธ์เชิงพื้นที่)
ในทางเทคนิคแล้ว จำนวนนี้เป็นเพียงการย้ายแบบสอบถาม คีย์ ค่า ก่อนที่จะดำเนินการความสนใจความคล้ายคลึงโคไซน์กับอุณหภูมิที่เรียนรู้
import torch
from vit_pytorch . xcit import XCiT
v = XCiT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 , # depth of xcit transformer
cls_depth = 2 , # depth of cross attention of CLS tokens to patch, attention pool at end
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1 ,
layer_dropout = 0.05 , # randomly dropout 5% of the layers
local_patch_kernel_size = 3 # kernel size of the local patch interaction module (depthwise convs)
)
img = torch . randn ( 1 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) 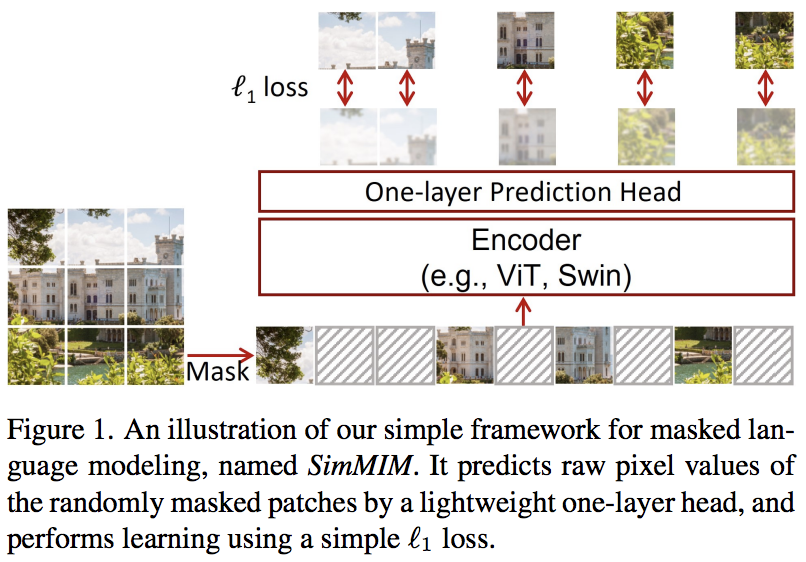
บทความนี้เสนอรูปแบบการสร้างแบบจำลองภาพมาสก์อย่างง่าย (SimMIM) โดยใช้เพียงการฉายภาพเชิงเส้นจากโทเค็นที่มาสก์ลงในพื้นที่พิกเซล ตามด้วยการสูญเสีย L1 พร้อมค่าพิกเซลของแพตช์ที่มาสก์ ผลลัพธ์สามารถแข่งขันกับแนวทางอื่นๆ ที่ซับซ้อนกว่าได้
คุณสามารถใช้สิ่งนี้ได้ดังนี้
import torch
from vit_pytorch import ViT
from vit_pytorch . simmim import SimMIM
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mim = SimMIM (
encoder = v ,
masking_ratio = 0.5 # they found 50% to yield the best results
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mim ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
torch . save ( v . state_dict (), './trained-vit.pt' )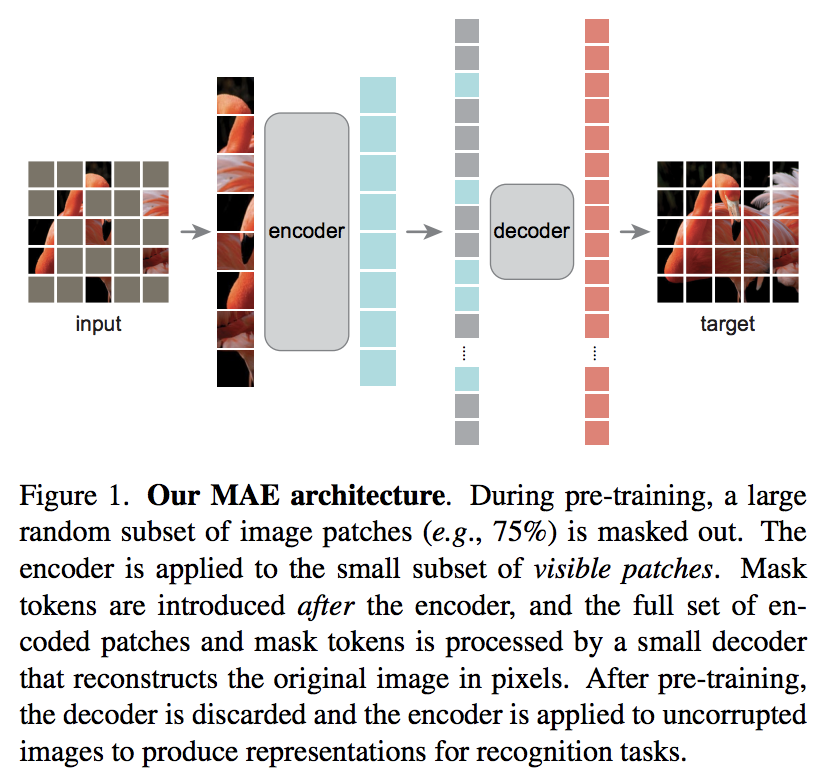
บทความใหม่ของ Kaiming He เสนอรูปแบบการเข้ารหัสอัตโนมัติแบบง่ายๆ โดยที่ Vision Transformer จะเข้าร่วมกับชุดของแพตช์ที่ไม่ได้ปกปิด และตัวถอดรหัสที่มีขนาดเล็กกว่าจะพยายามสร้างค่าพิกเซลที่ถูกมาสก์ขึ้นมาใหม่
การตรวจสอบบทความฉบับย่อของ DeepReader
AI Coffeebreak กับเลติเทีย
คุณสามารถใช้มันด้วยรหัสต่อไปนี้
import torch
from vit_pytorch import ViT , MAE
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
mae = MAE (
encoder = v ,
masking_ratio = 0.75 , # the paper recommended 75% masked patches
decoder_dim = 512 , # paper showed good results with just 512
decoder_depth = 6 # anywhere from 1 to 8
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mae ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )ต้องขอบคุณ Zach ที่ทำให้คุณสามารถฝึกฝนโดยใช้งานการทำนายแพทช์แบบสวมหน้ากากต้นฉบับที่นำเสนอในรายงานได้ ด้วยโค้ดต่อไปนี้
import torch
