atari
1.0.0

Research Playground สร้างขึ้นบน Atari Gym ของ OpenAI ซึ่งเตรียมไว้สำหรับการนำอัลกอริธึมการเรียนรู้แบบเสริมกำลังต่างๆ ไปใช้
มันสามารถจำลองเกมใด ๆ ต่อไปนี้:
['Asterix', 'ดาวเคราะห์น้อย', 'MsPacman', 'Kaboom', 'BankHeist', 'Kangaroo', 'สกี', 'FishingDerby', 'Krull', 'Berzerk', 'Tutankham', 'Zaxxon', ' กิจการ', 'Riverraid', 'Centipede', 'การผจญภัย', 'BeamRider', 'CrazyClimber', 'TimePilot', 'Carnival', 'เทนนิส', 'Seaquest', 'โบว์ลิ่ง', 'SpaceInvaders', 'ทางด่วน', 'YarsRevenge', 'RoadRunner ', 'JourneyEscape', 'พ่อมดแห่งWor', 'โกเฟอร์', 'ฝ่าวงล้อม', 'StarGunner', 'แอตแลนติส', 'DoubleDunk', 'ฮีโร่', 'BattleZone', 'Solaris', 'UpNDown', 'Frostbite', 'KungFuMaster', 'Pooyan', 'Pitfall ', 'MontezumaRevenge', 'PrivateEye', 'AirRaid', 