404 ไม่พบฐานความรู้
อัปเดตล่าสุด: 28/06/2020
เพิ่มใหม่ในสัปดาห์ที่ผ่านมา:
- [บรรจุภัณฑ์และการเผยแพร่โครงการ Python](# เครื่องมือ)
สารบัญ:
- พื้นฐานคอมพิวเตอร์
- พื้นฐานทฤษฎีคอมพิวเตอร์
- เครือข่ายคอมพิวเตอร์
- ระบบปฏิบัติการ
- โครงสร้างข้อมูลและอัลกอริทึม
- ฐานข้อมูล
- พื้นฐานของการเข้ารหัส
- พื้นฐานเทคโนโลยีคอมพิวเตอร์
- ภาษา
- กรอบ
- เครื่องมือ
- เทคโนโลยี
- การวิจัยพื้นฐาน
- ความปลอดภัย
- เทคโนโลยีความปลอดภัย
- ช่องโหว่
- ความปลอดภัยของเว็บ
- การทดสอบการเจาะ
- การตรวจสอบรหัส
- ความปลอดภัยของข้อมูล
- ความปลอดภัยของคลาวด์
- เครื่องมือรักษาความปลอดภัย
- การวิจัยด้านความปลอดภัย
- การตรวจจับ APT
- ตัวอย่างที่เป็นอันตราย
- ทีมสีแดง
- วัฟ
- การตรวจจับ URL ที่เป็นอันตราย
- ต่อสู้กับการจราจรของเครื่องจักร
- การตรวจจับความผิดปกติ
- ตัวเลขและความปลอดภัย
- AI และความปลอดภัย
- การก่อสร้างความปลอดภัยขององค์กร
- การพัฒนาที่ปลอดภัย
- การทดสอบความปลอดภัย
- ผลิตภัณฑ์รักษาความปลอดภัย
- การทำงานที่ปลอดภัย
- การจัดการความปลอดภัย
- คิดว่าปลอดภัย
- สถาปัตยกรรมความปลอดภัย
- การเผชิญหน้าสีแดงและสีน้ำเงิน
- ความปลอดภัยของอินทราเน็ต
- ความปลอดภัยของข้อมูล
- เทคโนโลยีใหม่และความปลอดภัยใหม่
- ภาพรวม
- เมฆพื้นเมือง
- คอมพิวเตอร์ที่เชื่อถือได้
- DevSecOps
- การพัฒนาที่ปลอดภัย
- การพัฒนาส่วนบุคคล
- การพัฒนาอุตสาหกรรม
- ข้อมูล
- ระบบข้อมูล
- การวิเคราะห์ข้อมูลและการดำเนินงาน
- การวิเคราะห์ข้อมูลความปลอดภัย
- อัลกอริทึม
- AI
- ระบบอัลกอริทึม
- ความรู้พื้นฐาน
- การเรียนรู้ของเครื่อง
- การเรียนรู้อย่างลึกซึ้ง
- การเรียนรู้การเสริมกำลัง
- พื้นที่ใช้งาน
- การพัฒนาอุตสาหกรรม
- คุณภาพครบวงจร
- วิชาชีพ
- การวางแผนอาชีพ
- กำลังคิด
- สื่อสาร
- จัดการ
- คิด
- สิ่งที่ควรทราบ
- ภาคผนวก
- บุคลากรด้านเทคนิคดีเด่นในประเทศ
- เว็บไซต์เทคโนโลยีต่างประเทศที่ยอดเยี่ยม
- ถูกทอดทิ้ง
พื้นฐานคอมพิวเตอร์
พื้นฐานทฤษฎีคอมพิวเตอร์
ระบบปฏิบัติการ
- [การสอบเข้าระดับบัณฑิตศึกษาคอมพิวเตอร์ 408 ครอบคลุมที่สุดในเครือข่ายทั้งหมด!!!!!] Kingly Computer Operating System
- การขัดจังหวะและข้อยกเว้น
- จะเข้าใจเพจและการแบ่งส่วนการจัดการหน่วยความจำในระบบปฏิบัติการด้วยวิธีง่ายๆ ได้อย่างไร?
รายละเอียด หน่วยตรรกะของข้อมูล และหน่วยทางกายภาพของข้อมูล ความยาวไม่แน่นอนและกำหนดได้ ที่อยู่สองมิติและที่อยู่หนึ่งมิติ ข้อมูลที่สมบูรณ์ และการจัดสรรหน่วยความจำแบบไม่ต่อเนื่อง - สรุปสถานะเคอร์เนลและสถานะผู้ใช้ของระบบปฏิบัติการ
- รวบรวมระบบปฏิบัติการคำถามสัมภาษณ์ทั่วไป (จำเป็นสำหรับนักพัฒนาทุกคน)
เครือข่ายคอมพิวเตอร์
- รวบรวมคำถามสัมภาษณ์ทั่วไป – เครือข่ายคอมพิวเตอร์ (จำเป็นสำหรับนักพัฒนาทุกคน)
ความแตกต่างระหว่าง TCP และ UDP, การจับมือสามทาง TCP และคลื่นสี่ทาง, กระบวนการหลังจากที่เบราว์เซอร์เข้าสู่ URL, ประเภทคำขอของโปรโตคอล HTTP, ความแตกต่างระหว่าง GET และ POST, โปรโตคอลการแก้ไขที่อยู่ ARP - หน้ากระบวนการร้องขอเบราว์เซอร์ที่สมบูรณ์ (เบราว์เซอร์ HTTP) คำขอต่อกระบวนการตอบสนองประกอบด้วยชุดของกระบวนการ เช่น TCP handshake สามทาง เช่น การจำแนกชื่อโดเมน การเริ่มต้น TCP three-way handshake การเริ่มคำขอ HTTP เซิร์ฟเวอร์ตอบสนองต่อคำขอ HTTP และเบราว์เซอร์ได้รับโค้ด HTML และเบราว์เซอร์จะแยกวิเคราะห์โค้ด HTML และร้องขอทรัพยากรในโค้ด HTML เบราว์เซอร์จะแสดงผลเพจและนำเสนอให้กับผู้ใช้
- ความน่าเชื่อถือของ tcp หมายถึงอะไรกันแน่? - คำตอบของ CYS - Zhihu
ความน่าเชื่อถือของ TCP หมายถึงการให้บริการการรับส่งข้อมูลที่เชื่อถือได้ที่ชั้นการขนส่งโดยอิงจากชั้น IP ที่ไม่น่าเชื่อถือ โดยหลักแล้วหมายความว่าข้อมูลจะไม่ได้รับความเสียหายหรือสูญหาย และข้อมูลทั้งหมดจะถูกส่งตามลำดับที่ถูกส่ง กลไกต่อไปนี้ใช้เพื่อให้เกิดการส่งผ่าน TCP ที่เชื่อถือได้: เช็คซัม (เพื่อตรวจสอบว่าข้อมูลเสียหายหรือไม่), ตัวจับเวลา (ส่งซ้ำหากแพ็กเก็ตสูญหาย), หมายเลขลำดับ (ใช้เพื่อตรวจจับแพ็กเก็ตที่สูญหายและแพ็กเก็ตซ้ำซ้อน), การยืนยัน (การแจ้งผู้รับ ผู้ส่งว่าได้รับแพ็กเก็ตอย่างถูกต้องและคาดว่าแพ็กเก็ตถัดไป), การตอบรับเชิงลบ (ผู้รับแจ้งผู้ส่งถึงแพ็กเก็ตที่ไม่ได้รับอย่างถูกต้อง), หน้าต่างและการวางท่อ (ใช้เพื่อเพิ่มปริมาณงานของช่องสัญญาณ)
โครงสร้างข้อมูลและอัลกอริทึม
- อัลกอริทึม 3: การเรียงลำดับแบบด่วนที่ใช้บ่อยที่สุด
การเรียงลำดับและการเรียงลำดับอย่างรวดเร็ว แนวคิดของการเรียงลำดับอย่างรวดเร็วคือการขุดหลุมแล้วเติมตัวเลข + หารและพิชิต - คำถามสัมภาษณ์ของ Tencent: ถ้วยของฉันยอดเยี่ยมมาก (ฉันได้เรียนรู้แล้ว)
วิธีแก้ปัญหา 1: วิธีการแบ่งส่วน วิธีที่ 2: วิธีการแบ่งช่วงการค้นหา วิธีที่ 3: วิธีการที่ใช้สมการทางคณิตศาสตร์ วิธีที่ 4: วิธีการเขียนโปรแกรมแบบไดนามิก (เรียนรู้) อธิบายโดยสูตร: W(n, k) = 1 + min{max(W(n -1, x -1), W(n, k - x))}, x in {2, 3, ……,k} (n คือเลขถ้วย k คือจำนวนชั้น) - วิธีเขียนคำถาม Algorithm อย่างมีประสิทธิภาพ
คำถามใน LeetCode แบ่งออกเป็นสามประเภทโดยประมาณ: ตรวจสอบโครงสร้างข้อมูล: เช่นรายการที่เชื่อมโยง, สแต็ก, คิว, ตารางแฮช, กราฟ, การลอง, ไบนารีทรี ฯลฯ ตรวจสอบอัลกอริธึมพื้นฐาน: เช่นความลึกก่อน ความกว้างก่อน ไบนารี การค้นหา การเรียกซ้ำ ฯลฯ ตรวจสอบแนวคิดอัลกอริทึมพื้นฐาน: การเรียกซ้ำ การแบ่งและการพิชิต การค้นหาแบบย้อนกลับ ความละโมบ และการเขียนโปรแกรมแบบไดนามิก - การอภิปรายสั้น ๆ เกี่ยวกับอัลกอริธึมการแบ่งและการพิชิตคืออะไร (เรียนรู้)
ปัญหาการเรียงสับเปลี่ยนแบบเต็ม ปัญหาการเรียงลำดับแบบผสาน ปัญหาการเรียงลำดับแบบเร็ว และปัญหาหอคอยฮานอยภายใต้แนวคิดการแบ่งแยกและพิชิต - 2018.08 ในการสัมภาษณ์งาน จำนวนที่มากที่สุดอันดับที่ k ในอาเรย์ที่ไม่เป็นระเบียบ ค่ามัธยฐานในอาเรย์ที่ไม่เป็นระเบียบ: ตัวชี้การเรียงลำดับอย่างรวดเร็ว O(N)
- [คำอธิบายวิดีโอ] ปัญหา LeetCode หมายเลข 1: ผลรวมของตัวเลขสองตัว
- กลยุทธ์การคว้าอั่งเปาในการประชุมประจำปี
พื้นฐานของการเข้ารหัส
- คำอธิบายโดยละเอียดเกี่ยวกับข้อดีและข้อเสียของการเข้ารหัสแบบสมมาตรและการเข้ารหัสแบบไม่สมมาตร การเข้ารหัสแบบสมมาตรเรียกอีกอย่างว่าการเข้ารหัสด้วยคีย์เดียว อัลกอริทึมได้แก่: AES, RC4, 3DES รวดเร็วและสามารถใช้ได้เมื่อต้องเข้ารหัสข้อมูลจำนวนมาก ปริมาณการคำนวณมีน้อยและมีประสิทธิภาพสูง หากมีการเปิดเผยรหัสลับของฝ่ายใดฝ่ายหนึ่ง การเข้ารหัสทั้งหมดจะไม่ปลอดภัย การเข้ารหัสแบบอสมมาตร อัลกอริธึมประกอบด้วย RSA, DSA/DSS ช้าและมีความปลอดภัยสูง อัลกอริธึมแฮชประกอบด้วย MD5, SHA1 และ SHA256 อัลกอริธึมสามประเภทเป็นพื้นฐานของการสื่อสาร HTTPS
ฐานข้อมูล
- บทสัมภาษณ์ของ Tencent: อะไรคือสาเหตุที่คำสั่ง SQL ทำงานช้า?
การเรียนรู้เพิ่มเติม : โปรแกรมฐานข้อมูล (InnoDB รองรับการประมวลผลธุรกรรมและคีย์นอก แต่ช้ากว่า ISAM และ MyISAM ใช้พื้นที่และหน่วยความจำต่ำ และแทรกข้อมูลได้อย่างรวดเร็ว) การเข้ารหัสฐานข้อมูล ( character_set_client、character_set_connection、character_set_database、character_set_results、character_set_server、character_set_system ), ฐานข้อมูล ดัชนี (ดัชนีคีย์หลัก ดัชนีแบบคลัสเตอร์ และดัชนีที่ไม่ใช่แบบคลัสเตอร์) และประเด็นความรู้พื้นฐานอื่นๆ
สาเหตุที่คำสั่ง SQL ถูกดำเนินการช้าแบ่งออกเป็นสองประเภท: 1) ปกติในกรณีส่วนใหญ่ บางครั้งช้ามาก: (1) ฐานข้อมูลกำลังรีเฟรชเพจสกปรก เช่น ทำซ้ำ เมื่อบันทึกเต็ม จะต้องซิงโครไนซ์กับดิสก์ (2) พบการล็อคระหว่างการดำเนินการ เช่น การล็อคตารางและการล็อคแถว 2) มันช้าเสมอ: (1) ไม่ได้ใช้ดัชนี: ตัวอย่างเช่น ฟิลด์ไม่มีดัชนี เนื่องจากไม่สามารถใช้ดัชนีได้เนื่องจากการคำนวณและการทำงานของฟังก์ชัน (2) เลือกดัชนีที่ไม่ถูกต้องในฐานข้อมูล การค้นหาตารางแบบเต็มโดยตรง อาจเป็นไปได้ว่าปัญหาการสุ่มตัวอย่างถูกตัดสินผิดและไม่ได้ดำเนินการสแกนตารางทั้งหมด - นี่อาจเป็นโซลูชันการปรับให้เหมาะสม SQL ที่ครอบคลุมที่สุด
พื้นฐานเทคโนโลยีคอมพิวเตอร์
ภาษา
- การวิเคราะห์เชิงลึกของมัณฑนากร Python ในบทความยาว 10,000 คำ
- ตัววนซ้ำและตัวสร้าง Python3
หลาม : Iterators มีสองวิธีพื้นฐาน: iter() และ next() สามารถใช้ออบเจ็กต์ที่ทำซ้ำได้ เช่น สตริง สิ่งอันดับ และรายการต่างๆ เพื่อสร้างตัววนซ้ำ (เนื่องจากคลาสเหล่านี้ใช้ฟังก์ชัน __iter__() ภายใน หลังจากเรียก iter() มันจะกลายเป็น list_iterator object คุณจะพบว่ามีการเพิ่มเมธอด __next__() แล้ว ออบเจ็กต์ทั้งหมดที่ใช้เมธอด __iter__ และ __next__ เป็นตัววนซ้ำ) ได้รับองค์ประกอบที่ถูกต้องในระหว่างการวนซ้ำครั้งถัดไป __iter__ ส่งคืนตัววนซ้ำ __next__ ส่งคืนค่าถัดไปในคอนเทนเนอร์ ตัวสร้าง: ฟังก์ชันที่ใช้ผลผลิตเรียกว่าตัวสร้าง เมื่อเรียกใช้ฟังก์ชันตัวสร้าง ตัววนซ้ำจะถูกส่งกลับ ตัวสร้างสามารถถือเป็นตัววนซ้ำได้ - ตัววนซ้ำเทคโนโลยี python black, เครื่องกำเนิด, มัณฑนากร
- คุณรู้เกี่ยวกับฟีเจอร์ขั้นสูงของ Python มากแค่ไหน? ลองเปรียบเทียบกัน
Python : ฟังก์ชันที่ไม่ระบุชื่อแลมบ์ดา ฟังก์ชันนี้คือการแสดงนิพจน์หรือการดำเนินการอย่างง่าย ๆ โดยไม่ต้องกำหนดฟังก์ชันทั้งหมด ฟังก์ชัน Map เป็นฟังก์ชัน Python ในตัวที่สามารถใช้ฟังก์ชันกับองค์ประกอบในโครงสร้างข้อมูลต่างๆ ได้ คล้ายกับ ฟังก์ชัน Map แต่ส่งคืนเฉพาะองค์ประกอบที่ฟังก์ชันที่ใช้ส่งคืน True เท่านั้น โมดูล Itertools คือชุดเครื่องมือสำหรับการประมวลผลตัววนซ้ำ ซึ่งเป็นประเภทข้อมูลที่สามารถใช้ในคำสั่งลูป ฟังก์ชัน Generator เป็นฟังก์ชันที่คล้ายกับตัววนซ้ำ . - เหตุใดจึงต้องใช้ภาษา Go? ข้อดีของภาษา Go คืออะไร?
Go : ข้อดีของ go และการใช้งานของ go ข้อดีหลักของ go ได้แก่: ภาษาแบบคงที่, การทำงานพร้อมกันหลายรายการ, ข้ามแพลตฟอร์ม, การคอมไพล์โดยตรงลงในรหัสเครื่อง, ไลบรารี่มาตรฐานที่หลากหลาย ฯลฯ การใช้งานหลักของ go ได้แก่ การเขียนโปรแกรมเซิร์ฟเวอร์ การเขียนโปรแกรมเครือข่าย ระบบแบบกระจาย ฐานข้อมูลในหน่วยความจำ และแพลตฟอร์มคลาวด์ - ชุดฝึกจิน - การแนะนำ Golang และการติดตั้งสภาพแวดล้อม
ไป : การติดตั้งสภาพแวดล้อมของ Go ความหมายของแต่ละโฟลเดอร์หลังจากติดตั้งสภาพแวดล้อมแล้ว พื้นที่ทำงานของ go ความหมายของแต่ละโฟลเดอร์ในพื้นที่ทำงาน - ruby-on-rails - อะไรคือความแตกต่างระหว่าง Ruby และ JRuby
Ruby : Ruby เป็นภาษาโปรแกรม ล่าม Ruby ที่เราอ้างถึงโดยทั่วไปหมายถึง CRuby ทำงานในสภาพแวดล้อมของล่ามภาษา C ในเครื่อง
กรอบ
- Gin - บทนำและการใช้เฟรมเวิร์กเว็บ Golang ประสิทธิภาพสูง
Gin : เป็นเฟรมเวิร์กแอปพลิเคชันเว็บที่เขียนด้วยภาษา Go - อะไรคือความแตกต่างระหว่าง spring boot และ spring mvc?