from vit_pytorch import ViT
from vit_pytorch . mpp import MPP
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
mpp_trainer = MPP (
transformer = model ,
patch_size = 32 ,
dim = 1024 ,
mask_prob = 0.15 , # probability of using token in masked prediction task
random_patch_prob = 0.30 , # probability of randomly replacing a token being used for mpp
replace_prob = 0.50 , # probability of replacing a token being used for mpp with the mask token
)
opt = torch . optim . Adam ( mpp_trainer . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . FloatTensor ( 20 , 3 , 256 , 256 ). uniform_ ( 0. , 1. )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = mpp_trainer ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )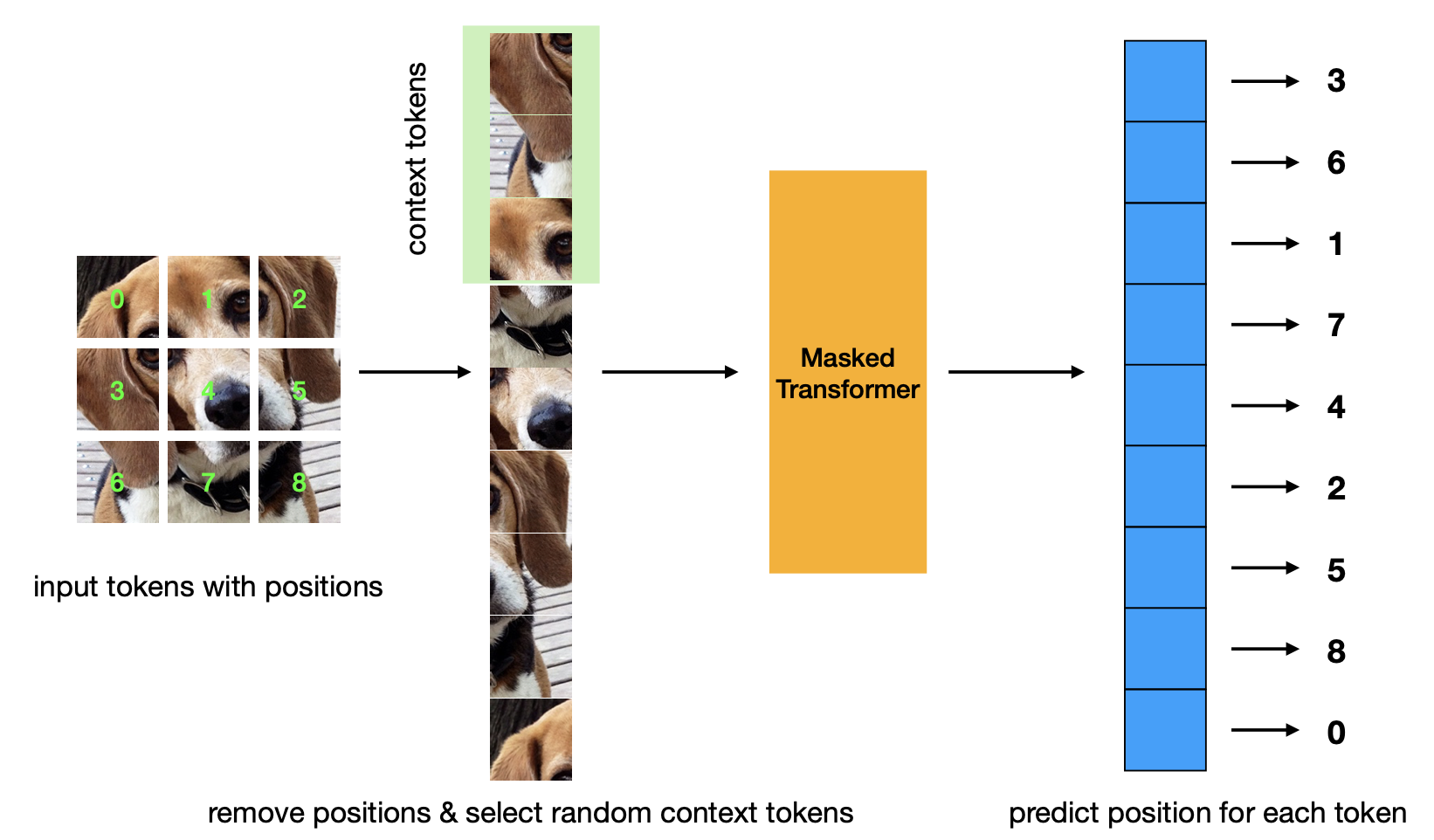
เอกสารใหม่ที่แนะนำเกณฑ์ก่อนการฝึกอบรมการทำนายตำแหน่งที่สวมหน้ากาก กลยุทธ์นี้มีประสิทธิภาพมากกว่ากลยุทธ์ Masked Autoencoder และมีประสิทธิภาพที่เทียบเคียงได้
import torch
from vit_pytorch . mp3 import ViT , MP3
v = ViT (
num_classes = 1000 ,
image_size = 256 ,
patch_size = 8 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
)
mp3 = MP3 (
vit = v ,
masking_ratio = 0.75
)
images = torch . randn ( 8 , 3 , 256 , 256 )
loss = mp3 ( images )
loss . backward ()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch . save ( v . state_dict (), './trained-vit.pt' )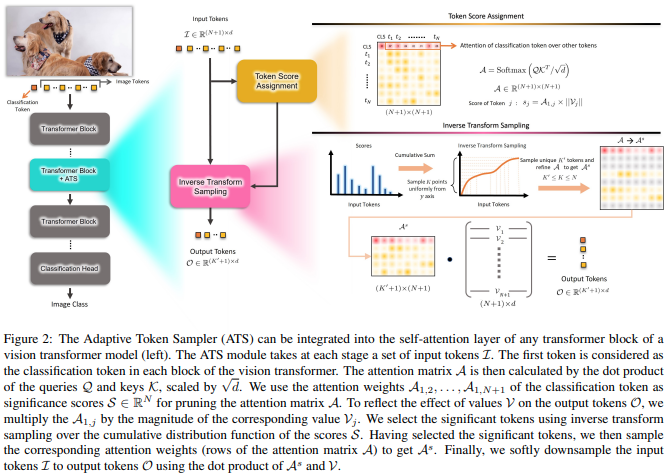
บทความนี้เสนอให้ใช้คะแนนความสนใจของ CLS ซึ่งชั่งน้ำหนักใหม่โดยบรรทัดฐานของส่วนหัวของค่า เพื่อละทิ้งโทเค็นที่ไม่สำคัญในเลเยอร์ต่างๆ
import torch
from vit_pytorch . ats_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
max_tokens_per_depth = ( 256 , 128 , 64 , 32 , 16 , 8 ), # a tuple that denotes the maximum number of tokens that any given layer should have. if the layer has greater than this amount, it will undergo adaptive token sampling
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000)
# you can also get a list of the final sampled patch ids
# a value of -1 denotes padding
preds , token_ids = v ( img , return_sampled_token_ids = True ) # (4, 1000), (4, <=8) 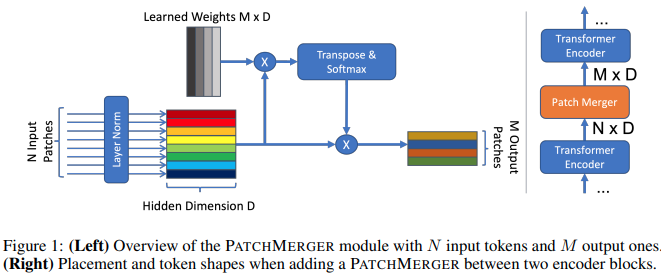
บทความนี้เสนอโมดูลอย่างง่าย (Patch Merger) เพื่อลดจำนวนโทเค็นที่ชั้นใดๆ ของวิชันทรานส์ฟอร์มเมอร์โดยไม่ทำให้ประสิทธิภาพลดลง
import torch
