rtdl num embeddings
v0.0.11
สำคัญ
ลองดูโมเดล DL แบบตารางใหม่: TabM
อาร์เอ็กซ์ ? แพ็คเกจ Python โครงการ DL แบบตารางอื่น ๆ
นี่คือการดำเนินการอย่างเป็นทางการของรายงาน "เกี่ยวกับการฝังสำหรับคุณลักษณะเชิงตัวเลขในการเรียนรู้เชิงลึกแบบตาราง"
ในประโยคเดียว: การแปลงคุณสมบัติต่อเนื่องแบบสเกลาร์ดั้งเดิมเป็นเวกเตอร์ก่อนที่จะผสมพวกมันในแบ็คโบนหลัก (เช่นใน MLP, Transformer ฯลฯ ) จะช่วยปรับปรุงประสิทธิภาพดาวน์สตรีมของโครงข่ายประสาทเทียมแบบตาราง
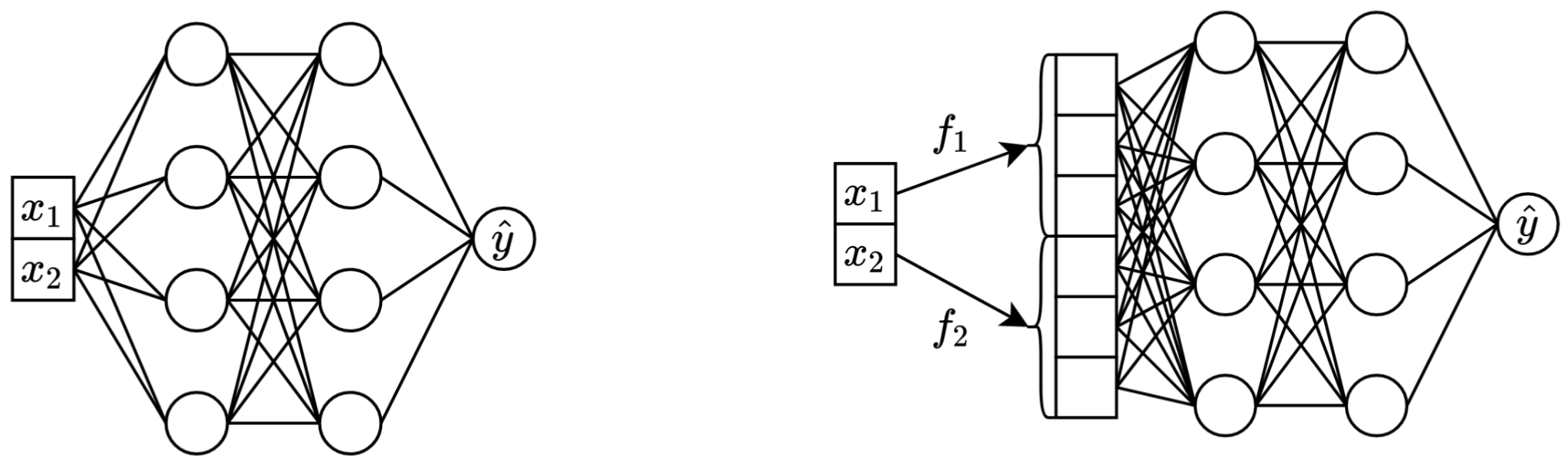
ซ้าย: vanilla MLP ใช้คุณสมบัติต่อเนื่องสองประการเป็นอินพุต
ขวา: MLP เดียวกัน แต่ตอนนี้มีการฝังสำหรับคุณสมบัติที่ต่อเนื่อง
รายละเอียดเพิ่มเติม:
พูดอย่างเคร่งครัดไม่มีคำอธิบายเดียว เห็นได้ชัดว่าการฝังช่วยจัดการกับความท้าทายต่างๆ ที่เกี่ยวข้องกับคุณลักษณะที่ต่อเนื่อง และปรับปรุงคุณสมบัติการปรับให้เหมาะสมโดยรวมของแบบจำลอง
โดยเฉพาะอย่างยิ่ง คุณลักษณะต่อเนื่องที่มีการกระจายไม่สม่ำเสมอ (และการกระจายรอยต่อที่ผิดปกติกับป้ายกำกับ) เป็นเรื่องปกติในข้อมูลแบบตารางในโลกแห่งความเป็นจริง และสิ่งเหล่านี้ก่อให้เกิดความท้าทายในการเพิ่มประสิทธิภาพขั้นพื้นฐานที่สำคัญสำหรับโมเดล DL แบบตารางแบบดั้งเดิม ข้อมูลอ้างอิงที่ดี สำหรับการทำความเข้าใจความท้าทายนี้ (และตัวอย่างที่ดีของการจัดการกับความท้าทายเหล่านั้นด้วยการเปลี่ยนพื้นที่อินพุต) คือบทความ "คุณสมบัติฟูเรียร์ให้เครือข่ายเรียนรู้ฟังก์ชันความถี่สูงในโดเมนมิติต่ำ"
อย่างไรก็ตาม ยังไม่ชัดเจนว่าการแจกแจงแบบไม่สม่ำเสมอเป็นสาเหตุเดียวที่ทำให้การฝังมีประโยชน์หรือไม่
แพ็คเกจ Python ในไดเร็กทอรี package/ เป็นวิธีที่แนะนำในการใช้กระดาษในทางปฏิบัติและสำหรับการทำงานในอนาคต
เอกสารที่เหลือ :
ไดเร็กทอรี exp/ ประกอบด้วยผลลัพธ์จำนวนมากและไฮเปอร์พารามิเตอร์ (ปรับแต่ง) สำหรับโมเดลและชุดข้อมูลต่างๆ ที่ใช้ในรายงาน