สปริง -> สปริง MVC -> สปริงบูท
เครื่องมือ
- เปรียบเทียบระหว่างประกายไฟและพายุ
เครื่องมือเทคโนโลยีบิ๊กดาต้า - ประเภทการประมวลผล : เปรียบเทียบจากแง่มุมต่างๆ ของโมเดลการประมวลผลแบบเรียลไทม์ เวลาแฝงของการประมวลผลแบบเรียลไทม์ ปริมาณงาน กลไกการทำธุรกรรม ความทนทาน/ความทนทานต่อข้อผิดพลาด การปรับแบบไดนามิกของความขนาน ฯลฯ การสตรีม Spark เป็นโมเดลกึ่งเรียลไทม์ โดยจะรวบรวมข้อมูลภายในระยะเวลาหนึ่งและประมวลผลเป็น RDD ความล่าช้าในการคำนวณแบบเรียลไทม์อยู่ในระดับที่สองและมีปริมาณงานสูง มีความทนทานโดยเฉลี่ยและไม่รองรับการเปลี่ยนแปลง ระดับของความเท่าเทียม Storm เป็นแบบจำลองแบบเรียลไทม์เพียงอย่างเดียว รองรับกลไกการทำธุรกรรมที่สมบูรณ์ มีความแข็งแกร่งสูงและรองรับการปรับระดับความเท่าเทียมแบบไดนามิก สถานการณ์การใช้งาน : Storm สามารถใช้ในสถานการณ์ที่เรียลไทม์ไม่สามารถทนต่อความล่าช้าเกิน 1 วินาทีได้ สำหรับฟังก์ชันการประมวลผลแบบเรียลไทม์ที่ต้องการกลไกการทำธุรกรรมที่เชื่อถือได้และกลไกความน่าเชื่อถือ กล่าวคือ การประมวลผลข้อมูลมีความแม่นยำอย่างสมบูรณ์ Storm ยังสามารถ ได้รับการพิจารณา ; หากคุณต้องการปรับความขนานของโปรแกรมคอมพิวเตอร์แบบเรียลไทม์ในช่วงพีคและพีคต่ำเพื่อเพิ่มการใช้ทรัพยากรให้สูงสุด คุณยังสามารถพิจารณาพายุได้ หากโปรเจ็กต์เป็นการประมวลผลแบบเรียลไทม์ล้วนๆ ก็ไม่จำเป็น เพื่อดำเนินการค้นหาแบบโต้ตอบ SQL ที่อยู่ตรงกลาง ฯลฯ สำหรับการดำเนินการอื่นๆ การใช้ storm เป็นตัวเลือกที่ดีกว่า ในทางกลับกัน หากคุณไม่ต้องการกลไกการทำธุรกรรมแบบเรียลไทม์และเชื่อถือได้ หรือการปรับความเท่าเทียมแบบไดนามิก คุณสามารถพิจารณาการสตรีมแบบประกายไฟได้ ข้อได้เปรียบที่ใหญ่ที่สุดของการสตรีมแบบประกายไฟก็คือมันอยู่ในสแต็กเทคโนโลยีระบบนิเวศแบบประกายไฟ มุมมองมหภาคของโครงการ หากไม่เพียงแต่จำเป็นต้องใช้แบบเรียลไทม์ คอมพิวเตอร์ยังต้องมีการประมวลผลแบบแบตช์ออฟไลน์และการสืบค้นแบบโต้ตอบ และในการคำนวณแบบเรียลไทม์ ยังจะเกี่ยวข้องกับการประมวลผลแบบแบตช์ที่มีความหน่วงสูง การสืบค้นเชิงโต้ตอบ และฟังก์ชันอื่นๆ ด้วย ใช้ spark core เพื่อพัฒนาการประมวลผลแบบแบตช์ออฟไลน์ และใช้ spark sql เพื่อพัฒนาแบบสอบถามเชิงโต้ตอบ การสตรีมพัฒนาการประมวลผลแบบเรียลไทม์ ผสานรวมได้อย่างราบรื่น และมอบความสามารถในการปรับขนาดสูงให้กับระบบ คุณสมบัตินี้ช่วยเพิ่มข้อดีของ Spark Streaming อย่างมาก กรอบงานทั้งสองนั้นดีในสถานการณ์การแบ่งส่วนที่แตกต่างกัน - บทช่วยสอนการเริ่มต้นใช้งาน Ziyu Big Data Spark (เวอร์ชัน Python) (สำคัญกว่า)
- อะไรคือความแตกต่างและความเชื่อมโยงระหว่างระบบรวบรวมบันทึก flume และ kafka?
เครื่องมือเทคโนโลยีข้อมูลขนาดใหญ่ - ประเภทมิดเดิลแวร์ : คาฟคาสามารถเข้าใจได้ว่าเป็นมิดเดิลแวร์หรือระบบแคชหรือฐานข้อมูล หน้าที่หลักคือการรักษาเสถียรภาพ Flume สามารถเข้าใจได้ว่าเป็นการรวบรวมข้อมูลบันทึกที่ใช้งานอยู่ เมื่อเทียบกับ Kafka เป็นการยากที่จะส่งเสริมอินเทอร์เฟซการปรับเปลี่ยนแอปพลิเคชันออนไลน์เพื่อเขียนข้อมูลลงใน Kafka - อะไรคือข้อดีและข้อเสียระหว่าง logstash และ flume และเหมาะกับสถานการณ์ใดบ้าง
เครื่องมือเทคโนโลยีข้อมูลขนาดใหญ่ - ประเภทเอเจนต์ : ขึ้นอยู่กับข้อกำหนด ทั้ง logstash และ flume มีอยู่ในฐานะตัวแทน Logstash มีปลั๊กอินมากกว่าและผลิตภัณฑ์ที่รองรับที่ดีกว่า เช่น elasticsearch แต่ภาษาการพัฒนาของ logstash นั้นเป็น Ruby และสภาพแวดล้อมการทำงานนั้น JRuby นอกจากนี้ข้อมูลที่ส่งอาจสูญหายได้ มีกลไกภายใน flume เพื่อให้แน่ใจว่าข้อมูลจำนวนหนึ่งจะถูกส่งโดยไม่สูญเสีย ภาษาการพัฒนาของ flume คือภาษา Java ซึ่งง่ายสำหรับการพัฒนารอง ว่า jvm ใช้หน่วยความจำมาก - รายการคีย์ลัดของ Mac
MAC : ปุ่มลัดพื้นฐาน: ภาพหน้าจอ, ในแอปพลิเคชัน, การประมวลผลข้อความ, ในตัวค้นหา, ในเบราว์เซอร์; ปุ่มลัดสำหรับการเริ่มต้นและปิดระบบ MAC - แผ่นคำสั่ง Git ที่ใช้กันทั่วไป
Git : คลังสินค้าระยะไกล- "คลังสินค้าในพื้นที่->พื้นที่จัดเตรียม-"พื้นที่ทำงาน, git add., git commit -m message, git push. - git-lfs
Git-lfs : เครื่องมือขยายการอัพโหลดไฟล์ขนาดใหญ่ git - แพ็คเกจ pcap การวิเคราะห์ทางสถิติของ tshark
- [บรรจุภัณฑ์และการเผยแพร่โครงการ Python](# เครื่องมือ)
ข้อควรจำ : 1. setup.py: long_description และ long_description_content_type (สังเกตปัญหาการเรนเดอร์รูปแบบ md และ rst) 2. manifest.in กับ gitignore 3. readme.rst กับ readme.md 4. .pypirc กับ gitconfig 5. หลาม setup.py อัพโหลด bdist_wheel
เทคโนโลยี
- การถอดรหัสและ xss ( มี
\u72 ในข้อความต้นฉบับ "หลังจากการเข้ารหัสเอนทิตี html" ควรเป็น -
ลำดับการถอดรหัสเทคโนโลยีเบราว์เซอร์ : การถอดรหัสเบราว์เซอร์ส่วนใหญ่เกี่ยวข้องกับสองส่วน: เอ็นจิ้นการเรนเดอร์และตัวแยกวิเคราะห์ js ลำดับการถอดรหัส: การถอดรหัสจะดำเนินการในทุกสภาพแวดล้อม ลำดับการถอดรหัสคือ: การเข้ารหัสที่สอดคล้องกับสภาพแวดล้อมภายนอกสุดจะถูกถอดรหัสก่อน ตัวอย่างเช่น: ใน <a href=javascript:alert(1)>click</a> alert(1) อยู่ในสภาพแวดล้อม html->url->js 1. คลิกใช้การเข้ารหัส Unicode e ซึ่งไม่สามารถถอดรหัสได้ในสภาพแวดล้อม html หรือ url สามารถถอดรหัสได้เป็นอักขระ e ในสภาพแวดล้อม js เท่านั้น ดังนั้นจะไม่มีหน้าต่างป๊อปอัปเกิดขึ้น
2. คลิกใช้การเข้ารหัส url ก่อนที่จะดำเนินการ js ให้ถอดรหัส url %65 ดังนั้นเมื่อเอ็นจิ้น js เริ่มทำงาน คุณจะเห็นการแจ้งเตือนที่สมบูรณ์ (1)
3. คลิกการถอดรหัสเอนทิตี html จะดำเนินการก่อน
4. คลิก ในกระบวนการถอดรหัส URL JavaScript จะไม่ถือเป็นโปรโตคอลหลอก และข้อผิดพลาดจะเกิดขึ้น
5. Click htmlparser จะถูกดำเนินการก่อน JavaScript parser ดังนั้นกระบวนการแยกวิเคราะห์คืออักขระของ htmlencode จะถูกถอดรหัสก่อน จากนั้นเหตุการณ์ JavaScript จะถูกดำเนินการ
ลำดับการถอดรหัสเบราว์เซอร์เป็นพื้นฐานสำหรับการเลี่ยงผ่านใน XSS - ความสัมพันธ์ระหว่าง dockerfile และ docker-compose
เทคโนโลยีนักเทียบท่า : ความสัมพันธ์ระหว่างไฟล์และโฟลเดอร์ - ความแตกต่างระหว่าง dockerfile และ docker-compose คืออะไร?
เทคโนโลยีนักเทียบท่า : docker-compose ใช้สำหรับการจัดการคอนเทนเนอร์ - เครื่องป้อมปราการคืออะไร?
เทคโนโลยีโฮสต์ Bastion : กำหนดทางเข้าสำหรับการเข้าถึงคลัสเตอร์ อำนวยความสะดวกในการควบคุมและติดตามการอนุญาต - จำเป็นต้องวิเคราะห์ความเป็นไปได้ของผลิตภัณฑ์จากด้านใด
การวิเคราะห์ความเป็นไปได้ : ความเป็นไปได้ของผลิตภัณฑ์แบ่งออกเป็น: ความเป็นไปได้ทางเทคนิค ความเป็นไปได้ทางเศรษฐกิจ และความเป็นไปได้ทางสังคม ในหมู่พวกเขา ฉันมุ่งเน้นไปที่ความเป็นไปได้ทางเทคนิค ความเป็นไปได้ทางเทคนิคส่วนใหญ่วัดจากการเปรียบเทียบฟังก์ชันของคู่แข่ง ความเสี่ยงทางเทคนิคและวิธีการหลีกเลี่ยง ความง่ายในการใช้งานและเกณฑ์ผู้ใช้ การพึ่งพาสภาพแวดล้อมของผลิตภัณฑ์ ฯลฯ - Nginx และ Gunicorn มีบทบาทอย่างไรในเซิร์ฟเวอร์
แอปพลิเคชันเซิร์ฟเวอร์ : สถานการณ์การปรับใช้ Nginx: การปรับสมดุลโหลด (เฟรมเวิร์ก เช่น ทอร์นาโดรองรับเฉพาะคอร์เดียว ดังนั้นการปรับใช้แบบหลายกระบวนการจึงจำเป็นต้องมีการปรับสมดุลโหลดแบบย้อนกลับ gunicorn นั้นเป็นแบบหลายกระบวนการและไม่จำเป็นต้องใช้) การรองรับไฟล์แบบคงที่ แรงกดดันในการต่อต้านการทำงานพร้อมกัน การควบคุมการเข้าถึงเพิ่มเติม - วิกิพีเดีย: เคอร์เบรอส
Kerberos : คำอธิบายพื้นฐาน เนื้อหาโปรโตคอล และกระบวนการเฉพาะของ Kerberos - ความสัมพันธ์ระหว่าง dockerfile และ docker-compose
เทคโนโลยีนักเทียบท่า : ความสัมพันธ์ระหว่างไฟล์และโฟลเดอร์ - ความแตกต่างระหว่าง dockerfile และ docker-compose คืออะไร?
เทคโนโลยีนักเทียบท่า : docker-compose ใช้สำหรับการจัดการคอนเทนเนอร์ - เครื่องป้อมปราการคืออะไร?