from vit_pytorch . vit_with_patch_merger import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 12 ,
heads = 8 ,
patch_merge_layer = 6 , # at which transformer layer to do patch merging
patch_merge_num_tokens = 8 , # the output number of tokens from the patch merge
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000) เราสามารถใช้โมดูล PatchMerger ได้ด้วยตัวเอง
import torch
from vit_pytorch . vit_with_patch_merger import PatchMerger
merger = PatchMerger (
dim = 1024 ,
num_tokens_out = 8 # output number of tokens
)
features = torch . randn ( 4 , 256 , 1024 ) # (batch, num tokens, dimension)
out = merger ( features ) # (4, 8, 1024) 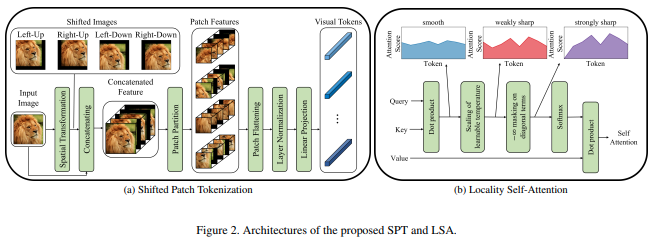
บทความนี้เสนอฟังก์ชันรูปภาพใหม่เพื่อแพตช์ที่รวมการเปลี่ยนแปลงของรูปภาพ ก่อนที่จะทำให้เป็นมาตรฐานและแบ่งรูปภาพออกเป็นแพตช์ ฉันพบว่าการเปลี่ยนเกียร์มีประโยชน์อย่างมากในงานของหม้อแปลงอื่นๆ ดังนั้นจึงตัดสินใจรวมสิ่งนี้ไว้เพื่อการสำรวจเพิ่มเติม นอกจากนี้ยังรวมถึง LSA ที่มีอุณหภูมิที่เรียนรู้และปกปิดโทเค็นที่ไม่สนใจตัวมันเอง
คุณสามารถใช้ได้ดังนี้:
import torch
from vit_pytorch . vit_for_small_dataset import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (1, 1000) คุณยังสามารถใช้ SPT จากเอกสารนี้เป็นโมดูลแบบสแตนด์อโลนได้
import torch
from vit_pytorch . vit_for_small_dataset import SPT
spt = SPT (
dim = 1024 ,
patch_size = 16 ,
channels = 3
)
img = torch . randn ( 4 , 3 , 256 , 256 )
tokens = spt ( img ) # (4, 256, 1024) ตามคำขอที่ได้รับความนิยม ฉันจะเริ่มขยายสถาปัตยกรรมบางส่วนในพื้นที่เก็บข้อมูลนี้เป็น 3D ViT เพื่อใช้กับวิดีโอ การสร้างภาพทางการแพทย์ ฯลฯ
คุณจะต้องส่งผ่านไฮเปอร์พารามิเตอร์เพิ่มเติมอีกสองรายการ: (1) จำนวนเฟรม frames และ (2) ขนาดแพตช์ตามขนาดเฟรม frame_patch_size
สำหรับผู้เริ่มต้น 3D ViT
import torch
from vit_pytorch . vit_3d import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)3D ง่าย ViT
import torch
from vit_pytorch . simple_vit_3d import SimpleViT
v = SimpleViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000)CCT เวอร์ชัน 3 มิติ
import torch
from vit_pytorch . cct_3d import CCT
cct = CCT (
img_size = 224 ,
num_frames = 8 ,
embedding_dim = 384 ,
n_conv_layers = 2 ,
frame_kernel_size = 3 ,
kernel_size = 7 ,
stride = 2 ,
padding = 3 ,
pooling_kernel_size = 3 ,
pooling_stride = 2 ,
pooling_padding = 1 ,
