gigagan pytorch
0.2.20

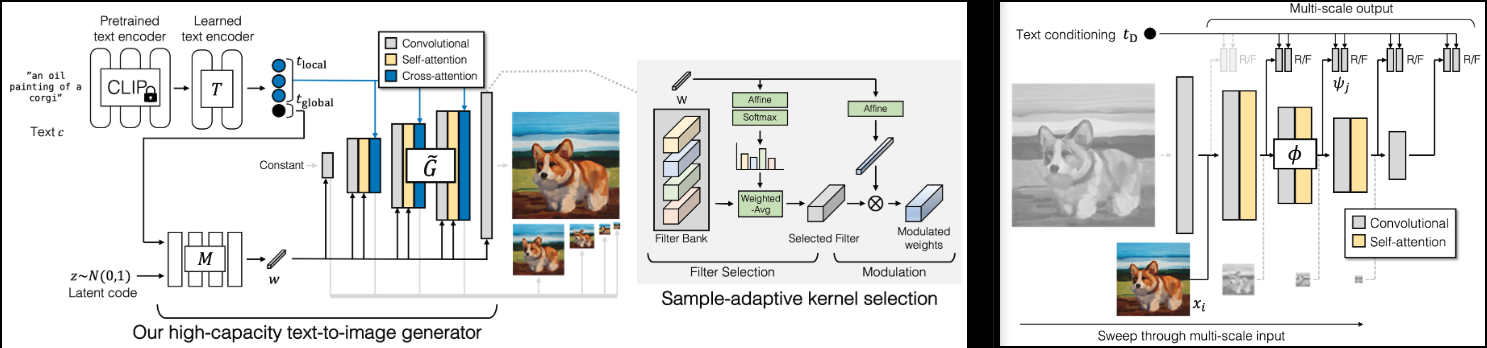
การใช้งาน GigaGAN (หน้าโครงการ) SOTA GAN ใหม่จาก Adobe
ฉันจะเพิ่มข้อค้นพบบางประการจาก Lightweight gan เพื่อการบรรจบกันที่เร็วขึ้น (ข้ามการกระตุ้นเลเยอร์) และความเสถียรที่ดีขึ้น (การสูญเสียเสริมในการสร้างใหม่ในตัวแบ่งแยก)
นอกจากนี้ ยังมีโค้ดสำหรับอัปตัวอย่างขนาด 1k - 4k ซึ่งฉันพบว่าเป็นจุดเด่นของบทความนี้
โปรดเข้าร่วมหากคุณสนใจที่จะช่วยเหลือในการจำลองแบบกับชุมชน LAION
ความเสถียร AI และ ? Huggingface สำหรับการสนับสนุนที่มีน้ำใจ เช่นเดียวกับผู้สนับสนุนอื่นๆ ของฉัน ที่ช่วยให้ฉันมีอิสระในการใช้ปัญญาประดิษฐ์แบบโอเพ่นซอร์ส
- Huggingface สำหรับห้องสมุดเร่งความเร็ว
ผู้ดูแลทุกคนที่ OpenClip สำหรับโมเดลข้อความรูปภาพการเรียนรู้เชิงเปรียบเทียบแบบโอเพ่นซอร์สของ SOTA
Xavier สำหรับการตรวจสอบโค้ดที่เป็นประโยชน์ และสำหรับการอภิปรายเกี่ยวกับวิธีการสร้างค่าคงที่ของขนาดในตัวแบ่งแยก!
@CerebralSeed สำหรับการดึงขอรหัสการสุ่มตัวอย่างเริ่มต้นสำหรับทั้งตัวสร้างและตัวเพิ่มตัวอย่าง!
Keerth สำหรับการตรวจสอบโค้ดและชี้ให้เห็นความคลาดเคลื่อนบางอย่างกับกระดาษ!