เทคโนโลยีโฮสต์ Bastion : กำหนดทางเข้าสำหรับการเข้าถึงคลัสเตอร์ อำนวยความสะดวกในการควบคุมและติดตามการอนุญาต - จำเป็นต้องวิเคราะห์ความเป็นไปได้ของผลิตภัณฑ์จากด้านใด
การวิเคราะห์ความเป็นไปได้ : ความเป็นไปได้ของผลิตภัณฑ์แบ่งออกเป็น: ความเป็นไปได้ทางเทคนิค ความเป็นไปได้ทางเศรษฐกิจ และความเป็นไปได้ทางสังคม ในหมู่พวกเขา ฉันมุ่งเน้นไปที่ความเป็นไปได้ทางเทคนิค ความเป็นไปได้ทางเทคนิคส่วนใหญ่วัดจากการเปรียบเทียบฟังก์ชันของคู่แข่ง ความเสี่ยงทางเทคนิคและวิธีการหลีกเลี่ยง ความง่ายในการใช้งานและเกณฑ์ผู้ใช้ การพึ่งพาสภาพแวดล้อมของผลิตภัณฑ์ ฯลฯ - Nginx และ Gunicorn มีบทบาทอย่างไรในเซิร์ฟเวอร์
แอปพลิเคชันเซิร์ฟเวอร์ : สถานการณ์การปรับใช้ Nginx: การปรับสมดุลโหลด (เฟรมเวิร์ก เช่น ทอร์นาโดรองรับเฉพาะคอร์เดียว ดังนั้นการปรับใช้แบบหลายกระบวนการจึงจำเป็นต้องมีการปรับสมดุลโหลดแบบย้อนกลับ gunicorn นั้นเป็นแบบหลายกระบวนการและไม่จำเป็นต้องใช้) การรองรับไฟล์แบบคงที่ แรงกดดันในการต่อต้านการทำงานพร้อมกัน การควบคุมการเข้าถึงเพิ่มเติม - วิกิพีเดีย: เคอร์เบรอส
Kerberos : คำอธิบายพื้นฐาน เนื้อหาโปรโตคอล และกระบวนการเฉพาะของ Kerberos - สถาปัตยกรรมไมโครเซอร์วิส** คืออะไร
- เซอร์วิสเมช (Service Mesh) คืออะไร
สถาปัตยกรรมไมโครเซอร์วิส : ทำไม: เหตุใดจึงต้องใช้ Service Mesh ภายใต้สถาปัตยกรรมแอปพลิเคชันเว็บสามชั้นของ MVC แบบดั้งเดิม การสื่อสารระหว่างบริการต่างๆ นั้นไม่ซับซ้อนและสามารถจัดการได้ภายในแอปพลิเคชัน อย่างไรก็ตาม ในเว็บไซต์ขนาดใหญ่ที่ซับซ้อนในปัจจุบัน แอปพลิเคชันเดี่ยวจะถูกแบ่งออกเป็นไมโครเซอร์วิสจำนวนมากและการสื่อสารระหว่างบริการต่างๆ ซับซ้อน. อะไร: Service mesh คือเลเยอร์โครงสร้างพื้นฐานสำหรับการสื่อสารระหว่างบริการต่างๆ สามารถเปรียบเทียบได้กับ TCP/IP ระหว่างแอปพลิเคชันหรือไมโครเซอร์วิส โดยมีหน้าที่รับผิดชอบในการโทรผ่านเครือข่าย การจำกัดกระแส การตัดวงจร และการตรวจสอบระหว่างบริการ คุณสมบัติของ Service Mesh: ชั้นกลางสำหรับการสื่อสารระหว่างแอปพลิเคชัน พร็อกซีเครือข่ายแบบน้ำหนักเบา ไม่เชื่อเรื่องแอปพลิเคชัน การลองซ้ำ/หมดเวลาของแอปพลิเคชันแบบแยกส่วน การตรวจสอบ การติดตาม และการค้นพบบริการ ซอฟต์แวร์โอเพ่นซอร์สยอดนิยมในปัจจุบันคือ Istio และ Linkerd ซึ่งสามารถผสานรวมเข้ากับสภาพแวดล้อม Cloud Native kubernetes ได้ - ตัวอัปเดตจะล้มเหลวหากไม่ได้ทำงานในฐานะผู้ดูแลระบบ แม้ว่าจะติดตั้งโดยผู้ใช้ก็ตาม
LaTeX : MiKTeX (ปัญหารีจิสทรีและปัญหาสิทธิ์ผู้ดูแลระบบ) + TeXnicCenter (ไม่สามารถสร้างปัญหา pdf ได้ ตั้งค่าเส้นทางการดำเนินการของ Adobe ใน Build เป็น AcroRd32.exe ของแท้) + Adobe Acrobat Reader DC จากนั้นใช้ Adobe Acrobat DC เวอร์ชันที่แคร็กเพื่อแปลง เป็นรูปแบบอื่นๆ - หลักการ HTTPS และกระบวนการโต้ตอบ
HTTPS : HTTPS จำเป็นต้องมีการจับมือกันระหว่างเบราว์เซอร์และเว็บไซต์ก่อนที่จะส่งข้อมูล ในระหว่างกระบวนการจับมือ ข้อมูลรหัสผ่านที่ทั้งสองฝ่ายใช้ในการเข้ารหัสข้อมูลที่ส่งจะได้รับการยืนยัน รับรหัสสาธารณะ -> เบราว์เซอร์สร้างรหัสลับแบบสุ่ม (สมมาตร) -> ใช้รหัสสาธารณะเพื่อเข้ารหัสรหัสลับสมมาตร -> ส่งรหัสลับสมมาตรที่เข้ารหัส -> การสื่อสารข้อความไซเฟอร์ที่เข้ารหัสโดยรหัสลับสมมาตร กระบวนการทั้งหมดของการสื่อสาร HTTPS ใช้การเข้ารหัสแบบสมมาตร การเข้ารหัสแบบอสมมาตร และอัลกอริธึม HASH - นโยบายต้นกำเนิดเดียวกันของเบราว์เซอร์
เทคโนโลยีเบราว์เซอร์ : นโยบายต้นกำเนิดเดียวกันเป็นฟังก์ชันหลักและความปลอดภัยขั้นพื้นฐานที่สุดของเบราว์เซอร์ - หลักการใช้งานข้ามโดเมนเก้าประการ (เวอร์ชันเต็ม)
เทคโนโลยีเบราว์เซอร์ : โซลูชันการร้องขอข้ามโดเมน: JSONP (ช่องโหว่ที่ต้องอาศัยแท็กสคริปต์โดยไม่มีข้อจำกัดข้ามโดเมน), CORS (การแบ่งปันทรัพยากรข้ามโดเมน), postMessage, websocket, พร็อกซีมิดเดิลแวร์ของโหนด, พร็อกซีย้อนกลับ nginx, windows.name+iframe , location.hash+iframe, document.domain+iframe
CORS รองรับคำขอ HTTP ทุกประเภทและเป็นโซลูชันพื้นฐานสำหรับคำขอ HTTP ข้ามโดเมน JSONP รองรับเฉพาะคำขอ GET ข้อดีคือรองรับเบราว์เซอร์รุ่นเก่าและสามารถขอข้อมูลจากเว็บไซต์ที่ไม่รองรับ CORS ไม่ว่าจะเป็น พร็อกซีมิดเดิลแวร์ของโหนด หรือ พร็อกซีย้อนกลับ nginx เหตุผลหลักคือการไม่มีข้อจำกัดบนเซิร์ฟเวอร์ผ่านนโยบายที่มีต้นกำเนิดเดียวกัน ในการทำงานประจำวัน โซลูชันข้ามโดเมนที่ใช้กันมากที่สุดคือ CORS และ nginx Reverse proxy - จะใช้สภาพแวดล้อมเสมือน Python ใน Jupyter Notebook ได้อย่างไร
Anaconda : ติดตั้งปลั๊กอิน, conda ติดตั้ง nb_conda - เนื่องจากมีคำขอ HTTP เหตุใดจึงใช้การเรียก RPC -คำตอบพี่ยี่
RPC : สงบ VS RPC RPC ประกอบด้วย: พร็อกซีย้อนกลับ, การทำให้เป็นซีเรียลไลซ์และดีซีเรียลไลซ์, การสื่อสาร (HTTP, TCP, UDP) การจัดการข้อยกเว้น
การวิจัยพื้นฐาน
การวิเคราะห์โดยย่อเกี่ยวกับกระบวนการร้องขอไลบรารี่ของ python
Python ร้องขอการใช้งานไลบรารี : socket->httplib->urllib->urllib3->requests กระบวนการเรียกภายในของ request.get: request.get->requests()->Session.request->Session.send->adapter.send->HTTPConnectionPool(urllib3)->HTTPConnection(httplib)
1、socket:是TCP/IP最直接的实现,实现端到端的网络传输
2、httplib:基于socket库,是最基础最底层的http库,主要将数据按照http协议组织,然后创建socket连接,将封装的数据发往服务端
3、urllib:基于httplib库,主要对url的解析和编码做进一步处理
4、urllib3:基于httplib库,相较于urllib更高级的地方在于用PoolManager实现了socket连接复用和线程安全,提高了效率
5、requests:基于urllib3库,比urllib3更高级的是实现了Session对象,用Session对象保存一些数据状态,进一步提高了效率
การวิเคราะห์หลักการ XGBoost และการใช้งานพื้นฐาน (เรียนรู้)
XGBoost : เข้าใจจากมุมมองของคะแนนของทรี (ฟังก์ชันวัตถุประสงค์: ฟังก์ชันการสูญเสีย (การขยายลำดับที่สอง) + เทอมปกติ) โครงสร้างของทรี (การตัดสินใจแบบแยก (การเรียงลำดับล่วงหน้า))
ความเข้าใจเชิงลึกเกี่ยวกับอัลกอริธึมการปรับฮิสโตแกรม Lightgbm
Lightgbm : เมื่อเปรียบเทียบกับการเรียงลำดับล่วงหน้า lgb จะใช้ฮิสโตแกรมเพื่อจัดการการแยกโหนดและค้นหาจุดแยกที่เหมาะสมที่สุด แนวคิดอัลกอริทึม: แปลงค่าฟีเจอร์เป็นค่า bin ล่วงหน้าก่อนการฝึก นั่นคือ สร้างฟังก์ชันทีละชิ้นสำหรับค่าของแต่ละฟีเจอร์ แบ่งค่าของตัวอย่างทั้งหมดในฟีเจอร์นี้ออกเป็นส่วนใดส่วนหนึ่ง (bin) และสุดท้ายค่าฟีเจอร์จะถูกแปลงจากค่าต่อเนื่องเป็นค่าที่ไม่ต่อเนื่อง ฮิสโตแกรมยังสามารถใช้สำหรับการเร่งความเร็วที่แตกต่างกันได้ ความซับซ้อนในการคำนวณฮิสโตแกรมจะขึ้นอยู่กับจำนวนที่เก็บข้อมูล
การวิเคราะห์ซอร์สโค้ดการประมวลผลล่วงหน้าข้อความ Keras
Keras - การประมวลผลข้อความล่วงหน้า : 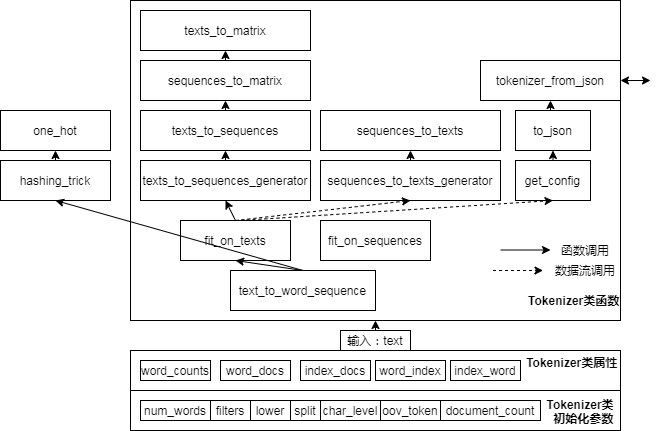
การวิเคราะห์ซอร์สโค้ดการประมวลผลล่วงหน้าลำดับ Keras
Word2Vec
- ทำความเข้าใจกับโมเดล Skip-Gram ของ Word2Vec
- การใช้โมเดล Skip-Gram ตามบทความของ TensorFlow - Tian Yusu
- บทช่วยสอน Word2Vec - โมเดล Skip-Gram
- บทช่วยสอน Word2Vec ตอนที่ 2 - การสุ่มตัวอย่างเชิงลบ
- บทช่วยสอนการฝังคำ Word2Vec ใน Python และ TensorFlow
- การวิเคราะห์ซอร์สโค้ด word2vec_basic tensorlflow
- บทช่วยสอน Word2Vec Keras
- keras_word2vec@adventures-in-ml-รหัส
ความปลอดภัย
เทคโนโลยีความปลอดภัย
ช่องโหว่
- การรวบรวมเพย์โหลดไลบรารีช่องโหว่ Wuyun และปลั๊กอินเสริม Burp
- boy-hack/wooyun-payload
- มุมมองของนักวิจัยเกี่ยวกับการวิจัยช่องโหว่ในปี 2010
การวิจัยเกี่ยวกับช่องโหว่: สถานะปัจจุบันและแนวโน้มของการวิจัยเกี่ยวกับช่องโหว่ในช่วง 10 ปีที่ผ่านมา : 1. ในยุคหลังพีซี ความสมบูรณ์ของโฟลว์การควบคุมได้กลายเป็นกลไกการป้องกันขั้นพื้นฐานใหม่สำหรับความปลอดภัยของระบบ 2. คุณสมบัติด้านความปลอดภัยของฮาร์ดแวร์ที่น่าประหลาดใจและช่องโหว่ด้านความปลอดภัยของฮาร์ดแวร์ 3. ไวน์ใหม่ในขวดเก่า การออกแบบที่ปลอดภัยของอุปกรณ์เคลื่อนที่ช่วยให้สามารถแซงในโค้งได้ 4. การต่อสู้เพื่อทางเข้าเครือข่ายทวีความรุนแรงมากขึ้น ทางเข้าเครือข่ายรวมถึง: เบราว์เซอร์, ตัวประมวลผลร่วม WiFi, เบสแบนด์, บลูทูธ, เราเตอร์, อุปกรณ์ส่งข้อความโต้ตอบแบบทันที, ซอฟต์แวร์โซเชียล, ไคลเอนต์อีเมล, พีซีและเซิร์ฟเวอร์แบบดั้งเดิม 5. การขุดช่องโหว่และการแสวงหาผลประโยชน์แบบอัตโนมัติยังคงต้องได้รับการปรับปรุง
ความปลอดภัยของเว็บ
- บทความเพื่อให้คุณเข้าใจเชิงลึกเกี่ยวกับช่องโหว่: ช่องโหว่ XXE
ช่องโหว่ XXE : หลักการของ XXE: การเรียกเอนทิตีภายนอก, การใช้ XXE: การใช้เอนทิตีทั่วไป, เอนทิตีพารามิเตอร์, เอนทิตีภายนอก, เอนทิตีภายในเพื่ออ่านไฟล์, การตรวจจับโฮสต์อินทราเน็ตและพอร์ต, อินทราเน็ต RCE (จำเป็นต้องรองรับส่วนขยายที่คาดหวังภายใต้ PHP) ) - เทคนิคการฉีดแบบไม่มีเครื่องหมายจุลภาคของ Mysql
การโจมตีแบบฉีด : การแทรก sql, การแทรก xml (ภาษามาร์กอัปที่แสดงข้อมูลเชิงโครงสร้างผ่านแท็ก), การแทรกโค้ด (คลาส eval), การแทรก CRLF (rn) การแทรก Mysql: ใช้ความคิดเห็นเพื่อข้ามช่องว่าง ใช้วงเล็บเพื่อข้ามช่องว่าง ใช้สัญลักษณ์เช่น %20 %0a เพื่อแทนที่ช่องว่าง ภายใต้แบบสอบถามแบบร่วม ใช้การรวมเพื่อข้ามการกรองลูกน้ำ select id,ip from client_ip where 1>2 union select * from ( (select user())a JOIN (select version())b ); ใช้ select case when(条件) then 代码1 else 代码2 end เพื่อข้ามการกรองเครื่องหมายจุลภาค insert into client_ip (ip) values ('ip'+(select case when (substring((select user()) from 1 for 1)='e') then sleep(3) else 0 end)); - [CRLF การใช้ช่องโหว่แบบฉีดและการวิเคราะห์ตัวอย่าง]([https://wooyun.js.org/drops/CRLF%20Injection%E6%BC%8F%E6%B4%9E%E7%9A%84%E5% 88%A9%E7%94%A8%E4%B8%8E%E5%AE%9E%E4%BE%8B%E5%88%86%E6%9E%90.html](https://wooyun.js .org/drops/CRLF การใช้ช่องโหว่ในการฉีดและตัวอย่าง analyse.html))
CRLF เป็นตัวย่อของ "การขึ้นบรรทัดใหม่ + การป้อนบรรทัด" (rn) HTTP Header และ HTTP Body ถูกคั่นด้วย CRLF สองตัว การฉีด CRLF เรียกอีกอย่างว่า HTTP Response Splitting หรือเรียกสั้น ๆ ว่า HRS X-XSS-Protection:0 จะปิดกลยุทธ์การป้องกันของเบราว์เซอร์สำหรับการกรอง XSS ที่สะท้อน - การแสวงหาประโยชน์จากช่องโหว่ SSRF และการต่อสู้แบบ getshell (เลือก)
- สรุปวิธีการต่างๆ ในการหลีกเลี่ยงการกรอง (ข้อจำกัด IP) ในช่องโหว่ SSRF
SSRF : ใช้ 302 Jump (xip.io, ที่อยู่แบบสั้น, บริการที่เขียนเอง), การเชื่อมโยง DNS ใหม่ (ข้ามข้อ จำกัด IP) เปลี่ยนวิธีการเขียนที่อยู่ IP; ใช้ปัญหาในการแยกวิเคราะห์ URL: http://[email protected]/ ; ผ่านโปรโตคอลที่ไม่ใช่ HTTP ต่างๆ - สรุปวิธีการบายพาส SSRF
SSRF : ใช้ @; ใช้ชื่อโดเมนพิเศษ xip.io; ใช้การแก้ไข DNS (ตั้งค่าระเบียน A ในชื่อโดเมน); - การวิเคราะห์ช่องโหว่ RCE ของ ThinkPHP 5.0.0~5.0.23
- การวิเคราะห์โดยย่อเกี่ยวกับการเข้ารหัสอักขระและการแทรก SQL ในการตรวจสอบกล่องสีขาว (ยอดเยี่ยม เรียนรู้แล้ว)
การโจมตีแบบฉีดตามการเข้ารหัสอักขระ : อักขระจีนที่เข้ารหัส gbk กินพื้นที่ 2 ไบต์ และอักขระจีนที่เข้ารหัส utf-8 กินพื้นที่ 3 ไบต์ การแทรกไบต์แบบกว้างใช้ประโยชน์จากคุณลักษณะของ mysql เมื่อ mysql ใช้การเข้ารหัส gbk มันจะคิดว่าอักขระสองตัวเป็นอักขระจีนตัวเดียว (ภายใต้ gbk รหัส ASCII ก่อนหน้าจะต้องมากกว่า 128 เพื่อให้ถึงช่วงของอักขระจีน การเข้ารหัส ช่วงค่าของ gb2312 : บิตสูง 0xA1-0xF7 บิตต่ำ 0xA1-0xFE และ 0x5c ไม่อยู่ในช่วงบิตต่ำ ดังนั้น 0x5c ไม่ใช่การเข้ารหัสใน gb2312 ดังนั้นจึงไม่ถูกกิน ขยายแนวคิดนี้ไปยังการเข้ารหัสแบบหลายไบต์ทั้งหมด ตราบใดที่ช่วงบิตต่ำมีการเข้ารหัส 0x5c การฉีดไบต์แบบกว้างสามารถทำได้) แผนการป้องกันที่หนึ่ง: mysql_set_charset+mysql_real_escape_string โดยคำนึงถึงชุดอักขระปัจจุบันของการเชื่อมต่อ แผนการป้องกันที่สอง: ตั้งค่า character_set_client เป็น binary (binary), SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary เมื่อ mysql ของเราได้รับข้อมูลของลูกค้า มันจะคิดว่าการเข้ารหัสของมันคือ character_set_client จากนั้นเปลี่ยนเป็นการเข้ารหัส character_set_connection จากนั้นป้อนตารางและฟิลด์เฉพาะ จากนั้นแปลงเป็นการเข้ารหัสที่สอดคล้องกับฟิลด์ จากนั้น เมื่อสร้างผลลัพธ์การสืบค้น ผลลัพธ์จะถูกแปลงจากการเข้ารหัสตารางและฟิลด์เป็นการเข้ารหัส character_set_results และส่งคืนไปยังไคลเอนต์ ดังนั้นหากเราตั้ง character_set_client เป็น binary จะไม่มีปัญหาเรื่อง wide byte หรือ multi-byte ข้อมูลทั้งหมดจะถูกถ่ายโอนในรูปแบบไบนารี่ ซึ่งสามารถหลีกเลี่ยงการแทรกอักขระแบบ wide ได้อย่างมีประสิทธิภาพ ปัญหาอาจเกิดขึ้นเมื่อเรียก iconv หลังจากการป้องกัน เมื่อใช้ iconv เพื่อแปลง utf-8 เป็น gbk วิธีการใช้ประโยชน์คือ錦' เนื่องจากการเข้ารหัส utf-8 ของมันคือ 0xe98ca6 และการเข้ารหัส gbk ของมันคือ 0xe55c ซึ่งในที่สุดจะกลายเป็น %e5%5c%5c%27 สอง %5c มัน ' เป็นเลขคี่ ' จะหนีจากขีดจำกัด เหตุใด錦' จึงใช้วิธีนี้ไม่ได้ ตามกฎการเข้ารหัส utf-8 (0x0000005c) จะไม่ปรากฏในการเข้ารหัส utf-8 ดังนั้นข้อผิดพลาดจะถูกรายงาน - ปัญหาด้านความปลอดภัยที่เกิดจากเซสชันไคลเอ็นต์
- ข้อมูลเชิงลึกเกี่ยวกับ DAST, SAST และ IAST ในบทความเดียว - การอภิปรายสั้น ๆ เกี่ยวกับการเปรียบเทียบเทคโนโลยีการทดสอบความปลอดภัยของแอปพลิเคชันบนเว็บ (เรียนรู้)
- พูดคุยเกี่ยวกับ SAST/IDAST/IAST
- ข้อมูลเบื้องต้นเกี่ยวกับวิธีการเชื่อมต่อ PHP และวิธีโจมตี PHP-FPM
- คำขอ GET เพื่อรับธง——การเขียนบทความ PUBG รอบชิงชนะเลิศของ XCTF 2018 (เว็บ 2)
การทดสอบการเจาะ
- ชุดคำถามสัมภาษณ์งานการทดสอบการเจาะระบบ ฟังก์ชันการดำเนินการโค้ด:
eval、preg_replace+/e、assert、call_user_func、call_user_func_array、create_function ; ฟังก์ชันการดำเนินการคำสั่ง: system、exec、shell_exec、passthru、pcntl_exec、popen、proc_open ; img tag นอกจากนี้มีวิธีอื่นในการรับเส้นทางผู้ดูแลระบบหรือไม่? src ระบุไฟล์สคริปต์ระยะไกลเพื่อรับผู้อ้างอิง - ชุดคำถามสัมภาษณ์งาน ทดสอบการเจาะระบบเชิงปฏิบัติ คุณรู้หรือไม่?