num_layers = 14 ,
num_heads = 6 ,
mlp_ratio = 3. ,
num_classes = 1000 ,
positional_embedding = 'learnable'
)
video = torch . randn ( 1 , 3 , 8 , 224 , 224 ) # (batch, channels, frames, height, width)
pred = cct ( video )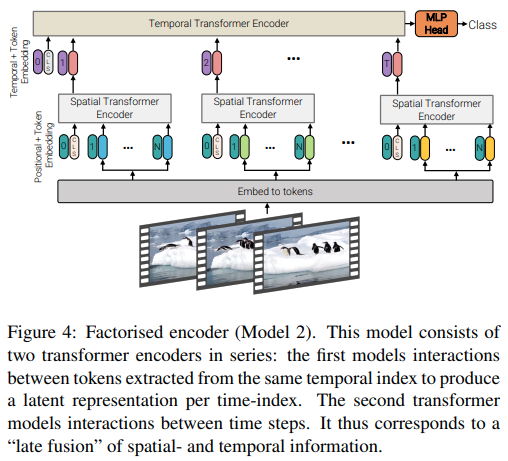
บทความนี้นำเสนอสถาปัตยกรรมที่แตกต่างกัน 3 ประเภทเพื่อการดึงดูดความสนใจของวิดีโออย่างมีประสิทธิภาพ โดยธีมหลักคือการแยกตัวประกอบความสนใจในพื้นที่และเวลา พื้นที่เก็บข้อมูลนี้ประกอบด้วยตัวเข้ารหัสแบบแยกตัวประกอบและตัวแปรการเอาใจใส่ตนเองแบบแยกตัวประกอบ ตัวแปรตัวเข้ารหัสแบบแยกตัวประกอบคือหม้อแปลงเชิงพื้นที่ตามด้วยหม้อแปลงชั่วคราว ตัวแปรการเอาใจใส่ตนเองแบบแยกตัวประกอบคือหม้อแปลงไฟฟ้าเชิงพื้นที่-ชั่วคราวซึ่งมีชั้นการเอาใจใส่ตนเองเชิงพื้นที่และเชิงเวลาสลับกัน
import torch
from vit_pytorch . vivit import ViT
v = ViT (
image_size = 128 , # image size
frames = 16 , # number of frames
image_patch_size = 16 , # image patch size
frame_patch_size = 2 , # frame patch size
num_classes = 1000 ,
dim = 1024 ,
spatial_depth = 6 , # depth of the spatial transformer
temporal_depth = 6 , # depth of the temporal transformer
heads = 8 ,
mlp_dim = 2048 ,
variant = 'factorized_encoder' , # or 'factorized_self_attention'
)
video = torch . randn ( 4 , 3 , 16 , 128 , 128 ) # (batch, channels, frames, height, width)
preds = v ( video ) # (4, 1000) 
บทความนี้เสนอให้บล็อกความสนใจและฟีดไปข้างหน้าหลายรายการพร้อมกันต่อเลเยอร์ (2 บล็อก) โดยอ้างว่าฝึกได้ง่ายกว่าโดยไม่สูญเสียประสิทธิภาพ
คุณสามารถลองใช้ตัวแปรนี้ได้ดังนี้
import torch
from vit_pytorch . parallel_vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
num_parallel_branches = 2 , # in paper, they claimed 2 was optimal
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
preds = v ( img ) # (4, 1000) 
เอกสารนี้แสดงให้เห็นว่าการเพิ่มโทเค็นหน่วยความจำที่สามารถเรียนรู้ได้ในแต่ละเลเยอร์ของวิชันทรานส์ฟอร์มเมอร์สามารถเพิ่มประสิทธิภาพผลลัพธ์ในการปรับแต่งได้อย่างมาก (นอกเหนือจากโทเค็น CLS และหัวอะแดปเตอร์เฉพาะงานที่เรียนรู้ได้)
คุณสามารถใช้สิ่งนี้กับ ViT ที่ดัดแปลงเป็นพิเศษได้ดังนี้
import torch
from vit_pytorch . learnable_memory_vit import ViT , Adapter
# normal base ViT
v = ViT (
image_size = 256 ,
patch_size = 16 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 4 , 3 , 256 , 256 )
logits = v ( img ) # (4, 1000)