'Amidar', 'Robotank', 'DemonAttack', 'Defender', 'NameThisGame', 'Phoenix', 'Gravitar', 'ElevatorAction', 'โป่ง', 'VideoPinball', 'IceHockey', 'มวย ', 'จู่โจม', 'เอเลี่ยน', 'คิวเบิร์ต', 'เอนดูโร', 'ช็อปเปอร์คอมมานด์', 'เจมส์บอนด์']
ลองอ่านบทความสื่อที่เกี่ยวข้อง: Atari - การเรียนรู้การเสริมกำลังในเชิงลึก ? (ส่วนที่ 1: DDQN)
เป้าหมายสูงสุดของโปรเจ็กต์นี้คือการใช้และเปรียบเทียบแนวทาง RL ต่างๆ กับเกมอาตาริที่เป็นตัวส่วนร่วม
pip install -r requirements.txtpython atari.py --help * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
โครงข่ายประสาทเทียมเชิงลึกโดย DeepMind
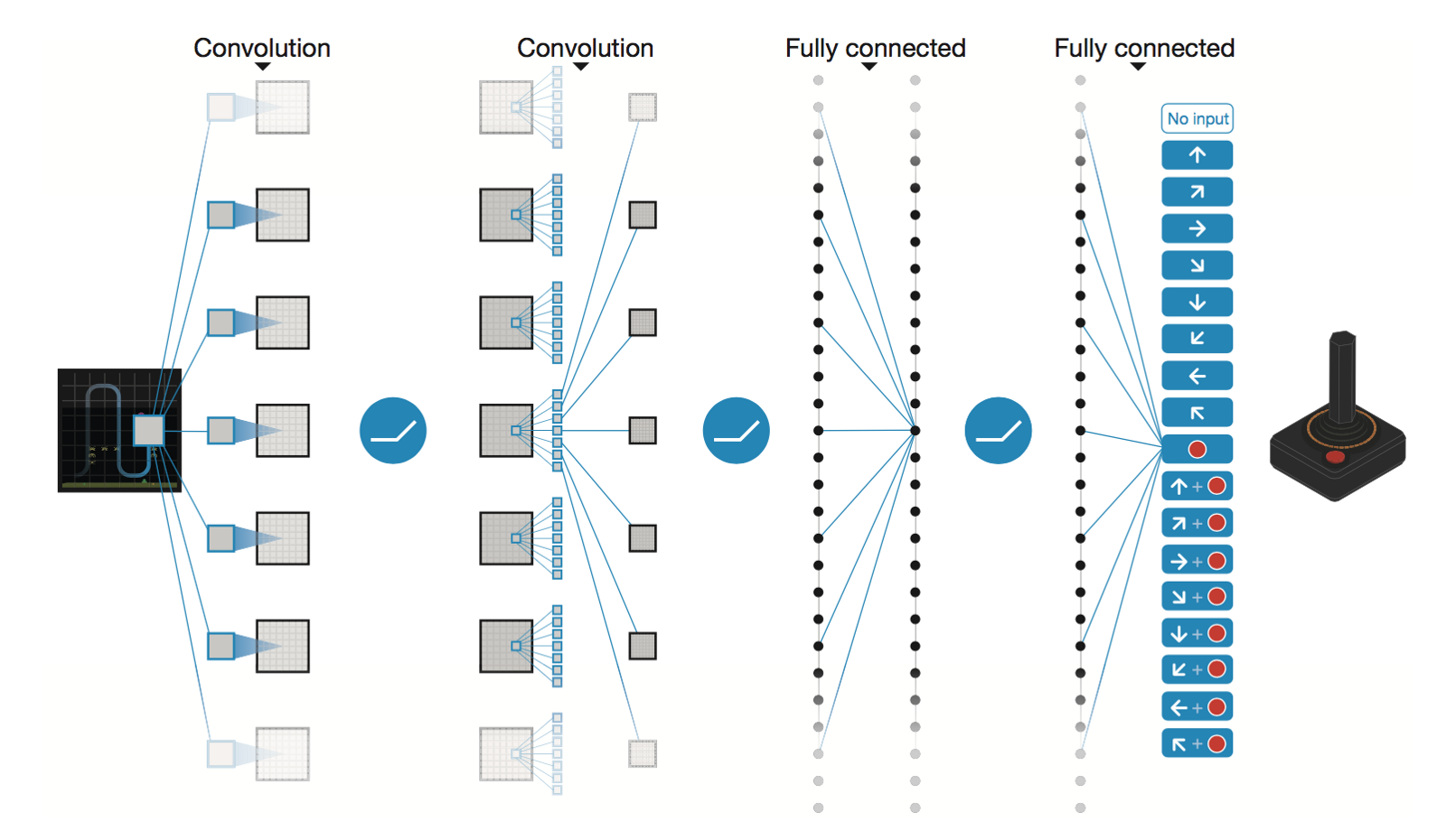
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
หลังจาก 5M ขั้นตอน ( ~40 ชั่วโมง บน Tesla K80 GPU หรือ ~90 ชั่วโมง บน 2.9 GHz Intel i7 Quad-Core CPU):