- ประสบการณ์การสัมภาษณ์ของฉัน การทดสอบการเจาะ
การตรวจสอบรหัส
- การตรวจสอบโค้ด Java - ความก้าวหน้าทีละชั้น
ความปลอดภัยของข้อมูล
- NO.27 สนทนาเกี่ยวกับความปลอดภัยของข้อมูล เทคโนโลยีและยุคของข้อมูลขนาดใหญ่ ข้อมูลเป็นทรัพย์สินหลักของหลายบริษัท ขอบเขตความปลอดภัยแบบดั้งเดิมนั้นไม่ชัดเจน เราจำเป็นต้องถือว่าขอบเขตของเราถูกเจาะเข้าไป และในขณะเดียวกันก็มีการป้องกันในเชิงลึก ความสามารถในการปกป้องความปลอดภัยของข้อมูล ดังนั้น ถึงแม้ว่าการเสริมสร้างวิธีการรักษาความปลอดภัยแบบเดิมๆ เราควรมุ่งเน้นการรักษาความปลอดภัยไปที่ตัวข้อมูลโดยตรง นี่คือสิ่งที่การรักษาความปลอดภัยของข้อมูลทำ ก่อนที่จะทำเช่นนี้ มีสมมติฐาน: เราต้องรู้ว่าความปลอดภัยยังคงให้บริการแก่ธุรกิจ (ในกรณีส่วนใหญ่ด้านความปลอดภัยขององค์กร ธุรกิจ > ความปลอดภัย) ดังนั้นจึงต้องชั่งน้ำหนักความปลอดภัยและการใช้งาน ในปัจจุบัน มาตรการที่ใช้กันทั่วไปในองค์กรส่วนใหญ่ ได้แก่ การจำแนกข้อมูล การจัดการวงจรชีวิตของข้อมูล การลดความไวของข้อมูลและการเข้ารหัสข้อมูล และการป้องกันการรั่วไหลของข้อมูล
- การสร้างระบบรักษาความปลอดภัยข้อมูลอินเทอร์เน็ตขององค์กร
ความปลอดภัยของคลาวด์
- ความปลอดภัยของคลาวด์ มันคืออะไรกันแน่?
มีสามทิศทางการวิจัยที่สำคัญในการรักษาความปลอดภัยบนคลาวด์: ความปลอดภัยของคลาวด์คอมพิวติ้งการทำให้เป็นเมฆโครงสร้างพื้นฐานด้านความปลอดภัยและบริการความปลอดภัยคลาวด์ ความร่วมมือด้านความปลอดภัยของข้อมูลยังกล่าวถึงในแนวโน้มการพัฒนาในอนาคตของการรักษาความปลอดภัยคลาวด์ซึ่งบ่งชี้ว่าไม่ว่าสถานการณ์ใดข้อมูลจะเป็นจุดสนใจของความปลอดภัย บริการรักษาความปลอดภัยบนคลาวด์สามารถมองเห็นได้ว่าเป็นพ่อครัวทำอาหาร (PPT จาก CDXY), คลาวด์คอมพิวติ้ง (พลังงาน), อัลกอริทึม (เครื่องมือ), ข้อมูล (วัตถุดิบ), วิศวกร (พ่อครัว), ข้าวชนิดใดที่สามารถทำได้ (บริการรักษาความปลอดภัยที่สามารถทำได้ ที่ให้ไว้) ) - อนาคตของการรักษาความปลอดภัยคลาวด์ (บทความเชิงลึกนาน)
แนวคิดการเขียน : แนวโน้มตลาดความปลอดภัยบนคลาวด์ -"ผลิตภัณฑ์ความปลอดภัยคลาวด์หลัก (ผลิตภัณฑ์รักษาความปลอดภัยแพลตฟอร์มคลาวด์และผลิตภัณฑ์ความปลอดภัยคลาวด์ของบุคคลที่สาม CWPP, CSPM, CASB) -การรวมกันของความปลอดภัยของคลาวด์และ SD -WAN -" Cloud Native (DevOps ต่อเนื่อง การจัดส่ง, microservices, คอนเทนเนอร์) ความปลอดภัย
อื่น
- ข้อมูลความปลอดภัย: Enterprise Labs, ชุมชนความปลอดภัย, ทีมรักษาความปลอดภัย, เครื่องมือรักษาความปลอดภัย ฯลฯ
เครื่องมือรักษาความปลอดภัย
การสแกนช่องโหว่
- การสแกนช่องโหว่โดยใช้โหมด Xray Proxy
การวิจัยความปลอดภัย
การตรวจจับที่เหมาะสม
- การตรวจจับ APT ตามการเรียนรู้ของเครื่องจักร
แบบจำลองการตรวจจับ APT : บทความนี้เสนอแบบจำลองการตรวจจับ APT โดยการตรวจจับลิงก์หลายลิงก์ในวงจรชีวิตที่เหมาะสมซึ่งสัมพันธ์กับเหตุการณ์การเตือนภัยในแต่ละลิงก์และใช้การเรียนรู้ของเครื่องเพื่อฝึกอบรมรูปแบบการตรวจจับ มันคล้ายกับความคิดของฉันเล็กน้อย จุดประสงค์ของสิ่งนี้คือเพื่ออธิบายชุดเหตุการณ์ความปลอดภัยอย่างสมบูรณ์ในสถานการณ์ที่เหมาะสมลดอัตราบวกที่ผิดพลาดปรับปรุงความแม่นยำและหลีกเลี่ยงปัญหาของการลบที่ไม่ได้รับและบวกเท็จที่เกิดจากการตรวจจับลิงค์เดียวแบบดั้งเดิม อย่างไรก็ตามยังมีปัญหาบางอย่างในบทความนี้เช่นการขาดแหล่งข้อมูลที่เหมาะสม
ตัวอย่างที่เป็นอันตราย
- ใช้การเรียนรู้ของเครื่องเพื่อตรวจจับการจราจรภายนอกที่เป็นอันตราย HTTP (ยอดเยี่ยม)
การตรวจจับการจราจรภายนอก HTTP ที่เป็นอันตราย : แนวคิดทั่วไป : 1. การรวบรวมข้อมูล ดำเนินการตัวอย่างที่เป็นอันตรายในกล่องทรายรวบรวมการจราจรที่เป็นอันตรายแยกแยะการจราจรที่เป็นอันตรายด้วยตนเองจากการจราจรสีขาวจากนั้นจำแนกการจราจรที่เป็นอันตรายในครอบครัวตามข่าวกรองภัยคุกคาม 2. การวิเคราะห์ข้อมูล (วิศวกรรมคุณลักษณะ): สำหรับความคล้ายคลึงกันของการรับส่งข้อมูลภายนอกที่เป็นอันตรายของตระกูลเดียวกันคุณสามารถพิจารณาใช้อัลกอริทึมการจัดกลุ่มเพื่อจัดกลุ่มการรับส่งข้อมูลของตระกูลเดียวกันเป็นหมวดหมู่เดียว ใช้เทมเพลตเพื่อตรวจจับการรับส่งข้อมูลที่ไม่รู้จัก 3. อัลกอริทึม: ขั้นตอนการฝึกอบรม : แยก HTTP การเชื่อมต่อการเชื่อมต่อภายนอก ---> ฟิลด์ส่วนหัวของคำขอดึงข้อมูล ---> การวางนัยทั่วไป ---> การคำนวณความคล้ายคลึงกัน ( การถ่วงน้ำหนักเฉพาะภาคสนามในส่วนหัวคำขอแล้วคำนวณความคล้ายคลึงกัน ) ---> ลำดับชั้น การจัดกลุ่ม ---> สร้างเทมเพลตการรับส่งข้อมูลภายนอกที่เป็นอันตราย (การรวมกันของฟิลด์นี้ในคลัสเตอร์ใช้เป็นค่าของฟิลด์นี้ในเทมเพลต) ขั้นตอนการตรวจจับ : การรับส่งข้อมูลภายนอก HTTP ที่ไม่รู้จัก ---> ฟิลด์ส่วนหัวของคำขอสารสกัด ---> การวางนัยทั่วไป ---> จับคู่กับแม่แบบที่เป็นอันตราย ---> พิจารณาว่าความคล้ายคลึงกันเกินกว่าเกณฑ์ (การกำหนดเกณฑ์) - การสร้างแพลตฟอร์มการวิเคราะห์อัตโนมัติ Cuckoo Malware
- สภาพแวดล้อมการวิเคราะห์มัลแวร์ Cuckoo
- เล่นกับนกกาเหว่า
Cuckoo Sandbox: ฉันพบข้อผิดพลาดมากมายในกระบวนการสร้างสภาพแวดล้อมการวิเคราะห์ตัวอย่างที่เป็นอันตรายของนกกาเหว่า PY ไปยังโฟลเดอร์เริ่มต้น บนโฮสต์ทางกายภาพ Windows 10 ได้รับการติดตั้งด้วย VMware VMware ติดตั้งด้วย Ubuntu16, Ubuntu16 ติดตั้งด้วย VirtualBox และ Cuckoo Server และ VirtualBox ติดตั้งด้วย Windows7 เป็นตัวแทน - สรุปทรัพยากรการวิเคราะห์ตัวอย่างที่เป็นอันตราย
ต่อสู้กับการจราจรของเครื่องจักร
- 2018 Bad Bot Report
การจราจรของเครื่องจักรการต่อสู้ : การเผชิญหน้าด้านความปลอดภัยได้ส่งเสริมการวิวัฒนาการของวิธีการโจมตีและเข้าสู่ขั้นตอนการเผชิญหน้าอัตโนมัติ การรับส่งข้อมูลของเครื่องจักรถูกสร้างขึ้นในขณะที่ตัวรวบรวมข้อมูลที่เป็นอันตรายและตัวรวบรวมข้อมูลที่เป็นอันตรายอื่น ๆ เลียนแบบคำขอของผู้ใช้ปกติเพื่อสร้างปริมาณการใช้งานที่เป็นอันตราย ไม่มีหัว เบราว์เซอร์เบราว์เซอร์ขั้นสูงสามารถจำลองการเคลื่อนไหวของเมาส์และคลิกได้ การรับส่งข้อมูลของเครื่องสามารถแยกแยะได้ตามสภาพแวดล้อมเครือข่าย (Amazon ISP, ศูนย์ข้อมูล, ผู้ให้บริการโฮสติ้งทั่วโลก), เครื่องมือที่ใช้ (เบราว์เซอร์ของการรับส่งข้อมูลของเครื่องจักรต้องการที่จะปลอมตัวเป็น Chrome, Firefox, Internet Explorer, Safari) การโต้ตอบเช่นวิถีเมาส์และการคลิก เมื่อพวกเขาตรวจพบความพยายามของเราที่จะหยุดพวกเขาการจราจรของเครื่องจักรที่เป็นอันตรายขั้นสูง APBs กลายเป็นแบบถาวรและปรับตัวได้ การป้องกัน: เข้าใจการดำเนินงานและวัตถุประสงค์ของศัตรูของเรา ปราบปราม UA/เบราว์เซอร์ที่ล้าสมัย; ความพยายามในการเข้าสู่ระบบล้มเหลว
การตรวจจับ URL ที่เป็นอันตราย
- ตรวจจับ URL ที่เป็นอันตราย
หลังจากอ่านอัลกอริทึมความปลอดภัยในประเทศและสื่อการวิเคราะห์ข้อมูลความปลอดภัยจนถึงที่สุดพวกเขาก็เริ่มหันมาให้ความสนใจกับต่างประเทศและติดตามกระบวนการพัฒนาของแอพพลิเคชั่นการเรียนรู้ของเครื่องจักรต่างประเทศในด้านความปลอดภัยของเครือข่าย ตัวอย่างการตรวจจับ URL เป็นตัวอย่างสถานการณ์ที่เกี่ยวข้องมากมายสามารถได้รับรวมถึงการตรวจจับหน้าเว็บที่เป็นอันตรายกิจกรรมการสื่อสารที่เป็นอันตรายและซอฟต์แวร์เว็บที่เป็นอันตราย - Beyond Blacklists: เรียนรู้ที่จะตรวจจับเว็บไซต์ที่เป็นอันตรายจาก URL ที่น่าสงสัย
ใช้การตรวจจับ URL ที่เป็นอันตรายเป็นวิธีเสริมสำหรับการตรวจจับหน้าเว็บที่เป็นอันตราย ข้อมูล: ตัวอย่าง URL แบบโอเพ่นซอร์สขาวดำไม่มีคุณสมบัติพิเศษ; ไม่มีคุณสมบัติการวิเคราะห์และการเปรียบเทียบของแต่ละประเภทย่อยโมเดลนี้ไม่มีคุณสมบัติ; ท้ายที่สุดมันเป็นกระดาษที่เขียนเมื่อสิบปีก่อน - การระบุ URL ที่น่าสงสัย: การประยุกต์ใช้การเรียนรู้ออนไลน์ขนาดใหญ่
- การใช้ประโยชน์จากคุณลักษณะความแปรปรวนร่วมในการเรียนรู้ออนไลน์ในมิติสูง
ทีมสีแดง
- การฝึกฝนและการคิดของทีมสีแดงตั้งแต่ 0 ถึง 1 (เรียนรู้)
คำจำกัดความของทีมสีแดง ---> เป้าหมายของทีมสีแดง (เรียนรู้และใช้ TTPs ของผู้โจมตีจริงที่รู้จักกันในการโจมตีประเมินประสิทธิภาพของความสามารถในการป้องกันที่มีอยู่ระบุจุดอ่อนในระบบการป้องกันและเสนอการตอบโต้ที่เฉพาะเจาะจงใช้การโจมตีแบบจำลองจริงและมีประสิทธิภาพ เพื่อประเมินผลกระทบทางธุรกิจที่อาจเกิดขึ้นจากปัญหาด้านความปลอดภัย) ---> ผู้ที่ต้องการทีมสีแดง ---> ทีมงานสีแดงทำงานอย่างไร (องค์ประกอบพื้นฐาน: สำรองความรู้โครงสร้างพื้นฐานความสามารถในการวิจัยทางเทคนิคกระบวนการทำงาน: การจำลองการโจมตีแบบเต็มเวที การจำลอง; การหาปริมาณและการประเมินของทีม (ความครอบคลุมของ TTPS ที่รู้จักอัตราการตรวจจับ/ระยะเวลาการตรวจจับ/ระยะเวลาการตรวจจับอัตราการปิดกั้น/ระยะเวลาการบล็อก/ขั้นตอนการปิดกั้น) ---> การเติบโตและการปรับปรุงของทีมสีแดง (การฝึกอบรมสภาพแวดล้อมการจำลองการวิเคราะห์ช่องโหว่และการวิจัยทางเทคนิคการสื่อสารภายนอกการสื่อสารภายนอกการสื่อสารภายนอกการสื่อสารภายนอก และการแบ่งปัน) - สรุป ATT & CK APT Organization TTPS
- สรุปเทคโนโลยีการโจมตีแพลตฟอร์มเต็มแพลตฟอร์มเต็มรูปแบบ
- สรุปรายงานการวิเคราะห์องค์กรที่มีความสามารถจริง
วัฟ
- การสนทนาทางเทคนิค | บายพาส WAF ที่ระดับ HTTP
- ใช้การถ่ายโอน chunked เพื่อเอาชนะ WAF ทั้งหมด
- บายพาส WAF จากระดับโปรโตคอล HTTP และระดับฐานข้อมูล
- การวิจัยการโจมตีและการป้องกัน WAF สี่ระดับ: บายพาส WAF
- ความรู้บางอย่างเกี่ยวกับ WAF
การตรวจจับความผิดปกติ
- n วิธีการตรวจจับความผิดปกติ (เรียนรู้)
หนึ่งในความยากลำบากในการตรวจจับความผิดปกติคือการขาดความจริงภาคพื้นดิน จากอนุกรมเวลา (ค่าเฉลี่ยเคลื่อนที่, ปีต่อปีและเดือนต่อเดือน, STL+GESD), สถิติ (ระยะทาง Mahalanobis, boxplot), มุมระยะทาง (KNN), วิธีเชิงเส้น (การสลายตัวของเมทริกซ์และการลดมิติมิติ PCA), การกระจาย (เอนโทรปี KL ตรวจจับความผิดปกติจากมุมต่าง ๆ เช่นความแตกต่างการทดสอบไคสแควร์), ต้นไม้, กราฟ, ลำดับพฤติกรรมและโมเดลภายใต้การดูแล (ซึ่งสามารถรวมคุณสมบัติเพิ่มเติมได้โดยอัตโนมัติเช่น GBDT) - อัลกอริธึมการตรวจจับการเรียนรู้ของเครื่องจักร (1): ป่าแยก
- อัลกอริธึมการตรวจจับการเรียนรู้ของเครื่องจักร (2): ปัจจัยค่าผิดปกติในท้องถิ่น
- อัลกอริธึมการตรวจจับการเรียนรู้ของเครื่องจักร (3): การวิเคราะห์องค์ประกอบหลัก
- เครื่องเวกเตอร์ที่รองรับระดับเดียวคืออะไร (SVM ชั้นหนึ่ง)?