# do your usual training with ViT
# ...
# then, to finetune, just pass the ViT into the Adapter class
# you can do this for multiple Adapters, as shown below
adapter1 = Adapter (
vit = v ,
num_classes = 2 , # number of output classes for this specific task
num_memories_per_layer = 5 # number of learnable memories per layer, 10 was sufficient in paper
)
logits1 = adapter1 ( img ) # (4, 2) - predict 2 classes off frozen ViT backbone with learnable memories and task specific head
# yet another task to finetune on, this time with 4 classes
adapter2 = Adapter (
vit = v ,
num_classes = 4 ,
num_memories_per_layer = 10
)
logits2 = adapter2 ( img ) # (4, 4) - predict 4 classes off frozen ViT backbone with learnable memories and task specific head 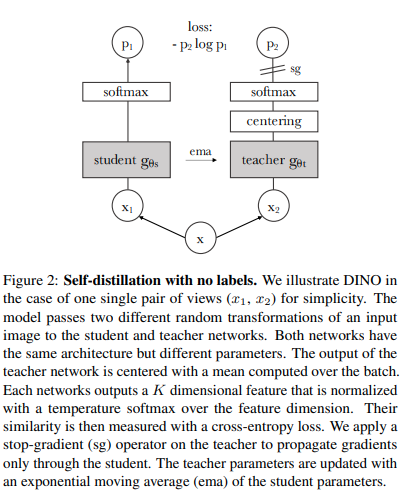
คุณสามารถฝึก ViT ด้วยเทคนิคการเรียนรู้แบบดูแลตนเองของ SOTA ล่าสุด Dino ด้วยโค้ดต่อไปนี้
วีดีโอ ยานนิค คิลเชอร์
import torch
from vit_pytorch import ViT , Dino
model = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 8 ,
mlp_dim = 2048
)
learner = Dino (
model ,
image_size = 256 ,
hidden_layer = 'to_latent' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( model . state_dict (), './pretrained-net.pt' )
EsViT เป็นเวอร์ชันหนึ่งของ Dino (จากด้านบน) ที่ได้รับการออกแบบใหม่เพื่อรองรับ ViT ที่มีประสิทธิภาพด้วยการรวมแพตช์ / การสุ่มตัวอย่างโดยคำนึงถึงการสูญเสียภูมิภาคเพิ่มเติมระหว่างมุมมองเสริม หากต้องการอ้างอิงบทคัดย่อ จะ outperforms its supervised counterpart on 17 out of 18 datasets ที่ปริมาณงานสูงกว่า 3 เท่า
แม้ว่าจะได้รับการตั้งชื่อเหมือนกับว่าเป็น ViT เวอร์ชันใหม่ แต่แท้จริงแล้วเป็นเพียงกลยุทธ์สำหรับการฝึกอบรม ViT แบบหลายขั้นตอน (ในรายงาน พวกเขามุ่งเน้นไปที่ Swin) ตัวอย่างด้านล่างจะแสดงวิธีการใช้งานกับ CvT คุณจะต้องตั้ง hidden_layer เป็นชื่อของเลเยอร์ภายใน ViT ที่มีประสิทธิภาพของคุณ ซึ่งจะส่งเอาท์พุตการแสดงภาพแบบรวมกลุ่มที่ไม่ใช่ค่าเฉลี่ย ก่อนที่จะรวมกลุ่มทั่วโลกและการฉายภาพเพื่อบันทึก
import torch
from vit_pytorch . cvt import CvT
from vit_pytorch . es_vit import EsViTTrainer
cvt = CvT (
num_classes = 1000 ,
s1_emb_dim = 64 ,
s1_emb_kernel = 7 ,
s1_emb_stride = 4 ,
s1_proj_kernel = 3 ,
s1_kv_proj_stride = 2 ,
s1_heads = 1 ,
s1_depth = 1 ,
s1_mlp_mult = 4 ,
s2_emb_dim = 192 ,
s2_emb_kernel = 3 ,
s2_emb_stride = 2 ,
s2_proj_kernel = 3 ,
s2_kv_proj_stride = 2 ,
s2_heads = 3 ,
s2_depth = 2 ,
s2_mlp_mult = 4 ,
s3_emb_dim = 384 ,
s3_emb_kernel = 3 ,
s3_emb_stride = 2 ,
s3_proj_kernel = 3 ,
s3_kv_proj_stride = 2 ,
s3_heads = 4 ,
s3_depth = 10 ,
s3_mlp_mult = 4 ,
dropout = 0.