ตัวอย่างเช่น เรามาสำรวจเมตริกสำหรับโมเดล MLP กัน ขั้นแรก มาโหลดรายงานกันก่อน (ไฟล์ report.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])ตอนนี้ สำหรับแต่ละชุดข้อมูล มาคำนวณคะแนนการทดสอบโดยเฉลี่ยจากเมล็ดสุ่มทั้งหมด:
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))ผลลัพธ์ตรงกับตารางที่ 3 จากกระดาษทุกประการ:
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
วิธีการข้างต้นยังสามารถใช้เพื่อสำรวจไฮเปอร์พารามิเตอร์เพื่อให้ได้สัญชาตญาณเกี่ยวกับค่าไฮเปอร์พารามิเตอร์ทั่วไปสำหรับอัลกอริทึมต่างๆ ตัวอย่างเช่น นี่คือวิธีที่เราสามารถคำนวณอัตราการเรียนรู้ที่ปรับค่ามัธยฐานสำหรับโมเดล MLP:
บันทึก
สำหรับอัลกอริธึมบางอย่าง (เช่น MLP, MLP-LR, MLP-PLR) โปรเจ็กต์ล่าสุดจะให้ผลลัพธ์ที่มากกว่าซึ่งสามารถสำรวจได้ในลักษณะเดียวกัน ตัวอย่างเช่น ดูบทความนี้ใน TabR
คำเตือน
ใช้แนวทางนี้ด้วยความระมัดระวัง เมื่อศึกษาค่าไฮเปอร์พารามิเตอร์:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358สำคัญ
ส่วนนี้ยาว ใช้ฟีเจอร์ "โครงร่าง" บน GitHub ในโปรแกรมแก้ไขข้อความเพื่อดูภาพรวมของส่วนนี้
เบื้องต้น:
/usr/local/cuda-11.1/bin อยู่ในตัวแปรสภาพแวดล้อม PATH ของคุณเสมอ export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddingsใบอนุญาต: โดยการดาวน์โหลดชุดข้อมูลของเรา คุณยอมรับใบอนุญาตของส่วนประกอบทั้งหมด เราไม่ได้กำหนดข้อจำกัดใหม่ใด ๆ นอกเหนือจากใบอนุญาตเหล่านั้น คุณสามารถดูรายชื่อแหล่งที่มาได้ในรายงาน
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tarโค้ดด้านล่างสร้างผลลัพธ์สำหรับ MLP บนชุดข้อมูล California Housing ไปป์ไลน์สำหรับอัลกอริทึมและชุดข้อมูลอื่นๆ จะเหมือนกันทุกประการ
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
ส่วน "ตัวชี้วัด" จะแสดงวิธีการสรุปผลลัพธ์ที่ได้รับ
รหัสถูกจัดระเบียบดังนี้:
bintrain4.py สำหรับโครงข่ายประสาทเทียม (ใช้การฝังและแบ็คโบนทั้งหมดจากกระดาษ)xgboost_.py สำหรับ XGBoostcatboost_.py สำหรับ CatBoosttune.py สำหรับการปรับแต่งevaluate.py สำหรับการประเมินผลensemble.py สำหรับการประกอบdatasets.py ถูกใช้เพื่อสร้างการแยกชุดข้อมูลsynthetic.py สำหรับสร้างชุดข้อมูลที่เป็นมิตรกับ GBDT แบบสังเคราะห์train1_synthetic.py สำหรับการทดลองกับข้อมูลสังเคราะห์lib มีเครื่องมือทั่วไปที่ใช้โดยโปรแกรมใน binexp ประกอบด้วยการกำหนดค่าการทดสอบและผลลัพธ์ (เมตริก การกำหนดค่าที่ปรับแต่ง ฯลฯ) ชื่อของโฟลเดอร์ที่ซ้อนกันเป็นไปตามชื่อจากกระดาษ (ตัวอย่าง: exp/mlp-plr สอดคล้องกับโมเดล MLP-PLR จากกระดาษ)package ประกอบด้วยแพ็คเกจ Python สำหรับเอกสารนี้CUDA_VISIBLE_DEVICES อย่างชัดเจนเมื่อเรียกใช้สคริปต์lib.dump_config และ lib.load_config แทนไลบรารี TOML เปล่ารูปแบบทั่วไปสำหรับการรันสคริปต์คือ:
python bin/my_script.py a/b/c.toml โดยที่ a/b/c.toml เป็นไฟล์การกำหนดค่าอินพุต (config) เอาต์พุตจะอยู่ที่ a/b/c โครงสร้างการกำหนดค่ามักจะเป็นไปตามคลาส Config จาก bin/my_script.py
นอกจากนี้ยังมีสคริปต์ที่ใช้อาร์กิวเมนต์บรรทัดคำสั่งแทนการกำหนดค่า (เช่น bin/{evaluate.py,ensemble.py} )
คุณต้องการสิ่งเหล่านี้ทั้งหมดเพื่อสร้างผลลัพธ์ แต่คุณต้องการเพียง train4.py สำหรับการทำงานในอนาคต เนื่องจาก:
bin/train1.py ใช้คุณสมบัติพิเศษจาก bin/train0.pybin/train3.py ใช้คุณสมบัติพิเศษจาก bin/train1.pybin/train4.py ใช้คุณสมบัติพิเศษจาก bin/train3.py หากต้องการดูว่าสคริปต์ตัวใดในสี่ตัวถูกใช้เพื่อทำการทดสอบ ให้ตรวจสอบช่อง "โปรแกรม" ของการกำหนดค่าการปรับแต่งที่เกี่ยวข้อง ตัวอย่างเช่น นี่คือการกำหนดค่าการปรับแต่งสำหรับ MLP บนชุดข้อมูล California Housing: exp/mlp/california/0_tuning.toml การกำหนดค่าบ่งชี้ว่ามีการใช้ bin/train0.py หมายความว่าการกำหนดค่าใน exp/mlp/california/0_evaluation เข้ากันได้กับ bin/train0.py โดยเฉพาะ เพื่อตรวจสอบว่าคุณสามารถคัดลอกหนึ่งในนั้นไปยังตำแหน่งอื่นและส่งไปที่ bin/train0.py :
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