$ pip install gigagan-pytorchGAN แบบไม่มีเงื่อนไขอย่างง่ายสำหรับผู้เริ่มต้น
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)สำหรับ Unet Upsampler ที่ไม่มีเงื่อนไข
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - เครื่องกำเนิดไฟฟ้าMSG - เครื่องกำเนิดหลายระดับD - ผู้เลือกปฏิบัติMSD - ผู้แบ่งแยกหลายระดับGP - การลงโทษแบบไล่ระดับSSL - การสร้างเสริมใหม่ใน Discriminator (จาก Lightweight GAN)VD - ผู้เลือกปฏิบัติด้วยการมองเห็นVG - เครื่องกำเนิดการมองเห็นCL - เครื่องกำเนิดการสูญเสียคอนทราสต์MAL - การสูญเสียการรับรู้ที่ตรงกัน การวิ่งที่ดีควรมี G , MSG , D , MSD ที่มีค่าอยู่ระหว่าง 0 ถึง 10 และมักจะคงที่ หากเมื่อใดก็ตามหลังจากการฝึกอบรม 1,000 ขั้นตอน ค่าเหล่านี้ยังคงเป็นเลขสามหลัก นั่นหมายความว่ามีบางอย่างผิดปกติ เป็นเรื่องปกติที่ค่าตัวกำเนิดและตัวแยกแยะจะลดลงเป็นลบเป็นครั้งคราว แต่ควรแกว่งกลับไปสู่ช่วงด้านบน
ควรผลักดัน GP และ SSL ไปทาง 0 GP สามารถขัดขวางได้เป็นครั้งคราว ฉันชอบที่จะจินตนาการว่ามันเป็นเครือข่ายที่อยู่ระหว่างการศักดิ์สิทธิ์
ตอนนี้คลาส GigaGAN ติดตั้ง ? คันเร่ง คุณสามารถฝึกอบรม multi-gpu ได้อย่างง่ายดายในสองขั้นตอนโดยใช้ accelerate CLI
ที่ไดเร็กทอรีรากของโปรเจ็กต์ซึ่งมีสคริปต์การฝึกอบรม ให้รัน
$ accelerate configจากนั้นในไดเร็กทอรีเดียวกัน
$ accelerate launch train . py ตรวจสอบให้แน่ใจว่าสามารถฝึกฝนได้โดยไม่มีเงื่อนไข
อ่านเอกสารที่เกี่ยวข้องและกำจัดการสูญเสียเสริมทั้ง 3 รายการ
Unet อัพตัวอย่าง
รับการตรวจสอบโค้ดสำหรับอินพุตและเอาท์พุตแบบหลายสเกล เนื่องจากกระดาษค่อนข้างคลุมเครือ
เพิ่มสถาปัตยกรรมเครือข่ายอัปแซมปลิง
ทำให้การทำงานแบบไม่มีเงื่อนไขสำหรับทั้งตัวสร้างฐานและอัพตัวอย่าง
ทำให้การฝึกอบรมแบบมีเงื่อนไขข้อความทำงานได้สำหรับทั้งฐานและอัพตัวอย่าง
ทำให้การรีคอนมีประสิทธิภาพมากขึ้นโดยการสุ่มแพตช์สุ่มตัวอย่าง
ตรวจสอบให้แน่ใจว่าตัวสร้างและตัวแยกแยะสามารถยอมรับการเข้ารหัสข้อความ CLIP ที่เข้ารหัสล่วงหน้าได้
ทำการทบทวนการสูญเสียเสริม
เพิ่มส่วนเสริมที่แตกต่าง ซึ่งเป็นเทคนิคที่ได้รับการพิสูจน์แล้วจาก GAN สมัยก่อน
ย้ายการฉายภาพการมอดูเลตทั้งหมดไปยังคลาส Conv2d แบบปรับได้
เพิ่มความเร่ง
clip ควรเป็นทางเลือกสำหรับโมดูลทั้งหมด และจัดการโดย GigaGAN โดยมี text -> text embeds ประมวลผลครั้งเดียว
เพิ่มความสามารถในการเลือกเซ็ตย่อยแบบสุ่มจากหลายมิติเพื่อประสิทธิภาพ
พอร์ตผ่าน CLI จาก Lightweight|stylegan2-pytorch
เชื่อมต่อชุดข้อมูล laion สำหรับข้อความรูปภาพ
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