)
learner = EsViTTrainer (
cvt ,
image_size = 256 ,
hidden_layer = 'layers' , # hidden layer name or index, from which to extract the embedding
projection_hidden_size = 256 , # projector network hidden dimension
projection_layers = 4 , # number of layers in projection network
num_classes_K = 65336 , # output logits dimensions (referenced as K in paper)
student_temp = 0.9 , # student temperature
teacher_temp = 0.04 , # teacher temperature, needs to be annealed from 0.04 to 0.07 over 30 epochs
local_upper_crop_scale = 0.4 , # upper bound for local crop - 0.4 was recommended in the paper
global_lower_crop_scale = 0.5 , # lower bound for global crop - 0.5 was recommended in the paper
moving_average_decay = 0.9 , # moving average of encoder - paper showed anywhere from 0.9 to 0.999 was ok
center_moving_average_decay = 0.9 , # moving average of teacher centers - paper showed anywhere from 0.9 to 0.999 was ok
)
opt = torch . optim . AdamW ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 8 , 3 , 256 , 256 )
for _ in range ( 1000 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of teacher encoder and teacher centers
# save your improved network
torch . save ( cvt . state_dict (), './pretrained-net.pt' )หากคุณต้องการเห็นภาพน้ำหนักความสนใจ (หลังซอฟต์แม็กซ์) สำหรับการวิจัยของคุณ เพียงทำตามขั้นตอนด้านล่าง
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . recorder import Recorder
v = Recorder ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
preds , attns = v ( img )
# there is one extra patch due to the CLS token
attns # (1, 6, 16, 65, 65) - (batch x layers x heads x patch x patch)เพื่อล้างคลาสและ hooks เมื่อคุณรวบรวมข้อมูลได้เพียงพอแล้ว
v = v . eject () # wrapper is discarded and original ViT instance is returned ในทำนองเดียวกัน คุณสามารถเข้าถึงการฝังด้วยกระดาษ Extractor
import torch
from vit_pytorch . vit import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v )
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # (1, 65, 1024) - (batch x patches x model dim) หรือพูดสำหรับ CrossViT ซึ่งมีตัวเข้ารหัสหลายสเกลที่ส่งออกการฝังสองชุดสำหรับสเกล 'ใหญ่' และ 'เล็ก'
import torch
from vit_pytorch . cross_vit import CrossViT
v = CrossViT (
image_size = 256 ,
num_classes = 1000 ,
depth = 4 ,
sm_dim = 192 ,
sm_patch_size = 16 ,
sm_enc_depth = 2 ,
sm_enc_heads = 8 ,
sm_enc_mlp_dim = 2048 ,
lg_dim = 384 ,
lg_patch_size = 64 ,
lg_enc_depth = 3 ,
lg_enc_heads = 8 ,
lg_enc_mlp_dim = 2048 ,
cross_attn_depth = 2 ,
cross_attn_heads = 8 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
# wrap the CrossViT
from vit_pytorch . extractor import Extractor
v = Extractor ( v , layer_name = 'multi_scale_encoder' ) # take embedding coming from the output of multi-scale-encoder
# forward pass now returns predictions and the attention maps
img = torch . randn ( 1 , 3 , 256 , 256 )
logits , embeddings = v ( img )
# there is one extra token due to the CLS token
embeddings # ((1, 257, 192), (1, 17, 384)) - (batch x patches x dimension) <- large and small scales respectively อาจมีบางคนที่มาจากการมองเห็นคอมพิวเตอร์ที่คิดว่าความสนใจยังคงได้รับผลกระทบจากต้นทุนกำลังสอง โชคดีที่เรามีเทคนิคใหม่ๆ มากมายที่อาจช่วยได้ พื้นที่เก็บข้อมูลนี้เสนอวิธีให้คุณเสียบปลั๊กตัวแปลงความสนใจแบบกระจัดกระจายของคุณเอง
ตัวอย่างกับ Nystromformer
$ pip install nystrom-attention import torch
from vit_pytorch . efficient import ViT
from nystrom_attention import Nystromformer
efficient_transformer = Nystromformer (
dim = 512 ,
depth = 12 ,
heads = 8 ,
num_landmarks = 256
)
v = ViT (
dim = 512 ,
image_size = 2048 ,
patch_size = 32 ,
num_classes = 1000 ,
transformer = efficient_transformer
)
img = torch . randn ( 1 , 3 , 2048 , 2048 ) # your high resolution picture
v ( img ) # (1, 1000)กรอบงานความสนใจกระจัดกระจายอื่น ๆ ที่ฉันอยากจะแนะนำเป็นอย่างยิ่งคือ Routing Transformer หรือ Sinkhorn Transformer
บทความนี้จงใจใช้เครือข่ายความสนใจส่วนใหญ่ในการแถลงข้อความ หากคุณต้องการใช้การปรับปรุงล่าสุดสำหรับ Attention Nets โปรดใช้ Encoder จากที่เก็บนี้
อดีต.
$ pip install x-transformers import torch
from vit_pytorch . efficient import ViT
from x_transformers import Encoder
v = ViT (
dim = 512 ,
image_size = 224 ,
patch_size = 16 ,
num_classes = 1000 ,
transformer = Encoder (
dim = 512 , # set to be the same as the wrapper
depth = 12 ,
heads = 8 ,
ff_glu = True , # ex. feed forward GLU variant https://arxiv.org/abs/2002.05202
residual_attn = True # ex. residual attention https://arxiv.org/abs/2012.11747
)
)
img = torch . randn ( 1 , 3 , 224 , 224 )
v ( img ) # (1, 1000) คุณสามารถส่งผ่านรูปภาพที่ไม่ใช่สี่เหลี่ยมจัตุรัสได้แล้ว - คุณเพียงแค่ต้องแน่ใจว่าความสูงและความกว้างของคุณน้อยกว่าหรือเท่ากับ image_size และทั้งสองหารด้วย patch_size
อดีต.
