byol pytorch
0.8.2
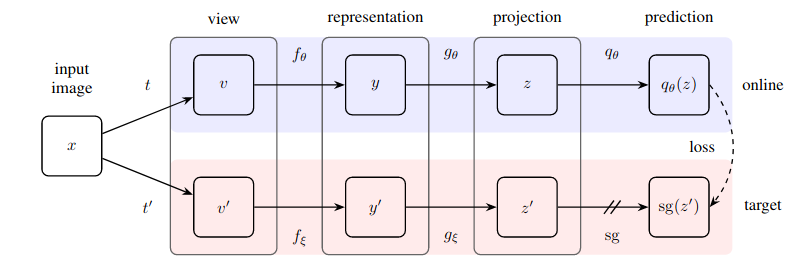
การนำวิธีการที่เรียบง่ายอย่างน่าประหลาดใจไปปฏิบัติจริงสำหรับการเรียนรู้แบบมีผู้ดูแลด้วยตนเองซึ่งบรรลุถึงความล้ำสมัยใหม่ (เหนือกว่า SimCLR) โดยไม่ต้องเรียนรู้แบบเปรียบเทียบและต้องกำหนดคู่เชิงลบ
พื้นที่เก็บข้อมูลนี้มีโมดูลที่สามารถรวมเครือข่ายประสาทเทียมที่ใช้รูปภาพใดๆ ได้อย่างง่ายดาย (เครือข่ายที่เหลือ ตัวแบ่งแยก เครือข่ายนโยบาย) เพื่อเริ่มรับประโยชน์จากข้อมูลรูปภาพที่ไม่มีป้ายกำกับทันที
อัปเดต 1: ขณะนี้มีหลักฐานใหม่ว่าการทำให้เป็นมาตรฐานแบบแบตช์เป็นกุญแจสำคัญในการทำให้เทคนิคนี้ทำงานได้ดี
อัปเดต 2: เอกสารใหม่ได้แทนที่มาตรฐานแบทช์ด้วยมาตรฐานกลุ่ม + มาตรฐานน้ำหนักเรียบร้อยแล้ว โดยหักล้างว่าสถิติแบทช์จำเป็นสำหรับ BYOL ในการทำงาน
อัปเดต 3: ในที่สุด เรามีการวิเคราะห์ว่าเหตุใดจึงใช้งานได้
คำอธิบายที่ยอดเยี่ยมของ Yannic Kilcher
ตอนนี้ไปช่วยองค์กรของคุณไม่ต้องจ่ายค่าป้ายกำกับ :)
$ pip install byol-pytorchเพียงเสียบปลั๊กโครงข่ายประสาทเทียมของคุณ โดยระบุ (1) ขนาดรูปภาพ รวมถึง (2) ชื่อ (หรือดัชนี) ของเลเยอร์ที่ซ่อนอยู่ ซึ่งเอาต์พุตจะใช้เป็นตัวแทนแฝงที่ใช้สำหรับการฝึกอบรมแบบมีผู้ดูแลด้วยตนเอง
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )นั่นก็ค่อนข้างมาก หลังจากการฝึกอบรมมามาก เครือข่ายที่เหลือควรจะทำงานได้ดีขึ้นกับงานที่ได้รับการดูแลดาวน์สตรีม
บทความใหม่จาก Kaiming He แนะนำว่า BYOL ไม่จำเป็นต้องมีตัวเข้ารหัสเป้าหมายเพื่อเป็นค่าเฉลี่ยเคลื่อนที่แบบเอ็กซ์โปเนนเชียลของตัวเข้ารหัสออนไลน์ ฉันได้ตัดสินใจสร้างตัวเลือกนี้เพื่อให้คุณสามารถใช้ตัวแปรนั้นสำหรับการฝึกอบรมได้อย่างง่ายดาย เพียงตั้งค่าสถานะ use_momentum เป็น False คุณไม่จำเป็นต้องเรียกใช้ update_moving_average อีกต่อไป หากคุณไปตามเส้นทางนี้ดังที่แสดงในตัวอย่างด้านล่าง
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )แม้ว่าไฮเปอร์พารามิเตอร์ได้รับการตั้งค่าให้เป็นสิ่งที่กระดาษพบว่าเหมาะสมที่สุดแล้ว คุณสามารถเปลี่ยนแปลงได้ด้วยอาร์กิวเมนต์คำหลักเพิ่มเติมในคลาส wrapper พื้นฐาน
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) ตามค่าเริ่มต้น ไลบรารีนี้จะใช้ส่วนเสริมจากกระดาษ SimCLR (ซึ่งใช้ในกระดาษ BYOL ด้วย) อย่างไรก็ตาม หากคุณต้องการระบุไปป์ไลน์การเพิ่มของคุณเอง คุณสามารถส่งฟังก์ชันการเพิ่มที่คุณกำหนดเองด้วยคีย์เวิร์ด augment_fn ได้
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)ในรายงานนี้ ดูเหมือนว่าพวกเขาจะรับประกันว่าการเสริมแบบใดแบบหนึ่งมีความน่าจะเป็นแบบเกาส์เซียนเบลอที่สูงกว่าแบบอื่น คุณสามารถปรับเปลี่ยนสิ่งนี้ได้ตามใจชอบ
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) หากต้องการดึงข้อมูลการฝังหรือการฉายภาพ คุณเพียงแค่ต้องส่งค่าสถานะ return_embeddings = True ไปยังอินสแตนซ์ของผู้เรียน BYOL
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) ขณะนี้พื้นที่เก็บข้อมูลมีการฝึกอบรมแบบกระจายด้วย ? กอดหน้าเร่งความเร็ว คุณเพียงแค่ต้องส่ง Dataset ของคุณเองไปยัง BYOLTrainer ที่นำเข้า
ขั้นแรก ให้ตั้งค่าการกำหนดค่าสำหรับการฝึกแบบกระจายโดยการเรียกใช้ Accelerate CLI
$ accelerate config จากนั้นสร้างสคริปต์การฝึกของคุณตามที่แสดงด้านล่าง พูดใน ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()จากนั้นใช้ Accelerator CLI อีกครั้งเพื่อเรียกใช้สคริปต์
$ accelerate launch ./train.pyหากงานดาวน์สตรีมของคุณเกี่ยวข้องกับการแบ่งส่วน โปรดดูที่พื้นที่เก็บข้อมูลต่อไปนี้ ซึ่งขยาย BYOL ไปสู่การเรียนรู้ระดับ 'พิกเซล'
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