- อัลกอริทึมการตรวจจับความผิดปกติ
- การขุดผิดปกติป่าแยก
- ความพยายามครั้งแรกในการตรวจจับความผิดปกติ
- การตรวจสอบอัจฉริยะของข้อมูลอนุกรมเวลาความผิดปกติที่ขับเคลื่อนโดยการเรียนรู้ของเครื่องจักร
- ข้อยกเว้นการขุดในการดำเนินการและบันทึกการบำรุงรักษาขนาดใหญ่
- ข้อมูลการประมวลผลข้อมูลล่วงหน้าล่วงหน้า
- การศึกษาเบื้องต้นเกี่ยวกับการใช้การตรวจจับที่ผิดปกติและการเรียนรู้ภายใต้การดูแลในการตรวจจับความผิดปกติ
- อัลกอริทึม "การตรวจจับความผิดปกติ" ทั่วไปในการขุดข้อมูลคืออะไร? - คำตอบที่ปรับแต่ง - Zhihu
1. แนะนำอัลกอริทึมการตรวจจับความผิดปกติที่ไม่ได้รับการดูแลโดยทั่วไป 1.1) แบบจำลองสถิติและความน่าจะเป็น: การกระจายสมมติฐานและการทดสอบสมมติฐาน, หนึ่งมิติและหลายมิติ, คุณลักษณะความเป็นอิสระและความสัมพันธ์คุณลักษณะ, ระยะทางยุคลิดและระยะทาง Mahalanobis; ระยะทางยูคลิดและระยะทาง Mahalanobis, PCA และ PCA ที่อ่อนนุ่มและ SVM แบบหนึ่งชั้น; 1.2) ตรวจสอบการเชื่อมต่อระหว่างอัลกอริทึมจากขอบเขตการตัดสินใจของกราฟผลการทดลอง 2.1) การเปรียบเทียบเอฟเฟกต์การตรวจจับแบบจำลองป่าแยกและ KNN ดำเนินการอย่างเสถียร 3.1) ปริมาณข้อมูลและขนาดข้อมูลยังมีผลกระทบต่อค่าใช้จ่ายอัลกอริทึม การแยกเหมาะสำหรับพื้นที่มิติสูง 4.1) ผลการทดลองนำแนวคิดสำหรับการเลือกแบบจำลองการตรวจจับความผิดปกติ: KNN และ MCD สำหรับชุดข้อมูลขนาดเล็กและขนาดกลางค่อนข้างมีความเสถียรและป่าแยกสำหรับชุดข้อมูลขนาดกลางและขนาดใหญ่มีความเสถียร ในฐานะที่เป็น PCA และ MCD; 4.2) สำหรับปัญหาการตรวจจับความผิดปกติใหม่คุณสามารถทำตามขั้นตอนต่อไปนี้เพื่อวิเคราะห์: A. เข้าใจข้อมูลการกระจายข้อมูลและการกระจายความผิดปกติและเลือกแบบจำลองตามสมมติฐานหรือไม่ ถ้าเป็นเช่นนั้นจะต้องไม่สูญเปล่า อัลกอริทึมการเลือกจุด; E. ไม่ใช่เรื่องง่ายที่จะตรวจสอบผลลัพธ์ของแบบจำลองการตรวจจับความผิดปกติที่ไม่ได้รับการดูแล ลักษณะของความผิดปกติมักจะเปลี่ยนแปลง กฎด้วยตนเองยังคงมีประโยชน์มากอย่าพยายามแทนที่กฎที่มีอยู่ด้วยกลยุทธ์ข้อมูลในขั้นตอนเดียว - การตรวจจับ
- การตรวจจับความผิดปกติการแยกป่าและการสร้างภาพข้อมูล
- การตรวจจับความผิดปกติพร้อมการพยากรณ์อนุกรมเวลา
ตัวเลขและความปลอดภัย
- รูป/Louvain/DGA แบบสุ่มพูดคุยกันว่ากราฟมีข้อมูลทอพอโลยีและข้อมูลทอพอโลยีสามารถถือได้ว่าเป็นมิติที่มีลักษณะเฉพาะ จุดสำคัญของอัลกอริทึม Louvain คือน้ำหนักของขอบของกราฟซึ่งต้องการการศึกษาพิเศษในสถานการณ์การโจมตีและการป้องกันที่เฉพาะเจาะจง ของ IPS ที่เคยเยี่ยมชมชื่อโดเมน A และ B ในเวลาเดียวกัน Master Cdxy ใช้ตรรกะนี้โดยใช้ SQL
- อัลกอริทึมการค้นพบชุมชน-การศึกษาเบื้องต้นเกี่ยวกับอัลกอริทึมการตีแผ่อย่างรวดเร็ว (Louvian)
- DGA Odyssey PDNS ขับเคลื่อนการวิเคราะห์ DGA
- การประมวลผลกราฟได้เรียนรู้เกี่ยวกับการใช้ความปลอดภัยขั้นพื้นฐาน: การใช้กราฟในการตรวจจับการบุกรุกการตอบสนองการบุกรุกความฉลาดของภัยคุกคามและ UEBA การตรวจจับการบุกรุก: ทิศทางการพัฒนาของการตรวจจับการบุกรุกขององค์กรและประวัติการพัฒนาของความสามารถในการวิเคราะห์ข้อมูล การตอบสนองการบุกรุก: ปัญหาที่แก้ไขได้ในระหว่างกระบวนการ (ความสมบูรณ์และความสมบูรณ์ของบันทึกการวิเคราะห์ความสัมพันธ์ของข้อมูลขนาดใหญ่และหน้าต่างที่ยาวนานการก่อสร้างแบบเรียลไทม์และการสืบค้นของกราฟการโต้ตอบและการสร้างภาพข้อมูล) UEBA: การพัฒนาความน่าเชื่อถือของคลาวด์และศูนย์ความน่าเชื่อถือ -"ปลอดภัยโดยค่าเริ่มต้น -" การได้รับข้อมูลรับรองสำหรับบริการที่เชื่อถือได้การโจมตี "ซัพพลายเชน" -"การตรวจจับการบุกรุกที่สร้างขึ้นจากการวิเคราะห์พฤติกรรม -" การวิเคราะห์พฤติกรรมและการทำโปรไฟล์ สรุป: ปัญหาทางธุรกิจ -> ปัญหาข้อมูล
AI และความปลอดภัย
- การรวบรวมสื่อการเรียนรู้สำหรับสถานการณ์ความปลอดภัยอัลกอริทึมความปลอดภัยที่ใช้ AI และการวิเคราะห์ข้อมูลความปลอดภัย
- สู่ความเป็นส่วนตัวและความปลอดภัยของระบบการเรียนรู้ลึก: การสำรวจ
การโจมตีพื้นผิวของ AI Security : ในแง่ของข้อมูลและแบบจำลองในขั้นตอนการฝึกอบรมและขั้นตอนการทดสอบการโจมตีรวมถึงการเป็นพิษข้อมูลและตัวอย่างที่เป็นปฏิปักษ์การสกัดแบบจำลองและการผกผันของแบบจำลอง ฯลฯ - การตรวจจับภัยคุกคามอัจฉริยะ: แพลตฟอร์มการตรวจจับการเรียนรู้ของเครื่อง SOC
การก่อสร้างความปลอดภัยขององค์กร
การพัฒนาที่ปลอดภัย
- การก่อสร้างแพลตฟอร์มการตรวจจับความปลอดภัยการสแกนอัตโนมัติ (เว็บ Black Box)
- พาคุณไปอ่านการวิเคราะห์ซอร์สโค้ด Kunpeng ของสิ่งประดิษฐ์
การทดสอบความปลอดภัย
- วางแผนสำหรับการตั้งค่าการควบคุมความเสี่ยงและระบบเตือนล่วงหน้า
การควบคุมความเสี่ยงด้านความปลอดภัยทางธุรกิจ : ตรวจจับความผิดปกติอย่างรวดเร็วและกำหนดความเสี่ยงอย่างถูกต้อง ค้นพบชิ้นส่วนและเอนทิตีที่ผิดปกติผ่านการเปลี่ยนแปลงตัวชี้วัดหลักและค้นพบเอนทิตีทั้งหมดภายใต้กลุ่มที่ผิดปกติผ่านวิธีการจัดกลุ่ม - การเดินทางของการเปลี่ยนจากการรักษาความปลอดภัยแบบดั้งเดิมไปสู่การควบคุมความเสี่ยงและการหารือเกี่ยวกับแนวโน้มในอุตสาหกรรมสีดำและอุตสาหกรรมการควบคุมความเสี่ยง
การควบคุมความปลอดภัยทางธุรกิจ : การต่อสู้ในด้านการควบคุมความเสี่ยงกำลังเพิ่มมากขึ้นเรื่อย ๆ . ด้วยการพิจารณาคดีด้วยการปราบปรามแรงดันสูงของรัฐบาลเกี่ยวกับผลิตภัณฑ์สีดำและสีเทา บริษัท ขนาดใหญ่จะให้ความสนใจกับความสามารถของผลิตภัณฑ์และความถูกต้องตามกฎหมายของซัพพลายเออร์ควบคุมความเสี่ยงในอนาคต - Model Model Model Respol Model การเตรียมการสัมภาษณ์-บททางเทคนิค
- รูปแบบการควบคุมความเสี่ยง-การแข่งขันอัลกอริทึมการควบคุมความเสี่ยง "Magic Mirror Cup"
- วิธีการระบุผู้ใช้ควบคุมความเสี่ยง
- GitHub: sladesha
- อัลกอริธึมหลายตัวระบุผู้ใช้ที่ผิดปกติเช่นการบรรจุรับรองและการฉ้อโกงคูปอง
- DNS Tunnel Covert Communication Experiment && พยายามที่จะทำซ้ำการตรวจจับโหมดการคิดแบบเวกเตอร์
- Hids for Enterprise Security Construction
- สร้างความมั่นใจในความปลอดภัยของ IDC: การออกแบบสถาปัตยกรรมคลัสเตอร์ HIDS แบบกระจาย
- Dianrong Open Source Agentsmith Hids --- ระบบ HIDS ที่มีน้ำหนักเบา
- การก่อสร้างความปลอดภัยขององค์กร-แนวคิดบางอย่างเกี่ยวกับการออกแบบระบบ HIDS ที่ใช้ตัวแทน
ระบบตรวจจับการบุกรุกของการตรวจจับการบุกรุก : การปฏิบัติอย่างเป็นระบบของ Meituan นั้นคุ้มค่ากับการเรียนรู้ จากคำอธิบายความต้องการผู้จัดการผลิตภัณฑ์ส่งต่อความต้องการ -> วิเคราะห์ความต้องการสรุปลักษณะที่สถาปัตยกรรมผลิตภัณฑ์ต้องปฏิบัติตาม -> ปัญหาทางเทคนิควิเคราะห์ความท้าทายทางเทคนิคที่พบ -> การออกแบบสถาปัตยกรรมและการเลือกเทคโนโลยี -> คลัสเตอร์ HIDS แบบกระจายกระจาย แผนภาพสถาปัตยกรรม -> การเลือกภาษาการเขียนโปรแกรม -> การใช้งานผลิตภัณฑ์ - วิธีการตรวจจับอุโมงค์ ICMP และการดำเนินการตามการวิเคราะห์ทางสถิติ
ผลิตภัณฑ์รักษาความปลอดภัย
- รวบรวมโครงการความปลอดภัยโอเพ่นซอร์สที่ยอดเยี่ยมเพื่อช่วยผู้ปฏิบัติงานด้านความปลอดภัยของฝ่าย A สร้างความสามารถด้านความปลอดภัยขององค์กร (เรียนรู้) ผลิตภัณฑ์รักษาความปลอดภัยโอเพนซอร์ส : รวมถึงการจัดการสินทรัพย์การพัฒนาความปลอดภัยการตรวจสอบรหัสอัตโนมัติการดำเนินงานด้านความปลอดภัยและการบำรุงรักษาโฮสต์ Bastion , Honeypot, WAF, Enterprise Cloud Disk, ระบบเว็บไซต์ฟิชชิ่ง, การตรวจสอบ GitHub, การควบคุมความเสี่ยง, การจัดการช่องโหว่, SIEM/SOC
การดำเนินงานที่ปลอดภัย
- สิ่งที่ฉันเข้าใจเกี่ยวกับการดำเนินงานด้านความปลอดภัย
บริษัท จ่ายเงินเพื่อผลผลิตไม่ใช่ความรู้ การดำเนินงานด้านความปลอดภัยเป็นการมุ่งเน้นการแก้ปัญหา ความรับผิดชอบหลักและ ความต้องการทักษะ สำหรับ การดำเนินงานด้านความ ปลอดภัย : ความปลอดภัย, การดำเนินการและการบำรุงรักษา - มาพูดถึง สาเหตุ ของการดำเนินงานที่ปลอดภัย: ความเสี่ยงของความปลอดภัยได้รับการมองเห็น และการปรากฏตัว ที่ ปรากฏ
สิ่งที่และวิธี การดำเนินงานที่ปลอดภัย: ยึด ความขัดแย้งหลัก และความขัดแย้ง ทุติยภูมิ และพยายามอย่างเต็มที่เพื่อแก้ไขปัญหา
การจัดการความปลอดภัย
- การเปิดตัวทักษะการก่อสร้างความปลอดภัยขององค์กร V1.0 รวมถึงหกส่วน: คำอธิบาย, แนวคิดความปลอดภัย, การกำกับดูแลความปลอดภัย, ทักษะทั่วไป, ทักษะระดับมืออาชีพและทรัพยากรที่มีคุณภาพสูง
คิดปลอดภัย
- พูดคุยเกี่ยวกับทิศทางการพัฒนาของ Internet Enterprise Security
ทิศทางการพัฒนาความปลอดภัยขององค์กร : จากความตื้นเขินไปจนถึงที่ลึกกว่านั้นแบ่งออกเป็นสี่เป้าหมาย: 1. ขับเคลื่อนโดยการกำจัดช่องโหว่เป้าหมายแรกคือการทำให้รหัสทุกบรรทัดเขียนโดยวิศวกรที่ปลอดภัย การวิจัยทางเทคนิคและเทคโนโลยีที่ได้รับ 2. SDL ไม่สามารถรักษาความปลอดภัยได้ 100% ดังนั้นเป้าหมายที่สองคือการเปิดใช้งานการโจมตีที่รู้จักและไม่รู้จักทั้งหมดที่จะค้นพบในครั้งแรกและแจ้งเตือนและติดตามอย่างรวดเร็ว ความท้าทาย: ข้อมูลขนาดใหญ่และข้อกำหนดที่ซับซ้อน: พลังการประมวลผลสุดยอดและโมเดลสามมิติ 3. เป้าหมายที่สามคือการทำให้ความปลอดภัยเป็นความสามารถในการแข่งขันหลักของ บริษัท และลึกเข้าไปในคุณสมบัติของแต่ละผลิตภัณฑ์เพื่อเป็นแนวทางในพฤติกรรมการใช้อินเทอร์เน็ตของผู้ใช้ 4. เป้าหมายสุดท้ายคือการสังเกตการเปลี่ยนแปลงในแนวโน้มความปลอดภัยทางอินเทอร์เน็ตทั้งหมดและให้คำเตือนล่วงหน้าเกี่ยวกับความเสี่ยงในอนาคต เมื่อทำการรักษาความปลอดภัยใน บริษัท อินเทอร์เน็ตคุณต้องมีจินตนาการและให้ความสนใจกับการพัฒนาด้านเทคนิคอื่น ๆ ทำเสร็จแล้วนี่เป็นพิมพ์เขียวที่ยิ่งใหญ่ - การส่งเสริมการป้องกันผ่านความผิด: ความคิดเกี่ยวกับการสร้างกองทัพสีน้ำเงินขององค์กร
- Ciso Blitz ของ Zhao Yan |
ขอบเขตวัตถุ (ธุรกิจของ บริษัท ความท้าทายและความต้องการด้านความปลอดภัย (การป้องกันในเชิงลึกความปลอดภัยของห่วงโซ่อุปทานของตัวเองเพิ่มขีดความสามารถในการรักษาความปลอดภัยของบุคคลที่สาม)) ---> การตั้งค่าเป้าหมาย (การตั้งค่าความต้องการในปัจจุบันและการพัฒนาในอนาคต) ---> ความท้าทาย (ทั่วทั้งทีม สแต็ค (โครงสร้างความรู้และทักษะที่สอดคล้องกับธุรกิจหลัก) ความสามารถทางวิศวกรรมความสามารถในการจัดการ) ---> การสลายตัว ระบบรักษาความปลอดภัย (Security Construction Sandbox ในสาขาทั่วไป: ความปลอดภัยด้านการวิจัยและพัฒนา, ความปลอดภัยด้านไอที, ความปลอดภัยของโครงสร้างพื้นฐาน, ความปลอดภัยของข้อมูล, ความปลอดภัยของเทอร์มินัล, ความปลอดภัยทางธุรกิจ, ความเป็นส่วนตัวและการปฏิบัติตามข้อกำหนดด้านความปลอดภัย) ---> การดำเนินการและการตอบสนอง (กรอบการกำกับดูแลความปลอดภัย, การเปรียบเทียบอุตสาหกรรม ความสามารถการสาธิตไม่ได้นับเป็นความสามารถนี้) การวิจัยความปลอดภัย) โดยทั่วไปมันเป็นวิสัยทัศน์ทางเทคนิคแบบเต็มรูปแบบ (มุ่งมั่นที่จะเพิ่มขึ้นจากระดับทักษะไปจนถึงระดับวิสัยทัศน์ทางเทคนิค) + ความสามารถในการจัดการความปลอดภัย
สถาปัตยกรรมความปลอดภัย
- สถาปัตยกรรมความปลอดภัยของเครือข่าย
การเผชิญหน้าสีแดงและสีน้ำเงิน
- [การเผชิญหน้าสีแดงและสีน้ำเงิน] การก่อสร้างทีมรักษาความปลอดภัยกองทัพสีน้ำเงินสำหรับผู้ประกอบการอินเทอร์เน็ตขนาดใหญ่ (เรียนรู้)
ทำไมการเผชิญหน้าสีแดงและสีน้ำเงิน : ทดสอบระบบป้องกันความปลอดภัยขององค์กร;
การเผชิญหน้ากับการค้นพบการบุกรุกของการบุกรุกเป็นอย่างไร
How of Red-Blue Comprontation : Simulate APT ---> ทีมสีน้ำเงินจำเป็นต้องพัฒนาฐานความรู้ที่เป็นระบบและห้องสมุดอาวุธของเทคนิคการโจมตี ---> ATT && CK Matrix Framework
ความท้าทายในการเผชิญหน้ากับ DO : ประสิทธิภาพ/ผลประโยชน์;