import torch
from vit_pytorch import ViT
v = ViT (
image_size = 256 ,
patch_size = 32 ,
num_classes = 1000 ,
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 ) # <-- not a square
preds = v ( img ) # (1, 1000) import torch
from vit_pytorch import ViT
v = ViT (
num_classes = 1000 ,
image_size = ( 256 , 128 ), # image size is a tuple of (height, width)
patch_size = ( 32 , 16 ), # patch size is a tuple of (height, width)
dim = 1024 ,
depth = 6 ,
heads = 16 ,
mlp_dim = 2048 ,
dropout = 0.1 ,
emb_dropout = 0.1
)
img = torch . randn ( 1 , 3 , 256 , 128 )
preds = v ( img )มาจากคอมพิวเตอร์วิทัศน์และใหม่กับหม้อแปลงใช่ไหม? ต่อไปนี้เป็นแหล่งข้อมูลบางส่วนที่ช่วยเร่งการเรียนรู้ของฉันได้อย่างมาก
ภาพประกอบ Transformer - Jay Alammar
Transformers from Scratch - ปีเตอร์ บลูม
หม้อแปลงไฟฟ้าที่มีคำอธิบายประกอบ - Harvard NLP
@article { hassani2021escaping ,
title = { Escaping the Big Data Paradigm with Compact Transformers } ,
author = { Ali Hassani and Steven Walton and Nikhil Shah and Abulikemu Abuduweili and Jiachen Li and Humphrey Shi } ,
year = 2021 ,
url = { https://arxiv.org/abs/2104.05704 } ,
eprint = { 2104.05704 } ,
archiveprefix = { arXiv } ,
primaryclass = { cs.CV }
} @misc { dosovitskiy2020image ,
title = { An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale } ,
author = { Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby } ,
year = { 2020 } ,
eprint = { 2010.11929 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2020training ,
title = { Training data-efficient image transformers & distillation through attention } ,
author = { Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou } ,
year = { 2020 } ,
eprint = { 2012.12877 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yuan2021tokenstotoken ,
title = { Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet } ,
author = { Li Yuan and Yunpeng Chen and Tao Wang and Weihao Yu and Yujun Shi and Francis EH Tay and Jiashi Feng and Shuicheng Yan } ,
year = { 2021 } ,
eprint = { 2101.11986 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { zhou2021deepvit ,
title = { DeepViT: Towards Deeper Vision Transformer } ,
author = { Daquan Zhou and Bingyi Kang and Xiaojie Jin and Linjie Yang and Xiaochen Lian and Qibin Hou and Jiashi Feng } ,
year = { 2021 } ,
eprint = { 2103.11886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { touvron2021going ,
title = { Going deeper with Image Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alexandre Sablayrolles and Gabriel Synnaeve and Hervé Jégou } ,
year = { 2021 } ,
eprint = { 2103.17239 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021crossvit ,
title = { CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification } ,
author = { Chun-Fu Chen and Quanfu Fan and Rameswar Panda } ,
year = { 2021 } ,
eprint = { 2103.14899 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wu2021cvt ,
title = { CvT: Introducing Convolutions to Vision Transformers } ,
author = { Haiping Wu and Bin Xiao and Noel Codella and Mengchen Liu and Xiyang Dai and Lu Yuan and Lei Zhang } ,
year = { 2021 } ,
eprint = { 2103.15808 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { heo2021rethinking ,
title = { Rethinking Spatial Dimensions of Vision Transformers } ,
author = { Byeongho Heo and Sangdoo Yun and Dongyoon Han and Sanghyuk Chun and Junsuk Choe and Seong Joon Oh } ,
year = { 2021 } ,
eprint = { 2103.16302 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { graham2021levit ,
title = { LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference } ,
author = { Ben Graham and Alaaeldin El-Nouby and Hugo Touvron and Pierre Stock and Armand Joulin and Hervé Jégou and Matthijs Douze } ,
year = { 2021 } ,
eprint = { 2104.01136 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { li2021localvit ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and Kai Zhang and Jiezhang Cao and Radu Timofte and Luc Van Gool } ,
year = { 2021 } ,
eprint = { 2104.05707 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chu2021twins ,
title = { Twins: Revisiting Spatial Attention Design in Vision Transformers } ,
author = { Xiangxiang Chu and Zhi Tian and Yuqing Wang and Bo Zhang and Haibing Ren and Xiaolin Wei and Huaxia Xia and Chunhua Shen } ,
year = { 2021 } ,
eprint = { 2104.13840 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { zhang2021aggregating ,
title = { Aggregating Nested Transformers } ,
author = { Zizhao Zhang and Han Zhang and Long Zhao and Ting Chen and Tomas Pfister } ,
year = { 2021 } ,
eprint = { 2105.12723 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { chen2021regionvit ,
title = { RegionViT: Regional-to-Local Attention for Vision Transformers } ,
author = { Chun-Fu Chen and Rameswar Panda and Quanfu Fan } ,
year = { 2021 } ,
eprint = { 2106.02689 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { wang2021crossformer ,
title = { CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention } ,
author = { Wenxiao Wang and Lu Yao and Long Chen and Binbin Lin and Deng Cai and Xiaofei He and Wei Liu } ,
year = { 2021 } ,
eprint = { 2108.00154 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { caron2021emerging ,
title = { Emerging Properties in Self-Supervised Vision Transformers } ,
author = { Mathilde Caron and Hugo Touvron and Ishan Misra and Hervé Jégou and Julien Mairal and Piotr Bojanowski and Armand Joulin } ,
year = { 2021 } ,
eprint = { 2104.14294 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { he2021masked ,
title = { Masked Autoencoders Are Scalable Vision Learners } ,
author = { Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Dollár and Ross Girshick } ,
year = { 2021 } ,
eprint = { 2111.06377 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { xie2021simmim ,
title = { SimMIM: A Simple Framework for Masked Image Modeling } ,
author = { Zhenda Xie and Zheng Zhang and Yue Cao and Yutong Lin and Jianmin Bao and Zhuliang Yao and Qi Dai and Han Hu } ,
year = { 2021 } ,