การฝึกอบรม:
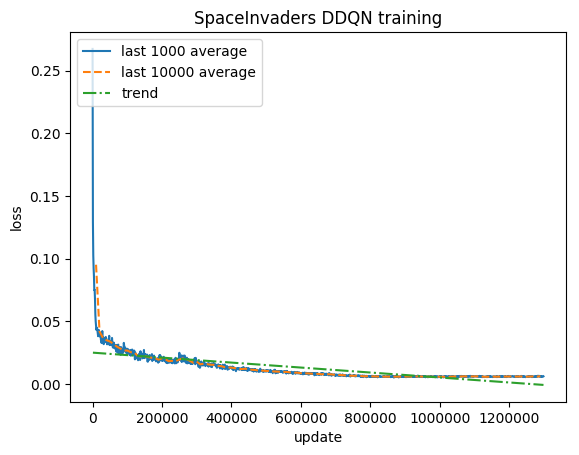
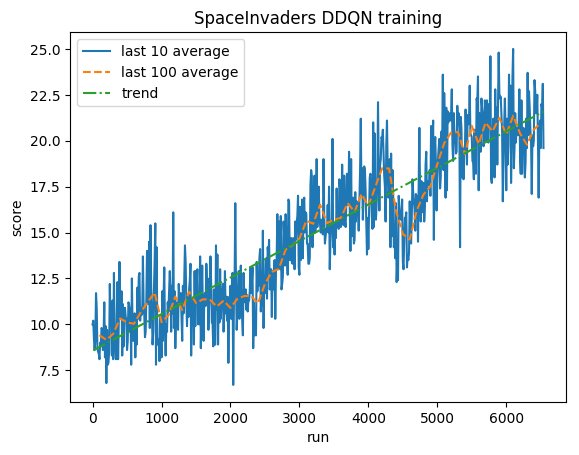
คะแนนปกติ - แต่ละรางวัลถูกตัดเป็น (-1, 1)
การทดสอบ:
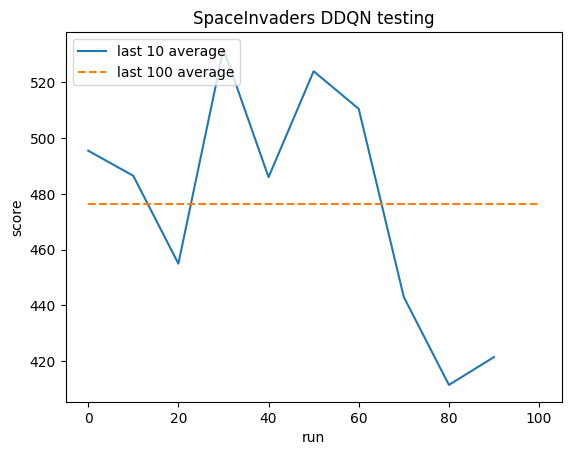
ค่าเฉลี่ยของมนุษย์: ~372
ค่าเฉลี่ย DDQN: ~479 (128%)
การฝึกอบรม:
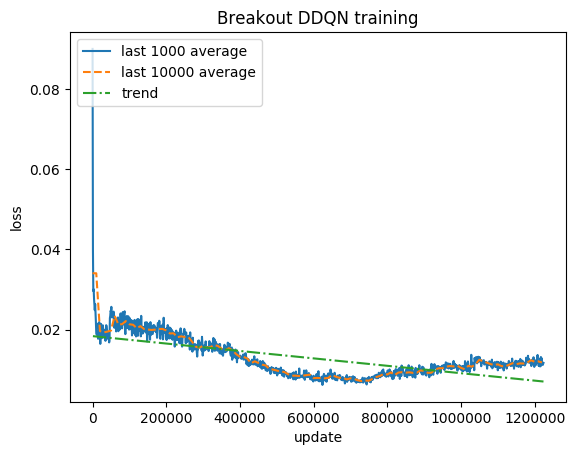
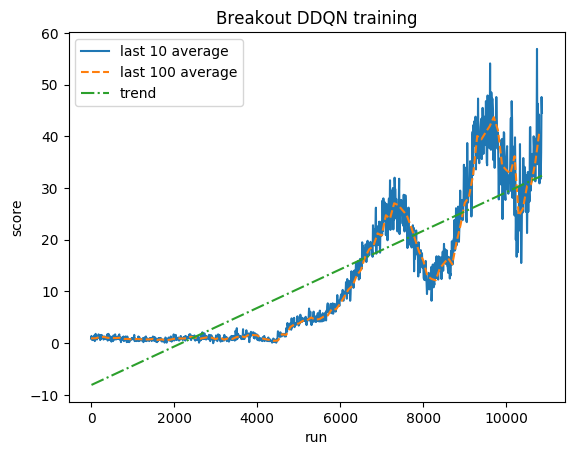
คะแนนปกติ - แต่ละรางวัลถูกตัดเป็น (-1, 1)
การทดสอบ:
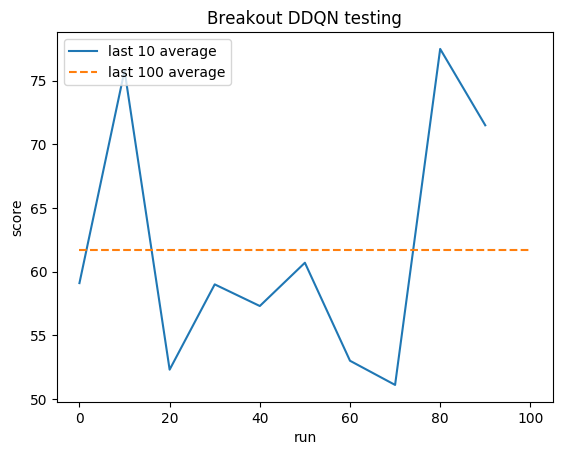
ค่าเฉลี่ยของมนุษย์: ~28
ค่าเฉลี่ย DDQN: ~62 (221%)
การฝึกอบรม:
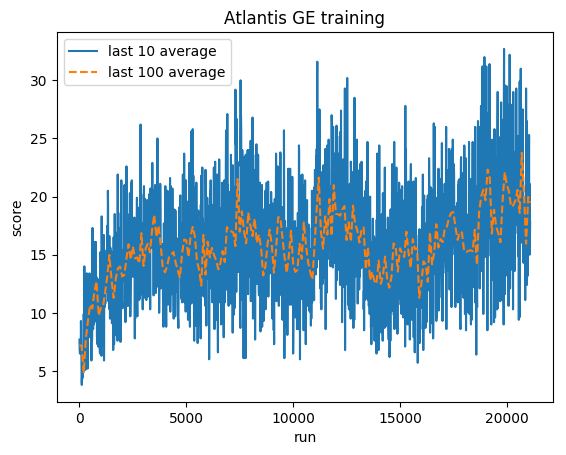
คะแนนปกติ - แต่ละรางวัลถูกตัดเป็น (-1, 1)
การทดสอบ:

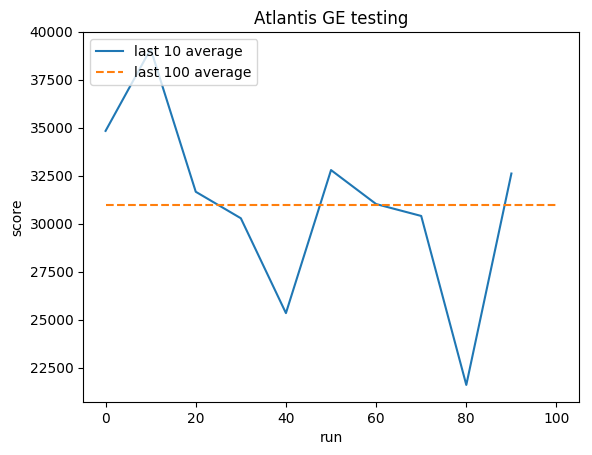
ค่าเฉลี่ยมนุษย์: ~29,000
GE เฉลี่ย: 31,000 (106%)
เกร็ก (เกรซกอร์ซ) เซอร์มา
ผลงาน
GITHUB
บล็อก