อนาคตของการเผชิญหน้ากับสีน้ำเงินสีแดง : กองทัพสีน้ำเงินหลายระดับและหลายระดับ - การสร้างการเผชิญหน้าสีแดงสีแดงในยุคของการรักษาความปลอดภัยไซเบอร์สเปซ (มีบทความที่เกี่ยวข้องกับการเผชิญหน้าสีแดงสีน้ำเงินในภาคผนวก)
การต่อสู้ที่เกิดขึ้นจริงเป็นเกณฑ์เดียวสำหรับการทดสอบความสามารถในการป้องกันความปลอดภัย การทดสอบการเจาะนั้นเหมาะสำหรับการก่อสร้างระบบรักษาความปลอดภัยระดับองค์กรหรือขั้นตอนของความอ่อนเพลียและการเผชิญหน้ากับสีแดงสีน้ำเงินเป็นรุ่นที่ได้รับการอัพเกรดของการทดสอบการเจาะ ระบบการก่อสร้าง ความ ปลอดภัย /การแอบดูและสาขาอื่น ๆ จากมุมมองความปลอดภัยในโลกไซเบอร์
ความปลอดภัยอินทราเน็ต
- การจำลองการโจมตีความปลอดภัยอินทราเน็ตและการปฏิบัติตามกฎการตรวจจับความผิดปกติ
แนวคิดการเขียน : การรวบรวมข้อมูลภายนอก -> การพัฒนาขอบเขต -> การรวบรวมข้อมูล, การเพิ่มสิทธิ์การเพิ่มสิทธิ์ -> การบำรุงรักษาสิทธิพิเศษ -> การรวบรวมข้อมูล, การแยกข้อมูลรับรอง -> การเคลื่อนไหวด้านข้าง -> การขโมยข้อมูล -> ทำความสะอาดร่องรอย
ความปลอดภัยของข้อมูล
- Tencent Security เปิดตัว "แผนที่ความสามารถด้านความปลอดภัยของข้อมูลระดับองค์กร"
แนวคิดการเขียน : แผนที่ความสามารถด้านความปลอดภัยของข้อมูลประกอบด้วยหกประเด็นสำคัญ: การจัดการสินทรัพย์ข้อมูลและความสามารถในการควบคุมความสามารถในการดำเนินงานด้านความปลอดภัยของข้อมูลการจัดการความปลอดภัยทางธุรกิจและความสามารถในการควบคุมข้อมูลการจัดการความปลอดภัยของสภาพแวดล้อมการจัดการความปลอดภัยและความสามารถในการควบคุมการดำเนินงานและการจัดการความปลอดภัยการบำรุงรักษา ความสามารถและความสามารถในการรับรู้ความปลอดภัยของข้อมูล
เทคโนโลยีใหม่และความปลอดภัยใหม่
ภาพรวม
- แอปพลิเคชันปรับปรุงความทันสมัยและการเปลี่ยนแปลงความปลอดภัยที่เหลืออยู่ในการแปลงดิจิตอล
แนวคิดการเขียน : โครงสร้างพื้นฐานใหม่ -> การเปลี่ยนแปลงแบบดิจิทัล -> การให้ข้อมูลแบบดั้งเดิมเผชิญกับความท้าทาย -> แอปพลิเคชันที่ขับเคลื่อนด้วยธุรกิจ -> คลาวด์ดั้งเดิม, คอนเทนเนอร์, devops, แอปพลิเคชันไมโครไซต์, การประสานและเทคโนโลยีใหม่ -> สถาปัตยกรรมที่ทันสมัยของแอปพลิเคชัน -> ความปลอดภัยภายนอก (ทั้งหมด -การรับรู้รอบ ๆ , ความน่าเชื่อถือ, การแทรกแซงความปลอดภัยเต็มรูปแบบและการดำเนินงานที่ปลอดภัยของเครือข่ายคลาวด์)
เมฆพื้นเมือง
- การตีความของพร็อกซีเครือข่ายเนทีฟ MOSN เทคโนโลยีการจี้โปร่งใส
แนวคิดการเขียน : บริการ mesh-> istio-> data plane-> network proxy-> mosn-> การจี้จี้ปริมาณการใช้งานที่มีประสิทธิภาพและโปร่งใส ปัญหา: การเข้ายึดครองการจราจร การแก้ปัญหา: การปรับสภาพแวดล้อมการจัดการการกำหนดค่าประสิทธิภาพของเครื่องบินข้อมูล - การสังเกตแนวโน้มการตรวจจับการบุกรุกของเมฆ
แนวคิดของการเขียน : การกระจายสินทรัพย์, การกระจายตัวของบริการ, การระเบิดของมิดเดิลแวร์, ความปลอดภัยของโครงสร้างพื้นฐานโดยค่าเริ่มต้น -> การตรวจจับการบุกรุกทางธุรกิจ "การวิเคราะห์เชิงพฤติกรรมการวิเคราะห์พฤติกรรมจะกลายเป็นความสามารถหลัก - Wang Renfei (Avfisher): Red Teaming for Cloud (ความผิดเมฆและการป้องกัน) (Mark)
คอมพิวเตอร์ที่เชื่อถือได้
- จางอู: การปฏิบัติเครือข่ายที่เชื่อถือได้ของธนาคารดิจิตอล
แนวคิดการเขียน : ประเด็นสำคัญคือ: การป้องกันในเชิงลึกในระดับเครือข่าย ทำไมต้องทำ (ท้าทาย) -> ความคิดและแผนสำหรับการดำเนินการ -> ความท้าทายและความคิดในกระบวนการ - เขายี่: เส้นทางสู่การฝึกฝนสถาปัตยกรรมความปลอดภัยที่น่าเชื่อถือเป็นศูนย์
จุดหลัก : แกนกลางของศูนย์ความไว้วางใจคือการจัดตั้งห่วงโซ่ความน่าเชื่อถือเช่นผู้ใช้ + อุปกรณ์ + แอปพลิเคชันการตรวจสอบแบบไดนามิกที่ปลอดภัยและต่อเนื่องและทำให้พื้นผิวการโจมตีลดลง ทำงานเสร็จแล้ว: เกตเวย์เครือข่าย, เกตเวย์โฮสต์, เกตเวย์แอปพลิเคชัน, SOC
devsecops
- "ความปลอดภัยต้องการการมีส่วนร่วมของวิศวกรทุกคน" -DevSecops ปรัชญาและการคิด (Mark)
การพัฒนาที่ปลอดภัย
การพัฒนาส่วนบุคคล
สัมภาษณ์
- การสัมภาษณ์ด้านความปลอดภัยการฝึกงาน ฯลฯ
การสัมภาษณ์ : Didi, Baidu (2), 360 (2), Alibaba (6), Tencent (3), Bilibili, Huawei, Tonghuashun, Mogujie โดยทั่วไปแล้วคนที่ยิ่งใหญ่นั้นแข็งแกร่งมากจนตัวเลือกส่วนใหญ่เป็นแผนกรักษาความปลอดภัยของ Party A ความเข้าใจของฉัน: หลังจากอ่านการสัมภาษณ์และคำถามที่ถามโดยคนที่ยิ่งใหญ่มันมีความหลากหลายมากรวมถึงการวางแนวถังการวางแนวความปลอดภัยของข้อมูลการวางแนวความปลอดภัย ฯลฯ ซึ่งมีค่าอ้างอิงบางอย่าง แต่เพราะทิศทางแตกต่างกันดังนั้นคุณ ไม่สามารถคัดลอกได้อย่างเข้มงวด - 2018 สรุปความปลอดภัยในการสรรหาบุคลากรในฤดูใบไม้ผลิการสัมภาษณ์การฝึกงาน
- TENCENT 2016 การฝึกงานการฝึกงานที่มีรายละเอียด
การทดสอบเป็นลายลักษณ์อักษร : การออกแบบโซลูชันการตรวจสอบเว็บที่ปลอดภัย: Front-end: รหัสการตรวจสอบ + CSRF_TOKEN + สร้างหมายเลขสุ่มตามการเข้ารหัส Timestamp; , พอร์ต, โปรโตคอล); - การสัมภาษณ์ตำแหน่งเทคโนโลยีความปลอดภัยใน บริษัท ขนาดใหญ่
การสัมภาษณ์ : พื้นฐานของเทคโนโลยีความปลอดภัย ---> รายละเอียดโครงการ (ความรู้เชิงลึกผู้สัมภาษณ์ในด้านความเชี่ยวชาญป้องกันไม่ให้ผู้สัมภาษณ์ถามคำถามเชิงลึก) ---> วิธีจัดการกับคำถามที่ท้าทาย (ความรู้และความรู้ความเข้าใจในอุตสาหกรรม โดยทั่วไปความสามารถไม่เบี่ยงเบนจากสาขาของความเชี่ยวชาญและต้องการการอ่านและการคิดทุกวัน) ---> อุตสาหกรรมความสามารถในการเรียนรู้เชิงลึกและการวางแผนอาชีพ - สถานการณ์ปัจจุบันของการอ้างอิงภายในสำหรับ Alibaba Interns ในปี 2562 คืออะไร? - คำตอบของ Zuo Zuo Vera - Zhihu (เรียนรู้)
- สิบใบหน้าของอาลี, หน้าตาเจ็ดหน้า, คุณคิดว่าฉันได้เข้าสู่อาลีหรือไม่?
บทสัมภาษณ์ : ประสบการณ์การสัมภาษณ์ที่ยอดเยี่ยม Java ซึ่งเป็นสิ่งที่ต้องมีสำหรับ Java - Book of Swords and Enmities: Me and Alibaba (แข็งแกร่งเกินไป)
- คำถามสัมภาษณ์การรับสมัครรักษาความปลอดภัย (เรียนรู้)
แนวคิดการเขียน : การทดสอบการเจาะ (ทิศทางเว็บ), การวิจัยและพัฒนาความปลอดภัย (ทิศทาง Java), การดำเนินงานด้านความปลอดภัย (ทิศทางการตรวจสอบการปฏิบัติตามกฎระเบียบ), สถาปัตยกรรมความปลอดภัย (ทิศทางการจัดการความปลอดภัย)
การเรียนรู้เพิ่มเติม : CRLF, ความแตกต่าง, ข้อดีและข้อเสียของการเข้ารหัสแบบสมมาตรและการเข้ารหัสแบบอสมมาตร, กระบวนการปฏิสัมพันธ์ HTTPS, นโยบายต้นกำเนิด, คำขอข้ามโดเมน - ประวัติย่อที่ดีมีลักษณะอย่างไรสำหรับการสรรหาที่ปลอดภัย?
- การรับสมัครรักษาความปลอดภัย: สถานการณ์ปัจจุบันของอุตสาหกรรมความปลอดภัย
- คุณสมบัติที่สำคัญของผู้ปฏิบัติงานด้านความปลอดภัยเพื่อการสรรหาความปลอดภัย
แนวคิดการเขียน: คุณภาพพื้นฐาน = ความสามารถขั้นพื้นฐาน (การเรียนรู้ด้วยตนเอง + การเรียนรู้อิสระ) + ความสามารถในการใช้งานระดับมืออาชีพ (การโจมตีการบุกและการป้องกัน + การพัฒนาซอฟต์แวร์) คุณภาพขั้นสูง = ความฉลาด (IQ + ความฉลาดทางอารมณ์) + ความกล้าหาญและการมองโลกในแง่ดี + วิปัสสนา - ขั้นตอนการสัมภาษณ์เพื่อการสรรหาอย่างปลอดภัยนั้นขี้เกียจตอนนี้และจะมีค่าใช้จ่ายมากขึ้นในการชดเชยในภายหลัง
- 2019 วิศวกรความปลอดภัย
การเขียนแนวคิด : การติดตามเก่าและการเดินทางใหม่ - "อุตสาหกรรมนักสำรวจหรือผู้ติดตาม -" การแลกเปลี่ยนข้อมูลอุตสาหกรรมที่โปร่งใส - "เพิ่มเกลือเล็กน้อยให้กับชีวิต"
การพัฒนาอาชีพ
- การฝึกฝนตนเองของนักวิจัยด้านความปลอดภัย
- การฝึกฝนตนเองของนักวิจัยด้านความปลอดภัย (ต่อ)
- การอภิปรายเกี่ยวกับทิศทางการพัฒนาของเจ้าหน้าที่รักษาความปลอดภัย
เส้นทางการพัฒนาความปลอดภัยของ Party A : ประเภทเทคโนโลยีฮาร์ดคอร์ ---> Dachang Laboratories และโพสต์การวิจัยด้านความปลอดภัยโพสต์ประเภทเทคโนโลยีที่ไม่ใช่หลัก ---> Internet Enterprise Security Construction สีแดงและสีน้ำเงินการดำเนินงานด้านเทคนิคการจัดการความปลอดภัย - ความสำคัญของการดำรงอยู่ของผู้ปฏิบัติงานด้านความปลอดภัย
การพัฒนาส่วนบุคคล : เป้าหมายคือการช่วยเพิ่มผลผลิตขั้นสูงแก้ปัญหาความปลอดภัย ปัญหาด้านความปลอดภัยเป็นปัญหาที่น่าเชื่อถือ (การสนับสนุนความน่าเชื่อถือการสนับสนุนต้นกำเนิด) วิทยาศาสตร์ที่ศึกษาการเผชิญหน้า (การเผชิญหน้าระหว่างผู้คน) และปัญหาความน่าจะเป็น (สถาปัตยกรรมความปลอดภัย)安全是一门应用科学,随着每个时代的不同,可以有很多不同的技术手段和工具来完成各自的安全目标,因此安全从业者应该对新技术和先进生产力保持敏感和接受度,这会带来很多新的视角和能力,包括机器智能和区块链技术等。 - 安全团队在企业中的几个身份
团队发展:安全团队应该以服务者和协作者的身份,用专业的安全能力给出一类安全问题的解决思路和方案并解决,防止安全问题发生多次。
行业发展
安全格局
- 最新统计2005-2017年国内科研单位在国际安全顶级会议中发表文章量统计
- 从内容产出看安全领域变化
技术格局:企鹅等互联网巨头开始进行流量封锁,对安全从业人员影响很大,爬不到数据,api又有限,只能上升到app hook了;技术上安全分析、数据挖掘、威胁情报的比重越来越重, AI已经不仅仅是噱头了,智能安全势不可挡;安全的职业发展方面,越来越多大佬们开始转型业务安全、数据安全。 - 网络安全行业竞争格局浅析
市场格局:基础安全防护(传统安全防护能力),中级安全防护(海量数据建模与分析能力),高级安全防护(云端威胁情报与分析能力),中高级安全防护市场广阔。此外,全文在多处凸显了人工智能技术,智能安全开始迈入开悟之坡了吗? -半数以上的人看好智能安全,也有人不看好智能安全,未来会怎么样,让我们拭目以待! - ZoomEye 网络空间测绘——委内瑞拉停电事件对其网络关键基础设施和重要信息系统影响
- 2020安全工作展望
Logic of writing : Major events in 2019 : HW action changes safety from implicit to explicit, low frequency to high frequency, exposes problems, and promotes management to pay attention to safety. This is the background; Classification Protection 2.0 safety compliance is becoming more stringent . 2019大变化:领导重视了;实战化了。 2020甲方安全关注技术点:安全运营(覆盖率和正常率等指标、是否有验证思路:能否在一定时间内主动发现安全措施失效)和安全资产管理(CMDB、主机上数据、流量、扫描、人工添加)。 2020关注“人”的需求。 2020展望行业:甲方安全团队组织架构会发生剧烈变化,安全团队能否承受变化;甲乙两方相处之道;安全黑天鹅事件越来越多。
安全产品
- C端安全产品的未来之路
C端安全产品:移动端安全产品是否会像前几天PC端安全产品一样迎来春天?PC时代windows是一家独大的完全开放的平台,这让第三方安全公司能够在平台和用户之间产生价值的空间足够的大,但在移动端,安卓开始封闭,就不好说了。传统安全软件围绕病毒和欺诈,而围绕个人信息安全的C端安全产品有一线生机。 - 下一座圣杯- 2019
API安全:应用安全的发展:2015年预测,数据是新中心,身份是新边界,行为是新控制,情报是新服务。基础设施演进->交付方式的改变。2015年,应用安全领域的WAF产品是良机,由市场决定。新形势与新机遇:微服务、Serverless、边缘计算。市场中的交付方式发生变化。跨细分领域且跨基础设施:API安全横跨应用安全、数据安全和身份安全三大领域。API使用场景广泛,需要产品有全面覆盖多种不同基础设施的能力。
ข้อมูล
数据体系
- 数据分析师如何搭建数据运营指标体系? - 张溪梦Simon的回答
Core point : Collaboration process empowerment : Implementing the data-driven XX indicator system construction process requires cross-team collaboration. The processes include: demand collection, program planning, data collection, collection program evaluation, data collection and data verification online, and effect evaluation .规划数据指标体系的两个模型:OSM和UJM。 OSM强调业务目标,UJM强调用户旅程。指标分级体系:一二三级指标联动。 - 如何在企业中从0-1建立一个数据/商业分析部门?(学到了)
部门的定位和价值——>里程碑设计——->团队搭建——->构建IT数据——->前期管理。
定位和价值是一个部门立足公司的根本:做报表的部门VS做战略的部门;业务其他公司的定位和公司内其他部门的认可;一定要会放大部门的价值和一定要走高层路线。
设立长期目标并拆解里程碑:公司业务目标--->公司战略--->部门目标--->部门里程碑--->工作计划;设立里程碑的技巧?借势、共赢、取巧、筑基;借老板势,寻找1-2个老板的痛点问题解决;寻找利益相同的部门共建共赢;取巧摘已有的“桃子”;筑基数据链路梳理、数据清洗、系统互联、数据仓库设计、数据集市设计。
基于里程碑进行团队搭建:切忌一步到位;审慎拉帮结派;遇到人才不可错过;学会“画饼”;注意团队文化建设。
构建公司的数据IT能力:搭建基础且通用的数据流框架:应用层、归集层、加工层、分析层、展示层; 同时根据各种数据库选型指标选择对应的数据库存储产品,数据库选型指标比如容量、水平扩展性、查询实时性、查询灵活性、写入速度、事务、数据存储、处理数据规模、列扩展性。在搭建数据框架中需要注意的点是:需要实现公司级别的业务数据架构。基于业务对整个公司的数据进行体系化的梳理,任何的业务变化都会体现在数据之上,实现数据充分体现业务现状的目的。要完成这一步的关键是完成公司级别的主数据管理:明确各项数据的业务含义和口径、明确每个数据的职责单位、打通数据链路,推动数据共享。
引领团队走向胜利:做“排长”而不要做“军长”;让合适的人做合适的事;明确规则,及时兑现。
数据分析与运营
- 数据分析与可视化:谁是安全圈的吃鸡第一人(学到了)
数据分析与可视化:收集数据集--->观察数据集--->社群发现与社区关系--->玩家画像。 - 请分享一下数据分析方面的思路,如何做好数据分析?