eprint = { 2111.09886 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { fayyaz2021ats ,
title = { ATS: Adaptive Token Sampling For Efficient Vision Transformers } ,
author = { Mohsen Fayyaz and Soroush Abbasi Kouhpayegani and Farnoush Rezaei Jafari and Eric Sommerlade and Hamid Reza Vaezi Joze and Hamed Pirsiavash and Juergen Gall } ,
year = { 2021 } ,
eprint = { 2111.15667 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mehta2021mobilevit ,
title = { MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer } ,
author = { Sachin Mehta and Mohammad Rastegari } ,
year = { 2021 } ,
eprint = { 2110.02178 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { lee2021vision ,
title = { Vision Transformer for Small-Size Datasets } ,
author = { Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song } ,
year = { 2021 } ,
eprint = { 2112.13492 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { renggli2022learning ,
title = { Learning to Merge Tokens in Vision Transformers } ,
author = { Cedric Renggli and André Susano Pinto and Neil Houlsby and Basil Mustafa and Joan Puigcerver and Carlos Riquelme } ,
year = { 2022 } ,
eprint = { 2202.12015 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yang2022scalablevit ,
title = { ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer } ,
author = { Rui Yang and Hailong Ma and Jie Wu and Yansong Tang and Xuefeng Xiao and Min Zheng and Xiu Li } ,
year = { 2022 } ,
eprint = { 2203.10790 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Touvron2022ThreeTE ,
title = { Three things everyone should know about Vision Transformers } ,
author = { Hugo Touvron and Matthieu Cord and Alaaeldin El-Nouby and Jakob Verbeek and Herv'e J'egou } ,
year = { 2022 }
} @inproceedings { Sandler2022FinetuningIT ,
title = { Fine-tuning Image Transformers using Learnable Memory } ,
author = { Mark Sandler and Andrey Zhmoginov and Max Vladymyrov and Andrew Jackson } ,
year = { 2022 }
} @inproceedings { Li2022SepViTSV ,
title = { SepViT: Separable Vision Transformer } ,
author = { Wei Li and Xing Wang and Xin Xia and Jie Wu and Xuefeng Xiao and Minghang Zheng and Shiping Wen } ,
year = { 2022 }
} @inproceedings { Tu2022MaxViTMV ,
title = { MaxViT: Multi-Axis Vision Transformer } ,
author = { Zhengzhong Tu and Hossein Talebi and Han Zhang and Feng Yang and Peyman Milanfar and Alan Conrad Bovik and Yinxiao Li } ,
year = { 2022 }
} @article { Li2021EfficientSV ,
title = { Efficient Self-supervised Vision Transformers for Representation Learning } ,
author = { Chunyuan Li and Jianwei Yang and Pengchuan Zhang and Mei Gao and Bin Xiao and Xiyang Dai and Lu Yuan and Jianfeng Gao } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09785 }
} @misc { Beyer2022BetterPlainViT
title = { Better plain ViT baselines for ImageNet-1k } ,
author = { Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander } ,
publisher = { arXiv } ,
year = { 2022 }
}
@article { Arnab2021ViViTAV ,
title = { ViViT: A Video Vision Transformer } ,
author = { Anurag Arnab and Mostafa Dehghani and Georg Heigold and Chen Sun and Mario Lucic and Cordelia Schmid } ,
journal = { 2021 IEEE/CVF International Conference on Computer Vision (ICCV) } ,
year = { 2021 } ,
pages = { 6816-6826 }
} @article { Liu2022PatchDropoutEV ,
title = { PatchDropout: Economizing Vision Transformers Using Patch Dropout } ,
author = { Yue Liu and Christos Matsoukas and Fredrik Strand and Hossein Azizpour and Kevin Smith } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.07220 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @inproceedings { Dehghani2023PatchNP ,
title = { Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution } ,
author = { Mostafa Dehghani and Basil Mustafa and Josip Djolonga and Jonathan Heek and Matthias Minderer and Mathilde Caron and Andreas Steiner and Joan Puigcerver and Robert Geirhos and Ibrahim M. Alabdulmohsin and Avital Oliver and Piotr Padlewski and Alexey A. Gritsenko and Mario Luvci'c and Neil Houlsby } ,
year = { 2023 }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @inproceedings { ElNouby2021XCiTCI ,
title = { XCiT: Cross-Covariance Image Transformers } ,
author = { Alaaeldin El-Nouby and Hugo Touvron and Mathilde Caron and Piotr Bojanowski and Matthijs Douze and Armand Joulin and Ivan Laptev and Natalia Neverova and Gabriel Synnaeve and Jakob Verbeek and Herv{'e} J{'e}gou } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2021 } ,
url = { https://api.semanticscholar.org/CorpusID:235458262 }
} @inproceedings { Koner2024LookupViTCV ,
title = { LookupViT: Compressing visual information to a limited number of tokens } ,
author = { Rajat Koner and Gagan Jain and Prateek Jain and Volker Tresp and Sujoy Paul } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:271244592 }
} @article { Bao2022AllAW ,
title = { All are Worth Words: A ViT Backbone for Diffusion Models } ,
author = { Fan Bao and Shen Nie and Kaiwen Xue and Yue Cao and Chongxuan Li and Hang Su and Jun Zhu } ,
journal = { 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 22669-22679 } ,
url = { https://api.semanticscholar.org/CorpusID:253581703 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Loshchilov2024nGPTNT ,
title = { nGPT: Normalized Transformer with Representation Learning on the Hypersphere } ,
author = { Ilya Loshchilov and Cheng-Ping Hsieh and Simeng Sun and Boris Ginsburg } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273026160 }
} @inproceedings { Liu2017DeepHL ,
title = { Deep Hyperspherical Learning } ,
author = { Weiyang Liu and Yanming Zhang and Xingguo Li and Zhen Liu and Bo Dai and Tuo Zhao and Le Song } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2017 } ,
url = { https://api.semanticscholar.org/CorpusID:5104558 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}ฉันจินตนาการถึงเวลาที่เราจะต้องเป็นหุ่นยนต์ว่าสุนัขเป็นอย่างไรสำหรับมนุษย์ และฉันก็สนับสนุนเครื่องจักรเหล่านี้ — คล็อด แชนนอน