核心点:数据分析的问题:业务的数据分析指标体系(点线面体)。数据分析的方法:分类和对比。
安全数据分析
- Data-Knowledge-Action: 企业安全数据分析入门(优秀,学到了)
综述: 1、让模型理解业务,基于业务历史行为建立异常基线,在异常的基础上检测威胁;将运营结果反馈到模型,将误报视作正常行为回流。2、安全运营可运营,降低事件调查成本,自动化信息收集与聚合。3、随着数据的积累,安全数据分析将向基于图结构的高级知识表达方式发展。(这点深表赞同)4、对场景、攻击模式、数据的认识深度,远比选择工具重要。 - Security Data Science Learning Resources
综述:作者的研究点也是安全数据科学,整理了一些学习方法和学习资源。学习方法主要分为三个方面:谷歌学术、Twitter、安全会议。谷歌学术关注知名研究者以及他们新出的文章,关注引用了你关注的文章的文章,Twitter关注细分安全领域的人群,关注安全会议以及会议议程。学习资源:书籍和课程。 - 快速搭建一个轻量级OpenSOC架构的数据分析框架(一)(学到了)
框架:行文思路:由粗变细(由框架到举例子(由框架到场景到实际架构))。OpenSOC介绍(框架组成和工作流程)---》构建轻量级OpenSOC(聚焦具体场景和工具及具体架构)---》搭建步骤(每一步的环境搭建及配置)---》效果展示。 - 先知talk:从数据视角探索安全威胁
- 大数据威胁建模方法论(学到了很多)
- 安全日志维度随想
- 数据安全分析思想探索
- DataCon 2019: 1st place solution of malicious DNS traffic & DGA analysis(学到了)
我的理解:涉及的知识点有:安全场景:DNS安全;数据处理:tshark工具的使用,MaxCompute和SQL的使用,PAI预分析和可视化;特征工程:DNS_type、src_ip维度的特征;异常检测算法:单特征3sigma检测;人工提取特征规则。
第一小题DNS恶意流量的异常检测:个人吸收80%,整理流程无障碍,每步流程中的细节和工具还未完全掌握,比如DNS安全场景了解不全面、tshark的大量数据解析、统计特征的全面提取、SQL语句做特征化;
第二小题DGA的多分类:个人吸收50%,流程搞懂了,但是对一些问题的理解还不到位,比如社区算法 - 基于大数据企业网络威胁发现模型实践
我的理解:问题:多源安全分析设备和服务(威胁数据)的横向和纵向联动。
อัลกอริทึม
AI
算法体系
- 机器学习算法集锦:从贝叶斯到深度学习及各自优缺点
算法知识框架:主要从算法的定义、过程、代表性算法、优缺点解释回归、正则化算法、人工神经网络、深度学习||决策树算法、集成算法||支持向量机||降维算法、聚类算法||基于实例的算法||贝叶斯算法||关联规则学习算法||图模型。
个人理解:回归系列主要基于线性回归和逻辑回归衍生,包括回归、正则化算法、人工神经网络、深度学习;树系列主要基于决策树衍生,包括决策树和基于树的集成学习算法;支持向量机属于老牌算法;降维算法和聚类算法主要基于数据的内在结构描述数据;基于实例的算法实际上并没有训练的过程,代表性算法是KNN,基于记忆的学习;贝叶斯算法利用贝叶斯定理计算输出概率;关联规则学习算法能够提取数据中变量之间的关系的最佳解释;图模型是一种概率模型,可以表示随机变量之间的条件依赖结构。 - Categories of algorithms non exhaustive (学到了)
算法知识框架:学到了搭建自己的算法体系。
基础知识
- HTTP DATASET CSIC 2010
Security Data Set-CSIC2010 : A security data set automatically generated based on e-Commerce Web application, including 36,000 normal requests and 25,000 abnormal requests. Abnormal requests include: SQL injection, buffer overflow, information collection, file leakage, CRLF injection, XSS etc . - 分类模型的性能评估——以SAS Logistic 回归为例(3): Lift 和Gain
- 机器学习中非均衡数据集的处理方法?
非均衡数据集:上采样和下采样、正负样本的惩罚权重(scikit-learn的SVM为例:class_weight:{dict,'balanced'})、组合/集成方法(从大样本中抽取多个小样本训练模型再集成)、特征选择(小样本量具有一定规模的时候,选择显著型的特征) - 机器学习算法中GBDT 和XGBOOST 的区别有哪些?
算法比较:GBDT基分类器为CART,XGB的分类器可以是多种基分类器,比如线性分类器,这时候就相当于L1、L2正则项的逻辑回归或线性回归;传统的GBDT在优化时用到的是一阶导数,XGB则对损失函数进行了二阶泰勒公式的展开,精度变高;XGB并行处理(特征粒度的并行,对特征值进行预排序存储为block结构,在进行节点分类的时候,需要计算每个特征的增益,最终选择增益最大的那个特征去做分类,那么各个特征的增益计算就可以开多线程进行),相对于GBM速度飞跃;剪枝时,当新增分类带来负增益时,GBM会停止分裂,而XGB一直分类到指定的最大深度,然后进行后全局剪枝;从最优化的角度来看,GBDT采用的是数值优化的思维,用的最速下降法去求解Loss function的最优解,其中用CART决策树去拟合负梯度,用牛顿法求步长,而XGB用的是解析的思维,对Loss function展开到二阶近似,求得解析解,用解析解作为Gain来建立决策树,使得Loss function最优。 - SVM和logistic回归分别在什么情况下使用?
算法使用场景-SVM和逻辑回归使用场景:需要根据特征数量和训练样本数量来确定。如果特征数相对于训练样本数已经够大了,使用线性模型就能取得不错的效果,不需要过于复杂的模型,则使用LR或线性核函数的SVM。 If the training samples are large enough and the number of features is small, better prediction performance can be obtained through SVM with complex kernel functions. If the samples do not reach millions, SVM with complex kernel functions will not cause the operation to be too slow .如果训练样本特别大,使用复杂核函数的SVM已经会导致运算过慢了,因此应该考虑引入更多特征,然后使用线性SVM或者LR来构造模型。 - gbdt的残差为什么用负梯度代替?
- 欧氏距离与马氏距离
- 机器学习算法常用指标总结
- 分类模型评估之ROC-AUC曲线和PRC曲线
การเรียนรู้ของเครื่อง
- 平均数编码:针对高基数定性特征(类别特征)的数据预处理/特征工程
- Mean Encoding
- kaggle编码categorical feature总结
- Python target encoding for categorical features
- Mean (likelihood) encodings: a comprehensive study
- 如何在Kaggle 首战中进入前10%
- kaggle竞赛总结
- 分享一波关于做Kaggle比赛,Jdata,天池的经验,看完我这篇就够了
- 为什么在实际的kaggle比赛中,GBDT和Random Forest效果非常好?
有监督学习-树系列算法:单模型,gradient boosting machine和deep learning是首选。gbm不需要复杂的特征工程,不需要太多时间去调参数,dl则需要比较多的时间去调网络结构。从overfit角度理解,两者都有overfit甚至perfect fit的能力,overfit能力越强,可塑性越强,然后我们要解决的问题就是如果把模型训练的“恰好”,比如gbm里有early_stopping功能。线性回归模型就缺乏overfit能力,如果实际数据符合线性模型的关系,那可以得到很好的结果,如果不符合的话,就需要做特征工程,可特征工程又是一个比较主观的过程。树的优势,非参数模型,gbm的overfit能力强。而random forest的perfact fit能力很差,这是因为rf的树是独立训练的,没有相互协作,虽然是非参数型模型,但是浪费了这个先天优势。 - 【总结】树类算法认知总结
有监督学习-树类算法:分类树和回归树的区别;避免决策树过拟合的方法;随机森林怎么应用到分类和回归问题上;kaggle上为啥GBDT比RF更优;RF、GBDT、XGBoost的认知(原理、优缺点、区别、特性)。 - LightGBM
- LightGBM算法总结
- 『我爱机器学习』集成学习(四)LightGBM
- 如何玩转LightGBM(官方slides讲解)
有监督学习-LightGBM-个人理解: LightGBM几大特性及原理:直方图分割及直方图差加速(直方图两大改进:直方图复杂度=O(#feature×#data),GOSS降低样本数,EFB降低特征数)-》效率和内存提升。Leaf-wise with max depth limitation取代Level-wise-》准确率提升。支持原生类别特征。并行计算:数据并行(水平划分数据)、特征并行(垂直划分数据)、PV-Tree投票并行(本质上是数据并行)。 - 快速弄懂机器学习里的集成算法:原理、框架与实战
- 时间序列数据的聚类有什么好方法?
无监督学习-时间序列问题:传统的机器学习数据分析领域:提取特征,使用聚类算法聚集;在自然语言处理领域:为了寻找相似的新闻或是把相似的文本信息聚集到一起,可以使用word2vec把自然语言处理成向量特征,然后使用KMeans等机器学习算法来作聚类;另一种做法是使用Jaccard相似度来计算两个文本内容之间的相似性,然后使用层次聚类的方法来作聚类。常见的聚类算法:基于距离的机器学习聚类算法(KMeans)、基于相似性的机器学习聚类算法(层次聚类)。对时间序列数据进行聚类的方法:时间序列的特征构造、时间序列的相似度方法。如果使用深度学习的话,要么就提供大量的标签数据;要么就只能使用一些无监督的编码器的方法。 - 凝聚式层次聚类算法的初步理解
无监督学习-层次聚类:算法步骤:计算邻近度矩阵--->(合并最接近的两个簇--->更新邻近度矩阵)(repeat),直到达到仅剩一个簇或达到终止条件。 - 推荐算法入门(1)相似度计算方法大全
无监督学习-层次聚类-相似性计算:曼哈顿距离、欧式距离、切比雪夫距离、余弦相似度、皮尔逊相关系数、Jaccard系数。
การเรียนรู้อย่างลึกซึ้ง
CPU环境搭建
- tensorflow issues#22512
Nature of the problem : Error: ImportError: DLL load failed, reason: missing dependencies, solution: pip install --index-url https://pypi.douban.com/simple tensorflow==2.0.0, dependencies will be installed automatically .
GPU环境搭建
- Tensorflow和Keras 常见问题(持续更新~)(坑点)
- Tested build configurations(版本对应速查表)
- windows tensorflow-gpu的安装(靠谱)
- windows下安装配置cudn和cudnn
问题本质:总的来说,是英伟达显卡驱动版本、cuda、cudnn和tensorflow-gpu之间版本的对应问题。最好装tensorflow-gpu==1.14.0,tensorflow-gpu==2.0需要cuda==10.0,10.2会报错,tensorflow-gpu==2.0不支持。 - win10搭建tensorflow-gpu环境
问题本质:CUDA的各种环境变量添加。
深度学习基础知识
- 深度学习中的batch的大小对学习效果有何影响?
- Batch Normalization原理与实战(还没完全看懂)
神经网络基本部件
- 如何计算感受野(Receptive Field)——原理感受野:卷积层越深,感受野越大,计算公式为(N-1)_RF = f(N_RF, stride, kernel) = (N_RF - 1) * stride + kernel,思路为倒推法。
- 如何理解空洞卷积(dilated convolution)谭旭的回答空洞卷积:池化层减小图像尺寸同时增大感受野,空洞卷积的优点是不做pooling损失信息的情况下,增大感受野。3层3*3的传统卷积叠加起来,stride为1的话,只能达到(kernel_size-1)layer+1=7的感受野,和层数layer成线性关系,而空洞卷积的感受野是指数级的增长,计算公式为(2^layer-1)(kernel_size-1)+kernel_size=15。
- 空洞卷积(dilated convolution)感受野计算
- 空洞卷积(dilated Convolution)
- 直观理解神经网络最后一层全连接+Softmax(便于理解)
全连接层:可以理解为对特征的加权求和。
神经网络基本结构
- 一组图文,读懂深度学习中的卷积网络到底怎么回事?
卷积神经网络:卷积层参数:内核大小(卷积视野3乘3)、步幅(下采样2)、padding(填充)、输入和输出通道。卷积类型:引入扩张率参数的扩张卷积、转置卷积、可分离卷积。 - 卷积神经网络(CNN)模型结构
- 总结卷积神经网络发展历程- 没头脑的文章(很全面)
- 三次简化一张图:一招理解LSTM/GRU门控机制(很清晰)
循环神经网络:文中电路图的形式好理解。RNN:输入状态、隐藏状态。LSTM:输入状态、隐藏状态、细胞状态、3个门。GRU:输入状态、隐藏状态、2个门。LSTM和GRU通过设计门控机制缓解RNN梯度传播问题。 - gcn
- GRAPH CONVOLUTIONAL NETWORKS
图神经网络:相较于CNN,区别是图卷积算子计算公式。 - keras-attention-mechanism
神经网络应用
- [AI识人]OpenPose:实时多人2D姿态估计| 附视频测试及源码链接
- 使用生成对抗网络(GAN)生成DGA
- GAN_for_DGA
- 详解如何使用Keras实现Wassertein GAN
- Wasserstein GAN in Keras
- WassersteinGAN
- keras-acgan
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题- 综述和实践
NLP :传统的高维稀疏->现在的低维稠密。注意事项:类目不均衡、理解数据(badcase)、fine-tuning(只用word2vec训练的词向量作为特征表示,可能会损失很大效果,预训练+微调)、一定要用dropout、避免训练震荡、超参调节、未必一定要softmax loss、模型不是最重要的、关注迭代质量(为什么?结论?下一步?)
强化学习
- 深度强化学习的弱点和局限
- 关于强化学习的局限的一些思考
强化学习的局限性:采样效率很差、很难设计一个合适的奖励函数。
应用领域
- 全球最全?的安全数据网站(有时间得好好整理一下)
- 初探机器学习检测PHP Webshell
- 基于机器学习的Webshell 发现技术探索
- 网络安全即将迎来机器对抗时代?
智能安全-智能攻击:国外已经在研究利用机器学习打造更智能的攻击工具,比如深度强化学习,就是深度学习和强化学习的结合,可以感知环境,做出最优决策,可能被应用到漏洞扫描器里,使扫描器能够自动化地入侵目标。
个人理解:国外已有案例Deep Exploit就是利用深度强化学习结合metasploit进行自动化地渗透测试,国内还没有看到过相关公开案例。由于学习门槛高、安全本身攻击场景需要精细化操作、弱智能化机器学习导致的机器学习和安全场景结合深度不够等一系列的问题,已有的机器学习+安全的大多数研究主要集中在安全防护方面,机器学习+攻击方面的研究较少且局限,但是我相信这个场景很有潜力,或许以后就成为蓝方的攻击利器。 - 人工智能反欺诈三部曲之:设备指纹
智能安全-业务安全-设备指纹:ip、cookie、设备ID ;主动式设备指纹:使用JS或SDK从客户端抓取各种各样的设备属性值,然后组合,通过hash算法得到设备ID;优点:Web内或者App内准确率高。缺点:主动式设备指纹在Web与App之间、不同的浏览器之间,会生成不同的设备ID,无法实现跨Web和App,不同浏览器之间的设备关联;由于依赖客户端代码,指纹在反欺诈的场景中对抗性较弱。被动式设备指纹:从数据报文中提取设备OS、协议栈和网络状态的特征集,并结合机器学习算法识别终端设备。优点:弥补了主动式设备指纹的缺点。缺点:占用处理资源多;响应时延比主动式长。 - 风险大脑支付风险识别初赛经验分享【谋杀电冰箱-凤凰还未涅槃】
智能安全-业务安全-风控:个人理解见:https://github.com/404notf0und/Risk-Operation-Detection/blob/master/atec.ipynb。 - 机器学习在互联网巨头公司实践
入侵检测:机器学习和统计建模的主要区别:机器学习主要依赖数据和算法,统计建模依赖建模者对数据特征的了解。两者的优缺点:机器学习:打标数据难获取,如果采用非监督学习,则性能不足以运维;机器学习结果不可解释。所以现在机器学习在做入侵检测的时候,一般都要限定一个特定的场景。统计建模:数据预处理阶段移除正常数据的干扰(重点关注查全率,强调过正常数据的过滤能力,尽可能筛除正常数据),构建能够识别恶意可疑行为的攻击模型(重点关注precision,强调模型对异常攻击模式判断的准确性,攻击链模型),缺点是泛化能力不足、在入侵检测一些场景中,模型易被干扰。我们的最终目的:大数据场景下安全分析可运维。 - Web安全检测中机器学习的经验之谈
Web安全:从文本分类的角度解决Web安全检测的问题。数据样本的多样性,短文本分类,词向量,句向量,文本向量。文本分类+多维度特征。与传统方法做对比得出更好的检测方式:传统方法+机器学习:传统waf/正则规则给数据打标;传统方法先进行过滤。 - 词嵌入来龙去脉(学到了)
เอ็นแอลพี :DeepNLP的核心关键:语言表示--->NLP词的表示方法类型:词的独热表示和词的分布式表示(这类方法都基于分布假说:词的语义由上下文决定,方法核心是上下文的表示以及上下文与目标词之间的关系的建模)--->NLP语言模型:统计语言模型--->词的分布式表示:基于矩阵的分布表示、基于聚类的分布表示、基于神经网络的分布表示,词嵌入--->词嵌入(word embedding是神经网络训练语言模型的副产品)--->神经网络语言模型与word2vec。 - 深入浅出讲解语言模型
NLP :NLP统计语言模型:定义(计算一个句子的概率的模型,也就是判断一句话是否是人话的概率)、马尔科夫假设(随便一个词出现的概率只与它前面出现的有限的一个或几个词有关)、N元模型(一元语言模型unigram、二元语言模型bigram)。 - 有谁可以解释下word embedding? - YJango的回答- 知乎
NLP :单词表达:one hot representation、distributed representation。Word embedding:以神经网络分析one hot representation和distributed representation作为例子,证明用distributed representation表达一个单词是比较好的。word embedding就是神经网络分析distributed representation所显示的效果,降低训练所需的数据量,就是要从数据中自动学习出输入空间到distributed representation空间的映射f(相当于加入了先验知识,相同的东西不需要分别用不同的数据进行学习)。训练方法:如何自动寻找到映射f,将one hot representation转变成distributed representation呢?思想:单词意思需要放在特定的上下文中去理解,例子:这个可爱的泰迪舔了我的脸和这个可爱的京巴舔了我的脸,用输入单词x 作为中心单词去预测其他单词z 出现在其周边的可能性(至此我才明白为什么说词嵌入是神经网络训练语言模型的副产品这句话)。用输入单词作为中心单词去预测周边单词的方式叫skip-gram,用输入单词作为周边单词去预测中心单词的方式叫CBOW。 - Chars2vec: character-based language model for handling real world texts with spelling errors and…
- Character Level Embeddings
- 使用TextCNN模型探究恶意软件检测问题
恶意软件检测:改进分为两个方面:调参和结构。调参:Embedding层的inputLen、output_dim,EarlyStopping,样本比例参数class_weight,卷积层和全连接层的正则化参数l2,适配硬件(GPU、TPU)的batch_size。结构:增加了全局池化层。
学到了:一个trick,通过训练集和评价指标logloss计算测试集的各标签数量,以此调整训练阶段的参数class_weight,还可以事先达到“对答案”的效果。和一个T大大佬在datacon域名安全检测比赛中使用的trick如出一辙。 - 基于海量url数据识别视频类网页
CV-行文思路:问题:视频类网页识别。解决方式:url粗筛->视频网页规则粗筛->视频网页截屏及CNN识别。
行业发展
- 认知智能再突破,阿里18 篇论文入选AI 顶会KDD
认知智能:计算智能->感知智能->认知智能。快速计算、记忆、存储->识别处理语言、图像、视频->实现思考、理解、推理和解释。认知智能的三大关键技术:知识图谱是底料、图神经网络是推理工具、用户交互是目的。 - 未来3~5 年内,哪个方向的机器学习人才最紧缺? - 王喆的回答
要点简记:站在机器学习“工程体系”之上,综合考虑“模型结构”,“工程限制”,“问题目标”的算法“工程师”。我的理解:红利的迁移,模型结构单点创新带来的收益->体系结构协同带来的收益。 阿里技术副总裁贾扬清:我对人工智能的一点浅见
AI发展:神经网络和深度学习的成功与局限,成功原因是大数据和高性能计算,局限原因是结构化的理解和小数据上的有效学习算法。 AI这个方向会怎么走?传统的深度学习应用,比如图像、语音等,应该如何输出产品和价值?而不仅仅是停留在安防这个层面,要深入到更广阔的领域。除了语音和图像之外,如何解决更多问题?而不仅仅是停留在解决语音图像等几个领域内的问题。
综合素质
- 算法工程师必须要知道的面试技能雷达图(学到了)
个人发展-必备技术素质:算法工程师必备技术素质拆分:知识、工具、逻辑、业务。 On the basis of meeting the minimum requirements, algorithm engineers have relatively comprehensive capabilities in these four aspects, including both "algorithm" and "engineering", while big data engineers focus on "tools" and researchers focus on "knowledge" and "logic" .
针对安全业务的算法工程师就是安全算法工程师。为了便于理解,举个例子,如果用XGBoost解决某个安全问题,那么可以由浅入深理解,把知识、工具、逻辑、业务四个方面串起来:
1.GBDT的原理(知识)
2.决策树节点分裂时是如何选择特征的? (ความรู้)
3.写出Gini Index和Information Gain的公式并举例说明(知识)
4.分类树和回归树的区别是什么(知识)
5.与Random Forest对比,理解什么是模型的偏差和方差(知识)
6.XGBoost的参数调优有哪些经验(工具)
7.XGBoost的正则化和并行化分别是如何实现的(工具)
8.为什么解决这个安全问题会出现严重的过拟合问题(业务)
9.如果选用一种其他模型替代XGBoost或改进XGBoost你会怎么做? ทำไม (业务、逻辑、知识)。
以上,就是以“知识”为切入点,不仅深度理解了“知识”,也深度理解了“工具”、“逻辑”、“业务”。
- [校招经验] BAT机器学习算法实习面试记录(学到了)
个人发展-面试经验:根据面试常遇到的问题再深入理解机器学习,储备自己的算法知识库。 - 机器学习如何才能避免「只是调参数」?(学到了)
个人发展-职业发展:机器学习工程师分为三种:应用型(能力:保持算法全栈,即数据、建模、业务、运维、后端,重点在建模能力,流程是遇到一个指定的业务场景应该迅速知道用什么数据做特征,用什么模型,这个模型在工程上的时效性和鲁棒性,最终会不会产生业务风险等一整套链路。预期目标:锻炼得到很强的业务敏感性,快速验证提出的需求)、造轮子型(多读顶会跟上时代节奏,且拥有超强的功能能力,打造ML框架,提供给应用型机器学习工程师使用)、研究型(AI Lab,读论文+试验性复现)。 Personal development: Develop business and engineering capabilities. The growth plan for the next few years is still the full-stack algorithm route. I will be independent in technology and bring KPIs in business. I will be promoted quickly + lead the team in the future .同时保持阅读习惯,多学习新知识。 - 做机器学习算法工程师是什么样的工作体验?
个人发展-工作体验:业务理解、数据清洗和特征工程、持续学习(增强解决方案的判断力)、编程能力、常用工具(XGB、TensorFlow、ScikitLearn、Pandas(表格类数据或时间序列数据)、Spark、SQL、FbProphet(时间序列)) - 大三实习面经(学到了)
- 如果你是面试官,你怎么去判断一个面试者的深度学习水平?
个人发展-心得体会:深度学习擅长处理具有局部相关性的问题和数据,在图像、语音、自然语言处理方面效果显著,因为图像是由像素构成,语音是由音位构成,语言是由单词构成,都有局部相关性,可以构造高级特征。 - 面试官如何判断面试者的机器学习水平? - 微调的回答- 知乎
个人发展-心得体会:考虑方法优点和局限性,培养独立思考的能力;正确判断机器学习对业务的影响力;学会分情况讨论(比如深度学习相对于机器学习而言);学习机器学习不能停留在“知道”的层次,要从原理级学习,甚至可以从源码级学习,知其然知其所以然,要做安全圈机器学习最6的。 - 两年美团算法大佬的个人总结与学习建议
个人发展-心得体会:算法的基本认识(知识)、过硬的代码能力(工具)、数据处理和分析能力(业务和逻辑)、模型的积累和迁移能力(业务和逻辑)、产品能力、软实力。
วิชาชีพ
การวางแผนอาชีพ
กำลังคิด
- 如何解决思维混乱、讲话没条理的情况?(学到了)
结构化思维->讲话有条理。 - 哪些思维方式是你刻意训练过的? (学到了)
结构化思维
金字塔思维:结论先行,以上统下,归类分组,逻辑递进。
金字塔结构:纵向延伸,横向分类。
如何得出金字塔结论:归纳法,演绎推理法。实际生活中,不是每时每刻都有相关的模型套用和演绎法的,这时候就用归纳法,自下而上进行梳理,得出结论,比如头脑风暴把闪过的碎片想法全部写下来,再抽象与分类,最后得出结论。 - 厉害的人是怎么分析问题的?(学到了)
Define the problem/describe the problem: The essence of the problem is the gap between reality and expectations ; clarify the expected value B', accurately locate the current situation B, and use the gap B--->B' to accurately describe the ปัญหา.
分析问题/解决问题:不能从现状B出发,找寻一条B--->B'的路径,要透过现象看本质。方法A,现实B,期望B',变量C。校准期望B',重构方法A,消除变量C。
สื่อสาร
จัดการ
- “我是技术总监,你干嘛总问我技术细节?”
(快速发展期、平稳期、衰退期等业务发展时期作为时间轴)(中高层管理者)(需要掌握)(应用场景、技术基础、技术栈中的技术细节)。技术基础要扎实,技术栈了解程度深(对技术原理和细节清楚),应用场景不能浮于表面。总的来说就是一句话:技术细节与技术深度。 - 阿里巴巴高级算法专家威视:组建技术团队的一些思考(学到了)
行文思路:团队的定位(定位(能力、业务、服务)、壁垒(以不变应万变沉淀风险管控知识作为壁垒)和价值(提供不同层次的服务形式))-》团队的能力(连接、生产、传播、服务)-》组织与个人的关系-》招人-》用人-》对内管理模式(找对前进的方向、绩效的考核(3个维度:业务结果、能力进步、技术影响力))
学到了:建设技术体系解决某一类问题,而不是某个技术点去解决某一个问题。 - 26岁当上数据总监,分享第一次做Leader的心得
团队管理方面的基本功和方法论:定策略、建团队、立规矩、拿结果。
定策略:要明确公司高层的真实目的;对自己的团队了如指掌;管理者专精的行业知识和经验。
建团队:避免嫉贤妒能、职场近亲、玻璃心。
立规矩:立规矩守规矩。
拿结果:注意吃相。
管理中常见的误区:做管理后放弃原来专业(要关注行业发展方向和前沿技术);过度管理(要自循环的稳定成熟团队);过度追求团队稳定(衡量团队稳定的核心标准不是人员的稳定,而是团队的效率和产出是否能够有持续稳定的增长) - 什么特质的员工容易成为管理者
公司内部晋升管理者:天时:企业/行业所处的阶段;地利:部门/业务所处的阶段;人和:人际关系+自身能力。
跳槽成为管理者:大公司跳槽到小公司,寻找职业突破,弊端是跳出去容易跳回来难;成为行业内有影响力的人物,被大公司挖角。大部分人都是第一种情况,在大公司的同学要多一点耐心,通过努力在公司内晋升,因为曲线救国式的跳槽已经没有市场了。 - 技术部门Leader是不是一定要技术大牛担任?
核心点:Manager vs Tech Leader、方法论、软技能、赋能成员、综合。
คิด
- 好的研究想法从哪里来
研究的本质是对未知领域的探索,是对开放问题的答案的追寻。“好”的定义-》区分好与不好的能力-》全面了解所在研究方向的历史和现状-》实践法/类比法/组合法。这就好比是机器学习的训练和测试阶段,训练:全面了解所在研究方向的历史和现状,判断不同时期的研究工作的好与不好。测试:实践法/类比法/组合法出的idea,判断自己的研究工作好与不好。 - 科研论文如何想到不错的idea?
模块化学习、交叉、布局可预期的趋势。 - 人在年轻的时候,最核心的能力是什么?
核心点:达到以前从未达到的高度:基本的事情做到极致、专注、坚持长久做一件事、延迟满足、认清自己+了解环境->准确定位、
注意事项
- 领域点-线-面体系:点:自己focus的领域;线:上游和下游;面:大领域。不要过度focus在自己工作的领域,要有全局化的眼光,特别是自己的上游和下游。
- 日常学习点-线-面体系:点:自己focus的安全数据分析领域;线:安全/数据分析;面:全局安全内容/行业发展/职业规划。 Study a small field for at least one hour every day; read intensively for at least half an hour every day/at least one quality article on security/data analysis/industry development/career planning; browse a large number of incremental articles/stock articles ทุกวัน.保持学习与思考的敏感性。
ภาคผนวก
国外优质技术站点
- https://resources.distilnetworks.com
站点概况:专注于机器流量对抗与缓解。 - http://www.covert.io
技术栈:Jason Trost,专注于安全研究、大数据、云计算、机器学习,即安全数据科学。 - http://cyberdatascientist.com
站点概括:专注于安全数据科学,提供网络安全、统计学和AI等学习资料,并提供14个安全数据集,包括:垃圾邮件、恶意网站、恶意软件、Botnet等。没有secrepo.com提供的资料全面。 - https://towardsdatascience.com
站点概括:专注于数据科学。
国内优秀技术人
- michael282694
技术栈:数据分析挖掘产品开发、爬虫、Java、Python。 - LittleHann
技术栈:我也不知道该怎么描述,Han师傅会的太多了,C++、Java、Python、PHP、Web安全、系统安全,不过目前好像做算法多一些。 - FeeiCN
技术栈:专注自动化漏洞发现和入侵检测防御。 - xiaojunjie
技术栈:专注于代码审计、CTF。 - 云雷
技术栈:阿里云存储技术专家,专注于日志分析与业务,日志计算驱动业务增长。 - iami
技术栈:主要研究Web安全、机器学习,喜欢Python和Go。一直偷学师傅的博客。 - cdxy
技术栈:早先主要做Web安全,CTF,代码审计,现在主要做安全研究与数据分析,初步估算技术领先我1~2年,师傅别学了。 - csuldw
技术栈:专注于机器学习、数据挖掘、人工智能。 - molunerfinn
技术栈:专注于前端,北邮大佬,和404notfound同级。 - 刘建平Pinard
技术栈:机器学习、深度学习、强化学习、自然语言处理、数学统计学、大数据挖掘,相关tutorial非常棒。
ถูกทอดทิ้ง
- Efficient and Flexible Discovery of PHP Vulnerability译文
- Efficient and Flexible Discovery of PHP Application Vulnerabilities原文
- The Code Analysis Platform "Octopus"
- A Code Intelligence System:The Octopus Platform


